

Ao final deste artigo, você entenderá como:
- Usar o serviço Bright Data Google IA Scraper API
- Aproveitar o Skyvern para automação de tarefas
- Use o serviço Bright Data API com o Skyvern para automatizar tarefas na web.
- Combinar automação e feeds de dados para criar um assistente de comércio eletrônico.
- Recuperar automaticamente os detalhes dos produtos do carrinho
Vamos começar!
Aproveitando o serviço API da Bright Data
A base da automação do navegador é a capacidade de contornar desafios como CAPTCHA, bloqueios de IP e carregamento dinâmico da web. É aqui que a Bright Data se torna essencial.
Com o Scraper da Bright Data, que suporta mais de 120 domínios da web, a automação do navegador é mais eficiente e confiável. Ele gerencia desafios comuns de scraping, como bloqueios de IP, CAPTCHA, cookies e outras formas de detecção de bots.
Para começar, inscreva-se para um teste grátis e obtenha sua chave API e dataset_id para o domínio que deseja rastrear. Depois de ter isso, você estará pronto para começar.
Abaixo estão as etapas para recuperar dados atualizados de qualquer domínio, como o BBC News:
- Crie uma conta Bright Data, se ainda não o fez. Está disponível uma versão de avaliação gratuita.
- Acesse a página Web Scrapers. Em Web Scrapers Library, explore os modelos de Scrapers disponíveis.
- Procure o domínio de destino, como BBC News, e selecione-o.
- Na lista de scrapers da BBC News, selecione BBC News — coletar por URL. Esse scraper permite recuperar dados sem fazer login no domínio.
- Escolha a opção Scraper API. O No-Code Scraper ajuda a recuperar Conjuntos de dados sem código.
- Clique em API Request Builder e copie sua
chave API,BBC Dataset URLedataset_id. - A
chave APIeo dataset_idsão necessários para habilitar os recursos de automação em seu fluxo de trabalho. Eles permitem que você acesse os recursos da Bright Data diretamente durante a programação.
O que é o Skyvern
O Skyvern é uma ferramenta de automação de navegador com IA que usa inteligência artificial para automatizar tarefas em navegadores da web. Ele combina aprendizado de máquina, processamento de linguagem natural e visão computacional para lidar com ações complexas do navegador.
O Skyvern difere das ferramentas de automação tradicionais, como Selenium e Playwright, das seguintes maneiras:
- Adaptabilidade às mudanças na interface do usuário: as habilidades de autocorreção permitem que o Skyvern se adapte dinamicamente às mudanças na interface do usuário sem interromper os scripts.
- Complexidade do fluxo de trabalho: capaz de lidar com fluxos de trabalho de várias etapas com raciocínio de IA por meio de um único prompt.
- Reconhecimento visual: usa visão computacional para compreender e interagir visualmente com elementos da interface do usuário.
Com esses recursos, você pode usar o Skyvern para fazer login em sites de reservas, preencher formulários ou adicionar itens ao carrinho de compras. Quando integrado aos recursos de Scraping de dados da Bright Data, o Skyvern pode fornecer uma estrutura poderosa para atender a diversas necessidades de automação da web.
Fluxo de trabalho de automação
Por exemplo, se você deseja comprar uma peça de veículo em uma loja online, pode querer comparar as opções disponíveis e adicionar uma automaticamente ao seu carrinho. O fluxo de trabalho seria assim:
- A API Bright Data IA Scraper busca a descrição e os detalhes do produto, como o número da peça, do fabricante especificado.
- Você analisa o resultado e faz sua seleção. A Bright Data fornece recuperação rápida e confiável de dados da web.
- O Skyvern usa os detalhes recuperados da Bright Data para acessar o site finditparts.com. Em seguida, ele navega pelo site, adiciona o(s) produto(s) selecionado(s) ao carrinho e exibe os detalhes do carrinho e a URL do carrinho.
- Prossiga diretamente para o checkout e o pagamento.
Pré-requisitos
- Conhecimento básico de programação Python. Baixe o Python aqui
- Uma conta ativa na Bright Data. Inscreva-se aqui e recupere sua chave API no e-mail de boas-vindas
- Conhecimento básico de JSON e APIs REST
Configurando o projeto
Etapa 1: Configure o Bright Data
Recupere sua chave API da Bright Data, ID do conjunto de dados e URL do Google AI Mode seguindo as mesmas etapas descritas em Aproveitando o robusto serviço API da Bright Data para o seu caso de uso.
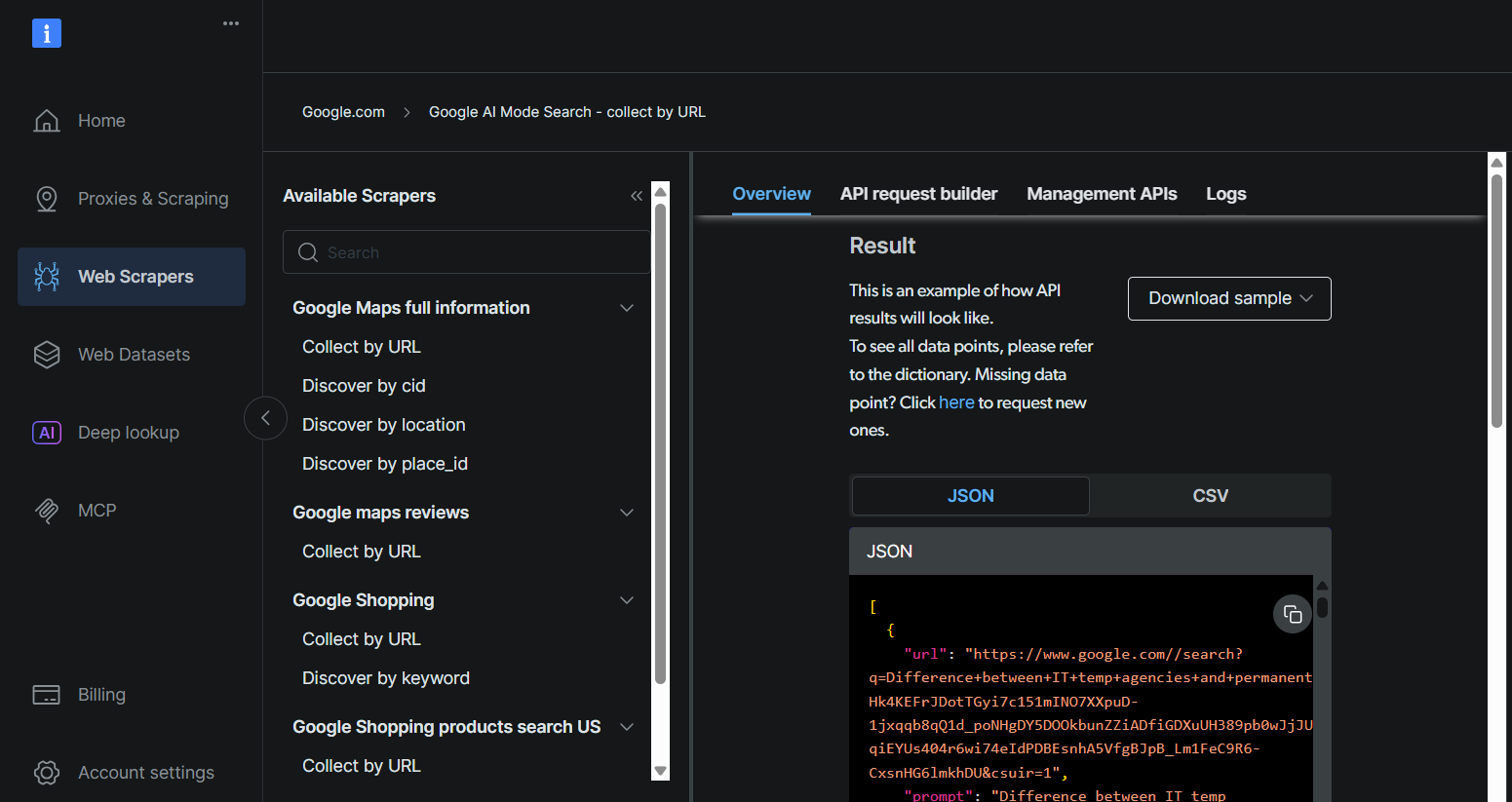
Etapa 2: Inscreva-se na Skyvern Cloud
- Acesse https://app.skyvern.com/ e inscreva-se para receber 5 dólares em créditos gratuitos.
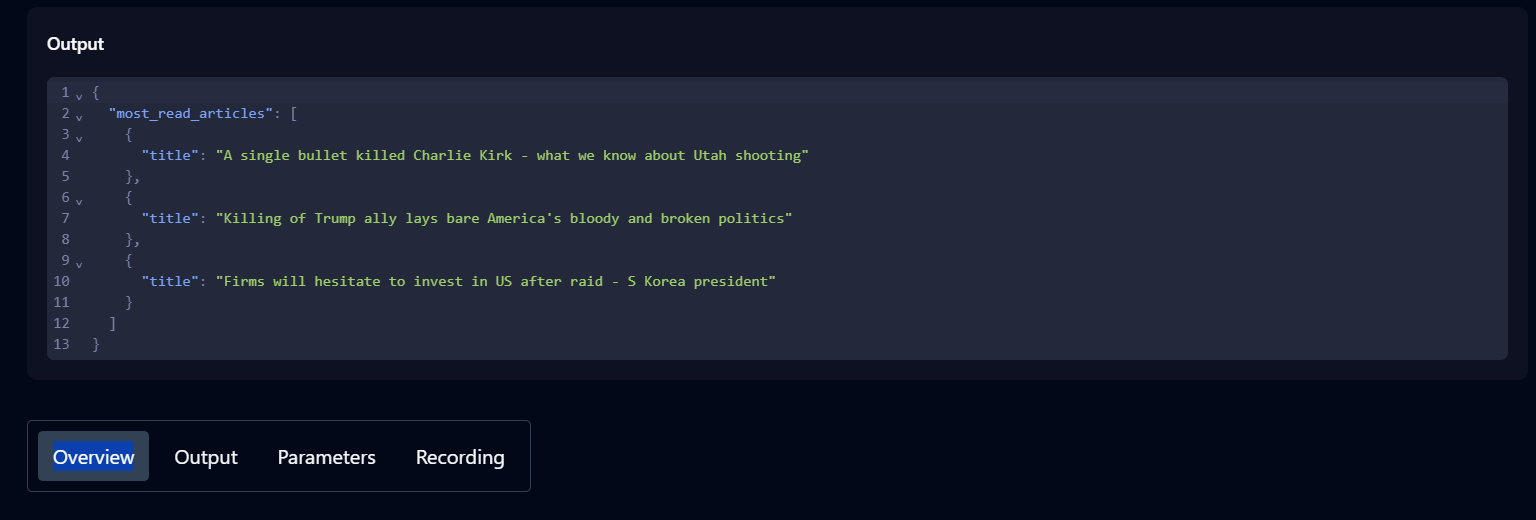
- Peça ao agente da Skyvern para executar uma tarefa para vê-la em ação. Por exemplo: navegue até a página inicial do Hacker News e recupere as três principais publicações.
- Verifique o histórico para acompanhar o andamento da tarefa. O status Concluído indica que a tarefa foi concluída com sucesso.
- Depois de concluída, clique na tarefa no histórico para ver o resultado, os parâmetros e detalhes adicionais sobre a tarefa.
Agora que o Skyvern está configurado, você pode começar a escrever seu script de código.
Etapa 3: instale o Skyvern em sua máquina
3.1 Crie um ambiente virtual
Na pasta do projeto desejado, crie um ambiente virtual com Python:
python -m venv .venv
Ative o ambiente.
.venvScriptsactivate
3.2 Instale o Skyvern em qualquer dispositivo com
pip install skyvern
Se você encontrar problemas de instalação, pode usar o terminal Ubuntu no Windows. Confira esta publicação para saber como configurar o terminal Ubuntu.
Depois que o terminal estiver em execução, navegue até o diretório desejado e execute:
pip install uvCrie um ambiente virtual com:
uv venv venvEm seguida, instale o Skyvern com:
uv pip install skyvern3.3 Início rápido do Skyvern
Quando a instalação estiver concluída, execute:
skyvern quickstart- Quando for solicitado “Deseja executar o Skyvern localmente ou na nuvem?”, digite “cloud”.
- Quando for solicitado “Digite a URL base do Skyvern”, pressione Enter.
- Digite “n” para todas as solicitações de instalação, exceto a solicitação MCP, onde você deve digitar “y”.
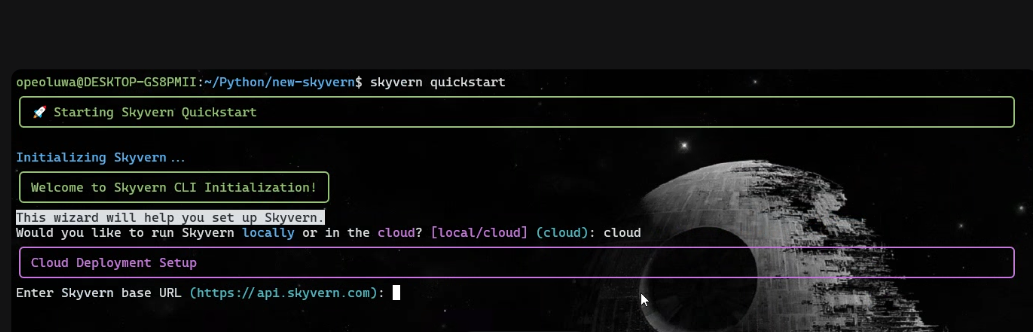
Após a configuração, execute:
skyvern initCrie um script Python chamado app.py.
Etapa 4: Recuperar detalhes do produto com Bright Data
4.1 Recupere o número da peça com o Bright Data usando este código no app.py:
import asyncio
import requests
import time
import json
def trigger_scraping_job(api_key, data):
"""
Aciona uma tarefa de Conjuntos de dados do Bright Data com uma lista de dicionários contendo url, prompt, país.
Retorna o snapshot_id se for bem-sucedido.
"""
endpoint = "https://api.brightdata.com/conjuntos_de_dados/v3/trigger"
params = {
"dataset_id": "gd_mcswdt6z2elth3zqr2", # Seu ID do conjunto de dados
"include_errors": "true",
}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(endpoint, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json().get("snapshot_id")
print(f"Solicitação bem-sucedida! ID do instantâneo: {snapshot_id}")
return snapshot_id
else:
print(f"Solicitação falhou! Status: {response.status_code}")
print(response.text)
return None
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
"""
Pesquise o endpoint do snapshot da Bright Data até que os dados estejam prontos.
Salve a resposta JSON em um arquivo de saída.
"""
snapshot_url = f"https://api.brightdata.com/conjuntos_de_dados/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Pesquisando snapshot para ID: {snapshot_id}...")
enquanto True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Instantâneo pronto. Baixando...")
snapshot_data = response.json()
com open(output_file, "w", encoding="utf-8") como arquivo:
json.dump(snapshot_data, file, indent=4)
print(f"Instantâneo salvo em {output_file}")
return
elif response.status_code == 202:
print(f"O instantâneo ainda não está pronto. Repetindo em {polling_timeout} segundos...")
time.sleep(polling_timeout)
else:
print(f"Solicitação falhou! Status: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "YOUR_BRIGHT_DATA_API_KEY" # Sua chave API
# Corresponda exatamente à estrutura de dados JSON do curl
data = [
{
"url": "https://google.com/aimode",
"prompt": "encontre o número de peça de uma vedação de roda em finditparts.com cujo fabricante seja SKF",
"country": ""
}
]
snapshot_id = trigger_scraping_job(BRIGHT_DATA_API_KEY, data)
if snapshot_id:
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "product.json")O prompt é: “encontre o número de peça de uma vedação de roda no site finditparts.com cujo fabricante seja a SKF”.
Isso criará um arquivo product.json contendo descrições de produtos e números de peças do fabricante SKF.
{
"url": "https://www.finditparts.com/products/16775486/skf-45093xt?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K16775486-L22",
"title": "www.finditparts.com",
"description": "Vedante de roda SKF 45093XT | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
{
"url": "https://www.finditparts.com/products/193780/cr-slash-skf-14115?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K193780-L1464",
"title": "www.finditparts.com",
"description": "Vedante de roda SKF 14115 | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
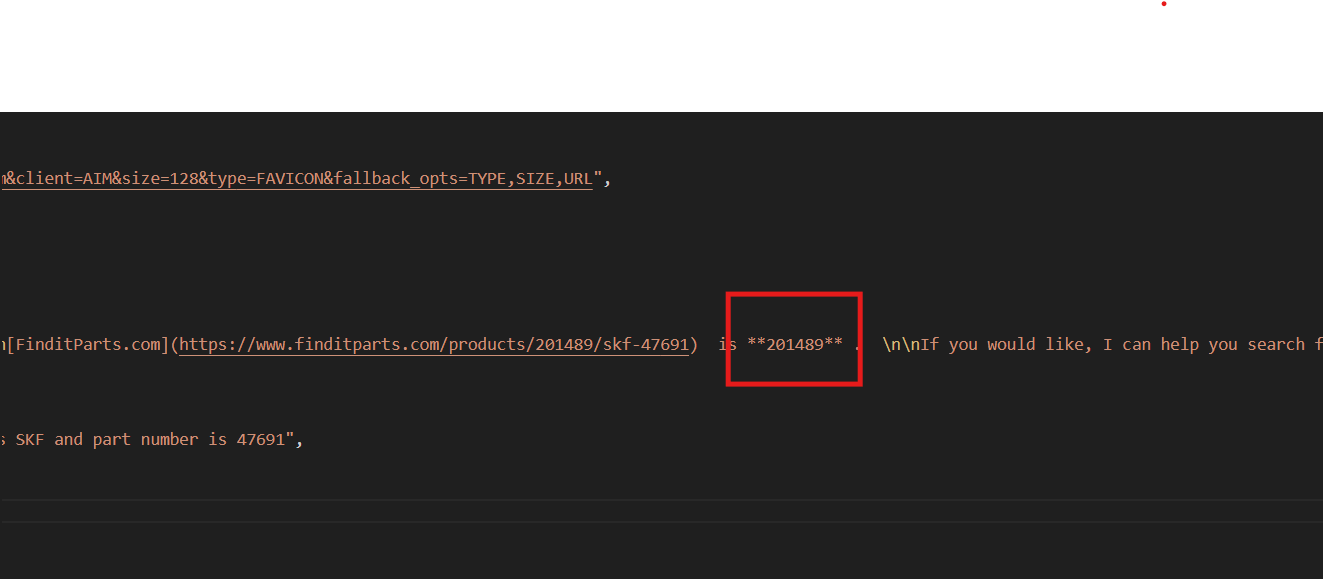
{Em seguida, escolha o número da peça de sua preferência (localizado na descrição) e execute novamente o código Bright Data com este prompt: “Encontre o ID do produto para o retentor de roda SKF com o número de peça 47691”.
# Corresponda exatamente à estrutura de dados JSON do curl
data = [
{
"url": "https://google.com/aimode",
"prompt": "Encontre o ID do produto para o vedante de roda SKF com o número de peça 47691",
"country": ""
}
]O Skyvern requer o ID do produto para adicionar detalhes ao carrinho no site finditparts.com (um site de comércio eletrônico de peças automotivas).
Esse processo irá gerar um arquivo product.json com o ID do produto desejado.
Etapa 5: Solicite as tarefas ao Skyvern
Primeiro, acesse https://app.skyvern.com/tasks/create/finditparts. Essa URL é um atalho para criar tarefas no Skyvern.
Clique em Configurações avançadas na seção Conteúdo básico e atualize o ID do produto e solicite seu caso de uso.
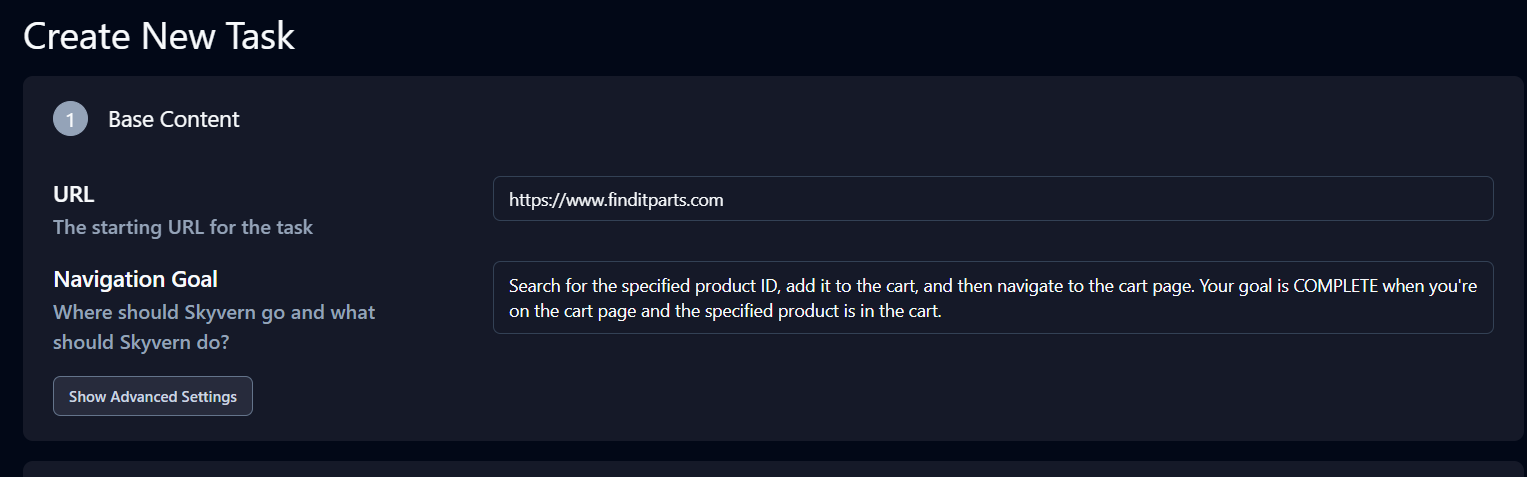
A solicitação é: “Pesquise o ID do produto especificado, adicione-o ao carrinho e navegue até a página do carrinho. Sua meta estará COMPLETA quando você estiver na página do carrinho e o produto especificado estiver no carrinho”.
A seção Extração abaixo de Configurações avançadas também é importante. Modifique a Meta de extração de dados para: “Extraia o URL da página do carrinho e todas as informações de quantidade do produto da página do carrinho”.
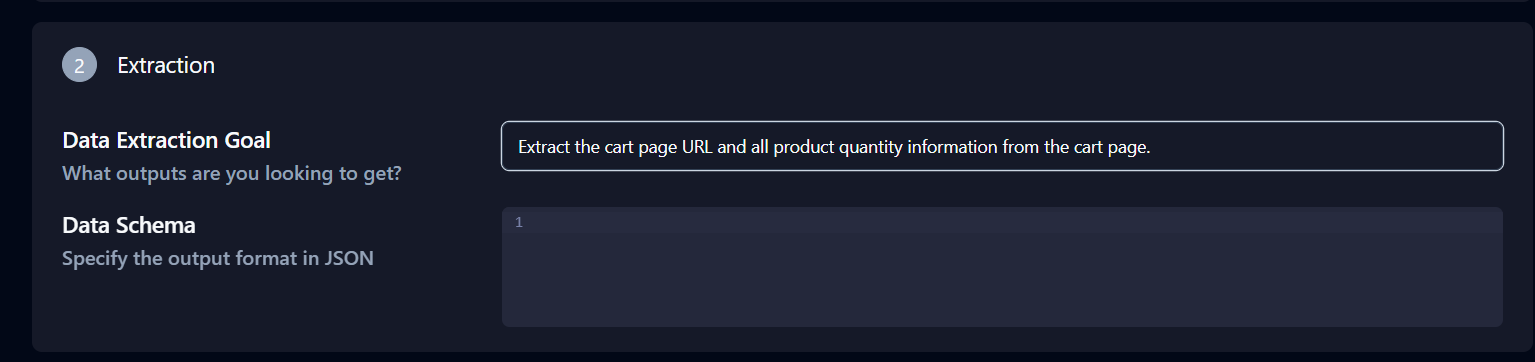
Clique em Copiar comando da API na parte inferior da página, cole-o no seu terminal e pressione Enter.
Isso criará um task_id no seu terminal e uma instância da tarefa na sua Skyvern Cloud. Você pode verificar o status em Histórico para ver se está na fila, em execução ou concluído.
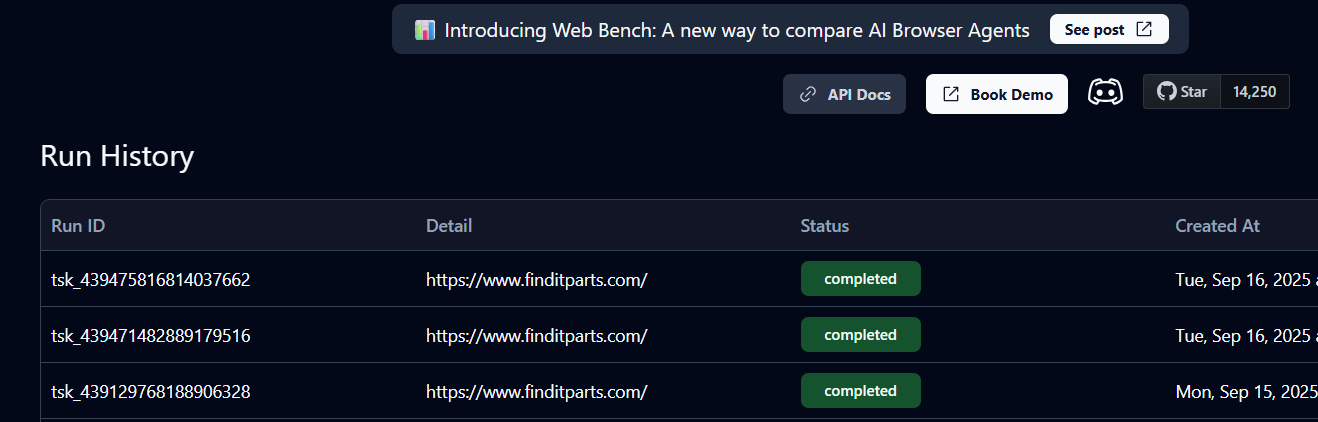
O status Concluída significa que a tarefa foi finalizada. Agora você pode visualizar os detalhes do carrinho e o URL do produto retornado pelo Skyvern.
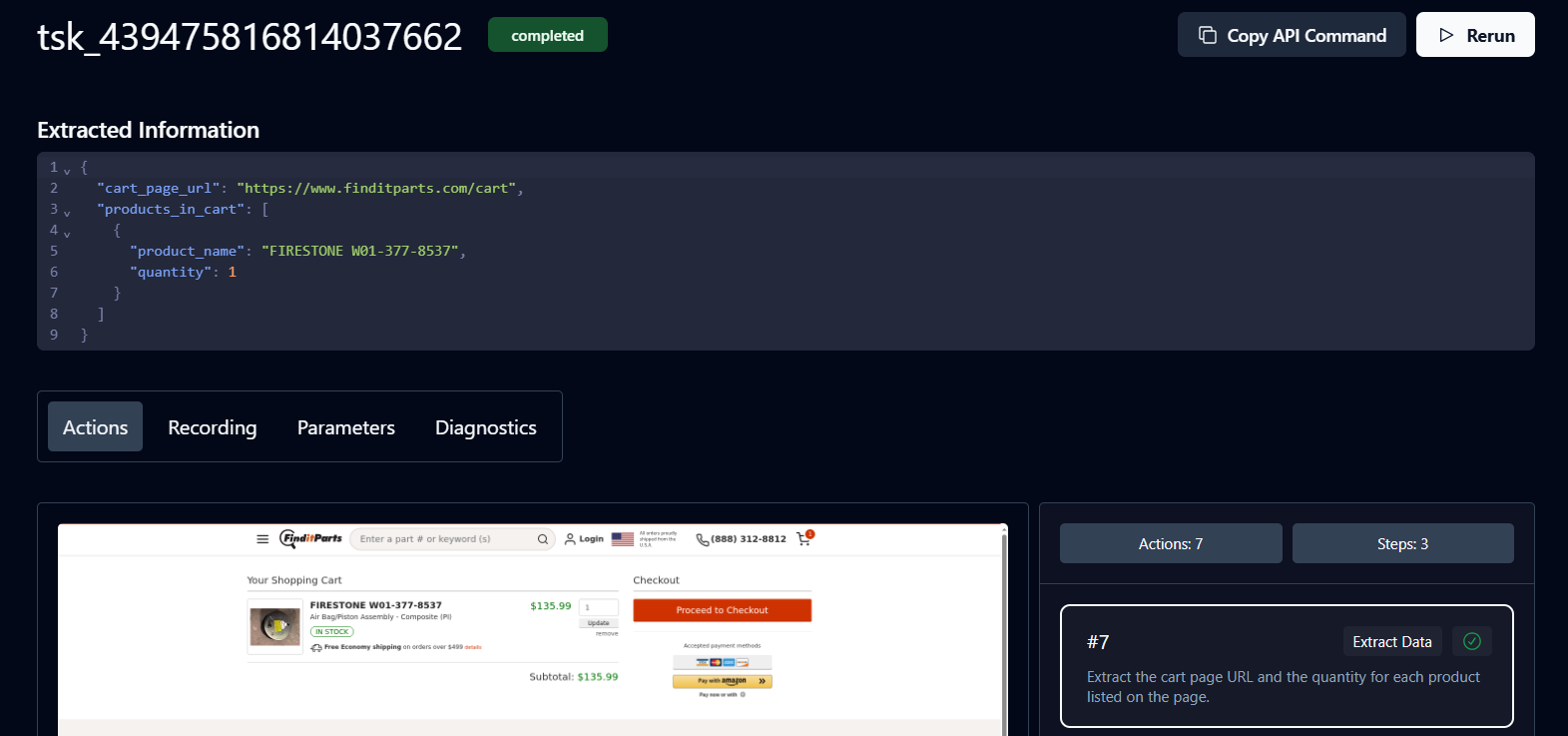
Parabéns. Seu fluxo de trabalho está concluído. Clique no URL para prosseguir com o pagamento.
A Bright Data elimina a necessidade de pesquisar manualmente os produtos online, trazendo as opções diretamente para o seu computador. Isso permite que você selecione o melhor produto e automatize o processo de compra com o Skyvern.
Próximos passos
Você pode expandir o fluxo de trabalho para incluir a adição de vários produtos ao carrinho para checkout e gerar um resumo de Processamento de Linguagem Natural (NLP) do total de produtos. Você também pode implantar o fluxo de trabalho na nuvem para monitoramento contínuo. Por fim, você pode integrá-lo ao Google Agenda para acompanhar os descontos.
Conclusão
Neste tutorial, você aprendeu como combinar a API Scraper da Bright Data com o Skyvern para automatizar o processo de localização e compra de produtos online. Além da API Scraper, a Bright Data oferece outras ferramentas que podem potencializar seus agentes de IA, como Conjuntos de dados prontos para uso, personalizados para comércio eletrônico, mídias sociais e muito mais, bem como o servidor Web MCP para automação avançada em várias etapas e acesso a mais de 40 ferramentas especializadas. Juntos, esses produtos facilitam a criação de fluxos de trabalho orientados por IA que podem coletar, analisar e agir sobre dados da web com eficiência.
Comece a explorar o conjunto completo da Bright Data para aprimorar seus projetos de automação de IA hoje mesmo.





