

O Google Trendsé uma ferramenta gratuita que fornece insights sobre o que as pessoas estão pesquisando online. Ao analisar essas tendências de pesquisa, as empresas podem identificar tendências emergentes do mercado, entender o comportamento do consumidor e tomar decisões baseadas em dados para impulsionar as vendas e os esforços de marketing. Extrair dados do Google Trends permite que as empresas se mantenham à frente da concorrência, adaptando suas estratégias.
Neste artigo, você aprenderá como extrair dados do Google Trends usando Python e como armazenar e analisar esses dados de maneira eficaz.
Por que extrair dados do Google Trends
Extrair e analisar dados do Google Trends pode ser valioso em vários cenários, incluindo os seguintes:
- Pesquisa de palavras-chave:criadores de conteúdo e especialistas em SEO precisam saber quais palavras-chave estão ganhando força para que possam direcionar mais tráfego orgânico para seus sites. O Google Trends ajuda a explorar termos de pesquisa em alta por região, categoria ou período, permitindo que você otimize sua estratégia de conteúdo com base no interesse em evolução dos usuários.
- Pesquisa de mercado:os profissionais de marketing devem entender os interesses dos clientes e antecipar mudanças nas demandas para tomar decisões informadas. Extrair e analisar os dados do Google Trends permite que eles entendam os padrões de pesquisa dos clientes e monitorem as tendências ao longo do tempo.
- Pesquisa social:vários fatores, incluindo eventos locais e globais, inovações tecnológicas, mudanças econômicas e desenvolvimentos políticos, podem impactar significativamente o interesse público e as tendências de pesquisa. Os dados do Google Trends fornecem informações valiosas sobre essas tendências em constante mudança ao longo do tempo, permitindo uma análise abrangente e previsões futuras informadas.
- Monitoramento da marca:as empresas e equipes de marketing devem monitorar como sua marca é percebida no mercado. Ao coletar dados do Google Trends, você pode comparar a visibilidade da sua marca com a dos concorrentes e reagir rapidamente às mudanças na percepção do público.
Alternativa da Bright Data para coletar dados do Google Trends – API SERP da Bright Data
Em vez de coletar manualmente o Google Trends, use a API SERP da Bright Data para automatizar a coleta de dados em tempo real dos mecanismos de pesquisa. A API SERP oferece dados estruturados, como resultados de pesquisa e tendências, com segmentação geográfica precisa e sem risco de bloqueios ou CAPTCHAs. Você paga apenas pelas solicitações bem-sucedidas, e os dados são entregues nos formatos JSON ou HTML para fácil integração.
Esta solução é mais rápida, mais escalável e elimina a necessidade de scripts de scraping complexos. Comece seu teste grátis e otimize sua coleta de dados com o scraper do Google Trends da Bright Data.
Como extrair dados do Google Trends
O Google Trends não oferece APIs oficiais para extrair dados de tendências, mas você pode usar várias APIs e bibliotecas de terceiros para acessar essas informações, comoo pytrends, que é uma biblioteca Python que fornece APIs fáceis de usar que permitem baixar automaticamente relatórios do Google Trends. No entanto, embora o pytrends seja fácil de usar, ele fornece dados limitados porque não pode acessar dados renderizados dinamicamente ou por trás de elementos interativos. Para resolver esse problema, você pode usaro Seleniumcomo Beautiful Souppara extrair dados do Google Trends e extrair dados de páginas da web renderizadas dinamicamente. O Selenium é uma ferramenta de código aberto para interagir e extrair dados de sites que usam JavaScript para carregar conteúdo dinamicamente. O Beautiful Soup ajuda a analisar o conteúdo HTML extraído, permitindo que você extraia dados específicos de páginas da web.
Antes de iniciar este tutorial, você precisa tero Pythoninstalado e configurado em sua máquina. Você também precisa criar um diretório de projeto vazio para os scripts Python que você criará nas próximas seções.
Crie um ambiente virtual
Um ambiente virtual permite isolar pacotes Python em diretórios separados para evitar conflitos de versão. Para criar um novo ambiente virtual, execute o seguinte comando no seu terminal:
# navegue até a raiz do diretório do seu projeto antes de executar o comando
python -m venv myenv
Este comando cria uma pasta chamada myenv no diretório do projeto. Ative o ambiente virtual executando o seguinte comando:
source myenv/bin/activate
Quaisquer comandos Python ou pip subsequentes também serão executados neste ambiente.
Instale suas dependências
Conforme discutido anteriormente, você precisa do Selenium e do Beautiful Soup para extrair e analisar páginas da web. Além disso, para analisar e visualizar os dados extraídos, você precisa instalar os módulos PythonpandaseMatplotlib. Use o seguinte comando para instalar esses pacotes:
pip install beautifulsoup4 pandas matplotlib selenium
Consultar dados de pesquisa do Google Trends
O painel do Google Trendspermite explorar as tendências de pesquisa por região, intervalo de datas e categoria. Por exemplo, esta URL mostra as tendências de pesquisa para café nos Estados Unidos nos últimos sete dias:
https://trends.google.com/trends/explore?date=now%207-d&geo=US&q=coffee
Ao abrir esta página da web no seu navegador, você notará que os dados são carregados dinamicamente usando JavaScript. Para extrair conteúdo dinâmico, você pode usar oSelenium WebDriver, que imita as interações do usuário, como clicar, digitar ou rolar a página.
Você pode usaro webdriverem seu script Python para carregar a página da web em uma janela do navegador e extrair o código-fonte da página assim que o conteúdo for carregado. Para lidar com conteúdo dinâmico, você pode adicionar umtime.sleepexplícito para garantir que todo o conteúdo seja carregado antes de buscar o código-fonte da página. Se quiser aprender mais técnicas para lidar com conteúdo dinâmico, consulteeste guia.
Crie um arquivo main.py na raiz do projeto e adicione o seguinte trecho de código a ele:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def get_driver():
# atualize o caminho para a localização do seu binário do Chrome
CHROME_PATH = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"
options = Options()
# options.add_argument("--headless=new")
options.binary_location = CHROME_PATH
driver = webdriver.Chrome(options=options)
retornar driver
def obter_dados_de_tendências_brutos(
driver: webdriver.Chrome, intervalo_de_datas: str, geo: str, consulta: str)
-> str:
url = f"https://trends.google.com/trends/explore?date={intervalo_de_datas}&geo={geo}&q={consulta}"
imprimir(f"Obter dados de {url}")
driver.get(url)
# solução alternativa para obter a fonte da página após o erro inicial 429
driver.get(url)
driver.maximize_window()
# Aguardar o carregamento da página
time.sleep(5)
retornar driver.page_source
O método get_raw_trends_data aceita intervalo de datas, região geográfica e nome da consulta como parâmetros e usa o Chrome WebDriver para buscar o conteúdo da página. Observe que o método driver.get é chamado duas vezes como uma solução alternativa para corrigir o erro 429 inicial gerado pelo Google quando a URL é carregada pela primeira vez.
Você usará esse método nas seções a seguir para buscar dados.
Analise os dados usando o Beautiful Soup
A página Tendências para um termo de pesquisa inclui um widget Interesse por sub-região que contém registros paginados com valores entre 0 e 100, indicando a popularidade do termo de pesquisa com base na localização. Use o seguinte trecho de código para analisar esses dados com o Beautiful Soup:
# Adicionar importação
from bs4 import BeautifulSoup
def extrair_interesse_por_sub_região(conteúdo: str) -> dict:
soup = BeautifulSoup(conteúdo, "html.parser")
interesse_por_sub_região = soup.find("div", class_="geo-widget-wrapper geo-resolution-subregion")
related_queries = interest_by_subregion.find_all("div", class_="fe-atoms-generic-content-container")
# Dicionário para armazenar os dados extraídos
interest_data = {}
# Extrair o nome da região e a porcentagem de interesse
for query in related_queries:
items = query.find_all("div", class_="item")
para item em itens:
região = item.find("div", class_="label-text").text.strip()
interesse = item.find("div", class_="progress-value").text.strip()
interest_data[região] = interesse
retornar interest_data
Este trecho de código localiza o div correspondente para os dados da sub-região usando seu nome de classe e itera sobre o resultado para construir um dicionário interest_data.
Observe que o nome da classe pode mudar no futuro, e talvez seja necessário usar orecursoInspecionarelemento do Chrome DevToolspara encontrar o nome correto.
Agora que você definiu os métodos auxiliares, use o seguinte trecho de código para consultar os dados para “café”:
# Parâmetros
date_range = "now 7-d"
geo = "US"
query = "coffee"
# Obter os dados brutos
driver = get_driver()
raw_data = get_raw_trends_data(driver, "now 7-d", "US", "coffee")
# Extrair o interesse por região
interest_data = extract_interest_by_sub_region(raw_data)
# Imprimir os dados extraídos
for region, interest in interest_data.items():
print(f"{region}: {interest}")
Sua saída ficará assim:
Havaí: 100
Montana: 96
Oregon: 90
Washington: 86
Califórnia: 84
Gerenciar paginação de dados
Como os dados no widget são paginados, o trecho de código na seção anterior retorna apenas os dados da primeira página do widget. Para obter mais dados, você pode usar o Selenium WebDriver para localizar e clicar no botão Avançar. Além disso, seu script deve lidar com o banner de consentimento de cookies clicando no botão Aceitar para garantir que o banner não obstrua outros elementos da página.
Para lidar com cookies e paginação, adicione este trecho de código no final do main.py:
# Adicionar importação
from selenium.webdriver.common.by import By
all_data = {}
# Aceitar os cookies
driver.find_element(By.CLASS_NAME, "cookieBarConsentButton").click()
# Obter dados de interesse paginados
while True:
# Clique no botão md para carregar mais dados, se disponíveis
try:
geo_widget = driver.find_element(
By.CSS_SELECTOR, "div.geo-widget-wrapper.geo-resolution-subregion"
)
# Encontre o botão carregar mais com o nome de classe "md-button" e aria-label "Próximo"
load_more_button = geo_widget.find_element(
By.CSS_SELECTOR, "button.md-button[aria-label='Próximo']"
)
icon = load_more_button.find_element(By.CSS_SELECTOR, ".material-icons")
# Verifique se o botão está desativado verificando se o nome da classe inclui arrow-right-disabled
if "arrow-right-disabled" in icon.get_attribute("class"):
print("Não há mais dados para carregar")
break
load_more_button.click()
time.sleep(2)
extracted_data = extract_interest_by_sub_region(driver.page_source)
all_data.update(extracted_data)
except Exception as e:
print("Não há mais dados para carregar", e)
break
driver.quit()
Este trecho usa a instância do driver existente para localizar e clicar no botão Avançar, comparando-o com o nome da classe. Ele verifica a presença da classe arrow-right-disabled no elemento para determinar se o botão está desativado, indicando que você chegou à última página do widget. Ele sai do loop quando essa condição é atendida.
Visualize os dados
Para acessar facilmente e analisar mais detalhadamente os dados que você coletou, você pode persistir os dados da sub-região extraídos em um arquivo CSV usando um csv.DictWriter.
Comece definindo o save_interest_by_sub_region no main.py para salvar o dicionário all_data em um arquivo CSV:
# Adicionar importação
import csv
def save_interest_by_sub_region(interest_data: dict):
interest_data = [{"Region": region, "Interest": interest} for region, interest in interest_data.items()]
csv_file = "interest_by_region.csv"
# Abrir o arquivo CSV para gravação
with open(csv_file, mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=["Region", "Interest"])
writer.writeheader() # Gravar o cabeçalho
writer.writerows(interest_data) # Gravar os dados
imprimir(f"Dados salvos em {csv_file}")
retornar csv_file
Em seguida, você pode usaro pandaspara abrir o arquivo CSV como umDataFramee realizar análises, como filtrar dados por condições específicas, agregar dados com operaçõesde agrupamentoou visualizar tendências com gráficos.
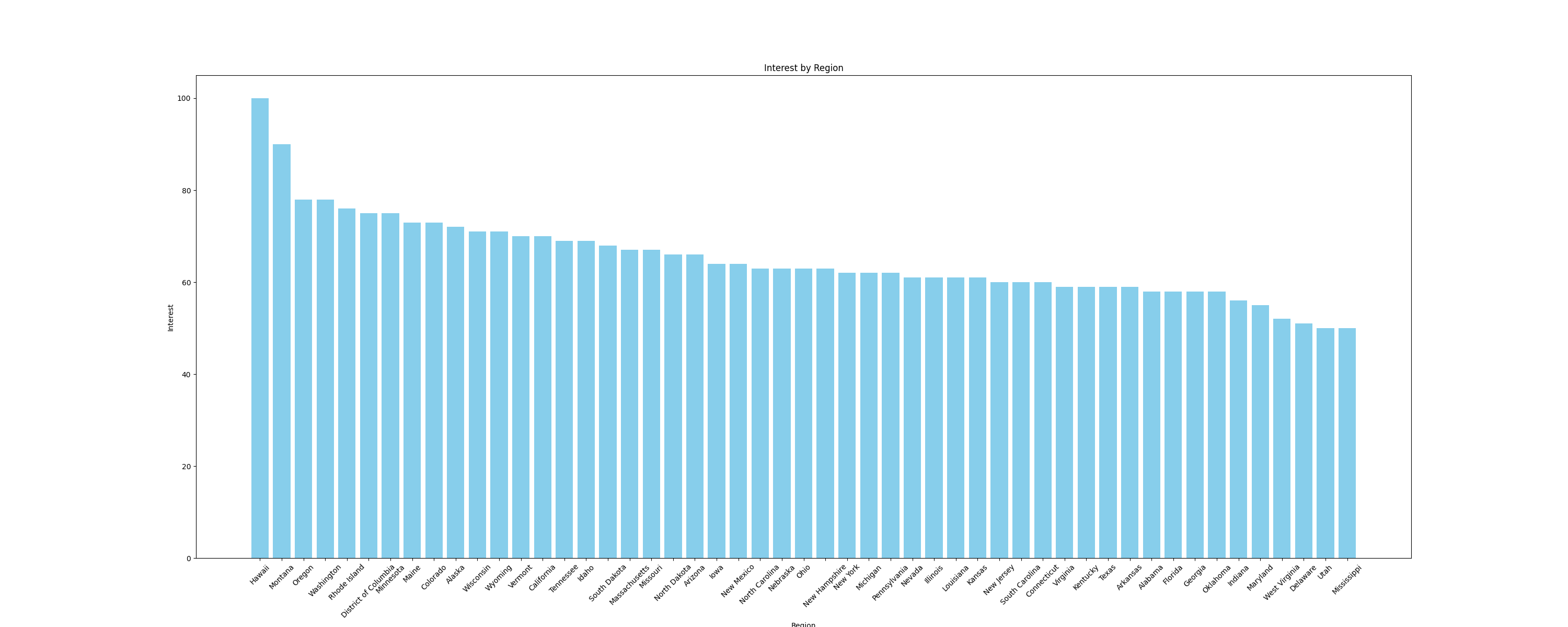
Por exemplo, vamos visualizar os dados como umgráfico de barraspara comparar o interesse por sub-regiões. Para criar gráficos, use a biblioteca Pythonmatplotlib, que funciona perfeitamente com DataFrames. Adicione a seguinte função ao arquivomain.pypara criar um gráfico de barras e salvá-lo como uma imagem:
# Adicionar importações
import pandas as pd
import matplotlib.pyplot as plt
def plot_sub_region_data(csv_file_path, output_file_path):
# Carregar os dados do arquivo CSV
df = pd.read_csv(csv_file_path)
# Criar um gráfico de barras para comparação por região
plt.figure(figsize=(30, 12))
plt.bar(df["Region"], df["Interest"], color="skyblue")
# Adicionar títulos e rótulos
plt.title('Interesse por região')
plt.xlabel('Região')
plt.ylabel('Interesse')
# Girar os rótulos do eixo x, se necessário
plt.xticks(rotation=45)
# Mostrar o gráfico
plt.savefig(output_file_path)
Adicione o seguinte trecho de código ao final do arquivo main.py para chamar as funções anteriores:
csv_file_path = save_interest_by_sub_region(all_data)
output_file_path = "interest_by_region.png"
plot_sub_region_data(csv_file_path, output_file_path)
Este trecho cria um gráfico semelhante a este:
Todo o código deste tutorial está disponívelneste repositório GitHub.
Desafios da extração de dados
Neste tutorial, você coletou uma pequena quantidade de dados do Google Trends, mas à medida que seus scripts de coleta crescem em tamanho e complexidade, é provável que você enfrente desafios como bloqueios de IP e CAPTCHAs.
Por exemplo, à medida que você envia tráfego mais frequente para um site usando este script, você pode enfrentar proibições de IP, pois muitos sites têm proteções para detectar e bloquear o tráfego de bots. Para evitar isso, você pode usar a rotação manual de IP ou um dos melhores serviços de proxy. Se você não tiver certeza de qual tipo de proxy deve usar, leia nosso artigo que aborda os melhores tipos de proxy para Scraping de dados.
Encontrar um CAPTCHA ou reCAPTCHA é outro desafio comum que os sites usam quando detectam ou suspeitam de tráfego de bots ou anomalias. Para evitar isso, você pode reduzir a frequência das solicitações, usar cabeçalhos de solicitação adequados ou usar serviços de terceiros que podem resolver esses desafios.
Conclusão
Neste artigo, você aprendeu como extrair dados do Google Trends com Python usando Selenium e Beautiful Soup.
À medida que você continua sua jornada de scraping de dados, pode encontrar desafios como banimentos de IP e CAPTCHAs. Em vez de gerenciar scripts de scraping complexos, considere usar a API SERP da Bright Data, que automatiza o processo de coleta de dados precisos e em tempo real do mecanismo de pesquisa, incluindo o Google Trends. A API SERP lida com conteúdo dinâmico, segmentação baseada em localização e garante altas taxas de sucesso, economizando seu tempo e esforço.
Inscreva-se agora e comece seu teste gratuito da API SERP!





