

Neste post, você vai entender:
- O que são conjuntos de dados, os benefícios que oferecem, como funcionam, quando faz sentido usá-los e onde encontrar conjuntos de dados confiáveis e de alta qualidade.
- O que são APIs de scraping de dados, as vantagens que envolvem, como funcionam, quando recorrer a elas e onde encontrar opções escaláveis.
- Como usar ambos em cenários semelhantes por meio de exemplos guiados.
- Como conjuntos de dados e APIs de scraping de dados se comparam e qual é melhor dependendo das suas necessidades.
- Se faz sentido usá-los juntos.
Vamos começar!
Explorando o Mundo dos Conjuntos de Dados
Começaremos este guia sobre conjuntos de dados vs APIs de scraping de dados com uma introdução aos conjuntos de dados.
O Que É um Conjunto de Dados?
Um conjunto de dados é uma coleção estruturada de informações organizadas para facilitar a análise, o processamento e a reutilização. Geralmente são armazenados em formatos como CSV, JSON ou SQL, e podem incluir textos, números, imagens, vídeos e outros tipos de dados.
A maioria dos conjuntos de dados se concentra em um tópico, setor, mercado ou área de interesse específico, como B2B, varejo e outros. Esse foco mais restrito ajuda empresas e pesquisadores a extrair insights, identificar tendências e apoiar a tomada de decisões baseada em dados.
Os conjuntos de dados são geralmente considerados instantâneos estáticos de dados coletados em um momento específico. No entanto, a maioria dos melhores provedores de conjuntos de dados oferece serviços para receber registros atualizados periodicamente, buscando informações atualizadas nas fontes de dados subjacentes.
Especificamente, os três principais benefícios proporcionados pelos conjuntos de dados são:
- Prontos para uso: Dados pré-coletados e estruturados, imediatamente utilizáveis para análise, IA ou aplicações de negócios. Nenhum conhecimento técnico é necessário.
- Eficiência de custo: Reduz a necessidade de recursos internos de coleta de dados e engenharia.
- Escalabilidade: Fornece acesso a grandes conjuntos de dados cobrindo milhões ou bilhões de registros em diversos setores.
Como os Conjuntos de Dados Funcionam
A maioria dos conjuntos de dados modernos tem origem na web, que é a maior e mais atualizada fonte de informações públicas do planeta. Afinal, novos dados são gerados continuamente em sites, marketplaces e plataformas de mídia social.
O processo de criação de conjuntos de dados envolve as seguintes etapas:
- Coleta de dados: As informações são coletadas de uma ou mais fontes, mais comumente de sites por meio de scraping de dados, APIs ou feeds públicos. Dependendo do caso de uso, isso pode incluir listagens de produtos, preços, avaliações, vagas de emprego, conteúdo de mídia social ou dados de empresas.
- Limpeza e validação de dados: Os dados brutos frequentemente são desorganizados, incompletos ou duplicados. Nesta etapa, os erros são removidos, os formatos são padronizados e os valores ausentes são tratados. Os dados são validados para garantir precisão e consistência.
- Estruturação de dados: Os dados limpos são organizados em um formato consistente como CSV, JSON ou Parquet. Isso facilita o armazenamento em bancos de dados ou data warehouses para consultas e o uso em análise de dados ou fluxos de trabalho de IA.
Embora essas etapas possam tecnicamente ser realizadas internamente, elas geralmente são delegadas a um provedor de conjuntos de dados. Isso ocorre porque coletar e processar dados em larga escala requer ferramentas e expertise especializados. Lembre-se de que alguns conjuntos de dados podem incluir vários bilhões de registros.
Uma vez processados, os provedores de conjuntos de dados distribuem os dados por meio de diferentes métodos de entrega. Esses incluem downloads diretos para conjuntos de dados menores, integrações com S3 e acesso via API.
Nota: Nem todos os conjuntos de dados vêm da web. Alguns são criados por meio de pesquisas, estudos de pesquisa, sensores, sistemas internos de empresas ou pela combinação de múltiplas fontes. Por exemplo, podem combinar dados públicos abertos com informações proprietárias ou coletadas de forma privada.
Casos de Uso
Abaixo estão alguns dos cenários mais relevantes para conjuntos de dados em empresas, pequenos negócios, indivíduos e no setor público:
- Treinamento de modelos de IA: Os conjuntos de dados estão no cerne dos processos de treinamento de machine learning e IA. Ao alimentar modelos com grandes volumes de dados de alta qualidade, eles aprendem padrões e desenvolvem capacidades como compreensão de linguagem, reconhecimento de imagens, recomendações e previsões.
- Análise de tendências de mercado: Analise dados históricos de mercado para estudar tendências do setor e entender o comportamento do cliente. Valide ideias de produtos e apoie decisões estratégicas com base em dados externos do mundo real, em vez de suposições.
- Análise de mídia social: Extraia insights sobre comportamento do usuário, engajamento e sentimento. Monitore marcas, analise públicos, identifique influenciadores e avalie o desempenho de conteúdo em plataformas como Reddit, Facebook e outras.
- Inteligência de negócios e tomada de decisão: Estude preços, concorrentes e sinais de mercado para descobrir oportunidades, otimizar a alocação de recursos e melhorar a tomada de decisões estratégicas.
- Recrutamento e inteligência de talentos: Analise dados do mercado de trabalho para encontrar candidatos, entender tendências de contratação, avaliar a demanda por habilidades e mapear estruturas de força de trabalho de concorrentes para melhorar estratégias de recrutamento.
- Desenvolvimento de produtos e otimização da experiência do usuário: Analise avaliações de usuários, feedbacks e dados comportamentais para melhorar produtos. Refine funcionalidades, personalize experiências e otimize jornadas do usuário para aumentar a satisfação e a retenção.
Onde Obter Conjuntos de Dados Atualizados, Estruturados e Prontos para IA
Entre os principais marketplaces de conjuntos de dados, a Bright Data ocupa o primeiro lugar, pois combina uma infraestrutura
de dados web em larga escala com conjuntos de dados prontos para uso e de nível empresarial.
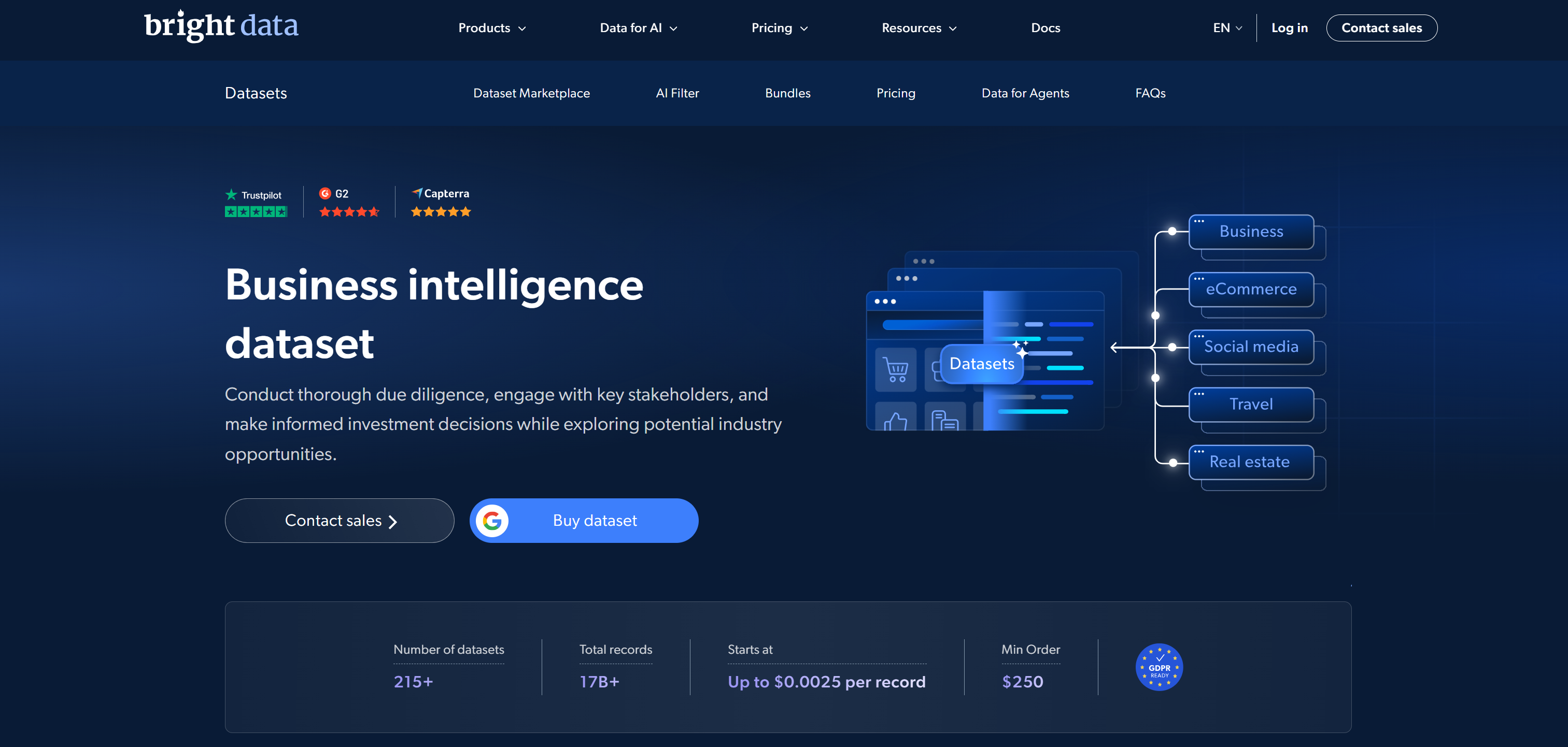
Seu marketplace de conjuntos de dados oferece conjuntos de dados pré-coletados de mais de 350 domínios web, totalizando mais de 17 bilhões de registros. Estes cobrem e-commerce, mídia social, imóveis, finanças, redes profissionais e muitos outros setores. Os conjuntos de dados são limpos, estruturados, padronizados e otimizados para IA e ML. São entregues em formatos como JSON, CSV, Parquet e NDJSON.
Os conjuntos de dados da Bright Data também podem ser personalizados para atender a objetivos altamente específicos, filtrando-os por múltiplas dimensões, incluindo critérios aplicados a campos de dados. Uma camada adicional de filtragem com IA permite que os usuários refinem grandes conjuntos de dados usando consultas em linguagem natural, tornando a seleção de dados mais acessível.
Os dados são entregues por múltiplos canais, incluindo acesso via API, Amazon S3, Snowflake, webhooks, integrações de armazenamento em nuvem e downloads diretos. Essa flexibilidade o torna adequado tanto para casos de uso leves quanto para pipelines em escala empresarial.
Os conjuntos de dados da Bright Data aderem aos padrões de conformidade com GDPR e CCPA. Também são suportados por processos de validação, segurança e controle de qualidade que garantem a confiabilidade e a obtenção ética de dados publicamente disponíveis.
Os preços começam em $250 por conjunto de dados (100K registros), dependendo do volume e da frequência de atualização (mensal, trimestral ou semestral).
Uma Visão Geral das APIs de Scraping de Dados
Agora que você sabe o que são conjuntos de dados e quando usá-los, está pronto para explorar os mesmos aspectos das APIs de scraping de dados.
O Que É uma API de Scraping de Dados?
Uma API de scraping de dados é um serviço que permite extrair dados de sites sem gerenciar sua própria infraestrutura de scraping. Ela lida com tarefas como recuperar páginas web de destino, contornar proteções anti-scraping e anti-bot, e fazer o parsing dos resultados em formatos estruturados.
As APIs de scraping de dados tendem a ter como alvo sites ou fontes de dados específicos, como plataformas de e-commerce, mecanismos de busca ou sites de mídia social. Algumas são mais genéricas ou podem ser estendidas via IA para retornar dados estruturados de qualquer site. Isso permite que empresas e desenvolvedores busquem dados ao vivo ou sob demanda de fontes online relevantes.
Em particular, as três principais vantagens das APIs de scraping de dados são:
- Acesso a dados em tempo real: Recupere informações atualizadas diretamente de sites quando necessário.
- Sem gerenciamento de infraestrutura: Não é necessário construir e manter scrapers, proxies e sistemas anti-bot.
- Escalabilidade: Colete dados de centenas ou milhares de páginas de forma confiável e eficiente.
Como as APIs de Scraping de Dados Funcionam
Internamente, uma API de scraping de dados funciona assim:
- Tratamento de solicitações: Um usuário envia uma solicitação à API especificando a URL da página web de destino, com possíveis argumentos para personalizar o comportamento de scraping subjacente (por exemplo, renderização de JavaScript, localização do IP, etc.).
- Recuperação de página e gerenciamento de acesso: A API busca as páginas web de destino enquanto cuida de desafios técnicos como renderização de JavaScript, proxies, limites de taxa, CAPTCHAs e outras proteções anti-bot.
- Extração de dados e parsing: O HTML bruto ou o conteúdo da resposta é processado e transformado em formatos estruturados (por exemplo, JSON, CSV e outros). Algumas APIs usam templates predefinidos, enquanto outras dependem de IA para extrair dinamicamente campos estruturados de qualquer página web.
- Entrega de dados: Os dados estruturados finais são retornados ao usuário via resposta da API. Opcionalmente, também podem ser enviados para sistemas de armazenamento como S3, webhooks ou bancos de dados para processamento posterior.
Casos de Uso
Aqui estão os cenários mais importantes onde as APIs de scraping de dados fazem a diferença:
- Pesquisa de mercado e rastreamento competitivo: Monitore sites de concorrentes, mudanças de preços e disponibilidade de produtos. Identifique tendências à medida que surgem e adapte estratégias de negócios com base em sinais de mercado em constante evolução.
- Tomada de decisão financeira: Extraia dados de mercado ao vivo como preços de ações, movimentos de criptomoedas e atualizações de empresas. Apoie estratégias de negociação, análise de investimentos e gestão de riscos com base em atualizações em streaming.
- Monitoramento de e-commerce e otimização de preços: Rastreie listagens de produtos, níveis de estoque e flutuações de preços em múltiplas plataformas. Habilite precificação dinâmica, descoberta de ofertas e otimização de catálogos usando dados web atualizados com frequência.
- Monitoramento de notícias e eventos: Colete notícias de última hora, atualizações regulatórias e anúncios do setor de múltiplas fontes. Melhore a consciência situacional e apoie respostas mais rápidas a mudanças de mercado ou de políticas.
- Geração de leads e inteligência de vendas: Extraia dados de negócios e contatos atualizados de diretórios, sites de empresas e plataformas profissionais. Identifique novos prospects e enriqueça pipelines de vendas com informações constantemente atualizadas.
- Monitoramento de marca e rastreamento de reputação: Observe menções em chatbots de IA e mecanismos de busca. Rastreie sentimentos de avaliações e discussões em fóruns, mídias sociais e sites de notícias. Detecte mudanças de sentimento precocemente e responda prontamente a riscos ou oportunidades reputacionais.
- Fundamentação de agentes de IA e acesso à web: Equipe agentes de IA com acesso direto a APIs de scraping de dados para recuperar dados externos contextuais e atualizados sob demanda. Isso permite raciocínio fundamentado, reduz alucinações e permite que os agentes atuem com base nas informações mais recentes disponíveis online.
APIs de Scraping de Dados: Qual É o Melhor Provedor?
A Bright Data se destaca como o melhor provedor de APIs de scraping de dados. Ela combina redes de proxies em larga escala com um ecossistema abrangente de API Web Scraper construído para extração de dados confiável, compatível e escalável.
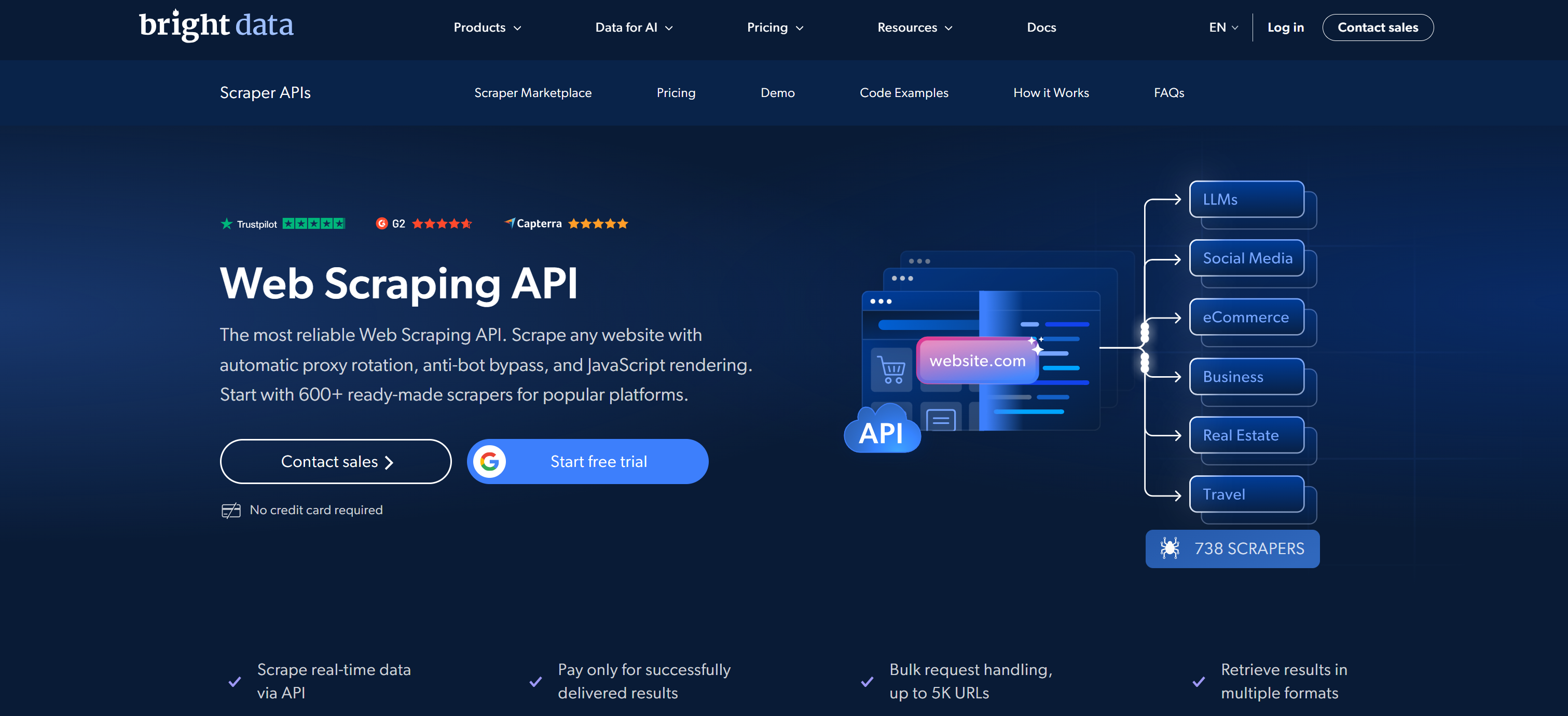
Sua biblioteca de Web Scraper API suporta mais de 600 scrapers prontos cobrindo as principais fontes de dados. Estes incluem Amazon, LinkedIn, X/Twitter, Instagram, TikTok, YouTube, Walmart, Zillow, Indeed, Glassdoor, Booking, Airbnb, Yelp, Yahoo Finance, Facebook e muitos mais. Essas APIs de scraping permitem a extração direta de dados estruturados e específicos de domínio em JSON, NDJSON ou CSV.
O que diferencia a Bright Data é sua rede global subjacente de mais de 400 milhões de IPs residenciais em 195 países. Isso permite uma arquitetura em larga escala e pronta para empresas com uptime de 99,99% garantido por SLA e uma taxa de sucesso de solicitações de 99,95%.
A Web Scraper API da Bright Data gerencia todo o ciclo de vida do scraping automaticamente, incluindo rotação de proxy, resolução de CAPTCHA, renderização de JavaScript, limitação de taxa e bypass de anti-bot. Também suportam solicitações em lote (até 5K URLs por trabalho), scraping programado e pipelines de entrega flexíveis.
O preço é baseado no uso e você paga apenas por solicitações bem-sucedidas. O modelo de pagamento por uso começa em $1,5 por 1K registros, com vários planos baseados em assinatura disponíveis para empresas e corporações.
Conjuntos de Dados e APIs de Scraping de Dados em um Cenário do Mundo Real
Para entender como recuperar dados usando conjuntos de dados ou APIs de scraping de dados, considere o mesmo caso de uso de alto nível. Você deseja extrair dados de empresas do Crunchbase, em um caso para prospecção de clientes e no outro para análise de empresas ao vivo com IA.
O primeiro caso de uso requer um conjunto de dados do Crunchbase, enquanto o segundo requer uma API de scraping de dados do Crunchbase. Nos próximos dois capítulos, você verá como acessar ambos os tipos de dados usando as soluções da Bright Data.
Nota: O pré-requisito para as seções guiadas abaixo é que você já tenha uma conta na Bright Data. Caso contrário, crie uma nova conta.
Comece com os Conjuntos de Dados da Bright Data
Nesta seção passo a passo, você verá como recuperar um conjunto de dados do Crunchbase pronto para uso da Bright Data.
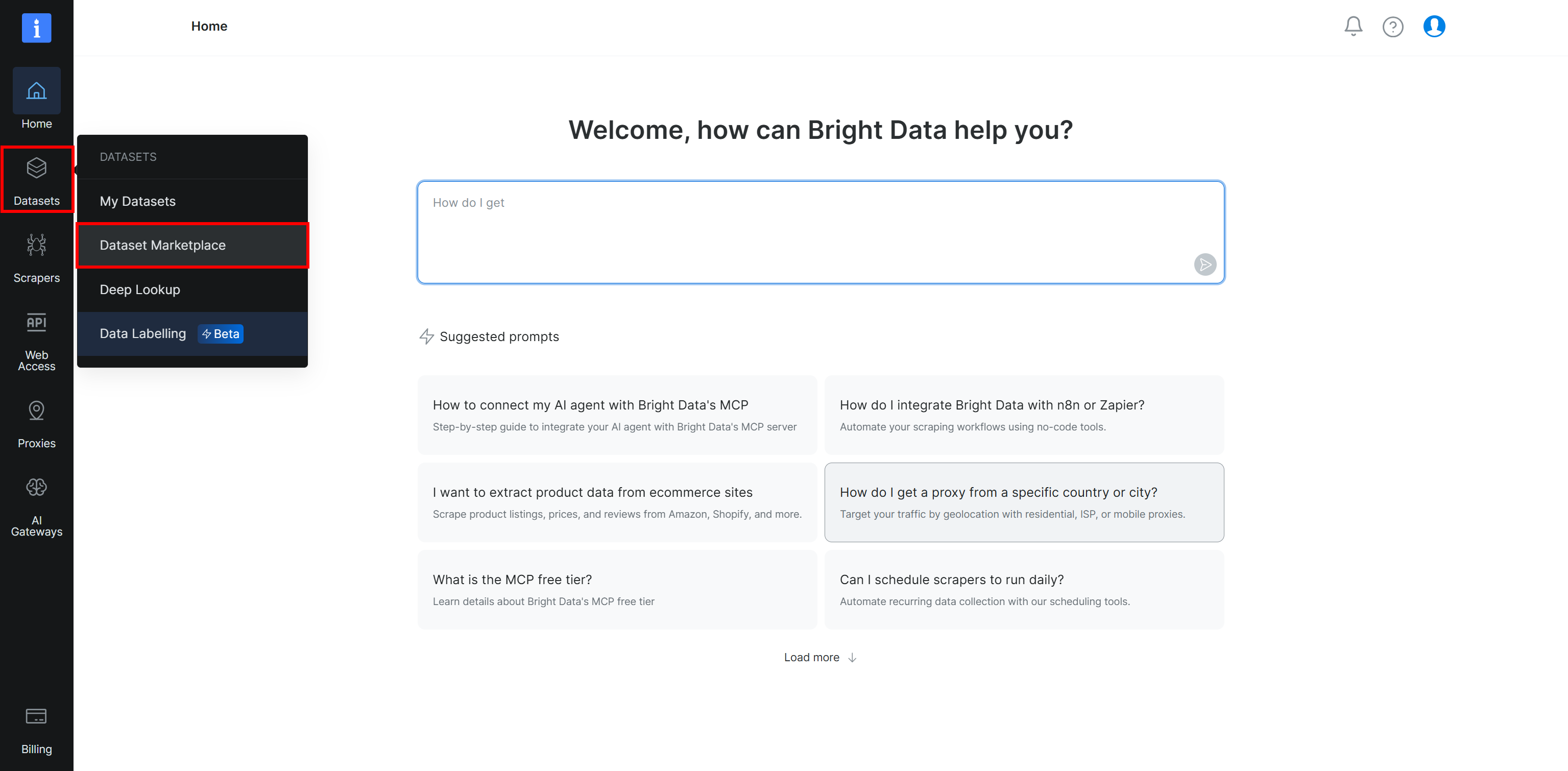
Passo #1: Acesse o Conjunto de Dados do Crunchbase
Comece fazendo login na sua conta da Bright Data. No painel de controle, selecione a opção “Dataset Marketplace” no menu “Datasets”.
Na página “My datasets”, navegue até a aba “Dataset Marketplace” e você chegará a esta página:
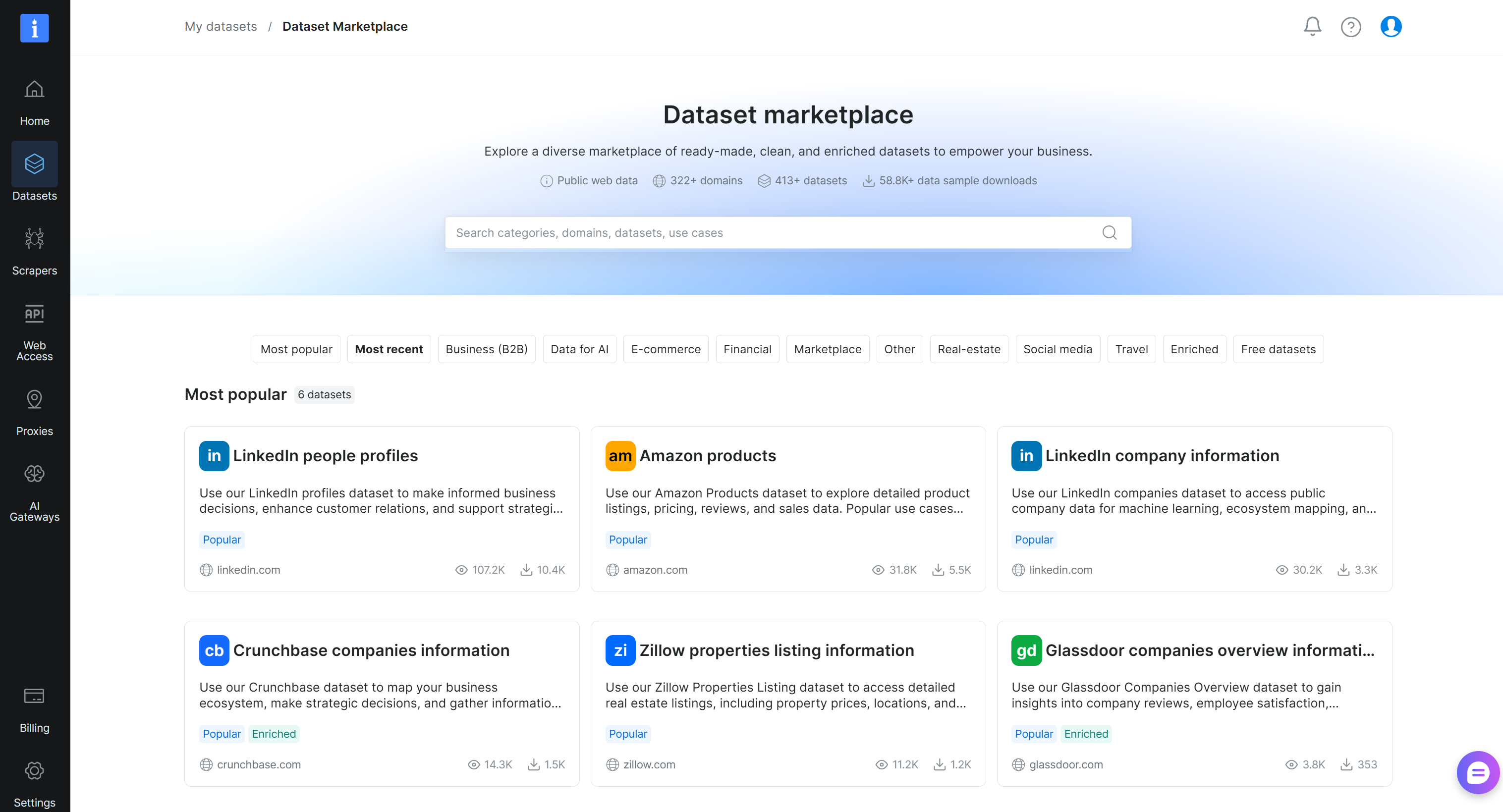
Pesquise por “crunchbase” e selecione o conjunto de dados “Crunchbase companies information”:
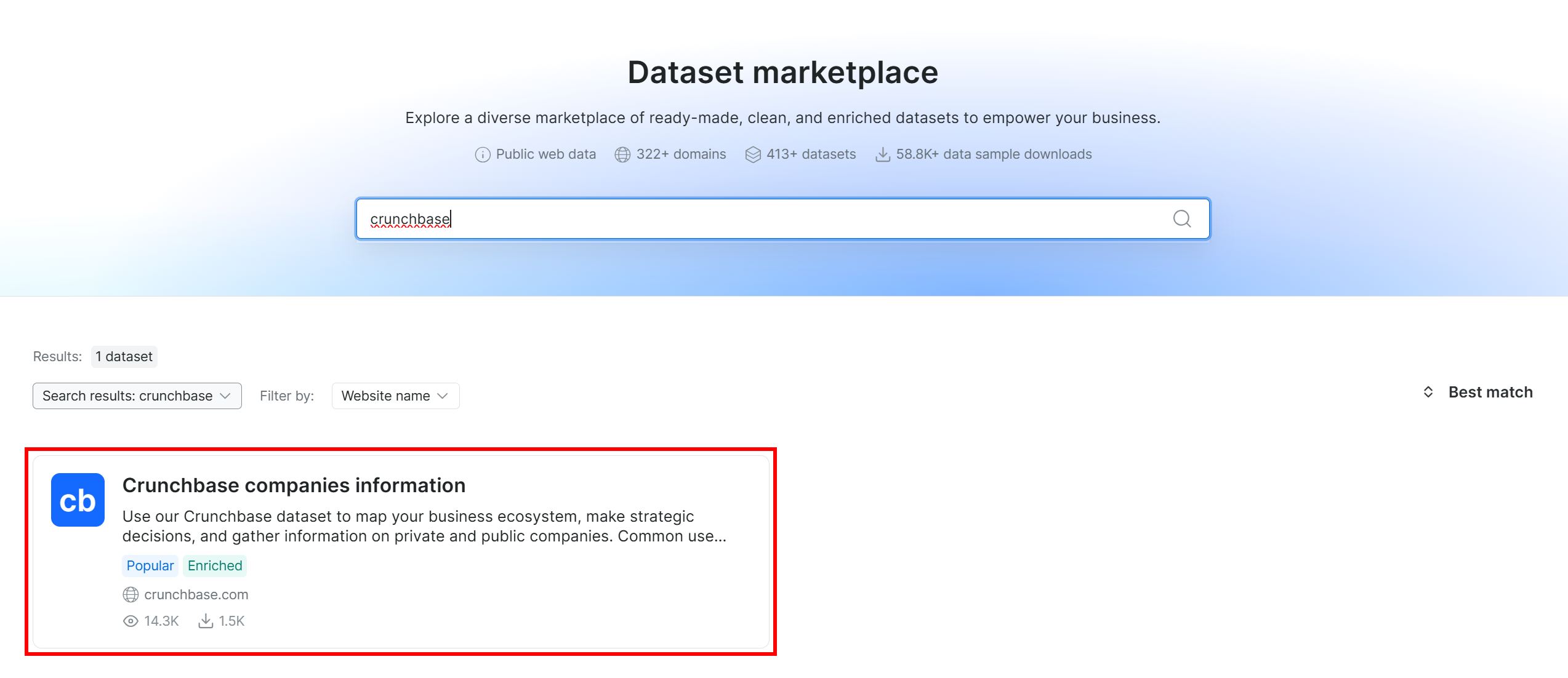
Você será então levado à página do conjunto de dados “Crunchbase companies information”. Ótimo!
Passo #2: Conheça o Conjunto de Dados
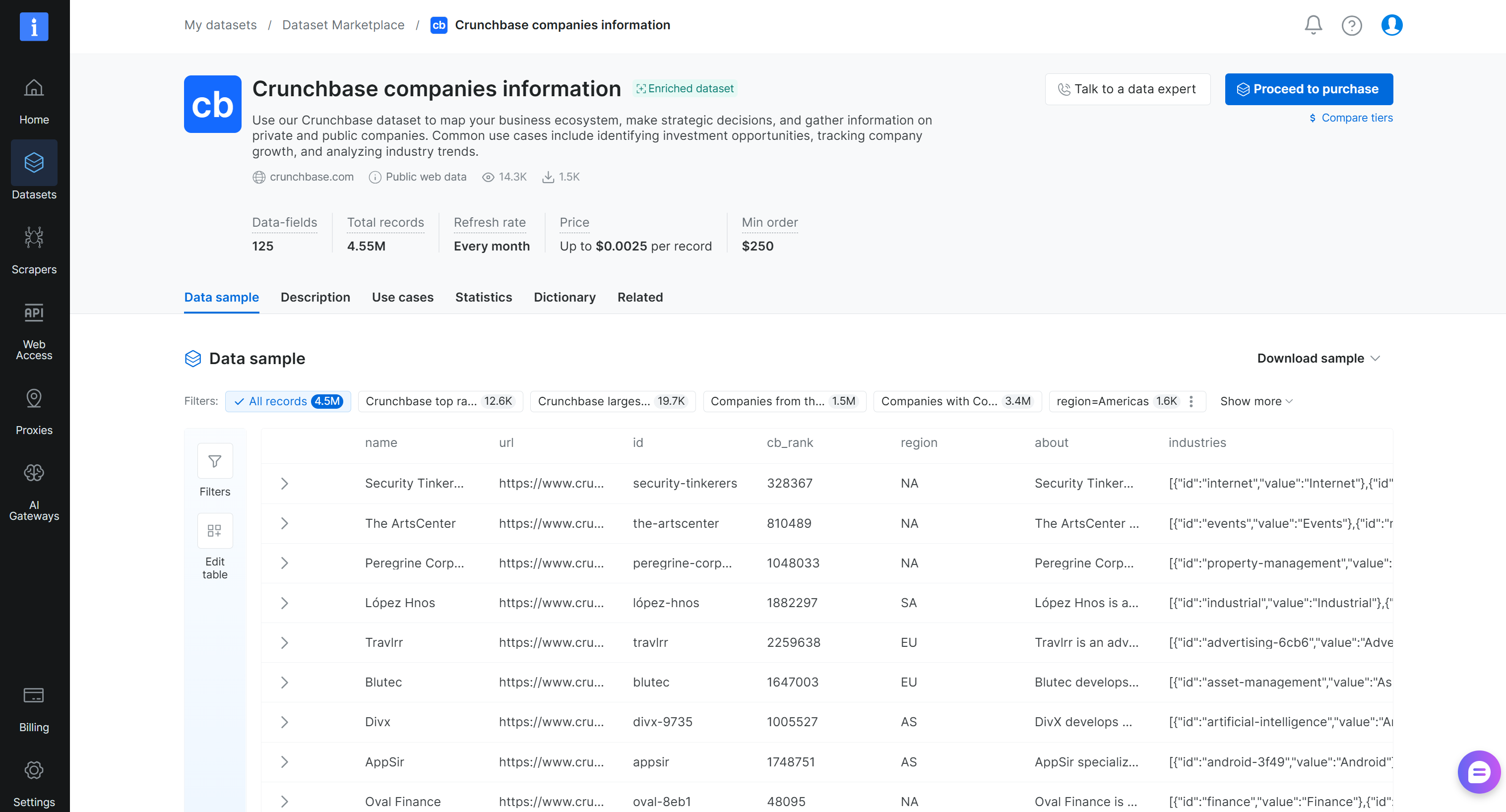
Na página do conjunto de dados “Crunchbase companies information”, você pode explorar o conjunto de dados. Em detalhes, pode acessar registros de amostra, navegar por subconjuntos prontos (por exemplo, as empresas do Crunchbase mais bem classificadas) e revisar estatísticas-chave como taxas de preenchimento de campos. Você também pode visualizar o dicionário de dados completo, incluindo nomes de campos, tipos e descrições, e aplicar filtros para refinar o conjunto de dados.
Se você clicar no botão “Filters” à esquerda, o seguinte modal será aberto:
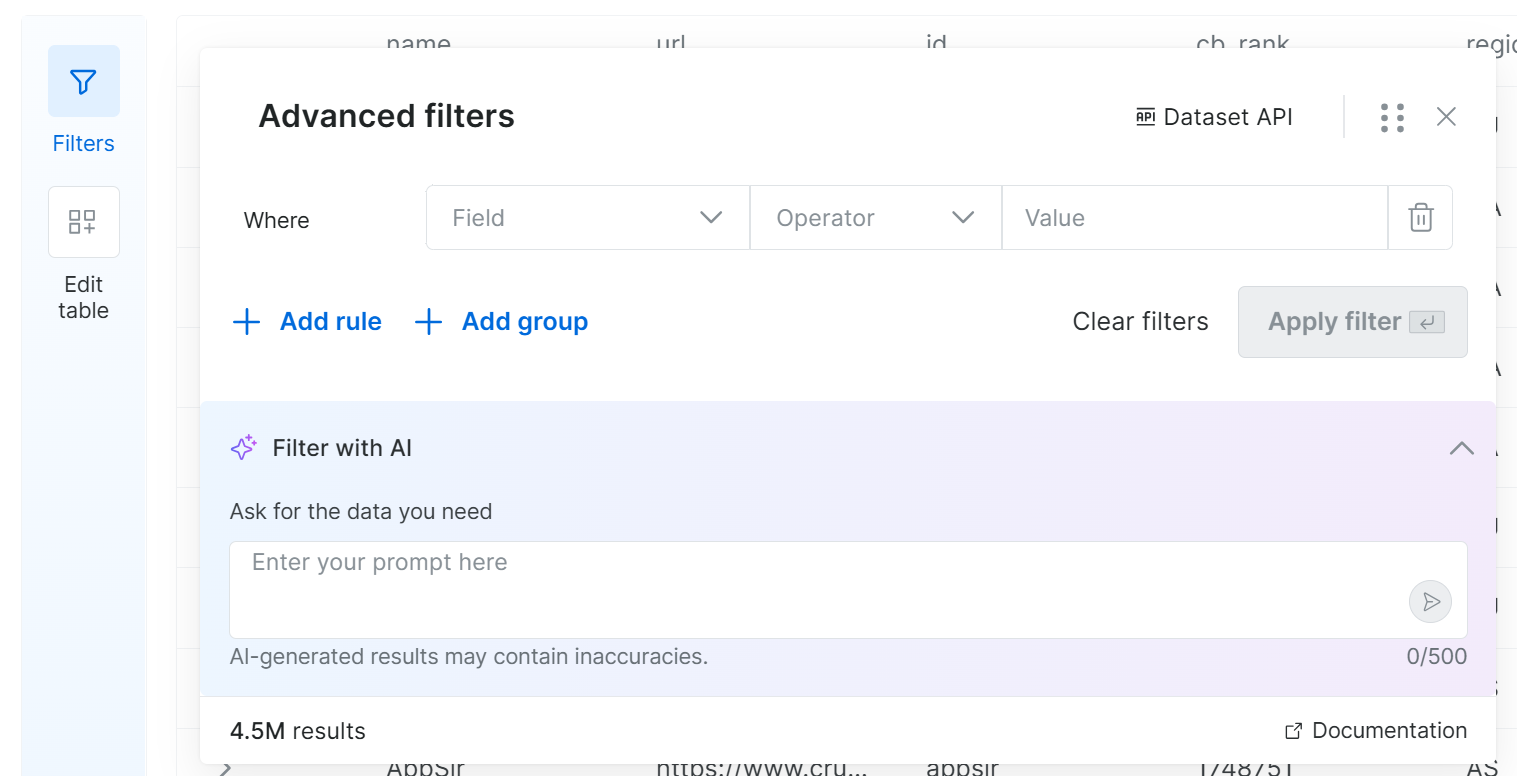
Graças a este recurso, você pode definir filtros configurando um ou mais critérios em campos selecionados. Ou simplesmente escreva um prompt em linguagem natural e deixe o sistema gerar os filtros para você. Incrível!
Passo #3: Compre o Conjunto de Dados
Após filtrar os dados para seu caso de uso específico (ou deixá-los como estão), pressione o botão “Proceed to purchase”:

Em seguida, defina o tamanho do snapshot do conjunto de dados e selecione a frequência de atualização:
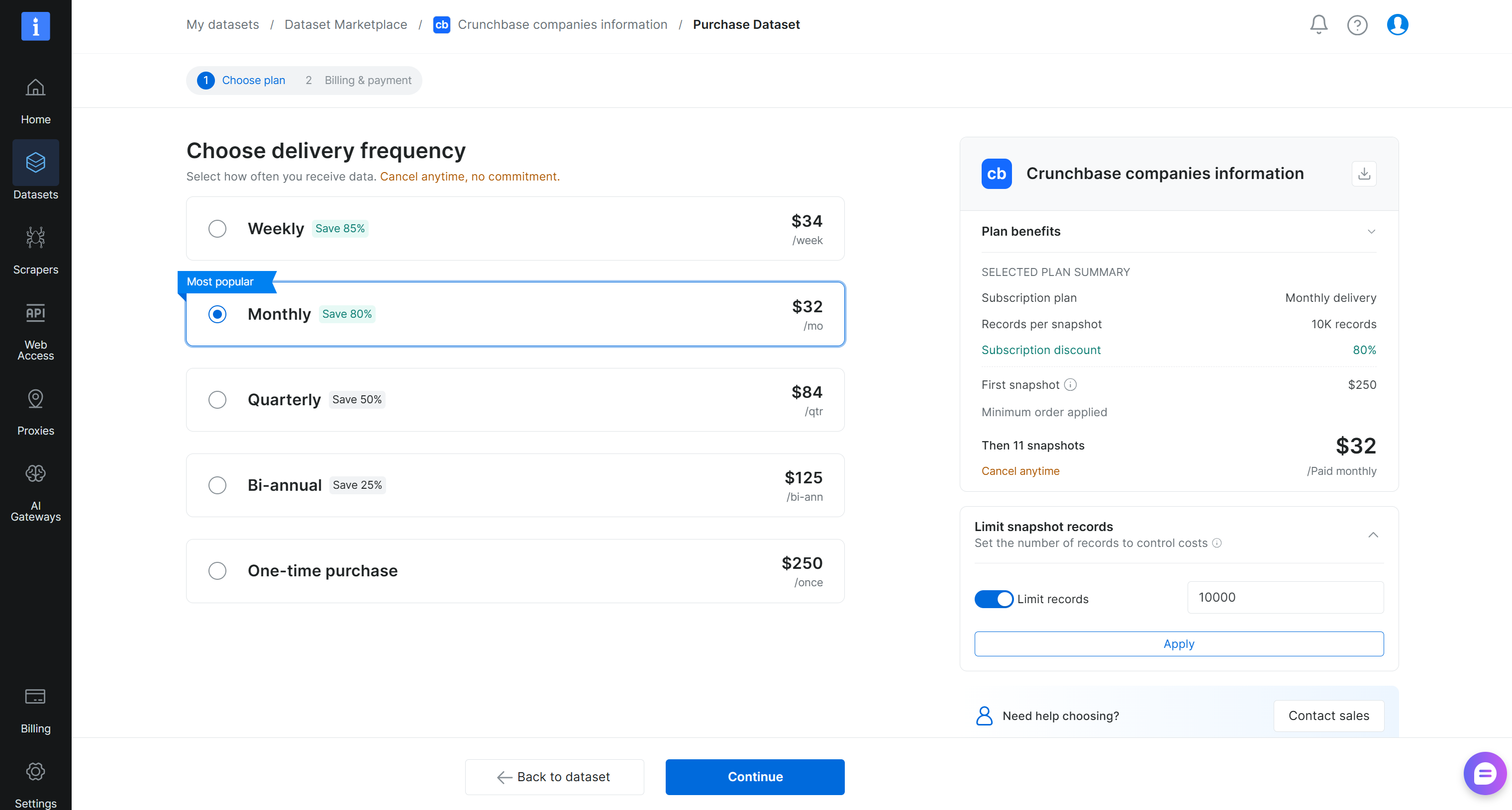
Neste exemplo, configuramos a entrega para incluir 10.000 registros imediatamente, seguidos de 11 atualizações mensais contínuas. Clique em “Continue” e conclua o processo de checkout adicionando seus dados de pagamento. Ótimo!
Passo #4: Explore o Conjunto de Dados Recebido
Quando o conjunto de dados estiver pronto, você receberá uma notificação por e-mail e poderá baixá-lo do painel de controle da Bright Data. De lá, você pode definir em qual formato baixar o conjunto de dados e configurar seu método de entrega preferido (download de arquivo, S3, etc.).
No caso de entrega em arquivo simples no formato CSV, você receberá um arquivo como este:
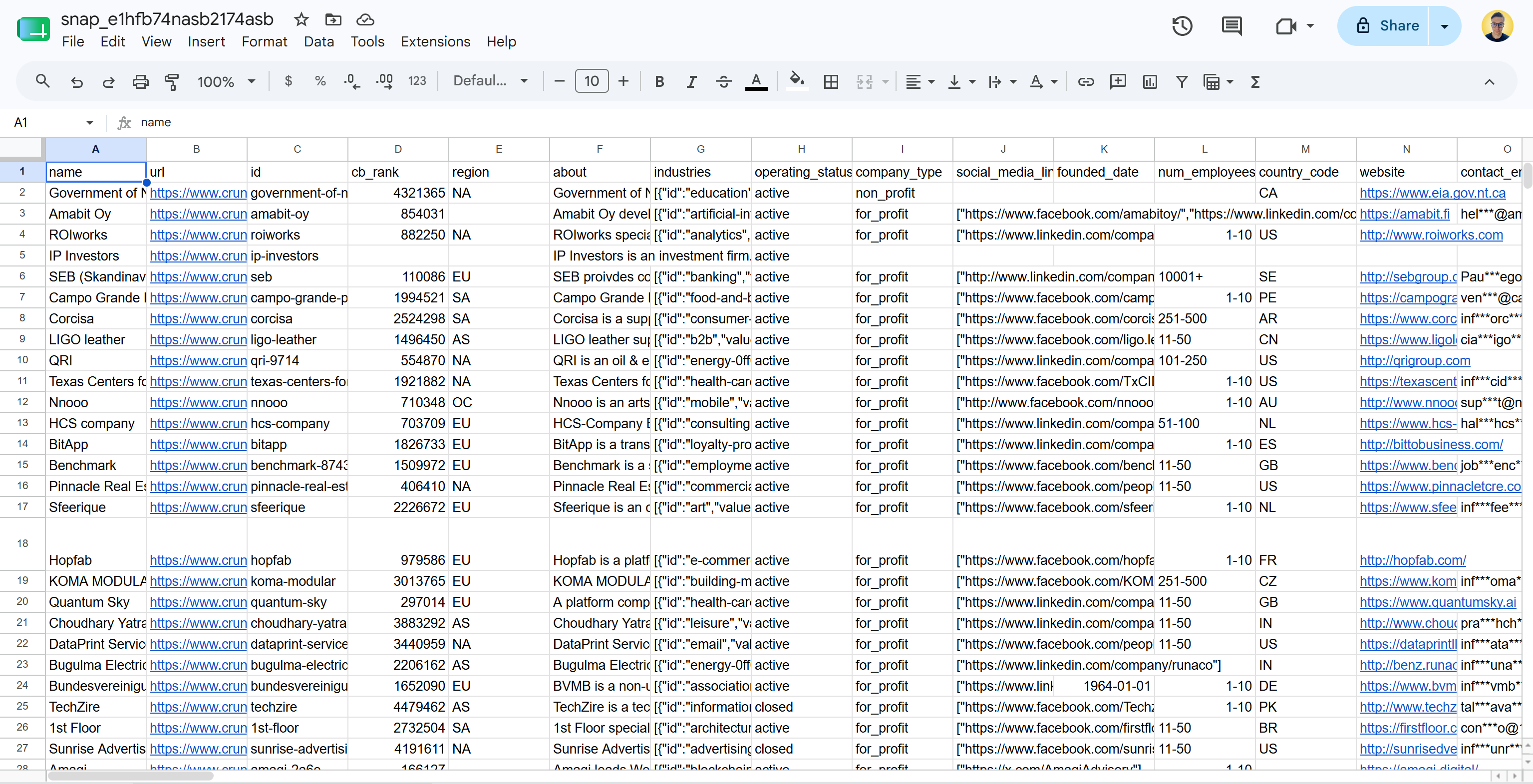
Observe que isso inclui dados reais do Crunchbase, prontos para análise, em um formato estruturado. Missão cumprida!
Próximos Passos
Com o conjunto de dados pronto, ingira-o em seu data warehouse ou banco de dados para consultas simplificadas. Você também pode integrá-lo aos seus pipelines de análise e processamento de dados.
Por exemplo, você poderia:
- Usá-lo para fazer fine-tuning de um modelo de IA.
- Alimentá-lo em um sistema de IA para análise, detecção de tendências ou previsões.
- Integrá-lo em dashboards de BI para relatórios e monitoramento.
- Combiná-lo com outros conjuntos de dados para enriquecer seus dados internos.
Essas são apenas algumas ideias para transformar dados brutos em insights acionáveis para seu caso de uso específico.
Colete Dados Frescos e Estruturados via APIs de Scraping de Dados da Bright Data
Aqui, você aprenderá como começar com as APIs de Scraping de Dados. Você verá como recuperar dados estruturados e atualizados do Crunchbase usando a API Scraper do Crunchbase da Bright Data.
Nota: O pré-requisito para esta seção é que você já tenha uma chave de API da Bright Data configurada. Se não for o caso, siga o guia oficial para gerar sua chave de API da Bright Data.
Passo #1: Acesse a API Web Scraper do Crunchbase
Comece fazendo login na sua conta da Bright Data. Em seguida, selecione a página “Scrapers Library” no menu:
Você chegará à página “Scrapers Library”, onde pode explorar todas as APIs Web Scraper da Bright Data disponíveis:
Pesquise por “crunchbase.com” e selecione o scraper “crunchbase.com”:
Você chegará então à página “crunchbase.com Scraper API” no painel de controle. Excelente!
Passo #2: Entenda as Opções da API Scraper
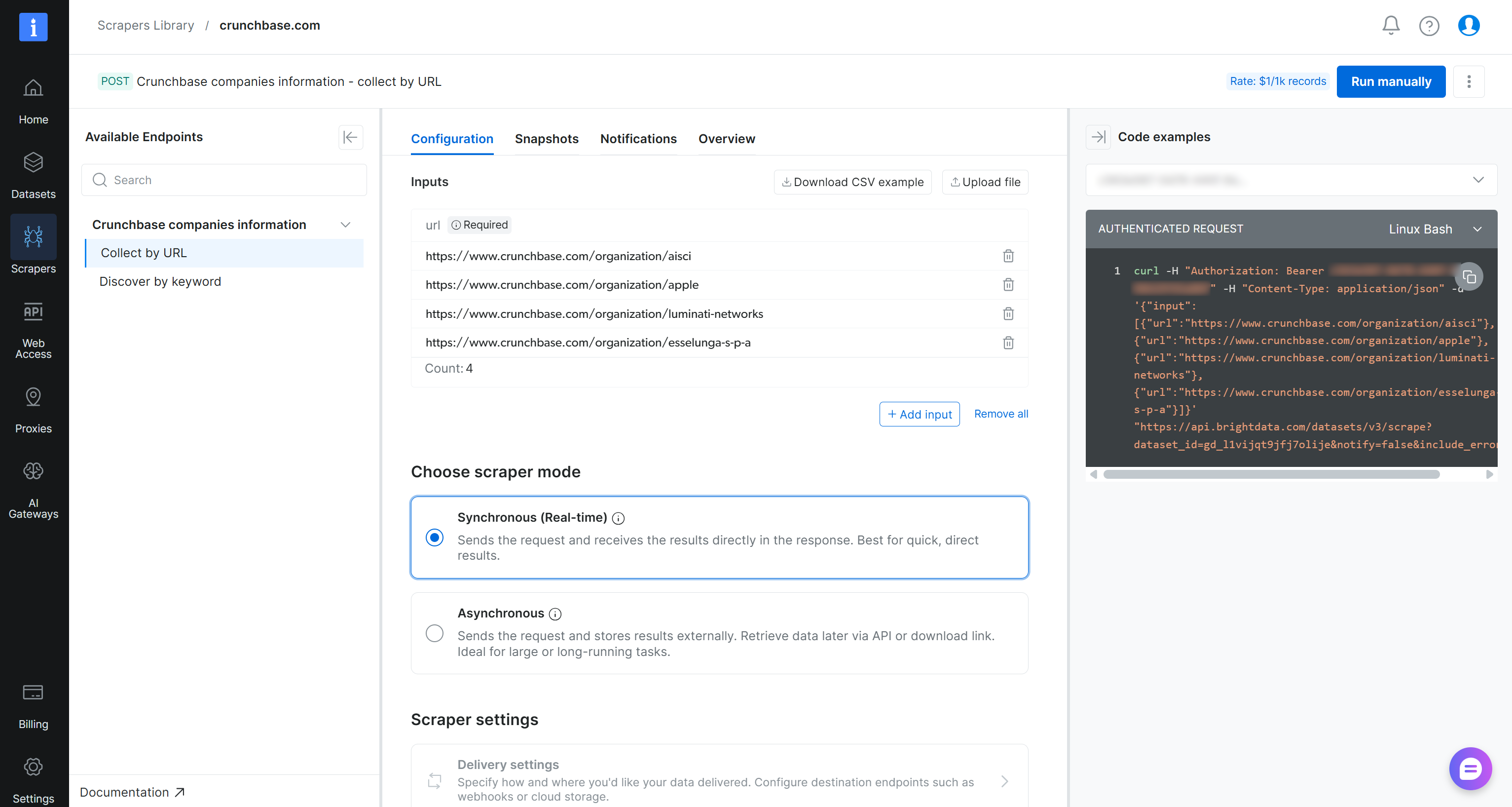
Na página da API Scraper “crunchbase.com”, você pode acessar todos os endpoints de scraping disponíveis no painel esquerdo. Para cada endpoint, você pode configurar uma chamada de API adicionando as URLs de destino. Você também pode escolher o modo de scraping (síncrono ou assíncrono) e configurar opções de entrega de dados.
Importante: Execute a API diretamente clicando no botão “Run manually”. Uma vez pronto, você poderá acessar os dados extraídos na aba “Snapshots”. Este fluxo de trabalho torna a API acessível a usuários não técnicos.
Ótimo! É hora de configurar uma chamada de API específica para obter dados frescos do Crunchbase.
Passo #3: Configure a Chamada de API
No lado direito da página, você pode acessar snippets de código predefinidos para chamar a API de Scraping de Dados. Estes são automaticamente configurados com sua chave de API da Bright Data.
Por exemplo, se você quiser recuperar dados da empresa Anthropic no Crunchbase usando Python, cole a URL de destino na seção Inputs (ou seja, https://www.crunchbase.com/organization/anthropic). Escolha o modo “Synchronous (Real-time)”, e então selecione o snippet “Python (requests)” nas opções disponíveis:
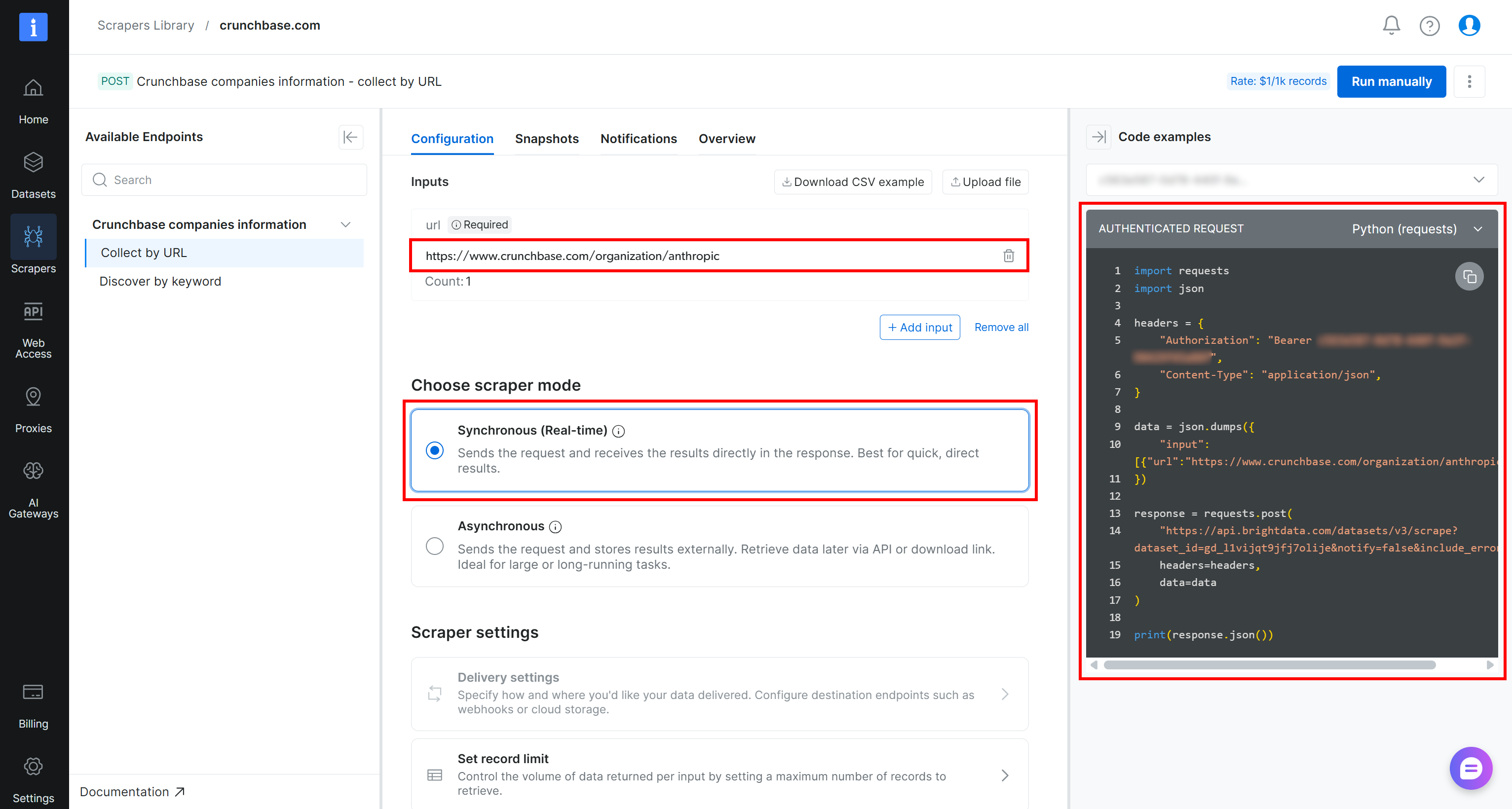
Este é o script que você receberá:
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://www.crunchbase.com/organization/anthropic"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_l1vijqt9jfj7olije¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())Hora de executá-lo para obter os resultados!
Passo #4: Explore os Resultados
Salve o snippet do painel de controle da Bright Data localmente em um arquivo como script.py.
Supondo que você tenha o Python instalado localmente, instale a dependência necessária:
pip install requestsEm seguida, execute o script com:
python script.pyO resultado será parecido com este:
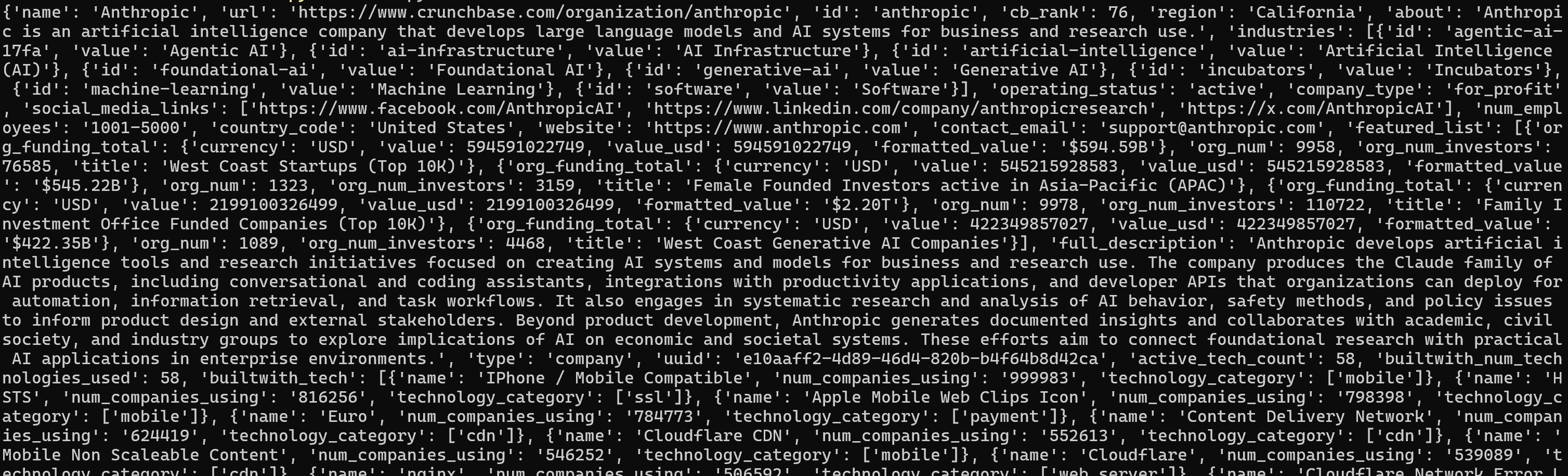
Para uma melhor visualização, cole a saída em um visualizador JSON:
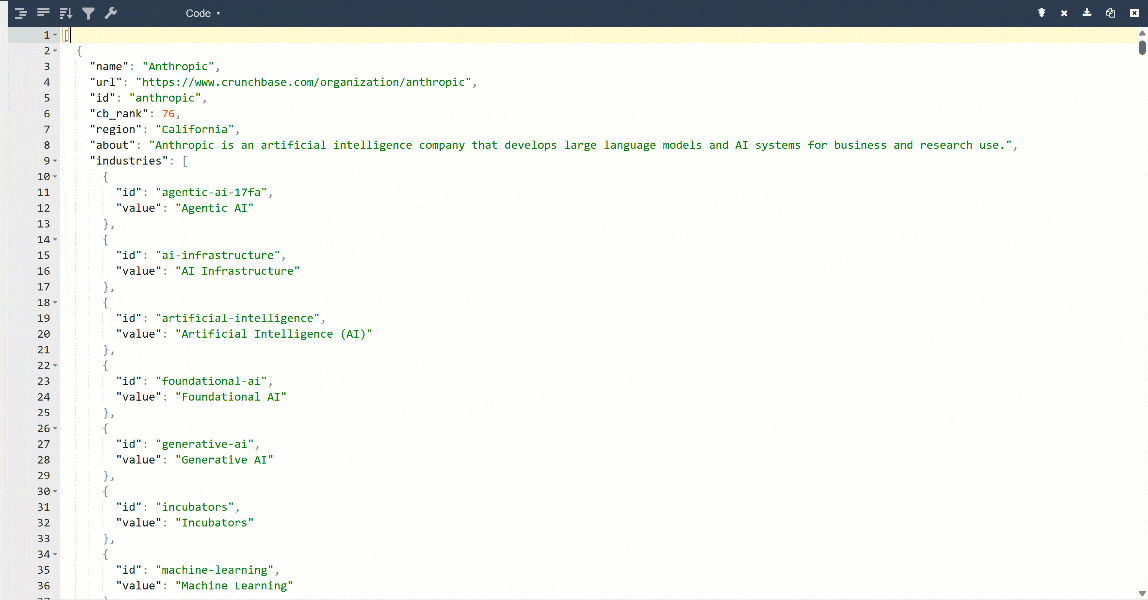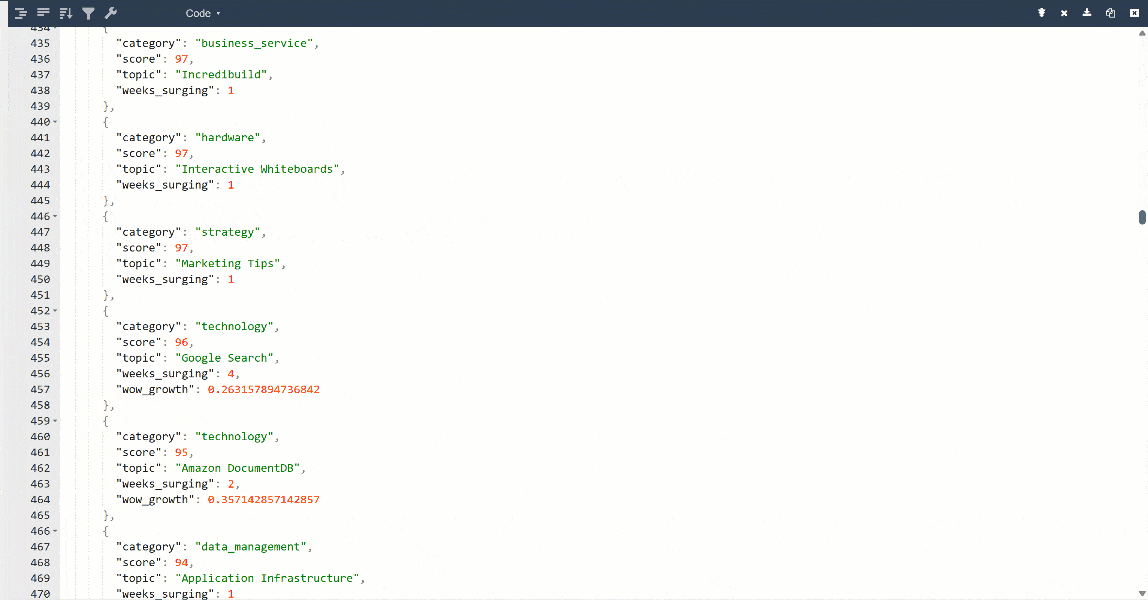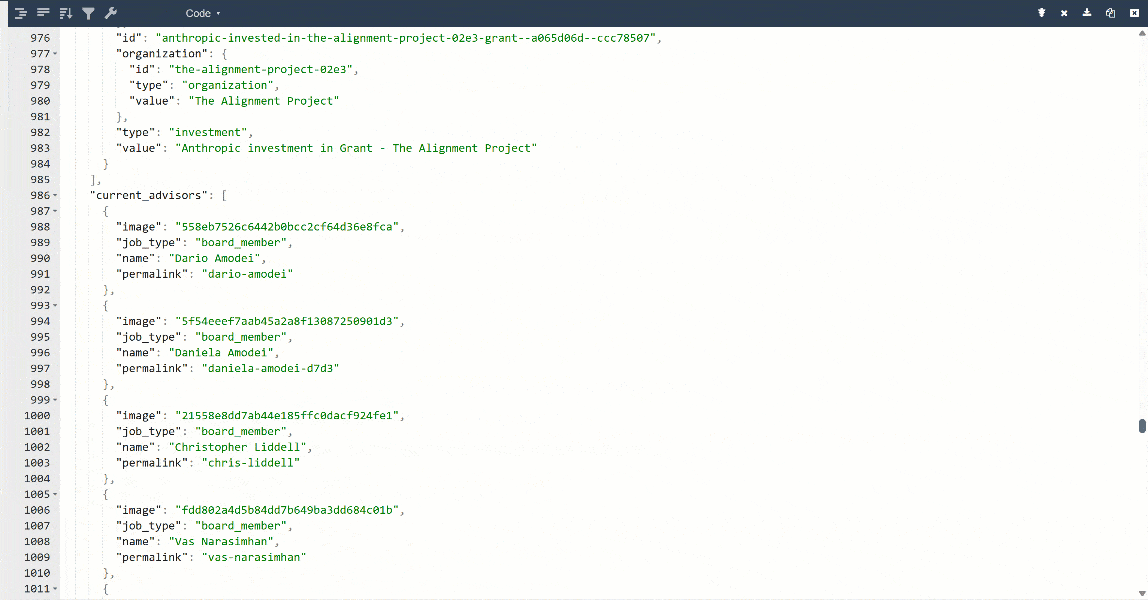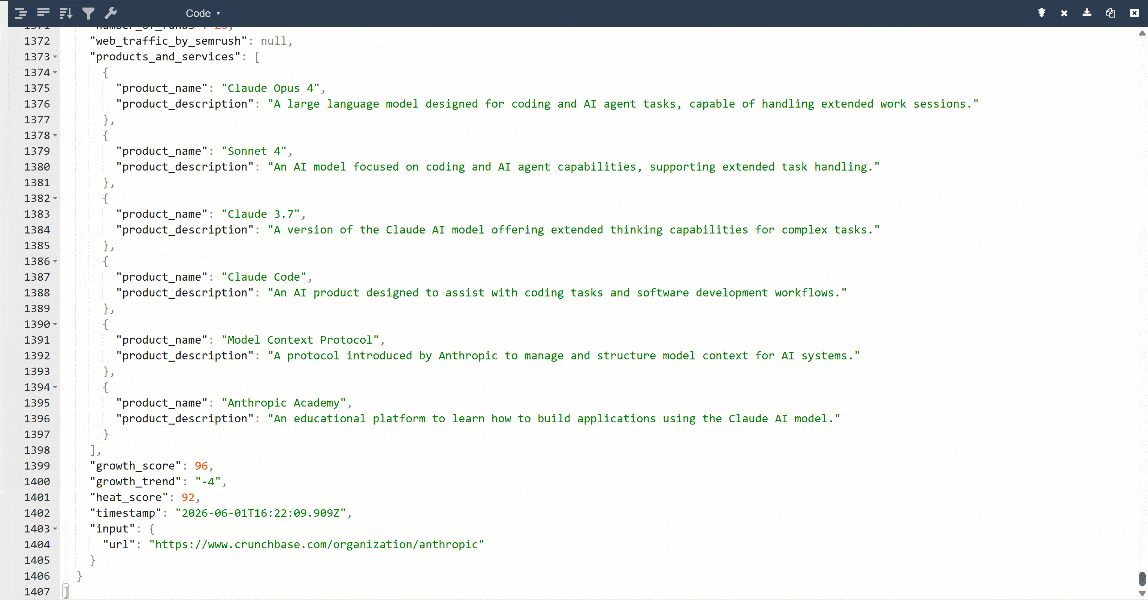
Estes são os mesmos dados extraídos da página de destino, mas em formato estruturado:
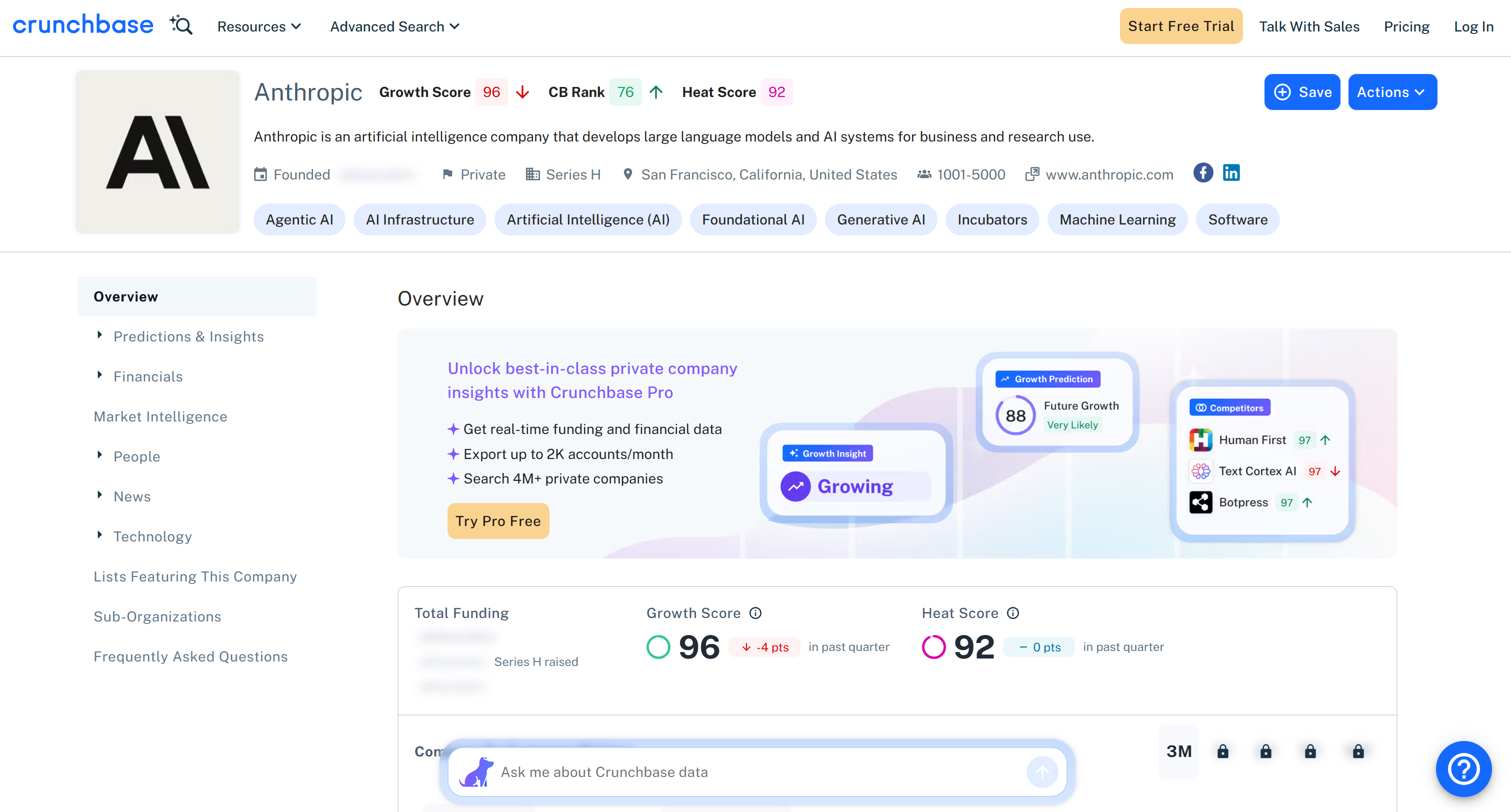
Observe que todas as informações retornadas pela API Scraper do Crunchbase da Bright Data correspondem ao conteúdo na página de destino. Isso ocorre porque os dados são recuperados em tempo real via scraping de dados, portanto estão sempre atualizados.
Et voilà! Você recuperou dados com sucesso usando a API de Scraping de Dados da Bright Data.
Próximos Passos
O capítulo acima mostrou um exemplo simples de como chamar uma API de Scraping de Dados da Bright Data em Python. No entanto, as APIs de Scraping de Dados podem fazer muito mais do que isso. Graças a elas, você pode transmitir dados estruturados e atualizados diretamente para seus aplicativos, sistemas ou fluxos de trabalho de IA.
Para casos de uso de agentes de IA em particular, essas APIs atuam como uma camada de fundamentação ao vivo, alimentando continuamente contexto externo fresco em seus sistemas. Por exemplo, você pode:
- Alimentar agentes de IA com dados web reais e atualizados para recuperação e raciocínio (por exemplo, via Web MCP da Bright Data).
- Fundamentar saídas de LLM com informações ao vivo de fontes como Crunchbase, plataformas de e-commerce ou mídias sociais.
- Construir pipelines RAG em tempo real onde dados web extraídos são injetados em prompts ou bancos de dados vetoriais.
- Suportar agentes financeiros ou de negócios que dependem de preços atuais, atualizações de empresas, sinais de mercado, etc.
Em geral, as APIs de Scraping de Dados da Bright Data são uma camada de infraestrutura central para construir sistemas dinâmicos e conscientes de dados que dependem de inteligência web atualizada.
Conjuntos de Dados ou APIs de Scraping de Dados: Tabela de Comparação Final
Compare as duas abordagens de recuperação de dados de forma rápida na tabela de comparação de conjuntos de dados vs APIs de scraping de dados abaixo:
| Conjuntos de Dados | APIs de Scraping de Dados | |
|---|---|---|
| Descrição | Coleções de dados pré-coletadas e estruturadas | APIs que extraem e retornam dados web ao vivo de sites de destino sob demanda |
| Formatos de dados | CSV, JSON, Excel, Parquet, NDJSON, etc. | JSON, CSV |
| Atualidade dos dados | Instantâneos estáticos ou atualizados periodicamente | Tempo real |
| Modelo de atualização | Ciclos de atualização diários, mensais, trimestrais | Tempo real |
| Escalabilidade | Bilhões de registros | Alta, dependendo dos limites de taxa e infraestrutura do provedor de API |
| Infraestrutura necessária | Nenhuma (gerenciada pelo provedor) | Nenhuma (gerenciada pelo provedor) |
| Cobertura | Ampla, mas limitada pelo escopo do conjunto de dados | Potencialmente qualquer site ou domínio |
| Complexidade para o usuário | Muito baixa | Baixa a média (integração de API necessária) |
| Uso de IA | Principalmente para treinamento | Fundamentação em tempo real e mais (suportado via Web MCP) |
Escolha Conjuntos de Dados Quando…
- Você precisa de dados limpos e estruturados imediatamente prontos para análise ou treinamento de ML.
- Seu caso de uso depende de informações históricas ou agregadas, sem necessidade de atualizações em tempo real.
- Você prefere evitar qualquer complexidade de engenharia de dados ou scraping.
- Você quer acesso econômico a dados curados em larga escala.
- Você prefere um fluxo de trabalho orientado a lotes (download → armazenar → consultar).
Prefira APIs de Scraping de Dados Quando…
- Você precisa de dados frescos e em tempo real da web.
- Seu sistema precisa reagir a mudanças ou eventos ao vivo (preços, notícias, atualizações de empresas, etc.).
- Você está construindo agentes de IA que requerem fundamentação externa.
- Você quer dados web sem manter uma infraestrutura de scraping internamente.
- Você requer extração contínua ou repetida de dados em evolução.
Conjuntos de Dados + APIs de Scraping de Dados: É Possível?
Usar conjuntos de dados juntamente com APIs de scraping de dados não é apenas possível, mas muitas vezes é a configuração mais prática para sistemas modernos de dados e IA.
Os conjuntos de dados fornecem instantâneos históricos limpos, estruturados e prontos para uso. São perfeitos quando você precisa de consistência, repetibilidade e análise em larga escala sem se preocupar com infraestrutura.
Por outro lado, as APIs de scraping de dados fornecem dados frescos e sob demanda diretamente da web. São mais adequadas para aplicações em tempo real e fontes em rápida mudança.
Na prática, as duas abordagens são altamente complementares. Um padrão comum é começar com um conjunto de dados para definir o estado de base de um domínio. Em seguida, usar APIs de scraping de dados para enriquecer ou atualizar partes específicas dele. Essa combinação é especialmente útil em cenários onde conhecimento de base estável e contexto ao vivo são ambos necessários.
Para um exemplo do mundo real sobre o Crunchbase, veja nosso artigo “Filter a Crunchbase Dataset and Process It with AI for Prospecting New Clients“. Ele explica como construir um fluxo de trabalho de prospecção de clientes com IA filtrando primeiro um conjunto de dados do Crunchbase e depois usando APIs de scraping de dados para buscar sites de empresas ao vivo e pontuar clientes potenciais com IA.
Conclusão
Neste post, você entendeu o que conjuntos de dados e APIs de scraping de dados têm a oferecer. Você aprendeu que os conjuntos de dados são ideais para cenários onde você precisa de grandes volumes de dados estáticos e estruturados. Já as APIs de scraping de dados são melhores quando você precisa de dados frescos recuperados diretamente da web.
Em ambos os casos, independentemente da abordagem que você escolher, você precisa de um provedor confiável de dados web. A Bright Data oferece suporte com:
- Marketplace de conjuntos de dados: Dados web públicos pré-construídos e filtrados em mais de 350 domínios em JSON, CSV, Parquet e outros formatos. Oferece acesso a uma coleção de mais de 17 bilhões de registros de dados.
- APIs de Scraping de Dados: Uma coleção de mais de 600 endpoints de scraping que automatizam a extração de dados web em tempo real em mais de 250 domínios. Eles gerenciam rotação de IP, CAPTCHAs e sistemas anti-bot, e retornam dados estruturados sem sobrecarga de infraestrutura.
Crie uma conta na Bright Data hoje e experimente nossas soluções de dados web gratuitamente!




