

Neste tutorial, você aprenderá:
- Como um assistente de busca de emprego no LinkedIn com tecnologia de IA poderia funcionar.
- Como construí-lo integrando os dados de empregos do LinkedIn da Bright Data com um fluxo de trabalho com tecnologia OpenAI.
- Como melhorar e ampliar esse fluxo de trabalho em um assistente de busca de emprego robusto.
Você pode ver os arquivos finais do projeto aqui.
Vamos mergulhar de cabeça!
Fluxo de trabalho do assistente de IA para busca de emprego no LinkedIn explicado
Em primeiro lugar, não é possível criar um assistente de IA para busca de emprego no LinkedIn sem acesso aos dados das listas de empregos do LinkedIn. É aqui que a Bright Data entra em ação!
Graças ao LinkedIn Jobs Scraper, você pode recuperar dados públicos de anúncios de emprego do LinkedIn por meio de raspagem da Web. A experiência que você obtém é exatamente como pesquisar no portal LinkedIn Jobs. Mas, em vez de uma página da Web, você recebe os dados estruturados do emprego diretamente no formato JSON ou CSV.
Com esses dados, você pode pedir a uma IA que pontue cada emprego com base em suas habilidades e no cargo desejado que você está buscando. Em um nível elevado, é isso que o LinkedIn Job AI Assistant faz por você.
Etapas técnicas
As etapas necessárias para implementar o fluxo de trabalho de IA do LinkedIn são
- Carregar os argumentos da CLI: Analisar os argumentos da linha de comando para obter parâmetros de tempo de execução. Isso permite uma execução flexível e uma personalização fácil sem alterar o código.
- Carregar as variáveis de ambiente: Carregue as chaves da API do OpenAI e do Bright Data nas variáveis de ambiente. Elas são necessárias para se conectar às integrações de terceiros que alimentam esse fluxo de trabalho de IA.
- Carregar o arquivo de configuração: Ler um arquivo de configuração JSON contendo parâmetros de pesquisa de trabalho, detalhes do perfil do candidato e descrição do trabalho desejado. Essas informações de configuração orientam a recuperação de vagas e a pontuação de IA.
- Extrair as vagas do LinkedIn: Obter listagens de vagas filtradas de acordo com a configuração da API do LinkedIn Jobs Scraper.
- Pontuar as vagas por meio de IA: enviar cada lote de publicações de vagas para a OpenAI. A IA as pontua de
0a100com base em seu perfil e no emprego desejado. Ela também adiciona um breve comentário explicando cada pontuação para ajudá-lo a entender a qualidade da correspondência. - Expanda os empregos com pontuações e comentários da IA: ****Merge as pontuações e os comentários gerados pela IA de volta às ofertas de emprego originais, enriquecendo cada registro de emprego com esses novos campos gerados pela IA.
- Exporte os dados das vagas pontuadas: Exporte os dados enriquecidos da vaga para um arquivo CSV para análise e processamento adicionais.
- Imprimir as principais correspondências de vagas: Exiba as principais correspondências de trabalho diretamente no console com os principais detalhes, fornecendo informações imediatas sobre as oportunidades mais relevantes.
Veja como implementar esse fluxo de trabalho de IA em Python!
Como usar OpenAI e Bright Data para criar um fluxo de trabalho de IA de busca de emprego no LinkedIn
Neste tutorial, você aprenderá a criar um fluxo de trabalho de IA para ajudá-lo a encontrar empregos no LinkedIn. Os dados de emprego do LinkedIn serão obtidos da Bright Data, enquanto os recursos de IA serão fornecidos pela OpenAI. Observe que você também pode usar qualquer outro LLM.
Ao final desta seção, você terá um fluxo de trabalho completo de IA em Python que poderá ser executado a partir da linha de comando. Ele identificará as melhores vagas de emprego no LinkedIn, poupando seu tempo e esforço na extenuante e desgastante tarefa de procurar emprego.
Vamos criar um assistente de IA para procurar emprego no LinkedIn!
Pré-requisitos
Para seguir este tutorial, certifique-se de que você tenha o seguinte:
- Python 3.8 ou superior instalado localmente (recomendamos usar a versão mais recente).
- Uma chave de API da Bright Data.
- Uma chave de API da OpenAI.
Se você ainda não tiver uma chave de API da Bright Data, crie uma conta da Bright Data e siga o guia de configuração oficial. Da mesma forma, siga as instruções oficiais da OpenAI para obter sua chave de API da OpenAI.
Etapa #0: Configure seu projeto Python
Abra um terminal e crie um novo diretório para seu assistente de IA de busca de emprego no LinkedIn:
mkdir linkedin-job-hunting-ai-assistant/A pasta linkedin-job-hunting-ai-assistant conterá todo o código Python para seu fluxo de trabalho de IA.
Em seguida, navegue até o diretório do projeto e inicialize um ambiente virtual dentro dele:
cd linkedin-job-hunting-ai-assistant/
python -m venv venvAgora, abra o projeto em seu IDE Python favorito. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Dentro da pasta do projeto, crie um novo arquivo chamado assistant.py. Sua estrutura de diretórios deve ser semelhante a esta:
linkedin-job-hunting-ai-assistant/
├── venv/
└── assistant.pyAtive o ambiente virtual em seu terminal. No Linux ou macOS, execute:
source venv/bin/activateDe forma equivalente, no Windows, inicie este comando:
venv/Scripts/activateNas próximas etapas, você será orientado na instalação dos pacotes Python necessários. Se você preferir instalar todos eles agora, no ambiente virtual ativado, execute:
pip install python-dotenv requests openai pydanticEm particular, as bibliotecas necessárias são:
python-dotenv: Carrega variáveis de ambiente de um arquivo.env, facilitando o gerenciamento seguro de chaves de API.pydantic: Ajuda a validar e analisar o arquivo de configuração em objetos Python estruturados.requests: Trata as solicitações HTTP para chamar APIs como Bright Data e recuperar dados.openai: Fornece o cliente OpenAI para interagir com os modelos de linguagem da OpenAI para pontuação de trabalho de IA.
Observação: estamos instalando a biblioteca openai aqui porque este tutorial depende da OpenAI como provedor de modelo de linguagem. Se você planeja usar um provedor de LLM diferente, certifique-se de instalar o SDK ou as dependências correspondentes.
Está tudo pronto! Seu ambiente de desenvolvimento Python agora está pronto para criar um fluxo de trabalho de IA usando o OpenAI e o Bright Data.
Etapa 1: carregar os argumentos da CLI
O script de IA de busca de emprego do LinkedIn requer alguns argumentos. Para mantê-lo reutilizável e personalizável sem alterar o código, você deve lê-los por meio da CLI.
Em detalhes, você precisará dos seguintes argumentos da CLI:
--config_file: O caminho para o arquivo de configuração JSON que contém seus parâmetros de busca de emprego, detalhes do perfil do candidato e descrição do emprego desejado. O padrão éconfig.json.--batch_size: O número de trabalhos a serem enviados à IA para pontuação de cada vez. O padrão é5.--jobs_number: O número máximo de entradas de trabalho que o raspador de trabalhos do LinkedIn da Bright Data deve retornar. O padrão é20.--output_csv: o nome do arquivo CSV de saída que contém os dados enriquecidos do trabalho com pontuações e comentários da IA. O padrão éjobs_scored.csv.
Leia esses argumentos na interface da linha de comando usando a seguinte função:
def parse_cli_args():
# Analisar argumentos da linha de comando para opções de configuração e tempo de execução
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Caminho para o arquivo JSON de configuração")
parser.add_argument("--jobs_number", type=int, default=20, help="Limitar o número de trabalhos retornados pela API do Bright Data Scraper")
parser.add_argument("--batch_size", type=int, default=5, help="Número de trabalhos a serem pontuados em cada lote")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Nome do arquivo CSV de saída")
return parser.parse_args()Não se esqueça de importar argparse da biblioteca padrão do Python:
import argparseÓtimo! Agora você tem acesso aos argumentos da CLI.
Etapa 2: carregar as variáveis de ambiente
Configure seu script para ler os segredos das variáveis de ambiente. Para simplificar o carregamento de variáveis de ambiente, use o pacote python-dotenv. Com seu ambiente virtual ativado, instale-o executando:
pip install python-dotenvEm seguida, em seu arquivo assistant.py, importe a biblioteca e chame load_dotenv() para carregar suas variáveis de ambiente:
from dotenv import load_dotenv
load_dotenv()Seu assistente agora pode ler as variáveis de um arquivo .env local. Portanto, adicione um arquivo .env à raiz do diretório do seu projeto:
linkedin-job-hunting-ai-assistant/
├── venv/
├── .env # <-----------
└─── assistant.pyAbra o arquivo .env e adicione os envs OPENAI_API_KEY e BRIGHT_DATA_API_KEY a ele:
OPENAI_API_KEY="<SUA_OPENAI_API_KEY>"
BRIGHT_DATA_API_KEY="<SUA_CHAVE_DE_API_DE_DADOS_BRILHANTES>"Substitua o espaço reservado <YOUR_OPENAI_API_KEY> pela sua chave de API OpenAI real. Da mesma forma, substitua o espaço reservado <YOUR_BRIGHT_DATA_API_KEY> pela sua chave de API do Bright Data.
Em seguida, adicione esta função ao seu script para carregar essas duas variáveis de ambiente:
def load_env_vars():
# Ler as chaves de API necessárias do ambiente e verificar a presença
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
se não for openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
se estiver faltando:
raise EnvironmentError(
f "Variáveis de ambiente necessárias ausentes: {', '.join(missing)}n"
"Defina-as em seu .env ou ambiente."
)
return openai_api_key, brightdata_api_keyAdicione a importação necessária da biblioteca padrão do Python:
import osMaravilhoso! Agora você carregou com segurança os segredos de integração de terceiros usando variáveis de ambiente.
Etapa nº 3: carregar o arquivo de configuração
Agora, você precisa de uma forma programática para informar ao seu assistente em quais empregos você está interessado. Para que os resultados sejam precisos, o assistente também deve conhecer a sua experiência profissional e o tipo de emprego que você está procurando.
Para evitar a codificação dessas informações diretamente em seu código, faz sentido lê-las em um arquivo de configuração JSON. Especificamente, esse arquivo deve conter:
localização: A localização geográfica onde você deseja procurar empregos. Isso define a área principal onde as listagens de empregos serão coletadas.palavra-chave: palavras ou frases específicas relacionadas ao título da vaga ou à função que você está procurando, como “Desenvolvedor Python”. Use aspas para impor correspondências exatas.país: Um código de país de duas letras (por exemplo,USpara os Estados Unidos,FRpara a França) para restringir a busca de vagas a um país específico.time_range: O período de tempo em que as publicações de vagas foram feitas, para filtrar vagas recentes ou relevantes (por exemplo,semana passada,mês passadoetc.).job_type: O tipo de emprego a ser filtrado, comoTempo integral,Meio período, etc.experience_level: O nível exigido de experiência profissional, comoEntry level,Associate, etc.remote: Filtrar vagas com base no modo de localização do trabalho (por exemplo,remoto,no localouhíbrido).empresa: Concentra a pesquisa em vagas de emprego de uma empresa ou empregador específico.selective_search: Quando ativada, exclui as listagens de empregos cujos títulos não contêm as palavras-chave especificadas para produzir resultados mais direcionados.jobs_to_not_include: Uma lista de IDs de empregos específicos a serem excluídos dos resultados da pesquisa, útil para remover duplicatas ou publicações indesejadas.location_radius: Define até onde a pesquisa deve se estender em torno do local especificado, incluindo áreas próximas.profile_summary: um resumo de seu perfil profissional. Essas informações são usadas pela IA para avaliar a adequação de cada emprego a você.desired_job_summary: uma breve descrição do tipo de emprego que você está procurando, ajudando a IA a classificar as listas de empregos com base na adequação.
Eles correspondem exatamente aos argumentos exigidos pela API “discover by keyword” (descobrir por palavra-chave) das listas de empregos do LinkedIn da Bright Data (que faz parte da solução LinkedIn Jobs Scraper):
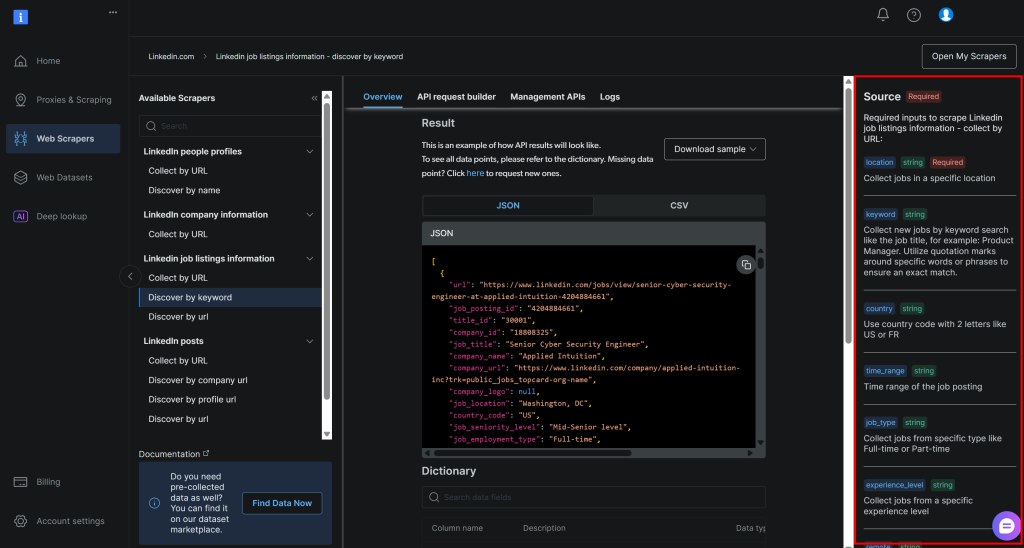
Para obter mais informações sobre esses campos e quais valores eles podem assumir, consulte a documentação oficial.
Os dois últimos campos(profile_summary e desired_job_summary) descrevem quem você é profissionalmente e o que está procurando. Eles serão passados à IA para classificar cada anúncio de emprego retornado pela Bright Data.
Para facilitar o manuseio do arquivo de configuração no código, é uma boa ideia mapeá-lo para um modelo Pydantic. Primeiro, instale o Pydantic em seu ambiente virtual:
pip install pydanticEm seguida, defina o modelo Pydantic mapeando o arquivo de configuração JSON conforme abaixo:
class JobSearchConfig(BaseModel):
location: str
keyword: Optional[str] = None
country: Optional[str] = None
time_range: Optional[str] = None
job_type: Optional[str] = None
experience_level: Optional[str] = None
remote: Optional[str] = None
company (empresa): Optional[str] = None
selective_search: Optional[bool] = Field(default=False)
jobs_to_not_include: Optional[List[str]] = Field(default_factory=list)
location_radius: Optional[str] = None
# Campos adicionais
profile_summary: str # Resumo do perfil do candidato para pontuação de IA
desired_job_summary: str # Descrição do cargo desejado para pontuação de IAObserve que somente o primeiro e os dois últimos campos de configuração são obrigatórios.
Em seguida, crie uma função para ler as configurações JSON do caminho do arquivo --config_file. Deserialize-a em uma instância JobSearchConfig:
def load_and_validate_config(filename: str) -> JobSearchConfig:
# Carrega o arquivo de configuração JSON
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Arquivo de configuração '{filename}' não encontrado.")
try:
# Deserializar os dados JSON de entrada para uma instância de JobSearchConfig
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f "Config deserialization error:n{e}")
return configDesta vez, você precisará dessas importações:
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
import jsonMuito bom! Agora seu arquivo de configuração foi lido e desserializado corretamente, conforme pretendido.
Etapa 4: extrair os trabalhos do LinkedIn
Chegou a hora de usar a configuração que você carregou anteriormente para chamar a API do Raspador de Empregos do LinkedIn da Bright Data.
Se você não estiver familiarizado com o funcionamento das APIs do raspador da Web da Bright Data, vale a pena verificar a documentação primeiro.
Em resumo, as APIs do Web Scraper fornecem pontos de extremidade de API que permitem que você recupere dados públicos de domínios específicos. Nos bastidores, a Bright Data inicializa e executa uma tarefa de raspagem pronta em seus servidores. Essas APIs lidam com rotação de IP, CAPTCHA e outras medidas para coletar dados públicos de páginas da Web de forma eficaz e ética. Após a conclusão da tarefa, os dados extraídos são analisados em um formato estruturado e disponibilizados para você como um instantâneo.
Portanto, o fluxo de trabalho geral é:
- Acionar a chamada de API para iniciar uma tarefa de raspagem da Web.
- Verificar periodicamente se o instantâneo que contém os dados extraídos está pronto.
- Recuperar os dados do instantâneo quando ele estiver disponível.
Você pode implementar a lógica acima com apenas algumas linhas de código:
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Aciona a pesquisa de empregos no LinkedIn da Bright Data
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f "Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # ID do conjunto de dados Bright Data "Linkedin job listings information - discover by keyword
"include_errors": "true",
"type" (tipo): "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Preparar carga útil para a Bright Data API com base na configuração do usuário
data = [{
"location": config.location,
"keyword": config.keyword ou "",
"country": config.country ou "",
"time_range": config.time_range ou "",
"job_type": config.job_type ou "",
"experience_level": config.experience_level ou "",
"remote": config.remote ou "",
"company": config.company ou "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include ou "",
"location_radius": config.location_radius ou "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
se response.status_code != 200:
raise RuntimeError(f "Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("Nenhum snapshot_id retornado do acionador de dados brilhantes.")
print(f "LinkedIn job search triggered! Snapshot ID: {snapshot_id}")
# Sondar o endpoint do snapshot até que os dados estejam prontos ou o tempo limite
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "Bearer {brightdata_api_key}"}
print(f "Polling snapshot for ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# O snapshot está pronto: retorna os dados JSON das postagens de trabalho
print("O instantâneo está pronto")
return snap_resp.json()
elif snap_resp.status_code == 202:
# O instantâneo ainda não está pronto: aguarde e tente novamente
print(f "O snapshot ainda não está pronto. Tentando novamente em {polling_timeout} segundos...")
time.sleep(polling_timeout)
else:
raise RuntimeError(f "Falha na sondagem do instantâneo: {snap_resp.status_code} - {snap_resp.text}")Essa função aciona o LinkedIn Jobs Scraper da Bright Data usando parâmetros de pesquisa do arquivo de configuração, garantindo que você obtenha apenas listagens que correspondam aos seus critérios. Em seguida, ele pesquisa até que o instantâneo de dados esteja pronto e, quando disponível, retorna as listagens de empregos no formato JSON. Observe que a autenticação é tratada usando a chave da API da Bright Data carregada anteriormente a partir de suas variáveis de ambiente.
O instantâneo recuperado com o LinkedIn Jobs Scraper conterá listagens de empregos no formato JSON como este:
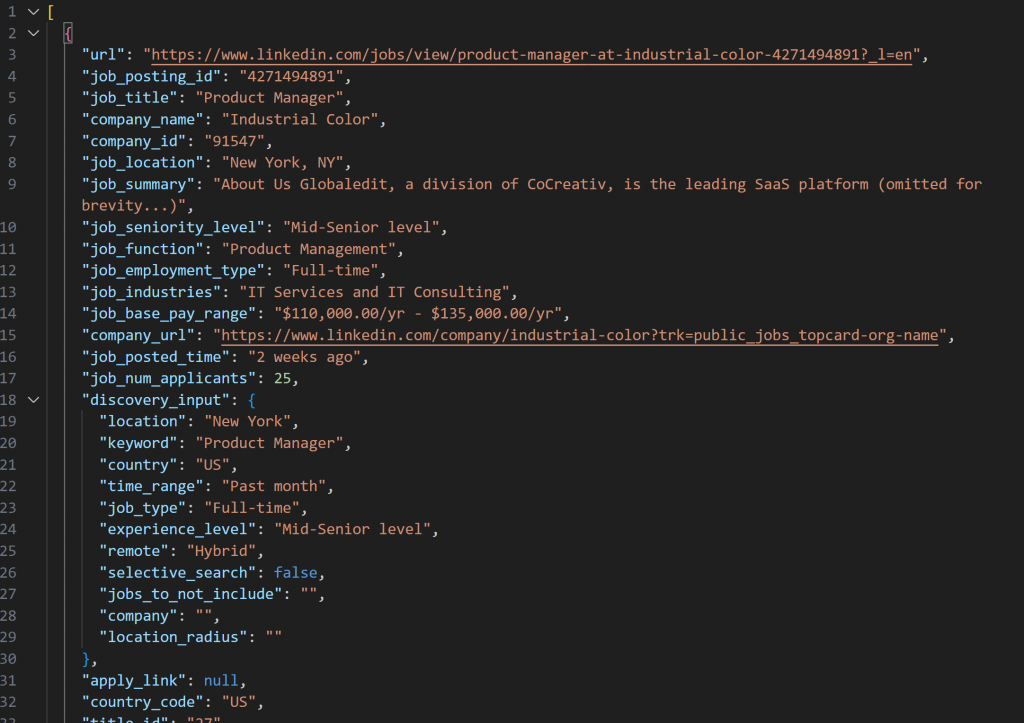
Observação: O instantâneo JSON produzido contém exatamente até --jobs_number empregos. Nesse caso, ele contém 20 empregos.
Para que a função acima funcione, você precisa instalar o requests:
pip install requestsPara obter mais informações sobre como funciona, consulte nosso guia avançado sobre Python HTTP Requests.
Em seguida, não se esqueça de importá-lo junto com o time da biblioteca padrão do Python:
importar requests
importar timeExcelente! Você acabou de se integrar à Bright Data para coletar dados novos e específicos das listas de empregos do LinkedIn.
Etapa 5: Pontuar os empregos por meio de IA
Agora, é hora de pedir a um LLM (como os modelos da OpenAI) que avalie cada anúncio de emprego extraído.
O objetivo é atribuir uma pontuação de 0 a 100, juntamente com um breve comentário, com base na adequação da vaga:
- Sua experiência de trabalho
(profile_summary) - Sua posição desejada
(desired_job_summary)
Para reduzir as idas e vindas da API e acelerar o processo, faz sentido processar os trabalhos em lotes. Em particular, você avaliará um número --batch_size de trabalhos de cada vez.
Comece instalando o pacote openai:
pip install openaiEm seguida, importe o OpenAI e inicialize o cliente:
from openai import OpenAI
# ...
# Inicializar o cliente OpenAI
cliente = OpenAI()Observe que não é necessário passar manualmente sua chave de API para o construtor do OpenAI. A biblioteca a lê automaticamente da variável de ambiente OPENAI_API_KEY, que você já definiu.
Prossiga criando a função de pontuação de trabalho acionada por IA:
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Construa o prompt para a IA pontuar as correspondências de trabalho com base no perfil do candidato
prompt = f"""
"Você é um recrutador especialista. Dado o seguinte perfil de candidato:n""
"{profile_summary}nn"
"Descrição do cargo desejado:n{desired_job_summary}nn"
"Pontue cada anúncio de emprego com precisão, de 0 a 100, de acordo com o quanto ele corresponde ao perfil e ao emprego desejado.n"
"Para cada vaga, adicione um breve comentário (máximo de 50 palavras) explicando a pontuação e a qualidade da correspondência.n"
"Retorne uma matriz de objetos com as chaves 'job_posting_id', 'score' e 'comment'.nn"
"Trabalhos:n{json.dumps(jobs_batch)}n"
"""
mensagens = [
{"role": "system" (sistema), "content" (conteúdo): "Você é um assistente útil de pontuação de trabalhos"},
{"role": "user" (usuário), "content" (conteúdo): prompt},
]
# Use a API OpenAI para analisar a resposta estruturada no modelo JobScoresResponse
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Retorna a lista de trabalhos pontuados
return response.output_parsed.scoresIsso usa o novo modelo gpt-5-mini para que o OpenAI pontue cada publicação de trabalho extraída de 0 a 100, juntamente com um breve comentário explicativo.
Para garantir que a resposta seja sempre retornada no formato exato de que você precisa, o método parse() é chamado. Esse método impõe um modelo de saída estruturado, definido aqui com os seguintes modelos Pydantic:
class JobScore(BaseModel):
job_posting_id: str
score: int = Field(..., ge=0, le=100)
comentário: str
class JobScoresResponse(BaseModel):
scores: List[JobScore]Basicamente, a IA retornará dados JSON estruturados como abaixo:
{
"scores": [
{
"job_posting_id": "4271494891",
"score": 80,
"comment": "Forte adequação ao produto SaaS com propriedade de ponta a ponta, APIs e trabalho multifuncional - alinha-se com seu PM de startup e experiência de colocar o cliente em primeiro lugar. A função tem como meta de 2 a 4 anos, portanto, é ligeiramente júnior para seus 7 anos."
},
// omitido por brevidade...
{
"job_posting_id": "4273328527",
"score": 65,
"comment": "Função de produto com grande ênfase em dados/técnica; as responsabilidades ágeis e multifuncionais estão alinhadas, mas é preferível ter experiência em domínio quantitativo/técnico (finanças/modelagem estatística), o que pode ser menos adequado."
}
]
}O método parse() converterá a resposta JSON em uma instância de JobScoresResponse. Em seguida, você poderá acessar programaticamente as pontuações e os comentários em seu código.
Observação: se você preferir usar um provedor de LLM diferente, certifique-se de ajustar o código acima para trabalhar com o provedor escolhido.
Aqui vamos nós! A avaliação do trabalho de IA está concluída.
Etapa nº 6: expandir os trabalhos com acores e comentários de IA
Dê uma olhada na saída JSON bruta retornada pela IA mostrada anteriormente. Você pode ver que cada pontuação de trabalho contém um campo job_posting_id. Isso corresponde ao ID que o LinkedIn usa para identificar as listagens de empregos.
Como esses IDs também aparecem nos dados de instantâneos produzidos pelo raspador de empregos do LinkedIn da Bright Data, você pode usá-los para:
- Encontrar os objetos originais de anúncio de emprego na matriz de empregos extraídos.
- Enriquecer esse objeto de anúncio de emprego adicionando a pontuação e o comentário gerados pela IA.
Faça isso com a seguinte função:
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Onde armazenar os dados enriquecidos
extended_jobs = []
# Combinar trabalhos originais com pontuações e comentários de IA
para score_obj em all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
pausa
se trabalho_correspondido:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# Ordenar os trabalhos estendidos pela pontuação de IA (a mais alta primeiro)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobsComo você pode ver, alguns loops for são suficientes para realizar a tarefa. Antes de retornar os dados enriquecidos, classifique a lista em ordem decrescente por ai_score. Dessa forma, os trabalhos com melhor correspondência aparecem no topo, tornando-os rápidos e fáceis de identificar.
Legal! Seu assistente de IA para caça a empregos no LinkedIn está quase pronto para funcionar!
Etapa nº 7: Exportar os dados dos empregos pontuados
Use o pacote csv integrado do Python para exportar os dados de empregos extraídos e enriquecidos para um arquivo CSV.
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Obter dinamicamente os nomes dos campos do primeiro elemento da matriz
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Gravar dados de trabalho estendidos com pontuações de IA em CSV
escritor = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writerow(job)
print(f "Exported {len(extended_jobs)} jobs to {output_csv}") A função acima será chamada substituindo output_csv pelo argumento --output_csv da CLI.
Não se esqueça de importar o csv:
import csvPerfeito! O assistente de IA de busca de emprego do LinkedIn agora exporta os dados enriquecidos com IA para um arquivo CSV de saída.
Etapa 8: Imprimir as principais correspondências de emprego
Para obter feedback imediato no terminal sem abrir o arquivo CSV de saída, escreva uma função para imprimir os principais detalhes das 3 principais correspondências de emprego:
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** Top {top} job matches ***")
for job in extended_jobs[:3]:
print(f "URL: {job.get('url', 'N/A')}")
print(f "Title: {job.get('job_title', 'N/A')}")
print(f "AI Score: {job.get('ai_score')}")
print(f "AI Comment: {job.get('ai_comment', 'N/A')}")
print("-" * 40)Etapa 9: Juntar tudo
Combine todas as funções das etapas anteriores na lógica principal do assistente de busca de emprego do LinkedIn:
# Obter parâmetros de tempo de execução da CLI
args = parse_cli_args()
try:
# Carregar chaves de API do ambiente
_, brightdata_api_key = load_env_vars()
# Carregar arquivo de configuração de busca de trabalho
config = load_and_validate_config(args.config_file)
# Buscar trabalhos
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs found!")
except Exception as e:
print(f"[Error] {e}")
return
all_scores = []
# Processar trabalhos em lotes para evitar sobrecarregar a API e lidar com grandes conjuntos de dados
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f "Pontuação do lote {i // args.batch_size + 1} com {len(batch)} trabalhos...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # Para evitar o acionamento dos limites de taxa da API
# Mesclar pontuações em trabalhos extraídos
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Salvar os resultados em CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Imprimir as principais correspondências de trabalho com informações importantes para revisão rápida
print_top_jobs(extended_jobs)Incrível! Resta apenas revisar o código completo do assistente e verificar se ele funciona conforme o esperado.
Etapa nº 10: Código completo e primeira execução
Seu arquivo assistant.py final deve conter:
# pip install python-dotenv requests openai pydantic
import argparse
from dotenv import load_dotenv
import os
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
import json
import requests
import time
from openai import OpenAI
importar csv
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Modelos Pydantic que suportam o projeto
class JobSearchConfig(BaseModel):
# Fonte: https://docs.brightdata.com/api-reference/web-scraper-api/social-media-apis/linkedin#discover-by-keyword
localização: str
keyword: Optional[str] = None
country (país): Optional[str] = None
time_range: Optional[str] = None
job_type: Optional[str] = None
experience_level: Optional[str] = None
remote: Optional[str] = None
company (empresa): Optional[str] = None
selective_search: Optional[bool] = Field(default=False)
jobs_to_not_include: Optional[List[str]] = Field(default_factory=list)
location_radius: Optional[str] = None
# Campos adicionais
profile_summary: str # Resumo do perfil do candidato para pontuação de IA
desired_job_summary: str # Descrição do cargo desejado para pontuação de IA
class JobScore(BaseModel):
job_posting_id: str
score: int = Field(..., ge=0, le=100)
comentário: str
class JobScoresResponse(BaseModel):
scores: List[JobScore]
def parse_cli_args():
# Analisar argumentos da linha de comando para opções de configuração e tempo de execução
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Caminho para o arquivo JSON de configuração")
parser.add_argument("--jobs_number", type=int, default=20, help="Limitar o número de trabalhos retornados pela API do Bright Data Scraper")
parser.add_argument("--batch_size", type=int, default=5, help="Número de trabalhos a serem pontuados em cada lote")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Nome do arquivo CSV de saída")
return parser.parse_args()
def load_env_vars():
# Ler as chaves de API necessárias do ambiente e verificar a presença
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
se não for openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
se estiver faltando:
raise EnvironmentError(
f "Variáveis de ambiente necessárias ausentes: {', '.join(missing)}n"
"Defina-as em seu .env ou ambiente."
)
return openai_api_key, brightdata_api_key
def load_and_validate_config(filename: str) -> JobSearchConfig:
# Carrega o arquivo de configuração JSON
try:
with open(filename, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Arquivo de configuração '{filename}' não encontrado.")
try:
# Deserielizar os dados JSON de entrada para uma instância de JobSearchConfig
config = JobSearchConfig(**data)
except ValidationError as e:
raise ValueError(f "Config deserialization error:n{e}")
return config
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Aciona a pesquisa de empregos no LinkedIn da Bright Data
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": f "Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # ID do conjunto de dados Bright Data "Linkedin job listings information - discover by keyword
"include_errors": "true",
"type" (tipo): "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Preparar carga útil para a Bright Data API com base na configuração do usuário
data = [{
"location": config.location,
"keyword": config.keyword ou "",
"country": config.country ou "",
"time_range": config.time_range ou "",
"job_type": config.job_type ou "",
"experience_level": config.experience_level ou "",
"remote": config.remote ou "",
"company": config.company ou "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include ou "",
"location_radius": config.location_radius ou "",
}]
response = requests.post(url, headers=headers, params=params, json=data)
se response.status_code != 200:
raise RuntimeError(f "Trigger request failed: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("Nenhum snapshot_id retornado do acionador de dados brilhantes.")
print(f "LinkedIn job search triggered! Snapshot ID: {snapshot_id}")
# Sondar o endpoint do snapshot até que os dados estejam prontos ou o tempo limite
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "Bearer {brightdata_api_key}"}
print(f "Polling snapshot for ID: {snapshot_id}")
while True:
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# O snapshot está pronto: retorna os dados JSON das postagens de trabalho
print("O instantâneo está pronto")
return snap_resp.json()
elif snap_resp.status_code == 202:
# O instantâneo ainda não está pronto: aguarde e tente novamente
print(f "O snapshot ainda não está pronto. Tentando novamente em {polling_timeout} segundos...")
time.sleep(polling_timeout)
else:
raise RuntimeError(f "Falha na sondagem do instantâneo: {snap_resp.status_code} - {snap_resp.text}")
# Inicializar o cliente OpenAI
cliente = OpenAI()
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Constrói o prompt para a IA pontuar as correspondências de trabalho com base no perfil do candidato
prompt = f"""
"Você é um recrutador especialista. Dado o seguinte perfil de candidato:n""
"{profile_summary}nn"
"Descrição do cargo desejado:n{desired_job_summary}nn"
"Pontue cada anúncio de emprego com precisão, de 0 a 100, de acordo com o quanto ele corresponde ao perfil e ao emprego desejado.n"
"Para cada vaga, adicione um breve comentário (máximo de 50 palavras) explicando a pontuação e a qualidade da correspondência.n"
"Retorne uma matriz de objetos com as chaves 'job_posting_id', 'score' e 'comment'.nn"
"Trabalhos:n{json.dumps(jobs_batch)}n"
"""
mensagens = [
{"role": "system" (sistema), "content" (conteúdo): "Você é um assistente útil de pontuação de trabalhos"},
{"role": "user" (usuário), "content" (conteúdo): prompt},
]
# Use a API OpenAI para analisar a resposta estruturada no modelo JobScoresResponse
response = client.responses.parse(
model="gpt-5-mini",
input=messages,
text_format=JobScoresResponse,
)
# Retorna a lista de trabalhos pontuados
return response.output_parsed.scores
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Onde armazenar os dados enriquecidos
extended_jobs = []
# Combinar trabalhos originais com pontuações e comentários de IA
para score_obj em all_scores:
matched_job = None
for job in jobs:
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
pausa
se trabalho_correspondido:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = score_obj.comment
extended_jobs.append(job_with_score)
# Ordenar os trabalhos estendidos pela pontuação de IA (a mais alta primeiro)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return extended_jobs
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Obter dinamicamente os nomes dos campos do primeiro elemento da matriz
fieldnames = list(extended_jobs[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Gravar dados de trabalho estendidos com pontuações de IA em CSV
escritor = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in extended_jobs:
writer.writerow(job)
print(f "Exported {len(extended_jobs)} jobs to {output_csv}")
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** Top {top} job matches ***")
for job in extended_jobs[:3]:
print(f "URL: {job.get('url', 'N/A')}")
print(f "Title: {job.get('job_title', 'N/A')}")
print(f "AI Score: {job.get('ai_score')}")
print(f "AI Comment: {job.get('ai_comment', 'N/A')}")
print("-" * 40)
def main():
# Obter parâmetros de tempo de execução da CLI
args = parse_cli_args()
try:
# Carregar chaves de API do ambiente
_, brightdata_api_key = load_env_vars()
# Carregar arquivo de configuração de busca de trabalho
config = load_and_validate_config(args.config_file)
# Buscar trabalhos
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f"{len(jobs_data)} jobs found!")
except Exception as e:
print(f"[Error] {e}")
return
all_scores = []
# Processar trabalhos em lotes para evitar sobrecarregar a API e lidar com grandes conjuntos de dados
for i in range(0, len(jobs_data), args.batch_size):
batch = jobs_data[i : i + args.batch_size]
print(f "Pontuação do lote {i // args.batch_size + 1} com {len(batch)} trabalhos...")
scores = score_jobs_batch(batch, config.profile_summary, config.desired_job_summary)
all_scores.extend(scores)
time.sleep(1) # Para evitar o acionamento dos limites de taxa da API
# Mesclar pontuações em trabalhos extraídos
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Salvar os resultados em CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Imprimir as principais correspondências de trabalho com informações importantes para revisão rápida
print_top_jobs(extended_jobs)
se __name__ == "__main__":
main()Suponha que você seja um gerente de produto com 7 anos de experiência e esteja procurando um emprego híbrido em Nova York. Configure seu arquivo config.json da seguinte forma:
{
"location" (local): "New York",
"keyword" (palavra-chave): "Product Manager" (gerente de produto),
"country" (país): "US",
"time_range": "Mês passado",
"job_type": "Tempo integral",
"experience_level": "Mid-Senior level" (Nível médio-sênior),
"remoto": "Hybrid",
"profile_summary": "Gerente de produtos experiente, com 7 anos de experiência em startups de tecnologia, especializado em metodologias ágeis e liderança de equipes multifuncionais."
"resumo_do_emprego_desejado": "Procurando uma função de gerente de produtos em tempo integral com foco em produtos SaaS e desenvolvimento centrado no cliente."
}Em seguida, você pode executar o assistente de busca de emprego do LinkedIn com:
python assistant.pyOpcional: Para uma execução personalizada, escreva algo como:
python assistant.py --config_file=config.json --batch_size=10 --jobs_number=40 --output_csv=results.csvEsse comando executa o assistente usando o arquivo config.json especificado. Ele processa trabalhos em lotes de 10, recupera até 40 listagens de trabalhos da Bright Data e salva os resultados enriquecidos com pontuações de IA e comentários em results.csv.
Agora, se você executar o assistente com os argumentos padrão da CLI, deverá ver algo parecido com isto no terminal:
Busca de emprego no LinkedIn acionada! ID do instantâneo: s_me6x0s3qldm9zz0wv
Polling snapshot para ID: s_me6x0s3qldm9zz0wv
O instantâneo ainda não está pronto. Nova tentativa em 10 segundos...
# Omitido por brevidade...
O instantâneo ainda não está pronto. Nova tentativa em 10 segundos...
O instantâneo está pronto
20 trabalhos encontrados!
Pontuação do lote 1 com 5 trabalhos...
Pontuação do lote 2 com 5 trabalhos...
Lote de pontuação 3 com 5 trabalhos...
Pontuação do lote 4 com 5 trabalhos...
Exportou 20 trabalhos para jobs.csvEntão, a saída com as 3 principais percepções de trabalho será algo como:
*** 3 principais correspondências de trabalho ***
URL: https://www.linkedin.com/jobs/view/product-manager-growth-at-yext-4267903356?_l=en
Título: Gerente de produtos, crescimento
Pontuação de IA: 92
Comentário da IA: Excelente ajuste: PM de crescimento focado em SaaS com objetivos centrados no cliente, crescimento liderado pelo produto, experimentação e colaboração multifuncional - correspondência direta com a experiência do candidato e a função desejada.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-industrial-color-4271494891?_l=en
Título: Gerente de produto
Pontuação de IA: 90
Comentário da IA: Forte combinação: Produto SaaS, API/integrações, liderança ágil e multifuncional enfatizada. A única pequena incompatibilidade é a meta listada de 2 a 4 anos (você tem 7), o que provavelmente o torna superqualificado, mas altamente aplicável.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-resourceful-talent-group-4277945862?_l=en
Título: Gerente de produto
Pontuação de IA: 88
Comentário da IA: Função de SaaS/integrações muito semelhante, com práticas ágeis e iteração orientada ao cliente. A listagem do recrutador tem como meta de 2 a 4 anos, mas seus 7 anos de experiência em gerência de startups e liderança multifuncional são bem compatíveis.
----------------------------------------Abra o arquivo jobs_scored.csv gerado. Nas colunas principais, você verá:
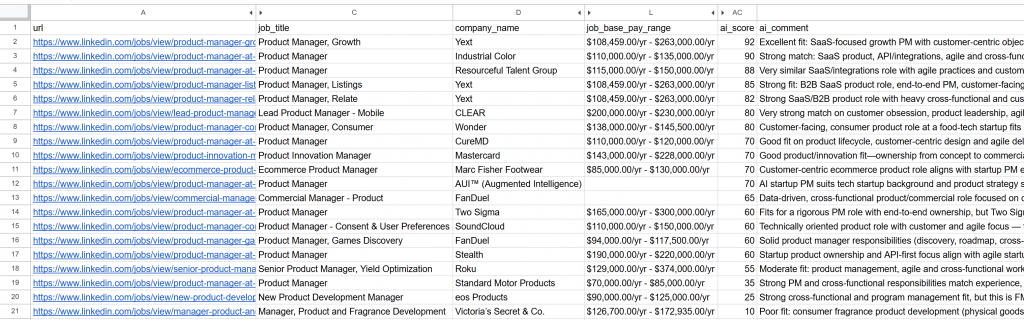
Observe como cada trabalho foi pontuado e comentado pela IA. Isso o ajuda a se concentrar apenas nos trabalhos em que você tem uma chance real de sucesso!
E pronto! Graças a esse fluxo de trabalho de busca de emprego no LinkedIn com tecnologia de IA, encontrar seu próximo emprego nunca foi tão fácil.
Próximos passos
O assistente de busca de emprego do LinkedIn criado aqui funciona como um bate-papo, mas há alguns aprimoramentos que vale a pena explorar:
- Evite avaliar os mesmos empregos repetidamente: Para avaliar trabalhos diferentes cada vez que você executar o script, defina a matriz
jobs_to_not_includeem seu arquivoconfig.json. Ele deve conter osjob_posting_idsdos trabalhos que o assistente já analisou. Por exemplo, para excluir os trabalhos raspados atuais, sua configuração pode ter a seguinte aparência:
{
"location": "New York",
"keyword" (palavra-chave): "Product Manager",
"country" (país): "US",
"time_range": "Mês passado",
"job_type": "Tempo integral",
"experience_level": "Mid-Senior level" (Nível médio-sênior),
"remoto": "Hybrid",
"jobs_to_not_include": ["4267903356", "4271494891", "4277945862", "4267906118", "4255405781", "4267537560", "4245709356", "4265355147", "4277751182", "4256914967", "4281336197", "4232207277", "4273328527", "4277435772", "4253823512", "4279286518", "4224506933", "4250788498", "4256023955", "4252894407"], // <--- OBSERVAÇÃO: as IDs dos trabalhos a serem excluídos
"profile_summary": "Gerente de produto experiente com 7 anos em startups de tecnologia, especializado em metodologias ágeis e liderança de equipes multifuncionais.",
"desired_job_summary": "Procurando uma função de gerente de produto em tempo integral com foco em produtos SaaS e desenvolvimento centrado no cliente."
}- Automatize execuções periódicas de scripts: Programe o script para ser executado regularmente (por exemplo, diariamente) com ferramentas como o Cron. Nesse caso, lembre-se de definir o argumento
time_rangecorreto (por exemplo, “Past 24 hours”) e atualize a listajobs_to_not_includepara excluir os trabalhos que você já avaliou. Isso ajuda você a se concentrar em novas publicações. - Use um modelo de juiz de IA dedicado: Em vez de um modelo GPT-5 geral, considere usar um modelo de IA especializado e ajustado para correspondência e pontuação de empregos. Essa simples mudança pode melhorar muito a precisão e a relevância das avaliações de cargos.
Conclusão
Neste artigo, você aprendeu como aproveitar os recursos de raspagem de empregos do LinkedIn da Bright Data para criar um assistente de busca de empregos com tecnologia de IA.
O fluxo de trabalho de IA criado aqui é perfeito para quem está procurando um novo emprego e deseja maximizar suas chances, concentrando-se apenas nas melhores oportunidades. Ele ajuda você a economizar tempo e energia candidatando-se a empregos que realmente correspondam às suas metas de carreira e que tenham uma chance maior de contratação.
Para criar fluxos de trabalho mais avançados, explore toda a gama de soluções para buscar, validar e transformar dados da Web ao vivo na infraestrutura de IA da Bright Data.
Crie uma conta gratuita na Bright Data e comece a fazer experiências com nossas ferramentas de dados prontas para IA!
Perguntas frequentes
O exemplo acima usa o LinkedIn como fonte de dados, mas você pode facilmente estender o script para trabalhar com o Indeed ou qualquer outra fonte de listagem de empregos disponível na Bright Data. Para obter mais detalhes sobre a integração com o Indeed, consulte o Indeed Jobs Scraper.
Esse fluxo de trabalho de IA se baseia no OpenAI devido à sua ampla adoção e popularidade. No entanto, você pode adaptar facilmente o fluxo de trabalho para operar com outros provedores de LLM, como Gemini, Anthropic, Cohere ou qualquer modelo de linguagem grande disponível na API.
Os dados retornados pelo LinkedIn Jobs Scraper são de tão alta qualidade e bem estruturados que você pode processá-los para pontuação usando um LLM diretamente. Por causa disso, você não precisa necessariamente da complexidade de um agente autônomo com recursos de raciocínio e tomada de decisão.
Ainda assim, se você quiser criar um agente de IA mais avançado para a busca de empregos no LinkedIn, poderá considerar a seguinte arquitetura de vários agentes:
Agente buscador de empregos: Um agente de IA integrado à infraestrutura da Bright Data (por meio de ferramentas ou MCP) que chama a API do LinkedIn Jobs Scraper para buscar e atualizar continuamente as listagens de empregos.
Agente pontuador de empregos: Um agente especializado em avaliar e pontuar empregos com base no perfil e nas preferências do candidato usando um LLM.
Agente orquestrador: Um agente de nível superior que coordena os outros dois agentes, acionando repetidamente a recuperação de dados e os ciclos de pontuação até obter um número desejado de listagens de empregos relevantes e com alta pontuação.
Você pode até programar o agente para se candidatar automaticamente a essas vagas de emprego para você. Se estiver pensando em criar um sistema de busca de emprego no LinkedIn, recomendamos o uso de uma plataforma multiagente como a CrewAI.




