

Neste artigo, você aprenderá:
- O que é o Ruflo, seus principais recursos e capacidades, e suas maiores limitações.
- Como lidar com essas limitações usando uma solução de infraestrutura de dados da web pronta para IA, como a Bright Data.
- As duas principais maneiras de integrar a Bright Data e o Ruflo em uma configuração do Claude Code ou do OpenAI Codex.
- Como começar a usar o Ruflo configurando-o em um projeto local baseado no Claude Code.
- Como adicionar a pesquisa na web, a recuperação de dados e a interação com sites de nível empresarial da Bright Data à configuração via MCP.
- Como alcançar a mesma integração usando as habilidades do Bright Data Claude.
- O que essa configuração Ruflo + Bright Data possibilita em um assistente de codificação autônomo.
Vamos começar!
Uma introdução ao Ruflo: a plataforma de orquestração de agentes para o Claude
Em breve você verá como e por que combinar o Ruflo com os recursos de recuperação de dados e pesquisa na web da Bright Data. Mas, primeiro, reserve um momento para entender o que é o Ruflo e o que ele tem a oferecer!
O que é o Ruflo?
O Ruflo (anteriormente Claude Flow) é uma estrutura de orquestração de IA projetada para transformar o Claude Code (e o OpenAI Codex) em uma estrutura de orquestração multiagente rica em recursos.
Mais especificamente, ele equipa assistentes de codificação com um conjunto coordenado de cerca de 100 agentes de IA especializados que trabalham em paralelo. Isso permite que o Claude Code e o OpenAI Codex realizem tarefas de software complexas por meio de roteamento inteligente, memória compartilhada e fluxos de trabalho de autoaprendizagem.
Como um projeto de código aberto, o Ruflo possui mais de 27 mil estrelas no GitHub e mais de 6.000 commits. Esse rápido crescimento destaca a rapidez com que o Ruflo ganhou força na comunidade de desenvolvedores.
Como o Ruflo leva os assistentes de codificação com IA a um novo patamar
Em um nível geral, os principais recursos oferecidos pelo Ruflo são:
- Orquestração multiagente em escala: Implemente e coordene cerca de 100 agentes de IA especializados trabalhando em paralelo em tarefas complexas de desenvolvimento.
- Colaboração baseada em enxames: os agentes operam em “enxames” estruturados com coordenação hierárquica, mecanismos de consenso e objetivos compartilhados.
- Autoaprendizagem e roteamento adaptativo: aprende com execuções anteriores e roteia dinamicamente as tarefas para os agentes mais eficazes usando reconhecimento de padrões.
- Memória persistente e grafos de conhecimento: Combina pesquisa vetorial (HNSW), memória compartilhada e grafos de conhecimento para reter o contexto entre sessões.
- Otimização inteligente de custo e desempenho: Utiliza roteamento em múltiplas camadas (WASM + LLMs) para reduzir a latência e cortar custos de API em até ~75%.
- Suporte a múltiplos LLMs com failover: Funciona com Claude, GPT, Gemini e modelos locais, selecionando automaticamente o melhor provedor para cada tarefa.
- Segurança e extensibilidade prontas para produção: proteções integradas (injeção de prompt, validação) além de um sistema de plug-ins para estender agentes, hooks e fluxos de trabalho.
Isso leva a uma grande diferença ao comparar o Claude Code com e sem o Ruflo:
| Claude Code sozinho | Claude Code + Ruflo | |
|---|---|---|
| Colaboração entre agentes | Os agentes trabalham de forma independente | Os agentes colaboram com memória compartilhada |
| Coordenação | Gerenciamento manual de tarefas | Hierarquia liderada pela rainha com coordenação automatizada |
| Mente coletiva | Não disponível | Inteligência coletiva entre agentes |
| Consenso | Sem decisões multiagentes | Votação tolerante a falhas com regras de maioria |
| Memória | Apenas sessão | Memória vetorial persistente + gráfico de conhecimento |
| Banco de dados vetorial | Nenhuma | RuVector PostgreSQL, pesquisa rápida e alto QPS |
| Grafo de conhecimento | Listas planas | Destaca os principais insights usando PageRank e detecção de comunidades |
| Memória coletiva | Sem conhecimento compartilhado | Base de conhecimento compartilhada entre agentes |
| Aprendizado | Estático, sem adaptação | Autoaprendizagem com rápida adaptação e transferência de insights |
| Escopo do agente | Apenas um único projeto | Memória multinível (projeto/local/usuário) com transferência entre agentes |
| Roteamento de tarefas | Seleção manual de agente | Roteamento inteligente com base em padrões aprendidos |
| Tarefas complexas | Divisão manual necessária | Descomposição automática em vários domínios |
| Trabalhadores em segundo plano | Nenhum | Despacho automático em gatilhos como alterações de arquivos ou padrões |
| Provedor de LLM | Apenas Anthropic | Vários provedores com failover e otimização de custos |
| Segurança | Proteções padrão | Reforçado: validação, criptografia, mitigação de CVE |
| Desempenho | Referência | Mais rápido por meio de enxames paralelos e roteamento inteligente |
Principais limitações e como lidar com elas
Independentemente de quão ricos e versáteis sejam os cerca de 100 agentes e as capacidades gerais do Ruflo, existe uma limitação fundamental. Ela reside na própria natureza dos LLMs. Esses modelos são treinados em Conjuntos de dados estáticos que param em um ponto específico no tempo, o que limita inerentemente seu conhecimento.
É claro que o Ruflo inclui um agente de automação de navegador dedicado para pesquisa na web, interação e extração de dados. O problema é que a maioria dos sites hoje em dia possui sistemas anti-bot que bloqueiam solicitações automatizadas. Isso inclui solicitações provenientes de agentes de navegador impulsionados por IA. Assim, a recuperação de conhecimento do Ruflo pode falhar ou acessar apenas uma parte do conteúdo necessário.
Esse é um problema crítico, pois conhecimento preciso, atualizado e contextual é o que torna os sistemas multiagentes verdadeiramente eficazes. Para superar essa questão, seu assistente de codificação de IA precisa de ferramentas projetadas especificamente para pesquisa na web em tempo real, extração de dados e interação na web sem bloqueios.
É exatamente isso que a Bright Data oferece!
Ferramentas de dados da web da Bright Data como solução
Como a plataforma líder de dados da web no mercado, a Bright Data oferece ferramentas prontas para agentes de IA, tais como:
- API SERP: Reúna resultados de mecanismos de busca do Google, Bing e outros para alimentar respostas bem fundamentadas.
- API Web Unlocker: acesse HTML bruto ou Markdown de qualquer site, contornando CAPTCHAs, bloqueios de IP e medidas anti-bot.
- API do navegador: Controle programaticamente um navegador remoto para interação automatizada e desbloqueada com qualquer site.
- API de Scraping de dados: Colete dados estruturados de plataformas como Amazon, Instagram, LinkedIn, Yahoo Finance e muitas outras.
- API de rastreamento: Converta sites inteiros em Conjuntos de dados estruturados para fluxos de trabalho de IA posteriores.
O que diferencia a Bright Data é sua infraestrutura de nível empresarial. Construída sobre uma rede global de Proxies com mais de 400 milhões de IPs em 195 países, ela oferece escalabilidade ilimitada, mantendo 99,99% de tempo de atividade e uma taxa de sucesso de 99,95%.
A Bright Data trabalha em conjunto com a Ruflo para dar ao seu sistema de codificação agênica a capacidade de explorar, recuperar e raciocinar sobre dados da web em tempo real. Tudo isso, em escala e sem encontrar bloqueios!
Como combinar a Bright Data e o Ruflo: duas abordagens
Tecnicamente, você pode integrar o Bright Data diretamente ao Ruflo usando o SDK do plugin. Você precisaria definir ferramentas personalizadas que se conectem a cada produto do Bright Data que deseja usar. No entanto, essa não é a abordagem mais rápida!
Em vez de reinventar a roda, é muito mais fácil contar com:
- Bright Data Web MCP: Um servidor open-source completo que oferece mais de 60 ferramentas para pesquisa na web, navegação, extração de dados e interação sem bloqueios.
- Habilidades da Bright Data: recursos pré-construídos que ensinam seu agente de codificação a realizar scraping de dados, pesquisa e recuperação de dados estruturados com tecnologia de IA. Elas incluem uma conexão com o Web MCP.
Elas podem ser adicionadas diretamente ao Claude Code (ou OpenAI Codex), levando a uma configuração de codificação unificada que combina tanto o Ruflo quanto o Bright Data. O LLM subjacente pode então usar ferramentas de ambas as soluções de maneira coordenada e sinérgica.
Observação: os exemplos abaixo usam o Claude Code, mas você pode adaptá-los facilmente ao OpenAI Codex.
Agora vamos ver como ampliar o Claude Code com o Bright Data e o Ruflo usando o MCP ou habilidades. Mas primeiro, configure o Ruflo!
Introdução ao Ruflo
Siga as instruções abaixo para aprender como configurar o Ruflo em seu projeto de codificação.
Pré-requisitos
Para acompanhar esta seção, certifique-se de ter:
- O Claude Code instalado e configurado localmente.
- Node.js 20+ instalado localmente (recomenda-se a versão LTS mais recente).
Passo 1: Configure o Ruflo
Crie uma nova pasta para seu projeto de programação (por exemplo, bright-data-ruflo-project). É lá que você inicializará o Ruflo. Em seguida, acesse a pasta no seu terminal:
mkdir bright-data-ruflo-project
cd bright-data-ruflo-projectObservação: você também pode começar a partir de uma pasta de projeto existente. Na maioria dos casos, é isso que você fará. Você adicionará o Ruflo ao seu projeto para aproveitar seus recursos.
Execute o seguinte comando no seu terminal para iniciar o assistente de instalação do Ruflo via npm:
npx ruflo@latest init --wizardA instalação do pacote ruflo pode levar alguns minutos, portanto, seja paciente.
Esta é a saída que você deve obter: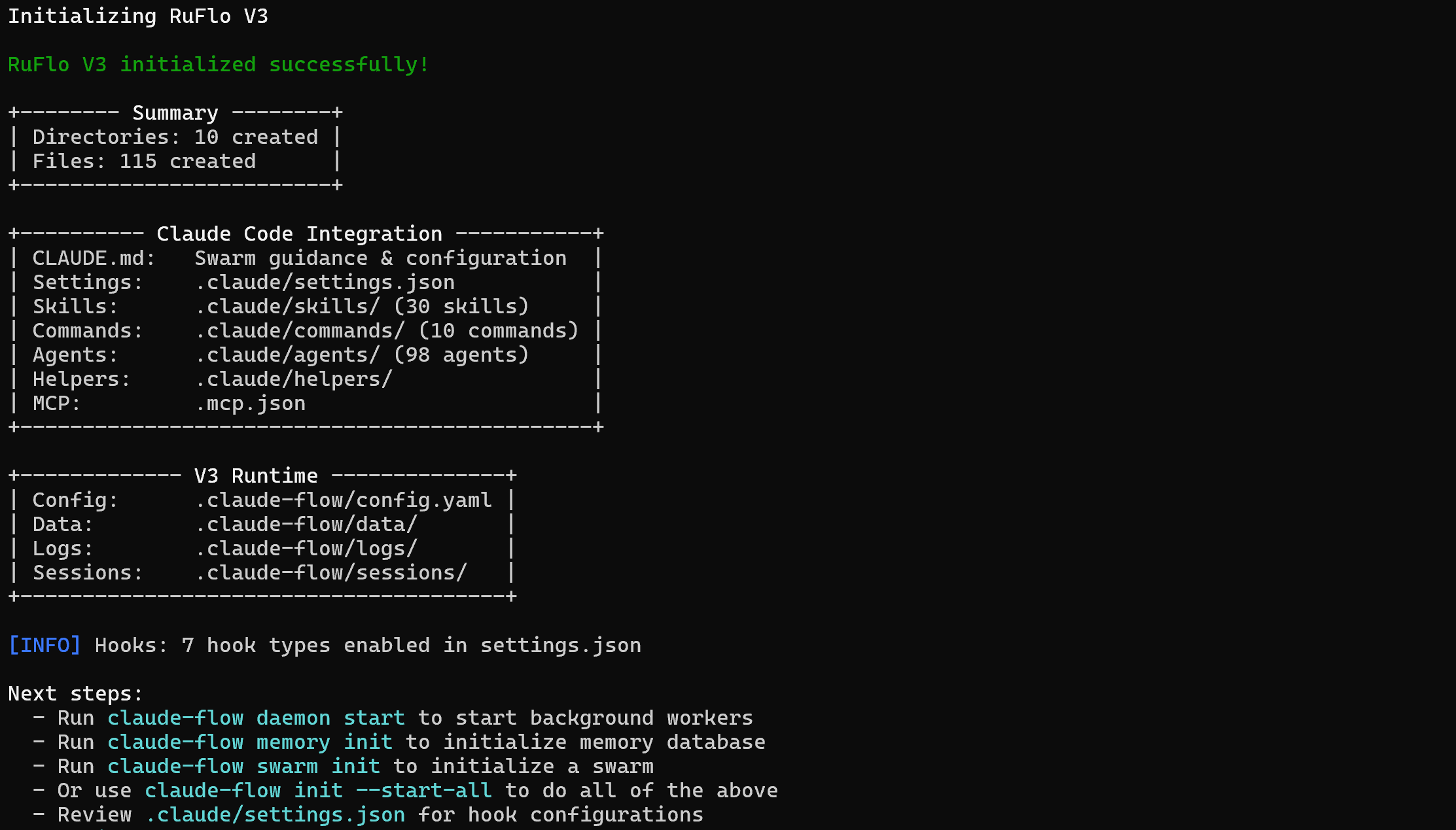
Nota: A saída na CLI pode sugerir o uso de comandos claude-flow para inicializar serviços de backend, bancos de dados em memória ou swarms. No entanto, isso não está correto. Ao instalar o Ruflo via npm, o comando básico correto é:
npx ruflo@latestA pasta do seu projeto agora armazenará:
bright-data-ruflo-project/
├─── .claude/
│ ├─── agents/
│ ├─── commands/
│ ├─── helpers/
│ └─── skills/
├─── .claude-flow/
├─── .swarm/
├─── .mcp.json
└─── CLAUDE.mdBasicamente, o bright-data-ruflo-project contém todos os arquivos de que o Claude Code precisa para acessar novas habilidades, comandos e agentes no nível do projeto. Em outras palavras, o Ruflo está totalmente integrado à sua configuração local do Claude Code. Muito bem!
Passo 2: Inicie o Ruflo
O Ruflo adicionou vários agentes, comandos e habilidades. No entanto, para que o Claude Code possa executá-los, você deve primeiro iniciar o Ruflo. Faça isso com:
npx ruflo@latest startVocê deve ver uma saída como esta: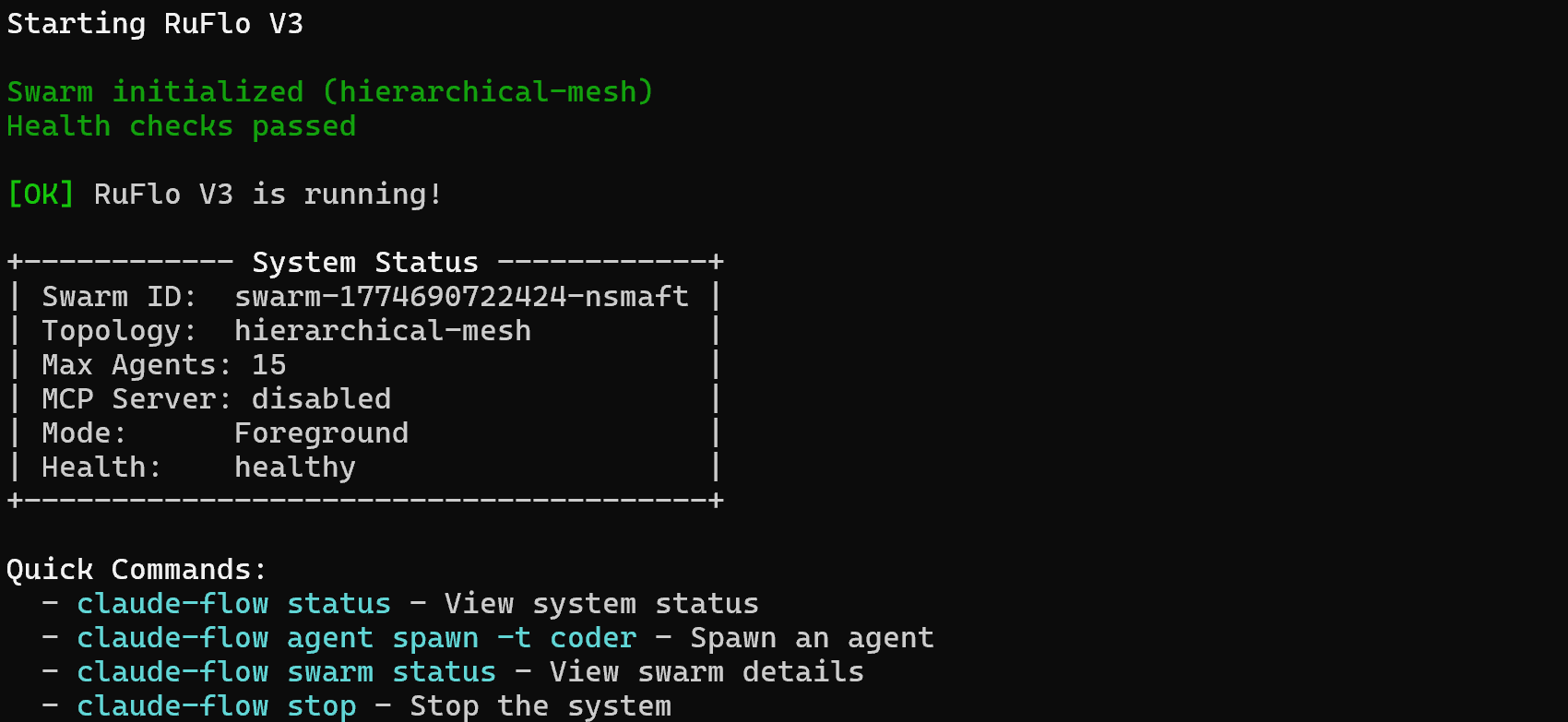
Fantástico! Sua configuração do Claude Code agora pode aproveitar a funcionalidade estendida fornecida pelo Ruflo.
Passo 3: Verifique a integração
No diretório do seu projeto, inicie o Claude Code:
claudeVocê pode receber uma mensagem como esta:
Selecione a opção 1 ou a opção 2. Dessa forma, o Claude Code iniciará o servidor Ruflo MCP e se conectará a ele ao ser iniciado.
Em seguida, você verá logs mostrando claramente que o Ruflo está disponível no Claude Code: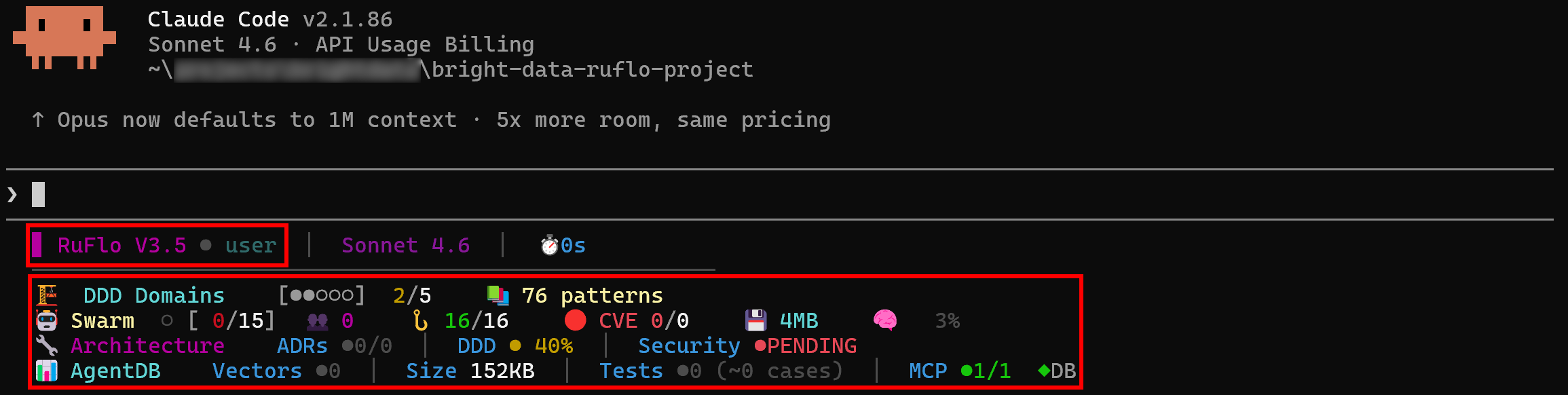
Digite “/agent” e você deverá ver alguns dos comandos adicionais do Ruflo:
Ótimo! O Claude Code se conectou com sucesso ao Ruflo, confirmando que a integração funciona.
Abordagem de integração nº 1: Ruflo MCP + Bright Data MCP
Nesta seção, você aprenderá como adicionar os recursos do Ruflo e do Bright Data à sua configuração do Claude Code via MCP.
Pré-requisitos
Para manter esta seção concisa, vamos supor que você já tenha integrado o Bright Data Web MCP à sua configuração do Claude Code.
Se você ainda não fez isso, siga o tutorial detalhado“Integrando o Claude Code com o Web MCP da Bright Data”ou o guia de documentação“Integração do servidor MCP do Claude Code”. Certifique-se apenas de adicionar a configuração necessária ao arquivo .mcp.json local criado pelo Ruflo durante o comando init.
Familiaridade com o funcionamento do MCP e com a forma de conectar servidores MCP ao Claude Code também é um pré-requisito importante.
Passo 1: Verifique os servidores MCP disponíveis
Por padrão, o servidor MCP do Ruflo está configurado no arquivo .mcp.json local. Esse arquivo também deve conter a configuração para se conectar ao Web MCP da Bright Data.
O comportamento esperado é que o Claude Code detecte e se conecte automaticamente a ambos os servidores MCP. Para verificar isso, inicie o Claude Code na pasta do seu projeto e execute o comando /mcp:
Você deverá ver:
bright-data-web-mcp(ou qualquer nome que você tenha dado ao Bright Data Web MCP na configuração.mcp.json).claude-flow(o nome do servidor MCP do Ruflo).
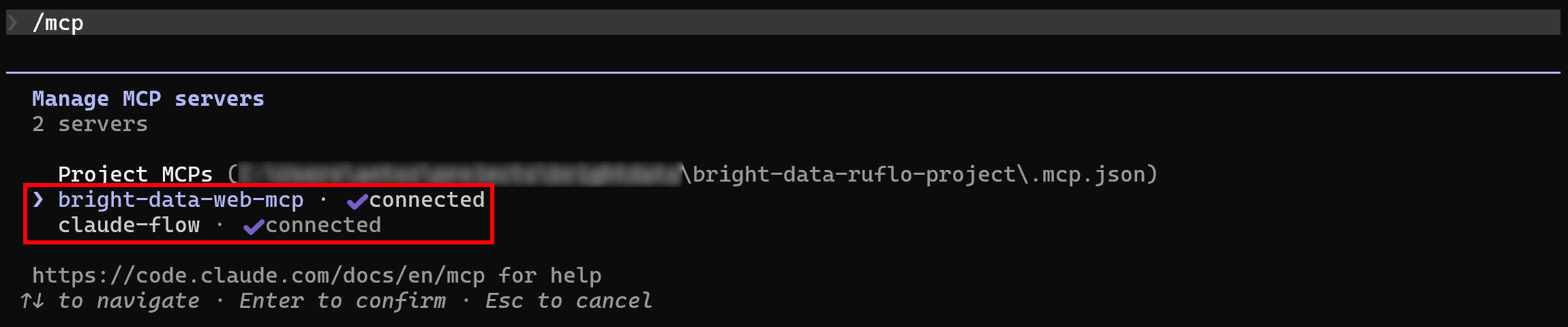
Ótimo! O Claude Code agora está conectado a ambos os servidores MCP, conforme esperado.
Passo 2: Inspecione o servidor MCP do Bright Data Web
Selecione a entrada bright-data-web-mcp (ou qualquer nome que você tenha dado a ela):
Escolha a opção “Exibir ferramentas” para ver todas as ferramentas disponíveis. Se você configurou no modo Pro, terá acesso a todas as mais de 65 ferramentas:
Caso contrário, você verá apenas 4 ferramentas (scrape_as_markdown, search_engine e suas 2 versões em lote).
Excelente! O Bright Data Web MCP está exibindo suas ferramentas conforme o esperado.
Passo 3: Inspecione o servidor Ruflo MCP
Repita o mesmo procedimento descrito acima, mas para o MCP claude-flow. Você deverá ver:
Observe como o MCP do Ruflo expõe um total impressionante de 254 ferramentas. Uau!
Abordagem de integração nº 2: Ruflo Skills + Bright Data Skills
Aqui, você será guiado pelo processo de adicionar recursos do Ruflo e da Bright Data à sua configuração do Claude Code por meio de skills.
Pré-requisitos
Para seguir esta seção, certifique-se de ter:
- Claude Code configurado em um sistema operacional baseado em Unix (macOS, Linux ou WSL).
- Git instalado localmente.
- Uma conta Bright Data com uma zona do Web Unlocker configurada e uma chave de API definida.
- Conhecimento básico sobre o que são as habilidades do Claude e como configurá-las no Claude Code.
- Familiaridade com as habilidades disponíveis no repositório oficial de habilidades do Claude da Bright Data.
Observação: não se preocupe em configurar uma conta Bright Data ainda, pois você será orientado a fazê-lo na etapa seguinte.
Em seguida, instale o curl e o jq, os dois pré-requisitos exigidos pelas habilidades do Bright Data Claude. No macOS, execute:
brew install curl jqDa mesma forma, no Linux, execute:
sudo apt-get install curl jqPor padrão, após configurar o Ruflo em seu projeto local, o Claude Code já listará suas 118 habilidades. Verifique isso executando o comando /skills: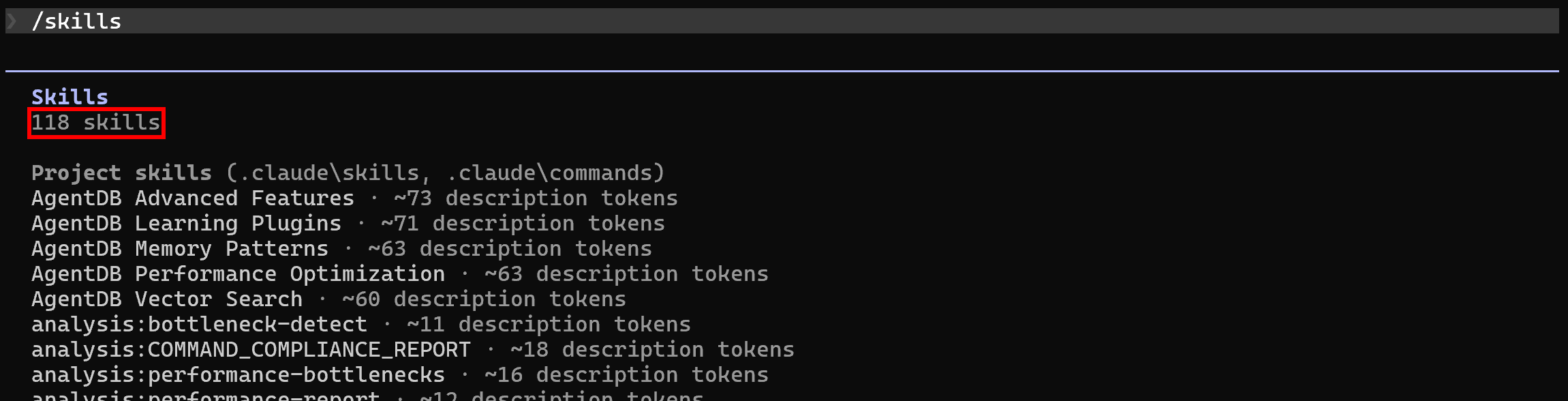
Passo 1: Configure sua conta Bright Data
Conforme explicado na documentação, as habilidades do Bright Data Claude exigem que os dois segredos a seguir sejam definidos como variáveis de ambiente globais:
BRIGHTDATA_API_KEY: Sua chave API da Bright Data.BRIGHTDATA_UNLOCKER_ZONE: O nome da zona do Web Unlocker configurada em sua conta.
Para orientação, você pode consultar a página de documentação“Guia de Início Rápido paraa APIdo Web Unlocker da Bright Data”.Como alternativa, siga as instruções abaixo.
Se você não tiver uma conta Bright Data, crie uma. Caso contrário, basta fazer login. Acesse o painel de controle e vá para a página “Proxies & Scraping”. Dê uma olhada na tabela “Minhas Zonas”: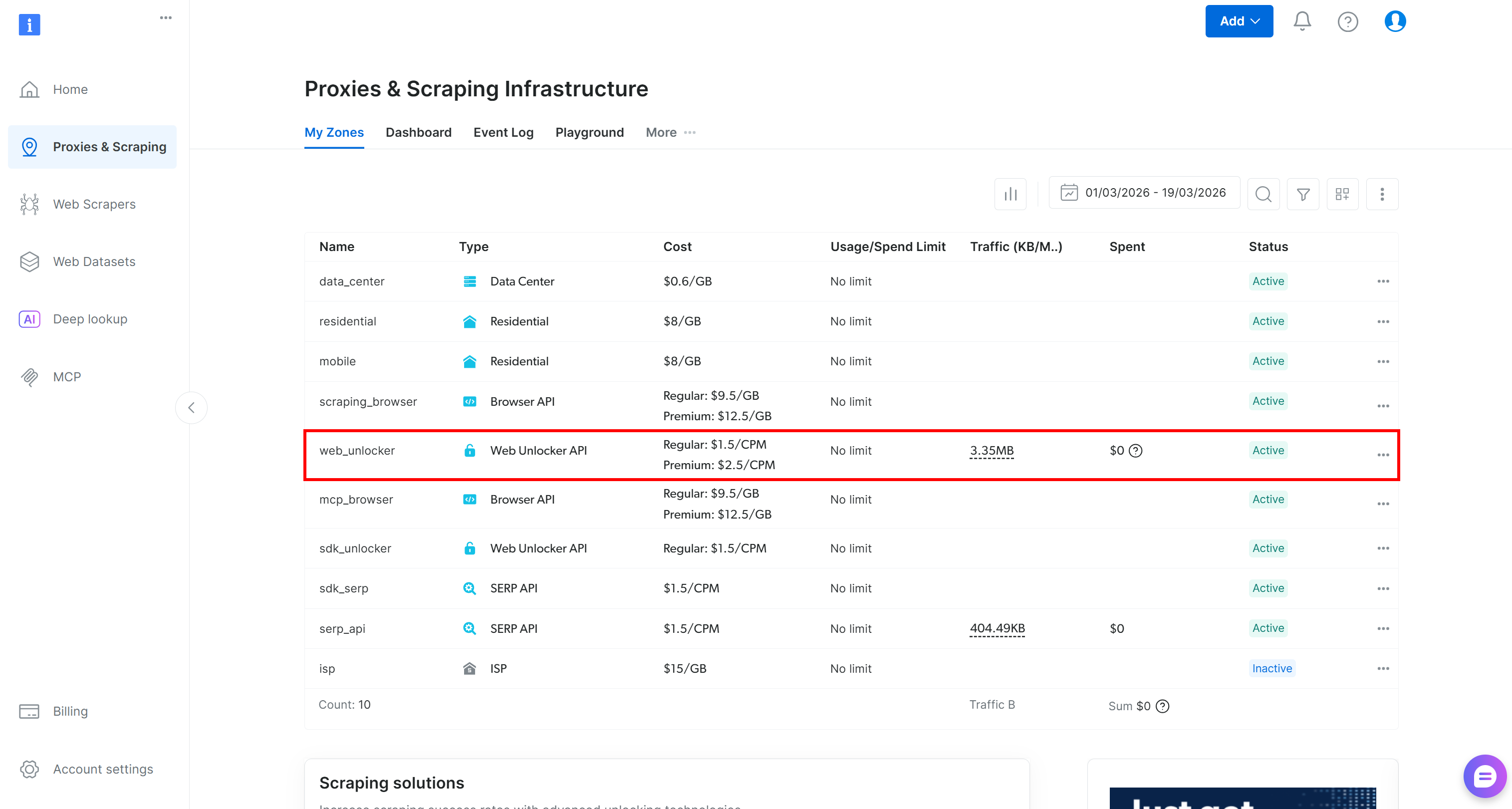
Se houver uma zona da API do Web Unlocker (por exemplo, web_unlocker), você pode prosseguir para a definição da chave da API.
Se ela estiver faltando, crie uma nova. Para isso, role até o cartão “Unblocker API”, clique em “Create zone” e siga o assistente.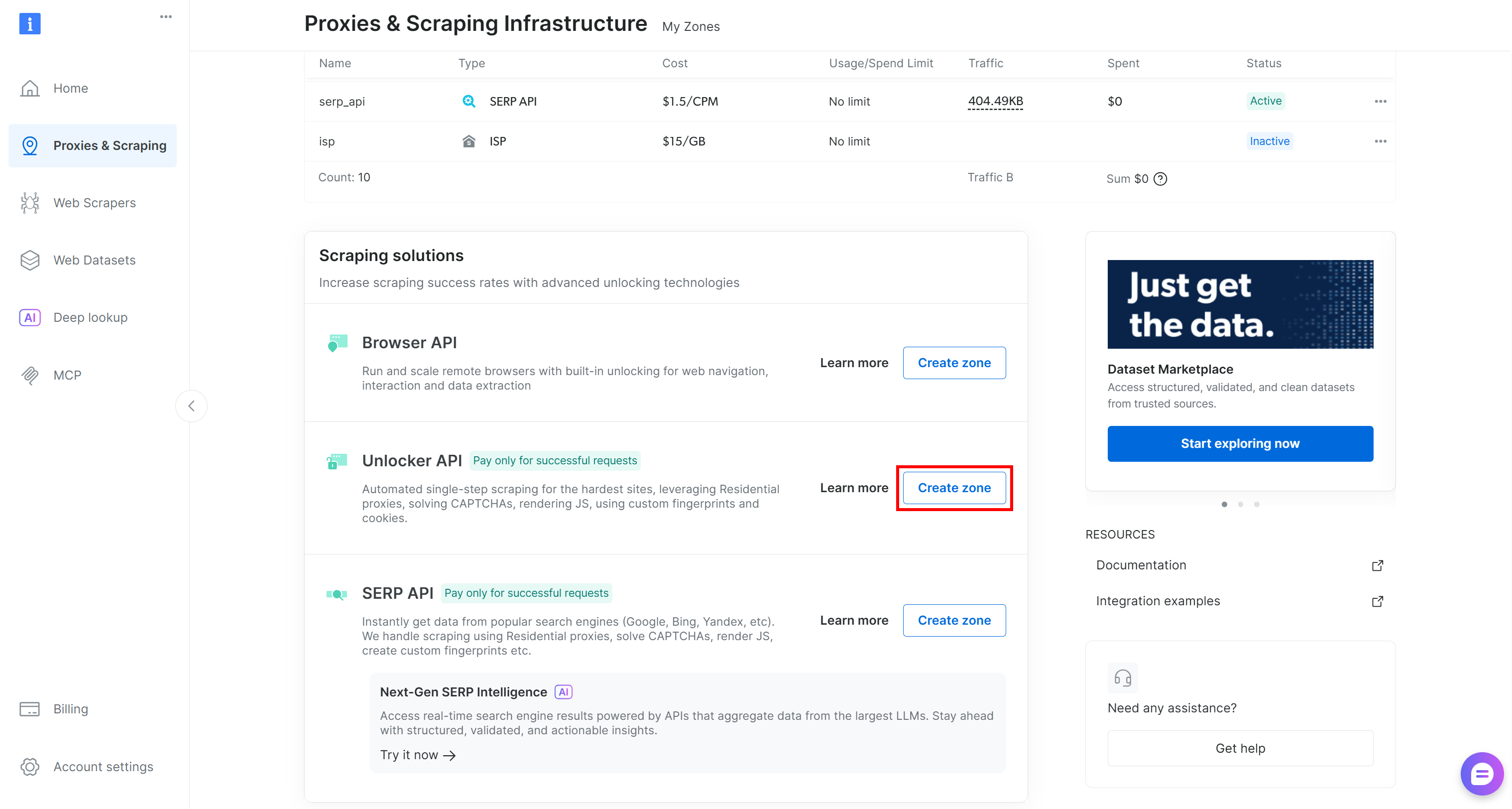
Siga as instruções do assistente, dando à sua zona um nome significativo (por exemplo, web_unlocker).
Por fim, gere sua chave de API da Bright Data. Agora, com seu token de API e o nome da zona, defina duas variáveis de ambiente globais da seguinte forma:
export BRIGHTDATA_API_KEY="<SUA_CHAVE_API_BRIGHTDATA>"
export BRIGHTDATA_UNLOCKER_ZONE="<SUA_ZONA_UNLOCKER_BRIGHTDATA>"Ótimo! As habilidades do Bright Data Claude agora podem se conectar à sua conta e funcionar corretamente.
Passo 2: Recuperar as habilidades do Bright Data
Para adicionar novas habilidades à sua configuração, copie suas pastas para o diretório local .claude/skills.
Comece clonando o repositório das habilidades do Bright Data Claude em uma pasta de sua escolha:
git clone https://github.com/brightdata/skillsA estrutura clonada deve ficar assim:
skills/
├── .claude-plugin
├── skills/
│ ├── bright-data-best-practices/
│ ├── bright-data-mcp/
│ ├── brightdata-cli/
│ ├── data-feeds/
│ ├── design-mirror/
│ ├── python-sdk-best-practices/
│ ├── scrape/
│ ├── scraper-builder/
│ └── search/
├── .gitignore
├── LICENSE
└── README.mdAs habilidades do Bright Data Claude são:
search: Consulta o Google e retorna resultados JSON estruturados, incluindo títulos, links e descrições.scrape: extrai qualquer página da web como Markdown limpo, contornando automaticamente a detecção de bots.data-feeds: Obtém dados estruturados de mais de 40 sites com polling e atualizações automatizadas.bright-data-mcp: Coordena mais de 60 ferramentas do Bright Data MCP para pesquisa, scraping, extração estruturada e automação de navegadores.scraper-builder: Crie scrapers prontos para produção, incluindo análise de sites, seleção de API, seletores, paginação e implementação.bright-data-best-practices: Referência para Web Unlocker, SERP, Web Scraper e APIs de navegador.python-sdk-best-practices: Guia para o pacote Pythonbrightdata-sdk: clientes assíncronos/síncronos, Scrapers, Conjuntos de dados, tratamento de erros e padrões.brightdata-cli: Guia de terminal para o Bright Data CLI: raspar, pesquisar, extrair dados, gerenciar zonas de Proxy e verificar conta.design-mirror: Replique tokens e componentes do sistema de design para uma implementação de interface do usuário consistente e de alta qualidade.
Copie as pastas dentro de skills/ (bright-data-best-practices/, bright-data-mcp/, etc.) para o diretório local .claude/skills no diretório do seu projeto. Faça isso manualmente ou através deste comando:
cp -r skills/skills/* <PATH_TO_YOUR_PROJECT>/.claude/skills/Perfeito! As habilidades do Bright Data Claude foram adicionadas ao seu projeto.
Etapa 3: Verifique as habilidades disponíveis
Inicie o Claude Code novamente na pasta do seu projeto e execute o comando /skills: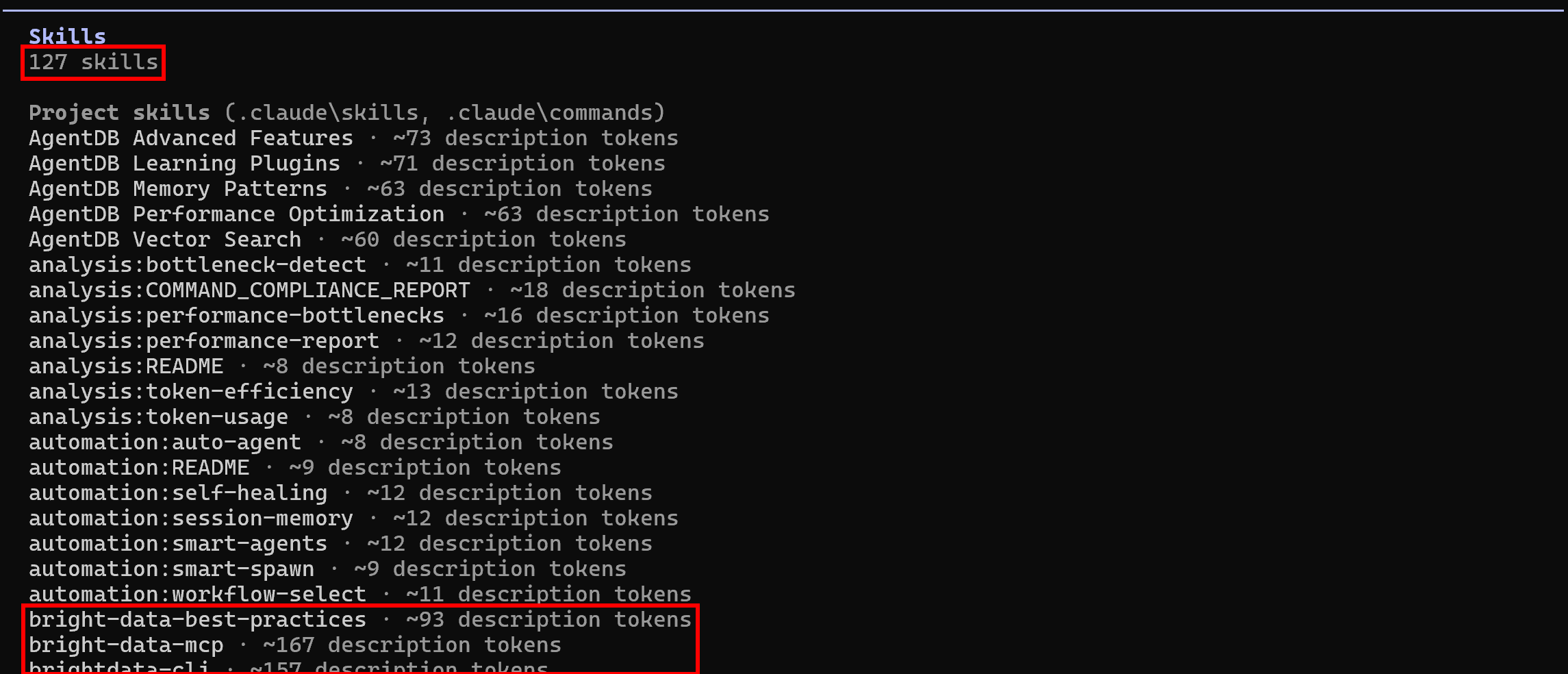
Desta vez, as habilidades disponíveis devem ser 127 (um aumento em relação às 118 iniciais), mostrando que as habilidades do Bright Data estão sendo lidas com sucesso. Missão cumprida! Seu sistema de codificação agentica agora pode aproveitar as habilidades do Bright Data para extração programática de dados da web, exploração da web e muito mais.
Ruflo + Bright Data: reunindo tudo
Sua configuração do Claude Code agora tem acesso a mais de 300 ferramentas MCP ou mais de 125 habilidades. Isso permite esforços coordenados de codificação, ao mesmo tempo em que permite que os agentes pesquisem a web de forma autônoma, coletem dados e interajam com páginas da web — tudo sem bloqueios ou limitações de escalabilidade.
Isso abre muitas novas possibilidades, incluindo:
- Recuperar resultados de pesquisa em tempo real (SERP) e incorporar links contextuais em
README.mde outras páginas de documentação. - Descobrir tutoriais ou documentação relevantes com base em suas tarefas de codificação atuais para melhorar sua base de código de forma eficiente.
- Extrair dados públicos atualizados de sites e salvá-los localmente para simulação, análise ou processamento posterior.
Esses exemplos demonstram a vantagem sinérgica de usar o Bright Data com o Ruflo em sua configuração do Claude Code / OpenAI Codex. Essa integração amplia ainda mais o já impressionante conjunto de recursos do Ruflo, ao mesmo tempo em que oferece suporte a casos de uso de nível empresarial graças à infraestrutura do Bright Data.
Conclusão
Nesta postagem do blog, você entendeu o que é o Ruflo (anteriormente conhecido como Claude Flow) e como ele transforma a experiência de agentes no Claude Code e no OpenAI Codex. Com uma infraestrutura de nível empresarial de cerca de 100 agentes trabalhando em paralelo, o Ruflo melhora drasticamente o desempenho, incluindo velocidade, eficiência de tokens e qualidade de saída.
No entanto, essas ferramentas carecem de uma solução pronta para uso corporativo para recuperação de dados da web, pesquisa na web e interação programática com sites. É aí que a Bright Data entra em cena, graças a um servidor Web MCP dedicado e a um conjunto oficial de Claude Skills. Isso simplifica a conexão com o conjunto completo de ferramentas, serviços e infraestrutura da Bright Data, desenvolvidos para IA.
Aqui, você aprendeu como configurar uma poderosa combinação de Ruflo + Bright Data no Claude Code para maximizar a eficiência e a eficácia da assistência à codificação.
Crie uma conta Bright Data gratuitamente hoje mesmo e comece a explorar soluções de dados da web preparadas para IA!




