

Neste artigo, você descobrirá:
- Quais produtos a Bright Data fornece no Databricks.
- Como configurar uma conta Databricks e recuperar todas as credenciais necessárias para recuperação e exploração programática de dados.
- Como consultar um conjunto de dados da Bright Data usando o Databricks:
- REST API
- CLI
- Conector SQL
Vamos começar!
Produtos de dados da Bright Data no Databricks
O Databricks é uma plataforma de análise aberta para criar, implantar, compartilhar e manter dados, análises e soluções de IA de nível empresarial em escala. No site, você pode encontrar produtos de dados de vários fornecedores, razão pela qual é considerado um dos melhores mercados de dados.
A Bright Data recentemente se juntou à Databricks como fornecedora de produtos de dados, já oferecendo mais de 40 produtos:
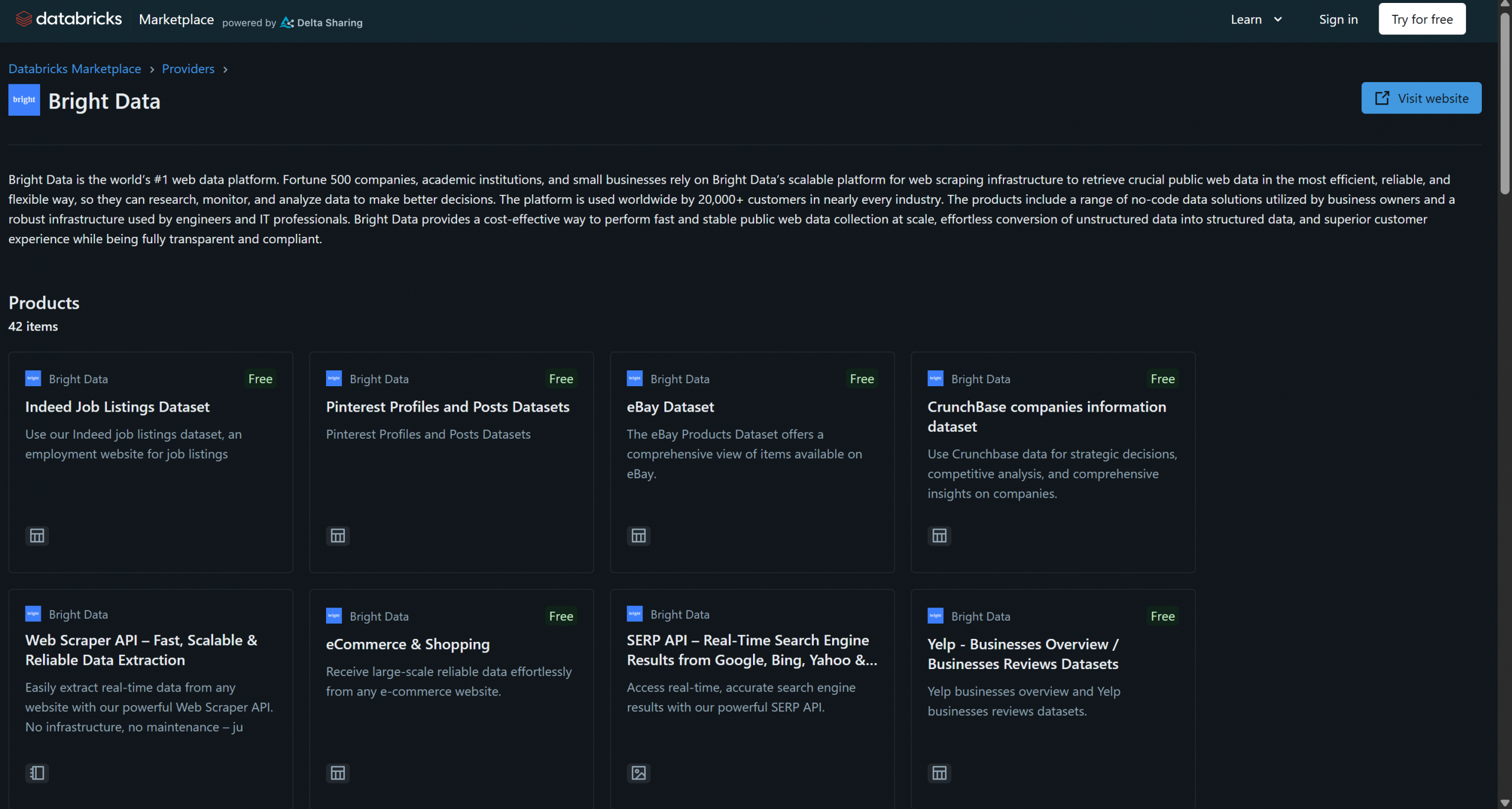
Essas soluções incluem conjuntos de dados B2B, conjuntos de dados de empresas, conjuntos de dados financeiros, conjuntos de dados imobiliários e muitos outros. Além disso, você também tem acesso a soluções mais gerais de recuperação de dados da web e Scraping de dados por meio da infraestrutura da Bright Data, como o Navegador de scraping e a API Web Scraper.
Neste tutorial, você aprenderá como consultar programaticamente os dados de um desses Conjuntos de dados da Bright Data usando a API Databricks, CLI e biblioteca SQL Connector dedicada. Vamos começar!
Introdução ao Databricks
Para consultar Conjuntos de dados da Bright Data a partir do Databricks via API ou CLI, primeiro você precisa configurar algumas coisas. Siga as etapas abaixo para configurar sua conta Databricks e recuperar todas as credenciais necessárias para acessar e integrar o conjunto de dados da Bright Data.
Ao final desta seção, você terá:
- Uma conta Databricks configurada
- Um token de acesso ao Databricks
- Um ID de armazém do Databricks
- Uma string de host do Databricks
- Acesso a um ou mais Conjuntos de dados Bright Data em sua conta Databricks
Pré-requisitos
Primeiro, certifique-se de ter uma conta Databricks (uma conta gratuita é suficiente). Se você não tiver uma, crie uma conta. Caso contrário, basta fazer login.
Configure seu token de acesso Databricks
Para autorizar o acesso aos recursos do Databricks, você precisa de um token de acesso. Siga as instruções abaixo para configurar um.
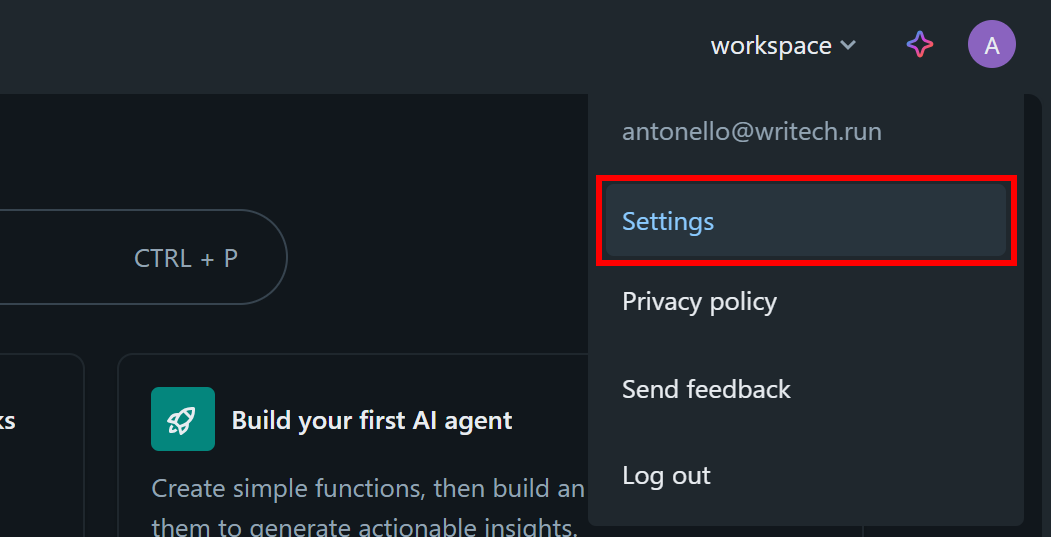
No painel do Databricks, clique na sua imagem de perfil e selecione a opção “Configurações”:
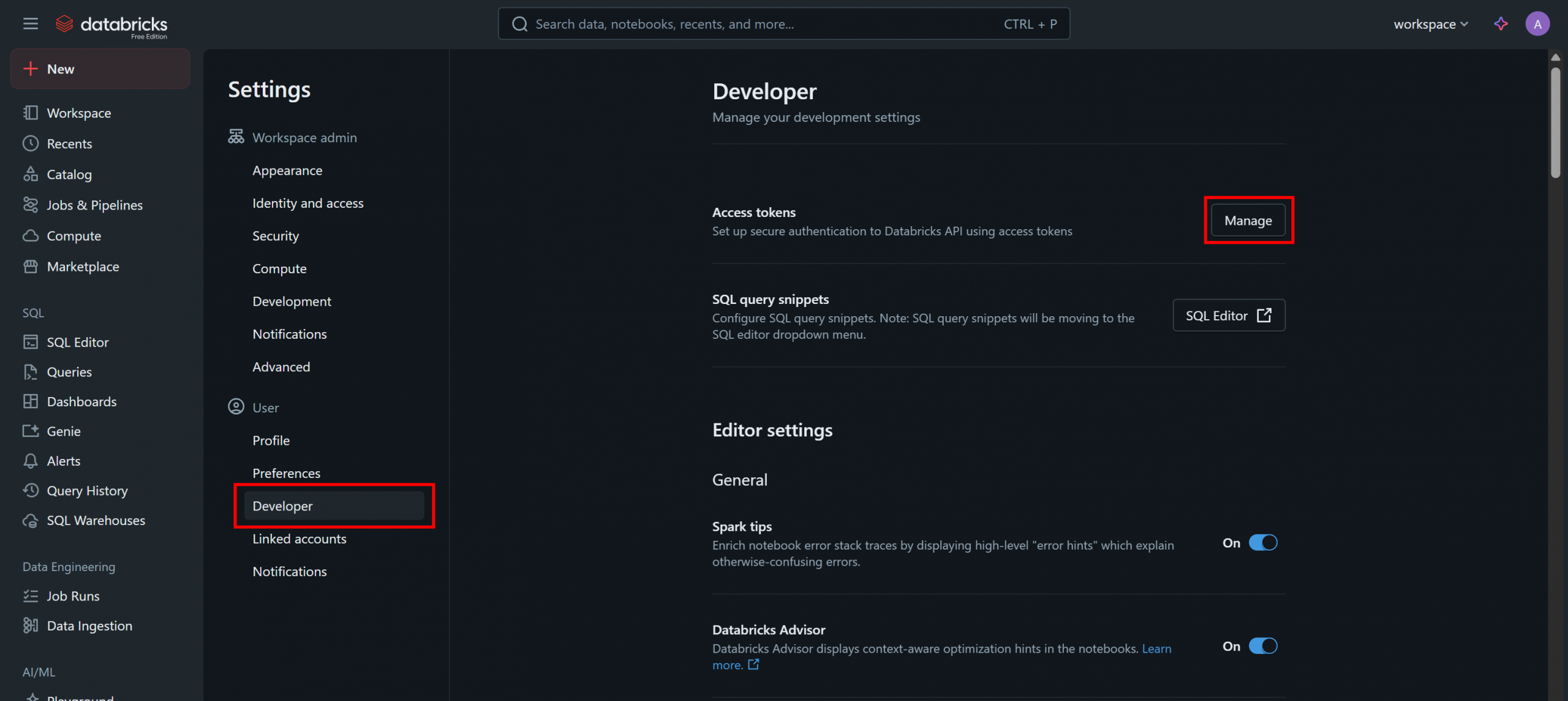
Na página “Configurações”, selecione a opção “Desenvolvedor” e clique no botão “Gerenciar” na seção “Tokens de acesso”:
Na página “Tokens de acesso”, clique em “Gerar novo token” e siga as instruções na janela modal:
Você receberá um token de acesso à API do Databricks. Guarde-o em um local seguro, pois você precisará dele em breve.
Recupere seu ID do Databricks Warehouse
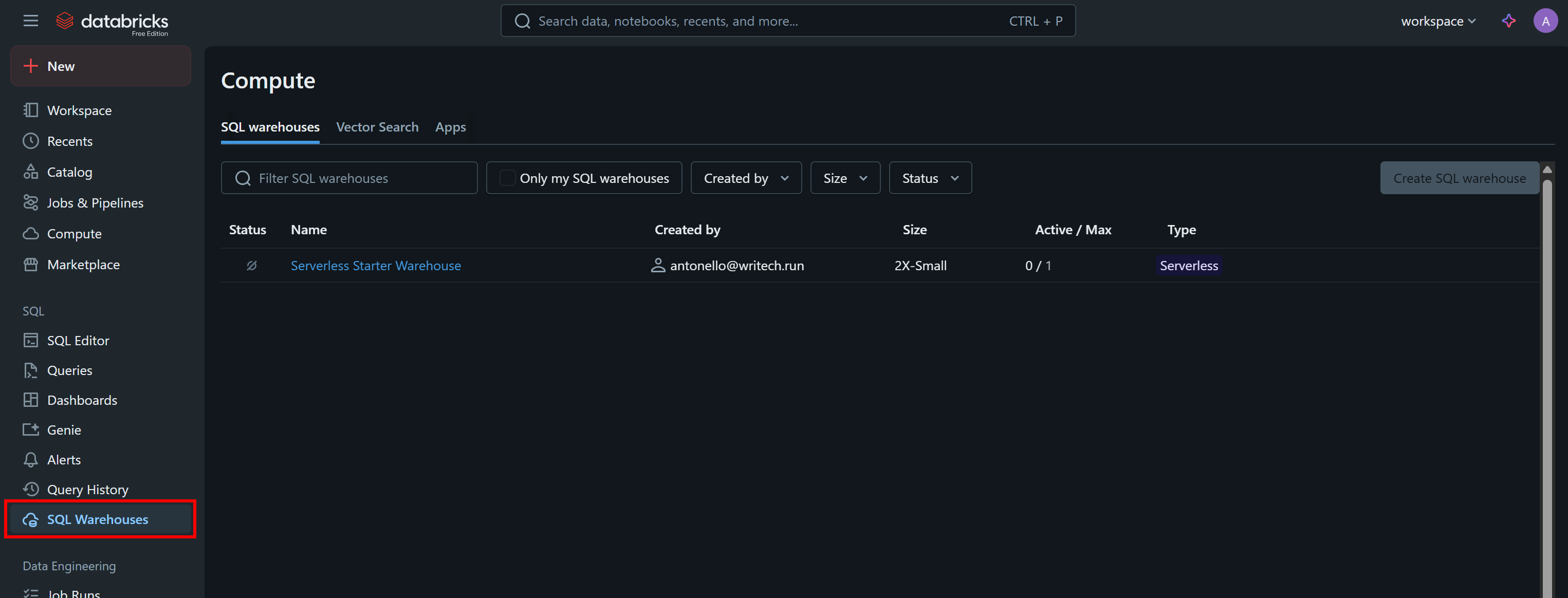
Outra informação necessária para chamar programaticamente a API ou consultar os Conjuntos de dados por meio da CLI é o seu ID do armazém Databricks. Para recuperá-lo, selecione a opção “Armazéns SQL” no menu:
Clique no armazém disponível (neste exemplo, “Serverless Starter Warehouse”) e acesse a guia “Visão geral”:
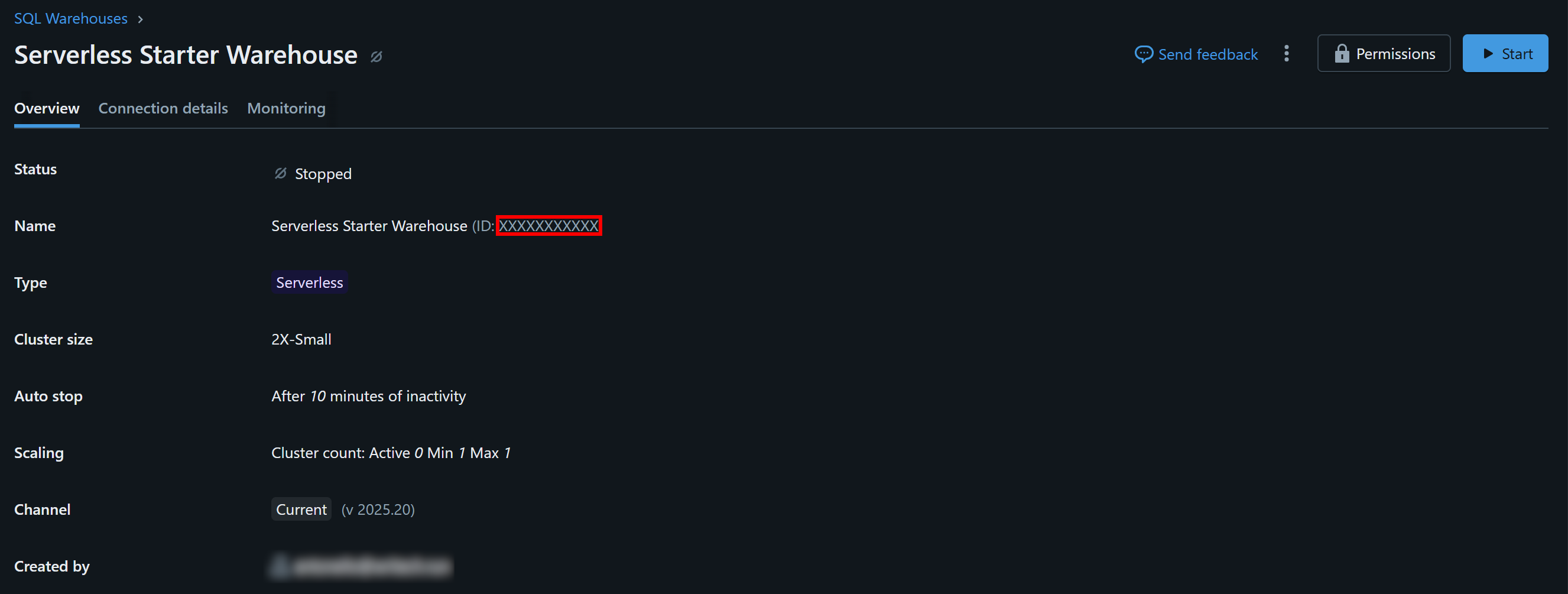
Na seção “Name” (Nome), você verá o ID do seu Databricks Warehouse (entre parênteses, após ID:). Copie-o e guarde-o em um local seguro, pois você precisará dele em breve.
Encontre seu host Databricks
Para se conectar a qualquer recurso de computação do Databricks, você precisa especificar o nome do seu host Databricks. Ele corresponde à URL base associada à sua conta Databricks e tem um formato como:
https://<string aleatória>.cloud.databricks.comVocê pode encontrar essas informações diretamente copiando-as da URL do seu painel do Databricks:

Obtenha acesso aos Conjuntos de dados da Bright Data
Agora você precisa adicionar um ou mais Conjuntos de dados da Bright Data à sua conta Databricks para poder consultá-los por meio da API, CLI ou SQL Connector.
Acesse a página “Marketplace”, clique no botão de configurações à esquerda e selecione “Bright Data” como o único provedor de seu interesse:
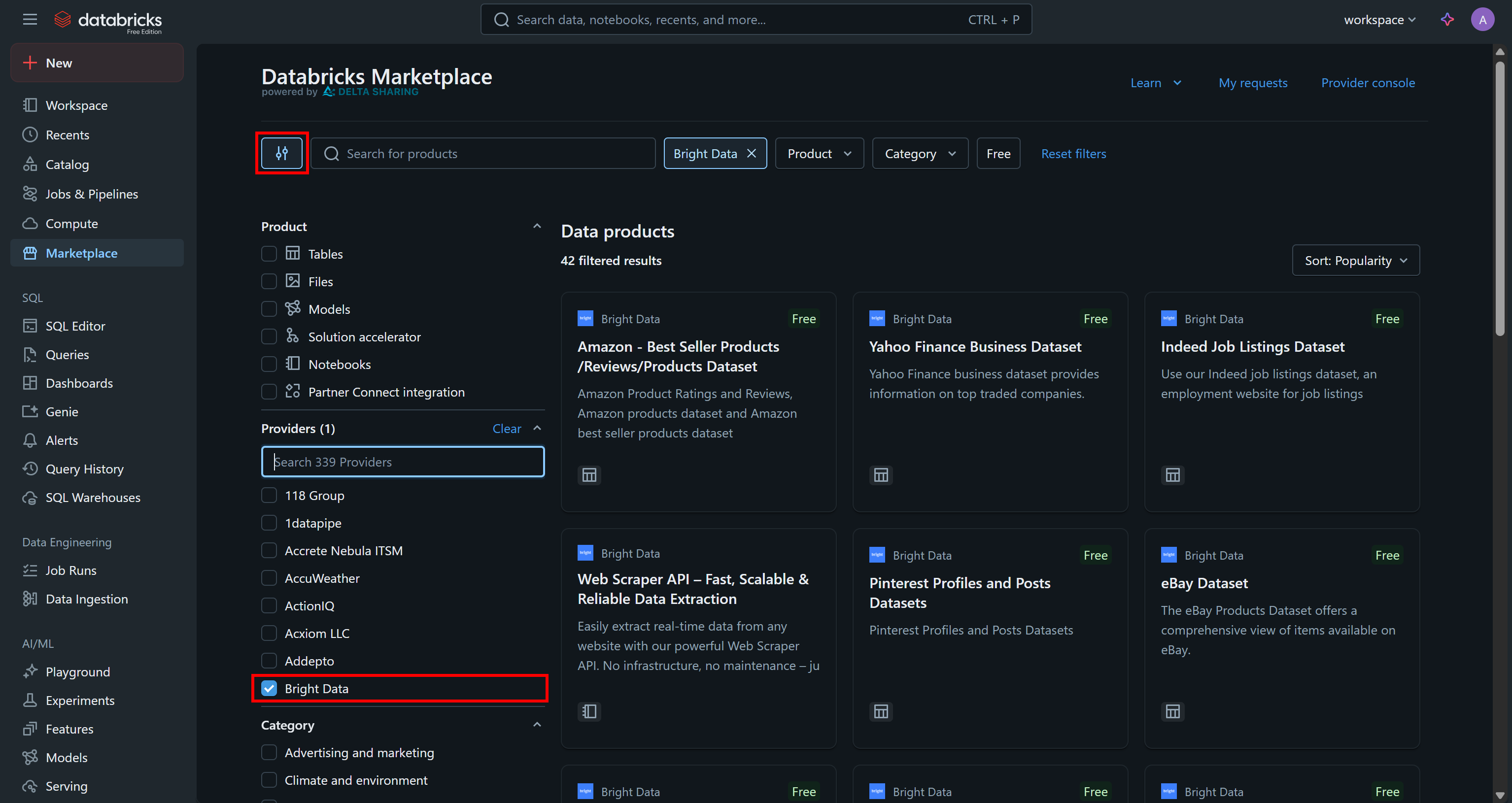
Isso filtrará os produtos de dados disponíveis apenas para aqueles fornecidos pela Bright Data e acessíveis via Databricks.
Para este exemplo, suponha que você esteja interessado no “Conjuntode dados de informações sobre propriedades da Zillow”:
Clique no cartão do conjunto de dados e, na página “Conjunto de dados de informações sobre propriedades da Zillow”, pressione “Obter acesso às instâncias” para adicioná-lo à sua conta Databricks:
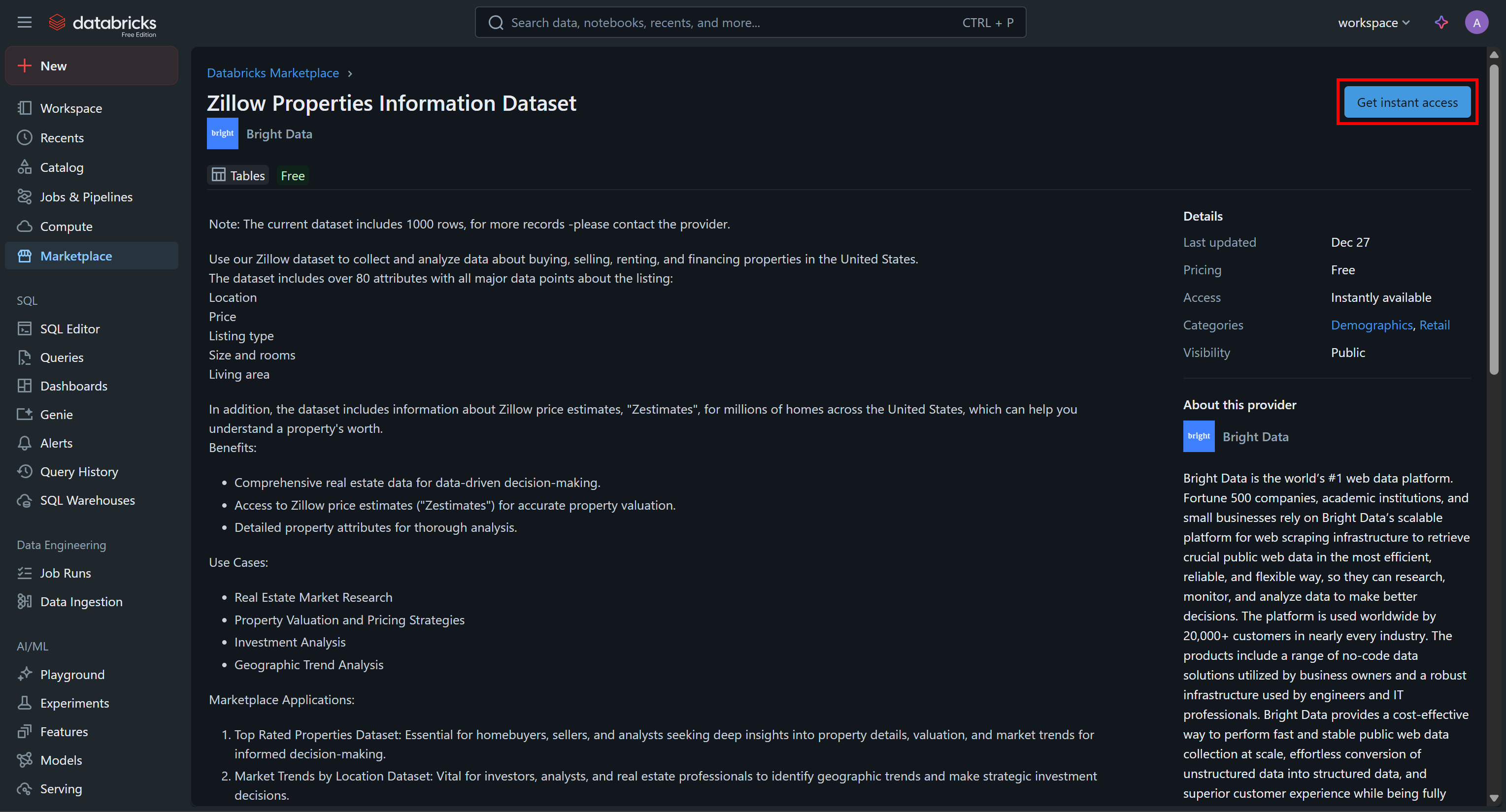
O conjunto de dados será adicionado à sua conta e agora você poderá consultá-lo através do Databricks SQL. Se você está se perguntando de onde vêm esses dados, a resposta é: dos Conjuntos de dados Zillow da Bright Data.
Verifique isso acessando a página “SQL Editor” e consulte os Conjuntos de dados usando uma consulta SQL como esta:
SELECT * FROM bright_data_zillow_properties_information_dataset.conjuntos de datos.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;O resultado deve ser algo como:
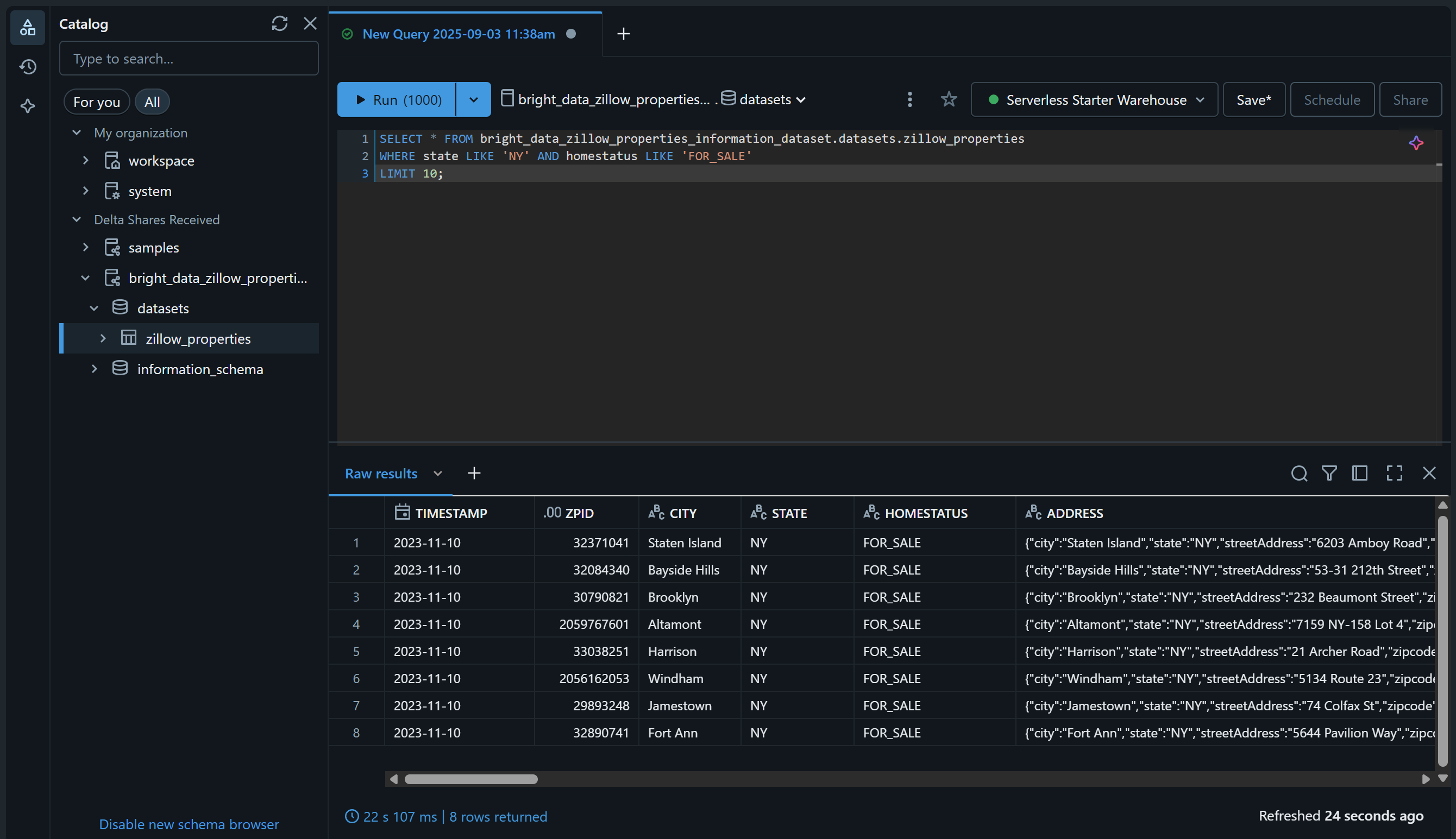
Ótimo! Você adicionou com sucesso o conjunto de dados Bright Data escolhido e o tornou pesquisável via Databricks. Você pode seguir as mesmas etapas para adicionar outros Conjuntos de dados Bright Data.
Nas próximas seções, você aprenderá como consultar este conjunto de dados:
- Por meio da API REST do Databricks
- Com o conector SQL do Databricks para Python
- Através da CLI do Databricks
Como consultar um conjunto de dados da Bright Data por meio da API REST do Databricks
O Databricks expõe alguns de seus recursos por meio de uma API REST, incluindo a capacidade de consultar Conjuntos de dados disponíveis em sua conta. Siga as etapas abaixo para ver como consultar programaticamente o “Conjunto de dados de informações sobre propriedades da Zillow” fornecido pela Bright Data.
Observação: o código abaixo foi escrito em Python, mas pode ser facilmente adaptado para outras linguagens de programação ou chamado diretamente no Bash por meio do cURL.
Etapa 1: instale as bibliotecas necessárias
Para executar consultas SQL em armazéns remotos do Databricks, o endpoint da API REST a ser usado é /api/2.0/sql/statements. Você pode chamá-lo por meio de uma solicitação POST usando qualquer cliente HTTP. Neste exemplo, usaremos a biblioteca Python Requests.
Instale-a com:
pip install requestsEm seguida, importe-a em seu script com:
import requestsSaiba mais sobre ela em nosso guia dedicado ao Python Requests.
Etapa 2: prepare suas credenciais e segredos do Databricks
Para chamar o endpoint da API REST do Databricks /api/2.0/sql/statements usando um cliente HTTP, você precisa especificar:
- Seu token de acesso ao Databricks: para autenticação.
- Seu host Databricks: para criar a URL completa da API.
- Seu ID do armazém do Databricks: para consultar a tabela correta no armazém correto.
Adicione os segredos que você recuperou anteriormente ao seu script desta forma:
databricks_access_token = "<SEU_TOKEN_DE_ACESSO_AO_DATABRICKS>"
databricks_warehouse_id = "<SEU_ID_DO_DATACENTRO_DO_DATABRICKS>"
databricks_host = "<SEU_HOST_DO_DATABRICKS>"Dica: em produção, evite codificar esses segredos em seu script. Em vez disso, considere armazenar essas credenciais em variáveis de ambiente e carregá-las usando python-dotenv para maior segurança.
Etapa 3: Chame a API de execução de instruções SQL
Faça uma chamada HTTP POST para o endpoint /api/2.0/sql/statements com os cabeçalhos e o corpo apropriados usando Requests:
# A consulta SQL parametrizada a ser executada no conjunto de dados fornecido
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.conjuntos_de_dados.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# O parâmetro para preencher a consulta SQL
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Fazer a solicitação POST e consultar os Conjuntos de dados
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Para autenticação no Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)Como você pode ver, o trecho acima depende de uma instrução SQL preparada. Conforme enfatizado na documentação, a Databricks recomenda fortemente o uso de consultas parametrizadas como prática recomendada para suas instruções SQL.
Em outras palavras, executar o script acima é equivalente a executar a seguinte consulta na tabela bright_data_zillow_properties_information_dataset.conjuntos de dados.zillow_properties, assim como fizemos anteriormente:
SELECT * FROM bright_data_zillow_properties_information_dataset.conjuntos de datos.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;Fantástico! Resta apenas gerenciar os dados de saída
Etapa 4: Exportar os resultados da consulta
Lide com a resposta e exporte os dados recuperados com esta lógica Python:
if response.status_code == 200:
# Acesse os dados JSON de saída
result = response.json()
# Exporte os dados recuperados para um arquivo JSON
output_file = "zillow_properties.json"
com open(output_file, "w", encoding="utf-8") como f:
json.dump(result, f, indent=4)
print(f"Consulta bem-sucedida! Resultados salvos em '{output_file}'")
else:
print(f"Erro {response.status_code}: {response.text}")Se a solicitação for bem-sucedida, o trecho criará um arquivo zillow_properties.json contendo os resultados da consulta.
Etapa 5: Junte tudo
Seu script final deve conter:
import requests
import json
# Suas credenciais do Databricks (substitua-as pelos valores corretos)
databricks_access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
databricks_warehouse_id = "<YOUR_DATABRICKS_WAREHOUSE_ID>"
databricks_host = "<SEU_HOST_DO_DATABRICKS>"
# A consulta SQL parametrizada a ser executada no conjunto de dados fornecido
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.conjuntos_de_dados.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# O parâmetro para preencher a consulta SQL
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Faça a solicitação POST e consulte os Conjuntos de dados
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Para autenticação no Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)
# Processar a resposta
if response.status_code == 200:
# Acessar os dados JSON de saída
result = response.json()
# Exportar os dados recuperados para um arquivo JSON
output_file = "zillow_properties.json"
com open(arquivo_de_saída, "w", codificação="utf-8") como f:
json.dump(resultado, f, indentação=4)
imprimir(f"Consulta bem-sucedida! Resultados salvos em '{arquivo_de_saída}'")
caso contrário:
imprimir(f"Erro {código_de_status_da_resposta}: {texto_da_resposta}")Execute-o e ele deverá produzir um arquivo zillow_properties.json no diretório do seu projeto.
A saída contém primeiro a estrutura da coluna para ajudar você a entender as colunas disponíveis. Em seguida, no campo data_array, você pode ver os dados da consulta resultante como uma string JSON:
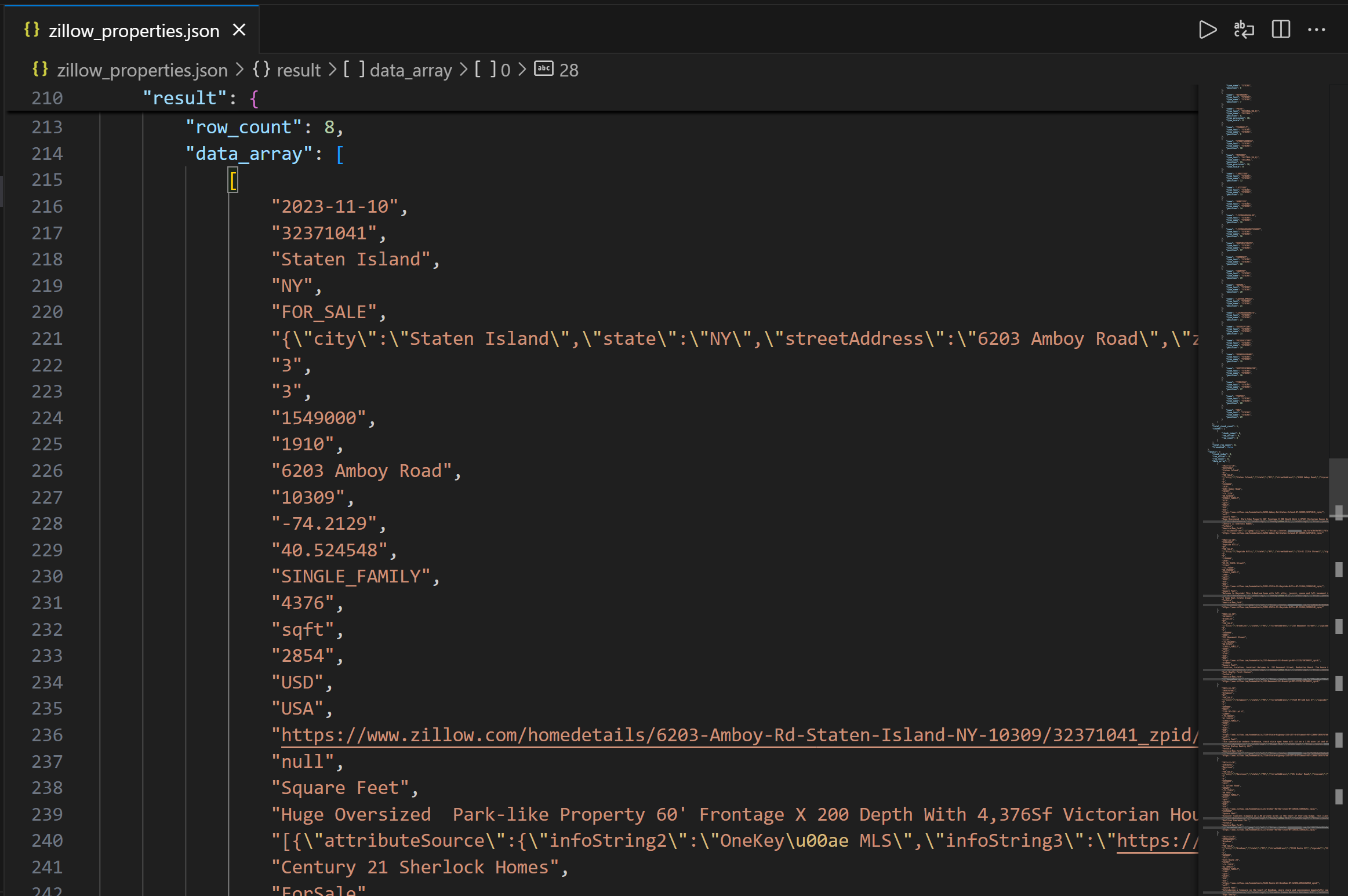
Missão cumprida! Você acabou de coletar os dados de propriedades da Zillow fornecidos pela Bright Data por meio da API REST da Databricks.
Como acessar Conjuntos de dados da Bright Data usando a CLI do Databricks
O Databricks também permite consultar dados em um armazém por meio da CLI do Databricks, que se baseia na API REST. Aprenda a usá-la!
Etapa 1: instale a CLI do Databricks
A CLI do Databricks é uma ferramenta de linha de comando de código aberto que permite interagir com a plataforma Databricks diretamente do seu terminal.
Para instalá-la, siga o guia de instalação do seu sistema operacional. Se tudo estiver configurado corretamente, ao executar o comando databricks -v, você verá algo assim:

Perfeito!
Etapa 2: defina um perfil de configuração para autenticação
Use a CLI do Databricks para criar um perfil de configuração chamado DEFAULT que autentica você com seu token de acesso pessoal do Databricks. Para fazer isso, execute o comando abaixo:
databricks configure --profile DEFAULTEm seguida, você será solicitado a fornecer:
- Seu host Databricks
- Seu token de acesso Databricks
Cole os dois valores e pressione Enter para concluir a configuração:

Agora você poderá autenticar os comandos da API da CLI especificando a opção --profile DEFAULT.
Etapa 3: consultar seu conjunto de dados
Use o seguinte comando CLI para executar uma consulta parametrizada por meio do comando API post:
databricks API post "/api/2.0/sql/statements"
--profile DEFAULT
--json '{
"warehouse_id": "<SEU_ID_DO_DATABRICKS_WAREHOUSE>",
"statement": "SELECT * FROM bright_data_zillow_properties_information_dataset.Conjuntos de dados.zillow_properties WHERE state LIKE :state AND homestatus LIKE :homestatus LIMIT :row_limit",
"parâmetros": [
{ "nome": "estado", "valor": "NY", "tipo": "STRING" },
{ "name": "homestatus", "value": "FOR_SALE", "type": "STRING" },
{ "name": "row_limit", "value": "10", "type": "INT" }
]
}'
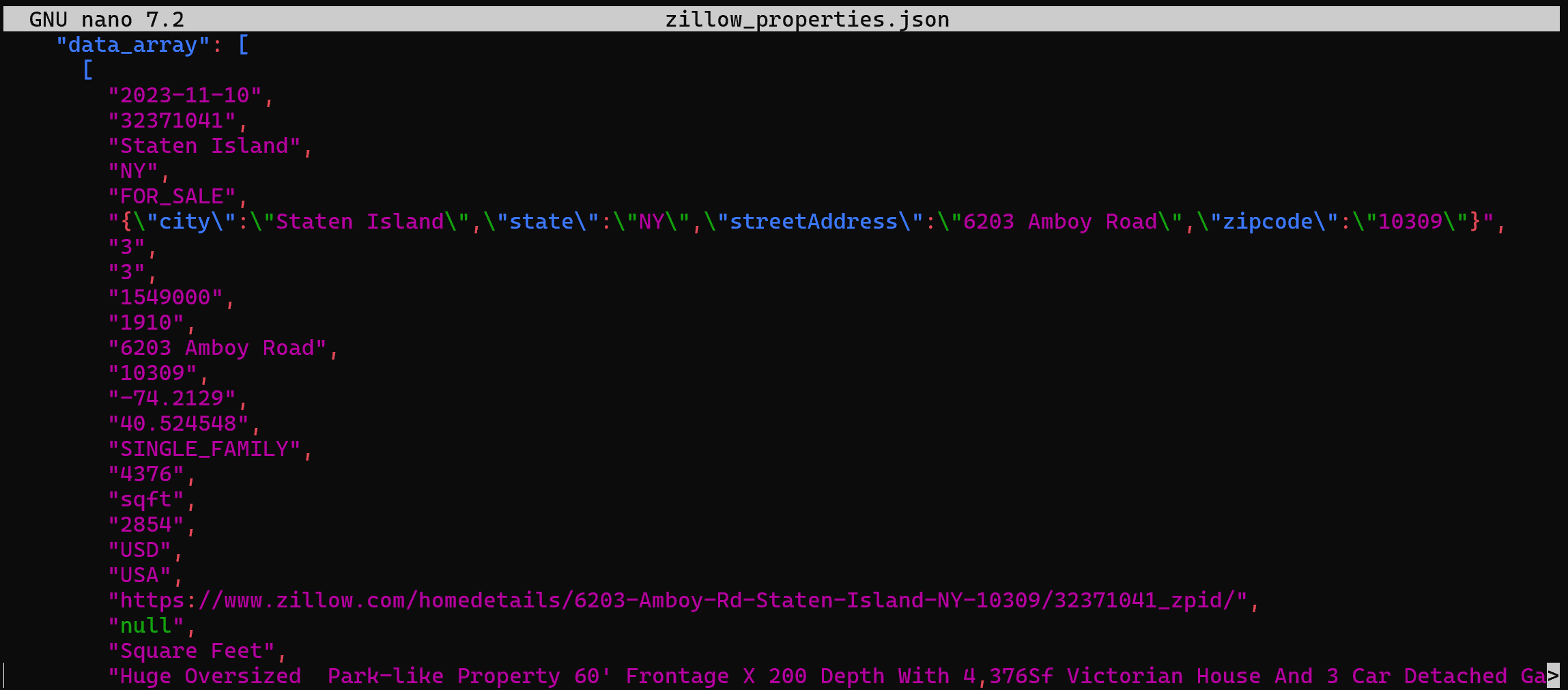
> zillow_properties.jsonSubstitua o espaço reservado <YOUR_DATABRICKS_WAREHOUSE_ID> pelo ID real do seu armazém de dados SQL do Databricks.
Nos bastidores, isso faz a mesma coisa que fizemos antes em Python. Mais especificamente, faz uma solicitação POST para a API REST SQL do Databricks. O resultado será um arquivo zillow_properties.json contendo os mesmos dados vistos anteriormente:
Como consultar um conjunto de dados do Bright Data através do conector Databricks SQL
O conector Databricks SQL é uma biblioteca Python que permite conectar-se a clusters Databricks e armazéns SQL. Em particular, ele fornece uma API simplificada para conectar-se à infraestrutura Databricks e explorar seus dados.
Nesta seção do guia, você aprenderá como usá-la para consultar o “Conjunto de dados de informações de propriedades da Zillow” da Bright Data.
Etapa 1: instale o conector SQL Databricks para Python
O conector SQL Databricks está disponível através da biblioteca Python databricks-sql-connector. Instale-o com:
pip install databricks-sql-connectorEm seguida, importe-o em seu script com:
from databricks import sqlEtapa 2: Comece a usar o Databricks SQL Connector
O Databricks SQL Connector requer credenciais diferentes em comparação com a API REST e a CLI. Especificamente, ele precisa de:
server_hostname: seu nome de host Databricks (sem a partehttps://).http_path: uma URL especial para se conectar ao seu armazém.access_token: seu token de acesso Databricks.
Você pode encontrar os valores de autenticação necessários, juntamente com um trecho de código inicial de exemplo, na guia “Detalhes da conexão” do seu armazém SQL:
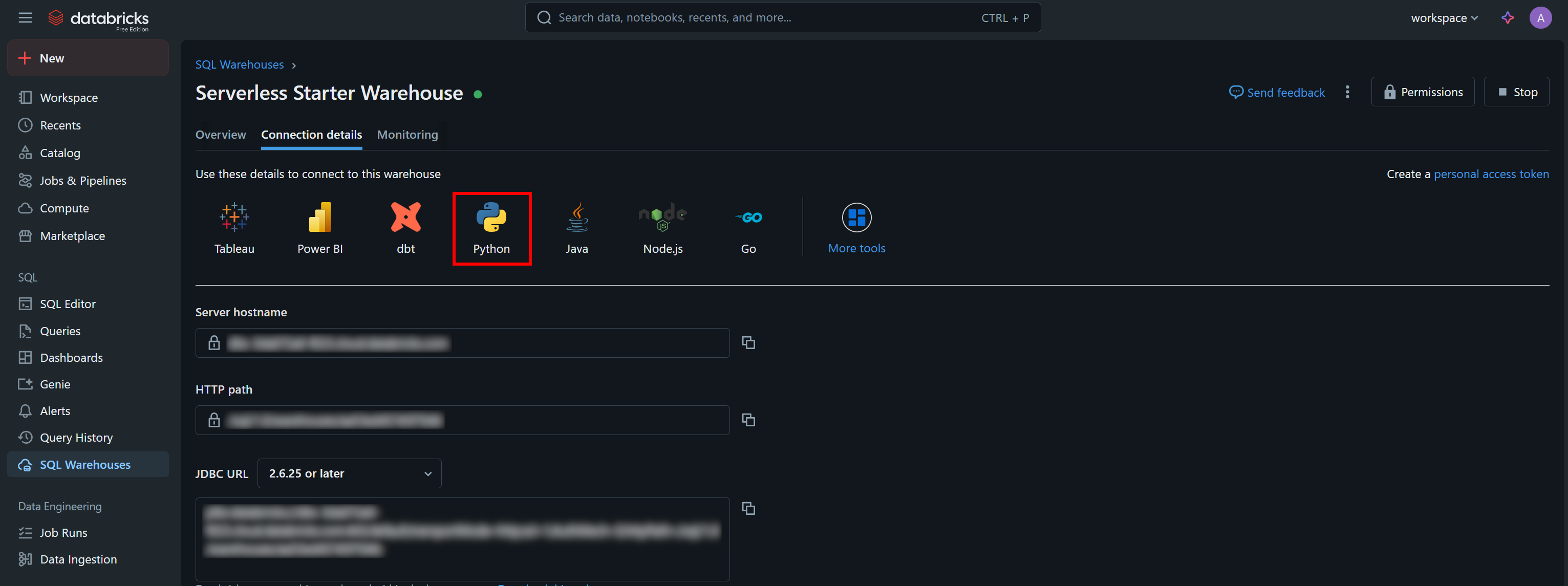
Pressione o botão “Python” e você obterá:
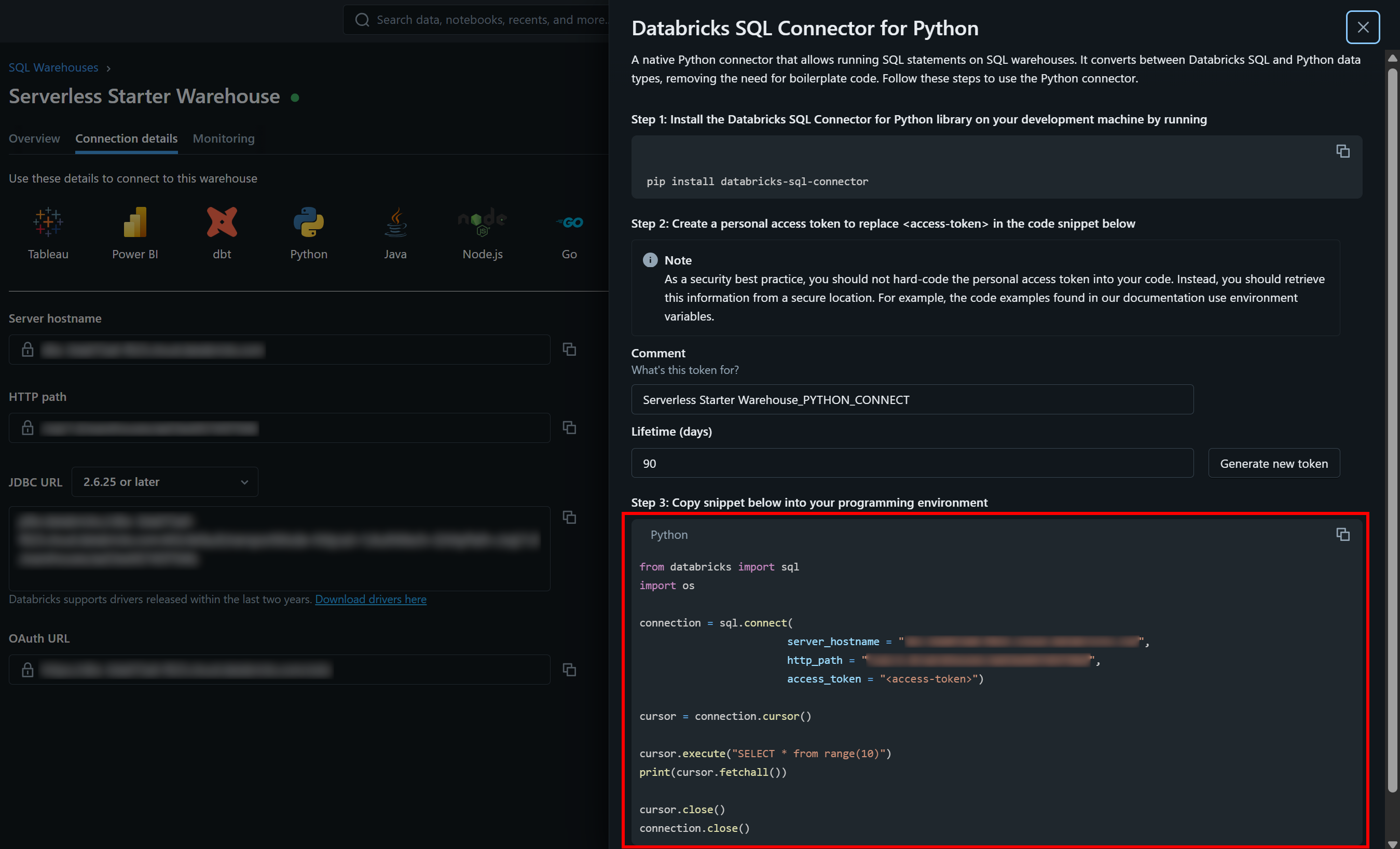
Estas são todas as instruções necessárias para começar a usar o databricks-sql-connector.
Etapa 3: Junte tudo
Adapte o código do trecho de código de exemplo na seção “Conector SQL do Databricks para Python” ao seu armazém para executar a consulta parametrizada de seu interesse. Você deve obter um script como o seguinte:
from databricks import sql
# Conecte-se ao seu armazenamento SQL no Databricks (substitua as credenciais pelos seus valores)
connection = sql.connect(
server_hostname = "<YOUR_DATABRICKS_HOST>",
http_path = "<YOUR_DATABRICKS_WAREHOUST_HTTP_PATH>",
access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
)
# Execute uma consulta parametrizada SQL e obtenha os resultados em um cursor
cursor = connection.cursor()
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.conjuntos de dados.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit
"""
params = {
"state": "NY",
"homestatus": "FOR_SALE",
"row_limit": 10
}
# Executar a consulta
cursor.execute(sql_query, params)
result = cursor.fetchall()
# Imprimir todos os resultados, uma linha por vez
for row in result[:2]:
print(row)
# Fechar o cursor e a conexão com o armazenamento SQL
cursor.close()
connection.close()Execute o script e ele gerará uma saída como esta:
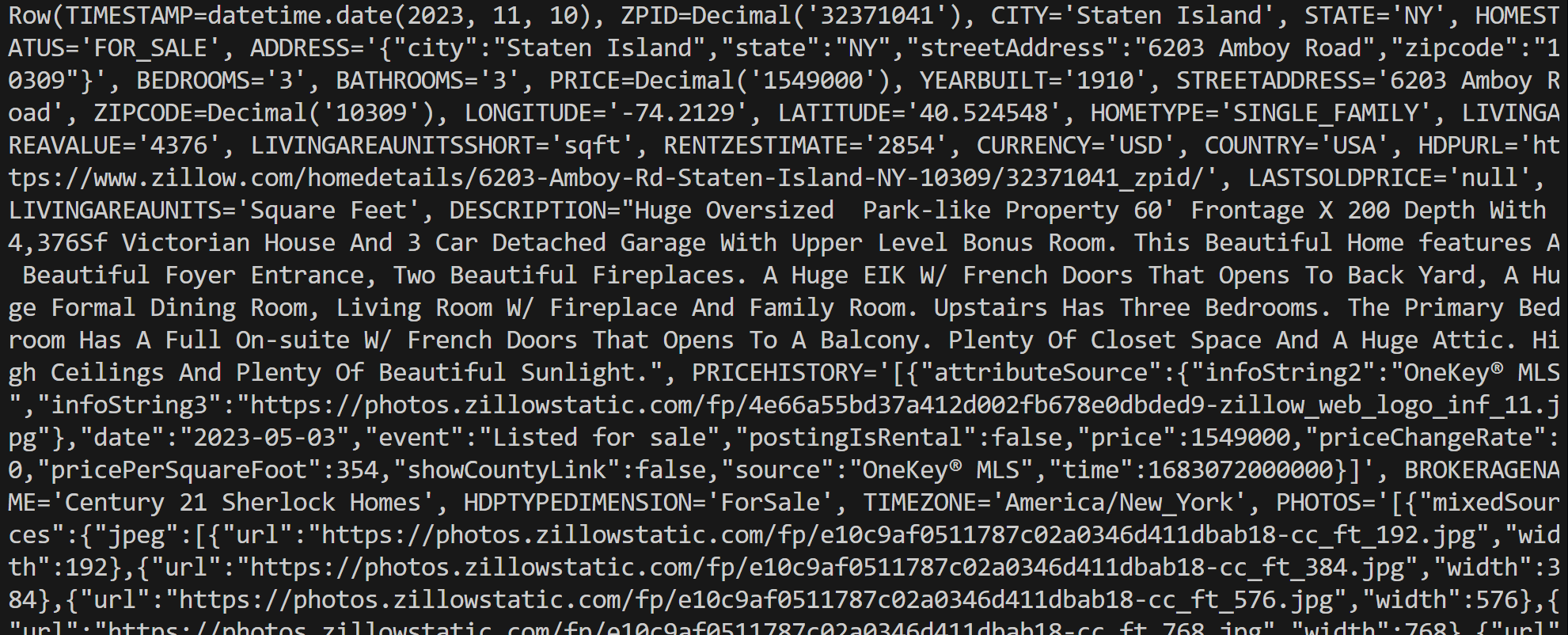
Observe que cada objeto de linha é uma instância Row, representando um único registro dos resultados da consulta. Você pode então processar esses dados diretamente em seu script Python.
Lembre-se de que você pode converter uma instância Row em um dicionário Python com o método asDict():
row_data = row.asDict()Et voilà! Agora você sabe como interagir e consultar seus Conjuntos de dados Bright Data no Databricks de várias maneiras.
Conclusão
Neste artigo, você aprendeu como consultar os Conjuntos de dados da Bright Data a partir do Databricks usando sua API REST, CLI ou biblioteca dedicada SQL Connector. Conforme demonstrado, o Databricks oferece várias maneiras de interagir com os produtos oferecidos por seus provedores de dados, que agora incluem a Bright Data.
Com mais de 40 produtos disponíveis, você pode explorar a extensa riqueza dos Conjuntos de dados da Bright Data diretamente no Databricks e acessar seus dados de várias maneiras.
Crie uma conta gratuita na Bright Data e comece a experimentar nossas soluções de dados hoje mesmo!




