
Neste tutorial, você aprenderá:
- O que é o Flyte e o que o torna especial para fluxos de trabalho de IA, dados e aprendizado de máquina.
- Por que os fluxos de trabalho do Flyte se tornam ainda mais avançados quando você incorpora dados da Web a eles.
- Como integrar o Flyte com o SDK da Bright Data para criar um fluxo de trabalho alimentado por IA para análise de SEO.
Vamos nos aprofundar!
O que é o Flyte?
O Flyte é uma plataforma de orquestração de fluxo de trabalho moderna e de código aberto que ajuda você a criar pipelines de IA, dados e aprendizado de máquina de nível de produção. Sua principal força está na unificação de equipes e pilhas de tecnologia, promovendo a colaboração entre cientistas de dados, engenheiros de ML e desenvolvedores.
Criado com base no Kubernetes, o Flyte foi desenvolvido para ser escalável, reprodutível e para processamento distribuído. Você pode usá-lo para definir fluxos de trabalho por meio de seu SDK Python. Em seguida, implemente-os em ambientes na nuvem ou no local, abrindo a porta para a utilização eficiente de recursos e o gerenciamento simplificado do fluxo de trabalho.
No momento em que este artigo foi escrito, o repositório do Flyte no GitHub contava com mais de 6,5 mil estrelas!
Principais recursos
Os principais recursos suportados pelo Flyte são:
- Interfaces fortemente tipadas: Defina os tipos de dados em cada etapa para garantir a exatidão e aplicar as proteções de dados.
- Imutabilidade: As execuções imutáveis garantem a reprodutibilidade ao impedir alterações no estado de um fluxo de trabalho.
- Linhagem de dados: Rastreie a movimentação e a transformação de dados em todo o ciclo de vida do fluxo de trabalho.
- Mapeamento de tarefas e paralelismo: Execute tarefas em paralelo de forma eficiente com o mínimo de configuração.
- Repetições granulares e recuperação de falhas: Tente novamente apenas tarefas com falha ou execute novamente tarefas específicas sem alterar os estados anteriores do fluxo de trabalho.
- Cache: armazene em cache os resultados das tarefas para otimizar as execuções repetidas.
- Fluxos de trabalho dinâmicos e ramificação: crie fluxos de trabalho adaptáveis que evoluem com base nos requisitos e executam ramificações seletivamente.
- Flexibilidade de linguagem: Desenvolva fluxos de trabalho usando Python, Java, Scala, SDKs JavaScript ou contêineres brutos em qualquer linguagem.
- Implementação nativa na nuvem: Implante o Flyte no AWS, GCP, Azure ou em outros provedores de nuvem.
- Simplicidade de desenvolvimento para produção: Mova os fluxos de trabalho do desenvolvimento ou da preparação para a produção sem nenhum esforço.
- Tratamento de entrada externa: Pause a execução até que as entradas necessárias estejam disponíveis.
Para explorar todos os recursos, consulte a documentação oficial do Flyte.
Por que os fluxos de trabalho de IA precisam de dados atualizados da Web
Os fluxos de trabalho de IA são tão poderosos quanto os dados que processam. É claro que os dados abertos são valiosos, mas o acesso a dados em tempo real é o que faz a diferença do ponto de vista comercial. E qual é a maior e mais rica fonte de dados? A Web!
Ao incorporar dados da Web em tempo real em seus fluxos de trabalho de IA, você pode obter insights mais profundos, melhorar a precisão das previsões e tomar decisões mais informadas. Por exemplo, tarefas como análise de SEO, pesquisa de mercado ou rastreamento do sentimento da marca dependem de informações atualizadas, que mudam constantemente on-line.
O problema é que obter dados atualizados da Web é um desafio. Os sites têm estruturas diferentes, exigem abordagens de raspagem diferentes e estão sujeitos a atualizações frequentes. É aí que entra uma solução como o Bright Data Python SDK!
O SDK permite que você pesquise, extraia e interaja com o conteúdo da Web ao vivo de forma programática. Mais especificamente, ele fornece acesso aos produtos mais úteis da infraestrutura da Bright Data por meio de apenas algumas chamadas de método simples. Isso torna o acesso aos dados da Web confiável e dimensionável.
Ao combinar os recursos da Web do Flyte e da Bright Data, você pode criar fluxos de trabalho automatizados de IA que se mantêm atualizados com a Web em constante mudança. Veja como no próximo capítulo!
Como criar um fluxo de trabalho de IA de SEO no Flyte e no SDK Python da Bright Data
Nesta seção guiada, você aprenderá a criar um agente de IA no Flyte que:
- Recebe uma palavra-chave (ou frase-chave) como entrada e usa o SDK da Bright Data para pesquisar resultados relevantes na Web.
- Utiliza o SDK da Bright Data para extrair as três principais páginas para a palavra-chave fornecida.
- Passa o conteúdo das páginas resultantes para o OpenAI para gerar um relatório Markdown com insights de SEO.
Em outras palavras, graças à integração Flyte + Bright Data, você criará um fluxo de trabalho de IA do mundo real para análise de SEO. Isso fornece insights acionáveis e relacionados ao conteúdo com base no que as páginas com melhor desempenho estão fazendo para obter uma boa classificação.
Vamos começar!
Pré-requisitos
Para acompanhar este tutorial, certifique-se de que você tenha:
- Python instalado localmente
- Uma chave de API da Bright Data (com permissões de administrador )
- Uma chave de API da OpenAI
Você será orientado na configuração da sua conta da Bright Data para uso com o Bright Data Python SDK, portanto, não precisa se preocupar com isso agora. Para obter mais informações, dê uma olhada na documentação.
O guia oficial de instalação do Flyte recomenda a instalação via uv. Portanto, instale/atualize o uv globalmente com:
pip install -U uvEtapa 1: Configuração do projeto
Abra um terminal e crie um novo diretório para seu projeto de IA de análise de SEO:
mkdir flyte-seo-workflowA pasta flyte-seo-workflow/ conterá o código Python para seu fluxo de trabalho Flyte.
Em seguida, navegue até o diretório do projeto:
cd flyte-seo-workflowNo momento em que este texto foi escrito, o Flyte suporta apenas as versões do Python >=3.9 e <3.13 (recomenda-se a versão 3.12 ).
Configure um ambiente virtual para o Python 3.12 com:
uv venv --python 3.12Ative o ambiente virtual. No Linux ou macOS, execute:
source .venv/bin/activateDe forma equivalente, no Windows, execute:
.venv/Scripts/activateAdicione um novo arquivo chamado workflow.py. Seu projeto agora deve conter:
flyte-seo-workflow/
├── .venv/
workflow.pyworkflow.py representa seu arquivo Python principal.
Com o ambiente virtual ativado, instale as dependências necessárias:
uv pip install flytekit brightdata-sdk openaiAs bibliotecas que você acabou de instalar são:
flytekit: Para criar fluxos de trabalho e tarefas do Flyte.brightdata-sdk: Para ajudá-lo a acessar as soluções da Bright Data em Python.openai: Para interagir com os LLMs da OpenAI.
Observação: o Flyte fornece um conector oficial do ChatGPT(ChatGPTTask), mas ele depende de uma versão mais antiga das APIs do OpenAI. Ele também vem com algumas limitações, como tempos limite rigorosos. Por esses motivos, geralmente é melhor prosseguir com uma integração personalizada.
Carregue o projeto em seu IDE Python favorito. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Pronto! Agora você tem um ambiente Python pronto para o desenvolvimento do fluxo de trabalho de IA no Flyte.
Etapa nº 2: conceber seu fluxo de trabalho de IA
Antes de ir direto para a codificação, é útil dar um passo atrás e pensar sobre o que o seu fluxo de trabalho de IA precisa fazer.
Primeiro, lembre-se de que um fluxo de trabalho do Flyte consiste em:
- Tarefas: Funções marcadas com a anotação
@task. Essas são as unidades fundamentais de computação no Flyte. As tarefas são executáveis de forma independente, fortemente tipadas e blocos de construção em contêineres que compõem os fluxos de trabalho. - Fluxosde trabalho: Marcados com
@workflow, os fluxos de trabalho são construídos encadeando tarefas, com a saída de uma tarefa alimentando a entrada da próxima para formar um gráfico acíclico direcionado (DAG).
Nesse caso, você pode atingir seu objetivo com as três tarefas simples a seguir:
get_seo_urls: Dada uma palavra-chave ou frase-chave de entrada, use o Bright Data SDK para recuperar os 3 principais URLs da SERP (página de resultados do mecanismo de pesquisa) resultante do Google.get_content_pages: Recebe os URLs como entrada e usa o SDK da Bright Data para extrair as páginas, retornando o conteúdo em formato Markdown(ideal para processamento de IA).generate_seo_report: Obtém a lista de conteúdo da página e a passa para um prompt, solicitando que ele produza um relatório Markdown contendo insights de SEO, como abordagens comuns, estatísticas importantes (número de palavras, parágrafos, H1s, H2s etc.) e outras métricas relevantes.
Prepare-se para implementar as tarefas e o fluxo de trabalho do Flyte importando-os do flytekit:
from flytekit import task, workflowMaravilhoso! Agora, tudo o que resta é implementar o fluxo de trabalho real.
Etapa nº 3: gerenciar as chaves de API
Antes de implementar as tarefas, você precisa cuidar do gerenciamento de chaves de API para as integrações OpenAI e Bright Data.
O Flyte vem com um sistema de gerenciamento de segredos dedicado, que permite que você manipule com segurança os segredos em seus scripts, como chaves e credenciais de API. Na produção, confiar no sistema de gerenciamento de segredos do Flyte é a melhor prática e altamente recomendada.
Para este tutorial, como estamos trabalhando com um script simples, podemos simplificar as coisas definindo as chaves de API diretamente no código:
importar os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHTDATA_API_TOKEN>"Substitua os espaços reservados por seus valores reais de chave de API:
<YOUR_OPENAI_API_KEY>→ Sua chave de API OpenAI.<YOUR_BRIGHT_DATA_API_TOKEN>→ Seu token de API da Bright Data (recupere-o conforme explicado no guia oficial da Bright Data)
Lembre-se de que é recomendável usar uma chave de API da Bright Data com permissões de administrador. Isso permite que o Bright Data Python SDK se conecte automaticamente à sua conta e configure os produtos necessários ao inicializar o cliente.
Em outras palavras, o Bright Data Python SDK com uma chave de API de administrador configurará automaticamente sua conta com tudo o que precisa para operar.
Lembre-se: Nunca codifique segredos em scripts de produção! Sempre use um gerenciador de segredos no Flyte.
Etapa nº 4: implementar a tarefa get_seo_urls
Defina uma função get_seo_urls() que aceite uma palavra-chave como string e anote-a com @task para que ela se torne uma tarefa válida do Flyte. Dentro da função, use o métodosearch() do Bright Data Python SDK para fazer uma pesquisa na Web.
Nos bastidores, search() chama a API SERP da Bright Data, que retorna os resultados da pesquisa como uma cadeia de caracteres JSON com este formato:
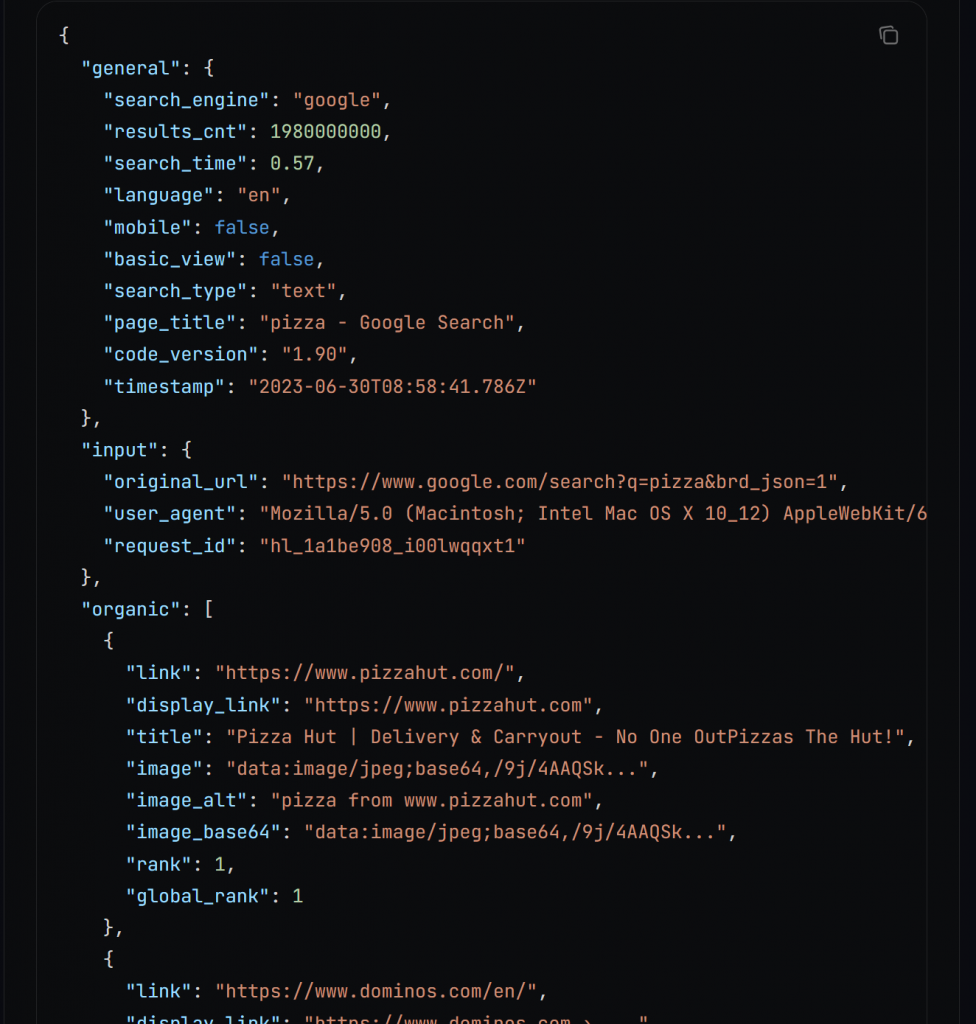
Saiba mais sobre o recurso de saída JSON na documentação.
Analise a cadeia de caracteres JSON em um dicionário e extraia um determinado número de URLs de SEO. Esses URLs correspondem aos X principais resultados que você normalmente obteria do Google ao pesquisar a palavra-chave de entrada.
Implemente a tarefa com:
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
import json
# Inicializar o cliente Bright Data SDK
from brightdata import bdclient
bright_data_client = bdclient()
# Obter o SERP do Google para a palavra-chave fornecida como uma cadeia de caracteres JSON analisada
res = bright_data_client.search(kw, response_format="json", parse=True)
json_response = res["body"]
dados = json.loads(json_response)
# Extrair os principais URLs da página de SEO "num_links" da SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urlsLembre-se da importação necessária para a digitação:
from typing import ListObservação: Você pode estar se perguntando por que o cliente Bright Data Python SDK é importado dentro da tarefa em vez de globalmente. Isso é intencional, pois as tarefas do Flyte devem ser executáveis de forma independente. Em outros termos, cada tarefa deve incluir tudo o que precisa para ser executada por conta própria, sem depender de dependências globais.
Etapa 5: implementar a tarefa get_content_pages
Agora que você recuperou os URLs de SEO, pode passá-los para o métodoscrape() do Bright Data Python SDK. Esse método extrai todas as páginas em paralelo e retorna seu conteúdo. Para receber a saída no formato Markdown, basta definir o argumento data_format="markdown":
@task()
def get_content_pages(page_urls:List[str]) -> List[str]:
# Inicializar o cliente Bright Data SDK
from brightdata import bdclient
bright_data_client = bdclient()
# Obter o conteúdo Markdown de cada página
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_listpage_content_list será uma lista de strings, em que cada string é a representação Markdown da página de entrada correspondente.
Por trás disso, scrape() chama a API Bright Data Web Unlocker. Essa é uma API de raspagem de uso geral capaz de acessar qualquer página da Web, independentemente de suas proteções anti-bot.
Independentemente dos URLs obtidos na tarefa anterior, get_content_pages() buscará com êxito o conteúdo deles e o converterá de HTML bruto em Markdown otimizado e pronto para IA.
Etapa 6: implementar a tarefa generate_seo_report
Chame a API da OpenAI com o prompt apropriado para gerar um relatório de SEO com base no conteúdo da página extraída:
def generate_seo_report(page_content_list: List[str]) -> str:
# Inicializar o cliente OpenAI para chamar as APIs OpenAI
from openai import OpenAI
openai_client = OpenAI()
# O prompt para gerar o relatório de SEO desejado
prompt = f"""
# Dado o conteúdo abaixo para algumas páginas da Web,
# produza um relatório estruturado no formato Markdown contendo insights de SEO obtidos pela análise do conteúdo de cada página.
# O relatório deve incluir:
# Tópicos e elementos comuns entre todas as páginas
# As principais diferenças entre as páginas
# Uma tabela de resumo que inclua estatísticas como o número de palavras, o número de parágrafos, a contagem de títulos H2 e H3 etc.
# CONTEÚDO:
# {"nnPAGE:".join(page_content_list)}
# """
# Executar o prompt no modelo de IA selecionado
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_textO resultado dessa tarefa será o relatório SEO Markdown desejado.
Observação: o modelo OpenAI usado acima foi o GPT-5-mini, mas você pode substituí-lo por qualquer outro modelo OpenAI. Da mesma forma, você pode trocar totalmente a integração do OpenAI e usar qualquer outro provedor de LLM.
Fantástico! As tarefas estão prontas, e agora é hora de combiná-las em um fluxo de trabalho de IA do Flyte.
Etapa nº 7: definir o fluxo de trabalho de IA
Crie uma função @workflow que orquestre as tarefas em sequência:
@workflow
def seo_ai_workflow() -> str:
input_kw = "best llms"
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
return reportNeste fluxo de trabalho:
- A tarefa
get_seo_urlsrecupera os 3 principais URLs de SEO para a frase-chave “best llms”. - A tarefa
get_content_pagescoleta e converte o conteúdo desses URLs em Markdown. - A tarefa
generate_seo_reportpega esse conteúdo Markdown e produz um relatório final de insights de SEO no formato Markdown.
Missão concluída!
Etapa nº 8: Juntar tudo
Seu arquivo workflow.py final deve conter:
do flytekit import task, workflow
import os
from typing import List
# Defina os segredos necessários (substitua-os por suas chaves de API)
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHTDATA_API_TOKEN>"
@task()
def get_seo_urls(kw: str, num_links: int = 3) -> List[str]:
import json
# Inicializar o cliente Bright Data SDK
from brightdata import bdclient
bright_data_client = bdclient()
# Obter o SERP do Google para a palavra-chave fornecida como uma cadeia de caracteres JSON analisada
res = bright_data_client.search(kw, response_format="json", parse=True)
# Analisar a cadeia de caracteres JSON para convertê-la em um dicionário
json_response = res["body"]
dados = json.loads(json_response)
# Extraia os principais URLs da página de SEO "num_links" da SERP
seo_urls = [item["link"] for item in data["organic"][:num_links]]
return seo_urls
@task()
def get_content_pages(page_urls: List[str]) -> List[str]:
# Inicializar o cliente Bright Data SDK
from brightdata import bdclient
bright_data_client = bdclient()
# Obter o conteúdo Markdown de cada página
page_content_list = bright_data_client.scrape(page_urls, data_format="markdown")
return page_content_list
@task
def generate_seo_report(page_content_list: List[str]) -> str:
# Inicializar o cliente OpenAI para chamar as APIs OpenAI
from openai import OpenAI
openai_client = OpenAI()
# O prompt para gerar o relatório de SEO desejado
prompt = f"""
# Dado o conteúdo abaixo para algumas páginas da Web,
# produza um relatório estruturado no formato Markdown contendo insights de SEO obtidos pela análise do conteúdo de cada página.
# O relatório deve incluir:
# Tópicos e elementos comuns entre todas as páginas
# As principais diferenças entre as páginas
# Uma tabela de resumo que inclua estatísticas como o número de palavras, o número de parágrafos, a contagem de títulos H2 e H3 etc.
# CONTEÚDO:
# {"nnPAGE:".join(page_content_list)}
# """
# Executar o prompt no modelo de IA selecionado
response = openai_client.responses.create(
model="gpt-5-mini",
input=prompt,
)
return response.output_text
@workflow
def seo_ai_workflow() -> str:
input_kw = "best llms" # Altere-o para corresponder às suas metas de análise de SEO
seo_urls = get_seo_urls(input_kw)
page_content_list = get_content_pages(seo_urls)
report = generate_seo_report(page_content_list)
return report
se __name__ == "__main__":
seo_ai_workflow()Uau! Em menos de 80 linhas de código Python, você acabou de criar um fluxo de trabalho completo de IA de SEO. Isso não teria sido possível sem o Flyte e o Bright Data SDK.
Você pode executar seu fluxo de trabalho a partir da CLI com:
pyflyte run workflow.py seo_ai_workflowEsse comando iniciará a função seo_ai_workflow @workflow do arquivo workflow.py.
Observação: os resultados podem demorar um pouco para aparecer, pois a pesquisa na Web, a raspagem e o processamento de IA levam algum tempo.
Quando o fluxo de trabalho for concluído, você deverá obter uma saída Markdown semelhante a esta:
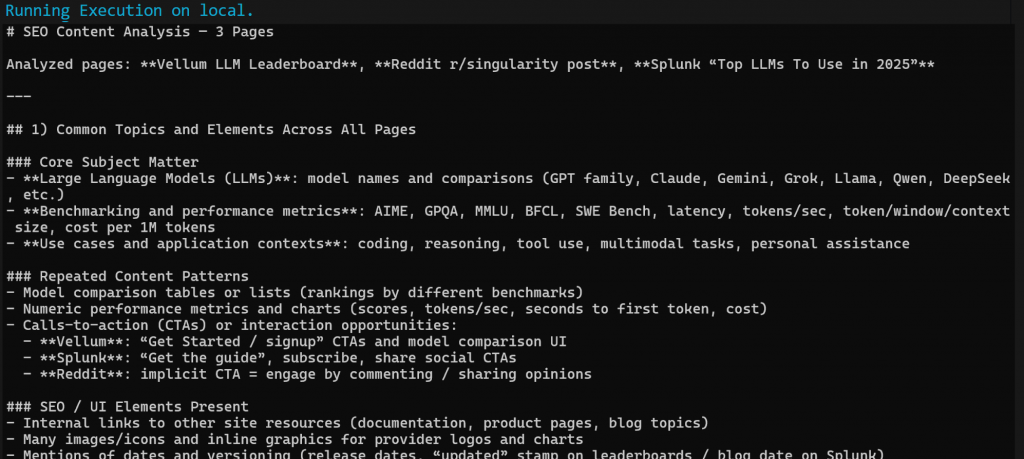
Cole a saída Markdown em qualquer visualizador Markdown para percorrê-la e explorá-la. Ele deve se parecer com o seguinte:
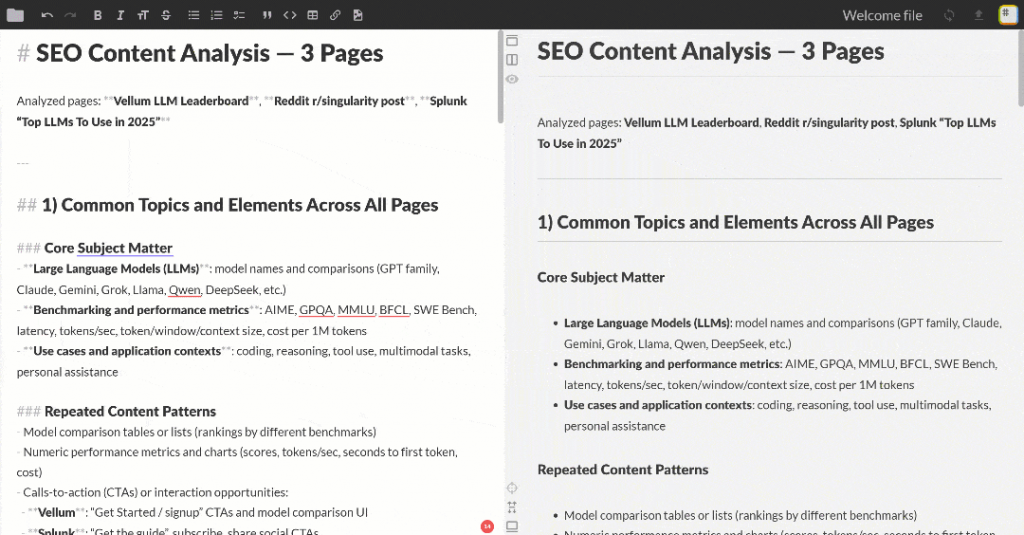
O resultado contém vários insights de SEO e uma tabela de resumo, exatamente como solicitado pela OpenAI. Esse foi apenas um exemplo simples do poder da integração Flyte + Bright Data!
E pronto! Sinta-se à vontade para definir outras tarefas e experimentar LLMs diferentes para implementar outros casos de uso úteis de fluxo de trabalho agêntico e de IA.
Próximas etapas
A implementação do fluxo de trabalho de IA da Flyte fornecida aqui é apenas um exemplo. Para torná-la pronta para produção ou para prosseguir com uma implementação adequada, as próximas etapas são:
- Integrar um sistema de gerenciamento de segredos suportado pelo Flyte: Evite codificar chaves de API no código. Use os segredos da tarefa Flyte ou outros sistemas compatíveis para lidar com as credenciais de forma segura e elegante.
- Tratamento de prompts: A geração de prompts dentro de uma tarefa é aceitável, mas, para fins de reprodutibilidade, considere a possibilidade de versionar seus prompts ou armazená-los externamente.
- Implemente o fluxo de trabalho: Siga as instruções oficiais para dockerizar seu fluxo de trabalho e prepará-lo para implantação usando os recursos do Flyte.
Conclusão
Nesta postagem do blog, você aprendeu a usar os recursos de pesquisa e raspagem da Web da Bright Data no Flyte para criar um fluxo de trabalho de análise de SEO alimentado por IA. O processo de implementação ficou mais simples graças ao SDK da Bright Data, que fornece acesso fácil aos produtos da Bright Data por meio de chamadas de método simples.
Para criar fluxos de trabalho mais sofisticados, explore o conjunto completo de soluções na infraestrutura de IA da Bright Data para buscar, validar e transformar dados da Web ao vivo.
Inscreva-se gratuitamente em uma conta da Bright Data e comece a experimentar nossas soluções de dados da Web prontas para IA!




