

Há quase 25 anos, o Tripadvisor é um ótimo lugar para descobrir todos os tipos de destinos de viagem na web. Hoje, vamos extrair dados de hotéis do Tripadvisor. O Tripadvisor emprega uma variedade de técnicas para bloquear Scrapers, tais como:
- Desafios de JavaScript
- Impressão digital do navegador
- Conteúdo dinâmico da página
Siga nosso guia abaixo e, ao final, você estará coletando dados do Tripadvisor com facilidade.
Pré-requisitos
O Tripadvisor usa várias técnicas de bloqueio. Para simplificar, nós as dividimos na lista abaixo.
- Desafio JavaScript: o Tripadvisor envia um desafio simples (em JavaScript) para o seu navegador na forma de um CAPTCHA. Se o seu navegador não conseguir resolvê-lo, é provável que seja um bot.
- Impressão digital do navegador: eles enviam um cookie para o seu navegador e, em seguida, rastreiam você com ele.
- Conteúdo dinâmico: inicialmente, recebemos uma página em branco. Em seguida, ele faz uma série de chamadas de API para buscar e renderizar nossos dados.
Python Requests e BeautifulSoup simplesmente não darão conta do recado. Precisamos de um navegador real. Com o Selenium, usamos o webdriver para controlar nosso navegador a partir de um script Python. O Selenium vem com tudo o que precisamos. Saiba mais sobre Scraping de dados com Selenium aqui.
Vamos instalar o Selenium. Você também deve se certificar de que o webdriver está instalado. Você pode encontrar a versão mais recente do webdriver aqui. Você deve se certificar de que a sua versão do Chromedriver corresponde à sua versão do Chrome.
Você pode verificar o número da sua versão com o seguinte comando. Certifique-se de que ela corresponda à sua versão do Chromedriver.
google-chrome --version
O resultado deve ser semelhante a este.
Google Chrome 130.0.6723.116
Em seguida, podemos instalar o Selenium com o seguinte comando.
pip install selenium
Com o Selenium instalado, não precisamos instalar mais nada. O Selenium cuidará de todas as nossas necessidades relacionadas à extração de dados. Todos os outros pacotes deste tutorial vêm pré-instalados com o Python.
O que extrair do Tripadvisor
Vamos dar uma olhada em como exatamente faremos o scraping de hotéis do Tripadvisor. Quando fazemos uma pesquisa básica por Miami no Tripadvisor, obtemos uma página semelhante à que você vê na captura de tela abaixo. Se você observar, não estamos obtendo apenas resultados para hotéis, mas para todas as categorias.
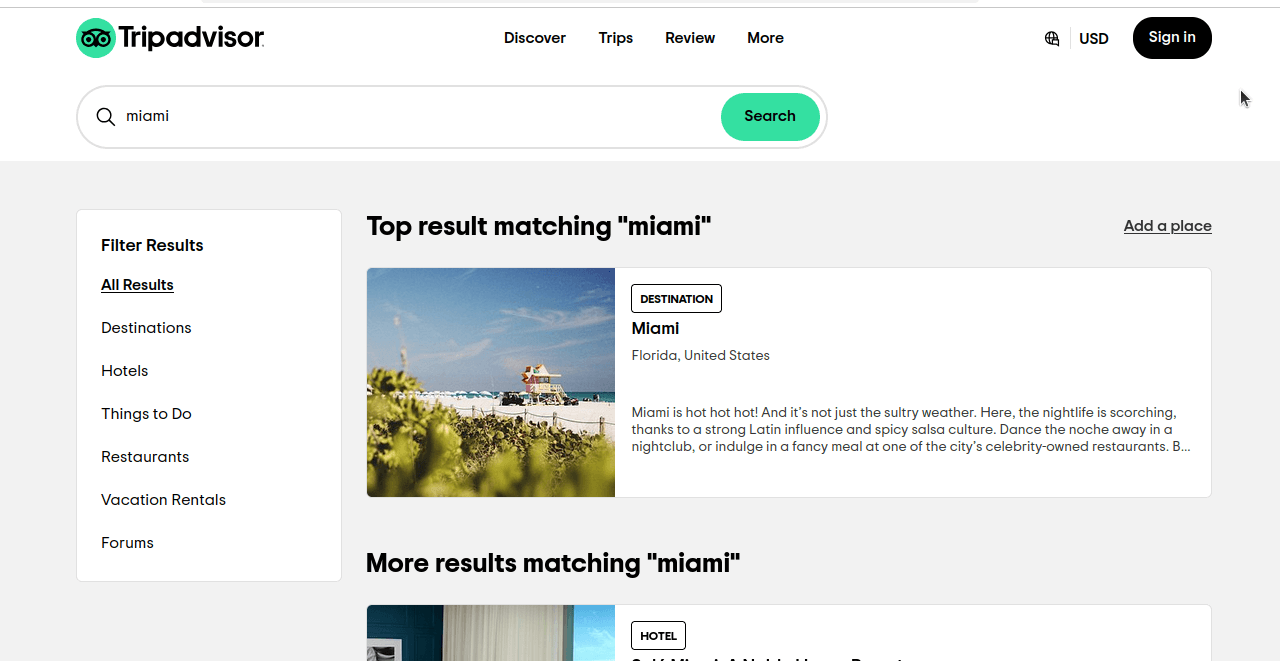
Observe mais de perto a URL desta página: https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. Agora, vamos clicar em Hotéis e examinar nossa URL: https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h&searchNearby=false&searchSessionId=001f4b791e61703a.ssid&offset=0. Os URLs ainda parecem muito semelhantes. Abaixo, vamos dar uma olhada nesses URLs, mas removeremos as partes desnecessárias.
- Todos os resultados:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=a - Hotéis:
https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h.
ssrc é a consulta que usamos para selecionar nossos resultados. ssrc=a é usado para Todos os resultados. ssrc=h é usado para Hotéis. Se você clicar neste link https://www.tripadvisor.com/Search?q=miami&geo=1&ssrc=h, deverá obter uma página semelhante à que você vê na captura de tela abaixo.
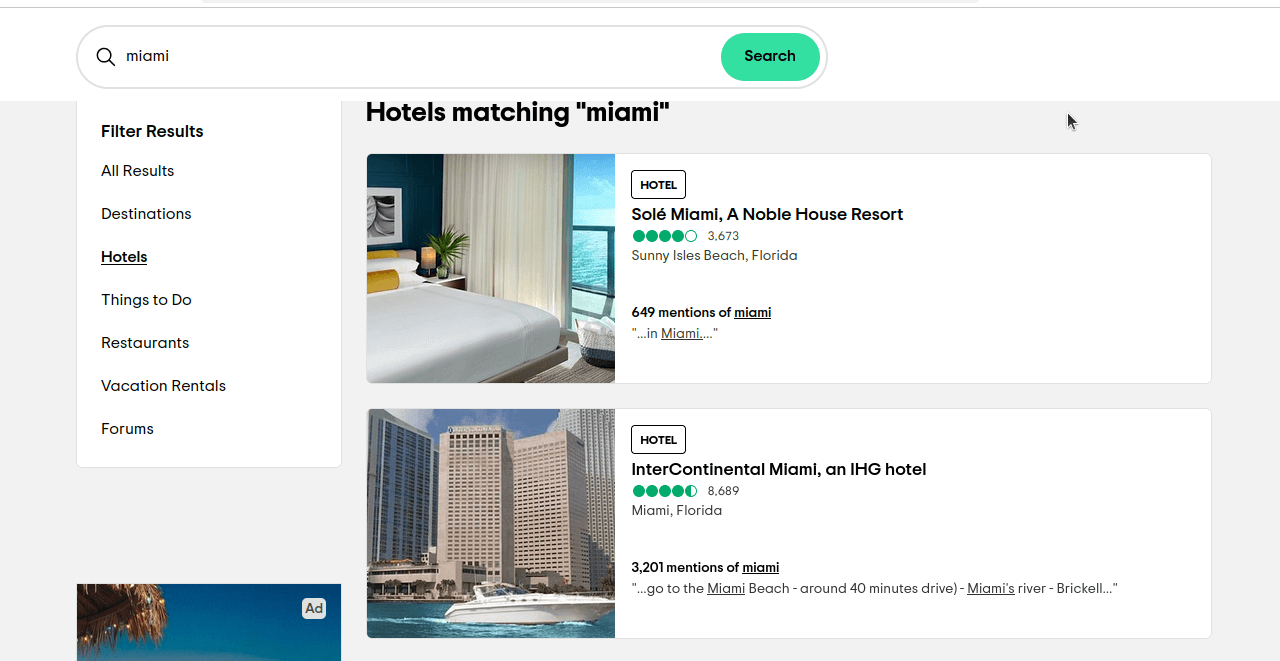
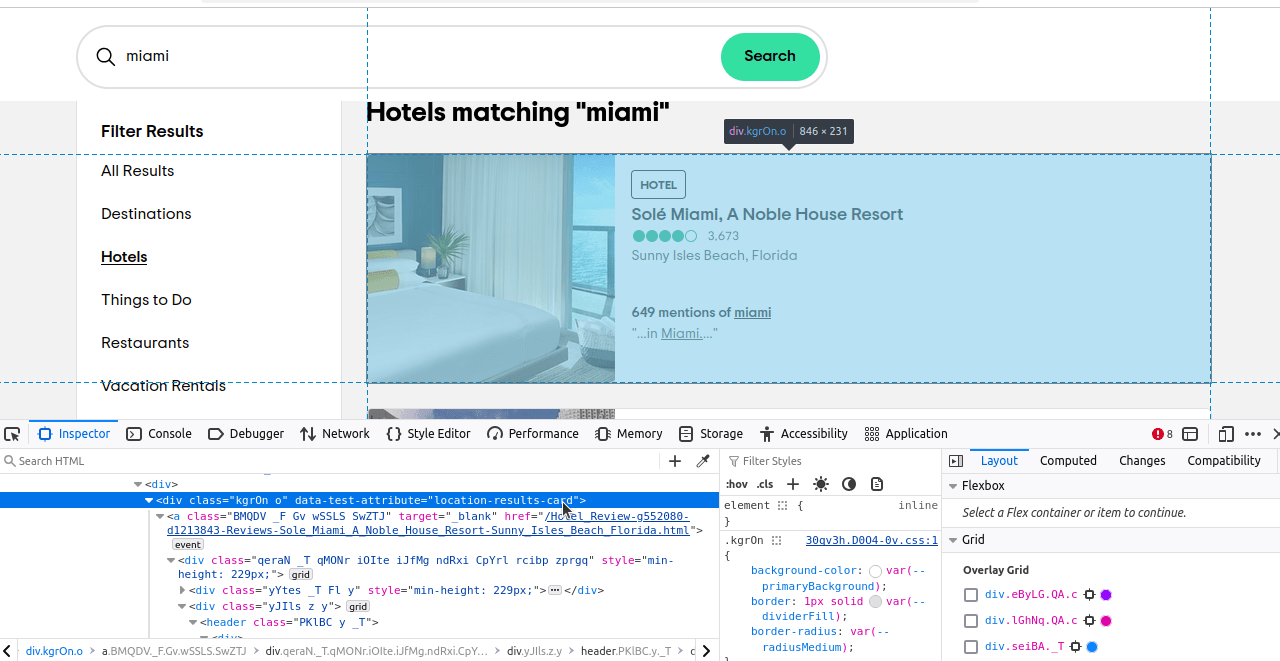
Agora, só precisamos descobrir quais elementos queremos localizar. Se você inspecionar esses elementos, verá que cada resultado tem um atributo de teste de dados “location-results-card”. Isso é muito importante. Podemos usar isso para escrever nosso seletor CSS: div[data-test-attribute='location-results-card']. Quando rastrearmos a página real, procuraremos todos os elementos na página que correspondam a esse seletor.
Extrair dados do Tripadvisor com o Vanilla Selenium
Agora, vamos tentar extrair o Tripadvisor usando o bom e velho Selenium. Vamos escrever um script que é bastante simples no geral. Na verdade, precisamos apenas de duas funções. Precisamos de uma para realizar nossa extração e outra para gravar nossos dados em CSV. Depois de ter isso, vamos juntar tudo em um script totalmente funcional.
Dê uma olhada em write_to_csv(). Ele recebe dois argumentos, data e page_number. data pode ser um dicionário ou uma matriz de objetos dicionários que queremos gravar. page_number é usado para gravar nosso nome de arquivo. Usamos Path(filename).exists() para verificar se nosso arquivo existe. mode é o modo que usamos para abrir o arquivo. Se o arquivo existir, definimos nosso modo como “a” ou append. Se o arquivo não existir, deixamos nosso modo como o padrão, “w”, write. Esses dois modos garantem que sempre tenhamos um arquivo e que o arquivo existente não seja sobrescrito.
Funções individuais
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Writing to CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Gravando dados no arquivo CSV...")
com open(filename, mode) como arquivo:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
se mode == "w":
writer.writeheader()
writer.writerows(data)
imprimir(f"Escreveu {page} em CSV com sucesso...")
- No início da função, verificamos se nossos
dadossão umalista. Se não forem, os convertemos em uma. f"tripadvisor-{número_da_página}.csv"cria nosso nome de arquivo.- Nosso
modopadrão é"w", mas se o arquivo existir, mudamos nosso modo para"a". csv.DictWriter(file, fieldnames=data[0].keys())inicializa nosso gravador de arquivos.- Se estivermos no modo de gravação, usamos as chaves do nosso primeiro objeto para nossos cabeçalhos. Se estivermos acrescentando ao arquivo, não precisamos fazer isso.
- Depois que o arquivo estiver configurado, usamos
writer.writerows(data)para gravar nossos dados em um arquivo CSV.
Agora, vamos dar uma olhada em nossa função de scraping. Essa função recebe apenas um argumento, nosso page_ number...bastante autoexplicativo. Começamos configurando algumas ChromeOptions personalizadas. Adicionamos argumentos para tornar nosso navegador headless e usar um agente de usuário falso. Isso deve mascarar nosso navegador o suficiente para que o Tripadvisor nos deixe passar. Em seguida, usamos o webdriver para iniciar nosso navegador e navegar até a página de resultados da pesquisa. Usamos sleep(5) para esperar 5 segundos pelo carregamento do conteúdo, o que também nos faz parecer mais com um usuário comum. Usamos o seletor CSS que mencionamos anteriormente na seção O que extrair. Se não tivermos hotel_cards, tiramos uma captura de tela e saímos da função antecipadamente. Se tivermos hotel_cards, extraímos seus dados e os adicionamos à nossa matriz scraped_data. Quando terminamos de coletar os dados, gravamos tudo em CSV.
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Conectando ao Navegador de scraping...")
scraped_data = []
print("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Conectado! Raspando a página...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = cartão.texto.split("n")
hotel_dict = {
"nome": data_array[1],
"avaliações": int(data_array[2].replace(",", "")),
"pontuação": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Cartão {index} raspado com sucesso")
imprimir(f"Página {page_number} coletada")
write_to_csv(scraped_data, page_number)
Extrair dados do Tripadvisor
Quando juntamos tudo, obtemos um script como este. Sinta-se à vontade para copiar e colar o código abaixo em seu próprio arquivo Python.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Gravando em CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Gravando dados em arquivo CSV...")
com open(nome_do_arquivo, modo) como arquivo:
writer = csv.DictWriter(arquivo, nomes_dos_campos=data[0].keys())
se modo == "w":
writer.writeheader()
writer.writerows(data)
imprimir(f"Escreveu {página} em CSV com sucesso...")
def scrape_page(page_number: int):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument(f"--user-agent={USER_AGENT}")
print("Conectando ao Navegador de scraping...")
scraped_data = []
imprimir("-------------------------------")
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
print("Conectado! Raspando a página...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
driver.save_screenshot("error.png")
driver.quit()
return
for index, card in enumerate(hotel_cards):
score = None
divs = card.find_elements(By.CSS_SELECTOR, "div")
for div in divs:
aria_label = div.get_attribute("aria-label")
if aria_label:
if "bubbles" in aria_label:
score = aria_label
break
data_array = cartão.texto.split("n")
hotel_dict = {
"nome": data_array[1],
"avaliações": int(data_array[2].replace(",", "")),
"pontuação": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Cartão {index} raspado com sucesso")
imprimir(f"Página {page_number} coletada")
write_to_csv(scraped_data, page_number)
if __name__ == '__main__':
PAGES = 1
para página em intervalo(PAGES):
scrape_page(página)
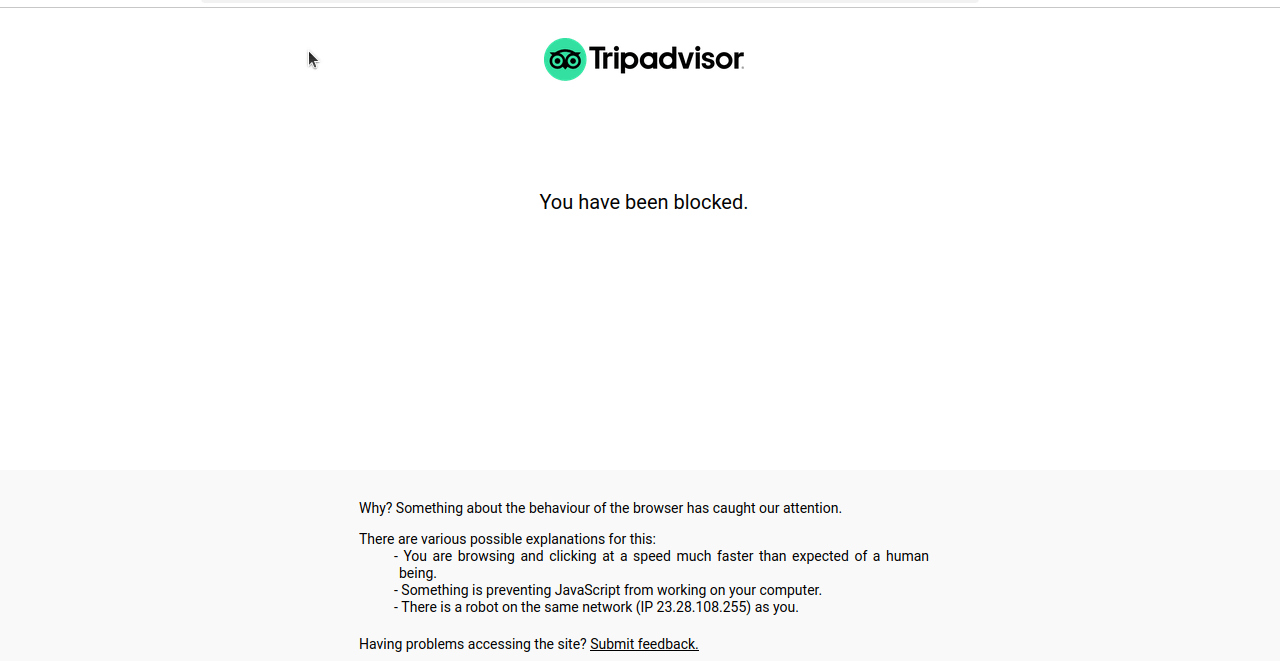
Quando executamos este código, na maioria das vezes, obtemos uma tela bloqueada ou um CAPTCHA, como você pode ver na captura de tela a seguir.

Técnicas avançadas
Abaixo estão algumas das técnicas mais avançadas usadas em nosso script. Principalmente, vamos abordar como a paginação é tratada e algumas técnicas para evitar o bloqueio.
Tratamento da paginação
Observe a URL que usamos: https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}. Nossa paginação é tratada com o parâmetro offset. Obtemos 30 resultados por página. page_number*30 multiplica nosso número de página pelos resultados por página (30). A página 0 apresentará os resultados de 1 a 30. A página 2 contém os resultados de 31 a 60… e assim por diante.
Observe também nosso main. PAGES contém o número de páginas que gostaríamos de extrair. Se você quiser extrair as cinco primeiras páginas de dados, basta alterar PAGES = 1 para PAGES = 5.
if __name__ == '__main__':
PAGES = 1
for page in range(PAGES):
scrape_page(page)
Mitigar o bloqueio
Com o Vanilla Selenium, usamos algumas técnicas para ajudar a evitar o bloqueio. Usamos um agente de usuário falso e sleep(5). Essa função sleep permite que a página seja carregada e também espaça nossas solicitações quando estamos coletando várias páginas.
Aqui está nosso agente de usuário. Ele informa ao Tripadvisor que nosso navegador é compatível com o Chrome 130.0.0.0 e o Safari 537.36. Quando o Tripadvisor lê isso, seu servidor nos envia uma página compatível com esses navegadores.
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/130.0.0.0 Safari/537.36
No entanto, ainda é possível ser detectado e ter seu Scraper bloqueado. Para contornar o bloqueio de forma consistente, precisamos de algo um pouco mais forte que o Vanilla Selenium.
Considere usar a Bright Data
A Bright Data tem todos os tipos de soluções para nos ajudar a contornar os bloqueios que encontramos com o Vanilla Selenium. O Navegador de scraping nos dá o poder de executar uma instância remota do Selenium usando nada além dos melhores Proxies da Bright Data. Primeiro, vamos revisar o processo de inscrição. Em seguida, vamos ajustar nosso script anterior para rodar com o Navegador de scraping.
Criando uma conta
Primeiro, acesse nossa página do Navegador de scraping. Clique em “Teste grátis”. Você pode criar uma conta usando o Google, o Github ou seu endereço de e-mail.
Depois de criar sua conta, você será direcionado para o painel. Clique em Adicionar.
Você verá um menu suspenso semelhante à imagem abaixo. Clique no Navegador de scraping.
Agora, você será direcionado para a página onde configura o Navegador de scraping. Vamos usar as configurações padrão. Por padrão, o Navegador de scraping vem com um solucionador CAPTCHA integrado.
Por fim, você será solicitado a criar sua zona do Navegador de scraping. Se estiver pronto para experimentar o Navegador de scraping, clique em Sim.
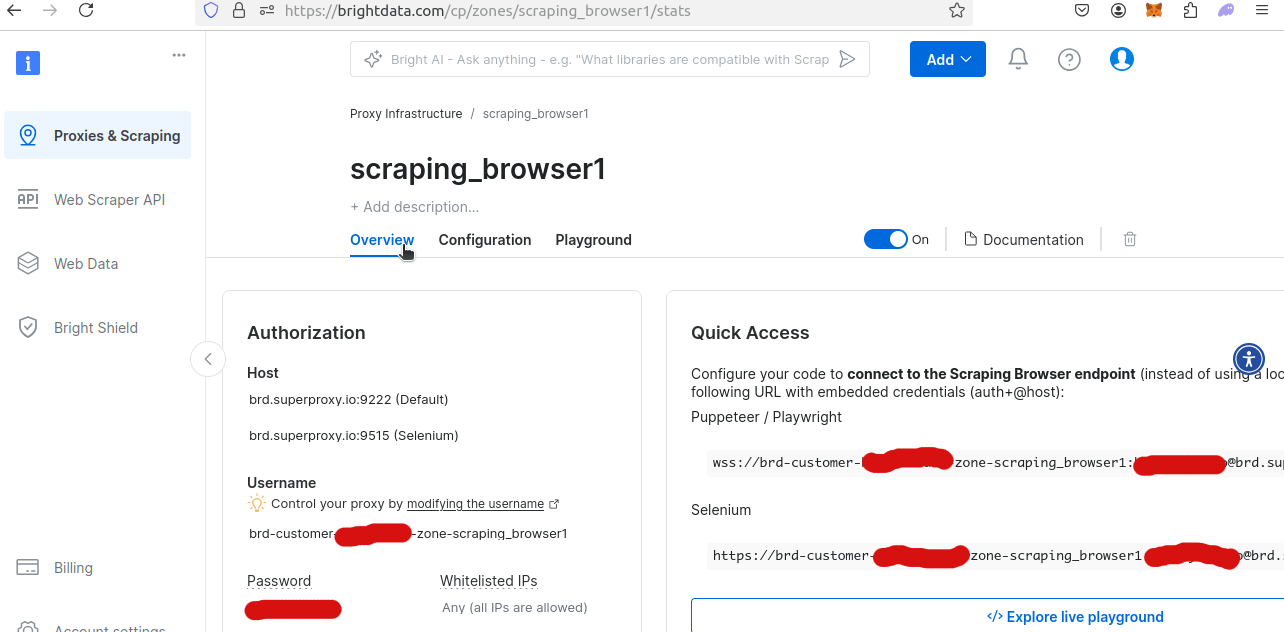
Se você olhar a Visão geral da sua nova zona do Navegador de scraping, poderá obter seu nome de usuário e senha exclusivos. Você precisará deles para acessar o Navegador de scraping a partir do seu script Python.
Extraia nossos dados usando o Navegador de scraping da Bright Data
Nosso exemplo de código abaixo foi modificado para usar o Remote Webdriver com o Navegador de scraping. Certifique-se de substituir YOUR_USERNAME, YOUR_ZONE_NAME e YOUR_PASSWORD pelo seu nome de usuário, zona e senha reais!
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.common.by import By
from time import sleep
import csv
from pathlib import Path
AUTH = "brd-customer-YOUR_USERNAME-zona-YOUR_ZONA_NAME:YOUR_PASSWORD"
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515"
def write_to_csv(data, page_number):
if type(data) != list:
data = [data]
print("Escrevendo em CSV...")
filename = f"tripadvisor-{page_number}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Escrevendo dados em arquivo CSV...")
com open(nome_do_arquivo, modo) como arquivo:
writer = csv.DictWriter(arquivo, nomes_dos_campos=dados[0].keys())
se modo == "w":
writer.writeheader()
writer.writerows(dados)
imprimir(f"Escreveu {página} em CSV com sucesso...")
def scrape_page(page_number: int):
print("Conectando ao Navegador de scraping...")
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, "goog", "chrome")
scraped_data = []
print("-------------------------------")
with Remote(sbr_connection, options=ChromeOptions()) as driver:
driver.get(f"https://www.tripadvisor.com/Search?q=Miami&geo=1&ssrc=h&offset={page_number*30}")
imprimir("Conectado! Raspando a página...")
sleep(5)
hotel_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-test-attribute='location-results-card']")
if not hotel_cards:
print("Nenhum cartão de hotel encontrado! Capturando tela e saindo.")
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png")
return
for index, card in enumerate(hotel_cards):
score = None
divs = cartão.find_elements(By.CSS_SELECTOR, "div")
para div em divs:
aria_label = div.get_attribute("aria-label")
se aria_label:
se "bubbles" em aria_label:
pontuação = aria_label
break
matriz_de_dados = cartão.text.split("n")
hotel_dict = {
"name": data_array[1],
"reviews": int(data_array[2].replace(",", "")),
"score": float(aria_label[0:3]),
"location": data_array[3],
"location_mentions": data_array[4].split(" ")[0],
"review_summary": data_array[5]
}
scraped_data.append(hotel_dict)
print(f"Cartão {index} raspado com sucesso")
imprimir(f"Página {page_number} coletada")
escrever_em_csv(scraped_data, page_number)
if __name__ == '__main__':
PÁGINAS = 1
para página em intervalo(PÁGINAS):
coletar_página(página)
Este exemplo é bastante semelhante ao nosso exemplo com o Vanilla Selenium, mas há algumas pequenas diferenças a serem observadas aqui. Elas envolvem principalmente o fato de estarmos usando o webdriver remoto em vez do webdriver padrão.
- Configuramos uma instância do webdriver remoto com nossa conexão Proxy:
SBR_WEBDRIVER = f"https://{AUTH}@zproxy.lum-superproxy.io:9515". - Nosso tratamento de erros foi ligeiramente alterado:
driver.get_screenshot_as_file(f"./error_screenshot_page_{page_number}.png"). Agora usamosdriver.get_screenshot_as_file()em vez dedriver.save_screenshot().
Além de alguns pequenos ajustes para nossa conexão Proxy remota, nosso código para o Navegador de scraping com Selenium é praticamente o mesmo que com o Vanilla Selenium. A maior diferença: o Navegador de scraping obtém nossos resultados facilmente.
Ao executar este código, você pode receber o erro abaixo. Isso pode acontecer ao lidar com uma conexão remota. Se isso acontecer, tente novamente o script. Às vezes, são necessárias várias tentativas para estabelecer uma conexão estável.
urllib3.exceptions.ProtocolError: ('Conexão abortada.', RemoteDisconnected('O terminal remoto fechou a conexão sem resposta'))
Se o seu script foi executado com sucesso, você deve receber a saída abaixo.
Conectando ao Navegador de scraping...
-------------------------------
Conectado! Raspando a página...
Cartão 0 raspado com sucesso
Cartão 1 raspado com sucesso
Cartão 2 raspado com sucesso
Cartão 3 raspado com sucesso
Cartão 4 raspado com sucesso
Cartão 5 raspado com sucesso
Cartão 6 raspado com sucesso
Cartão 7 raspado com sucesso
Cartão 8 raspado com sucesso
Cartão 9 raspado com sucesso
Cartão 10 raspado com sucesso
Cartão 11 raspado com sucesso
Cartão 12 raspado com sucesso
Cartão 13 raspado com sucesso
Cartão raspado com sucesso 14
Cartão raspado com sucesso 15
Cartão raspado com sucesso 16
Cartão raspado com sucesso 17
Cartão raspado com sucesso 18
Cartão raspado com sucesso 19
Cartão raspado com sucesso 20
Cartão raspado com sucesso 21
Cartão raspado com sucesso 22
Cartão raspado com sucesso 23
Cartão 24 raspado com sucesso
Cartão 25 raspado com sucesso
Cartão 26 raspado com sucesso
Cartão 27 raspado com sucesso
Cartão 28 raspado com sucesso
Cartão 29 raspado com sucesso
Página 0 raspada
Gravando em CSV...
Gravando dados no arquivo CSV...
0 gravado com sucesso em CSV...
Aqui está uma captura de tela dos nossos dados CSV usando o ONLYOFFICE.
Imagem não exibida Possíveis motivos
- O arquivo de imagem pode estar corrompido
- O servidor que hospeda a imagem está indisponível
- O caminho da imagem está incorreto
- O formato da imagem não é compatível
Abordagem alternativa: Conjuntos de dados
Se codificar um Scraper não é sua abordagem preferida ou se você precisa de dados em maior escala, considere utilizar Conjuntos de dados estruturados do Tripadvisor. Nossos Conjuntos de dados fornecem informações bem organizadas e de alta qualidade, adaptadas às suas necessidades, permitindo que você analise tendências de viagem, monitore os preços dos concorrentes e otimize a experiência do cliente sem esforço.
Com um conjunto de dados do Tripadvisor, você pode acessar pontos de dados importantes, como nomes de hotéis, avaliações, classificações, comodidades, preços e muito mais — tudo fornecido em formatos flexíveis (por exemplo, JSON, CSV, Parquet) e atualizado em um cronograma que se adapta ao seu fluxo de trabalho. O melhor de tudo é que esses conjuntos de dados são 100% compatíveis e escaláveis, economizando seu tempo e recursos e garantindo precisão.
Principais benefícios:
- Acesse todos os principais pontos de dados do Tripadvisor sem lidar com bloqueios.
- Adapte os Conjuntos de Dados às suas necessidades específicas com filtros e formatação personalizada.
- Automatize a entrega de dados para plataformas como Snowflake, S3 ou Azure.
Concentre-se em analisar os dados, não em coletá-los — deixe a parte difícil conosco. Explore nossos Conjuntos de dados do Tripadvisor hoje mesmo!
Conclusão
De desafios de JavaScript a conteúdo totalmente dinâmico, o Tripadvisor pode ser realmente difícil de extrair. Agora que você terminou nosso guia, deve estar um pouco mais fácil. A esta altura, você deve entender que pode usar o Selenium para controlar um navegador tanto localmente quanto usando uma sessão remota. Com navegadores headless (como o Selenium), você também tem a capacidade de fazer uma captura de tela dos seus dados. Isso torna muito mais fácil depurar nosso Scraper. Você sabe como extrair dados de hotéis e sabe como escrever um arquivo CSV usando o bom e velho Python, sem precisar instalar nada mais!
Se você deseja fazer scraping em grande escala, a Bright Data tem vários produtos para ajudá-lo. O Navegador de scraping oferece as melhores ferramentas para qualquer tarefa relacionada a scraping. Você pode controlar um navegador real com uma conexão Proxy estável com o navegador headless de sua escolha. Você também nunca precisa se preocupar com CAPTCHAs!
Ou você pode escolher a melhor maneira de obter dados: compre um Conjunto de dados do Tripadvisor pronto para uso. Inscreva-se agora para iniciar seu Teste grátis!





