
Neste tutorial, você aprenderá:
- O que é o MLflow e os recursos de rastreamento que ele oferece.
- Por que criar experimentos de ML/IA com base em Conjuntos de dados coletados por Scraping de dados é uma abordagem vencedora.
- Como realizar o rastreamento de experimentos usando um conjunto de dados coletados com o MLflow.
Vamos começar!
O que é o MLflow?
O MLflow é uma plataforma de código aberto para gerenciar todo o ciclo de vida do aprendizado de máquina. Ele oferece muitos recursos e uma API rica para rastrear, reproduzir e implantar modelos com eficiência.
O MLflow oferece suporte a fluxos de trabalho tradicionais de aprendizado de máquina e aprendizado profundo, oferecendo ferramentas para experimentação, controle de versão, avaliação e implantação. Tudo isso de forma reproduzível e colaborativa.
O MLflow é independente de linguagem, funcionando em Python, R e Java, e suporta ambientes locais, em nuvem e gerenciados. Isso o torna neutro em relação ao fornecedor e altamente flexível. Além disso, ele mantém sua natureza de código aberto, com seu repositório GitHub ostentando mais de 24 mil estrelas.
Os principais recursos do MLflow incluem:
- Rastreamento: registre experimentos, rastreie parâmetros, métricas, versões de código e artefatos.
- Modelos: padronize o empacotamento de modelos para implantação em diferentes plataformas.
- Registro de modelos: repositório centralizado para controle de versão de modelos, transições de estágio e anotações.
- Projetos: empacote código de ciência de dados reutilizável para consistência e reprodutibilidade.
- Avaliação de IA/LLM: rastreie, compare e avalie saídas de IA generativa ou LLM.
- Integração e registro automático: funciona com scikit-learn, TensorFlow, PyTorch, OpenAI e muito mais, automatizando o registro.
Saiba mais nos documentos oficiais.
Por que conjuntos de dados contendo dados da web coletados são ideais para experimentar com o MLflow
Ao construir pipelines de ML/IA, a qualidade e a variedade de seus conjuntos de dados geralmente determinam o sucesso ou o fracasso de seus experimentos. Os dados da web coletados, por sua natureza, oferecem diversidade e escala. Esses são os dois principais ingredientes para uma experimentação significativa.
Ao contrário de conjuntos de dados pequenos ou sintéticos, os conjuntos de dados derivados da web capturam distribuições do mundo real, casos extremos e variabilidade natural. Esses aspectos tornam seus modelos mais robustos e suas experiências com o MLflow mais informativas. É por isso que os dados da web são geralmente considerados uma das melhores fontes de dados.
A Bright Data se destaca como a melhor fornecedora de conjuntos de dados. Seu mercado oferece conjuntos de dados estruturados prontos para ML e IA, abrangendo mais de 150 domínios, desde comércio eletrônico e varejo até mídias sociais e viagens. Cada conjunto de dados contém milhões de registros, garantindo amplitude e profundidade.
Esses conjuntos de dados são atualizados regularmente, refletindo a natureza dinâmica da web, para que seus fluxos de trabalho de ML/IA possam ser treinados e avaliados com as informações mais atuais. Essa combinação de escala, atualização e formatação pronta para ML torna os conjuntos de dados da Bright Data perfeitos para experimentos sólidos, reproduzíveis e de alto impacto com o MLflow. Explore os conjuntos de dados disponíveis no mercado!
Como realizar o rastreamento de experimentos usando o MLflow e um conjunto de dados da Bright Data
Nesta seção guiada, você aprenderá como realizar o rastreamento de experimentos com o MLflow. Em particular, você criará um pipeline de aprendizado de máquina usando o conjunto de dados Bright Data Amazon Best Product Seller.
O objetivo desse pipeline é treinar um modelo que preveja o preço final de um produto com base em sua classificação, número de avaliações e marca. A suposição subjacente é que esses recursos contêm sinais preditivos correlacionados com o preço do produto.
O pipeline combina o pré-processamento com um modelo Random Forest e avalia seu desempenho. Ao longo do processo, o MLflow rastreará métricas, artefatos, o conjunto de dados e o uso de recursos do sistema.
Siga as etapas abaixo!
Pré-requisitos
Para acompanhar este tutorial, você precisa de:
- Python 3.10 ou superior instalado localmente.
- Uma conta Bright Data para acessar Conjuntos de dados coletados.
- Conhecimento básico sobre treinamento de modelos preditivos de ML usando scikit-learn.
Etapa 1: Configuração do projeto
Comece abrindo seu terminal e criando uma nova pasta para seu projeto de experimento MLflow:
mkdir mlflow-experiment-trackingEm seguida, navegue até o diretório do projeto e crie um ambiente virtual Python dentro dele:
cd mlflow-experiment-tracking
python -m venv .venvAgora, carregue a pasta do projeto no seu IDE Python preferido. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Crie um novo arquivo chamado experiment.py na raiz do diretório do seu projeto. A estrutura do seu projeto deve ficar assim:
mlflow-experiment-tracking/
├── .venv/
└── experiment.pyNo terminal, ative o ambiente virtual. No Linux ou macOS, execute:
source venv/bin/activateDe forma equivalente, no Windows, execute:
venv/Scripts/activateCom o ambiente virtual ativado, instale as dependências do projeto:
pip install mlflow pandas scikit-learn psutil nvidia-ml-pyAs bibliotecas necessárias são:
mlflow: para rastreamento de experimentos de ponta a ponta, observabilidade e registro de modelos e métricas de ML.pandas: Carrega, limpa e manipula dados tabulares de JSON/CSV para treinamento de modelos.scikit-learn: cria pipelines de ML, lida com o pré-processamento, treina modelos e calcula métricas de avaliação.psutil, nvidia-ml-py: exigidas pelo MLflow para monitorar recursos de CPU e GPU e outras métricas do sistema durante os experimentos.
Em seguida, em experiment.py, importe todas as bibliotecas necessárias com:
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputerMuito bem! Seu ambiente de desenvolvimento Python agora está pronto para rastrear experimentos de ML e IA no MLflow.
Etapa 2: familiarize-se com a interface do usuário do MLflow
Para verificar se o MLflow está funcionando, abra um terminal com seu ambiente virtual ativado e inicie a interface do usuário do MLflow:
mlflow uiNa primeira inicialização, o MLflow inicializará um banco de dados SQLite local para armazenar os dados do experimento. Em particular, você notará que um arquivo mlflow.db apareceu na pasta do seu projeto. Esse é o banco de dados local usado pelo SQLite.
No terminal, você verá um log como este:
INFO: Uvicorn em execução em http://127.0.0.1:5000 (Pressione CTRL+C para sair)Isso significa que a interface do usuário está em execução. Abra seu navegador e acesse http://127.0.0.1:5000/. Você deverá ver: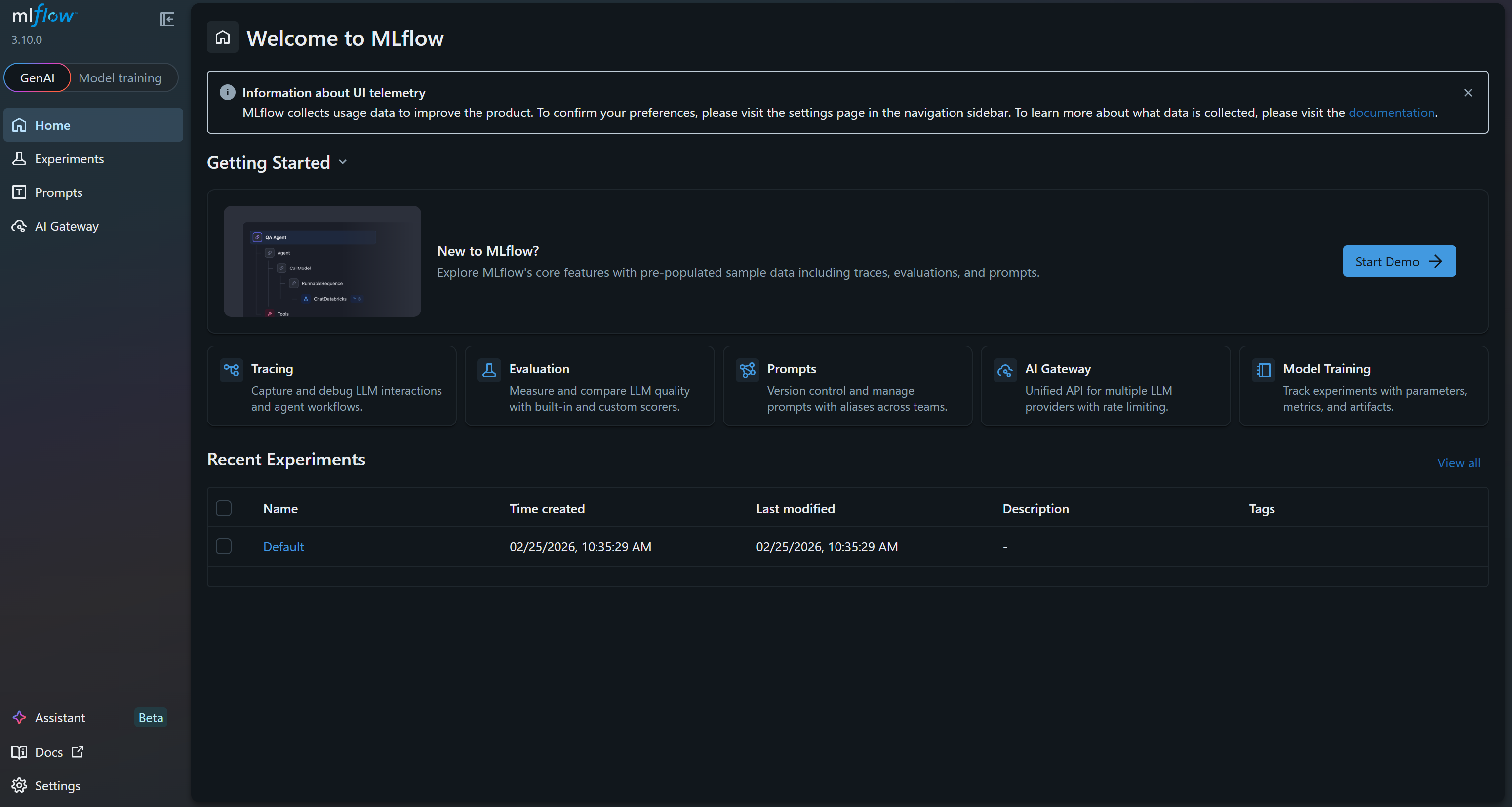
Esta é a interface do usuário do MLflow, onde você pode observar e acompanhar seus experimentos. Reserve alguns minutos para se familiarizar com ela, explorando os links do menu e os recursos disponíveis. Aqui, você monitorará métricas, logs e artefatos de maneira eficaz durante seus projetos de ML. Ótimo!
Etapa 3: habilite os recursos de registro automático e rastreamento do sistema do MLflow
No seu arquivo experiment.ml, habilite o registro de métricas do sistema MLflow para rastrear o uso da CPU, do disco, da RAM e outras métricas no nível do sistema durante o treinamento.
# Habilite o registro automático de métricas do sistema (CPU, memória etc.)
mlflow.enable_system_metrics_logging()
# Registrar eventos automaticamente para sklearn
mlflow.sklearn.autolog()
# Configurar a frequência com que as métricas do sistema são amostradas e registradas
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1) Este trecho também ativa o registro automático para que o MLflow registre automaticamente os eventos do scikit-learn. Em seguida, ele define o intervalo de amostragem das métricas do sistema para 1 segundo para garantir um monitoramento detalhado e frequente.
Fantástico! Agora, seu aplicativo MLflow rastreará informações úteis sobre seu experimento de treinamento de modelo de aprendizado de máquina.
Etapa 4: recuperar o conjunto de dados de origem com dados coletados da Bright Data
Agora você tem uma configuração MLflow pronta para realizar experimentos de ML/IA. O que falta é a fonte de dados para treinar seu modelo. Conforme mencionado anteriormente, usaremos o conjunto de dados Amazon Best Sellers da Bright Data para construir um modelo de previsão de preços com base em um pipeline Random Forest.
Primeiro, você precisa recuperar o conjunto de dados de origem. Neste caso, ele contém mais de 45 campos de dados e abrange mais de 171 milhões de produtos mais vendidos da Amazon.
Se você ainda não tem uma conta na Bright Data, crie uma. Caso contrário, faça login. No painel de controle da Bright Data, selecione a opção de menu “Conjuntos de dados da Web”. Em seguida, navegue até a guia “Mercado de conjuntos de dados”: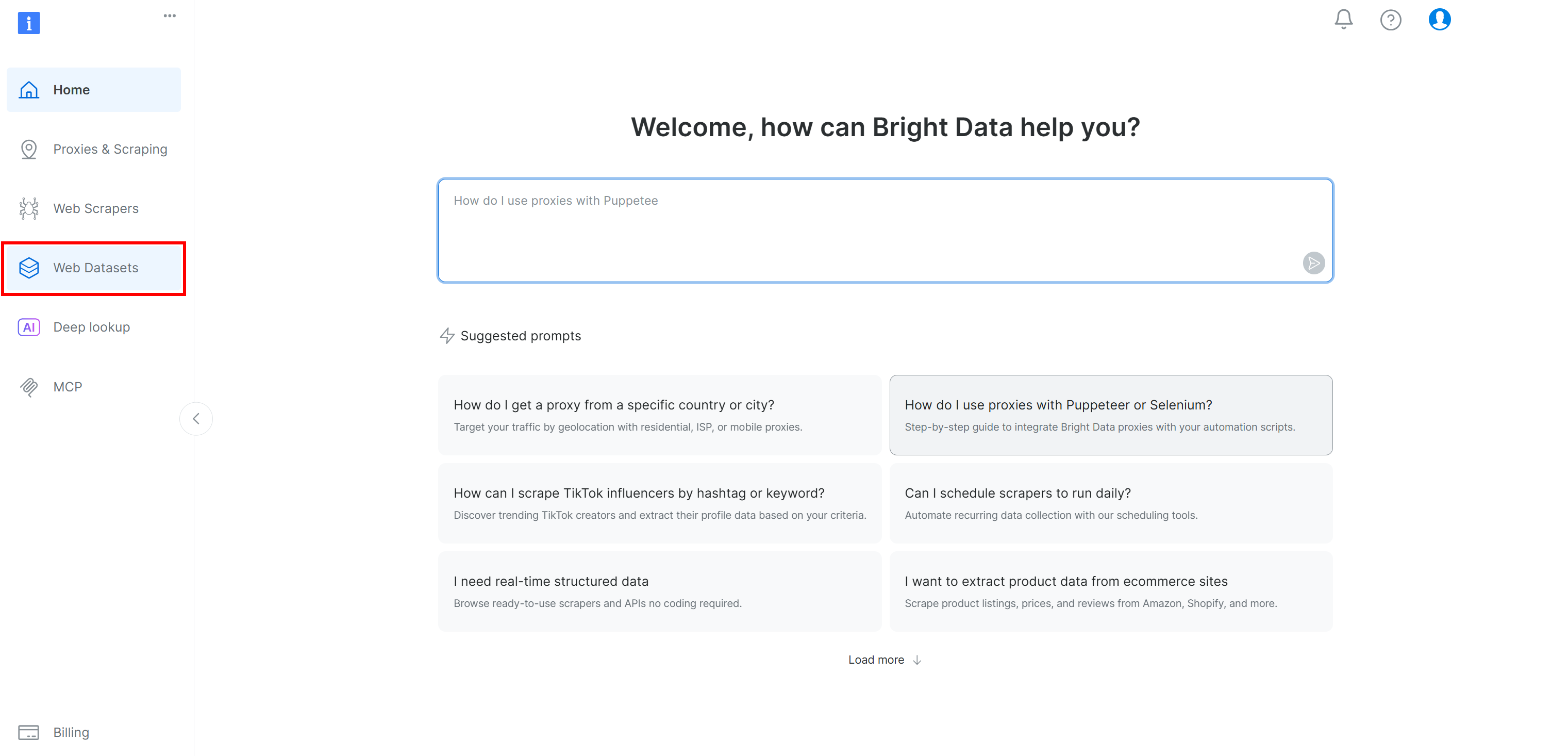
Vá para a guia “Dataset marketplace”:
Você chegará à página“Dataset marketplace”: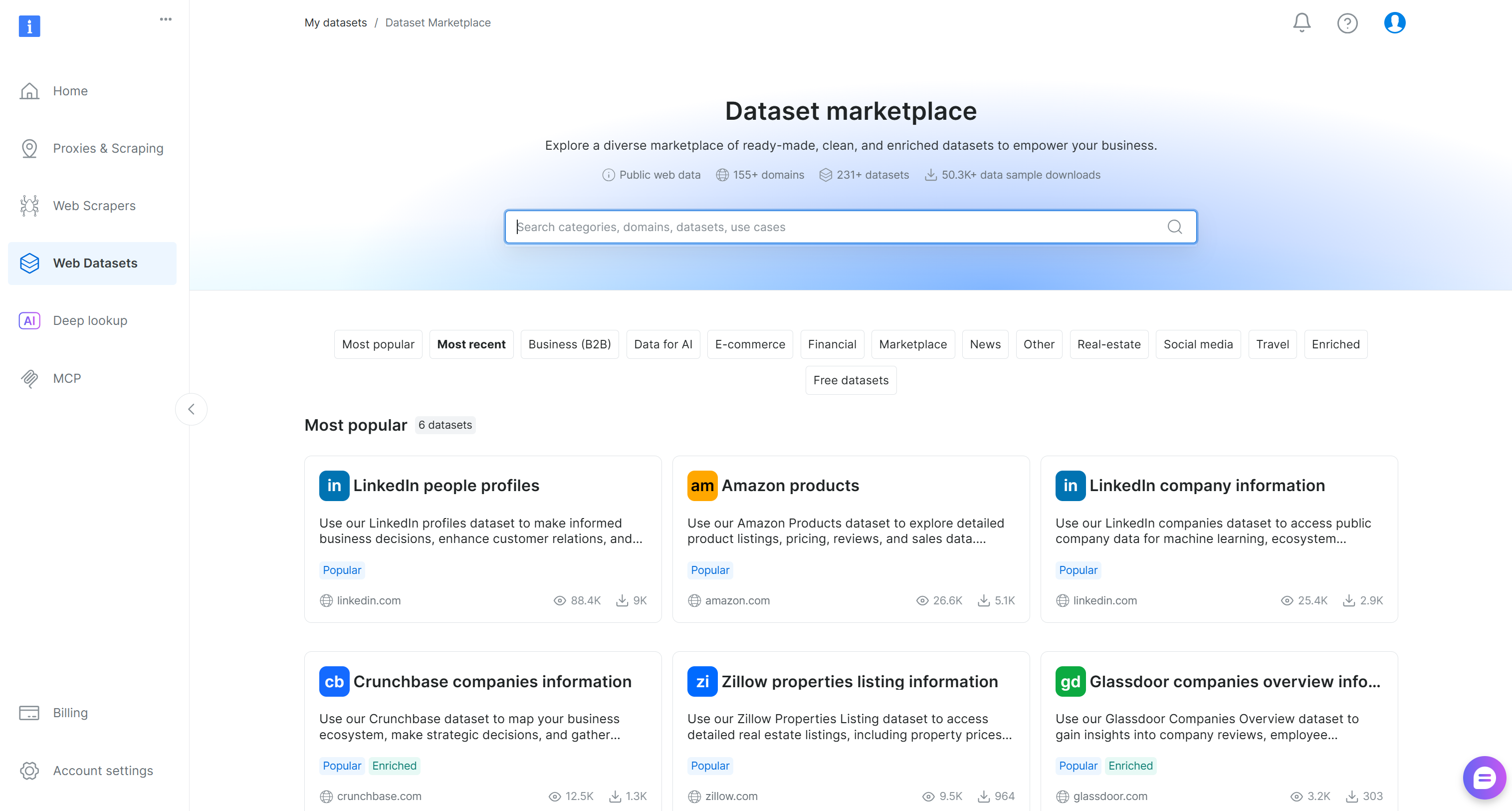
Aqui, você pode navegar por mais de 200 Conjuntos de dados coletados de mais de 155 domínios, com bilhões de registros disponíveis.
Pesquise por “Amazon best seller products” (produtos mais vendidos da Amazon) e selecione-o. Isso o levará à página do conjunto de dados: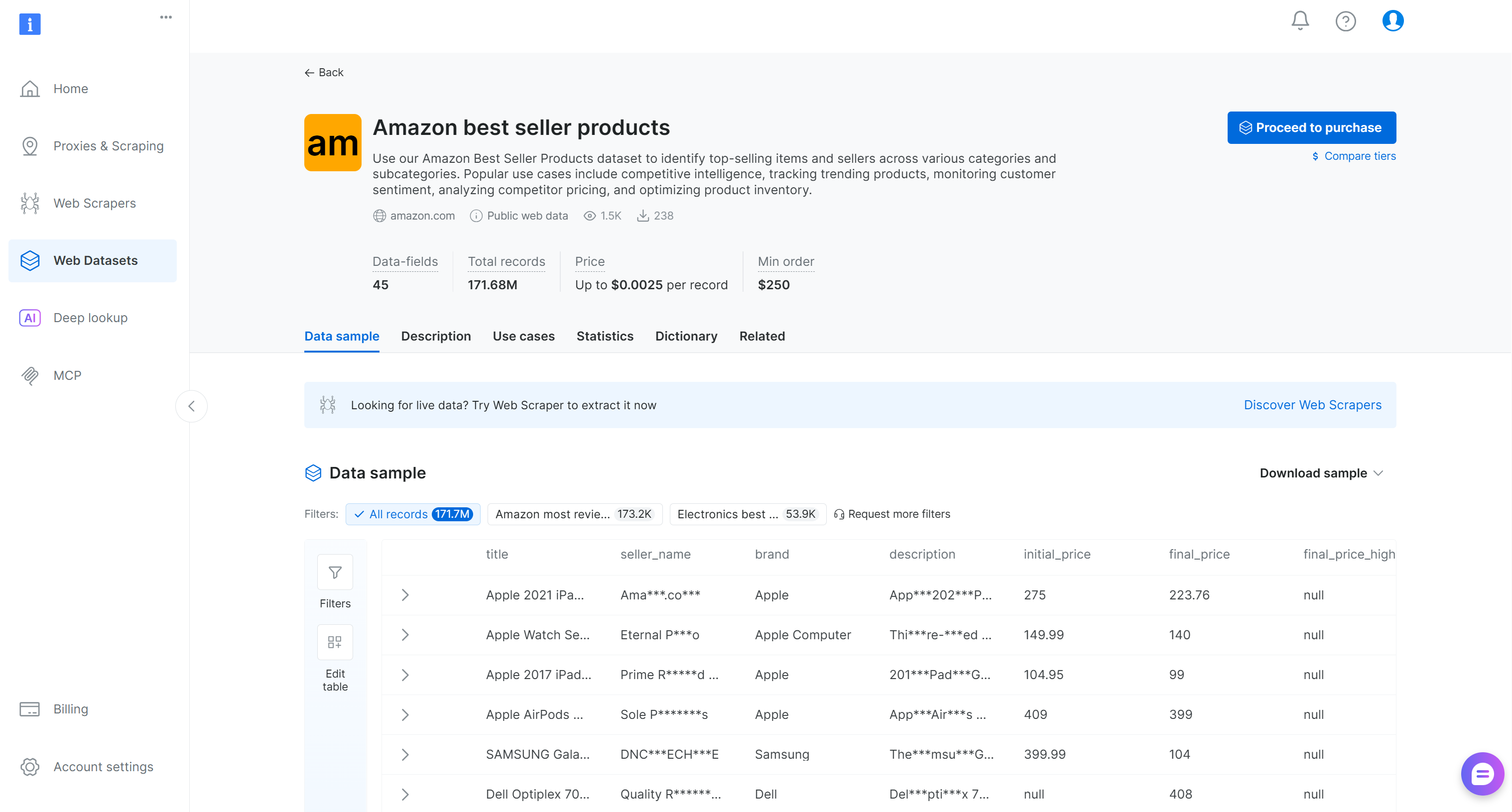
Você pode comprar um subconjunto filtrado de registros ou baixar uma amostra gratuita. Como este é apenas um exemplo, usaremos a amostra gratuita.
Clique no menu suspenso “Baixar amostra” e escolha a opção “Baixar como JSON”: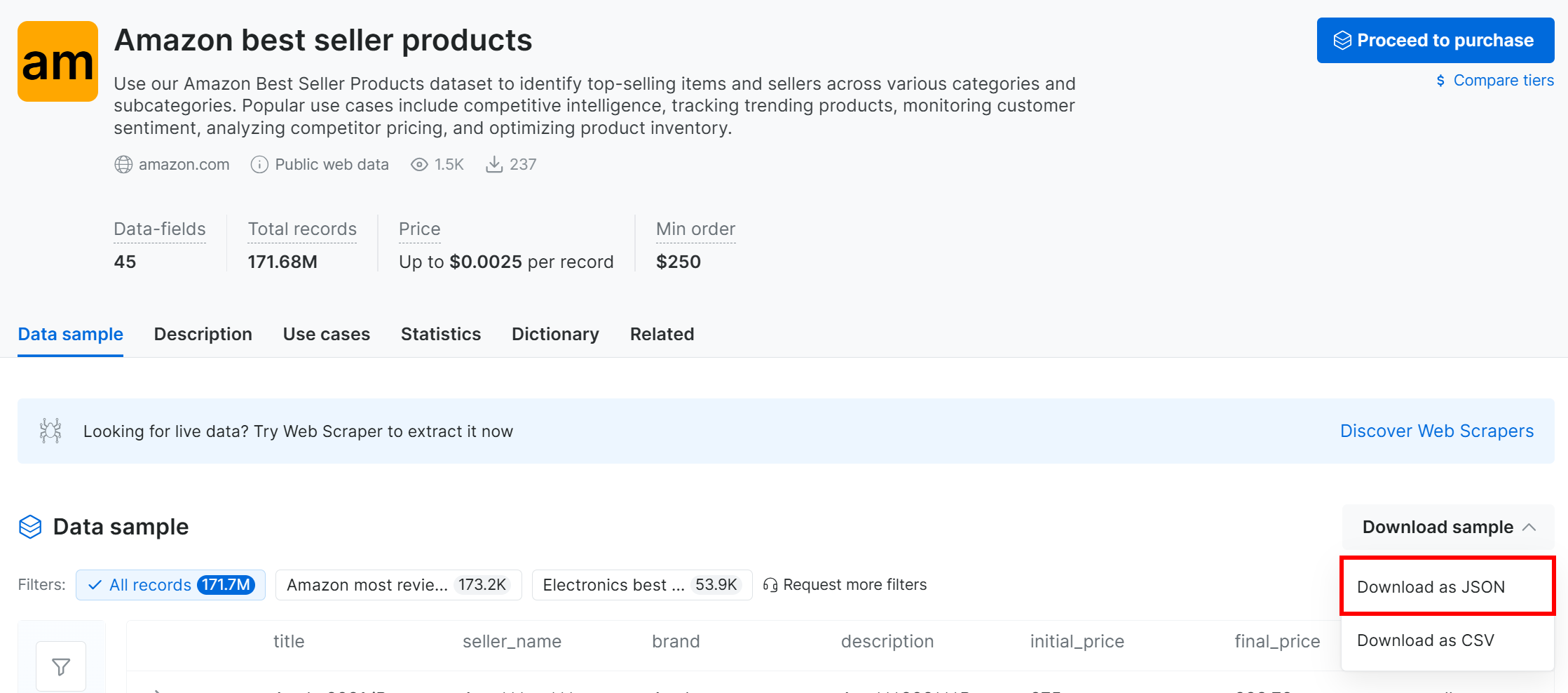
Você receberá um conjunto de dados de amostra com 1.000 registros dos produtos mais vendidos da Amazon. Alguns campos estão parcialmente mascarados (por meio de “***”) por motivos de privacidade, mas o conjunto de dados completo está disponível após o pagamento. Ainda assim, a amostra é suficiente para experimentos simples do MLflow.
Como alternativa, você pode baixar um conjunto de dados de amostra semelhante de um repositório GitHub dedicado.
Renomeie o arquivo do conjunto de dados baixado para products.json e coloque-o na pasta do seu projeto:
mlflow-experiment-tracking/
├── .venv/
├── experiment.py
├── mlflow.db
└── products.json # <--------Abra o arquivo e você verá: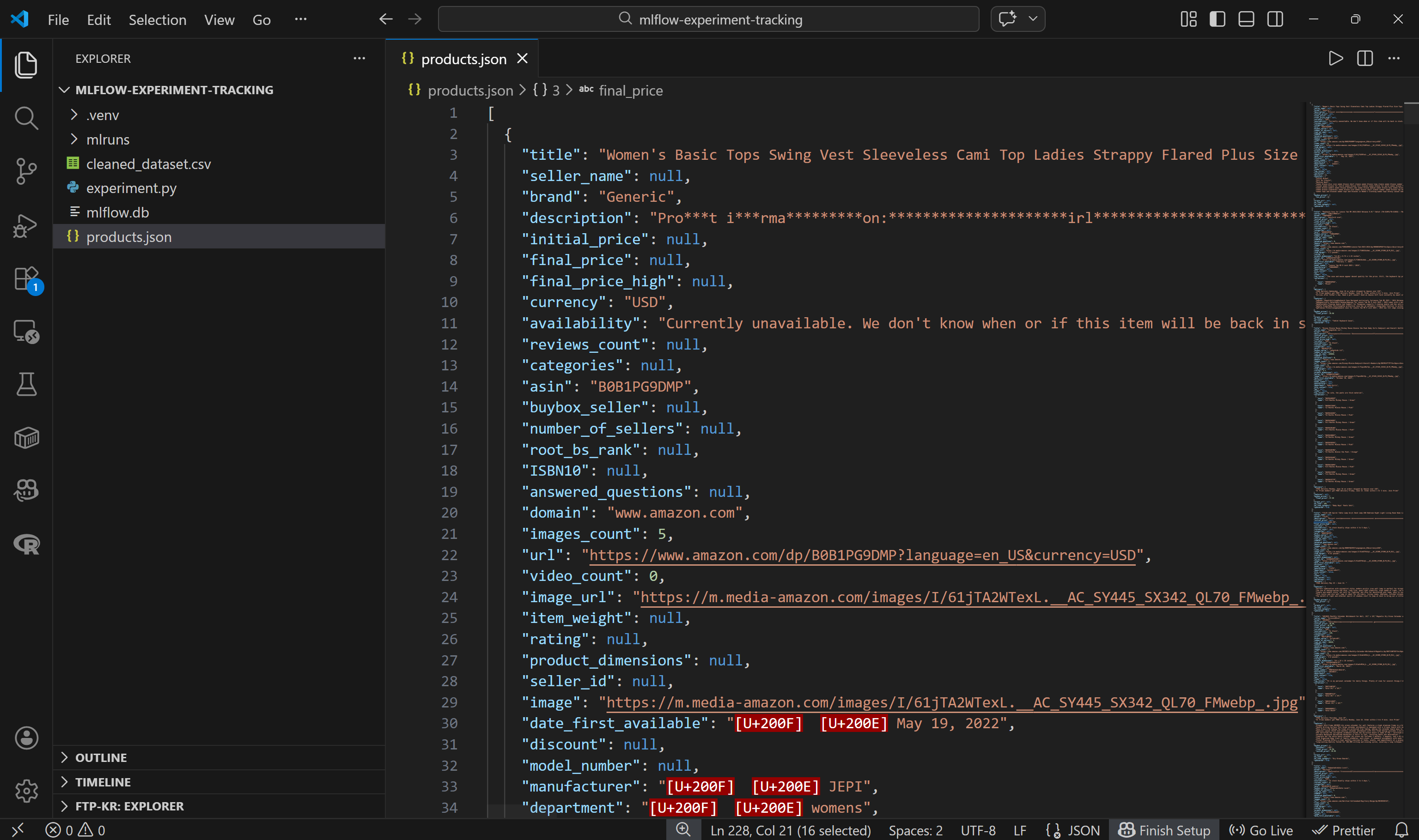
Observe que cada produto da Amazon é representado como um objeto JSON contendo cerca de 45 campos de dados. Isso fornece uma base rica para experimentação.
Perfeito! Agora você está pronto para carregar esse conjunto de dados em seu código e começar a processá-lo.
Etapa 5: carregue e pré-processe o conjunto de dados
Antes de carregar o conjunto de dados em seu código, reserve um tempo para explorar as colunas disponíveis. Vá para a guia “Dicionário” para ver informações detalhadas sobre cada coluna, incluindo sua descrição e porcentagem de presença: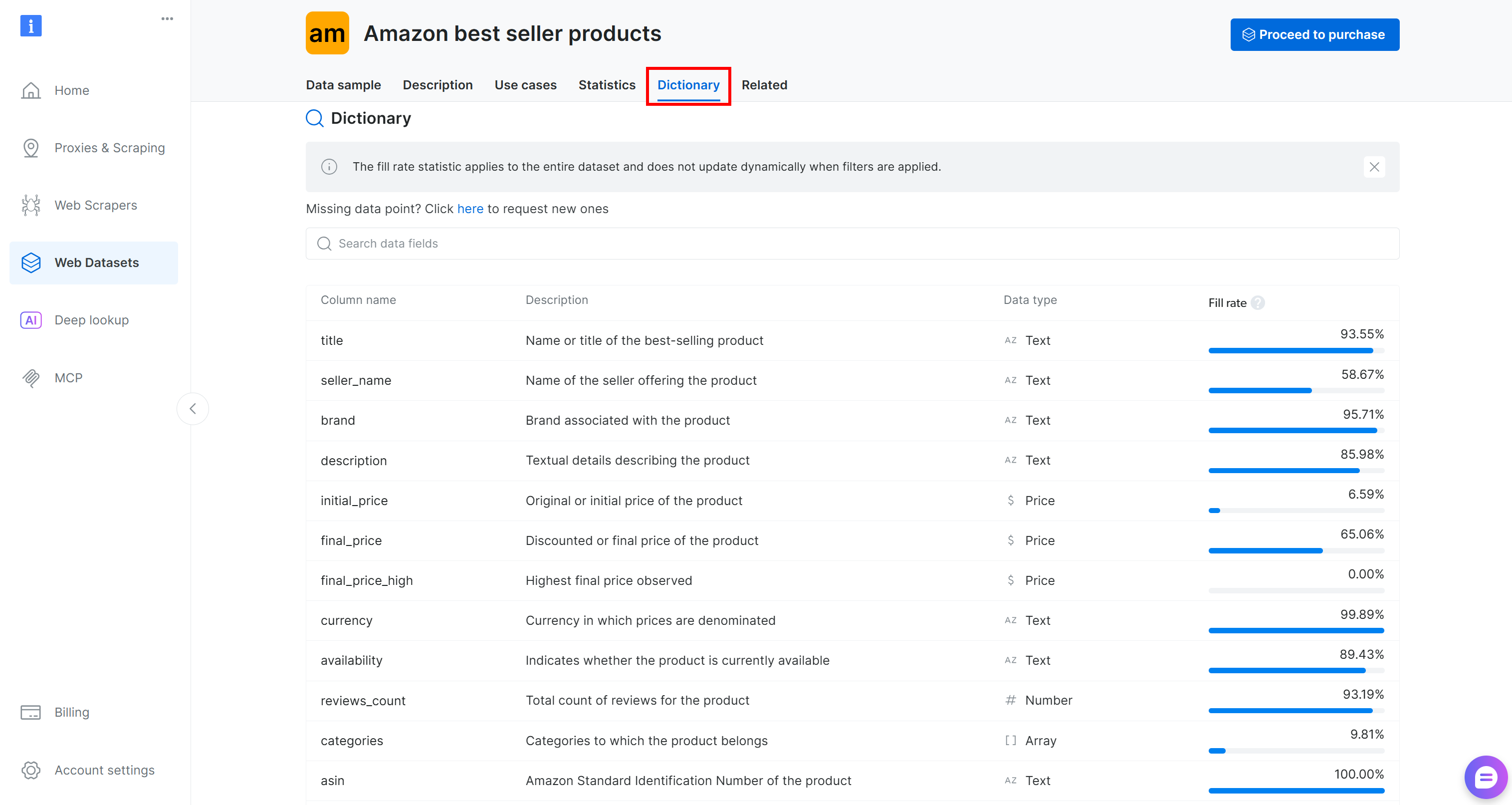
Nesse caso, as colunas de interesse são:
marca(texto): marca associada ao produto.final_price(preço): Preço com desconto ou final do produto.reviews_count(número): Número total de avaliações.classificação(número): classificação média do produto.
Agora, carregue o arquivo JSON:
com open("products.json", "r", encoding="utf-8") como f:
data = json.load(f)Em seguida, converta-o em um DataFrame do pandas:
df = pd.DataFrame(data)Se você inspecionar a coluna final_price, perceberá que, às vezes, ela contém apenas valores numéricos (por exemplo, 1500), enquanto outras vezes inclui strings formatadas (por exemplo, $1.500).
Para um processamento consistente, converta todos os preços para o formato numérico e exclua as linhas em que final_price é nulo:
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
df = df.dropna(subset=["final_price"])Por fim, registre os conjuntos de dados no MLflow:
# Defina colunas de recursos e coluna de destino
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# Defina explicitamente a fonte do conjunto de dados
dataset_source = CodeDatasetSource(tags="v1")
# Registre o conjunto de dados no MLflow com alguns metadados
mlflow_dataset = mlflow.data.from_pandas(
df[FEATURES + [TARGET]],
source=dataset_source,
name="brightdata_products",
targets=TARGET
)Este código define os recursos de entrada (classificação, número de avaliações, marca) e a variável alvo (preço final) para o seu pipeline de ML. Em seguida, ele cria um objeto CodeDatasetSource e registra o DataFrame selecionado no MLflow com metadados para garantir o rastreamento e a reprodutibilidade do experimento.
Excelente! Agora você está pronto para usar esses dados em seu pipeline de treinamento de modelo.
Etapa 6: definir o pipeline do modelo preditivo
Prepare seus dados para o treinamento do modelo de ML usando a seguinte lógica:
# Separar recursos e alvo
X = df[FEATURES]
y = df[TARGET]
# Pipeline de pré-processamento:
# - Imputação mediana para colunas numéricas
# - Preenchimento constante + codificação one-hot para coluna categórica
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# Pipeline completo de ML: pré-processamento + modelo RandomForest
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# Dividir os conjuntos de dados em conjuntos de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)Este trecho prepara os dados e constrói um pipeline completo de ML ao:
- Separar os recursos de entrada (
classificação,número de avaliações,marca) do alvo (preço final). - Tratar valores ausentes com imputação mediana para características numéricas e preenchimento constante para características categóricas, e então codificar o campo de texto
da marcaem um formato numérico. Essas precauções garantem que o modelo receba entradas numéricas limpas. - Combinar o pré-processamento com um modelo Random Forest e dividir os dados em conjuntos de treinamento e teste para avaliação.
Ótimo! É hora de executar seu experimento MLflow no conjunto de dados coletados pela Bright Data.
Etapa 7: execute o experimento MLflow
Agora você tem todos os blocos de construção para executar seu experimento MLflow. Execute-o com:
# Inicie a execução do MLflow e habilite o rastreamento de métricas do sistema
com mlflow.start_run(log_system_metrics=True) como execução:
# Registre o conjunto de dados como uma entrada para a execução
mlflow.log_input(mlflow_dataset, context="training")
# Treine o pipeline do modelo
pipeline.fit(X_train, y_train)
# Gere as previsões no conjunto de testes
predictions = pipeline.predict(X_test)
# Registrar as métricas de avaliação (RMSE e R2)
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predictions))
mlflow.log_metric("r2_score", r2_score(y_test, predictions))
# Registrar o conjunto de dados de saída CSV em um arquivo local e, em seguida, como um artefato no MLflow
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# Registre o modelo treinado com assinatura e exemplo de entrada
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
imprimir(f"Execução concluída. Verifique a guia 'Métricas do sistema' na interface do usuário do MLflow para o ID da execução: {run.info.run_id}")É isso que o trecho acima faz:
- Inicia uma execução do MLflow com o rastreamento de métricas do sistema ativado.
- Registra
mlflow_datasetcomo uma entrada para o experimento para rastreabilidade e reprodutibilidade. - Treina o pipeline do modelo ajustando o pipeline ML completo (pré-processamento + Random Forest) nos dados de treinamento.
- Gera previsões utilizando o modelo treinado para prever valores-alvo no conjunto de testes.
- Registra RMSE e R² no MLflow para avaliar o desempenho do modelo.
- Registre o conjunto de dados limpo como um artefato, para que você possa explorá-lo no MLflow para referência.
- Registra o pipeline treinado no MLflow, incluindo sua assinatura de entrada e um exemplo de entrada para reprodutibilidade.
Ótimo! Agora só falta explorar o código final e executar seu experimento no MLflow.
Etapa 8: junte tudo e execute o experimento
Seu arquivo experiment.py deve conter:
# pip install mlflow pandas scikit-learn psutil nvidia-ml-py
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputer
# Habilitar registro automático de métricas do sistema (CPU, memória, etc.)
mlflow.enable_system_metrics_logging()
# Registrar eventos automaticamente para sklearn
mlflow.sklearn.autolog()
# Configurar a frequência com que as métricas do sistema são amostradas e registradas (1 segundo)
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1)
# Carregar dados de produtos coletados do arquivo de Conjuntos de dados Bright Data de entrada
# (baixe em: /cp/datasets/browse/gd_l1vijixj9g2vp7563)
com open("products.json", "r", encoding="utf-8") como f:
data = json.load(f)
# Converter JSON para um DataFrame pandas
df = pd.DataFrame(data)
# Limpar a coluna de destino "final_price":
# - Remover sinais de dólar e vírgulas
# - Converter para numérico
# - Valores inválidos tornam-se NaN
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
# Excluir linhas onde o valor alvo está faltando
df = df.dropna(subset=["final_price"])
# Definir colunas de características e coluna alvo
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# Definir explicitamente a fonte do conjunto de dados
dataset_source = CodeDatasetSource(tags="v1")
# Registrar o conjunto de dados no MLflow com alguns metadados
mlflow_dataset = mlflow.data.from_pandas(
df[FEATURES + [TARGET]],
source=dataset_source,
name="brightdata_products",
targets=TARGET)
# Separar características e alvo
X = df[FEATURES]
y = df[TARGET]
# Pipeline de pré-processamento:
# - Imputação mediana para colunas numéricas
# - Preenchimento constante + codificação one-hot para coluna categórica
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# Pipeline completo de ML: pré-processamento + modelo RandomForest
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# Dividir os conjuntos de dados em conjuntos de treinamento e teste
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Definir o experimento MLflow
mlflow.set_experiment("brightdata_product_price_prediction")
# Iniciar a execução do MLflow e ativar o rastreamento de métricas do sistema
com mlflow.start_run(log_system_metrics=True) como execução:
# Registrar o conjunto de dados como uma entrada para a execução
mlflow.log_input(mlflow_dataset, context="training")
# Treinar o pipeline do modelo
pipeline.fit(X_train, y_train)
# Gerar as previsões no conjunto de testes
predictions = pipeline.predict(X_test)
# Registrar as métricas de avaliação (RMSE e R2)
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predictions))
mlflow.log_metric("r2_score", r2_score(y_test, predictions))
# Registrar o conjunto de dados de saída CSV em um arquivo local e, em seguida, como um artefato no MLflow
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# Registre o modelo treinado com assinatura e exemplo de entrada
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
imprimir(f"Execução concluída. Verifique a guia 'Métricas do sistema' na interface do usuário do MLflow para o ID da execução: {run.info.run_id}")Com o ambiente Python ativado, execute seu experimento MLflow com:
python experiment.pyA execução deve levar alguns segundos, então seja paciente.
Missão concluída! Você acabou de implementar um pipeline de rastreamento de experimento MLflow com um conjunto de dados coletados da Bright Data.
Etapa 9: Explore os resultados de rastreamento do MLflow
Acesse a interface do usuário do MLflow em http://127.0.0.1:5000/. Você deverá ver uma entrada de experimento brightdata_product_price_prediction (que é o nome dado ao experimento MLflow no código). Clique nela:
Vá para a seção “Execuções de treinamento” para obter mais detalhes:
Você deverá ver a última execução que acabou de realizar:
Clique nela para acessar imediatamente mais de 15 métricas: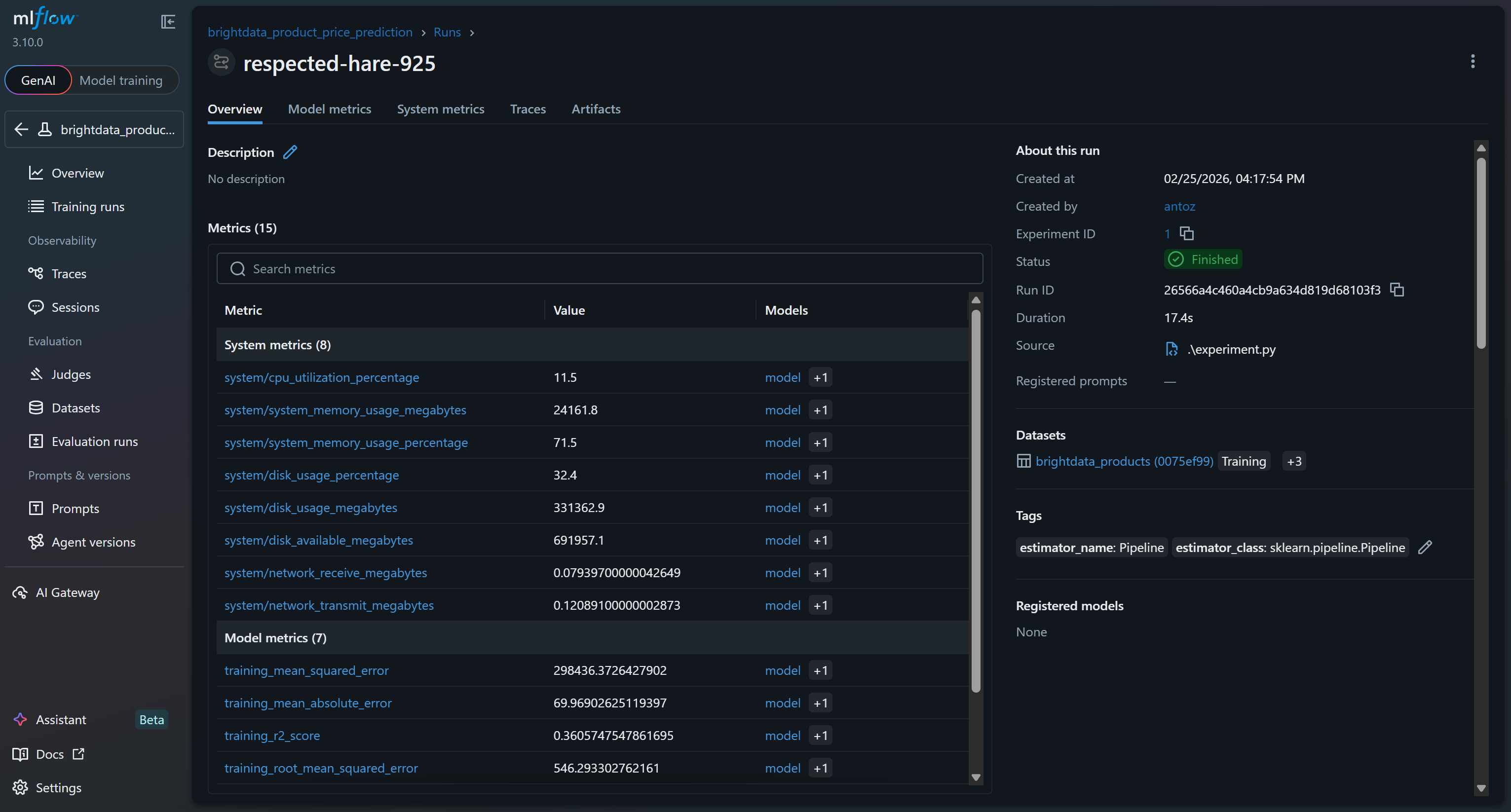
Elas incluem métricas do sistema e do modelo coletadas automaticamente pelos recursos de rastreamento do MLflow, bem como métricas do modelo registradas durante a execução (por exemplo, val_rmse, r2_score).
Para explorar as métricas do modelo, acesse a guia correspondente: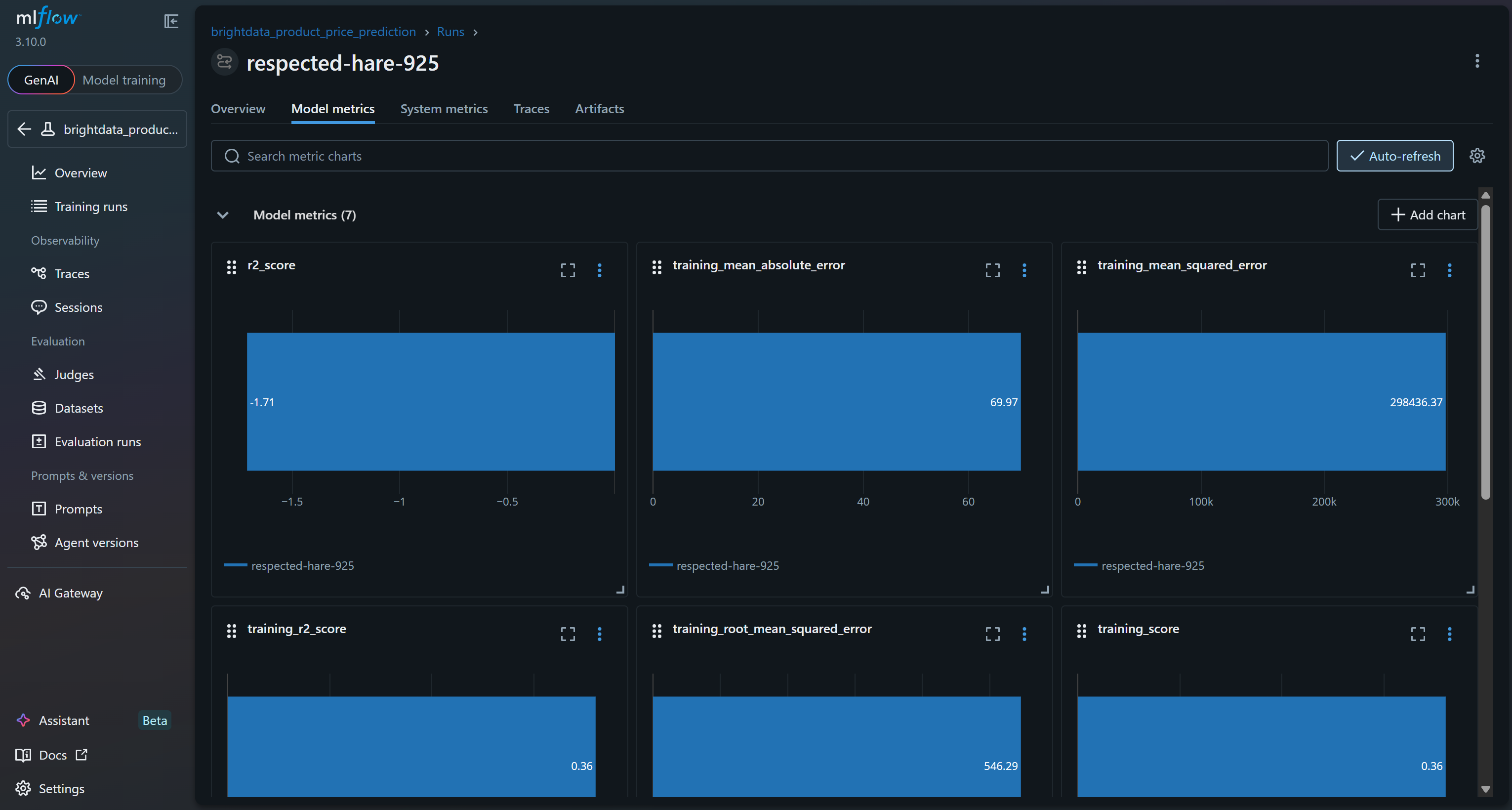
Ou analise os gráficos de métricas do sistema na guia “Métricas do sistema”: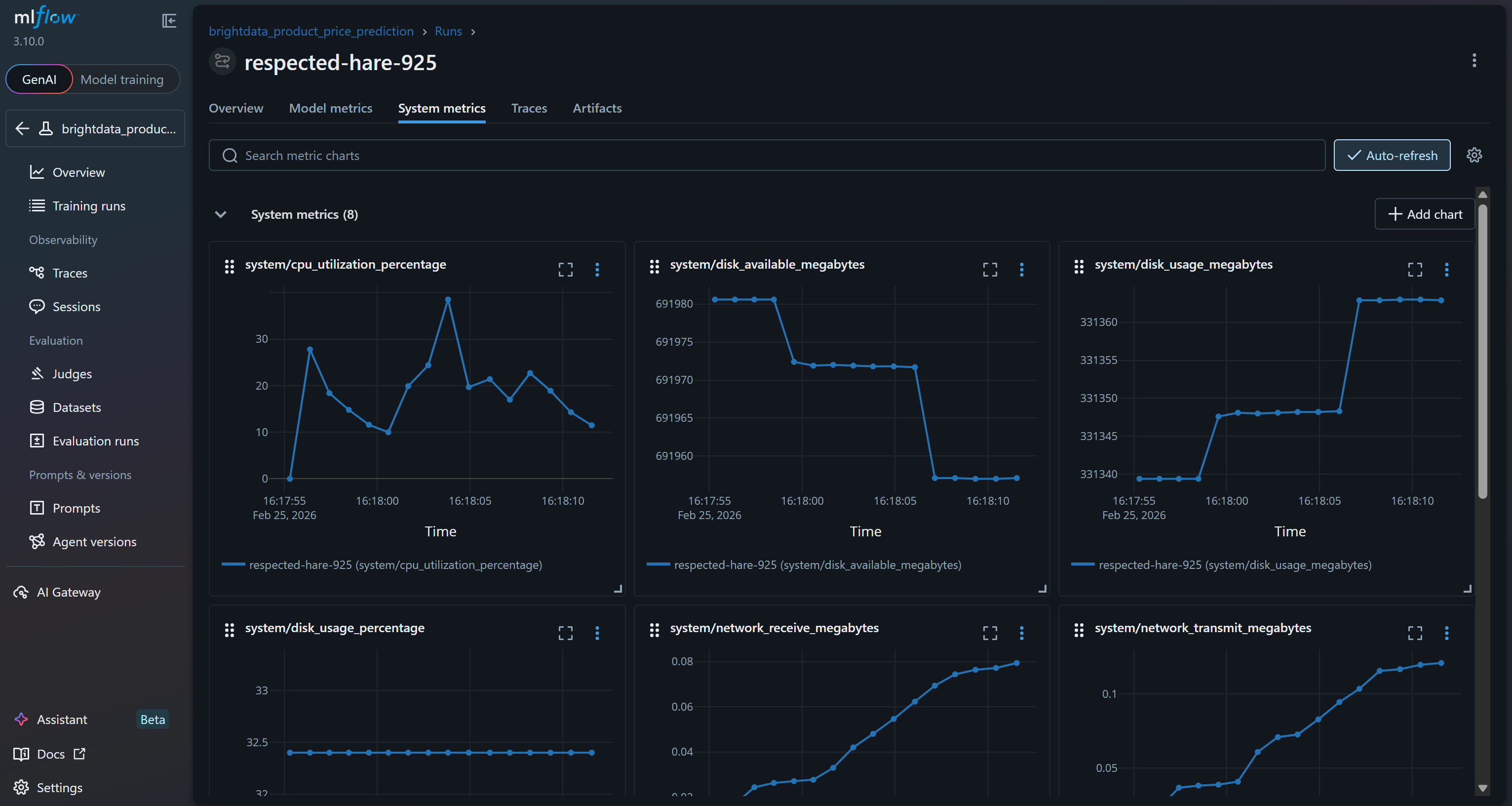
Além disso, a seção “Artefatos” mostra os arquivos de saída (como o arquivo cleaned_dataset.csv, conforme registrado em seu código):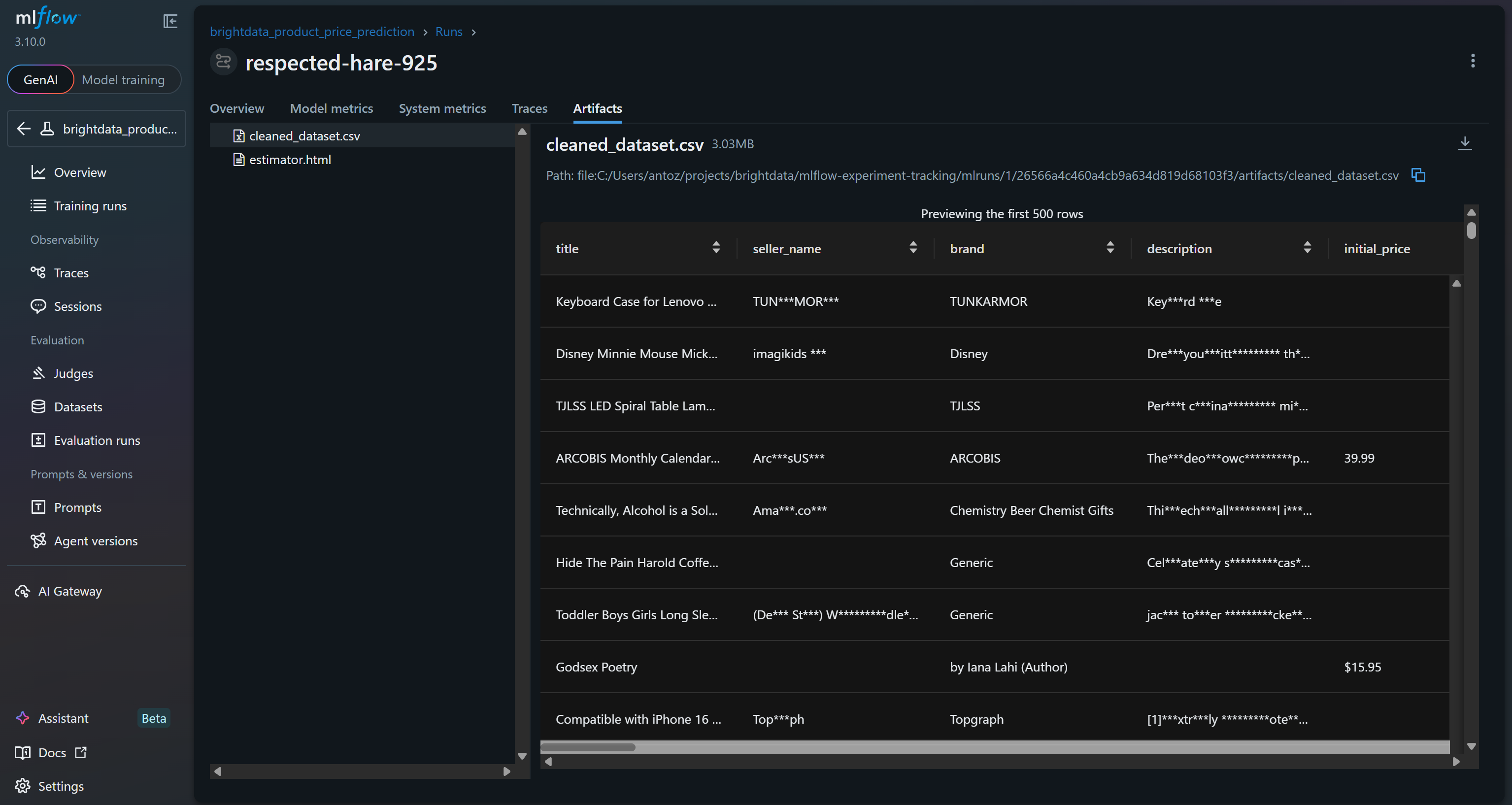
Essas são apenas algumas das métricas e saídas que você pode rastrear graças a um experimento do MLflow criado com base em um conjunto de dados coletados pelo Bright Data!
Etapa 10: comente os resultados
Para verificar se o processo de treinamento do modelo funcionou, concentre-se nas métricas do modelo: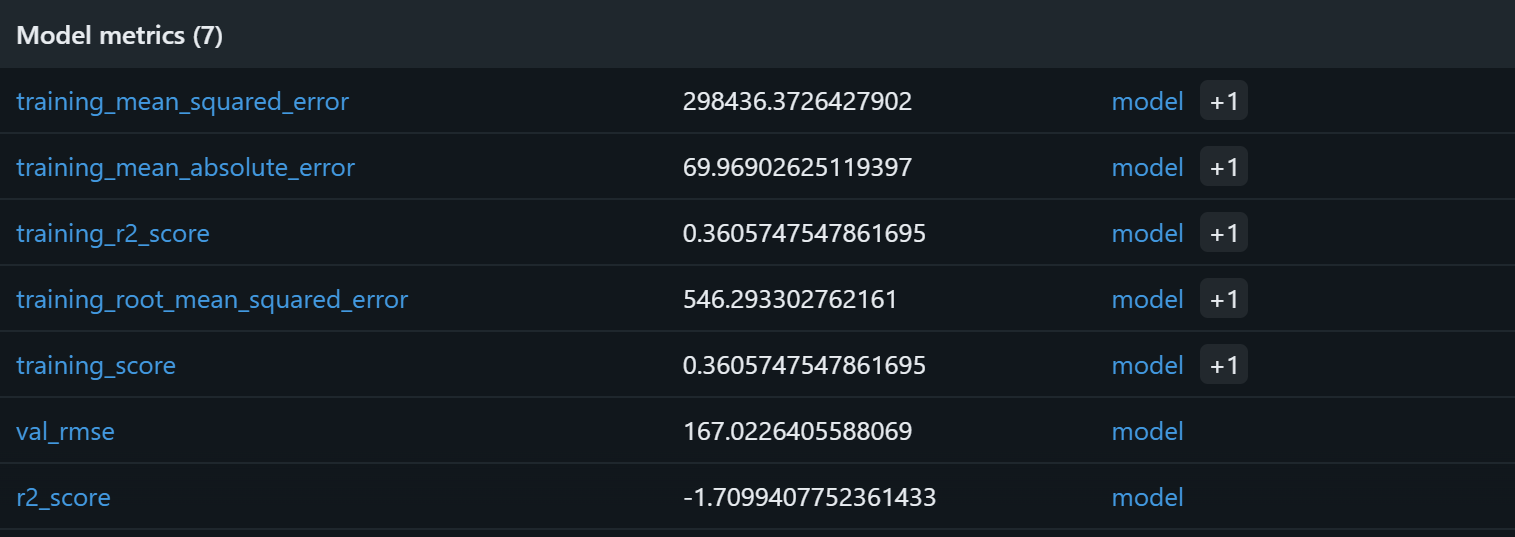
Com base nessas métricas do modelo, é provável que o pipeline atual produza previsões sem sentido no conjunto de validação. O R² de treinamento de 0,36 indica que o modelo explica aproximadamente 36% da variação nos dados de treinamento, o que é modesto. O RMSE de treinamento (546) e o MAE (~70) sugerem que os erros são bastante altos em relação aos preços típicos dos produtos, possivelmente devido a dados ruidosos ou correlações fracas entre os recursos e o alvo.
Mais preocupante é o desempenho da validação: o R² é negativo (-1,71) e o RMSE de validação (167) continua significativo. Um R² negativo implica que o modelo tem um desempenho pior do que simplesmente prever o preço médio para todas as amostras. Isso sinaliza que a relação assumida entre classificação, número de avaliações, marca e preço final pode não ser forte ou suficientemente linear para que uma Random Forest capture efetivamente!
As melhorias potenciais incluem expandir o conjunto de características, realizar engenharia de características (por exemplo, transformar logaritmicamente o número de avaliações, codificar a popularidade da marca), tentar modelos alternativos como gradient boosting ou XGBoost e aumentar o tamanho do conjunto de dados para além do subconjunto de 1.000 amostras. Com um conjunto de dados Bright Data maior, você teria mais dados e variedade, permitindo experimentos mais profundos e relevantes.
Em resumo, o pipeline atual funciona tecnicamente, mas não consegue capturar adequadamente os padrões de preços subjacentes. Graças ao rastreamento de experimentos do MLflow, você pode identificar que as suposições subjacentes a este pipeline de aprendizado de máquina provavelmente estão erradas.
Próximos passos
Se você deseja usar o MLflow para rastrear pipelines de IA com Conjuntos de dados da Bright Data para ajuste fino ou RAG, lembre-se de que o rastreamento do MLflow é totalmente compatível com o OpenTelemetry. Especificamente, o MLflow fornece uma solução de observabilidade LLM que captura entradas, saídas e metadados para cada etapa intermediária de uma solicitação.
Ao integrar com o OpenAI, você pode habilitá-lo facilmente com:
import mlflow
mlflow.openai.autolog() Para obter mais detalhes, consulte a documentação oficial do MLflow.
Conclusão
Neste tutorial, você viu o que o MLflow oferece para a construção e o rastreamento de pipelines de aprendizado de máquina e IA. Você também entendeu por que os Conjuntos de dados coletados são excelentes fontes para treinar ou ajustar modelos.
Conforme demonstrado, a Bright Data oferece um rico mercado de conjuntos de dados que abrange centenas de domínios e bilhões de registros de dados da web. Esses conjuntos de dados são atualizados continuamente por meio do Scraping de dados para dar suporte a fluxos de trabalho de aprendizado de máquina e IA. Em detalhes, eles são perfeitamente compatíveis com o rastreamento do MLflow, conforme mostrado aqui.
Crie uma conta gratuita na Bright Data e comece a explorar nossas soluções de dados da web hoje mesmo!






