
Neste artigo, você aprenderá:
- O que é o Akamai e como funciona seu sistema anti-bot.
- Como verificar se um site usa o Akamai.
- Abordagens de alto nível para contornar a detecção de bots do Akamai.
- Como usar ferramentas de código aberto para superar os desafios do Akamai.
- Como lidar de forma mais confiável com o bypass do Akamai com a Bright Data, tanto em solicitações estáticas quanto em cenários de automação de navegador.
Vamos começar!
Como Funciona o Mecanismo Anti-Bot do Akamai
O Akamai funciona como uma CDN e uma camada de gerenciamento de bots posicionada entre os usuários e os servidores de origem. Cada solicitação passa pela sua rede de borda, onde é inspecionada e permitida, desafiada ou bloqueada.
Do ponto de vista anti-bot, o Akamai utiliza um sistema de detecção em múltiplas camadas:
- Camada #1 – Análise de rede e solicitações: Avalia a reputação do IP e padrões em nível de protocolo (como TLS fingerprinting).
- Camada #2 – Fingerprinting e análise do lado do cliente: O Akamai injeta desafios JavaScript que são executados no navegador para coletar sinais como características do dispositivo, configuração do navegador e comportamento do ambiente de execução. Esses fingerprints ajudam a distinguir navegadores reais de navegadores headless ou automatizados, mesmo quando as solicitações HTTP parecem válidas.
- Camada #3: Análise comportamental: Inclui movimento do mouse, padrões de digitação, fluxo de navegação e tempo entre ações. É aqui que bots mais avançados tentam imitar humanos para evitar a detecção e caem em uma “zona cinza” de incerteza.
Com base nesses sinais, o Akamai atribui uma pontuação de risco (Bot Score) e classifica o tráfego em categorias como usuários legítimos, bots conhecidos e tráfego suspeito. As respostas variam de acordo: o tráfego pode ser permitido, limitado por taxa, desafiado com mecanismos como CAPTCHAs ou totalmente bloqueado.
Como Verificar se um Site É Protegido pelo Akamai
Para determinar se um site usa o Akamai, você deve procurar uma combinação de indicadores em nível de rede e em nível de navegador.
Por exemplo, considere uma página de produto da Zalando, amplamente conhecida por estar atrás da CDN e da camada anti-bot do Akamai. Abra o DevTools do navegador, navegue até a aba “Network” e recarregue a página. Inspecione a solicitação feita pelo navegador, focando nos cabeçalhos de resposta: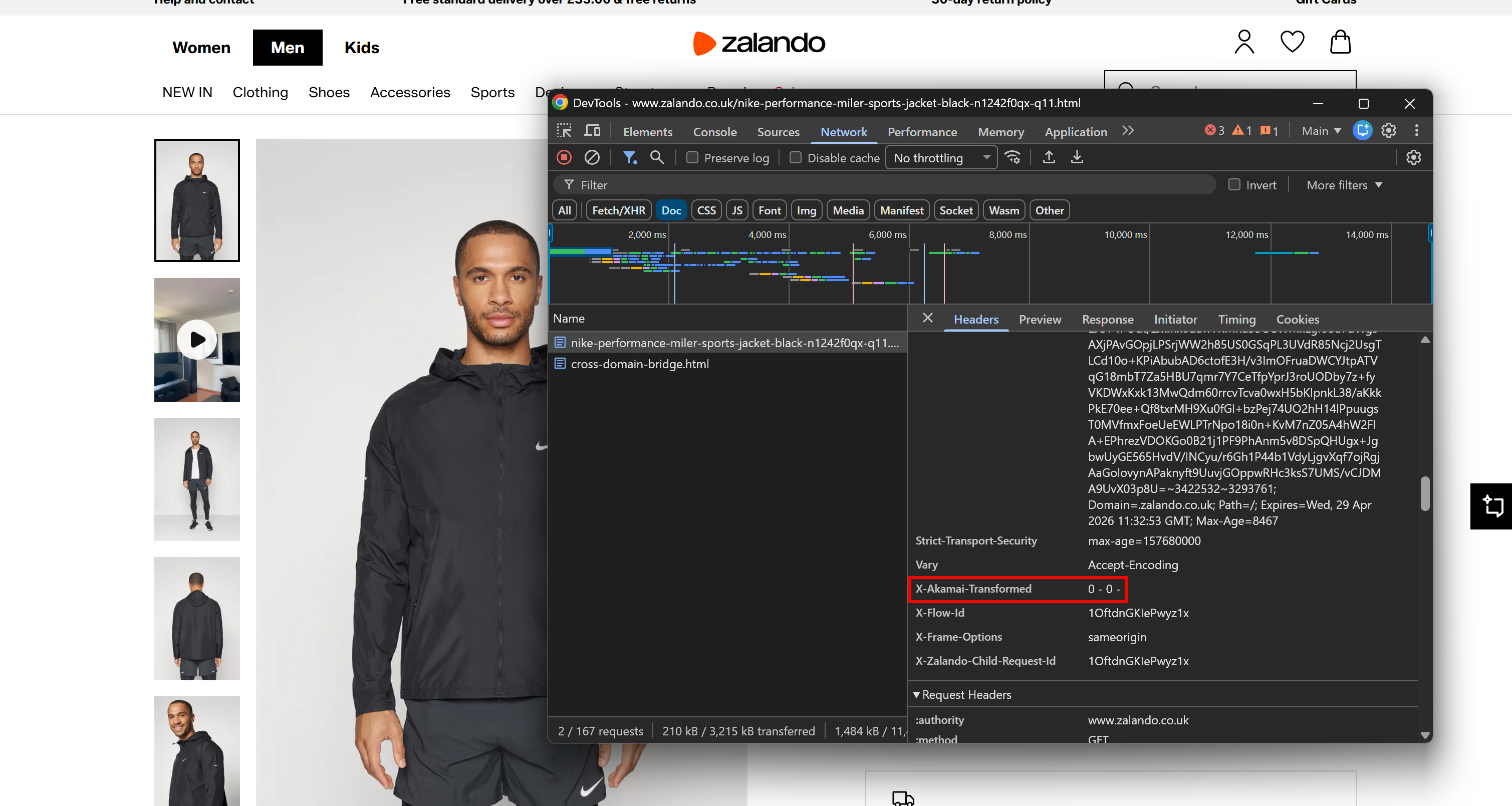
Você pode notar um cabeçalho X-Akamai-Transformed. A presença de cabeçalhos X-Akamai-* indica que o tráfego está sendo processado pela camada CDN do Akamai.
Outro sinal importante vem dos cookies definidos pelo servidor. Você pode encontrá-los na seção “Cookies” na aba “Application”. Em páginas com Akamai, você notará as _abck e ak_bmsc.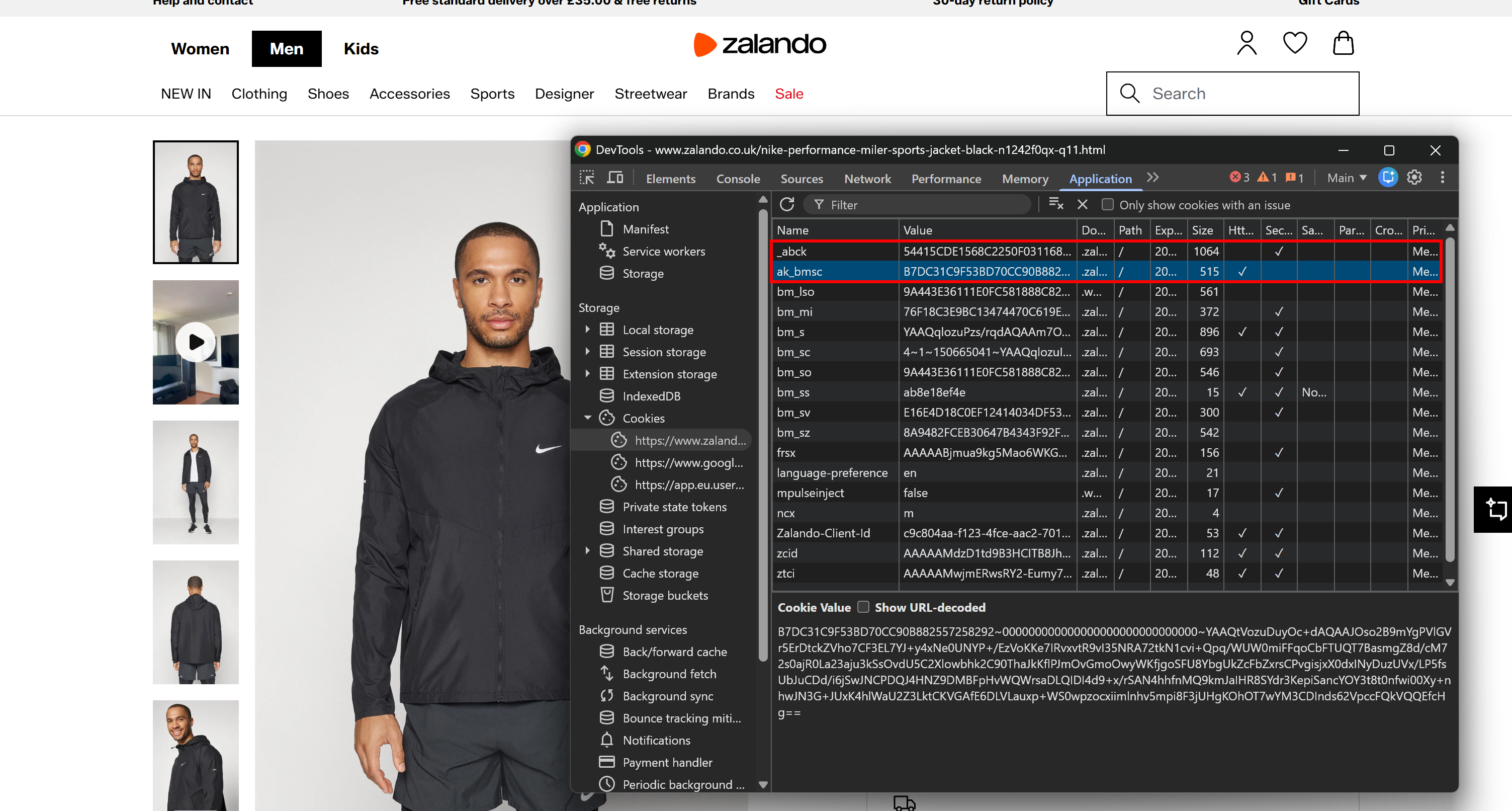
Esses são os cookies essenciais definidos pelos sistemas de detecção de bots do Akamai:
_abck: Um cookie de longa duração usado para rastreamento comportamental e pontuação de risco (pode persistir por meses).ak_bmsc: Um cookie de sessão de curta duração usado para detectar anomalias no comportamento de navegação (expira em algumas horas).
Embora possa haver sinais adicionais, esses são suficientes para identificar a maioria dos sites protegidos pelo Akamai.
Detecção de Bots do Akamai em Ação
Para entender como os mecanismos anti-bot do Akamai se comportam em um cenário de automação, considere duas abordagens comuns:
- Enviar uma solicitação direta ao servidor alvo com um cliente HTTP como o Requests.
- Renderizar a página em modo headless usando uma ferramenta de automação de navegador como o Playwright.
Nota: A página alvo continua sendo a mesma página de produto da Zalando mencionada anteriormente.
Akamai vs Requests
Tente recuperar uma página gerenciada pelo Akamai usando a biblioteca requests:
# pip install requests
import requests
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
response = requests.get(url)
print("Status code:", response.status_code)
print("\nPage HTML:\n")
print(response.text[:2500])O script imprimirá:
Status code: 403Isso mostra que o servidor rejeitou a solicitação com uma resposta 403 Forbidden. O HTML retornado exibirá uma página de erro em vez do conteúdo do produto esperado.
Portanto, uma chamada básica ao requests não é suficiente para acessar uma página gerenciada pelo Akamai. O mesmo resultado ocorrerá com a maioria dos clientes HTTP padrão.
Akamai vs Playwright
Visite a página alvo usando o Playwright em modo headless. Em seguida, imprima o código de status HTTP e tire um screenshot:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with sync_playwright() as p:
# Visit the target page in headless mode
browser = p.chromium.launch(headless=True)
context = browser.new_context()
page = context.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()Novamente, a solicitação é bloqueada e a saída será:
Status code: 403O screenshot resultante conterá uma página de negação de acesso em vez do conteúdo do produto esperado: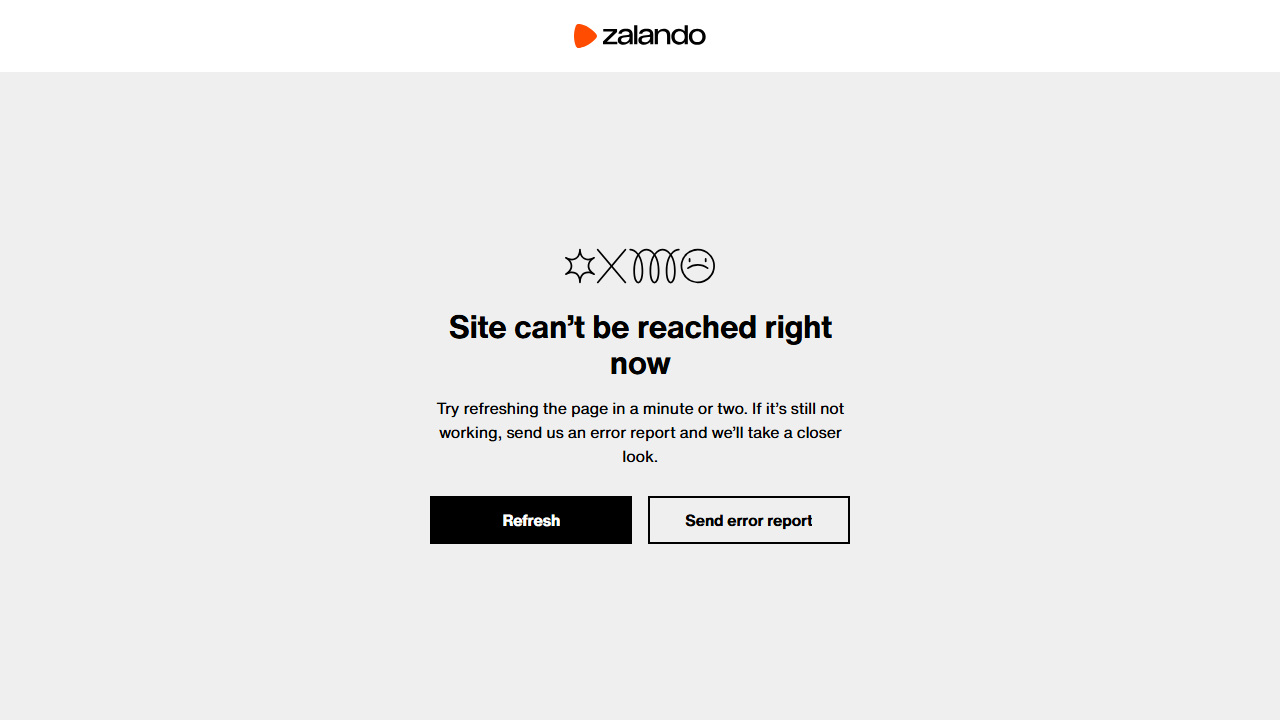
A página de erro indica que o acesso não é permitido sem fornecer informações detalhadas.
Nota: Ao contrário de outros sistemas anti-bot (como o Cloudflare), as respostas de erro do Akamai geralmente variam entre sites.
Abordagens de Alto Nível para Contornar a Detecção de Bots do Akamai
Neste capítulo, você explorará as principais abordagens para contornar a detecção de bots do Akamai. Se estiver com pressa, consulte a tabela resumida abaixo.
| Abordagem | Descrição resumida | Vantagens | Desvantagens |
|---|---|---|---|
| Acesso direto à origem | Tenta contornar a CDN enviando solicitações diretamente ao servidor de origem se seu IP estiver exposto | Nenhuma ferramenta adicional necessária | Raramente funciona na prática |
| Ferramentas de bypass de automação de navegador de código aberto | Usa frameworks de automação específicos para simular sessões reais de navegador do usuário | Gratuito | Detectável devido à engenharia reversa e bloqueio baseado em IP |
| Ferramentas premium de scraping com bypass anti-bot | Usa serviços gerenciados em nuvem que lidam com tudo para você | Altamente confiável, escalável, configuração mínima, gerencia toda a pilha anti-bot | Pago |
Abordagem #1: Acesso Direto à Origem
No fim das contas, o Akamai é uma CDN. Isso significa que ele fica entre o servidor de origem alvo e você (o usuário), armazenando em cache e protegendo o conteúdo enquanto roteia o tráfego pela sua rede de borda distribuída.
Em teoria, se o endereço IP do servidor de origem estivesse exposto (por exemplo, por meio de registros DNS históricos ou configurações incorretas), você poderia tentar enviar solicitações diretamente a ele. Isso significaria contornar a rede Akamai diretamente, pois seu tráfego seria roteado fora da camada CDN.
Na prática, essa abordagem não é confiável por vários motivos:
- Restrições de acesso à origem: Servidores de origem devidamente configurados aceitam apenas tráfego dos intervalos de IP da CDN ou exigem solicitações autenticadas (como cabeçalhos ou tokens assinados).
- Controles em nível de rede: Firewalls e grupos de segurança geralmente bloqueiam o acesso público direto.
- Exposição limitada: Descobrir o IP de origem por trás de uma CDN é incomum, pois as configurações modernas são projetadas para evitar esse tipo de vazamento.
Devido a essas limitações, o acesso direto à origem geralmente não é viável em ambientes bem configurados. Trata-se mais de um conceito teórico do que de uma abordagem prática.
Abordagem #2: Usar Ferramentas de Bypass de Automação de Navegador de Código Aberto
Várias bibliotecas de automação de navegador de código aberto produzem sessões automatizadas que se assemelham ao comportamento real do usuário. Isso inclui ferramentas como Camoufox, SeleniumBase, NODRIVER e outros frameworks de automação orientados a anti-bot. Além disso, alguns frameworks completos de scraping como o Scrapling oferecem recursos semelhantes.
Essas ferramentas ajustam o navegador subjacente para obter fingerprints realistas, ao mesmo tempo em que fornecem uma API de automação de navegador semelhante ao Selenium ou ao Playwright. Isso se aplica mesmo ao executar a automação do navegador em modo headless.
No entanto, essa abordagem de bypass da detecção de bots do Akamai tem duas limitações principais:
- Visibilidade do código aberto: Como essas ferramentas são de código aberto, seus detalhes de implementação estão disponíveis publicamente. Como resultado, provedores anti-bot como o Akamai podem fazer engenharia reversa delas, bloqueando ou degradando temporariamente sua eficácia (até que atualizações sejam lançadas). Isso cria um ciclo contínuo de gato e rato entre sistemas de detecção e ferramentas de automação.
- Imposição baseada em IP: Essa abordagem é ótima para contornar verificações baseadas em fingerprint. No entanto, as solicitações de scraping ainda se originam do seu endereço IP. Portanto, o Akamai ainda pode bloqueá-lo por meio de limitação de taxa ou mecanismos baseados em reputação de IP. Para mitigar isso, você deve integrar um serviço premium de rotação de proxies de terceiros.
Abordagem #3: Integrar Ferramentas Premium de Scraping com Bypass do Akamai
A maneira mais confiável e escalável de contornar a proteção de bots do Akamai é usar ferramentas premium de web scraping. Esses serviços gerenciam toda a pilha de desafios, incluindo fingerprinting de navegador, detecção de automação, gerenciamento de IP, resolução de CAPTCHA e escalabilidade de infraestrutura.
Em vez de gerenciar solicitações diretamente, você fornece uma URL alvo e recebe de volta o conteúdo desbloqueado. Isso pode ser entregue por meio de respostas HTTP padrão ou, em alguns casos, por sessões de automação de navegador.
Como essas soluções são implantadas na nuvem, não há risco de engenharia reversa, ao contrário das bibliotecas de código aberto. Além disso, geralmente são construídas em redes de proxies de grande escala, permitindo escalabilidade em nível empresarial.
A principal desvantagem é o custo, pois esses serviços são produtos comerciais. Ainda assim, o custo por solicitação bem-sucedida costuma ser muito baixo (às vezes frações de centavo).
Como Contornar o Akamai com Soluções de Código Aberto
O acesso direto à origem é mais uma abordagem teórica do que prática. Portanto, vamos começar demonstrando o uso de ferramentas de automação de navegador específicas para anti-bot para contornar as proteções do Akamai.
Nesta seção, testaremos o Camoufox e o SeleniumBase, embora outras ferramentas também possam ser usadas. O teste alvo será visitar a página de produto protegida da Zalando mencionada anteriormente e tentar tirar um screenshot dela.
Nota: O resultado abaixo refere-se a uma única execução do script usando um IP residencial. O mesmo script, quando executado a partir de um servidor ou em escala, provavelmente falhará devido a limitações de taxa ou problemas de reputação de IP.
Veja o Camoufox e o SeleniumBase em ação contra conteúdo protegido pelo Akamai!
Teste de Bypass do Akamai com Camoufox
Primeiro, instale o Camoufox no seu projeto Python:
pip install camoufoxEm seguida, recupere os binários do navegador:
python -m camoufox fetchO Camoufox é construído sobre o Playwright, então sua API é muito semelhante. Visite a página alvo, imprima o código de status HTTP e tire um screenshot com:
# pip install camoufox
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with Camoufox(headless=True) as browser:
# Visit the target page
page = browser.new_page()
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="camoufox_zalando.png")Para mais informações sobre esta biblioteca, leia nosso guia sobre web scraping com Camoufox.
Mesmo em modo headless, o resultado esperado deve ser:
Status code: 200E o arquivo camoufox_zalando.png gerado deve conter a página renderizada: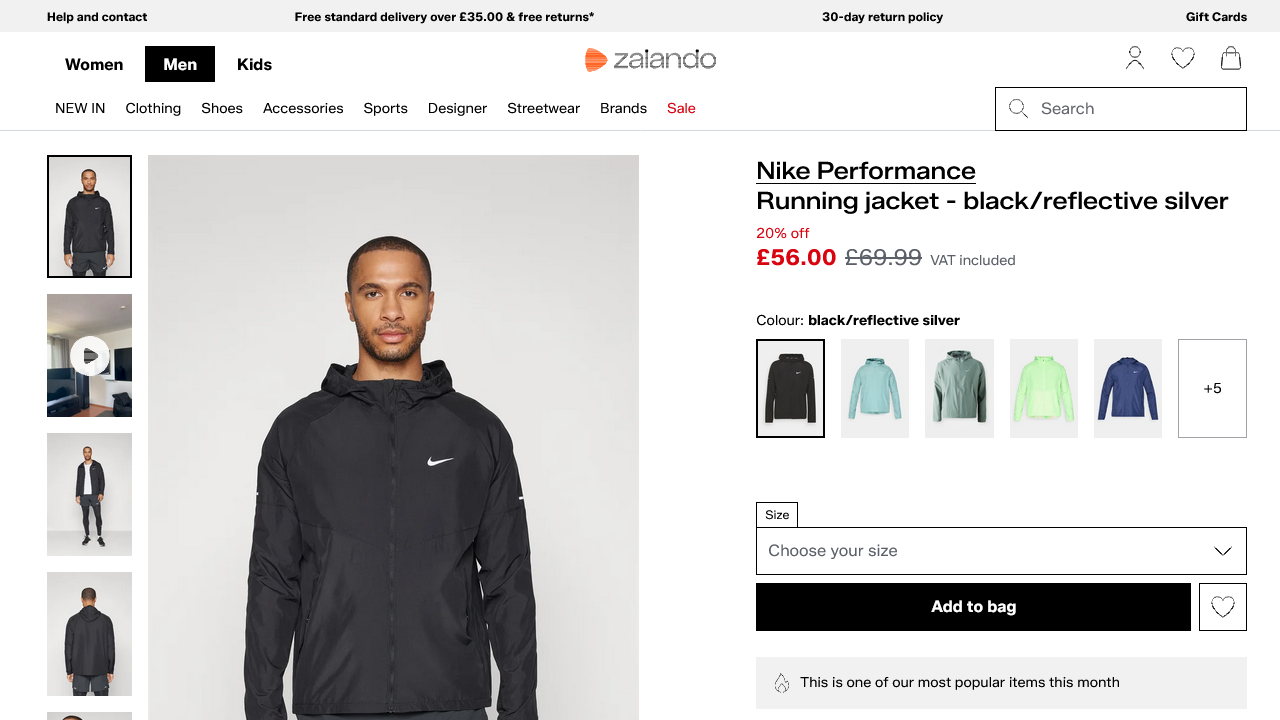
Excelente! O Camoufox conseguiu contornar o Akamai.
Teste de Bypass do Akamai com SeleniumBase
Instale o SeleniumBase com:
pip install seleniumbaseEm seguida, use-o para visitar a página alvo no Modo UC e tirar um screenshot:
# pip install seleniumbase
from seleniumbase import SB
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
with SB(uc=True, headless=True) as sb:
# Open the page
sb.open(url)
# Get status code via JS (as Selenium does not expose it directly)
status = sb.execute_script(
"return window.performance.getEntries()[0]?.responseStatus || 'unknown';"
)
print("Status code:", status)
# Wait for page load
sb.sleep(3)
# Take a screenshot
sb.save_screenshot("seleniumbase_zalando.png")Para mais informações sobre como o modo UC funciona e como configurá-lo, consulte o guia de scraping com SeleniumBase.
O resultado esperado deve ser:
Status code: 200E o arquivo seleniumbase_zalando.png produzido deve mostrar: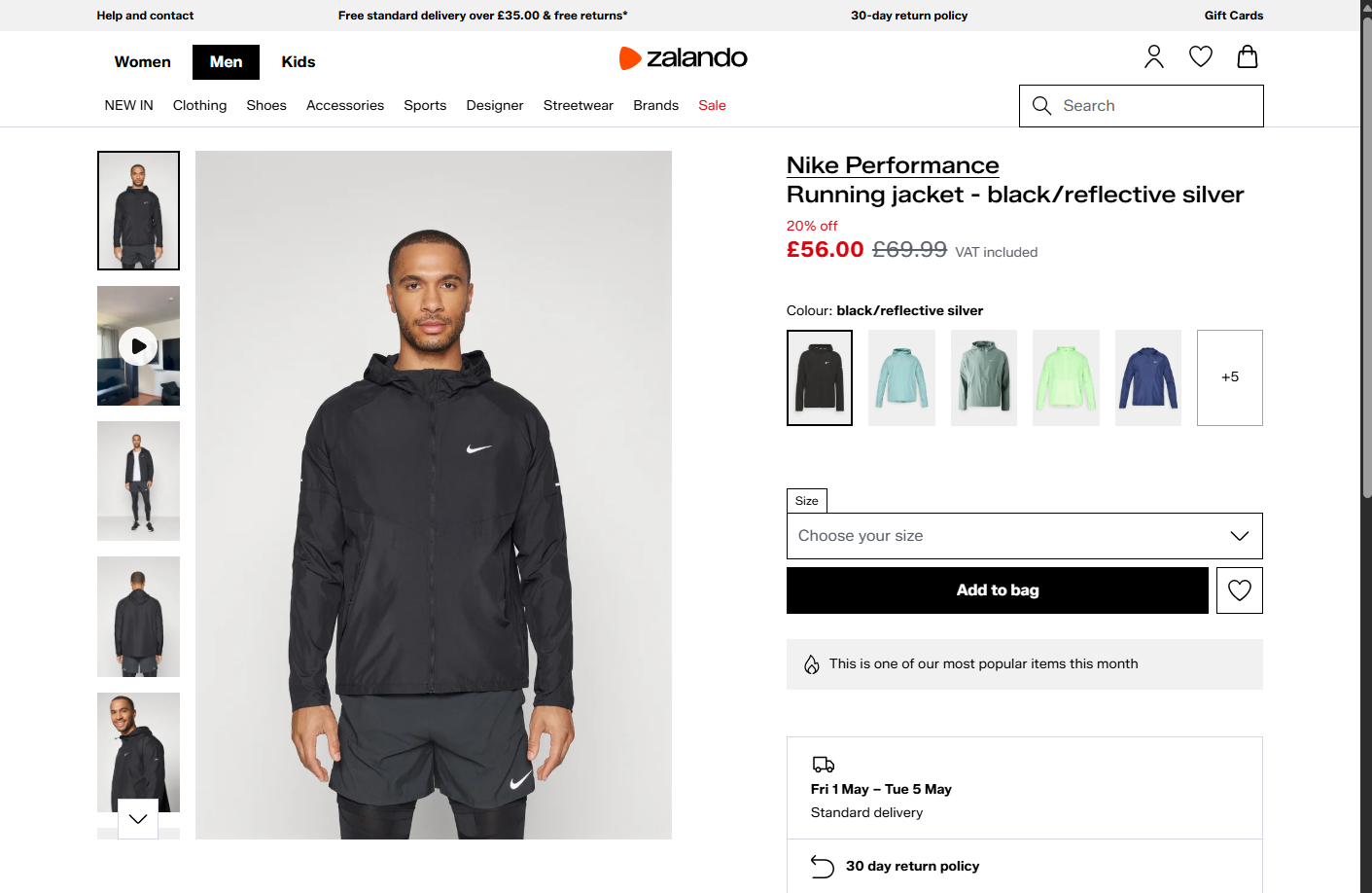
Ótimo! O SeleniumBase também contornou as proteções anti-bot do Akamai.
Como Contornar o Akamai em Escala com a Bright Data
A Bright Data permite que você acesse praticamente qualquer página da web, independentemente de ser protegida pelo Akamai, Cloudflare ou outros sistemas anti-bot.
Em particular, todos os serviços de scraping da Bright Data são respaldados por um sistema dedicado de Bypass de Bots do Akamai. Isso lida automaticamente com os desafios anti-bot do Akamai para você.
Uma vantagem fundamental da Bright Data é que ela é alimentada por uma das maiores redes de proxies do mundo, com mais de 400 milhões de IPs. Isso permite concorrência ilimitada, com 99,99% de uptime e 99,95% de sucesso nas solicitações. Além disso, graças a isso, não é afetada por bloqueios relacionados a IP ou limitação de taxa, ao contrário das ferramentas de automação de navegador de código aberto.
A seguir, demonstraremos como contornar a proteção do Akamai usando:
- Web Unlocker API: Uma API de scraping que gerencia a rotação de proxies, desafios anti-bot (incluindo Akamai) e resolução de CAPTCHA em uma única solicitação.
- Browser API: Uma sessão de navegador em nuvem, otimizada para anti-bot, que pode ser controlada via Playwright, Selenium, Puppeteer ou qualquer ferramenta de automação compatível com CDP.
Siga as instruções nos próximos capítulos!
Contornando o Akamai com a Web Unlocker API da Bright Data
Experimente o bypass da detecção de bots do Akamai usando a Web Unlocker API da Bright Data em um cenário de scraping estático.
Pré-requisitos
Para seguir esta seção, certifique-se de ter:
- Uma conta Bright Data com uma chave de API configurada.
- Uma zona da Web Unlocker API configurada em sua conta.
- Um script de scraping baseado em uma abordagem de cliente HTTP.
Para configurar sua conta Bright Data para uso da Web Unlocker API, siga o guia oficial “Crie Sua Primeira Unlocker API“.
Exemplo
Se você estiver interessado em recuperar o HTML desbloqueado pelo Akamai de uma página, use a Web Unlocker API assim:
import requests
# Replace with your Bright Data API key and Web Unlocker API zone name
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_WEB_UNLOCKER_API_ZONE = "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>"
target_url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
payload = {
"zone": BRIGHT_DATA_WEB_UNLOCKER_API_ZONE,
"url": target_url,
"format": "raw"
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
# Perform a request to the Bright Data Web Unlocker API
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
print("Status code:", response.status_code)
html = response.text
print("\nPage HTML:\n")
print(html)
# Perform web scraping on the returned HTML...O resultado será:
Status code: 200Em seguida, a variável html conterá o código-fonte completo da página. Você pode facilmente analisá-lo com um parser HTML e extrair os dados desejados em um fluxo de web scraping. Para scraping em grande escala, confira nosso Scraper da Zalando.
Contornando o Akamai com a Browser API da Bright Data
Aqui, você verá como superar as verificações anti-bot do Akamai usando a Browser API da Bright Data em um cenário de automação de navegador.
Pré-requisitos
Para acompanhar esta seção, certifique-se de ter:
- Uma zona da Browser API configurada em sua conta Bright Data.
- Um script de scraping com automação de navegador.
Para obter a URL de conexão da Browser API, leia o guia oficial “Crie Sua Primeira Browser API“.
Aqui, mostraremos um exemplo com Playwright, então a URL de conexão da Browser API terá este formato:
wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222Exemplo
Conecte seu script de automação Playwright à Browser API da Bright Data e repita a lógica de screenshot mostrada anteriormente:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
url = "https://www.zalando.co.uk/nike-performance-miler-sports-jacket-black-n1242f0qx-q11.html"
BRIGHT_DATA_BROWSER_API_CDP_URL = "wss://<BRIGHT_DATA_BROWSER_API_USERNAME>:<BRIGHT_DATA_BROWSER_API_PASSWORD>@brd.superproxy.io:9222"
with sync_playwright() as p:
# Connect to Bright Data CDP endpoint
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_BROWSER_API_CDP_URL)
# Create a new context and page
context = browser.new_context()
page = context.new_page()
# Visit the target page in headless mode
response = page.goto(url)
# Print the response's HTTP status code
if response:
print("Status code:", response.status)
else:
print("No response received")
# Take a screenshot of the page
page.screenshot(path="zalando.png")
browser.close()Quando executado, o script retornará:
Status code: 200O screenshot resultante conterá o conteúdo renderizado da página: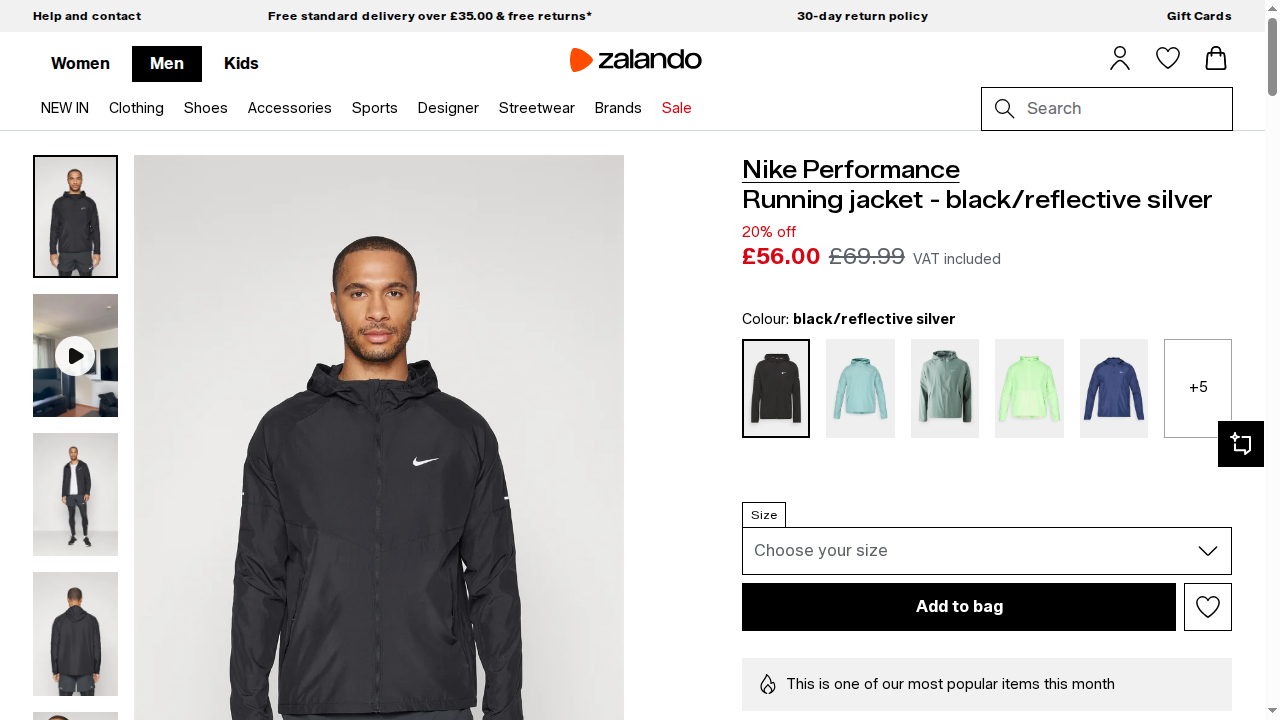
Fantástico! Desta vez, graças à integração com a Browser API, o script Playwright funcionou corretamente. A Browser API gerencia a automação em sessões reais de navegador na infraestrutura de nuvem da Bright Data.
Agora você pode criar fluxos de trabalho automatizados para interagir com a página sem restrições!
Conclusão
Neste artigo, você aprendeu como o sistema anti-bot do Akamai funciona e explorou abordagens práticas para lidar com ele em fluxos de automação e scraping.
Independentemente do método escolhido, o processo se torna mais fácil com soluções empresariais profissionais, rápidas e confiáveis, como:
- Web Unlocker API: Um endpoint de API que gerencia automaticamente limitação de taxa, desafios de fingerprinting e outros mecanismos anti-bot.
- Browser API: Um navegador anti-detecção em nuvem gerenciado que permite automatizar interações com qualquer site em escala.
Como outros produtos de scraping da Bright Data, esses serviços são alimentados pelo Akamai Bot Solver.
Crie uma nova conta Bright Data gratuitamente hoje e explore nossas soluções de scraping!




