

Neste tutorial, você aprenderá:
- Em primeiro lugar, por que você precisa de uma solução de monitoramento de marca personalizada.
- Como criar uma solução usando o Bright Data SDK, OpenAI e SendGrid.
- Como implementar um fluxo de trabalho de IA de monitoramento da reputação da marca em Python.
Você pode visualizar o repositório do GitHub para todos os arquivos do projeto. Agora, vamos nos aprofundar!
Por que criar uma solução personalizada de monitoramento de marca?
O monitoramento da marca é uma das tarefas mais importantes do marketing, e há vários serviços on-line disponíveis para ajudar com isso. O problema com essas soluções é que elas tendem a ser caras e podem não ser adaptadas às suas necessidades específicas.
É por isso que faz sentido criar uma solução personalizada de monitoramento da reputação da marca. A princípio, isso pode parecer intimidador, pois pode parecer uma meta complexa. No entanto, com as ferramentas certas (como você verá a seguir), isso é totalmente possível.
Fluxo de trabalho de IA de reputação da marca Fluxo de trabalho explicado
Em primeiro lugar, não é possível criar uma ferramenta eficaz de monitoramento de marca sem informações externas confiáveis sobre sua marca. Uma ótima fonte para isso é o Google News. Ao entender o que está sendo dito sobre sua marca em artigos de notícias diárias e o sentimento por trás deles, você pode tomar decisões informadas. O objetivo final é responder, proteger ou promover sua marca.
O problema é que a extração de artigos de notícias é um desafio. O Google News, em particular, é protegido por várias medidas anti-bot. Além disso, cada fonte de notícias tem seu próprio site com proteções exclusivas, o que dificulta a coleta programática e consistente de dados de notícias.
É aí que entra a Bright Data. Graças aos seus recursos de pesquisa e raspagem na Web, ela o equipa com muitos produtos e integrações para acessar programaticamente dados públicos da Web prontos para IA de qualquer site.
Especificamente, com o novo SDK da Bright Data, você pode aproveitar as soluções mais úteis da Bright Data de forma simplificada com apenas algumas linhas de código Python!
Depois de obter os dados de notícias, você pode contar com a IA para selecionar os artigos mais relevantes e analisá-los para obter insights sobre sentimentos e marcas. Em seguida, você pode utilizar um serviço como o Twilio SendGrid para enviar o relatório resultante para toda a sua equipe de marketing. Em um nível mais alto, isso é exatamente o que um fluxo de trabalho personalizado de IA de reputação de marca faz.
Agora, vamos dar uma olhada mais de perto em como implementá-lo de uma perspectiva técnica!
Etapas técnicas
As etapas para implementar o fluxo de trabalho de IA de monitoramento da reputação da marca são as seguintes
- Carregar variáveis de ambiente: Carregar as chaves de API da Bright Data, OpenAI e SendGrid das variáveis de ambiente. Essas chaves são necessárias para se conectar aos serviços de terceiros que alimentam esse fluxo de trabalho.
- Carregar o arquivo de configuração: Leia um arquivo de configuração JSON (por exemplo,
config.json) contendo as consultas de pesquisa iniciais, o número de artigos de notícias a serem incluídos no relatório, juntamente com o endereço de e-mail do remetente e os endereços de e-mail dos destinatários. - Recuperar URLs de páginas do Google News: Use o Bright Data SDK para extrair páginas de resultados de mecanismos de pesquisa (SERPs) para o termo de pesquisa configurado. Em cada uma delas, acesse os URLs das páginas do Google News.
- Extrair as páginas do Google News: Use o Bright Data SDK para coletar as páginas completas do Google News no formato Markdown. Cada uma dessas páginas contém vários URLs de artigos de notícias.
- Deixe a IA identificar as principais notícias: Envie as páginas raspadas do Google News para um modelo OpenAI e faça com que ele selecione os artigos de notícias mais relevantes para o monitoramento da marca.
- Extraia artigos de notícias individuais: Use o Bright Data SDK para recuperar o conteúdo de cada artigo de notícias retornado pela IA.
- Analisar artigos de notícias para verificar a reputação da marca: Envie cada artigo de notícias para a IA e peça que ela forneça um resumo, uma indicação de análise de sentimento e os principais insights sobre a reputação da marca.
- Gerar um relatório HTML final: Passe os resultados da análise de notícias para a IA e peça que ela produza um relatório HTML bem estruturado.
- Envie o relatório por e-mail: Utilize o SendGrid SDK para enviar o relatório HTML gerado pela IA para os destinatários especificados, fornecendo uma visão geral abrangente da reputação da marca.

Veja como implementar esse fluxo de trabalho de IA em Python!
Como criar um fluxo de trabalho de reputação de marca com IA com o SDK da Bright Data
Nesta seção do tutorial, você aprenderá a criar um fluxo de trabalho de IA para monitorar a reputação da sua marca. Os dados necessários sobre as notícias da marca serão obtidos da Bright Data, por meio do Bright Data Python SDK. Os recursos de IA serão fornecidos pela OpenAI, e a entrega de e-mails será feita pela SendGrid.
Ao final deste tutorial, você terá um fluxo de trabalho completo de IA em Python que fornecerá resultados diretamente na sua caixa de entrada. O relatório de saída identificará as principais notícias sobre as quais sua marca deve estar ciente, fornecendo tudo o que você precisa para responder rapidamente e manter uma presença forte da marca.
Vamos criar um fluxo de trabalho de IA de reputação de marca!
Pré-requisitos
Para seguir este tutorial, verifique se você tem o seguinte:
- Python 3.8+ instalado localmente.
- Uma chave de API da Bright Data.
- Uma chave de API da OpenAI.
- Uma chave de API do Twilio SendGrid.
Se você ainda não tiver um token de API da Bright Data, inscreva-se na Bright Data e siga o guia de configuração. Da mesma forma, siga as instruções oficiais da OpenAI para obter sua chave de API da OpenAI.
Quanto ao SendGrid, crie uma conta, verifique-a, conecte um endereço de e-mail e verifique seu domínio. Crie uma chave de API e verifique se você pode enviar e-mails de forma programática por meio dela.
Etapa 1: criar seu projeto Python
Abra um terminal e crie um novo diretório para seu fluxo de trabalho de IA de monitoramento da reputação da marca:
mkdir brand-reputation-monitoring-workflowA pasta brand-reputation-monitoring-workflow/ conterá o código Python para seu fluxo de trabalho de IA.
Em seguida, navegue até o diretório do projeto e configure um ambiente virtual:
cd brand-reputation-monitoring-workflow
python -m venv .venvAgora, carregue o projeto em seu IDE Python favorito. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Dentro da pasta do projeto, adicione um novo arquivo chamado workflow.py. Seu projeto agora deve conter:
brand-reputation-monitoring-workflow/
├── .venv/
workflow.pyworkflow.py será seu arquivo Python principal.
Ative o ambiente virtual. No Linux ou macOS, execute:
source .venv/bin/activateDe forma equivalente, no Windows, execute:
.venv/Scripts/activateCom o ambiente ativado, instale as dependências necessárias com:
pip install python-dotenv brightdata-sdk openai sendgrid pydanticAs bibliotecas que você acabou de instalar são:
python-dotenv: para carregar variáveis de ambiente de um arquivo.env, facilitando o gerenciamento seguro de chaves de API.brightdata-sdk: Para ajudá-lo a acessar as ferramentas e soluções de raspagem da Bright Data em Python.openai: Para interagir com os modelos de linguagem da OpenAI.sendgrid: Para enviar e-mails rapidamente usando a API Web v3 do Twilio SendGrid.pydantic: Para definir modelos para saídas de IA e sua configuração.
Pronto! Seu ambiente de desenvolvimento Python está pronto para criar um fluxo de trabalho de IA de monitoramento da reputação da marca com OpenAI, Bright Data SDK e SendGrid.
Etapa 2: configurar a leitura da variável de ambiente
Configure seu script para ler segredos das variáveis de ambiente. Em seu arquivo workflow.py, importe python-dotenv e chame load_dotenv() para carregar automaticamente as variáveis de ambiente:
from dotenv import load_dotenv
load_dotenv()Seu script agora pode ler variáveis de um arquivo .env local. Portanto, crie um arquivo .env na raiz do diretório do seu projeto:
brand-reputation-monitoring-workflow/
├── .venv/
├── .env # <-----------
workflow.pyAbra o arquivo .env e adicione os envs OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN e SENDGRID_API_KEY:
OPENAI_API_KEY="<SUA_OPENAI_API_KEY>"
BRIGHT_DATA_API_TOKEN="<SEU_DATA_BRIGHT_API_TOKEN>"
SENDGRID_API_KEY="<SEU_SENDGRID_API_TOKEN>"Substitua os espaços reservados por suas credenciais reais:
<YOUR_OPENAI_API_KEY>→ Sua chave da API OpenAI.<YOUR_BRIGHT_DATA_API_TOKEN>→ Seu token da API da Bright Data.<YOUR_SENDGRID_API_KEY>→ Sua chave de API SendGrid.
Ótimo! Agora você configurou com segurança os segredos de terceiros usando variáveis de ambiente.
Etapa #3: inicializar os SDKs
Comece adicionando as importações necessárias:
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClientEm seguida, inicialize os clientes SDK:
brightdata_client = bdclient()
openai_client = OpenAI()
sendgrid_client = SendGridAPIClient()As três linhas acima inicializam o seguinte:
- SDK Python da Bright Data
- OpenAI Python SDK
- SendGrid Python SDK
Observe que não é necessário carregar manualmente as variáveis de ambiente da chave de API em seu código e passá-las para os construtores. Isso ocorre porque o OpenAI SDK, o Bright Data SDK e o SendGrid SDK procuram automaticamente por OPENAI_API_KEY, BRIGHT_DATA_API_TOKEN e SENDGRID_API_KEY em seu ambiente, respectivamente. Em outras palavras, quando esses ambientes são definidos em .env, os SDKs cuidam do carregamento para você.
Em particular, os SDKs usarão as chaves de API configuradas para autenticar as chamadas de API subjacentes aos servidores deles usando sua conta.
Importante: Para obter mais detalhes sobre como o SDK da Bright Data funciona e como conectá-lo às zonas necessárias em sua conta da Bright Data, consulte a página oficial do GitHub ou a documentação.
Perfeito! Os blocos de construção para a criação do fluxo de trabalho de IA de monitoramento da reputação da sua marca estão prontos.
Etapa nº 4: recuperar os URLs do Google News
A primeira etapa da lógica do fluxo de trabalho é extrair as SERPs das consultas de pesquisa relacionadas à marca que você deseja monitorar. Faça isso por meio do método search() do Bright Data SDK, que chama a API SERP nos bastidores.
Em seguida, analise a resposta de texto JSON que você obtém de search() para acessar os URLs da página do Google News, que terão a seguinte aparência:
https://www.google.com/search?sca_esv=7fb9df9863b39f3b&hl=en&q=nike&tbm=nws&source=lnms&fbs=AIIjpHxU7SXXniUZfeShr2fp4giZjSkgYzz5-5RrRWAIniWd7tzPwkE1KJWcRvaH01D-XIVr2cowAnfeRRP_dme4bG4a8V_AkFVl-SqROia4syDA2-hwysjgAT-v0BCNgzLBnrhEWcFR7F5dffabwXi9c9pDyztBxQc1yfKVagSlUz7tFb_e8cyIqHDK7O6ZomxoJkHRwfaIn-HHOcZcyM2n-MrnKKBHZg&sa=X&ved=2ahUKEwiX1vu4_KePAxVWm2oFHT6tKsAQ0pQJegQIPhABConsiga tudo isso com esta função:
def get_google_news_page_urls(search_queries):
# Recupera SERPs para as consultas de pesquisa fornecidas
serp_results = brightdata_client.search(
search_queries,
search_engine="google",
parse=True # Para obter o resultado da SERP como uma string JSON analisada
)
news_page_urls = []
for serp_result in serp_results:
# Carregando a string JSON em um dicionário
serp_data = json.loads(serp_result)
# Extrair o URL do Google News de cada SERP analisado
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "News":
news_url = item["href"]
news_page_urls.append(news_url)
return news_page_urlsQuando você passa uma matriz de consultas para search() (como neste caso), o método retorna uma matriz de SERPs, uma para cada consulta, respectivamente. Como parse está definido como True, cada resultado retorna como uma string JSON, que você precisa analisar com o módulo json integrado do Python.
Lembre-se de importar json da biblioteca padrão do Python:
import jsonFantástico! Agora você pode recuperar de forma programática uma lista de URLs de páginas do Google News relacionadas à sua marca.
Etapa 5: Extraia as páginas do Google News e obtenha os melhores URLs de notícias
Lembre-se de que uma única página do Google News contém vários artigos de notícias:
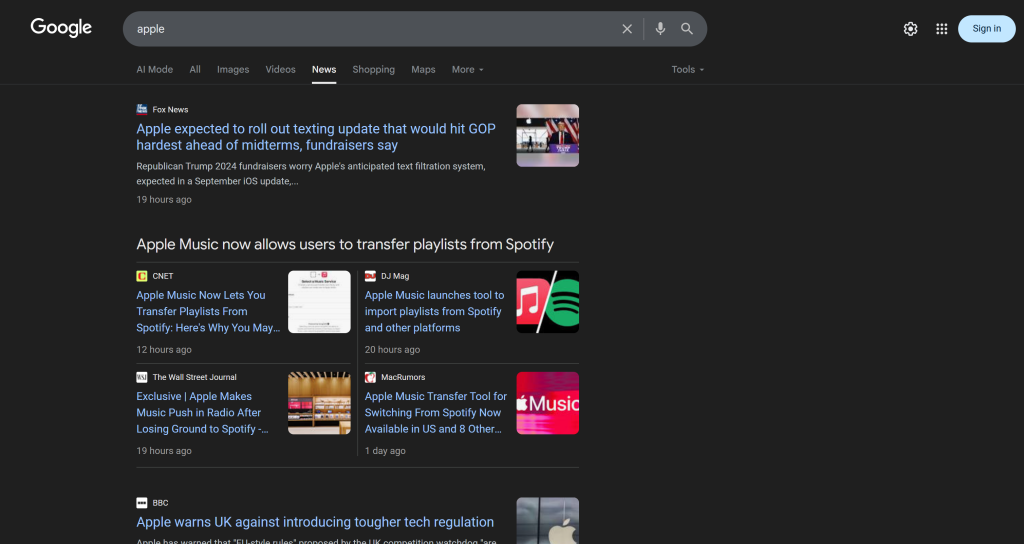
Portanto, a ideia é:
- Extrair o conteúdo das páginas do Google News e obter os resultados no formato Markdown.
- Alimentar o conteúdo Markdown para uma IA (um modelo OpenAI, neste caso), solicitando que ela selecione os 5 principais artigos de notícias para o monitoramento da reputação da marca.
Realize a primeira microetapa com esta função:
def scrape_news_pages(news_page_urls):
# Extrair cada página de notícias em paralelo e retornar seu conteúdo em Markdown
return brightdata_client.scrape(
url=news_page_urls,
data_format="markdown"
) Por trás disso, o método scrape() do Bright Data SDK chama a API do Web Unlocker. Quando você passa uma matriz de URLs, scrape() executa a tarefa de raspagem em paralelo, buscando todas as páginas ao mesmo tempo. Nesse caso, a API é configurada para retornar dados em Markdown, o que é ideal para a ingestão de LLM (conforme comprovado em nosso benchmark de formato de dados no Kaggle).
Em seguida, conclua a segunda microetapa com:
def get_best_news_urls(news_pages, num_news):
# Use o GPT para extrair os URLs de notícias mais relevantes
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system" (sistema),
"content": f "Extraia do texto as {num_news} notícias mais relevantes para o monitoramento da reputação da marca e retorne-as como uma lista de strings de URL."
},
{
"role": "user" (usuário),
"content" (conteúdo): "nn---------------nn".join(news_pages)
},
],
text_format=URLList,
)
return response.output_parsed.urlsIsso simplesmente concatena as saídas de texto Markdown da função anterior e as passa para o modelo GPT-5-mini OpenAI, solicitando que ele extraia os URLs mais relevantes.
Espera-se que a saída siga o modelo URLList, que é um modelo Pydantic definido como:
class URLList(BaseModel):
urls: List[str]Graças à opçãotext_format no método parse(), você está instruindo a API OpenAI a retornar o resultado como uma instância de URLList. Basicamente, você está obtendo uma lista de strings, em que cada string representa um URL.
Importe as classes necessárias da pydantic:
da pydantic import BaseModel
from typing import ListFantástico! Agora você tem uma lista estruturada de URLs de notícias, pronta para ser extraída e analisada quanto à reputação da marca.
Etapa 6: Extraia as páginas de notícias e analise-as para monitorar a reputação da marca
Agora que você tem uma lista dos melhores URLs de notícias, use scrape() novamente para obter seu conteúdo em Markdown:
def scrape_news_articles(news_urls):
# Extrai cada URL de notícia e retorna uma lista de ditados com URL e conteúdo
news_content_list = brightdata_client.scrape(
url=news_urls,
data_format="markdown"
)
lista_de_notícias = []
para url, conteúdo em zip(news_urls, news_content_list):
news_list.append({
"url": url,
"content": content
})
return news_listIndependentemente do domínio em que esses artigos de notícias estejam hospedados ou de quais medidas antirrastreamento estejam em vigor, a API do Web Unlocker cuidará disso e retornará o conteúdo de cada artigo em Markdown. Em detalhes, os artigos de notícias serão extraídos em paralelo. Para manter o controle de qual URL de notícia corresponde a qual saída Markdown, use zip().
Em seguida, alimente cada conteúdo de notícias Markdown com o OpenAI para analisá-lo quanto à reputação da marca. Para cada artigo, extraia:
- O título
- O URL
- Um breve resumo
- Um rótulo de sentimento rápido (por exemplo, “positivo”, “negativo” ou “neutro”)
- 3 a 5 insights práticos, curtos e fáceis de entender
Faça isso com a função a seguir:
def process_news_list(news_list):
# Onde armazenar os artigos de notícias analisados
lista_de_análise_de_notícias = []
# Analisar cada artigo de notícias com GPT para obter insights de monitoramento da reputação da marca
for news in news_list:
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system" (sistema),
"content": f"""
Dado o conteúdo da notícia:
1. Extraia o título.
2. Extraia o URL.
3. Escreva um resumo com no máximo 30 palavras.
4. Extraia o sentimento da notícia como uma das seguintes opções: "positivo", "negativo" ou "neutro".
5. Extraia da notícia os 3 a 5 principais insights práticos e curtos (não mais que 10/12 palavras) sobre a reputação da marca, apresentando-os em uma linguagem clara, concisa e direta.
"""
},
{
"role": "usuário",
"content": f "URL das NOTÍCIAS: {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NewsAnalysis,
)
# Obter o objeto de notícias analisadas de saída e anexá-lo à lista
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_listDesta vez, o modelo Pydantic definido em text_format é:
class NewsAnalysis(BaseModel):
title: str
url: str
resumo: str
sentiment_analysis: str
insights: List[str]Portanto, o resultado da função process_news_list() será uma lista de objetos NewsAnalysis.
Legal! O processamento de notícias com IA para monitoramento da reputação da marca está concluído.
Etapa nº 7: Gerar o relatório de e-mail e enviá-lo
Você já se perguntou como os e-mails são estruturados e aparecem bem na caixa de entrada do seu cliente? Isso ocorre porque a maioria dos corpos de e-mail são, na verdade, apenas páginas HTML estruturadas. Afinal de contas, o protocolo de e-mail suporta o envio de documentos HTML.
Com base na lista de objetos de análise de notícias gerada anteriormente, converta-a em JSON, passe-a para a IA e peça a ela que produza um documento HTML pronto para ser enviado por e-mail:
def create_html_email_body(news_analysis_list):
# Gera um corpo de e-mail HTML estruturado a partir das notícias analisadas
response = openai_client.responses.create(
model="gpt-5-mini",
input=f"""
Com base no conteúdo abaixo, gere um corpo de e-mail em HTML estruturado que esteja bem formatado, responsivo e pronto para ser enviado.
Garanta o uso adequado de cabeçalhos, parágrafos, rótulos coloridos e links, quando apropriado.
Não inclua uma seção de cabeçalho ou rodapé e inclua apenas essas informações, nada mais.
CONTEÚDO:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]}
"""
)
return response.output_textPor fim, use o SDK do Twilio SendGrid para enviar o e-mail de forma programática:
def send_email(sender, recipients, html_body):
# Enviar o e-mail em HTML usando o SendGrid
message = Mail(
from_email=sender,
to_emails=recipients,
subject="Relatório semanal de monitoramento de marca",
html_content=html_body
)
sendgrid_client.send(message)Isso requer a seguinte importação:
from sendgrid.helpers.mail import MailAqui vamos nós! Todas as funções para implementar esse fluxo de trabalho de IA de monitoramento da reputação da marca já foram implementadas.
Etapa 8: carregar suas preferências e configurações
Algumas das funções definidas nas etapas anteriores aceitam argumentos específicos (por exemplo, search_queries, num_news, sender, recipients). Esses valores podem mudar de uma execução para outra, portanto, você não deve codificá-los em seu script Python.
Em vez disso, leia-os em um arquivo config.json que contenha os seguintes campos:
search_queries: A lista de consultas de reputação de marca para recuperar notícias.num_news: O número de artigos de notícias a serem apresentados no relatório final.sender (remetente): Um endereço de e-mail aprovado pela SendGrid a partir do qual o relatório será enviado.recipients (destinatários): A lista de endereços de e-mail para os quais enviar o relatório HTML.
Modele o objeto de configuração usando a seguinte classe Pydantic:
class Config(BaseModel):
search_queries: List[str] = Field(..., min_items=1)
num_news: int = Field(..., gt=0)
remetente: str = Field(..., min_length=1)
destinatários: List[str] = Field(..., min_items=1)As definições de Field especificam regras de validação para garantir que as configurações estejam em conformidade com o formato esperado. Importe-as com:
from pydantic import FieldEm seguida, leia as configurações do fluxo de trabalho de um arquivo config.json local e analise-o em um objeto Config:
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config) Adicione um arquivo config.json ao diretório do seu projeto:
brand-reputation-monitoring-workflow/
├── .venv/
├─── .env
├── config.json # <-----------
└── workflow.pyE preencha-o com algo como isto:
{
"search_queries": ["apple", "iphone", "ipad"],
"sender" (remetente): "[email protected]",
"recipients": ["[email protected]", "[email protected]", "[email protected]"],
"num_news": 5
}Adapte os valores às suas metas específicas. Além disso, lembre-se de que o campo do remetente deve ser um endereço de e-mail verificado em sua conta SendGrid. Caso contrário, a função send_email() falhará com um erro 403 Forbidden.
Muito bem! Mais uma etapa e o fluxo de trabalho está concluído.
Etapa 9: definir a função principal
É hora de compor tudo. Chame cada função predefinida na ordem correta, fornecendo as entradas corretas da configuração:
search_queries = config.search_queries
print(f "Retrieving Google News page URLs for the following search queries: {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} URL(s) de páginas do Google News recuperados!n")
print("Extração de conteúdo de cada página do Google News...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Páginas de notícias do Google raspadas!n")
print("Extraindo os URLs de notícias mais relevantes...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)} artigos de notícias encontrados:n" + "n".join(f"- {news}" for news in news_urls) + "n")
print("Raspando os artigos de notícias selecionados...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} artigos de notícias extraídos!")
print("Analisando cada notícia para monitoramento da reputação da marca...")
lista_de_análise_de_notícias = process_news_list(lista_de_notícias)
print("Análise de notícias concluída!n")
print("Gerando o corpo do e-mail em HTML...")
html = create_html_email_body(news_analysis_list)
print("Corpo do e-mail em HTML gerado!n")
print("Enviando o e-mail com o relatório HTML de monitoramento da reputação da marca...")
send_email(config.sender, config.recipients, html)
print("E-mail enviado!")Observação: o fluxo de trabalho pode demorar um pouco para ser concluído, portanto, é útil adicionar registros para acompanhar o progresso no terminal. Missão concluída!
Etapa 10: juntar tudo
O código final do arquivo workflow.py é:
from dotenv import load_dotenv
from brightdata import bdclient
from openai import OpenAI
from sendgrid import SendGridAPIClient
from pydantic import BaseModel, Field
from typing import List
import json
from sendgrid.helpers.mail import Mail
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Inicializar o cliente Bright Data SDK
brightdata_client = bdclient()
# Inicializar o cliente OpenAI SDK
openai_client = OpenAI()
# Inicializar o cliente SendGrid SDK
sendgrid_client = SendGridAPIClient()
# Modelos Pydantic
class Config(BaseModel):
search_queries: List[str] = Field(..., min_items=1)
num_news: int = Field(..., gt=0)
remetente: str = Field(..., min_length=1)
destinatários: List[str] = Field(..., min_items=1)
class URLList(BaseModel):
urls: List[str]
class NewsAnalysis(BaseModel):
title: str
url: str
resumo: str
sentiment_analysis: str
insights: List[str]
def get_google_news_page_urls(search_queries):
# Recupera SERPs para as consultas de pesquisa fornecidas
serp_results = brightdata_client.search(
search_queries,
search_engine="google",
parse=True # Para obter o resultado da SERP como uma string JSON analisada
)
news_page_urls = []
for serp_result in serp_results:
# Carregando a string JSON em um dicionário
serp_data = json.loads(serp_result)
# Extrair o URL do Google News de cada SERP analisado
if serp_data.get("navigation"):
for item in serp_data["navigation"]:
if item["title"] == "News":
news_url = item["href"]
news_page_urls.append(news_url)
return news_page_urls
def scrape_news_pages(news_page_urls):
# Extrai cada página de notícias em paralelo e retorna seu conteúdo em Markdown
return brightdata_client.scrape(
url=news_page_urls,
data_format="markdown"
)
def get_best_news_urls(news_pages, num_news):
# Use o GPT para extrair os URLs de notícias mais relevantes
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system" (sistema),
"content": f "Extraia do texto as {num_news} notícias mais relevantes para o monitoramento da reputação da marca e retorne-as como uma lista de strings de URL."
},
{
"role": "user" (usuário),
"content" (conteúdo): "nn---------------nn".join(news_pages)
},
],
text_format=URLList,
)
return response.output_parsed.urls
def scrape_news_articles(news_urls):
# Extrai cada URL de notícia e retorna uma lista de ditados com URL e conteúdo
news_content_list = brightdata_client.scrape(
url=news_urls,
data_format="markdown"
)
lista_de_notícias = []
para url, conteúdo em zip(news_urls, news_content_list):
news_list.append({
"url": url,
"content": content
})
return news_list
def process_news_list(news_list):
# Onde armazenar os artigos de notícias analisados
lista_de_análise_de_notícias = []
# Analisar cada artigo de notícias com GPT para obter insights de monitoramento da reputação da marca
for news in news_list:
response = openai_client.responses.parse(
model="gpt-5-mini",
input=[
{
"role": "system" (sistema),
"content": f"""
Dado o conteúdo da notícia:
1. Extraia o título.
2. Extraia o URL.
3. Escreva um resumo com no máximo 30 palavras.
4. Extraia o sentimento da notícia como uma das seguintes opções: "positivo", "negativo" ou "neutro".
5. Extraia da notícia os 3 a 5 principais insights práticos e curtos (não mais que 10/12 palavras) sobre a reputação da marca, apresentando-os em uma linguagem clara, concisa e direta.
"""
},
{
"role": "usuário",
"content": f "URL das NOTÍCIAS: {news["url"]}nnNEWS CONTENT:{news["content"]}"
},
],
text_format=NewsAnalysis,
)
# Obter o objeto de notícias analisadas de saída e anexá-lo à lista
news_analysis = response.output_parsed
news_analysis_list.append(news_analysis)
return news_analysis_list
def create_html_email_body(news_analysis_list):
# Gera um corpo de e-mail HTML estruturado a partir das notícias analisadas
response = openai_client.responses.create(
model="gpt-5-mini",
input=f"""
Com base no conteúdo abaixo, gere um corpo de e-mail em HTML estruturado que esteja bem formatado, responsivo e pronto para ser enviado.
Garanta o uso adequado de cabeçalhos, parágrafos, rótulos coloridos e links, quando apropriado.
Não inclua uma seção de cabeçalho ou rodapé e inclua apenas essas informações, nada mais.
CONTEÚDO:
{[json.dumps([item.model_dump() for item in news_analysis_list], indent=2)]}
"""
)
return response.output_text
def send_email(sender, recipients, html_body):
# Enviar o e-mail em HTML usando o SendGrid
message = Mail(
from_email=sender,
to_emails=recipients,
subject="Relatório semanal de monitoramento de marca",
html_content=html_body
)
sendgrid_client.send(message)
def main():
# Ler o arquivo de configuração e validá-lo
with open("config.json", "r", encoding="utf-8") as f:
raw_config = json.load(f)
config = Config.model_validate(raw_config)
search_queries = config.search_queries
print(f "Recuperando URLs de páginas do Google News para as seguintes consultas de pesquisa: {", ".join(search_queries)}")
google_news_page_urls = get_google_news_page_urls(search_queries)
print(f"{len(google_news_page_urls)} URL(s) de páginas do Google News recuperados!n")
print("Extração de conteúdo de cada página do Google News...")
scraped_news_pages = scrape_news_pages(google_news_page_urls)
print("Páginas de notícias do Google raspadas!n")
print("Extraindo os URLs de notícias mais relevantes...")
news_urls = get_best_news_urls(scraped_news_pages, config.num_news)
print(f"{len(news_urls)} artigos de notícias encontrados:n" + "n".join(f"- {news}" for news in news_urls) + "n")
print("Raspando os artigos de notícias selecionados...")
news_list = scrape_news_articles(news_urls)
print(f"{len(news_urls)} artigos de notícias extraídos!")
print("Analisando cada notícia para monitoramento da reputação da marca...")
lista_de_análise_de_notícias = process_news_list(lista_de_notícias)
print("Análise de notícias concluída!n")
print("Gerando o corpo do e-mail em HTML...")
html = create_html_email_body(news_analysis_list)
print("Corpo do e-mail em HTML gerado!n")
print("Enviando o e-mail com o relatório HTML de monitoramento da reputação da marca...")
send_email(config.sender, config.recipients, html)
print("E-mail enviado!")
# Executar a função principal
if __name__ == "__main__":
main()E pronto! Graças ao SDK da Bright Data, à API da OpenAI e ao SDK do Twilio SendGrid, você conseguiu criar um fluxo de trabalho de monitoramento da reputação da marca com tecnologia de IA em menos de 200 linhas de código.
Etapa 11: testar o fluxo de trabalho
Suponha que suas search_queries sejam "nike" e "nike shoes". num_news está definido como 5 e o relatório está configurado para ser enviado para seu e-mail pessoal (observe que você pode usar o mesmo endereço de e-mail tanto para o remetente quanto para o primeiro item nos destinatários).
Em seu ambiente virtual ativado, inicie seu fluxo de trabalho com:
python workflow.pyO resultado no terminal será algo parecido com:
Recuperação de URLs de páginas do Google News para as seguintes consultas de pesquisa: nike, nike shoes
2 URL(s) de página(s) do Google News recuperados!
Extração de conteúdo de cada página do Google News...
Páginas do Google News extraídas!
Extração dos URLs de notícias mais relevantes...
5 artigos de notícias encontrados:
- https://www.espn.com/wnba/story/_/id/46075454/caitlin-clark-becomes-nike-newest-signature-athlete
- https://wwd.com/footwear-news/sneaker-news/nike-acg-radical-airflow-ultrafly-release-dates-1238068936/
- https://www.runnersworld.com/news/a65881486/cooper-lutkenhaus-professional-contract-nike/
- https://hypebeast.com/2025/8/nike-kobe-3-protro-low-reveal-info
- https://wwd.com/footwear-news/sneaker-news/nike-air-diamond-turf-must-be-the-money-release-date-1238075256/
Extração dos artigos de notícias selecionados...
5 artigos de notícias extraídos!
Análise de cada artigo de notícias para monitoramento da reputação da marca...
Análise de notícias concluída!
Geração do corpo do e-mail em HTML...
Corpo do e-mail em HTML gerado!
Envio do e-mail com o relatório HTML de monitoramento da reputação da marca...
E-mail enviado!Observação: Os resultados mudarão de acordo com as notícias disponíveis. Portanto, eles nunca serão iguais aos anteriores no momento em que você ler este tutorial.
Após a mensagem “E-mail enviado!”, você verá um e-mail “Relatório semanal de monitoramento de marca” na sua caixa de entrada:

Abra-o e ele conterá algo como:
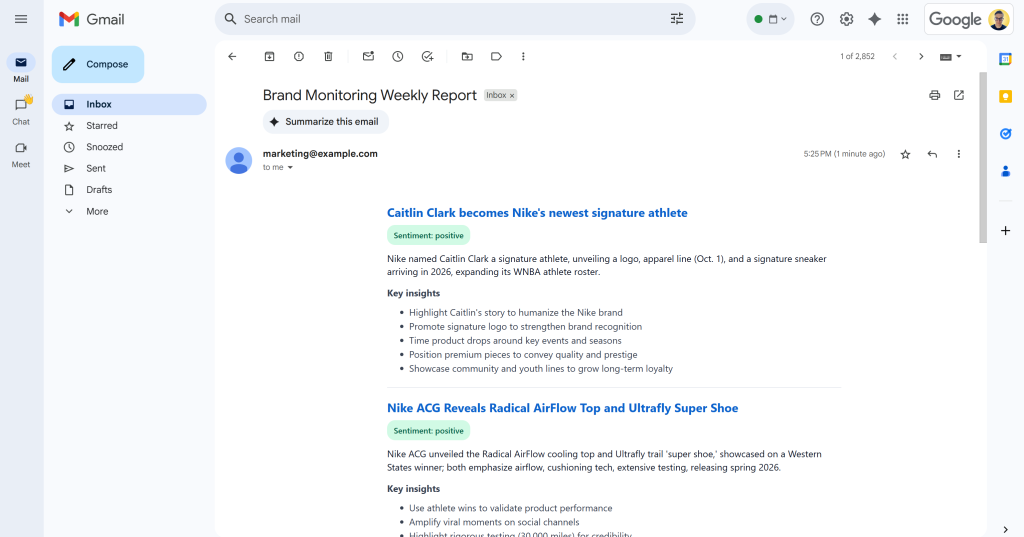
Como você pode ver, a IA foi capaz de produzir um relatório de monitoramento de marca visualmente atraente com todos os dados solicitados.
Percorra o relatório e você verá:
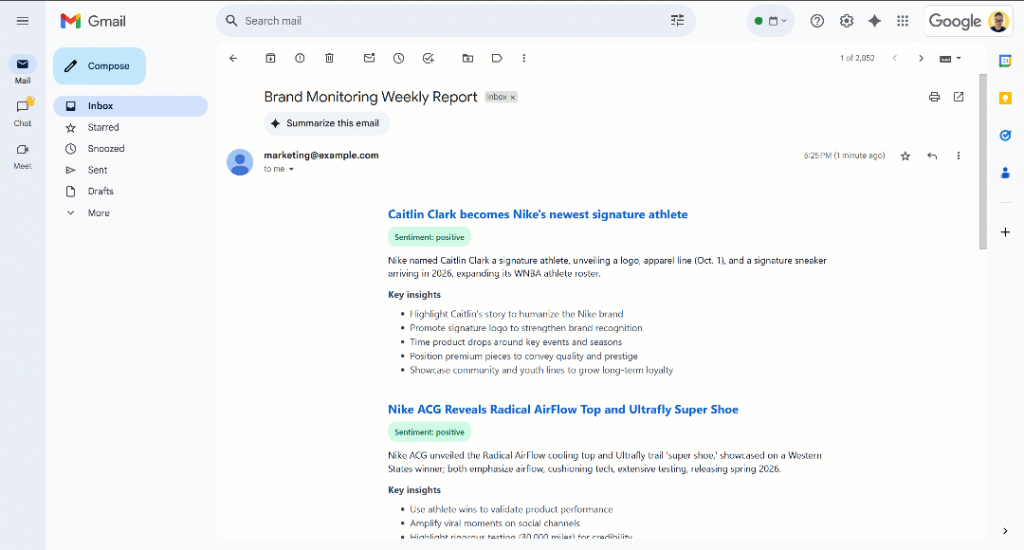
Observe que os rótulos de sentimento são codificados por cores para ajudá-lo a entender rapidamente o sentimento. Além disso, os títulos dos itens de notícias estão em azul, pois são links para os artigos originais.
E pronto! Você começou com algumas consultas de pesquisa e terminou com um e-mail contendo um relatório de monitoramento de marca bem estruturado.
Tudo isso foi possível graças ao poder das soluções de coleta de dados da Web disponíveis no SDK da Bright Data. Lembre-se de que as páginas raspadas são retornadas em formatos Markdown otimizados para LLM, de modo que qualquer modelo de IA possa analisá-las de acordo com suas necessidades. Explore outros casos de uso de fluxo de trabalho agêntico e de IA suportados!
Próximas etapas
O atual fluxo de trabalho de IA para monitoramento da reputação da marca já é bastante sofisticado, mas você pode aprimorá-lo ainda mais com estas ideias:
- Adicionar uma camada de memória para notícias cobertas anteriormente: Para evitar analisar os mesmos artigos várias vezes, aprimorando a precisão do relatório e reduzindo a duplicação.
- Introduzir modelos SendGrid para padronização: A IA pode produzir relatórios HTML ligeiramente diferentes com estruturas variadas em cada execução. Para tornar o layout consistente, defina um modelo SendGrid, preencha-o com os dados de análise de notícias gerados e envie-o por meio do SendGrid SDK. Saiba mais na documentação oficial.
- Armazene o relatório HTML gerado na nuvem: Salve o relatório no S3 para garantir que ele seja arquivado e esteja disponível para análise de monitoramento histórico da marca.
Conclusão
Neste artigo, você aprendeu a aproveitar os recursos de pesquisa e raspagem da Web da Bright Data para criar um fluxo de trabalho de reputação de marca alimentado por IA. Esse processo ficou ainda mais fácil graças ao novo SDK da Bright Data, que permite o acesso aos produtos da Bright Data com chamadas de método simples.
O fluxo de trabalho de IA apresentado aqui é ideal para equipes de marketing interessadas em monitorar sua marca e receber insights acionáveis a um baixo custo. Ele ajuda a economizar tempo e esforço, fornecendo instruções contextuais para apoiar a proteção da marca e a tomada de decisões.
Para criar fluxos de trabalho mais avançados, explore toda a gama de soluções na infraestrutura de IA da Bright Data para buscar, validar e transformar dados da Web ao vivo.
Crie uma conta gratuita na Bright Data e comece a experimentar nossas soluções de dados da Web prontas para IA!






