

Se você é um vendedor ou está fazendo uma pesquisa de mercado, saber o ASIN de um produto pode ajudá-lo a encontrar rapidamente produtos exatamente iguais, analisar listagens de concorrentes e permanecer à frente no mercado. Este artigo mostrará métodos simples e eficazes para extrair ASINs da Amazon em grande escala. Você também aprenderá sobre a solução da Bright Data, que pode acelerar significativamente esse processo.
O que é um ASIN na Amazon?
Um ASIN é um código de 10 caracteres que combina letras e números (por exemplo, B07PZF3QK9). A Amazon atribui esse código exclusivo a todos os produtos em seu catálogo, desde livros até eletrônicos e roupas.
Existem duas maneiras simples de encontrar o ASIN de qualquer produto:
1. Observe a URL do produto – o ASIN aparece logo após “/dp/” na barra de endereço.
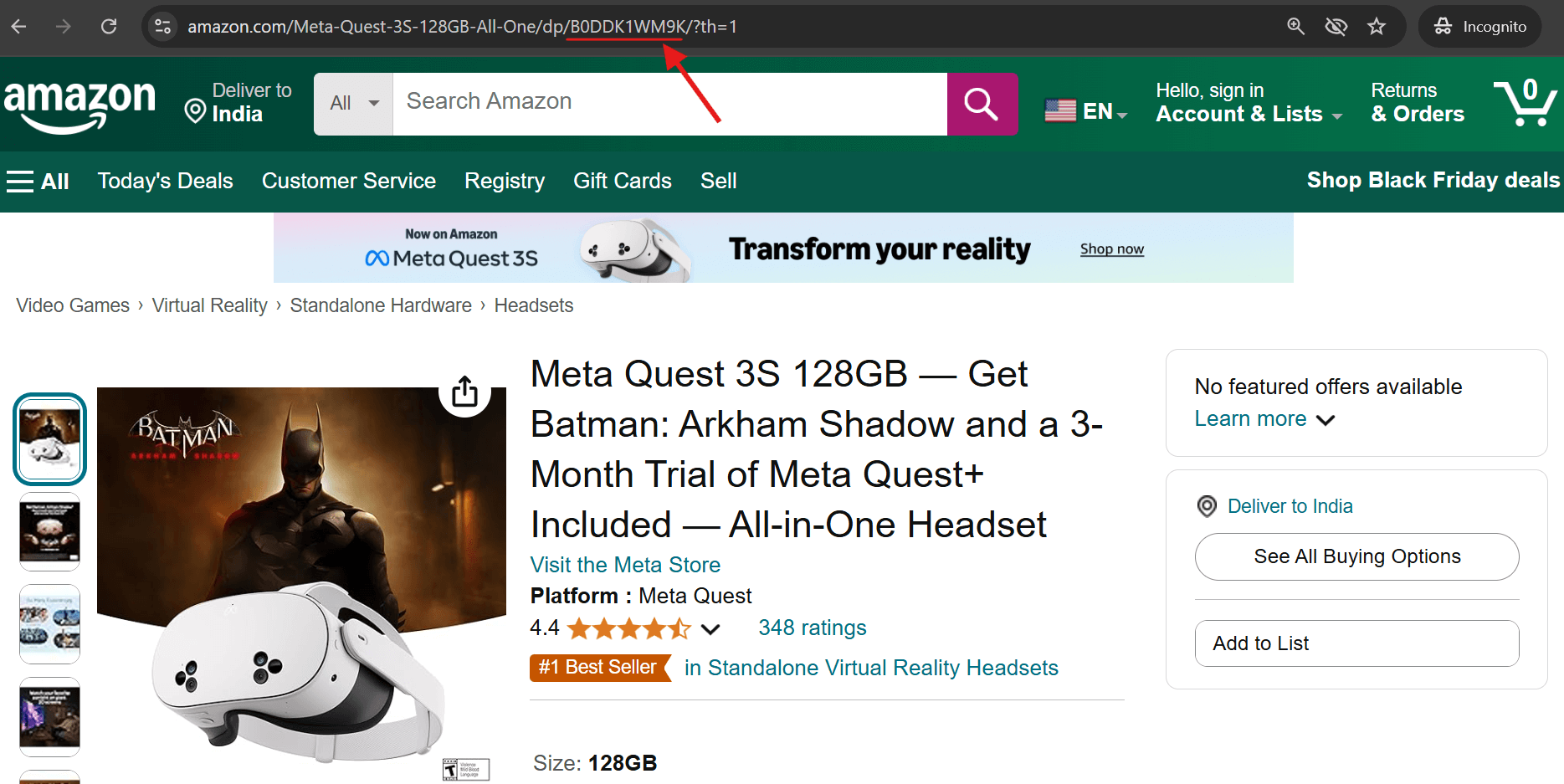
2. Role para baixo até a seção de informações do produto em qualquer lista da Amazon – você encontrará o ASIN listado lá.
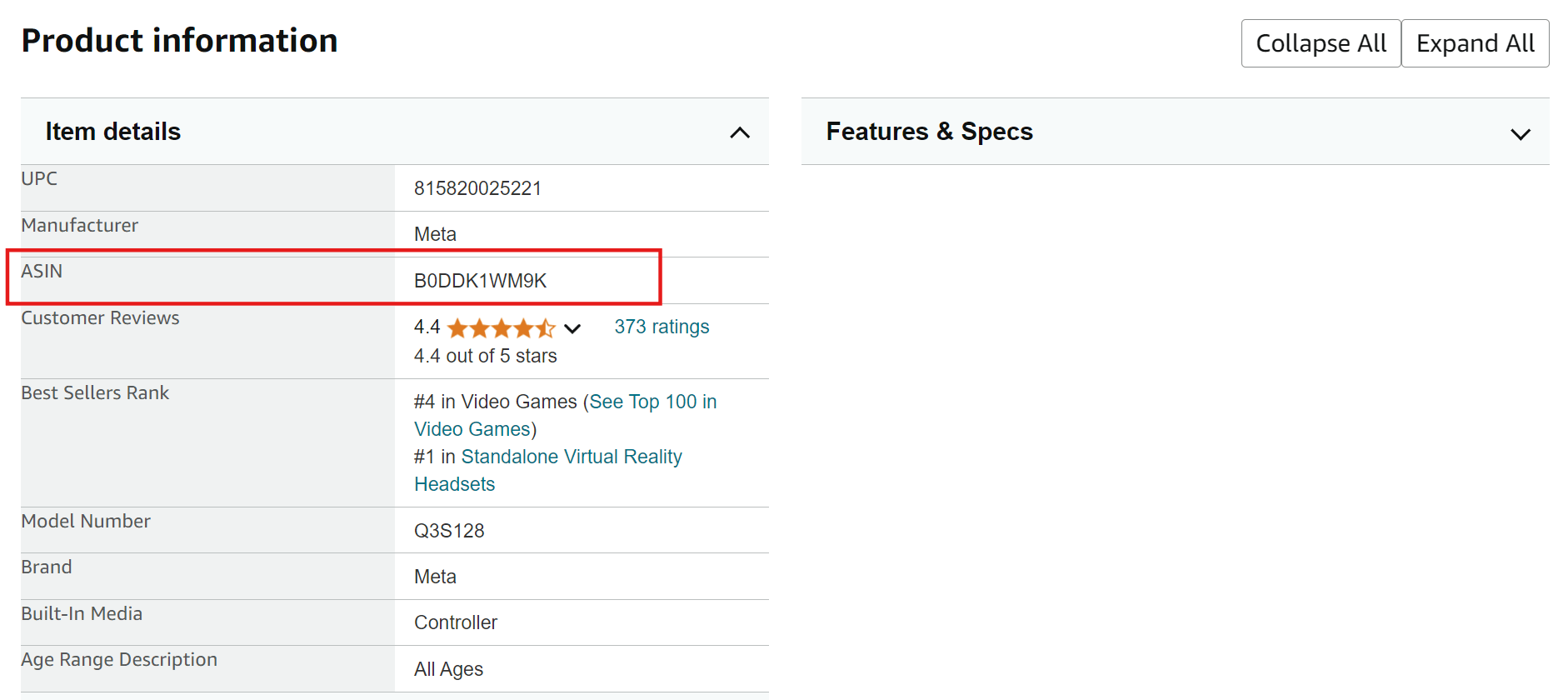
Como extrair ASINs da Amazon
Extrair dados da Amazon pode parecer simples à primeira vista, mas é bastante desafiador devido às suas robustas medidas anti-extração. A Amazon protege-se ativamente contra a coleta automatizada de dados por meio de vários métodos sofisticados:
- Desafios CAPTCHA
- Erros HTTP 503 que bloqueiam o acesso às páginas solicitadas
- Mudanças frequentes no layout do site que quebram a lógica de Parsing
Aqui está uma captura de tela de um erro HTTP 503 típico acionado pela Amazon:

Você pode tentar este script simples para coletar ASINs da Amazon:
import asyncio import os from curl_cffi import requests from bs4 import BeautifulSoup from tenacity import retry, stop_after_attempt, wait_random class AsinScraper: def __init__(self): self.session = requests.Session() self.asins = set() def create_url(self, keyword: str, page: int) -> str: return f"https://www.amazon.com/s?k={keyword.replace(' ', '+')}&page={page}" @retry(stop=stop_after_attempt(3), wait=wait_random(min=2, max=5)) async def fetch_page(self, url: str) -> str | None: tente: imprima(f"Buscando URL: {url}") resposta = self.session.get( url, impersonate="chrome120", timeout=30) imprima(f"Código de status HTTP: {response.status_code}") if response.status_code == 200: # Verificar se há indicadores de bloqueio na resposta if "Sorry" not in response.text: return response.text else: print("Sorry, request blocked!") else: print(f"Unexpected HTTP status code: {response.status_code}") except Exception as e: imprimir(f"Ocorreu uma exceção durante a busca: {e}") retornar Nenhum def extrair_asins(self, html: str) -> set[str]: soup = BeautifulSoup(html, "lxml") containers = soup.find_all( "div", {"data-component-type": "s-search-result"}) novos_asins = conjunto() para contêiner em contêineres: asin = contêiner.obter("data-asin") se asin e asin.remover(): novos_asins.adicionar(asin) retornar novos_asins def salvar_em_csv(self, palavra-chave: str): se não self.asins: imprimir("Nenhum ASIN para salvar") retornar # Criar diretório de resultados se não existir os.makedirs("results", exist_ok=True) # Gerar nome do arquivo csv_path = f"results/amazon_asins_{keyword.replace(' ', '_')}.csv" # Salvar como CSV with open(csv_path, 'w') as f: f.write("asinn") for asin in sorted(self.asins): f.write(f"{asin}n") print(f"ASINs salvos em: {csv_path}") async def main(): scraper = AsinScraper() palavra-chave = "laptop" máximo_de_páginas = 5 para página em intervalo(1, máximo_de_páginas + 1): imprimir(f"Raspando página {página}...") html = aguardar scraper.fetch_page(scraper.create_url(palavra-chave, página)) if not html: print(f"Falha ao buscar a página {page}") break new_asins = Scraper.extract_asins(html) if new_asins: Scraper.asins.update(new_asins) print(f"Encontrados {len(new_asins)} ASINs na página { page}. Total de ASINs: {len(Scraper.asins)}") else: print("Não foram encontrados mais ASINs. Finalizando a coleta.") break # Salvar resultados em CSV Scraper.save_to_csv(palavra-chave) if __name__ == "__main__": asyncio.run(main())
Então, qual é a solução para coletar ASINs da Amazon? A abordagem mais confiável envolve o uso de Proxies residenciais dos melhores provedores de Proxy, juntamente com cabeçalhos HTTP adequados.
Usando proxies Bright Data para coletar ASINs da Amazon
A Bright Data é um provedor líder de proxies com uma rede global de proxies. Ela oferece diferentes tipos de proxies em servidores compartilhados e privados, atendendo a uma ampla gama de casos de uso. Esses servidores podem rotear o tráfego usando os protocolos HTTP, HTTPS e SOCKS.
Por que escolher a Bright Data para coletar dados da Amazon?
- Vasta rede IP: acesso a 400M+ monthly IPs em 195 países
- Segmentação precisa por geolocalização: segmente cidades específicas, códigos postais ou até mesmo operadoras
- Vários tipos de proxies: escolha entre proxies residenciais, de datacenter, móveis ou ISP.
- Alta confiabilidade: taxa de sucesso de 99,9% com tempo de atividade opcional de 100%
- Escalabilidade flexível: opções de pagamento conforme o uso disponíveis para empresas de todos os tamanhos
Configurando o Bright Data para scraping da Amazon
Se você deseja usar proxies Bright Data para scraping de ASIN da Amazon, siga estas etapas simples:
Etapa 1: Inscreva-se no Bright Data
Acesse o site da Bright Data e crie uma conta. Se você já tem uma conta, prossiga para a próxima etapa.
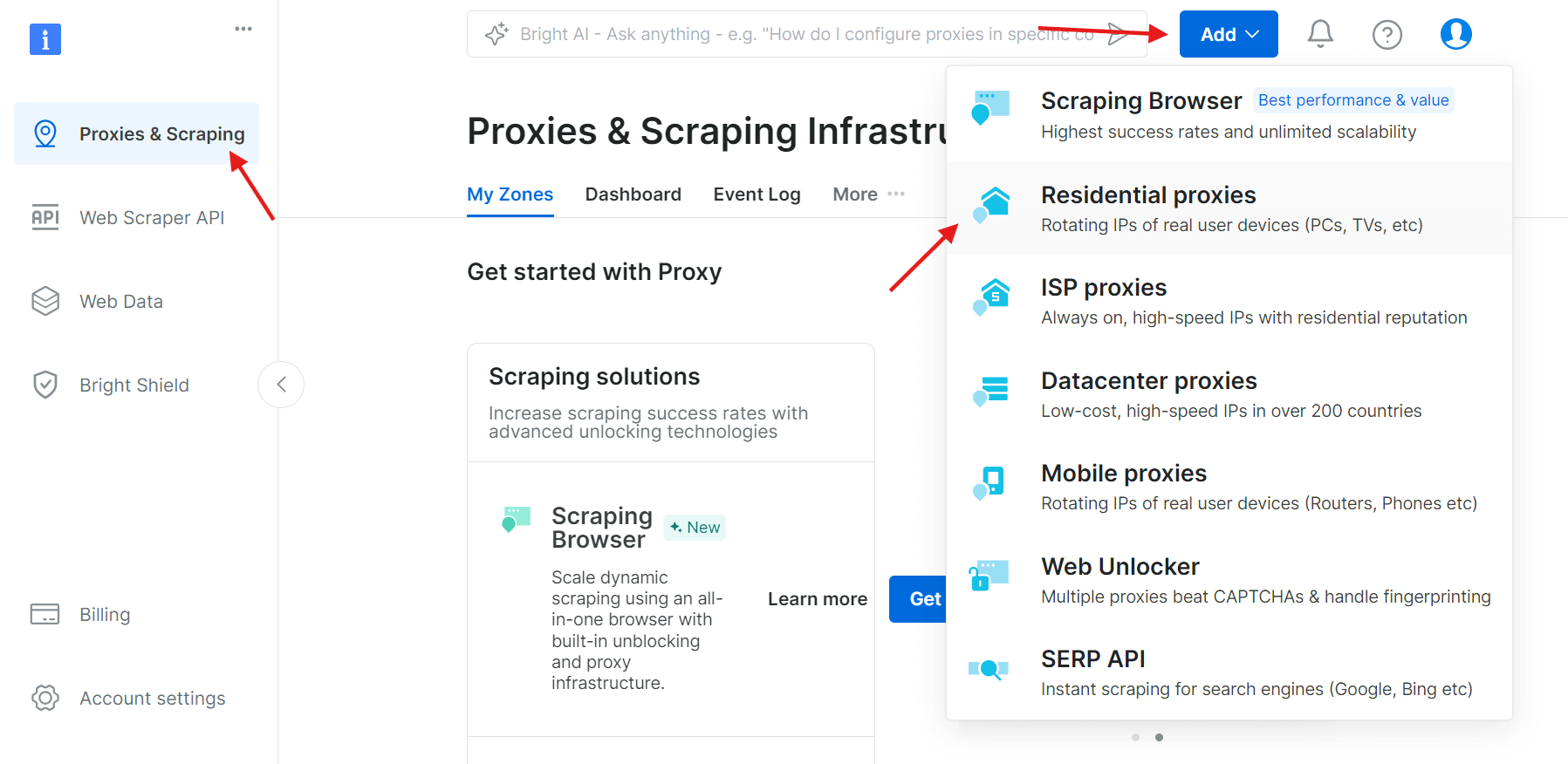
Etapa 2: crie uma nova zona de Proxy
Faça login, acesse a seção Infraestrutura de proxy e scraping e clique em Adicionar para criar uma nova zona de proxy. Selecione Proxies residenciais, que são a melhor opção para evitar restrições anti-scraping, pois usam IPs de dispositivos reais.
Etapa 3: Configure as definições do Proxy
Escolha as regiões ou países para navegação. Dê um nome apropriado à sua Zona (por exemplo, “asin_scraping”).
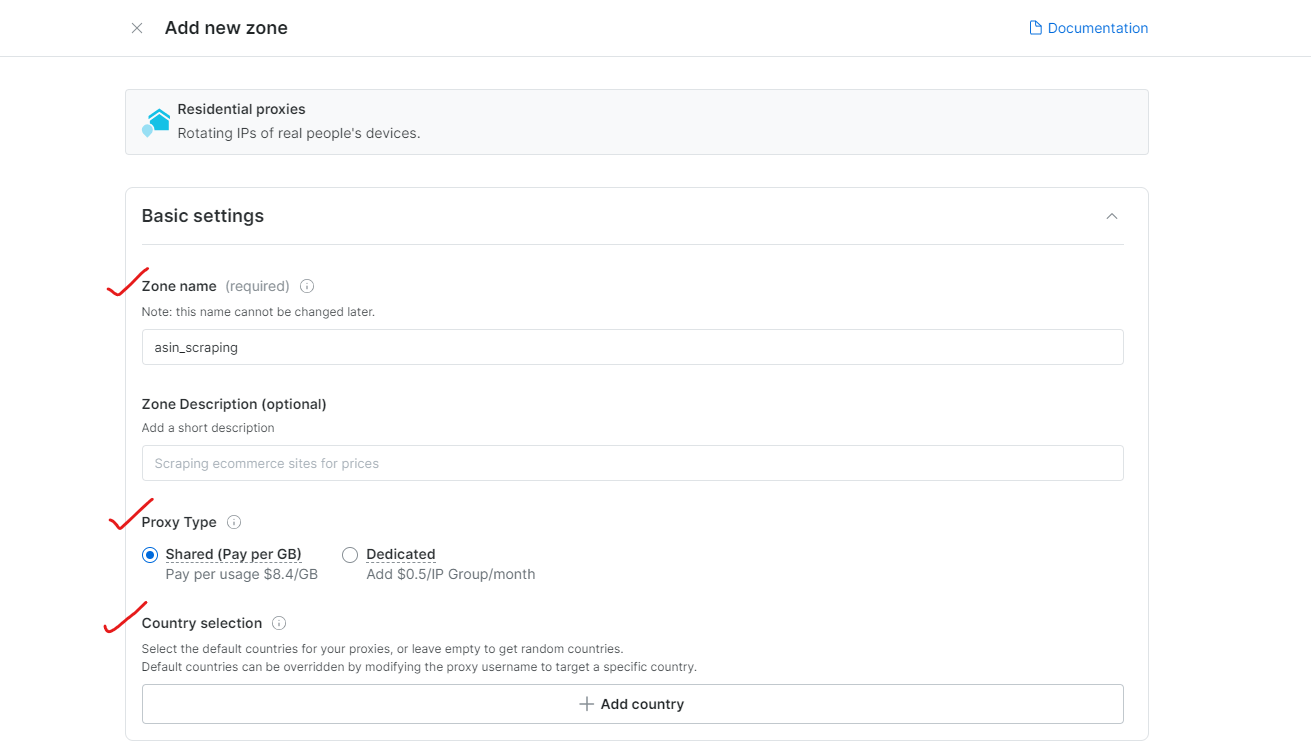
A Bright Data permite uma segmentação geográfica precisa, até a cidade ou CEP.
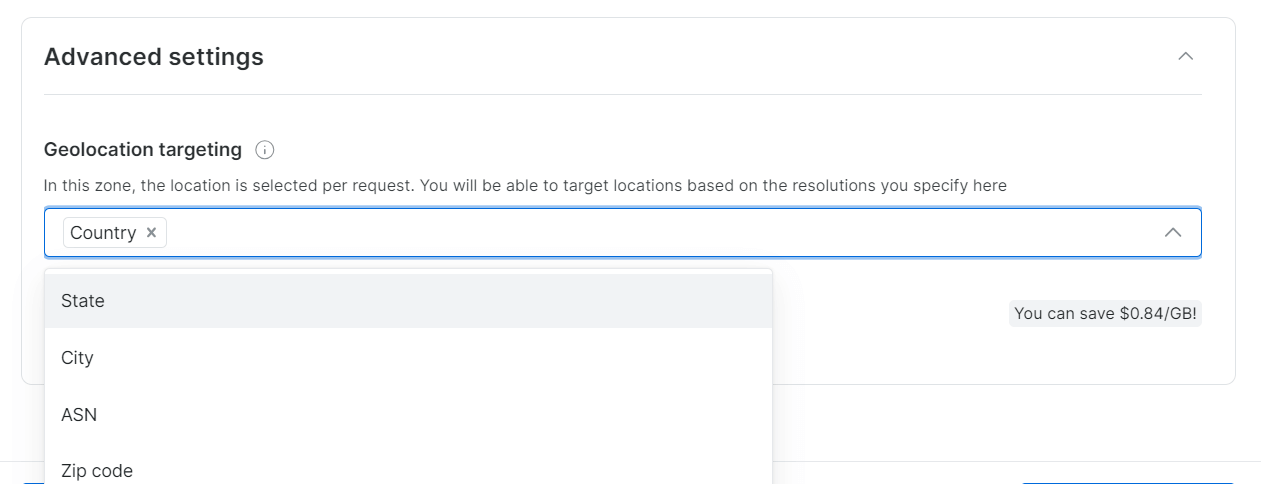
Etapa 4: Conclua a verificação KYC
Para ter acesso total aos Proxies residenciais da Bright Data, conclua o processo de Verificação KYC.
Passo 5: Comece a usar proxies
Depois que a zona de Proxy for criada, você verá as credenciais (host, porta, nome de usuário, senha) para começar a fazer o scraping.
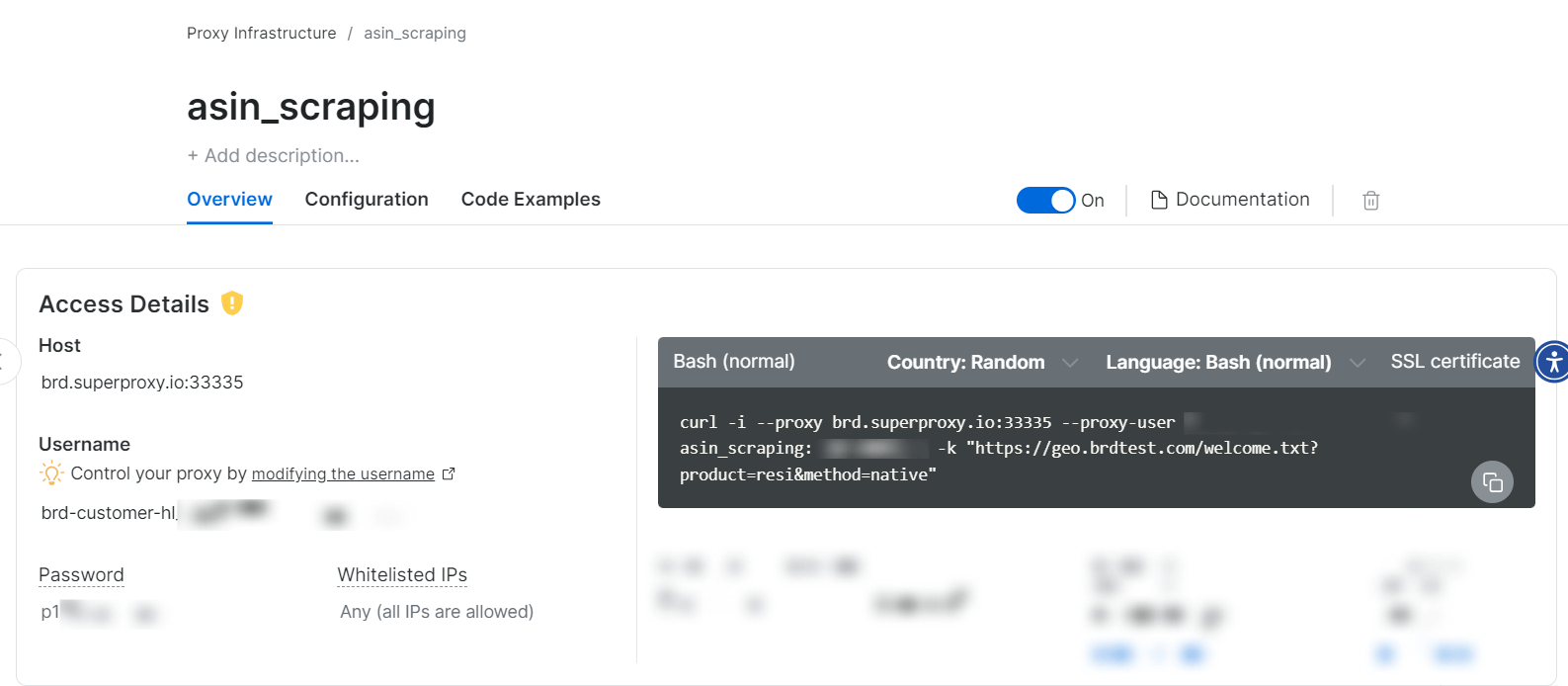
Sim, é simples assim!
Implementando o Scraper
Etapa 1: Configurar os cabeçalhos do navegador
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"sec-ch-ua": '"Chromium";v="119", "Not?A_Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
Etapa 2: Configurando as definições do Proxy
proxy_config = {
"username": "SEU_NOME_DE_USUÁRIO",
"password": "SUA_SENHA",
"server": "brd.superproxy.io:33335",
}
proxy_url = f"http://{proxy_config['username']}:{proxy_config['password']}@{proxy_config['server']}"
Etapa 3: Fazendo solicitações
Faça uma solicitação usando cabeçalhos e Proxies com a biblioteca curl_cffi:
response = session.get(
url,
headers=headers,
impersonate="chrome120",
proxies={"http": proxy_url, "https": proxy_url},
timeout=30,
verify=False,
)
Observação: a biblioteca curl_cffi é uma excelente opção para o Scraping de dados, oferecendo recursos avançados de representação de navegador que superam a biblioteca de solicitações padrão.
Etapa 4: Executando seu Scraper
Para executar seu Scraper, você precisará configurar suas palavras-chave de destino. Aqui está um exemplo:
keywords = [
"coffee maker",
"office desk",
"cctv camera"
]
max_pages = None # Defina como None para todas as páginas
Encontre o código completo aqui.
O Scraper irá gerar resultados para um arquivo CSV contendo:
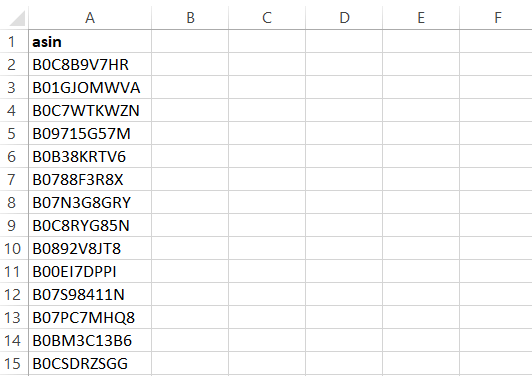
Usando la API Bright Data Amazon Scraper para extrair ASINs
Embora a extração baseada em Proxy funcione, usar a API Bright Data Amazon Scraper oferece vantagens significativas:
- Sem gerenciamento de infraestrutura: não é preciso se preocupar com Proxies, rotações de IP ou captchas
- Scraping por localização geográfica: faça scraping de qualquer região geográfica
- Integração simples: implementação em minutos com qualquer linguagem de programação
- Várias opções de entrega de dados:
- Exporte para Amazon S3, Google Cloud, Azure, Snowflake ou SFTP
- Obtenha dados nos formatos JSON, NDJSON, CSV ou .gz
- Em conformidade com o GDPR e a CCPA: garante a conformidade com a privacidade para o Scraping de dados ético da web
- 20 chamadas de API gratuitas: teste o serviço antes de se comprometer
- Suporte 24 horas por dia, 7 dias por semana: suporte dedicado para ajudar com quaisquer dúvidas ou problemas relacionados à API
Configurando a API do Amazon Scraper
A configuração da API é simples e pode ser concluída em algumas etapas.
Etapa 1: Acesse a API
Navegue até a API Web Scraper e procure por “amazon products search” (pesquisa de produtos Amazon) nas APIs disponíveis:
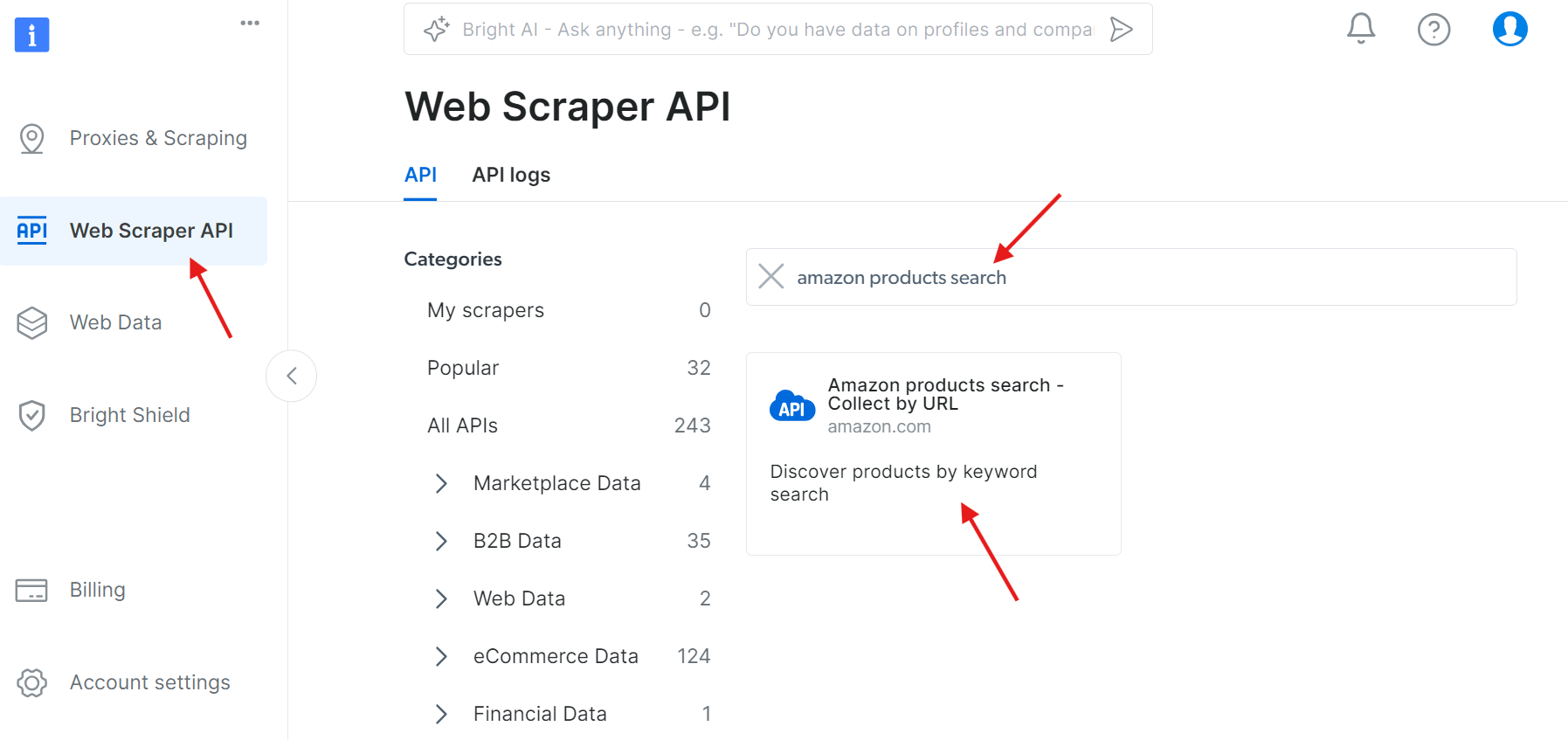
Clique em “Iniciar configuração de uma chamada de API”:
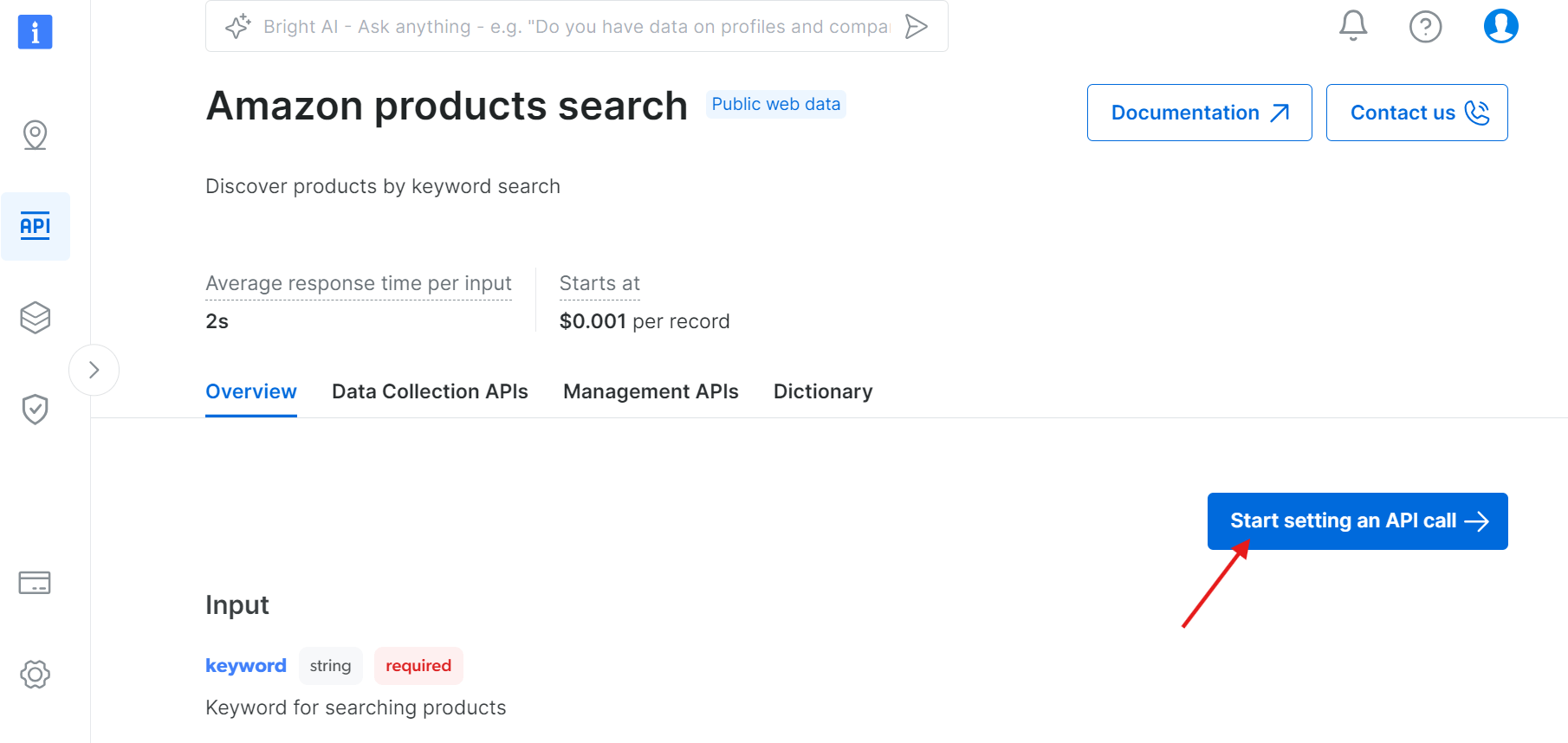
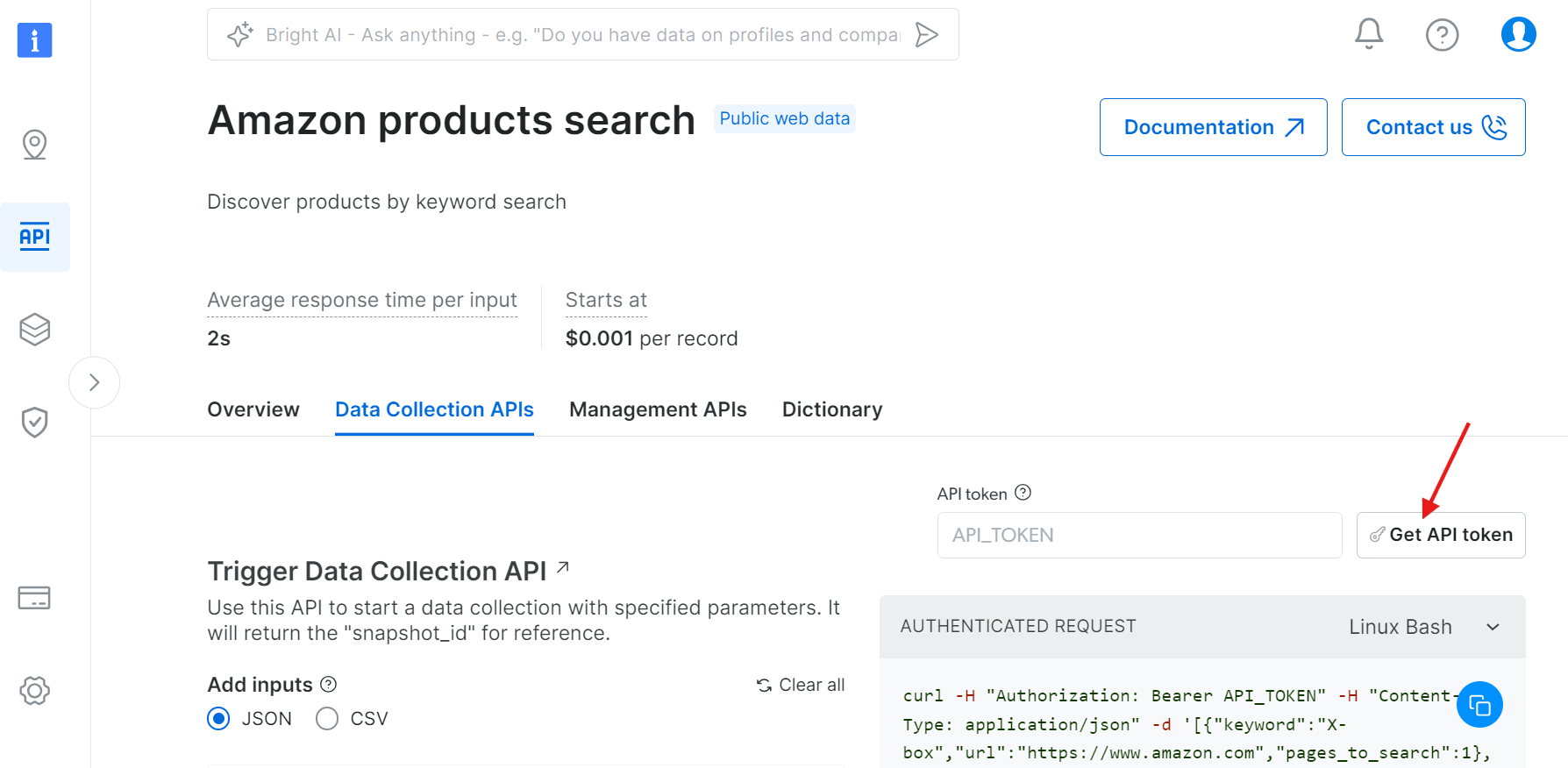
Etapa 2: Obtenha seu token de API
Clique em “Obter token da API”:
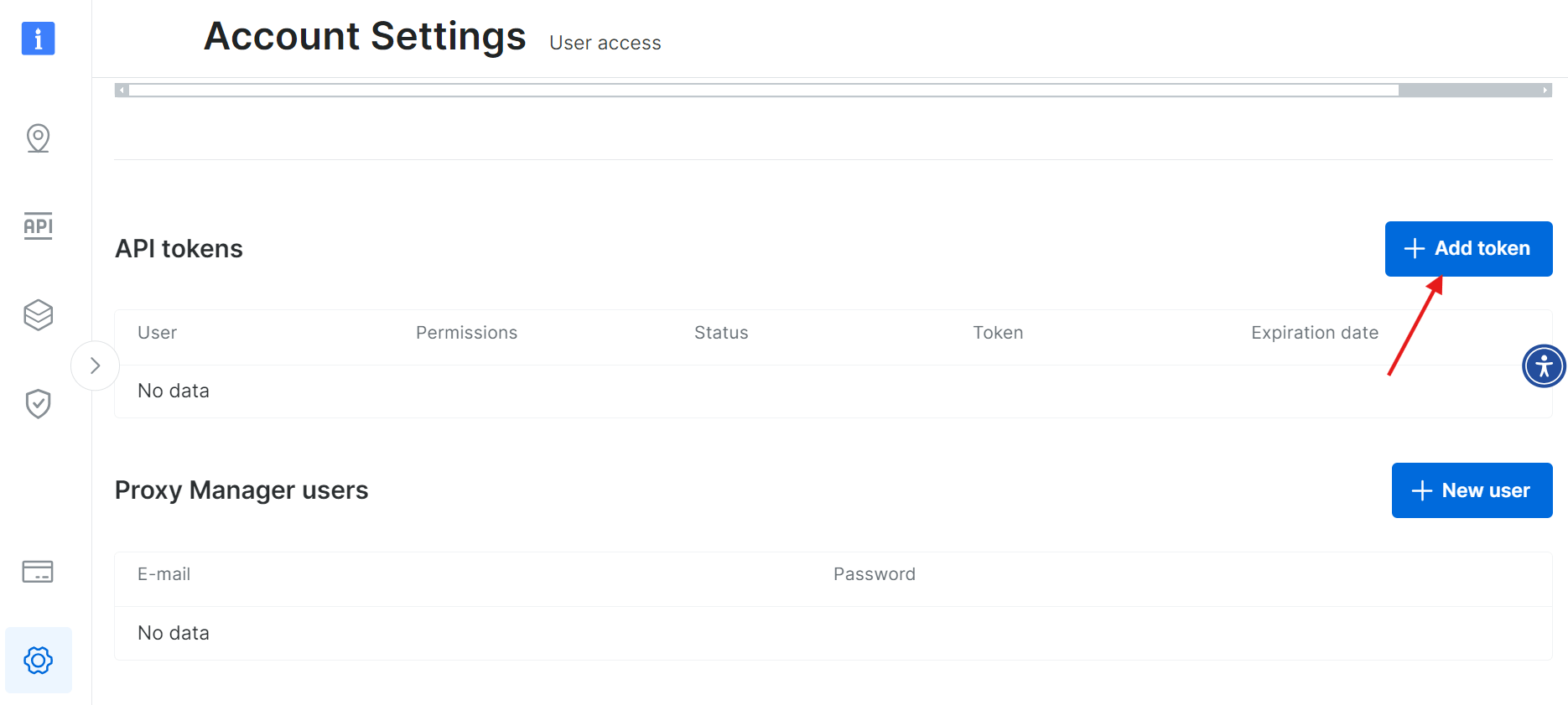
Selecione “Adicionar token”:
Salve seu novo token de API com segurança:
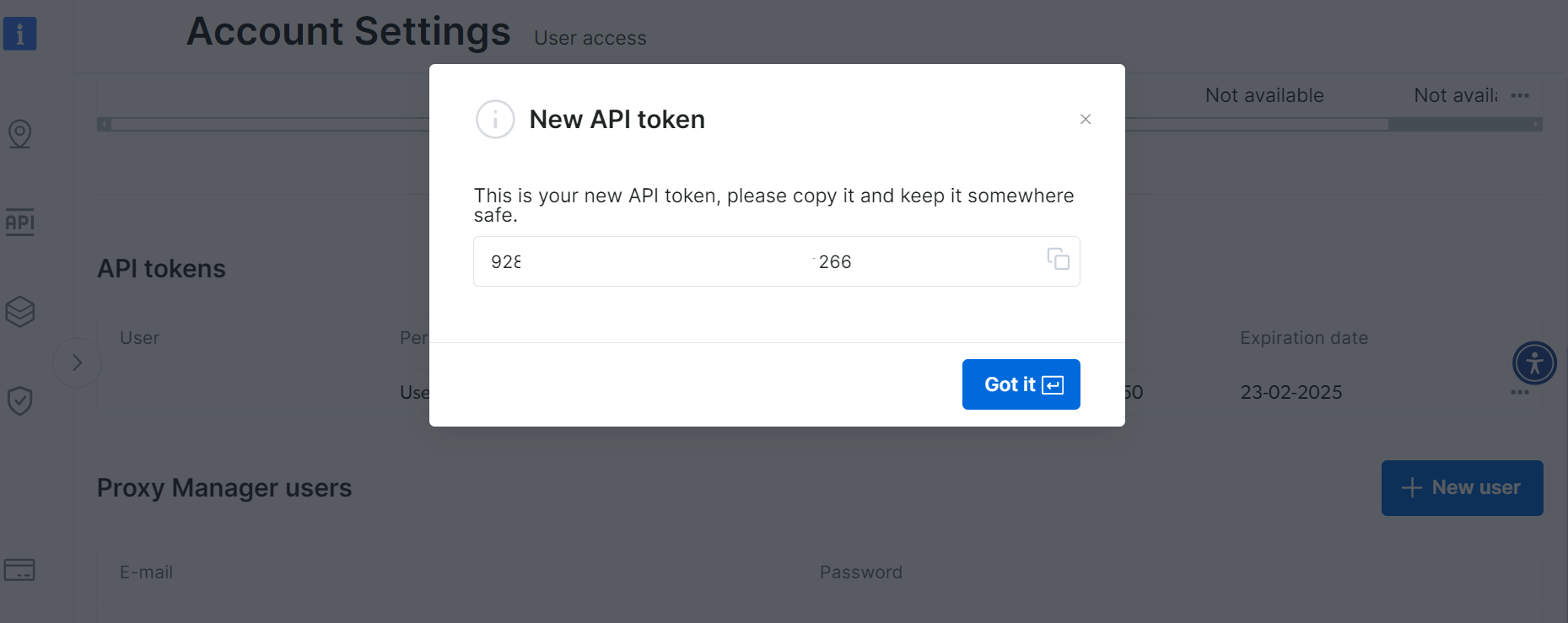
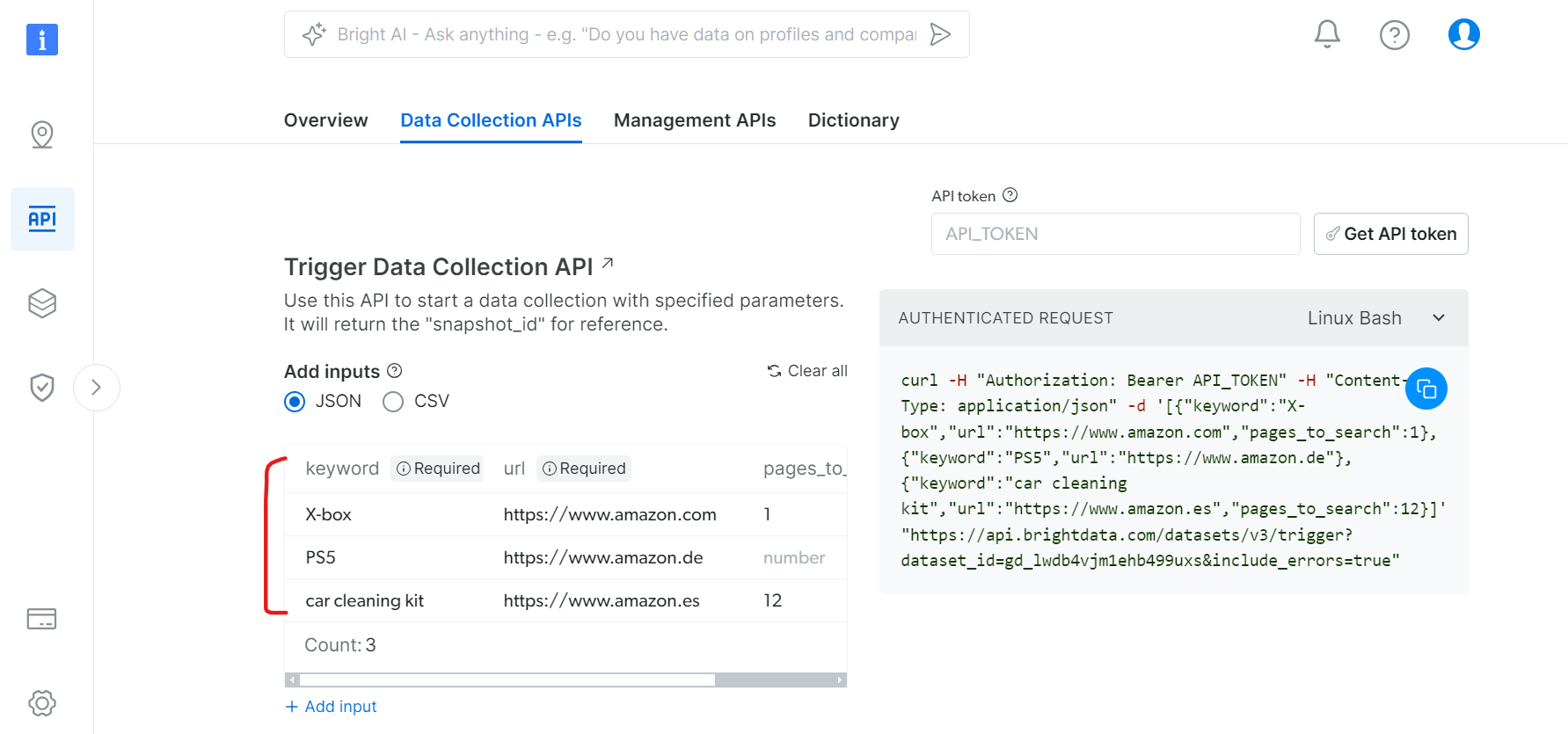
Etapa 3: Configure a coleta de dados
Na guia APIs de coleta de dados:
- Especifique palavras-chave para pesquisa de produtos
- Defina os domínios Amazon de destino
- Defina o número de páginas a serem rastreadas
- Filtros adicionais (opcional)
Usando a API com Python
Aqui está um exemplo de script Python para acionar a coleta de dados e recuperar resultados:
import json
import requests
import time
from typing import Dict, List, Optional, Union, Tuple
from datetime import datetime, timedelta
import logging
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from enum import Enum
class SnapshotStatus(Enum):
SUCCESS = "success"
PROCESSING = "processing"
FAILED = "failed"
TIMEOUT = "timeout"
class BrightDataAmazonScraper:
def __init__(self, api_token: str, dataset_id: str):
self.api_token = api_token
self.dataset_id = dataset_id
self.base_url = "https://api.brightdata.com/conjuntos-de-dados/v3"
self.headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
# Configurar o registro com formato personalizado
logging.basicConfig(
level=logging.INFO,
format='%(message)s' # Formato simplificado para mostrar apenas mensagens
)
self.logger = logging.getLogger(__name__)
# Configurar sessão com estratégia de repetição
self.session = self._create_session()
# Acompanhar progresso
self.last_progress_update = 0
def _create_session(self) -> requests.Session:
"""Criar uma sessão com estratégia de repetição"""
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=0.5,
status_forcelist=[500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
session.mount("http://", adapter)
return session
def trigger_collection(self, datasets: List[Dict]) -> Optional[str]:
"""Aciona a coleta de dados para Conjuntos de dados especificados"""
trigger_url = f"{self.base_url}/trigger?dataset_id={self.dataset_id}"
tente:
resposta = self.session.post(
trigger_url,
headers=self.headers,
json=Conjuntos de datos
)
resposta.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
if snapshot_id:
self.logger.info("Inicializando coleta de dados da Amazon...")
return snapshot_id
else:
self.logger.error("Não foi possível inicializar a coleta de dados.")
return None
exceto requests.exceptions.RequestException como e:
self.logger.error(f"Falha na inicialização da coleta: {str(e)}")
retornar None
def check_snapshot_status(self, snapshot_id: str) -> Tuple[SnapshotStatus, Optional[Dict]]:
"""Verificar o status atual de um snapshot"""
snapshot_url = f"{self.base_url}/snapshot/{snapshot_id}?format=json"
tente:
resposta = self.session.get(snapshot_url, headers=self.headers)
if response.status_code == 200:
return SnapshotStatus.SUCCESS, response.json()
elif response.status_code == 202:
return SnapshotStatus.PROCESSING, None
else:
return SnapshotStatus.FAILED, None
exceto requests.exceptions.RequestException:
retorne SnapshotStatus.FAILED, None
def esperar_por_dados_do_instantâneo(
self,
snapshot_id: str,
timeout: Opcional[int] = None,
check_interval: int = 10,
max_interval: int = 300,
callback=None
) -> Opcional[Dict]:
"""Aguardar dados de snapshot com saída mínima do console"""
hora_inicial = datetime.now()
intervalo_atual = intervalo_de_verificação
tentativas = 0
progresso_mostrado = Falso
enquanto Verdadeiro:
tentativas += 1
if timeout is not None:
elapsed_time = (datetime.now() - start_time).total_seconds()
if elapsed_time >= timeout:
self.logger.error("A coleta de dados excedeu o limite de tempo.")
return None
status, data = self.check_snapshot_status(snapshot_id)
if status == SnapshotStatus.SUCCESS:
self.logger.info(
"Coleta de dados da Amazon concluída com sucesso!")
return data
elif status == SnapshotStatus.FAILED:
self.logger.error("Ocorreu um erro na coleta de dados.")
return None
elif status == SnapshotStatus.PROCESSING:
# Mostrar indicador de progresso apenas a cada 30 segundos
current_time = time.time()
if not progress_shown:
self.logger.info("Coletando dados da Amazon...")
progress_shown = True
elif current_time - self.last_progress_update >= 30:
self.logger.info("Coleta de dados em andamento...")
self.last_progress_update = current_time
if callback:
callback(attempts, (datetime.now() -
start_time).total_seconds())
time.sleep(intervalo_atual)
intervalo_atual = min(intervalo_atual * 1.5, intervalo_máximo)
def armazenar_dados(self, dados: Dict, nome_arquivo: str = "amazon_data.json") -> None:
"""Armazena os dados coletados em um arquivo JSON"""
if data:
try:
with open(filename, "w", encoding='utf-8') as file:
json.dump(data, file, indent=4, ensure_ascii=False)
self.logger.info(f"Dados salvos com sucesso em {filename}")
exceto IOError como e:
self.logger.error(f"Erro ao salvar dados: {str(e)}")
else:
self.logger.warning("Nenhum dado disponível para salvar.")
def progress_callback(tentativas: int, tempo_transcorrido: float):
"""Função de retorno de chamada mínima - pode ser personalizada com base nas necessidades"""
pass # Silencioso por padrão
def main():
# Configuração
API_TOKEN = "YOUR_API_TOKEN"
DATASET_ID = "gd_lwdb4vjm1ehb499uxs"
# Inicializar Scraper
Scraper = BrightDataAmazonScraper(API_TOKEN, DATASET_ID)
# Definir parâmetros de pesquisa
Conjuntos de dados = [
{"keyword": "X-box", "url": "https://www.amazon.com", "pages_to_search": 1},
{"keyword": "PS5", "url": "https://www.amazon.de"},
{"keyword": "car cleaning kit",
"url": "https://www.amazon.es", "pages_to_search": 4},
]
# Executar processo de scraping
snapshot_id = scraper.trigger_collection(Conjuntos de dados)
if snapshot_id:
data = scraper.wait_for_snapshot_data(
snapshot_id,
timeout=None,
check_interval=10,
max_interval=300,
callback=progress_callback
)
if data:
Scraper.store_data(data)
print("nProcesso de scraping concluído com sucesso!n")
if __name__ == "__main__":
main()
Para executar este código, certifique-se de substituir os seguintes valores:
API_TOKENpelo seu token API real.- Modifique a lista
de Conjuntos de dadospara incluir os produtos ou palavras-chave que você deseja pesquisar.
Aqui está um exemplo da estrutura JSON dos dados recuperados:
{
"asin": "B0CJ3XWXP8",
"url": "https://www.amazon.com/Xbox-X-Console-Renewed/dp/B0CJ3XWXP8/ref=sr_1_1",
"name": "Xbox Series X Console (Renovado) Xbox Series X Console (Renovado) 15 de setembro de 2023",
"sponsored": "false",
"initial_price": 449.99,
"final_price": 449.99,
"currency": "USD",
"sold": 2000,
"rating": 4.1,
"num_ratings": 1529,
"variations": null,
"badge": null,
"business_type": null,
"brand": null,
"delivery": ["Entrega GRÁTIS domingo, 1 de dezembro", "Ou entrega mais rápida sexta-feira, 29 de novembro"],
"palavra-chave": "X-box",
"imagem": "https://m.media-amazon.com/images/I/51ojzJk77qL._AC_UY218_.jpg",
"domínio": "https://www.amazon.com/",
“comprado_no_mês_passado”: 2000,
“número_da_página”: 1,
“classificação_na_página”: 1,
“timestamp”: “2024-11-26T05:15:24.590Z”,
"input": {
"keyword": "X-box",
"url": "https://www.amazon.com",
"pages_to_search": 1,
},
}
Você pode visualizar a saída completa baixandoeste arquivo JSON de amostra.
Conclusão
Discutimos o processo de coleta de ASINs da Amazon usando Python, mas também enfrentamos vários desafios ao longo do caminho. Problemas como CAPTCHAs e limites de taxa podem atrapalhar bastante nossos esforços de coleta de dados. Como solução, podemos usar ferramentas como os Proxies da Bright Data ou a API Amazon Scraper. Essas opções podem ajudar a acelerar o processo e nos ajudar a contornar obstáculos comuns. Se você preferir evitar o trabalho de configurar suas ferramentas de scraping, a Bright Data também oferece Conjuntos de dados prontos da Amazon que você pode usar imediatamente.
Inscreva-se agora e comece seu teste grátis!





