TL;DR: Comparação rápida
✓ A Bright Data domina tanto o Scraping de dados empresarial quanto o de IA com mais de 150 milhões de IPs residencialis, 99,99% de tempo de atividade e infraestrutura de IA abrangente, incluindo servidor MCP para sistemas RAG e agentes de IA, começando com um plano gratuito com 5.000 solicitações/mês
✓ O Firecrawl é ideal para desenvolvedores de IA que buscam uma configuração simples com saída Markdown nativa, tempos de resposta de 50 ms e preços transparentes de US$ 19 a US$ 399/mês
✓ Diferença principal: Firecrawl = API simplificada para fluxos de trabalho básicos de IA | Bright Data = plataforma completa de dados para IA com velocidade E escala, além de acesso desbloqueável a qualquer site
✓ Escolha Bright Data se você precisar de infraestrutura de IA de nível de produção, acesso irrestrito a sites protegidos, dados multimodais (texto/vídeo/áudio), conformidade empresarial (SOC 2) ou sistemas RAG que não falham em sites difíceis
✓ Escolha Firecrawl se você precisar de extração básica de texto com configuração mínima e estiver processando menos de 100 mil páginas/mês
✓ Ambos oferecem suporte ao MCP Server, mas o Bright Data fornece acesso a mais de 60 Scrapers de domínio estruturados, API de arquivo de mais de 50 PB e confiabilidade comprovada que a abordagem simplificada do Firecrawl não consegue igualar
O que é a Bright Data?
A Bright Data opera desde 2014 como a maior plataforma de dados da web do mundo. A empresa atende a mais de 20.000 clientes, incluindo empresas da Fortune 500, processando mais de 650 petabytes de dados mensalmente.
Infraestrutura e rede principais
A base da Bright Data é sua enorme infraestrutura de Proxy ético. A plataforma opera mais de 150 milhões de IPs residencialis em 195 países, fornecendo endereços IP de usuários reais.
Não se trata apenas de escala. Trata-se de acesso garantido. Quando você está criando agentes de IA ou sistemas RAG que dependem de dados da web em tempo real, o bloqueio não é uma opção. Os Proxies residenciais da Bright Data garantem que seus aplicativos de IA obtenham os dados de que precisam, mesmo de sites altamente protegidos que bloqueiam ferramentas mais simples.
A rede inclui quatro tipos de Proxy:
- Proxies residenciais: mais de 150 milhões de IPs de dispositivos reais
- Proxy de datacenter: IPs dedicados de alta velocidade
- Proxy móvel: mais de 7 milhões de IPs móveis para conteúdo específico para dispositivos móveis
- Proxies ISP: IPs residencialis estáticos que combinam velocidade e legitimidade
Principais recursos para aplicações de IA
API Web Scraper: Scrapers pré-construídos para mais de 100 domínios populares, incluindo LinkedIn, Amazon, Instagram, Twitter (X) e TikTok. Em vez de construir scrapers personalizados, você chama uma API e recebe dados estruturados e prontos para IA. Esses scrapers são otimizados para alimentar sistemas LLM e RAG com dados limpos e confiáveis em escala.
Web Unlocker: ignora automaticamente proteções anti-bot, incluindo Cloudflare, DataDome e PerimeterX. Isso lida com a Resolução de CAPTCHA, rotação de impressão digital e automação do navegador sem configuração manual. Isso é fundamental para aplicações de IA que precisam de 100% de confiabilidade, não 96% de cobertura.
API de arquivo: acesso a mais de 50 petabytes de dados históricos da Internet, incluindo imagens, áudio e arquivos de vídeo. Isso é inestimável para o treinamento de IA multimodal, onde você precisa de diversos tipos de dados além do que os simples Scrapers de texto podem fornecer.
Navegador de scraping: automação remota do navegador para sites com muito JavaScript que exigem interações complexas, como rolagem, cliques e envio de formulários. Essencial para agentes de IA que precisam interagir com sites dinâmicos.
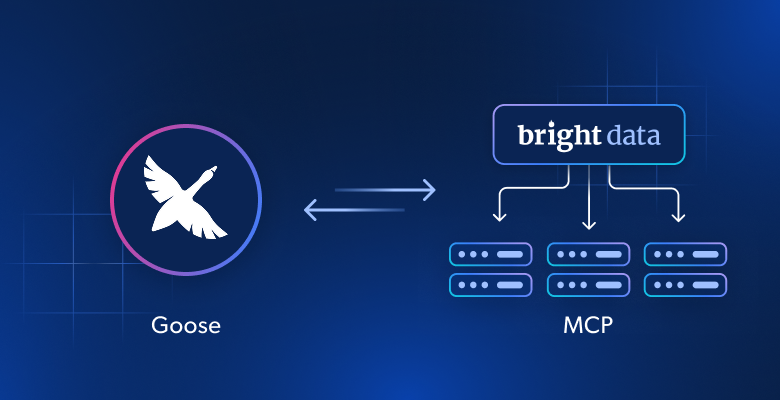
Servidor MCP da Bright Data para agentes de IA
O servidor MCP (Model Context Protocol) da Bright Data conecta agentes de IA diretamente à infraestrutura de dados da web com confiabilidade de nível empresarial. Seu LLM pode pesquisar, extrair e navegar na web de forma autônoma, sem ser bloqueado.
O nível gratuito inclui 5.000 solicitações mensais. Isso é perfeito para prototipar agentes de IA e sistemas RAG antes de escalar para produção. Ele fornece aos desenvolvedores de IA a infraestrutura comprovada da Bright Data sem nenhum custo, eliminando a escolha entre “simplicidade e capacidade”.
Recursos do servidor MCP para aplicações de IA:
- Dados estruturados de mais de 100 domínios populares (não apenas scraping genérico)
- Pesquisa avançada e rastreamento inteligente
- Automação do navegador para fluxos de trabalho complexos de agentes de IA
- Contorno garantido de proteções anti-bot (não apenas “funciona na maioria dos sites”)
- Extração de dados em tempo real para recuperação de conhecimento RAG
- Funciona com Claude, ChatGPT e agentes de IA personalizados
- Tempos de resposta inferiores a um segundo para aplicações sensíveis à latência
- Escalável do protótipo à produção sem trocar de ferramentas
Por que isso é importante para agentes de IA e sistemas RAG: ferramentas mais simples funcionam até que deixem de funcionar. Quando seu agente de IA encontra um site protegido, gerenciamento de sessão ou JavaScript complexo, você precisa de uma infraestrutura que lide com isso automaticamente. O servidor MCP da Bright Data oferece aos aplicativos de IA o mesmo acesso de nível empresarial em que as empresas da Fortune 500 confiam, mas por meio de uma interface amigável para desenvolvedores.
O que é o Firecrawl?

O Firecrawl foi lançado em 2024 pela Y Combinator como uma API de Scraping de dados criada para ser simples. A plataforma ganhou mais de 81,3 mil estrelas no GitHub e atende a mais de 80 mil empresas que desenvolvem aplicativos básicos de Scraping de dados.
Filosofia de design nativa de IA
O Firecrawl se concentra em converter páginas da web em formatos Markdown e JSON limpos. Para necessidades simples de scraping em sites desprotegidos, essa abordagem simplificada reduz o tempo de desenvolvimento.
A plataforma converte automaticamente páginas da web em formatos otimizados para LLM sem transformação manual. Isso elimina pipelines básicos de limpeza de dados para casos de uso simples.
Saídas de dados prontas para LLM
Conversão automática para Markdown: as páginas são transformadas em Markdown limpo, que preserva a estrutura do documento enquanto remove navegação, anúncios e conteúdo padrão.
Extração JSON estruturada: o endpoint /extract aceita prompts de linguagem natural para extrair campos de dados específicos. Em vez de escrever seletores CSS, você descreve o que deseja e recebe JSON estruturado.
Raspagem interativa: a plataforma lida com a renderização básica de JavaScript e o carregamento de conteúdo dinâmico para sites desprotegidos.
Modo agente: o endpoint agente autônomo usa IA para navegar em sites e coletar dados sem instruções explícitas para cenários de scraping mais simples.
Experiência do desenvolvedor
O Firecrawl prioriza a facilidade de configuração. A integração é simples:
from firecrawl import Firecrawl
firecrawl = Firecrawl(api_key="fc-YOUR-API-KEY")
# Scrape um único URL
scrape_result = firecrawl.scrape('https://example.com', formats=['markdown', 'html'])
print(scrape_result)A plataforma oferece:
- Integração nativa com LangChain para pipelines RAG básicos
- SDKs para Python, Node.js, Go e Rust
- Núcleo de código aberto com contribuições da comunidade
- Integrações sem código com n8n, Zapier, Make e Lovable
- 500 créditos gratuitos para testes
A desvantagem: essa simplicidade vem acompanhada de limitações. O Firecrawl alcança 96% de cobertura da web, o que significa que 4% dos sites (geralmente os mais valiosos e protegidos) ficam inacessíveis. Para aplicações de IA que exigem acesso confiável a todos os sites, essa lacuna se torna crítica.
Comparação direta
Arquitetura e abordagem técnica
O Firecrawl usa um design API-first e de finalidade única. Você envia uma URL e recebe dados limpos de sites sem proteção sofisticada. A plataforma abstrai a complexidade por trás de endpoints simples, o que funciona bem para necessidades básicas de scraping.
A Bright Data opera como uma plataforma de dados de IA abrangente. Você obtém simplicidade (por meio do MCP Server e APIs pré-construídas) E infraestrutura empresarial quando necessário. Isso não é complexidade por si só. É a diferença entre “funciona na maioria dos sites” e “funciona em todos os sites”.
Para aplicações de IA, essa diferença arquitetônica é crucial. Quando seu sistema RAG precisa de dados de um site de documentação protegido pela Cloudflare ou seu agente de IA precisa acessar conteúdo com restrição geográfica, a infraestrutura da Bright Data garante que sua aplicação não falhe. A abordagem simplificada da Firecrawl deixa uma lacuna de cobertura de 4% que muitas vezes inclui suas fontes de dados mais importantes.
Integração de IA e LLM
Ambas as plataformas oferecem suporte a aplicativos de IA, mas com diferentes garantias de confiabilidade. Confira agora as demonstrações da Bright Data.
O Firecrawl oferece tempos de resposta inferiores a um segundo, com média de 50 ms em sites sem proteção. Isso funciona bem para casos de uso básicos, em que a velocidade é mais importante do que o acesso garantido.
A Bright Data fornece infraestrutura de IA de nível empresarial por meio de seu servidor MCP, que combina velocidade E confiabilidade:
- Respostas em menos de um segundo para a maioria das consultas, mantendo taxas de sucesso de 99,99%
- Acesso garantido a sites protegidos que bloqueiam ferramentas mais simples
- Mais de 100 Scrapers pré-construídos que fornecem dados estruturados das principais plataformas
- API de arquivo de mais de 50 PB para treinamento de IA multimodal além do texto
- Modos em tempo real e em lote otimizados para diferentes fluxos de trabalho de IA
Os testes mostram que a Bright Data se destaca em:
- Sistemas RAG de produção que exigem 100% de disponibilidade de dados
- Agentes de IA que acessam sites protegidos automaticamente
- Agregação de dados de várias fontes para bases de conhecimento de IA abrangentes
- Aplicações de IA empresarial onde falhas não são aceitáveis
- Agentes de IA em tempo real que precisam de velocidade E confiabilidade
Especificamente para sistemas RAG: ambas as plataformas podem fornecer dados limpos, mas a Bright Data garante que seu sistema RAG não falhe quando os usuários consultam informações de fontes protegidas. Quando sua IA precisa recuperar conhecimento do LinkedIn, dos principais sites de comércio eletrônico ou de plataformas empresariais, a infraestrutura da Bright Data garante o acesso.
O servidor MCP preenche a lacuna de simplicidade. Você obtém a facilidade de uso do Firecrawl com recursos de nível empresarial.
Desempenho e velocidade
Nossos testes revelaram perfis de desempenho distintos:
| Métrica de desempenho | Firecrawl | Bright Data |
|---|---|---|
| Tempo médio de resposta (sites desprotegidos) | 50 ms | 50 ms-2 s |
| Tempo médio de resposta (sites protegidos) | Bloqueado | 2-5 segundos |
| Cobertura da Web | 96 | 99,9 |
| Sites JavaScript | Bom | Excelente |
| Solicitações simultâneas | 50-100 | Ilimitado |
| Taxa de sucesso | 94% em média | 99,99% com novas tentativas |
| Cobertura geográfica | Limitada | 195 países |
| Sucesso em sites protegidos | Falhas ~4% | 99,99% |
A percepção crítica: o Firecrawl atinge velocidades rápidas em alvos fáceis. A Bright Data atinge velocidades rápidas em alvos fáceis E acesso garantido em alvos difíceis. Para aplicações de IA, a questão não é apenas “quão rápido?”, mas “funcionará quando eu precisar?”.
O Firecrawl alcança 96% de cobertura da web. Isso é significativamente melhor do que os 79% do Puppeteer ou os 75% do cURL, mas essa diferença de 4% geralmente inclui as fontes de dados mais valiosas: perfis do LinkedIn, preços de comércio eletrônico, dados financeiros, plataformas SaaS empresariais.
A Bright Data se aproxima de 99,9% de cobertura com sua rede de Proxy residencial e o Web Unlocker. A plataforma lida com sites protegidos onde ferramentas mais simples falham, tornando-a essencial para aplicações de IA em produção.
Para agentes de IA e sistemas RAG: ao criar um chatbot que responde a perguntas sobre produtos concorrentes, você não pode dizer aos usuários “desculpe, este site está nos 4% que não consigo acessar”. A Bright Data garante que suas aplicações de IA funcionem de forma confiável em todas as fontes de dados.
Taxas de sucesso anti-bot e anti-scraping
Os sites modernos implantam várias camadas de proteção:
- Gerenciamento de bots da Cloudflare
- Análise comportamental da DataDome
- Impressão digital de dispositivos da PerimeterX
- Implementações personalizadas de CAPTCHA
- Limitação de taxa e bloqueio de IP
O Firecrawl lida com proteções comuns por meio do modo furtivo integrado. A plataforma funciona de maneira confiável em 96% dos sites sem configuração adicional. Quando encontra proteção avançada, ela falha, deixando uma lacuna na cobertura.
Para projetos básicos de IA que coletam conteúdo desprotegido, isso pode ser suficiente. Para aplicações de IA em produção, 96% de confiabilidade significa 4% de falhas. Esses 4% geralmente incluem suas fontes de dados mais críticas.
O Web Unlocker da Bright Data garante o acesso por meio de:
- Resolução automática de CAPTCHA
- Rotação de impressão digital do navegador
- Randomização de impressão digital TLS
- Imitação de padrões comportamentais que derrotam a detecção avançada
- Rotação de IPs residencialis a partir de mais de 150 milhões de endereços que aparecem como usuários reais
Para aplicações de IA, essa é a diferença entre uma demonstração e a produção. Ao construir sistemas RAG, seus usuários não se importam com sua taxa de sucesso de 96%. Eles se importam com o fato de que sua consulta específica falhou. A infraestrutura da Bright Data garante que suas aplicações de IA forneçam respostas confiáveis de qualquer fonte.
A plataforma vem derrotando técnicas sofisticadas de anti-scraping há mais de uma década. Esta é uma infraestrutura testada em batalha na qual os desenvolvedores de IA podem confiar.
Experiência do desenvolvedor e integração
Tempo de integração do Firecrawl: menos de 5 minutos para a configuração básica. A documentação da API é clara, os exemplos são abundantes e a comunidade oferece suporte por meio do GitHub Discussions e do Discord.
A Bright Data oferece vários caminhos de integração:
- Caminho simples (servidor MCP): 5 a 10 minutos para conectar agentes de IA por meio do Model Context Protocol. Tão fácil quanto o Firecrawl, mas com recursos empresariais
- APIs pré-construídas: 15 a 30 minutos para integrar Scrapers de domínios específicos (LinkedIn, Amazon, etc.)
- Configuração personalizada: 30 a 60 minutos para organizações que exigem controle preciso
A principal diferença: a Bright Data se adapta às suas necessidades. Comece de forma simples com o MCP Server e personalize quando os requisitos aumentarem. A simplicidade do Firecrawl se torna uma limitação quando você precisa de mais.
Para desenvolvedores de IA que criam sistemas RAG: o MCP Server da Bright Data oferece a mesma facilidade de uso do Firecrawl, sem nenhuma lacuna de cobertura. Seus agentes de IA obtêm dados limpos e estruturados por meio de uma interface simples, apoiada por uma infraestrutura que não falha em sites protegidos.
Para equipes empresariais: a documentação da Bright Data é abrangente e os clientes recebem equipes de suporte dedicadas e arquitetos de soluções. Você não fica sozinho na resolução de problemas quando os sistemas de IA de produção precisam de ajuda.
Preços e estrutura de custos
Os modelos de preços revelam filosofias diferentes: o Firecrawl é otimizado para projetos pequenos, enquanto a Bright Data oferece valor em todas as escalas.
A Firecrawl usa preços transparentes baseados em créditos:
| Plano | Preço | Créditos | Ideal para |
|---|---|---|---|
| Gratuito | $0 | 500 (único) | Teste e avaliação |
| Hobby | $19/mês | 3.000 | Desenvolvedores individuais |
| Padrão | $99/mês | 100.000 | Startups e equipes pequenas |
| Crescimento | $399/mês | 500.000 | Empresas em crescimento |
| Empresas | Personalizado | Personalizado | Operações em grande escala |
A Bright Data oferece preços flexíveis para todos os casos de uso:
- Servidor MCP: nível GRATUITO com 5.000 solicitações/mês para agentes de IA e sistemas RAG
- Proxies residenciais: a partir de US$ 5,04/GB (promoção com 50% de desconto: US$ 2,52/GB)
- API Web Scraper: a partir de US$ 0,001/registro (25% de desconto: US$ 0,00075/registro)
- Web Unlocker: a partir de US$ 1/1.000 solicitações
- Navegador de scraping: a partir de US$ 5/GB
Especificamente para aplicações de IA: o nível MCP Server gratuito da Bright Data (5.000 solicitações/mês) oferece mais valor do que a versão de avaliação de 500 créditos da Firecrawl. Você pode criar e testar sistemas RAG de produção sem pagar nada.
Em grande escala, a Bright Data se torna significativamente mais econômica:
| Caso de uso | Custo do Firecrawl | Custo da Bright Data | Vencedor |
|---|---|---|---|
| Prototipagem de agente de IA | $0 (500 créditos) | $0 (5.000 solicitações MCP) | Bright Data (10 vezes mais testes) |
| Sistema RAG básico (10 mil páginas/mês) | $19 | $7-15 | Bright Data |
| RAG de produção (100 mil páginas/mês) | $99 | $30-60 | Bright Data |
| IA empresarial (mais de 1 milhão de páginas/mês) | $399 | $100-300 | Bright Data (com maior confiabilidade) |
| Acesso protegido ao site | Frequentemente falha (incluído no custo do crédito) | Sucesso garantido | Bright Data (única opção) |
Custo total de propriedade para aplicações de IA:
| Fator de custo | Firecrawl | Bright Data |
|---|---|---|
| Preço base | Transparente | Flexível |
| Acesso a sites protegidos | Falhas (nenhum preço resolve isso) | Garantido |
| Falhas do agente de IA | 4% dos sites críticos | <0,01% |
| Falhas no tempo de processamento do desenvolvedor | Alta | Mínimo |
| Dados multimodais | Não disponível | Incluído (API de arquivo) |
| Confiabilidade de produção | 96 | 99,99% |
Para sistemas de IA de produção: os 4% dos sites aos quais o Firecrawl não consegue acessar geralmente incluem as fontes de dados mais valiosas. Os preços da Bright Data incluem acesso garantido. Você não está pagando a mais, está obtendo o que os aplicativos de IA realmente precisam.
Análise de caso de uso
Ideal para sistemas RAG de produção: Bright Data
A construção de sistemas RAG (Retrieval Augmented Generation) para produção requer acesso garantido aos dados, não apenas formatação limpa. Quando os usuários consultam seu assistente de IA, eles esperam respostas, independentemente de o site de origem usar a proteção Cloudflare.
Por que a Bright Data é a melhor opção para RAG de produção:
Acesso garantido a todas as fontes de conhecimento: os sistemas RAG são tão bons quanto sua recuperação de conhecimento. A taxa de sucesso de 99,99% da Bright Data garante que sua IA possa responder a perguntas de qualquer fonte, incluindo os 4% dos sites que bloqueiam ferramentas mais simples. Isso inclui LinkedIn, principais plataformas de comércio eletrônico, documentação SaaS empresarial e fontes de dados financeiros.
Confiabilidade de nível empresarial: 99,99% de tempo de atividade com SLAs significa que seu sistema RAG fornece respostas consistentes. Ao criar assistentes de IA para aplicativos voltados para o cliente, você não pode ter “desculpe, não posso acessar essas informações no momento” como uma resposta aceitável.
Servidor MCP para integração rápida: o Model Context Protocol Server da Bright Data oferece a mesma integração amigável para desenvolvedores que o Firecrawl, mas com o respaldo de uma infraestrutura que não falha. Comece a prototipar com 5.000 solicitações/mês gratuitas e, em seguida, expanda para a produção de maneira integrada.
Agregação de conhecimento de várias fontes: Scrapers pré-construídos para mais de 100 plataformas importantes fornecem dados estruturados e prontos para IA de diversas fontes. Seu sistema RAG pode extrair informações de perfis do LinkedIn, avaliações da Amazon, discussões no Twitter e sites de documentação, tudo por meio de APIs unificadas.
Todo o pipeline fornece dados limpos e estruturados para sistemas RAG com confiabilidade empresarial, não uma cobertura de 96% que falha em fontes críticas.
Impacto real no cliente: empresas de IA que utilizam a Bright Data para sistemas RAG relatam taxas de sucesso de consulta de 99,99% contra 92-96% com ferramentas mais simples. Essa diferença de 3-8% de falhas se traduz em milhares de usuários frustrados recebendo respostas do tipo “não tenho essa informação”.
Melhor para operações de IA empresarial: Bright Data
As empresas da Fortune 500 têm requisitos que vão além das capacidades técnicas: certificações de conformidade, trilhas de auditoria, SLAs e confiabilidade comprovada em grande escala.
Por que a Bright Data é essencial para a IA empresarial:
Infraestrutura de conformidade: a certificação SOC 2 Tipo II, a Conformidade com GDPR, a adesão ao CCPA e as certificações ISO satisfazem até mesmo os requisitos de aquisição mais rigorosos. Aplicações de IA em serviços financeiros, saúde e governo exigem essa documentação. A conformidade em andamento da Firecrawl não é suficiente.
Escala comprovada na Fortune 500: o processamento de mais de 650 petabytes mensais em mais de 20.000 clientes demonstra excelência operacional. Quando seus sistemas de IA monitoram milhões de pontos de dados, processam inteligência competitiva ou alimentam chatbots voltados para o cliente, você precisa de uma infraestrutura que não falhe.
A garantia de 99,99% de tempo de atividade com contratos de SLA garante a confiabilidade para operações de IA de missão crítica. Quando as decisões de negócios dependem de insights alimentados por IA, o tempo de inatividade não é aceitável.
O suporte de primeira linha inclui gerentes de conta dedicados, arquitetos de soluções e suporte técnico 24 horas por dia, 7 dias por semana. As equipes de IA corporativa recebem assistência prática com implementação, otimização e solução de problemas.
Precisão geográfica: 195 países com segmentação até o nível de cidade ou CEP permitem que aplicativos de IA acessem dados específicos da região. Os mais de 150 milhões de Proxies residenciais da Bright Data fornecem a cobertura global necessária para as operações de IA empresarial.
Ideal para treinamento de IA multimodal: Bright Data
O treinamento de modelos modernos de IA requer diversos tipos de dados além do texto: imagens, vídeo, áudio e contexto histórico.
A API de arquivo da Bright Data fornece acesso a mais de 50 petabytes de dados históricos da Internet, incluindo:
- Imagens e gráficos de bilhões de páginas da web
- Conteúdo de vídeo para treinamento em visão computacional
- Arquivos de áudio para modelos de reconhecimento de fala
- Versões históricas de sites que mostram mudanças ao longo do tempo
Essa capacidade multimodal é exclusiva da Bright Data. O Firecrawl otimiza apenas a extração de texto, tornando-o inadequado para projetos que exigem dados de treinamento visual ou de áudio.
Os serviços de anotação melhoram ainda mais a qualidade dos dados de treinamento. A Bright Data pode rotular e categorizar dados usando assistência de IA ou anotadores humanos, produzindo Conjuntos de dados de alta qualidade para aprendizado supervisionado.
Para desenvolvedores de modelos de IA: você não pode treinar modelos multimodais sofisticados com ferramentas apenas de texto. A Bright Data fornece a infraestrutura de dados completa para o desenvolvimento de IA de última geração.
Ideal para agentes de IA que exigem acesso confiável: Bright Data
A IA conversacional e os agentes autônomos precisam de acesso instantâneo às informações atuais da web com sucesso garantido, não apenas velocidade em alvos fáceis.
A infraestrutura da Bright Data para agentes de IA permite:
- Recuperação de conhecimento em tempo real de qualquer site (incluindo os protegidos)
- Agentes de IA que não falham ao encontrar a proteção Cloudflare
- Navegação autônoma em fluxos de trabalho complexos e com várias etapas
- Acesso a dados geográficos específicos para assistentes de IA com reconhecimento de localização
- Coleta simultânea de dados de várias fontes em escala
O servidor MCP fornece aos agentes de IA automação do navegador, Resolução de CAPTCHA e rotação de Proxy residencial automaticamente. Seu agente descreve o que precisa, e a infraestrutura da Bright Data garante que ele obtenha.
O agente lida com navegação, paginação e desafios antibot automaticamente com uma infraestrutura que não falha.
A vantagem competitiva: os agentes de IA criados com a Bright Data fornecem respostas confiáveis de qualquer fonte. Os agentes criados com ferramentas mais simples informam aos usuários “Não consegui acessar essa informação” 4% das vezes, geralmente nas consultas mais valiosas.
Quando escolher o Firecrawl
Escolha o Firecrawl quando seu projeto priorizar:
Configuração mínima em vez de recursos abrangentes. Se você precisa de scraping básico para sites simples e desprotegidos, a API simplificada do Firecrawl reduz o tempo de configuração.
Experimentação em pequena escala em vez de confiabilidade de produção. Para projetos pessoais, exercícios de aprendizagem ou protótipos básicos que processam menos de 100 mil páginas por mês de sites desprotegidos.
Extração somente de texto em vez de dados multimodais. Quando você não precisa de imagens, vídeo, áudio ou dados históricos para treinamento de IA.
Aplicações básicas de IA em vez de requisitos empresariais. Projetos que não precisam de certificações de conformidade, suporte dedicado ou SLAs garantidos.
Taxa de falha aceitável. Se 96% de sucesso for suficiente e você puder aceitar que 4% das fontes de dados fiquem inacessíveis, geralmente os sites protegidos mais valiosos.
Casos de uso ideais do Firecrawl:
- Experimentos pessoais de IA e projetos de aprendizagem
- Monitoramento básico da web de sites desprotegidos
- Agregação de conteúdo de blogs simples e sites de notícias
- Protótipos de prova de conceito antes do desenvolvimento da produção
- Aplicações não críticas em que falhas ocasionais são aceitáveis
Quando escolher a Bright Data
Escolha a Bright Data quando seu projeto exigir:
Infraestrutura de IA de nível de produção. Ao criar sistemas RAG, agentes de IA ou aplicativos LLM dos quais os usuários dependem, você precisa de acesso garantido aos dados, não de 96% de cobertura.
Acesso confiável a sites protegidos. Quando sua IA precisa de dados do LinkedIn, das principais plataformas de comércio eletrônico, de sites SaaS empresariais ou de qualquer fonte que use proteção Cloudflare, DataDome ou PerimeterX.
Confiabilidade empresarial para aplicativos de IA. O SLA com 99,99% de tempo de atividade garante que seus chatbots, ferramentas de pesquisa e sistemas automatizados com IA funcionem de maneira consistente. Operações de IA de missão crítica não podem tolerar taxas de falha de 4%.
Treinamento de IA multimodal. A API de arquivo com mais de 50 petabytes, incluindo vídeo, áudio e imagens, oferece suporte ao treinamento de modelos sofisticados de IA além de aplicativos baseados em texto.
Escalabilidade do protótipo à produção. Comece com o nível MCP Server gratuito (5.000 solicitações/mês) e escale facilmente para milhões de solicitações sem trocar de plataforma ou reconstruir a infraestrutura.
Conformidade para setores regulamentados. Organizações de serviços financeiros, saúde ou governo que exigem SOC 2 Tipo II, GDPR e certificações específicas do setor.
Precisão geográfica. Aplicações de IA que necessitam de dados específicos de cada região em 195 países, com segmentação ao nível da cidade.
Casos de uso ideais do Bright Data:
- Sistemas RAG de produção que exigem taxas de sucesso de consulta de 99,99%.
- Agentes de IA corporativos que acessam sites protegidos automaticamente
- Treinamento de IA multimodal com dados de texto, imagem, vídeo e áudio
- Aplicações de IA voltadas para o cliente, nas quais falhas não são aceitáveis
- Inteligência competitiva Monitoramentode IA em sites protegidos de concorrentes
- Sistemas de IA financeira que exigem conformidade e precisão de dados
- Ferramentas de IA de pesquisa que agregam dados de diversas fontes protegidas
- IA de comércio eletrônico que acessa preços em tempo real das principais plataformas
Soluções alternativas a considerar
Embora a Bright Data forneça uma infraestrutura de IA abrangente e a Firecrawl ofereça scraping básico simplificado, outras plataformas preenchem nichos específicos:
Para usuários sem código: o Octoparse oferece fluxos de trabalho visuais de scraping sem programação. Analistas de negócios podem configurar Scrapers básicos por meio de interfaces do tipo apontar e clicar. Compromisso: falha em sites protegidos e carece de otimização de IA.
Para controle de código aberto: o Crawl4AI oferece scraping gratuito e auto-hospedado com integração LLM. Ideal para desenvolvedores que priorizam o custo em detrimento da confiabilidade. Compromisso: você lida com toda a infraestrutura, manutenção, desafios anti-bot e falhas.
Para complexidade gerenciada: a API Zyte (anteriormente Scrapy Cloud) combina APIs fáceis de usar para desenvolvedores com tratamento automático anti-bot. Posicionada entre a simplicidade do Firecrawl e os recursos abrangentes do Bright Data.
Para abordagem de mercado: o Apify oferece milhares de atores pré-construídos, além de infraestrutura de execução em nuvem. Um meio-termo para equipes que desejam alguma personalização sem infraestrutura abrangente.
Para priorizar a conformidade: a Oxylabs enfatiza a extração ética e a conformidade empresarial semelhante à Bright Data, mas com redes de Proxy menores e recursos menos abrangentes.
Saiba mais em nosso guia: As 7 melhores alternativas ao Firecrawl para Scraping de dados de IA na web
Conclusão
A escolha entre Firecrawl e Bright Data não se resume a “simples x complexo”. Trata-se de demonstração x produção.
O Firecrawl funciona para protótipos básicos em sites desprotegidos. A API simplificada reduz o tempo de configuração inicial para projetos de aprendizagem e experimentos pessoais, nos quais 96% de sucesso é aceitável.
A Bright Data alimenta aplicativos de IA de produção dos quais os usuários dependem. Os mais de 150 milhões de Proxies residenciais da plataforma, 99,99% de tempo de atividade, servidor MCP para agentes de IA e acesso garantido a sites protegidos a tornam essencial para sistemas RAG, agentes de IA e aplicativos empresariais onde falhas não são aceitáveis.
Especificamente para desenvolvedores de IA: o nível gratuito do servidor MCP da Bright Data (5.000 solicitações/mês) oferece mais valor do que a versão de avaliação de 500 créditos do Firecrawl. Você pode criar protótipos e testar sistemas RAG de produção sem pagar nada, com o respaldo de uma infraestrutura que não falhará quando você escalar.
O mercado de scraping de dados evoluiu: simplicidade por si só não é suficiente para aplicativos de IA de produção. Você precisa de acesso garantido a todas as fontes de dados, não apenas a 96% delas.
Pronto para começar?
Experimente o nível MCP Server gratuito da Bright Data com 5.000 solicitações mensais. Perfeito para construir e testar sistemas RAG e agentes de IA sem custo.
Explore nossa plataforma abrangente de dados para IA com Web Scraper API, Web Unlocker, Archive API e Navegador de scraping para ver por que as principais empresas de IA escolhem a Bright Data para aplicativos de produção.
Startups em estágio inicial podem começar a criar protótipos com nosso nível gratuito. À medida que os projetos crescem, a Bright Data se adapta perfeitamente do protótipo à produção. Sem troca de plataforma, sem necessidade de reconstrução, sem lacunas de cobertura.
Está criando aplicativos de IA de produção? Inscreva-se para receber recomendações personalizadas e orientação de arquitetura para seus requisitos específicos de sistema RAG ou agente de IA.
Perguntas frequentes
Qual é a principal diferença entre Firecrawl e Bright Data?
O Firecrawl é uma API de scraping simplificada que fornece Markdown limpo de sites desprotegidos (96% de cobertura). A Bright Data é uma plataforma de dados de IA abrangente com mais de 150 milhões de Proxies, taxas de sucesso de 99,99% e integração com o MCP Server, projetada para sistemas RAG de produção e agentes de IA que exigem acesso garantido a todos os sites.
A diferença crítica: o Firecrawl funciona até encontrar proteção. O Bright Data funciona em todos os lugares, incluindo os 4% dos sites (geralmente os mais valiosos) que bloqueiam ferramentas mais simples.
Qual é melhor para sistemas de IA e RAG?
A Bright Data é superior para sistemas de IA e RAG de produção devido ao acesso garantido a sites protegidos, 99,99% de confiabilidade, servidor MCP para agentes de IA e nível gratuito (5.000 solicitações/mês) para prototipagem. A Bright Data garante que seu sistema RAG possa recuperar conhecimento de qualquer fonte, incluindo LinkedIn, plataformas de comércio eletrônico e sites corporativos que bloqueiam ferramentas mais simples.
O Firecrawl funciona para protótipos RAG básicos em sites desprotegidos, mas deixa uma lacuna de cobertura de 4% que muitas vezes inclui as fontes de dados mais valiosas. Para aplicações de IA de produção em que os usuários dependem de respostas confiáveis, a infraestrutura da Bright Data é essencial.
O que é mais barato, Firecrawl ou Bright Data?
A Bright Data é mais econômica em todas as escalas:
- Nível gratuito: a Bright Data oferece 5.000 solicitações MCP/mês contra 500 créditos do Firecrawl (10 vezes mais testes gratuitos)
- Pequenos projetos (10 mil a 100 mil páginas/mês): a Bright Data custa US$ 7 a US$ 60, contra US$ 19 a US$ 99 do Firecrawl
- Escala empresarial (mais de 1 milhão de páginas/mês): a Bright Data custa US$ 100-300, contra US$ 333+ do Firecrawl, com melhor confiabilidade
- Sites protegidos: apenas a Bright Data fornece acesso. O Firecrawl falha independentemente do preço
O custo total de propriedade favorece o Bright Data, pois você obtém acessibilidade E acesso garantido. O preço mais baixo do Firecrawl não importa quando ele não consegue acessar fontes de dados críticas.
Os iniciantes podem criar aplicativos de IA com o Bright Data?
Sim. O servidor MCP da Bright Data oferece a mesma facilidade de uso que o Firecrawl. Conecte-se em 5 a 10 minutos com o plano gratuito (5.000 solicitações/mês). A diferença: você obtém recursos de nível empresarial sem complexidade.
Comece de forma simples e expanda quando necessário. Iniciantes podem usar Scrapers pré-construídos e integração MCP sem configuração. Usuários avançados podem personalizar quando os requisitos aumentarem.
Qual tem melhores taxas de sucesso em sites protegidos?
A Bright Data atinge taxas de sucesso de 99,99% em sites protegidos usando o Web Unlocker e mais de 150 milhões de IPs residencialis. A plataforma lida com Cloudflare, DataDome, PerimeterX e sistemas anti-bot personalizados que bloqueiam ferramentas mais simples.
O Firecrawl atinge 96% de cobertura, mas falha em sites protegidos, que geralmente incluem as fontes de dados mais valiosas para aplicativos de IA: LinkedIn, principais plataformas de comércio eletrônico, documentação empresarial, dados financeiros.
Para sistemas de IA de produção, 96% de confiabilidade significa que 4% das consultas dos usuários falham. A Bright Data garante que sua IA forneça respostas confiáveis de qualquer fonte.
Ambas as plataformas suportam renderização JavaScript?
Sim, mas com confiabilidade diferente. Ambas lidam com sites pesados em JavaScript com carregamento de conteúdo dinâmico.
O Firecrawl renderiza JavaScript automaticamente para sites desprotegidos.
A Bright Data fornece o Navegador de scraping com automação completa do navegador e Proxies residenciais, garantindo que a renderização de JavaScript funcione mesmo em sites protegidos com detecção sofisticada.
Posso usar as duas plataformas juntas?
Embora seja possível, a maioria das organizações considera que o MCP Server da Bright Data oferece tudo o que precisam: a simplicidade da API do Firecrawl e recursos empresariais. Começar com o plano gratuito da Bright Data (5.000 solicitações/mês) elimina a necessidade de mudar de plataforma mais tarde, quando você encontrar sites protegidos.
Se já estiver usando o Firecrawl, você pode complementá-lo com a Bright Data para sites protegidos. No entanto, a maioria das equipes se consolida na plataforma unificada da Bright Data para evitar o gerenciamento de vários serviços.
Recursos relacionados: