

Neste artigo, você aprenderá passo a passo como extrair dados doGoogle Scholarcom Python. Antes de mergulhar nas etapas de extração, vamos revisar os pré-requisitos e como configurar nosso ambiente. Vamos começar!
Alternativa à extração manual do Google Scholar
Extrair manualmente do Google Scholar pode ser desafiador e demorado. Como alternativa, considere usar os Conjuntos de dados da Bright Data:
- Mercado de conjuntos de dados: acesse dados pré-coletados que estão prontos para uso imediato.
- Conjuntos de dados personalizados: solicite ou crie conjuntos de dados personalizados específicos para suas necessidades.
Usar os serviços da Bright Data economiza tempo e garante que você tenha informações precisas e atualizadas sem as complexidades da extração manual. Agora, vamos continuar!
Pré-requisitos
Antes de iniciar este tutorial, você precisa instalar os seguintes itens:
- A versão mais recente doPython
- Um editor de código de sua escolha, comoo Visual Studio Code
Além disso, antes de iniciar qualquer projeto de scraping, certifique-se de que seus scripts estejam em conformidade com o arquivorobots.txtdo site, para não coletar dados de áreas restritas. O código usado neste artigo destina-se exclusivamente a fins de aprendizagem e deve ser usado com responsabilidade.
Configure um ambiente virtual Python
Antes de configurar seu ambiente virtual Python, navegue até o local desejado do projeto e crie uma nova pasta chamada google_scholar_scraper:
mkdir google_scholar_scraper
cd google_scholar_scraper
Depois de criar a pasta google_scholar_scraper, crie um ambiente virtual para o projeto com o seguinte comando:
python -m venv google_scholar_env
Para ativar seu ambiente virtual, use o seguinte comando no Linux/Mac:
source google_scholar_env/bin/activate
No entanto, se você estiver no Windows, use o seguinte:
.google_scholar_envScriptsactivate
Instale os pacotes necessários
Depois queo venvestiver ativado, você precisará instalaro Beautiful Soupeo pandas:
pip install beautifulsoup4 pandas
O Beautiful Soup ajuda a analisar estruturas HTML nas páginas do Google Scholar e extrair elementos de dados específicos, como artigos, títulos e autores. O pandas organiza os dados extraídos em um formato estruturado e os armazena como um arquivo CSV.
Além do Beautiful Soup e do pandas, você também precisa configuraro Selenium. Sites como o Google Scholar costumam implementar medidas para bloquear solicitações automatizadas e evitar sobrecarga. O Selenium ajuda a contornar essas restrições, automatizando as ações do navegador e imitando o comportamento do usuário.
Use o seguinte comando para instalar o Selenium:
pip install selenium
Certifique-se de usar a versão mais recente do Selenium (4.6.0 no momento da redação) para não precisar baixaro ChromeDriver.
Crie um script Python para acessar o Google Scholar
Depois que seu ambiente estiver ativado e você tiver baixado as bibliotecas necessárias, é hora de começar a extrair dados do Google Scholar.
Crie um novo arquivo Python chamado gscholar_scraper.py no diretório google_scholar_scraper e importe as bibliotecas necessárias:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
Em seguida, você vai configurar oSelenium WebDriverpara controlar o navegador Chrome no modo headless (ou seja, sem interface gráfica do usuário), pois isso ajuda a coletar dados sem abrir uma janela do navegador. Adicione a seguinte função ao script para inicializar o Selenium WebDriver:
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
Depois de inicializar o WebDriver, você precisa adicionar outra função ao script que envia a consulta de pesquisa ao Google Scholar usando o Selenium WebDriver:
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
driver.get(base_url + params)
driver.implicitly_wait(10) # Aguarde até 10 segundos para que a página carregue
# Retorne a fonte da página (conteúdo HTML)
return driver.page_source
Neste código, driver.get(base_url + params) instrui o Selenium WebDriver a navegar até a URL construída. O código também configura o WebDriver para aguardar até dez segundos até que todos os elementos da página sejam carregados antes do Parsing.
Analisar o conteúdo HTML
Depois de obter o conteúdo HTML da página de resultados da pesquisa, você precisa de uma função para analisá-lo e extrair as informações necessárias.
Para obter os seletores CSS e elementos corretos para os artigos, você precisa inspecionar manualmente a página do Google Scholar. Use as ferramentas de desenvolvedor do seu navegador e procure por classes ou IDs exclusivas para os elementos autor, título e trecho (por exemplo, gs_rt para o título, conforme mostrado na imagem a seguir):
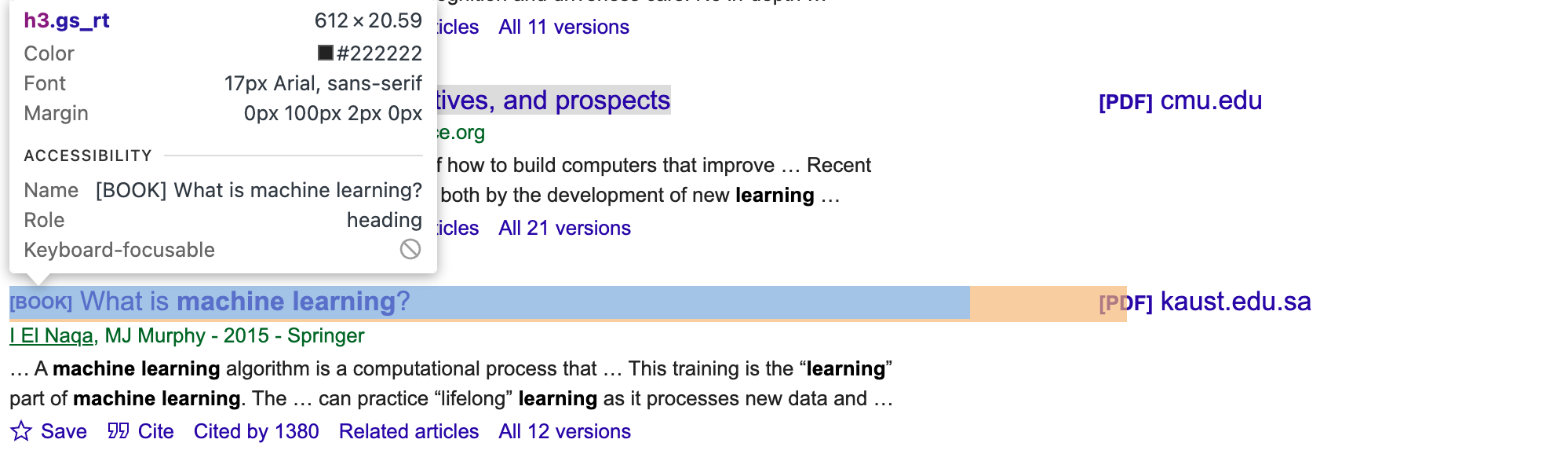
Em seguida, atualize o script:
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
Esta função usa o BeautifulSoup para navegar pela estrutura HTML; localizar elementos que contêm informações do artigo; extrair os títulos, autores e trechos de cada artigo; e, em seguida, combiná-los em uma lista de dicionários.
Você notará que o script atualizado contém .select(.gs_ri), que é o seletor CSS que corresponde a cada item de resultado de pesquisa na página do Google Scholar. Em seguida, o código extrai o título, os autores e o trecho (breve descrição) de cada resultado usando seletores mais específicos (.gs_rt, .gs_a e .gs_rs).
Execute o script
Para testar o script do scraper, adicione o seguinte código _main_ para executar uma pesquisa por “machine learning”:
if __name__ == "__main__":
search_query = "machine learning"
# Inicializar o Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
A função fetch_search_results extrai o conteúdo HTML da página de resultados da pesquisa. Em seguida, parse_results extrai os dados do conteúdo HTML.
O script completo fica assim:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
# Use o Selenium WebDriver para buscar a página
driver.get(base_url + params)
# Aguarda o carregamento da página
driver.implicitly_wait(10) # Aguarda até 10 segundos pelo carregamento da página
# Retorne a fonte da página (conteúdo HTML)
return driver.page_source
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
if __name__ == "__main__":
search_query = "machine learning"
# Inicializar o Selenium WebDriver
driver = init_selenium_driver()
tente:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
imprimir(df.head())
finalmente:
driver.quit()
Execute python gscholar_scraper.py para executar o script. Sua saída deve ficar assim:
% python3 scrape_gscholar.py
título autores trecho
0 [PDF][PDF] Algoritmos de aprendizado de máquina - uma revisão B Mahesh - Revista Internacional de Ciência e... Aqui está uma rápida visão geral de alguns dos mais comuns...
1 [LIVRO][B] Aprendizado de máquina E Alpaydin - 2021 - books.google.com O MIT apresenta uma introdução concisa ao aprendizado de máquina...
2 Aprendizado de máquina: tendências, perspectivas e pr... MI Jordan, TM Mitchell - Science, 2015 - scien... … O aprendizado de máquina aborda a questão de h...
3 [LIVRO][B] O que é aprendizado de máquina? I El Naqa, MJ Murphy - 2015 - Springer … Um algoritmo de aprendizado de máquina é um cálculo...
4 [LIVRO][B] Aprendizado de máquina
Transforme a consulta de pesquisa em um parâmetro
Atualmente, a consulta de pesquisa é codificada. Para tornar o script mais flexível, você precisa passá-la como um parâmetro para que possa alterar facilmente o termo de pesquisa sem modificar o script.
Comece importando sys para acessar os argumentos da linha de comando passados para o script:
import sys
Em seguida, atualize o script do bloco __main__ para usar a consulta como um parâmetro:
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Uso: python gscholar_scraper.py '<search_query>'")
sys.exit(1)
search_query = sys.argv[1]
# Inicialize o Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
Execute o seguinte comando junto com uma consulta de pesquisa especificada:
python gscholar_scraper.py <search_query>
Neste ponto, você pode executar todos os tipos de consultas de pesquisa através do terminal (por exemplo, “inteligência artificial”, “modelagem baseada em agentes” ou “aprendizagem afetiva”).
Habilite a paginação
Normalmente, o Google Scholar exibe apenas alguns resultados de pesquisa por página (cerca de dez), o que pode não ser suficiente. Para obter mais resultados, você precisa explorar várias páginas de pesquisa, o que significa modificar o script para solicitar e analisar páginas adicionais.
Você pode modificar a função fetch_search_results para incluir um parâmetro inicial que controla o número de páginas a serem buscadas. O sistema de paginação do Google Scholar incrementa esse parâmetro em dez para cada página subsequente.
Se você percorrer a primeira página de um link típico do Google Scholar, como https://scholar.google.ca/scholar?start=10&q=machine+learning&hl=en&as_sdt=0,5, o parâmetro start na URL determina qual conjunto de resultados é exibido. Por exemplo, start=0 busca a primeira página, start=10 busca a segunda página, start=20 busca a terceira página e assim por diante.
Vamos atualizar o script para lidar com isso:
def fetch_search_results(driver, query, start=0):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}&start={start}"
# Use o Selenium WebDriver para buscar a página
driver.get(base_url + params)
# Aguarde o carregamento da página
driver.implicitly_wait(10) # Aguarde até 10 segundos para o carregamento da página
# Retorne a fonte da página (conteúdo HTML)
return driver.page_source
Em seguida, você precisa criar uma função para lidar com a extração de várias páginas:
def scrape_multiple_pages(driver, query, num_pages):
all_articles = []
para i no intervalo (num_pages):
início = i * 10 # cada página contém 10 resultados
conteúdo_html = buscar_resultados_da_pesquisa(driver, consulta, início=início)
artigos = analisar_resultados(conteúdo_html)
todos_os_artigos.extender(artigos)
retornar todos_os_artigos
Esta função itera sobre o número de páginas especificado (num_pages), analisa o conteúdo HTML de cada página e coleta todos os artigos em uma única lista.
Não se esqueça de atualizar o script principal para usar a nova função:
if __name__ == "__main__":
if len(sys.argv) < 2 or len(sys.argv) > 3:
print("Uso: python gscholar_scraper.py '<search_query>' [<num_pages>]")
sys.exit(1)
search_query = sys.argv[1]
num_pages = int(sys.argv[2]) if len(sys.argv) == 3 else 1
# Inicialize o Selenium WebDriver
driver = init_selenium_driver()
tente:
todos_os_artigos = scrape_multiple_pages(driver, search_query, num_pages)
df = pd.DataFrame(todos_os_artigos)
df.to_csv('results.csv', index=False)
finalmente:
driver.quit()
Este script também inclui uma linha (df.to_csv('results.csv', index=False)) para armazenar todos os dados agregados e não apenas enviá-los para o terminal.
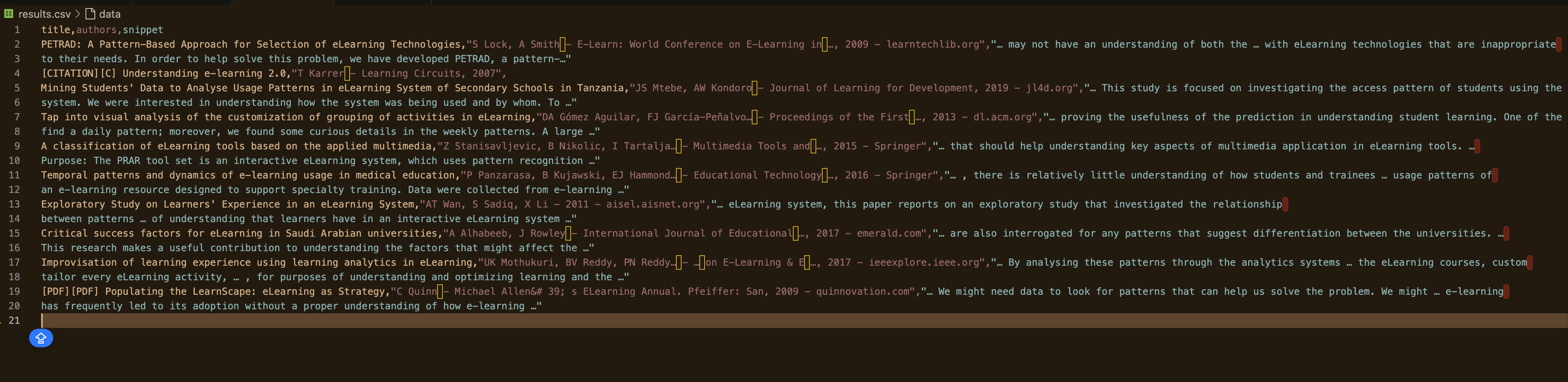
Agora, execute o script e especifique o número de páginas a serem extraídas:
python gscholar_scraper.py "understanding elearning patterns" 2
Sua saída deve ficar assim:
Como evitar o bloqueio de IP
A maioria dos sites possui medidas anti-bot que detectam padrões de solicitações automatizadas para impedir a extração. Se um site detectar atividades incomuns, seu IP poderá ser bloqueado.
Por exemplo, ao criar este script, houve um momento em que a resposta retornada era apenas dados vazios:
DataFrame vazio
Colunas: []
Índice: []
Quando isso acontece, seu IP pode já ter sido bloqueado. Nesse cenário, você precisa encontrar uma maneira de contornar isso para evitar que seu IP seja sinalizado. A seguir estão algumas técnicas para ajudar a evitar bloqueios de IP.
Use Proxies
Os serviços de Proxy ajudam a distribuir solicitações por vários endereços IP, reduzindo a chance de bloqueio. Por exemplo, quando você encaminha uma solicitação por meio de um Proxy, o servidor Proxy encaminha as solicitações diretamente para o site. Dessa forma, o site vê sua solicitação apenas a partir do endereço IP do Proxy, em vez do seu próprio. Se você quiser saber como implementar um Proxy em seu projeto, confira este artigo.
Alterne IPs
Outra técnica para ajudar a evitar bloqueios de IP é configurar seu script para alternar endereços IP após um determinado número de solicitações. Você pode fazer isso manualmente ouusar um serviço de Proxy que alterna IPs automaticamente para você. Isso torna mais difícil para o site detectar e bloquear seu IP, pois as solicitações parecem ser de usuários diferentes.
Incorpore redes privadas virtuais
Uma rede privada virtual (VPN) mascara seu endereço IP, encaminhando seu tráfego de internet por um servidor localizado em outro lugar. Você pode configurar uma VPN com servidores em diferentes países para simular tráfego de várias regiões. Ela também oculta seu endereço IP real e dificulta que os sites rastreiem e bloqueiem suas atividades com base no IP.
Conclusão
Neste artigo, exploramos como extrair dados do Google Scholar usando Python. Configuramos um ambiente virtual, instalamos pacotes essenciais como Beautiful Soup, pandas e Selenium e escrevemos scripts para buscar e analisar resultados de pesquisa. Também implementamos paginação para extrair várias páginas e discutimos técnicas para evitar o bloqueio de IP, como o uso de proxies, rotação de IPs e incorporação de VPNs.
Embora a extração manual possa ser bem-sucedida, ela geralmente traz desafios como proibições de IP e a necessidade de manutenção contínua do script. Para simplificar e aprimorar seus esforços de coleta de dados, considere aproveitar as soluções da Bright Data. Nossa rede de proxies residenciais oferece alto anonimato e confiabilidade, garantindo que suas tarefas de extração sejam executadas sem interrupções. Além disso, nossas APIs Web Scraper lidam com a rotação de IPs e a resolução de CAPTCHA automaticamente, economizando seu tempo e esforço. Para dados prontos para uso, explore nossa ampla variedade de conjuntos de dados adaptados a várias necessidades.
Leve sua coleta de dados para o próximo nível —inscreva-se hoje mesmopara um teste gratuito com a Bright Data e experimente soluções de scraping eficientes e confiáveis para seus projetos.





