

Neste tutorial, aprenderemos como extrair anúncios de emprego do JOBKOREA, um portal de emprego moderno.
Abordaremos:
- Extração manual em Python, extraindo dados Next.js incorporados
- Scraping de dados com Bright Data Web MCP para uma solução mais estável e escalável
- Extração sem código usando o AI Scraper Studio da Bright Data
Cada técnica é implementada usando o código do projeto fornecido neste repositório, progredindo de extração de baixo nível para extração totalmente autônoma e alimentada por IA.
Pré-requisitos
Antes de iniciar este tutorial, certifique-se de ter o seguinte:
- Python 3.9+
- Conhecimento básico de Python e JSON
- Uma conta Bright Data com acesso ao MCP
- Claude Desktop instalado (usado como agente de IA para a abordagem sem código)
Configuração do projeto
Clone o repositório do projeto e instale as dependências:
python -m venv venv
source venv/bin/activate # macOS / Linux
venvScriptsactivate # Windows
pip install -r requirements.txtEstrutura do projeto
O repositório está organizado de forma que cada técnica de scraping seja fácil de seguir:
jobkorea_scraper/
│
├── manual_scraper.py # Scraping manual em Python
├── mcp_scraper.py # Scraping Bright Data Web MCP
├── parsers/
│ └── jobkorea.py # Lógica de análise compartilhada
├── schemas.py # Esquema de dados de emprego
├── requirements.txt
├── README.mdCada script pode ser executado independentemente, dependendo do método que você deseja explorar.
Técnica 1: Scraping manual em Python
Começaremos com a abordagem mais básica: scraping do JOBKOREA usando Python simples, sem navegador, MCP ou agente de IA.
Essa técnica é útil para entender como o JOBKOREA fornece seus dados e para prototipar rapidamente um scraper antes de passar para soluções mais robustas.
Buscando a página
Abra manual_scraper.py.
O Scraper começa enviando uma solicitação HTTP padrão usando requests. Para evitar ser bloqueado imediatamente, incluímos cabeçalhos semelhantes aos do navegador.
headers = {
"User-Agent": "Mozilla/5.0 (...)",
"Accept": "text/html,application/xhtml+xml,*/*",
"Accept-Language": "en-US,en;q=0.9,ko;q=0.8",
"Referer": "https://www.jobkorea.co.kr/"
}O objetivo é simplesmente fazer com que a solicitação pareça tráfego normal da web. Em seguida, buscamos a página e forçamos a codificação UTF-8 para evitar problemas com o texto em coreano:
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
response.encoding = "utf-8"
html = response.textPara depuração, o HTML bruto é salvo localmente:
com open("debug.html", "w", encoding="utf-8") como f:
f.write(html)Esse arquivo é extremamente útil quando o site muda e a Parsing de repente para de funcionar.
Parsing a resposta
Depois que o HTML é baixado, ele é passado para uma função de análise compartilhada:
jobs = parse_job_list(html)Essa função fica em parsers/jobkorea.py e contém toda a lógica específica do JOBKOREA.
Tentativa de análise HTML tradicional
Dentro de parse_job_list, primeiro tentamos extrair as listas de empregos usando o BeautifulSoup, como se o JOBKOREA fosse um site tradicional renderizado pelo servidor.
soup = BeautifulSoup(html, "html.parser")
job_lists = soup.find_all("div", class_="list-default")Se nenhuma lista for encontrada, um seletor secundário é tentado:
job_lists = soup.find_all("ul", class_="clear")Quando isso funciona, o scraper extrai campos como:
- Cargo
- Nome da empresa
- Local
- Data da publicação
- Link da vaga
No entanto, essa abordagem só funciona quando o JOBKOREA expõe elementos HTML significativos, o que nem sempre é o caso.
Fallback: extraindo dados de hidratação do Next.js
Se nenhum emprego for encontrado por meio da análise HTML, o scraper muda para uma estratégia alternativa que tem como alvo os dados de hidratação Next.js incorporados.
nextjs_jobs = parse_nextjs_data(html)Esta função verifica a página em busca de strings JSON injetadas durante a renderização do lado do cliente. Uma versão simplificada da lógica de correspondência se parece com isto:
padrão = r'\"id\":\"(?P<id>d+)\",\"title\":\"(?P<title>.*?)\",\"postingCompanyName\":\"(?P<company>.*?)\"'A partir desses dados, reconstruímos as URLs das vagas de emprego:
link = f"https://www.jobkorea.co.kr/Recruit/GI_Read/{job_id}"Esse recurso permite que o scraper funcione sem executar um navegador.
Salvar os resultados
Cada vaga é validada usando um esquema compartilhado e gravada em disco:
com open("jobs.json", "w", encoding="utf-8") como f:
json.dump(
[job.model_dump() para job em jobs],
f,
ensure_ascii=False,
indent=2
)Execute o scraper desta forma:
python manual_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"Agora você deve ter um arquivo jobs.json contendo as listagens extraídas.
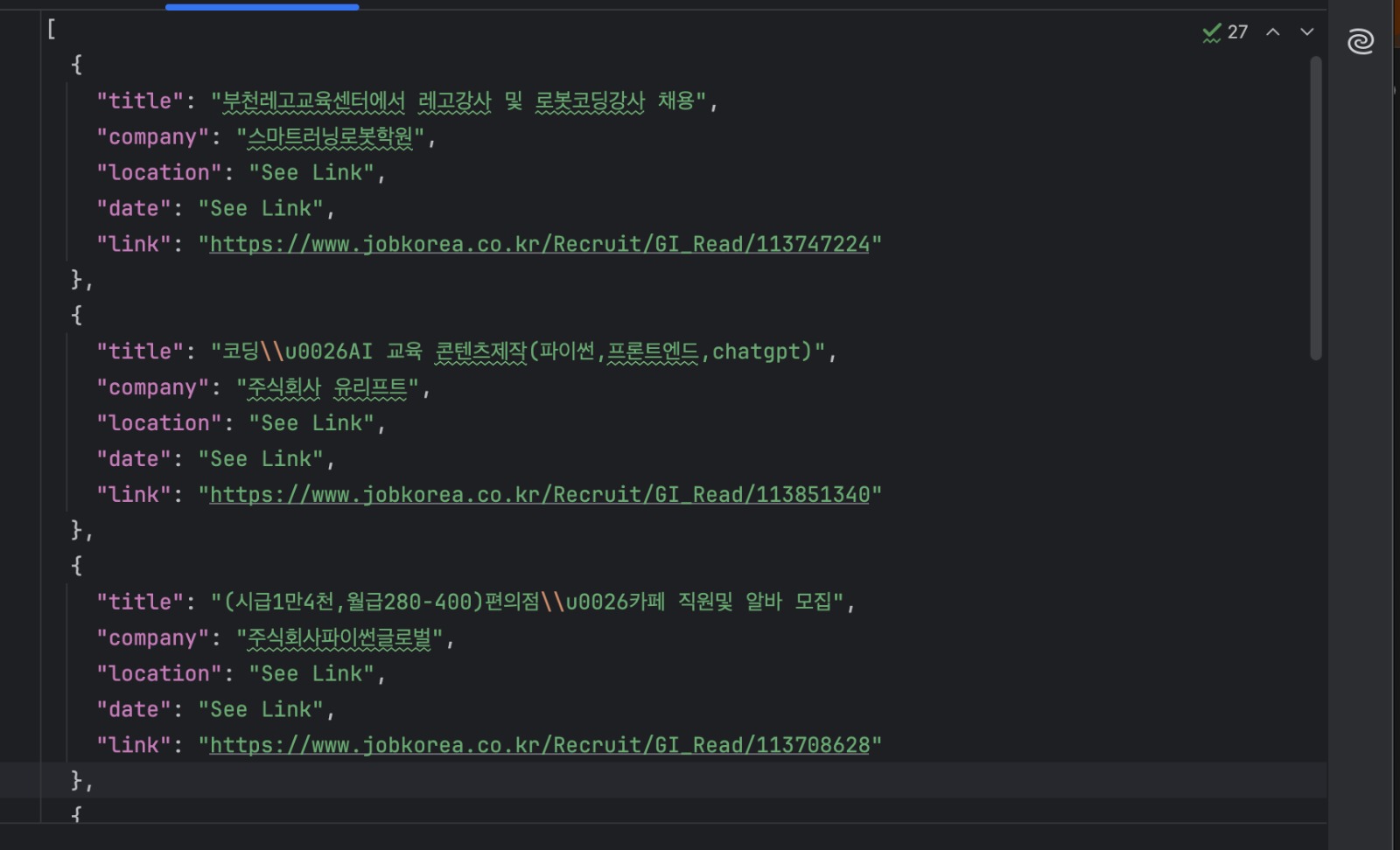
Quando essa abordagem é ideal
O scraping manual é útil quando você está explorando como um site funciona ou criando um protótipo rápido. É rápido, simples e não depende de serviços externos.
No entanto, essa abordagem está intimamente ligada à estrutura atual da página do JOBKOREA. Como depende de layouts HTML específicos e padrões de hidratação incorporados, ela pode quebrar quando o site mudar.
Para uma extração mais estável e de longo prazo, é melhor contar com ferramentas que lidam com a renderização e as alterações do site para você, que é exatamente o que faremos a seguir usando o Bright Data Web MCP.
Técnica 2: Scraping com o Bright Data Web MCP
Na seção anterior, fizemos o scraping do JOBKOREA baixando manualmente o HTML e extraindo os dados incorporados. Embora essa abordagem funcione, ela está intimamente ligada à estrutura atual do site.
Nesta técnica, usamos o Bright Data Web MCP para lidar com a obtenção e renderização da página. Em seguida, nos concentramos apenas em transformar o conteúdo retornado em dados estruturados de vagas de emprego.
Essa abordagem é implementada em mcp_scraper.py.
Obtenha sua chave/token da API Bright Data
- Faça login no painel do Bright Data
- Abra Configurações na barra lateral esquerda
- Vá para Usuários e Chaves API
- Copie sua chave API
Mais adiante neste tutorial, capturas de tela mostrarão exatamente onde essa página está localizada e onde o token aparece.
Crie um arquivo .env na raiz do projeto e adicione:
BRIGHT_DATA_API_TOKEN=seu_token_aquiO script carrega o token em tempo de execução e para antecipadamente se ele estiver faltando.
Requisitos para o MCP
O Bright Data Web MCP é iniciado localmente usando o npx, portanto, certifique-se de ter:
- Node.js instalado
- npx disponível em seu PATH
O servidor MCP é iniciado a partir do Python usando:
server_params = StdioServerParameters( command="npx", args=["-y", "@brightdata/mcp"], env={"API_TOKEN": BRIGHT_DATA_API_TOKEN, **os.environ} )Executando o MCP Scraper
Execute o script com uma URL de pesquisa do JOBKOREA:
python mcp_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"O script abre uma sessão MCP e inicializa a conexão:
async com stdio_client(server_params) como (leitura, gravação):
async com ClientSession(leitura, gravação) como sessão:
aguardar sessão.initialize()Uma vez conectado, o scraper está pronto para buscar conteúdo.
Buscando a página com o MCP
Neste projeto, o scraper usa a ferramenta MCP scrape_as_markdown:
result = await session.call_tool(
"scrape_as_markdown",
arguments={"url": url}
)O conteúdo retornado é coletado e salvo localmente:
com open("scraped_data.md", "w", encoding="utf-8") como f:
f.write(content_text)Isso fornece um instantâneo legível do que o MCP retornou, o que é útil para depuração e análise.
Parsing tarefas do Markdown
O markdown retornado pelo MCP é então convertido em dados estruturados de tarefa.
A lógica de análise procura links de markdown:
link_pattern = re.compile(r"[(.*?)]((.*?))")As publicações de tarefas são identificadas por URLs que contêm:
if "Recruit/GI_Read" in url:Quando um link de vaga é encontrado, as linhas ao redor são usadas para extrair o nome da empresa, a localização e a data da publicação.
Por fim, os resultados são gravados no disco:
com open("jobs_mcp.json", "w", encoding="utf-8") como f:
json.dump(
[job.model_dump() para job em jobs],
f,
ensure_ascii=False,
indent=2
)Arquivos de saída
Após a conclusão do script, você deverá ter:
scraped_data.md
O markdown bruto retornado pelo Bright Data Web MCP
jobs_mcp.json
As listas de empregos analisadas em formato JSON estruturado
Quando essa abordagem é ideal
Usar o Bright Data Web MCP diretamente do Python é uma boa opção quando você deseja um scraper que seja confiável e repetível.
Como o MCP lida com renderização, rede e defesas básicas do site, essa abordagem é muito menos sensível a alterações de layout do que o scraping manual. Ao mesmo tempo, manter a lógica no Python facilita a automação, o agendamento e a integração em pipelines de dados maiores.
Essa técnica funciona bem quando você precisa de resultados consistentes ao longo do tempo ou ao fazer scraping de várias páginas de pesquisa ou palavras-chave. Ela também oferece um caminho claro de atualização do scraping manual, sem exigir uma mudança completa para um fluxo de trabalho baseado em IA.
A seguir, passaremos para a terceira técnica, na qual usamos o Claude Desktop como um agente de IA conectado ao Bright Data Web MCP para fazer o scraping do JOBKOREA sem escrever nenhum código de scraping.
Técnica 3: Código de raspagem gerado por IA usando o Bright Data IDE
Nesta técnica final, geramos código de raspagem usando o raspador assistido por IA da Bright Data dentro do Scraping de Dados IDE.
Você não escreve manualmente a lógica de scraping do zero. Em vez disso, você descreve o que deseja, e o IDE ajuda a gerar e refinar o scraper.
Abrindo o Scraper IDE
No painel do Bright Data:
Abra Dados na barra lateral esquerda
- Clique em Meus Scrapers

- Selecione Novo no canto superior direito
- Selecione Desenvolva seu próprio raspador da web

Isso abre o ambiente de desenvolvimento integrado (IDE) JavaScript
Insira o URL de destino “https://www.jobkorea.co.kr/Search/” e clique em “Gerar código”
O IDE processará sua solicitação e gerará um modelo de código pronto para uso. Você receberá uma notificação por e-mail assim que estiver pronto. Em seguida, você poderá editar ou executar o código conforme necessário.
Comparando as três técnicas de scraping
Cada técnica neste projeto resolve o mesmo problema, mas é adequada para um fluxo de trabalho diferente. A tabela abaixo destaca as diferenças práticas.
| Técnica | Esforço de configuração | Confiabilidade | Automação | Onde funciona | Melhor caso de uso |
|---|---|---|---|---|---|
| Raspagem manual em Python | Baixo | Baixo a médio | Limitado | Máquina local | Aprendizado, experimentos rápidos |
| Bright Data MCP (Python) | Médio | Alta | Alta | Local + Bright Data | Extração de dados em produção, tarefas programadas |
| Scraper gerado por IA (Bright Data IDE) | Baixo | Alto | Alta | Plataforma Bright Data | Configuração rápida, scrapers gerenciados reutilizáveis |
Conclusão
Neste tutorial, abordamos três maneiras diferentes de fazer scraping no JOBKOREA: scraping manual em Python, um fluxo de trabalho mais estável baseado no Bright Data Web MCP e o uso do AI Scraper Studio da Bright Data para uma abordagem sem código.
Cada técnica se baseia na anterior. O scraping manual ajuda a entender como o site funciona, o scraping baseado em MCP oferece confiabilidade e automação, e a abordagem do agente de IA oferece o caminho mais rápido para dados estruturados com configuração mínima.
Se você estiver raspando sites modernos renderizados pelo cliente, como o JOBKOREA, e precisar de uma alternativa mais confiável aos seletores frágeis e à automação do navegador, o Bright Data Web MCP oferece uma base sólida que funciona tanto com scripts tradicionais quanto com fluxos de trabalho orientados por IA.





