

Neste guia, você aprenderá:
- O que é um Scraper do ZoomInfo e como ele funciona
- Os tipos de dados que você pode extrair automaticamente do ZoomInfo
- Como criar um script de scraping do ZoomInfo usando Python
- Quando e por que uma solução mais avançada pode ser necessária
Vamos começar!
O que é um Scraper do ZoomInfo?
Um scraper do ZoomInfo é uma ferramenta para extrair dados do ZoomInfo, uma plataforma líder que oferece informações detalhadas sobre empresas e profissionais. Essa solução automatiza o processo de scraping, permitindo que você colete muitos dados. O scraper utiliza técnicas como automação de navegador para navegar no site e recuperar conteúdo.
Dados que você pode recuperar do ZoomInfo
Aqui estão alguns dos dados mais importantes que você pode extrair do ZoomInfo:
- Informações sobre empresas: nomes, setores, receita, sedes e número de funcionários.
- Detalhes dos funcionários: nomes, cargos, e-mails e números de telefone.
- Informações sobre o setor: concorrentes, tendências de mercado e hierarquias da empresa.
Extraindo dados do ZoomInfo em Python: guia passo a passo
Nesta seção, você aprenderá como criar um Scraper do ZoomInfo.
O objetivo é orientá-lo na criação de um script Python que coleta automaticamente dados dapágina da empresa NVIDIA ZoomInfo.
Siga as etapas abaixo!
Etapa 1: Configuração do projeto
Antes de começar, certifique-se de que o Python 3 esteja instalado em seu computador. Caso contrário, baixe-o e instale-o seguindo o assistente.
Agora, use o seguinte comando para criar uma pasta para o seu projeto:
mkdir zoominfo-scraper
O diretório zoominfo-scraper representa a pasta do projeto do seu scraper Python ZoomInfo.
Entre nela e inicialize um ambiente virtual dentro dela:
cd zoominfo-Scraper
python -m venv env
Carregue a pasta do projeto em seu IDE Python favorito. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são opções adequadas.
Crie um arquivo scraper.py na pasta do projeto, que deve conter a estrutura de arquivos abaixo:

No momento, o scraper.py é um script Python em branco. Em breve, ele conterá a lógica de raspagem desejada.
No terminal do IDE, ative o ambiente virtual. No Linux ou macOS, execute este comando:
./env/bin/activate
Da mesma forma, no Windows, execute:
env/Scripts/activate
Ótimo, agora você tem um ambiente Python para Scraping de dados!
Etapa 2: selecione a biblioteca de scraping
Antes de mergulhar na programação, você deve entender quais ferramentas são mais adequadas para atingir o objetivo. Para fazer isso, você deve primeiro realizar um teste preliminar para estudar o site de destino. Veja como:
- Abra a página de destino no modo de navegação anônima do seu navegador. Isso evita que cookies e preferências pré-armazenados afetem sua análise.
- Clique com o botão direito do mouse em qualquer lugar da página e selecione “Inspecionar” para abrir as ferramentas de desenvolvedor do navegador.
- Navegue até a guia “Rede”.
- Recarregue a página e examine a atividade na guia “Busca/XHR”.
Isso lhe dará uma visão sobre como a página da web se comporta no momento da renderização:
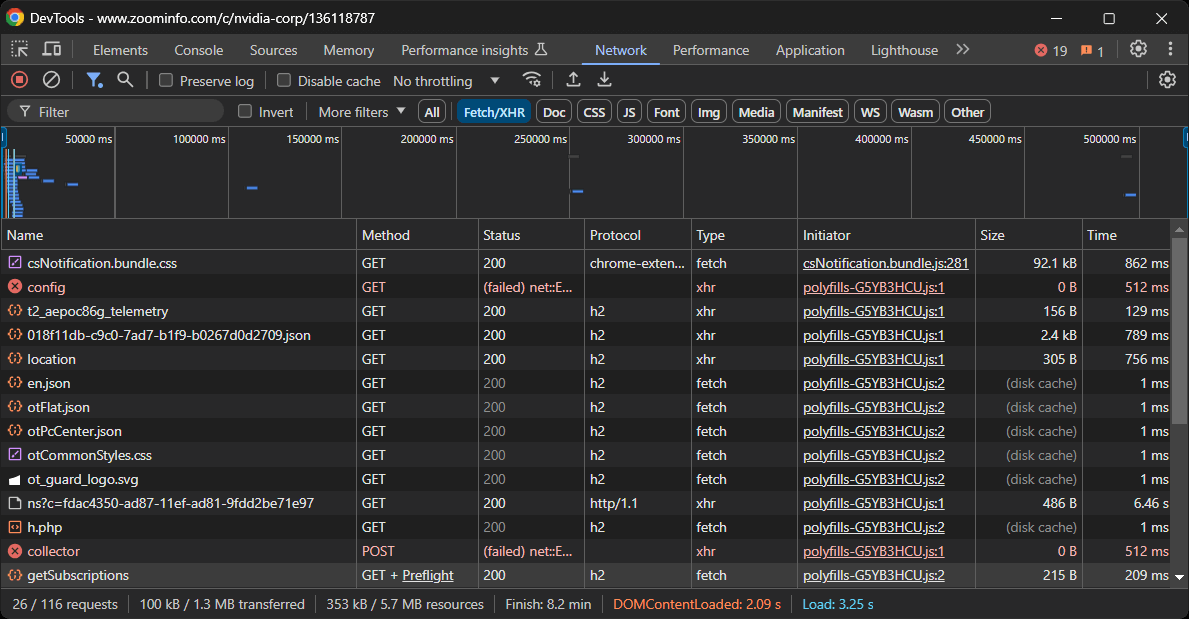
Nesta seção, você pode visualizar todas as solicitações AJAX dinâmicas feitas pela página. Inspecione cada solicitação e você perceberá que nenhuma delas contém dados relevantes. Isso indica que a maioria das informações na página já está incorporada no documento HTML retornado pelo servidor.
Os resultados naturalmente o levarão a adotar um cliente HTTP e um analisador HTML para extrair dados do ZoomInfo. No entanto, o site usa tecnologias anti-bot rigorosas que podem bloquear a maioria das solicitações automatizadas que não se originam de um navegador. A maneira mais simples de contornar isso é usando uma ferramenta de automação de navegador como o Selenium!
O Selenium permite controlar um navegador da web programaticamente, instruindo-o a realizar ações específicas em páginas da web, como usuários reais fariam. É hora de instalá-lo e começar a usá-lo!
Etapa 3: Instale e configure o Selenium
Em Python, o Selenium está disponível através do pacote pip selenium. Em um ambiente virtual Python ativado, instale-o com este comando:
pip install -U selenium
Para obter orientações sobre como usar a ferramenta, siga nosso tutorial sobre Scraping de dados com o Selenium.
Importe o Selenium em scraper.py e inicialize um objeto WebDriver para controlar uma instância do Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# criar uma instância do driver web do Chrome
driver = webdriver.Chrome(service=Service())
O código acima cria uma instância do WebDriver para operar no Chrome. Observe que o ZoomInfo usa tecnologia anti-scraping que bloqueia navegadores headless. Portanto, você não pode definir o sinalizador --headless. Como solução alternativa, considere explorar o Playwright Stealth.
Na última linha do seu Scraper, lembre-se de fechar o driver da web:
driver.quit()
Ótimo! Agora você está totalmente configurado para começar a fazer scraping no ZoomInfo.
Etapa 4: conecte-se à página de destino
Use o método get() de um objeto Selenium WebDriver para instruir o navegador a visitar a página desejada:
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
Seu arquivo scraper.py agora deve conter estas linhas de código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# criar uma instância do Chrome Web Driver
driver = webdriver.Chrome(service=Service())
# conectar-se à página de destino
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# lógica de raspagem...
# fechar o navegador
driver.quit()
Coloque um ponto de interrupção de depuração na linha final e execute o script. Ele deve levá-lo à página da empresa NVIDIA.
A mensagem “O Chrome está sendo controlado por um software de teste automatizado” certifica que o Selenium está controlando o Chrome conforme o esperado. Muito bem!
Etapa 5: extraia as informações gerais da empresa
Você precisa analisar a estrutura DOM da página para entender como extrair os dados necessários. O objetivo é identificar os elementos HTML que contêm os dados desejados. Comece inspecionando os elementos na seção superior da seção de informações da empresa:
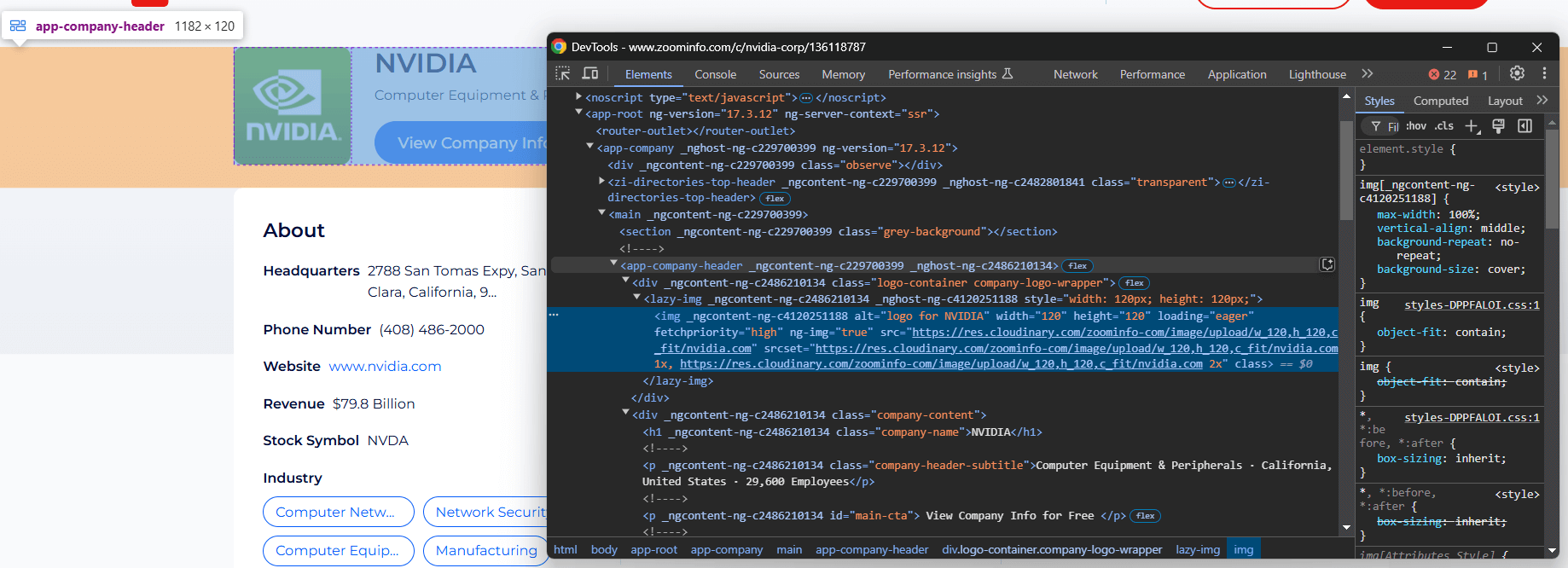
O elemento <app-company-header> contém:
- A imagem da empresa em uma tag
<img>dentro de um<div>com a classecompany-logo-wrapper. - O nome da empresa dentro de um nó com a classe
company-name. - O subtítulo da empresa armazenado em um nó com a classe
company-header-subtitle.
Use o Selenium para localizar esses elementos e coletar dados deles:
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
Para que o código funcione, não se esqueça de importar By:
from selenium.webdriver.common.by import By
Observe que o método find_element() seleciona um nó usando a estratégia de seleção de nó especificada. Acima, usamos seletores CSS. Saiba mais sobre a diferença entre seletores XPath e CSS.
Em seguida, você pode acessar o conteúdo do nó com o atributo de texto. Para acessar um atributo, utilize o método get_attribute().
Imprima os dados coletados:
print(logo_url)
print(name)
print(subtitle)
Este é o resultado que você obterá:
https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com
NVIDIA
Equipamentos e periféricos de computador · Califórnia, Estados Unidos · 29.600 funcionários
Uau! O Scraper ZoomInfo funciona muito bem.
Etapa 6: extraia as informações da seção “Sobre”
Concentre-se na seção “Sobre” da página da empresa:
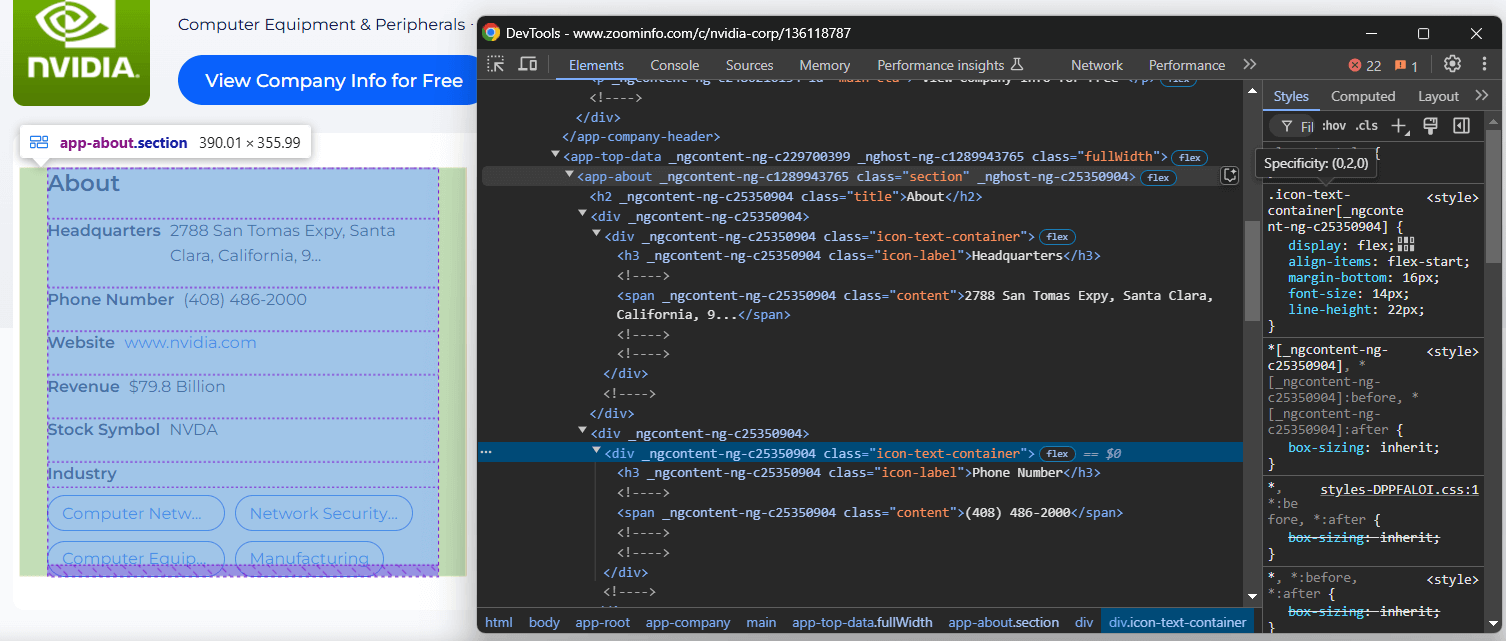
O nó <app-about> contém elementos com classes genéricas e atributos aparentemente gerados aleatoriamente. Como esses atributos podem mudar a cada compilação, você deve evitar confiar neles para selecionar elementos para extrair.
Para extrair as informações desta seção, comece selecionando o nó <app-about>:
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
Agora, concentre-se em todos os elementos .icon-text-container dentro de <app-about>. Em seguida, inspecione seus rótulos (.icon-label) para identificar os elementos específicos de interesse. Se o rótulo corresponder, extraia os dados do elemento .content. Encapsule essa lógica em uma função:
def scrape_about_node(text_container_elements, text_label):
# itere por eles para extrair dados dos
# nós específicos de interesse
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# selecione o elemento de conteúdo e extraia os dados dele
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
Você pode então extrair as informações “Sobre” com:
headquarters = scrape_about_node(text_container_elements, "Headquarters")
phone_number = scrape_about_node(text_container_elements, "Phone Number")
revenue = scrape_about_node(text_container_elements, "Revenue")
stock_symbol = scrape_about_node(text_container_elements, "Stock Symbol")
Em seguida, selecione as tags do setor e da empresa.
Selecione o setor da empresa com h3 .incon-label e as tags com zi-directories-chips a. Extraia os dados deles com:
elemento_do_setor = about_element.find_element(By.CSS_SELECTOR, "h3.icon-label")
setor = elemento_do_setor.texto
elementos_da_tag = about_element.find_elements(By.CSS_SELECTOR, "zi-directories-chips a")
tags = [elemento_da_tag.texto para elemento_da_tag em elementos_da_tag]
Incrível! A lógica de extração de dados do ZoomInfo está completa.
Etapa 7: coletar os dados coletados
Atualmente, você tem os dados coletados espalhados por várias variáveis. Preencha um novo objeto da empresa com esses dados:
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
Imprima os dados coletados para garantir que eles contenham as informações desejadas
imprimir(itens)
Isso produzirá a seguinte saída:
{'logo_url': 'https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com', 'name': 'NVIDIA', 'subtitle': 'Equipamentos e periféricos de computador · Califórnia, Estados Unidos · 29.600 funcionários', 'headquarters': '2788 San Tomas Expy, Santa Clara, Califórnia, 95051, Estados Unidos', 'phone_number': '(408) 486-2000', 'receita': 'US$ 79,8 bilhões', 'símbolo_da_ação': 'NVDA', 'setor': 'Sede', 'tags': ['Equipamentos de rede de computadores', 'Hardware e software de segurança de rede', 'Equipamentos e periféricos de computador', 'Manufatura']}
Fantástico! Agora só falta exportar essas informações para um arquivo legível, como JSON.
Etapa 8: Exportar para JSON
Exporte a empresa para um arquivo company.json com:
com open("company.json", "w") como json_file:
json.dump(company, json_file, indent=4)
Primeiro, open() cria um arquivo de saída company.json. Em seguida, json.dump() transforma a empresa em sua representação JSON e a grava no arquivo de saída.
Lembre-se de importar json da biblioteca padrão do Python:
import json
Etapa 9: Junte tudo
Abaixo está o arquivo scraper.py final:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
def scrape_about_node(text_container_elements, text_label):
# itere por eles para extrair dados dos
# nós específicos de interesse
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# selecione o elemento de conteúdo e extraia os dados dele
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
retornar None
# criar uma instância do driver web Chrome
driver = webdriver.Chrome(service=Service())
# conectar-se à página de destino
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# extrair as informações da empresa
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
# extrair dados da seção "Sobre"
elemento_sobre = driver.find_element(By.CSS_SELECTOR, "app-about")
elementos_contêiner_texto = elemento_sobre.find_elements(By.CSS_SELECTOR, ".icon-text-container")
headquarters = scrape_about_node(text_container_elements, "Headquarters")
phone_number = scrape_about_node(text_container_elements, "Phone Number")
revenue = scrape_about_node(text_container_elements, "Revenue")
stock_symbol = scrape_about_node(text_container_elements, "Stock Symbol")
# extrair o setor e as tags da empresa
elemento_setor = about_element.find_element(By.CSS_SELECTOR, "h3.icon-label")
setor = elemento_setor.text
elementos_tag = about_element.find_elements(By.CSS_SELECTOR, "zi-directories-chips a")
tags = [tag_element.text para tag_element em tag_elements]
# coletar os dados extraídos
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
# exportar os dados coletados para JSON
com open("company.json", "w") como json_file:
json.dump(company, json_file, indent=4)
# fechar o navegador
driver.quit()
Em pouco mais de 70 linhas de código, você acabou de criar um script de extração de dados do ZoomInfo em Python!
Inicie o Scraper com o seguinte comando:
python3 script.py
Ou, no Windows:
python script.py
Um arquivo company.json aparecerá na pasta do seu projeto. Abra-o e você verá:
{
"logo_url": "https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com",
"name": "NVIDIA",
"subtitle": "Equipamentos e periféricos de computador · Califórnia, Estados Unidos · 29.600 funcionários",
"headquarters": "2788 San Tomas Expy, Santa Clara, Califórnia, 95051, Estados Unidos",
"phone_number": "(408) 486-2000",
"revenue": "$79,8 bilhões",
"stock_symbol": "NVDA",
"industry": "Headquarters",
"tags": [
"Equipamentos de rede de computadores",
"Hardware e software de segurança de rede",
"Equipamentos e periféricos de informática",
"Fabricação"
]
}Parabéns, missão concluída!
Desbloqueando dados do ZoomInfo com facilidade
O ZoomInfo oferece muito mais do que apenas visões gerais das empresas — ele fornece uma grande variedade de informações úteis. O problema é que extrair esses dados pode ser bastante desafiador, pois a maioria das páginas do domínio ZoomInfo é protegida por medidas anti-bot.
Se você tentar acessar essas páginas usando o Selenium ou outras ferramentas de automação de navegador, provavelmente encontrará uma página CAPTCHA bloqueando suas tentativas.
Como primeiro passo, considere seguir nosso guia sobre como contornar CAPTCHAs em Python. No entanto, você ainda pode enfrentar erros 429 Too Many Requests devido à limitação de taxa rigorosa do site. Nesses casos, você pode integrar um Proxy ao Selenium para alternar seu IP de saída.
Essas questões resumem como a extração de dados do ZoomInfo sem as ferramentas certas pode rapidamente se tornar um processo frustrante. Além disso, o fato de você não poder usar navegadores headless torna seu script de extração lento e consome muitos recursos.
A solução? Usar a API dedicada ZoomInfo Scraper da Bright Data para recuperar dados do site de destino por meio de chamadas de API simples e sem ser bloqueado!
Conclusão
Neste tutorial passo a passo, você aprendeu o que é um Scraper do ZoomInfo e os tipos de dados que ele pode recuperar. Você também criou um script Python para extrair dados gerais da empresa do ZoomInfo, o que exigiu muito menos do que 100 linhas de código.
O desafio é que o ZoomInfo emprega medidas anti-bot rigorosas, incluindo CAPTCHAs, impressão digital do navegador e bloqueios de IP, para bloquear scripts automatizados. Esqueça todos esses desafios com nossa API ZoomInfo Scraper.
Se o Scraping de dados não é para você, mas você ainda está interessado em dados de empresas ou funcionários, explore nossos Conjuntos de dados ZoomInfo!
Crie uma conta gratuita na Bright Data hoje mesmo para experimentar nossas APIs de Scraper ou explorar nossos Conjuntos de dados.




