

Python é uma das linguagens mais populares quando se trata de Scraping de dados. Qual é a maior fonte de informação na Internet? O Google! É por isso que o Scraping do Google com Python é tão popular. A ideia é recuperar automaticamente os dados SERP e utilizá-los para marketing, monitoramento da concorrência e muito mais.
Siga este tutorial guiado e aprenda como fazer scraping do Google em Python com Selenium. Vamos começar!
Que dados extrair do Google?
O Google é uma das maiores fontes de dados públicos na Internet. Há toneladas de informações interessantes que você pode recuperar dele, desde avaliações do Google Maps até respostas do “As pessoas também perguntam”:
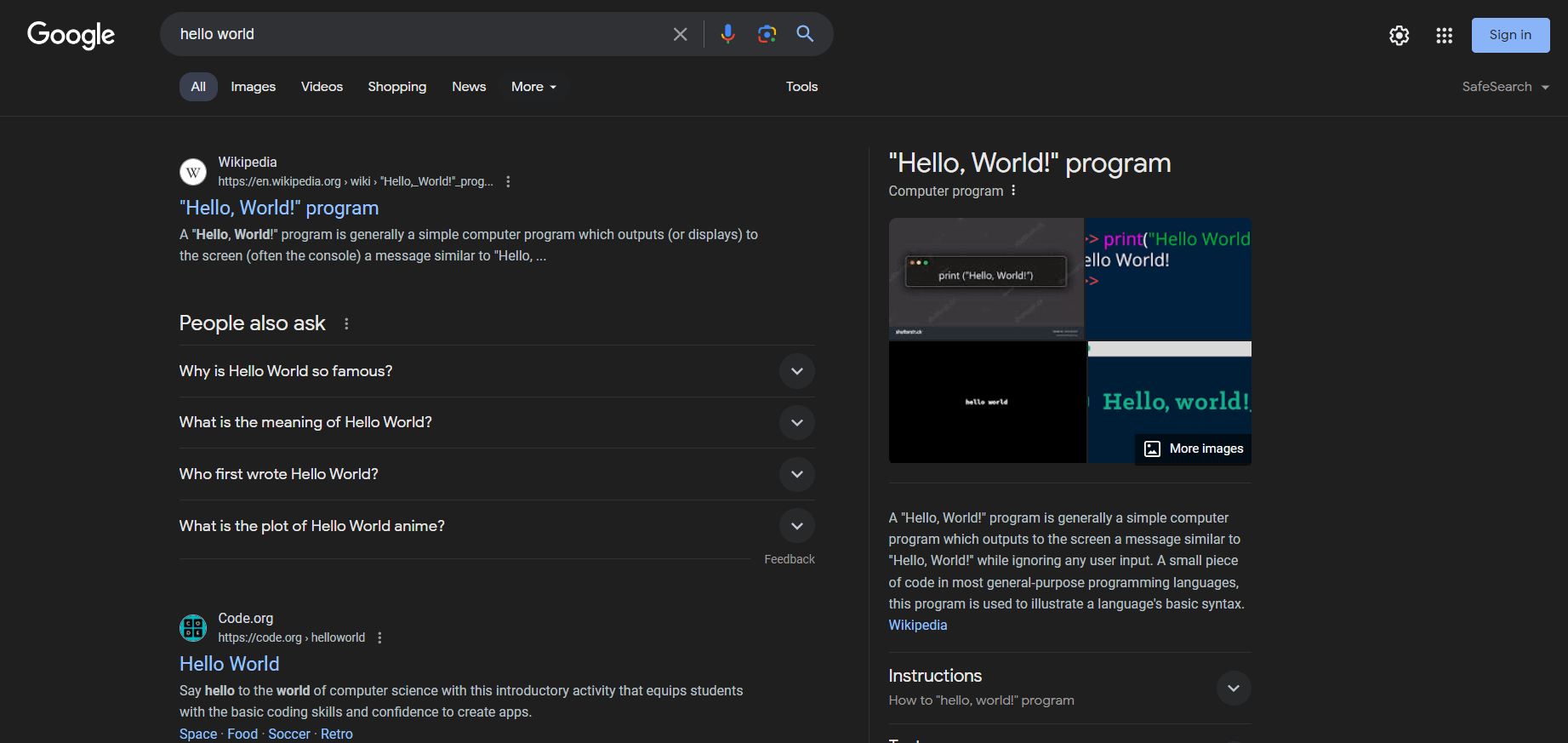
No entanto, o que geralmente interessa aos usuários e às empresas são os dados SERP. SERP, abreviação de“Search Engine Results Page” (página de resultados do mecanismo de pesquisa), é a página retornada por mecanismos de pesquisa como o Google em resposta a uma consulta do usuário. Normalmente, ela inclui uma lista de cartões com links e descrições de texto para páginas da web propostas pelo mecanismo de pesquisa.
Veja como é uma página SERP:
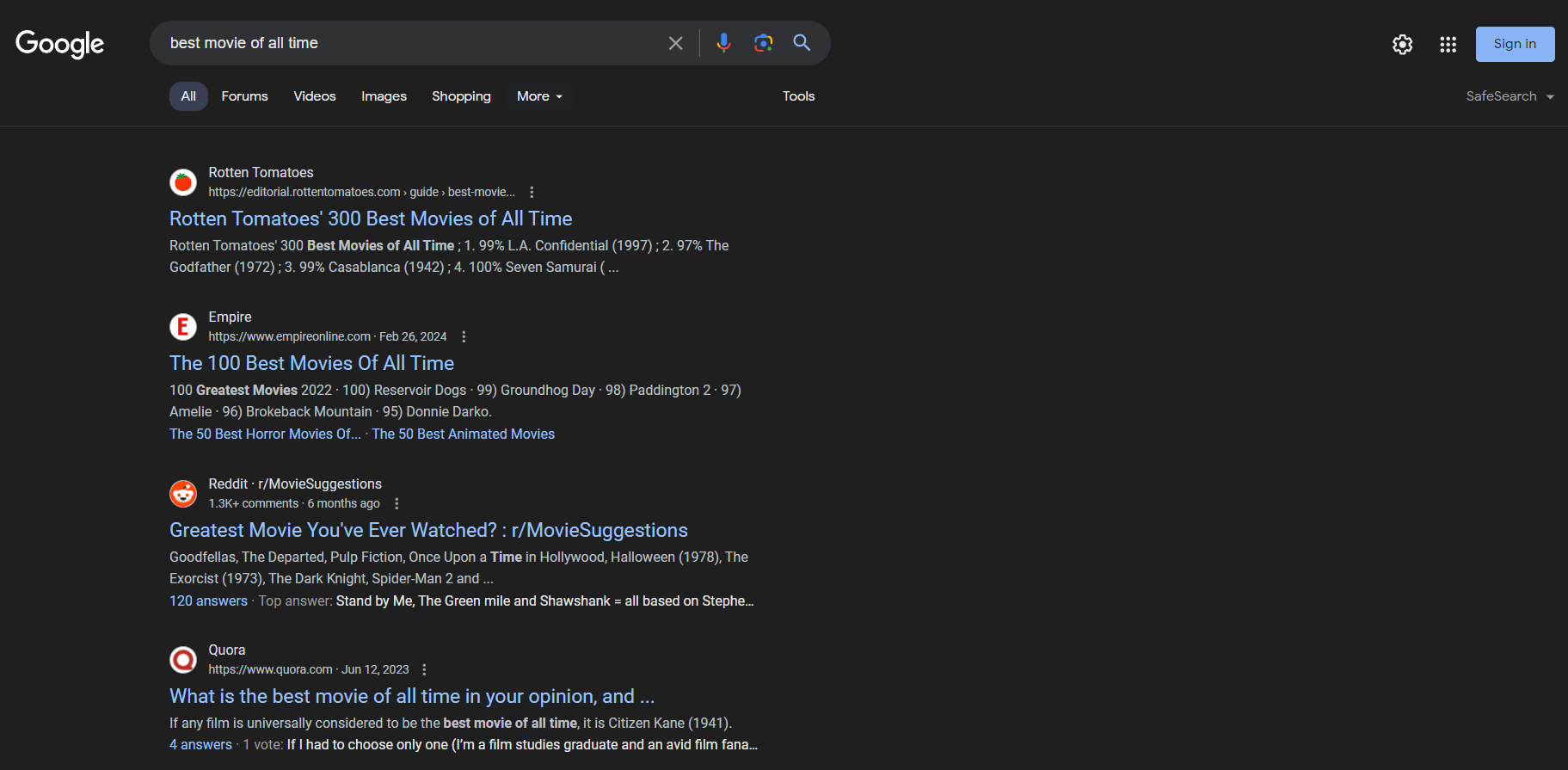
Os dados SERP são cruciais para as empresas entenderem sua visibilidade online e estudarem a concorrência. Eles fornecem insights sobre as preferências dos usuários, o desempenho das palavras-chave e as estratégias dos concorrentes. Ao analisar os dados SERP, as empresas podem otimizar seu conteúdo, melhorar as classificações de SEO e adaptar as estratégias de marketing para melhor atender às necessidades dos usuários.
Então, agora você sabe que os dados SERP são, sem dúvida, muito valiosos. Resta apenas descobrir como escolher a ferramenta certa para recuperá-los. Python é uma das melhores linguagens de programação para Scraping de dados e é perfeitamente adequada para esse fim. Mas antes de mergulhar no scraping manual, vamos explorar a melhor e mais rápida opção para fazer scraping dos resultados de pesquisa do Google: a API SERP da Bright Data.
Apresentando a API SERP da Bright Data
Antes de mergulhar no guia de scraping manual, considere aproveitar a API SERP da Bright Data para uma coleta de dados eficiente e contínua. A API SERP fornece acesso em tempo real aos resultados de todos os principais mecanismos de pesquisa, incluindo Google, Bing, DuckDuckGo, Yandex, Baidu, Yahoo e Naver. Essa ferramenta poderosa é baseada nos serviços de Proxy líderes do setor e nas soluções anti-bot avançadas da Bright Data, garantindo a recuperação de dados confiável e precisa, sem os desafios habituais associados ao Scraping de dados.
Por que escolher a API SERP da Bright Data em vez da coleta manual?
- Resultados em tempo real e alta precisão: a API SERP fornece resultados de mecanismos de pesquisa em tempo real, garantindo que você obtenha dados precisos e atualizados. Com precisão de localização até o nível da cidade, você vê exatamente o que um usuário real veria em qualquer lugar do mundo.
- Soluções anti-bot avançadas: esqueça o bloqueio ou os desafios do CAPTCHA. A API SERP inclui Resolução de CAPTCHA automatizada, impressão digital do navegador e gerenciamento completo de Proxy para garantir uma coleta de dados suave e ininterrupta.
- Personalizável e escalável: a API suporta uma variedade de parâmetros de pesquisa personalizados, permitindo que você personalize suas consultas para atender a necessidades específicas. Ela foi criada para lidar com grandes volumes, gerenciando o tráfego crescente e os períodos de pico com facilidade.
- Facilidade de uso: com chamadas de API simples, você pode recuperar dados SERP estruturados no formato JSON ou HTML, facilitando a integração com seus sistemas e fluxos de trabalho existentes. O tempo de resposta é excepcional, normalmente inferior a 5 segundos.
- Custo-benefício: economize em custos operacionais usando a API SERP. Você paga apenas pelas solicitações bem-sucedidas e não precisa investir na manutenção da Infraestrutura de scraping ou lidar com problemas de servidor.
Comece hoje mesmo seu teste grátis e experimente a eficiência e a confiabilidade da API SERP da Bright Data!
Crie um Scraper do Google SERP em Python
Siga este tutorial passo a passo e veja como criar um script de scraping do Google SERP em Python.
Etapa 1: Configuração do projeto
Para seguir este guia, você precisa ter o Python 3 instalado em sua máquina. Se precisar instalá-lo, baixe o instalador, execute-o e siga o assistente.
Agora você tem tudo o que precisa para fazer scraping do Google em Python!
Use os comandos abaixo para criar um projeto Python com um ambiente virtual:
mkdir google-scraper
cd google-scraper
python -m venv envgoogle-Scraper será o diretório raiz do seu projeto.
Carregue a pasta do projeto em seu IDE Python favorito. O PyCharm Community Edition ou o Visual Studio Code com a extensão Python são ótimas opções.
No Linux ou macOS, ative o ambiente virtual com o seguinte comando:
./env/bin/activateNo Windows, execute:
env/Scripts/activateObserve que alguns IDEs reconhecem o ambiente virtual automaticamente, portanto, você não precisa ativá-lo manualmente.
Adicione um arquivo scraper.py na pasta do seu projeto e inicialize-o conforme abaixo:
print("Olá, mundo!")Este é apenas um script simples que imprime a mensagem “Olá, mundo!”, mas em breve conterá a lógica de scraping do Google.
Verifique se o seu script funciona conforme desejado, executando-o através do botão “run” no seu IDE ou com este comando:
python Scraper.pyO script deve imprimir:
Olá, mundo!Muito bem! Agora você tem um ambiente Python para scraping de SERP.
Antes de começar a fazer scraping no Google com Python, considere dar uma olhada em nosso guia sobre Scraping de dados com Python.
Etapa 2: Instale as bibliotecas de scraping
É hora de instalar a biblioteca Python apropriada para extrair dados do Google. Existem algumas opções disponíveis, e escolher as melhores abordagens requer uma análise do site de destino. Ao mesmo tempo, estamos falando do Google, e todos sabemos como o Google funciona.
Criar uma URL de pesquisa do Google que não desperte a atenção de suas tecnologias anti-bot é complexo. Todos sabemos que o Google exige interação do usuário. É por isso que a maneira mais fácil e eficaz de interagir com o mecanismo de pesquisa é por meio de um navegador, simulando o que um usuário real faria.
Em outras palavras, você precisará de uma ferramenta de navegador headless para renderizar páginas da web em um navegador controlável. O Selenium será perfeito!
Em um ambiente virtual Python ativado, execute o comando abaixo para instalar o pacote selenium:
pip install seleniumO processo de configuração pode demorar algum tempo, então seja paciente.
Ótimo! Você acabou de adicionar o selenium às dependências do seu projeto.
Etapa 3: Configure o Selenium
Importe o Selenium adicionando as seguintes linhas ao Scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import OptionsInicialize uma instância do Chrome WebDriver para controlar uma janela do Chrome no modo headless, conforme abaixo:
# opções para iniciar o Chrome no modo headless
options = Options()
options.add_argument('--headless') # comente enquanto estiver desenvolvendo localmente
# inicialize uma instância do web driver com as
# opções especificadas
driver = webdriver.Chrome(
service=Service(),
options=options
)Observação: o sinalizador --headless garante que o Chrome seja iniciado sem GUI. Se você quiser ver as operações realizadas pelo seu script na página do Google, comente essa opção. Em geral, desative o sinalizador --headless durante o desenvolvimento local, mas deixe-o na produção. Isso porque executar o Chrome com a GUI consome muitos recursos.
Na última linha do seu script, não se esqueça de fechar a instância do driver da web:
driver.quit()Seu arquivo scraper.py agora deve conter:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# opções para iniciar o Chrome no modo headless
options = Options()
options.add_argument('--headless') # comente-o durante o desenvolvimento local
# inicializar uma instância do web driver com as
# opções especificadas
driver = webdriver.Chrome(
service=Service(),
options=options)
# lógica de scraping...
# fechar o navegador e liberar seus recursos
driver.quit()Ótimo! Você tem tudo o que precisa para fazer scraping em sites dinâmicos.
Etapa 4: Visite o Google
A primeira etapa para fazer scraping no Google com Python é conectar-se ao site de destino. Use a função get() do objeto driver para instruir o Chrome a visitar a página inicial do Google:
driver.get("https://google.com/")Esta é a aparência do seu script de scraping SERP em Python até agora:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# opções para iniciar o Chrome no modo headless
options = Options()
options.add_argument('--headless') # comente durante o desenvolvimento local
# inicializar uma instância do web driver com as
# opções especificadas
driver = webdriver.Chrome(
service=Service(),
options=options)
# conectar-se ao site de destino
driver.get("https://google.com/")
# lógica de scraping...
# fechar o navegador e liberar seus recursos
driver.quit()Inicie o script no modo headed e você verá a seguinte janela do navegador por uma fração de segundo antes que a instrução quit() o encerre:
Se você é um usuário localizado na UE (União Europeia), a página inicial do Google também conterá o pop-up do GDPR abaixo:
Em ambos os casos, a mensagem “O Chrome está sendo controlado por um software de teste automatizado” informa que o Selenium está controlando o Chrome conforme desejado.
Ótimo! O Selenium abre a página do Google conforme desejado.
Observação: se o Google exibiu a caixa de diálogo da política de cookies por motivos relacionados ao GDPR, siga a próxima etapa. Caso contrário, você pode pular para a etapa 6.
Etapa 5: Lide com a caixa de diálogo de cookies do GDPR
A seguinte caixa de diálogo de cookies do GDPR do Google aparecerá ou não, dependendo da localização do seu IP. Integre um Proxy no Selenium para escolher um IP de saída do país de sua preferência e evitar esse problema.
Inspecione o elemento HTML da caixa de diálogo de cookies com o DevTools:
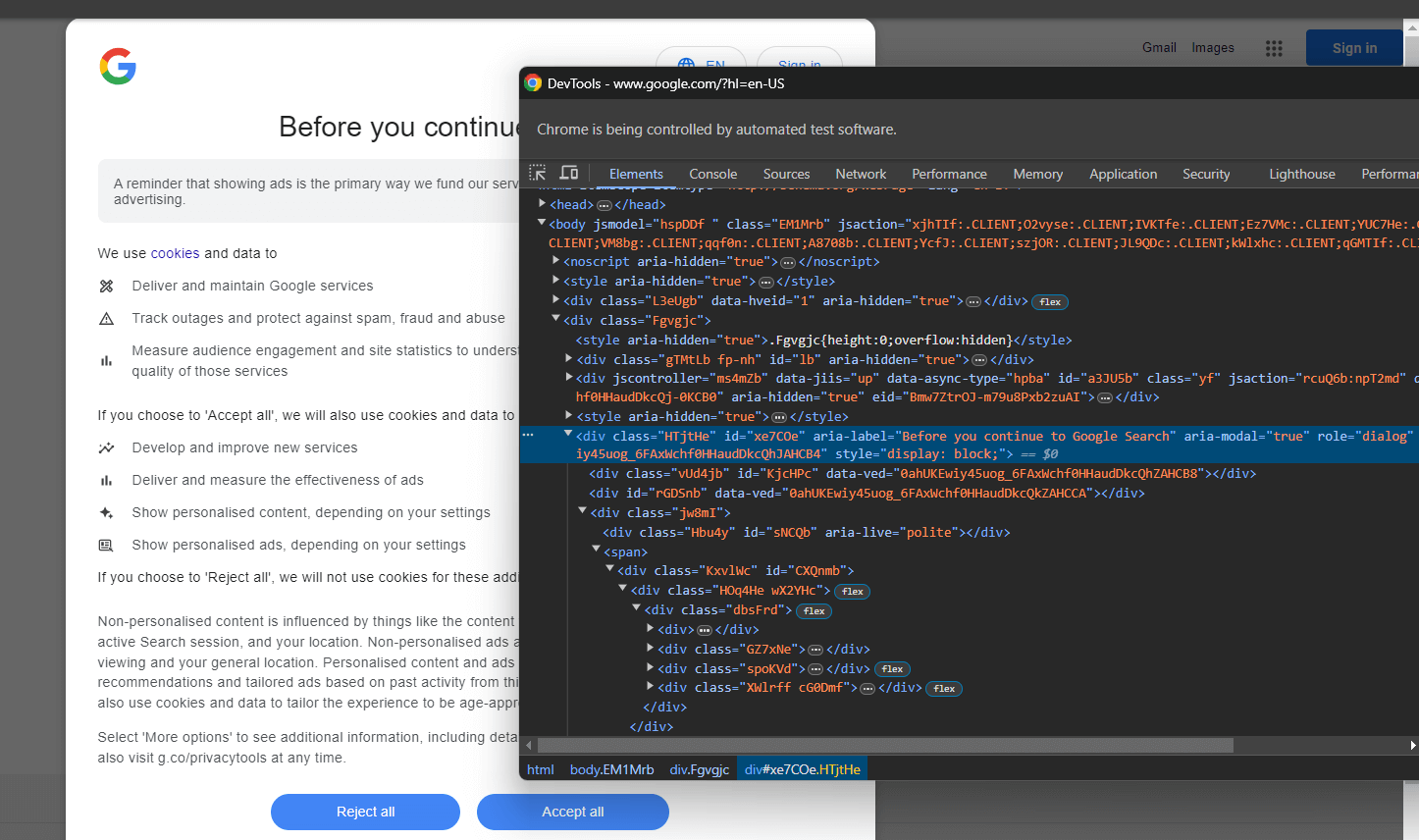
Expanda o código e você verá que pode selecionar este elemento HTML com o seletor CSS abaixo:
[role='dialog']Se você inspecionar o botão “Aceitar tudo”, perceberá que não há uma estratégia simples de seleção CSS para selecioná-lo:
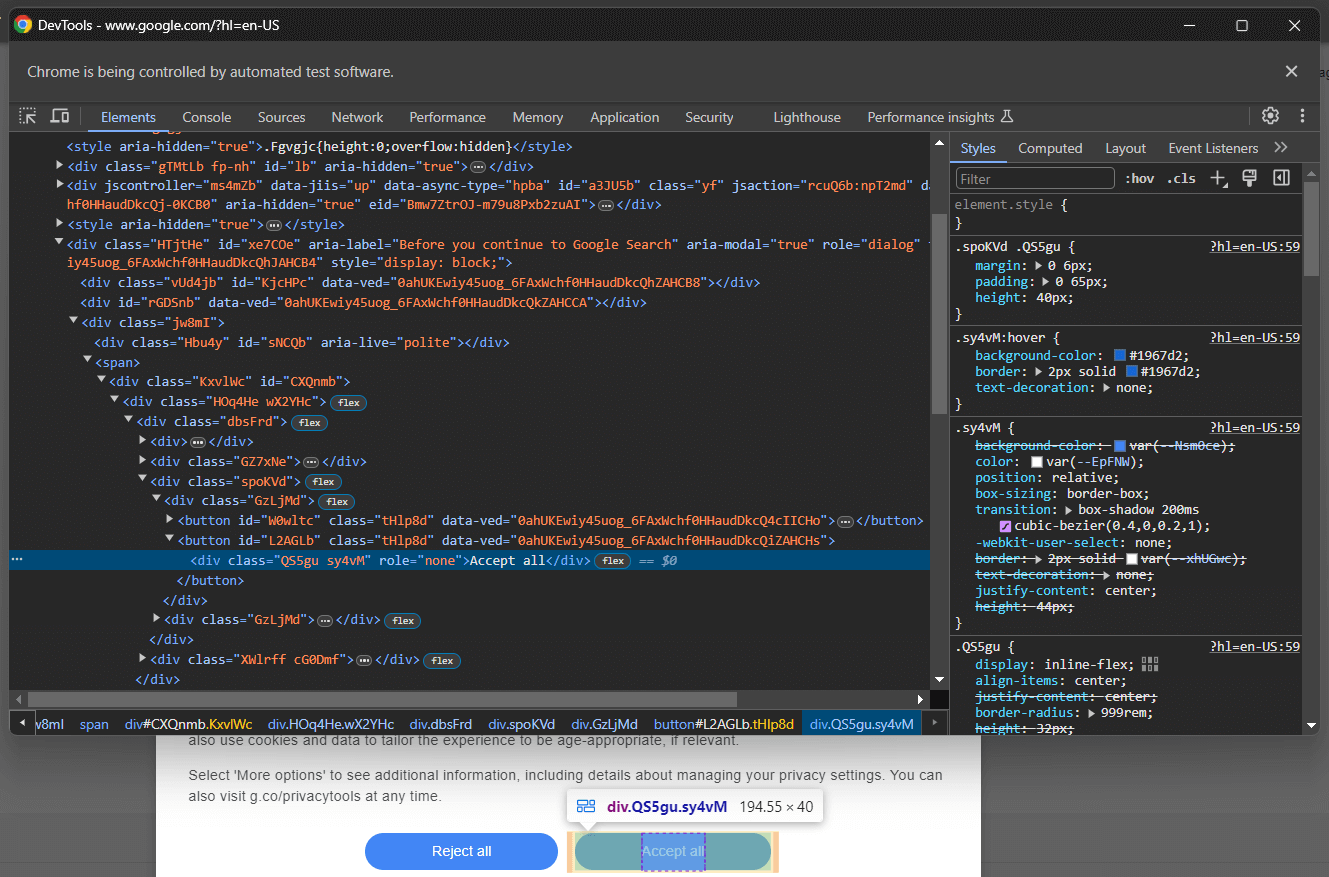
Em detalhes, as classes CSS no código HTML parecem ser geradas aleatoriamente. Para selecionar o botão, obtenha todos os botões no elemento da caixa de diálogo de cookies e encontre aquele com o texto “Aceitar tudo”. O seletor CSS para obter todos os botões dentro da caixa de diálogo de cookies é:
[role='dialog'] buttonAplique um seletor CSS no DOM passando-o para o método find_elements() do Selenium. Isso seleciona elementos HTML na página com base na estratégia especificada, que neste caso é um seletor CSS:
buttons = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] button")Para funcionar corretamente, a linha acima requer a seguinte importação:
from selenium.webdriver.common.by import ByUse next() para encontrar o botão “Aceitar tudo”. Em seguida, clique nele:
accept_all_button = next((b for b in buttons if "Aceitar tudo" in b.get_attribute("innerText")), None)
# clique no botão "Aceitar tudo", se estiver presente
if accept_all_button is not None:
accept_all_button.click()Esta instrução localizará o elemento <button> na caixa de diálogo cujo texto contém a string “Aceitar tudo”. Se estiver presente, ele clicará nele chamando o método click() do Selenium.
Fantástico! Você está pronto para simular uma pesquisa no Google em Python para coletar alguns dados SERP.
Etapa 6: Simule uma pesquisa no Google
Abra o Google no seu navegador e inspecione o formulário de pesquisa no DevTools:
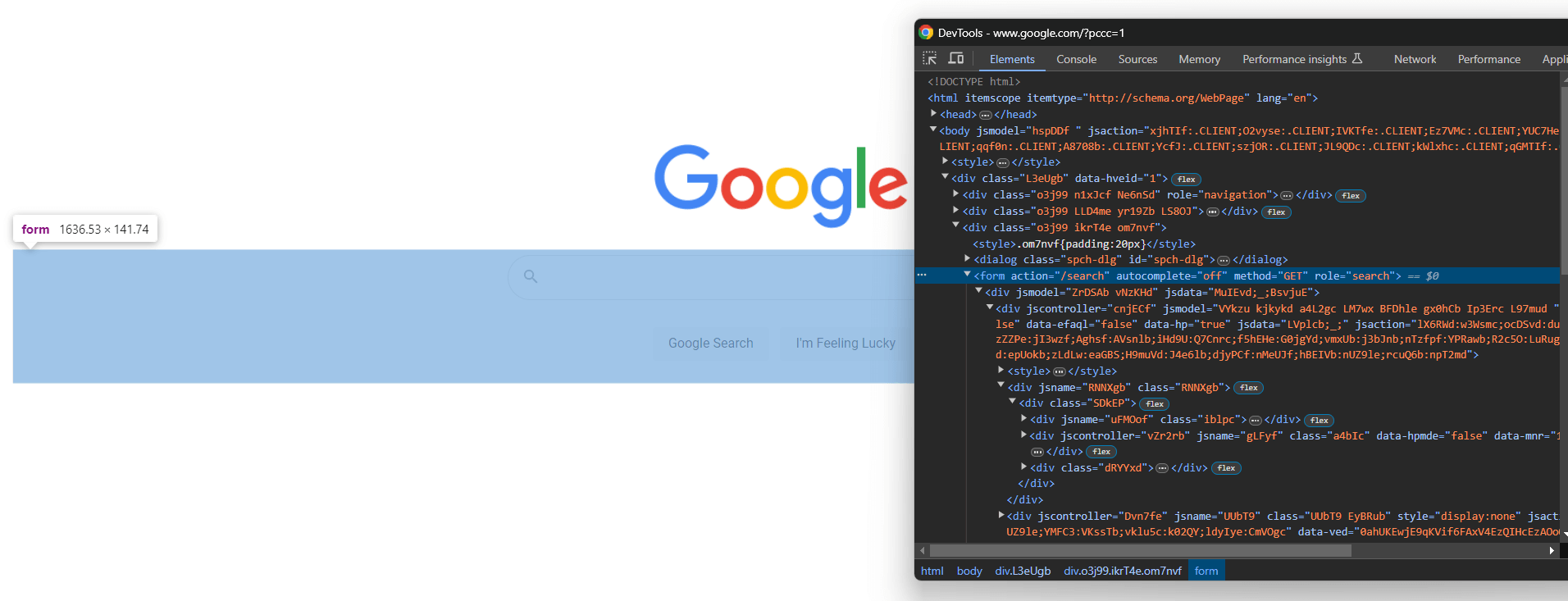
As classes CSS parecem ser geradas aleatoriamente, mas você pode selecionar o formulário direcionando seu atributo de ação com este seletor CSS:
form[action='/search']Aplique-o no Selenium para recuperar o elemento do formulário por meio do método find_element():
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")Se você pulou a etapa 5, precisará adicionar a seguinte importação:
from selenium.webdriver.common.by import ByExpanda o código HTML do formulário e concentre-se na área de texto de pesquisa:
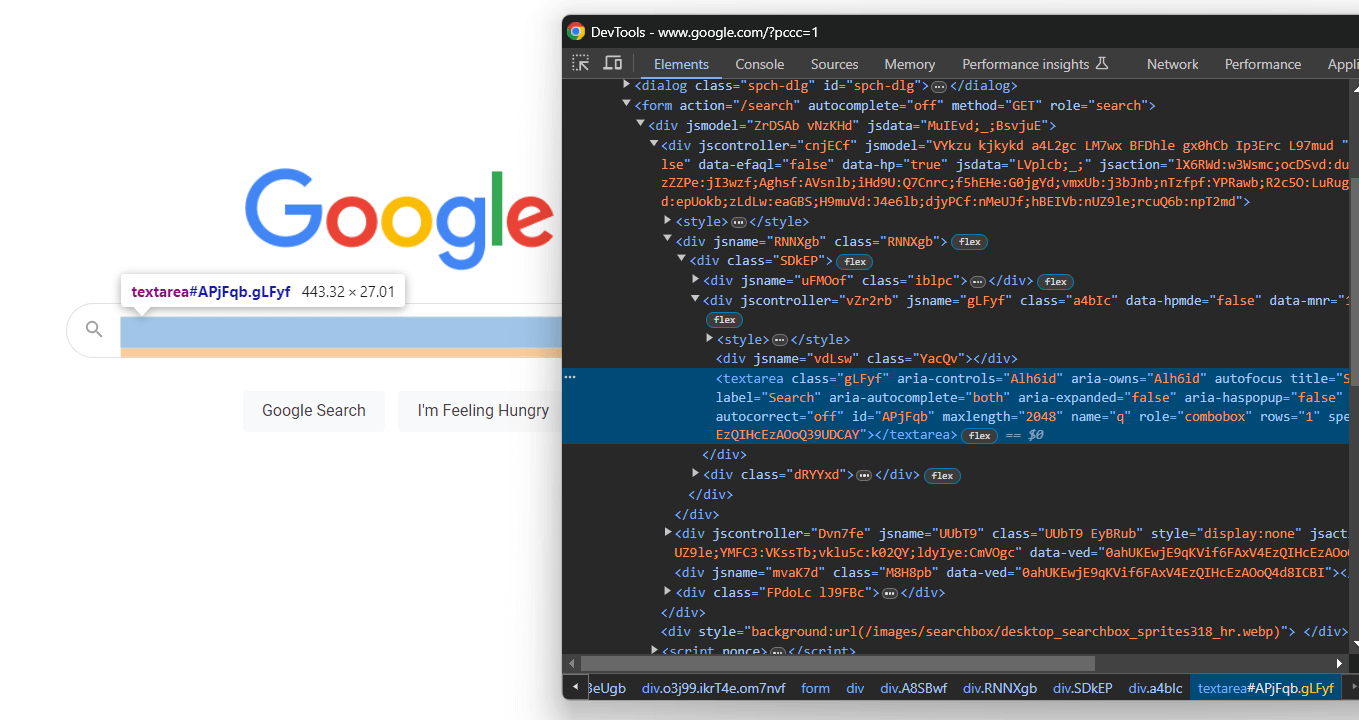
Novamente, a classe CSS é gerada aleatoriamente, mas você pode selecioná-la direcionando seu valor aria-label:
textarea[aria-label='Pesquisar']Assim, localize a área de texto dentro do formulário e use o botão send_keys() para digitar a consulta de pesquisa do Google:
search_form_textarea= search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)Nesse caso, a consulta do Google será “bright data”. Lembre-se de que qualquer outra consulta servirá.
Agora, chame o submit() no elemento do formulário para enviar o formulário e simular uma pesquisa no Google:
search_form.submit()O Google realizará a pesquisa com base na consulta especificada e redirecionará você para a página SERP desejada:
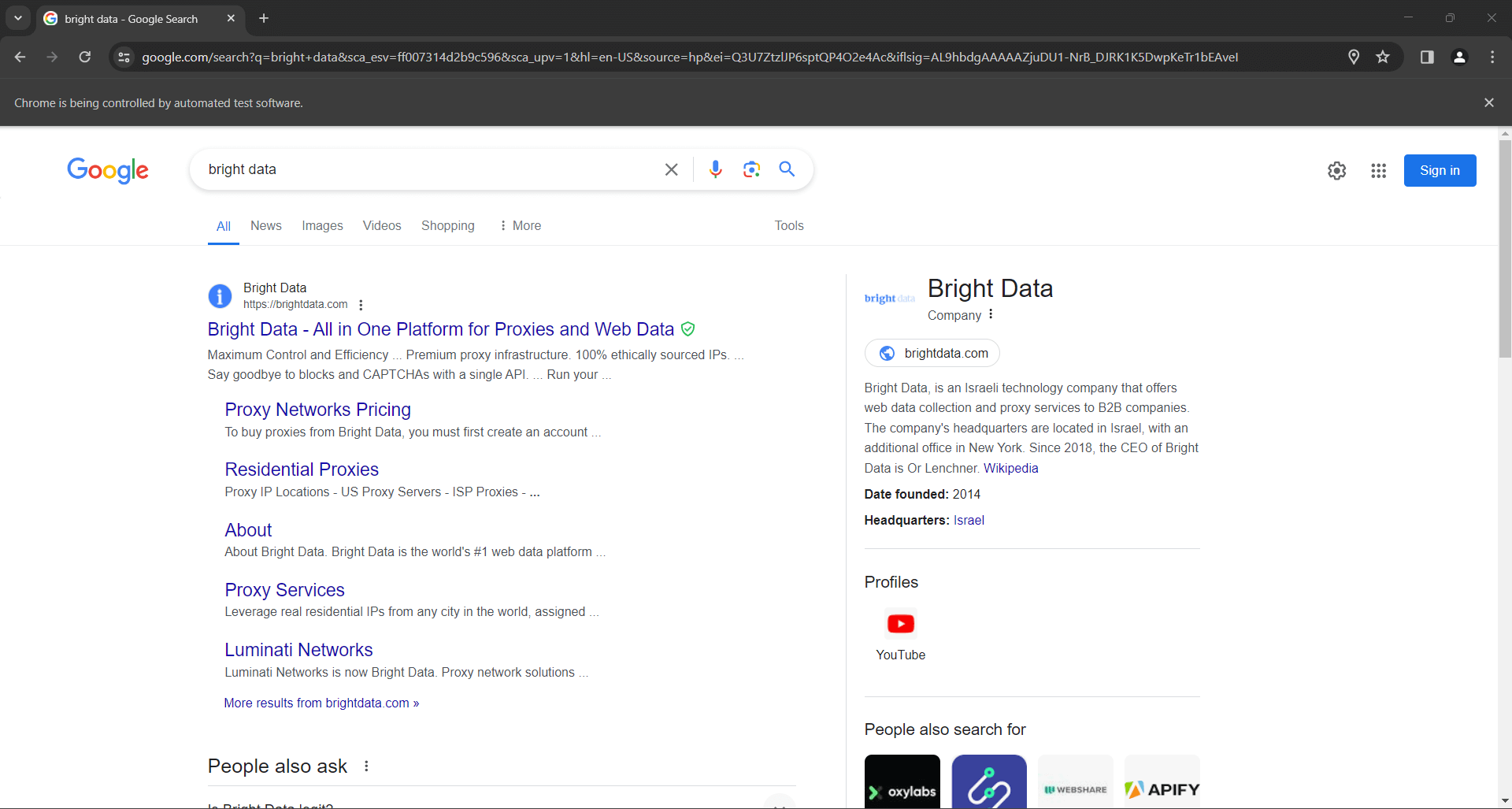
As linhas para simular uma pesquisa no Google em Python com o Selenium são:
# selecione o formulário de pesquisa do Google
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# selecione a área de texto dentro do formulário
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# preencha a área de texto com uma determinada consulta
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# envie o formulário e execute a pesquisa no Google
search_form.submit()Pronto! Prepare-se para recuperar dados SERP raspando o Google em Python.
Etapa 7: Selecione os elementos do resultado da pesquisa
Inspecione a coluna à direita na seção de resultados:
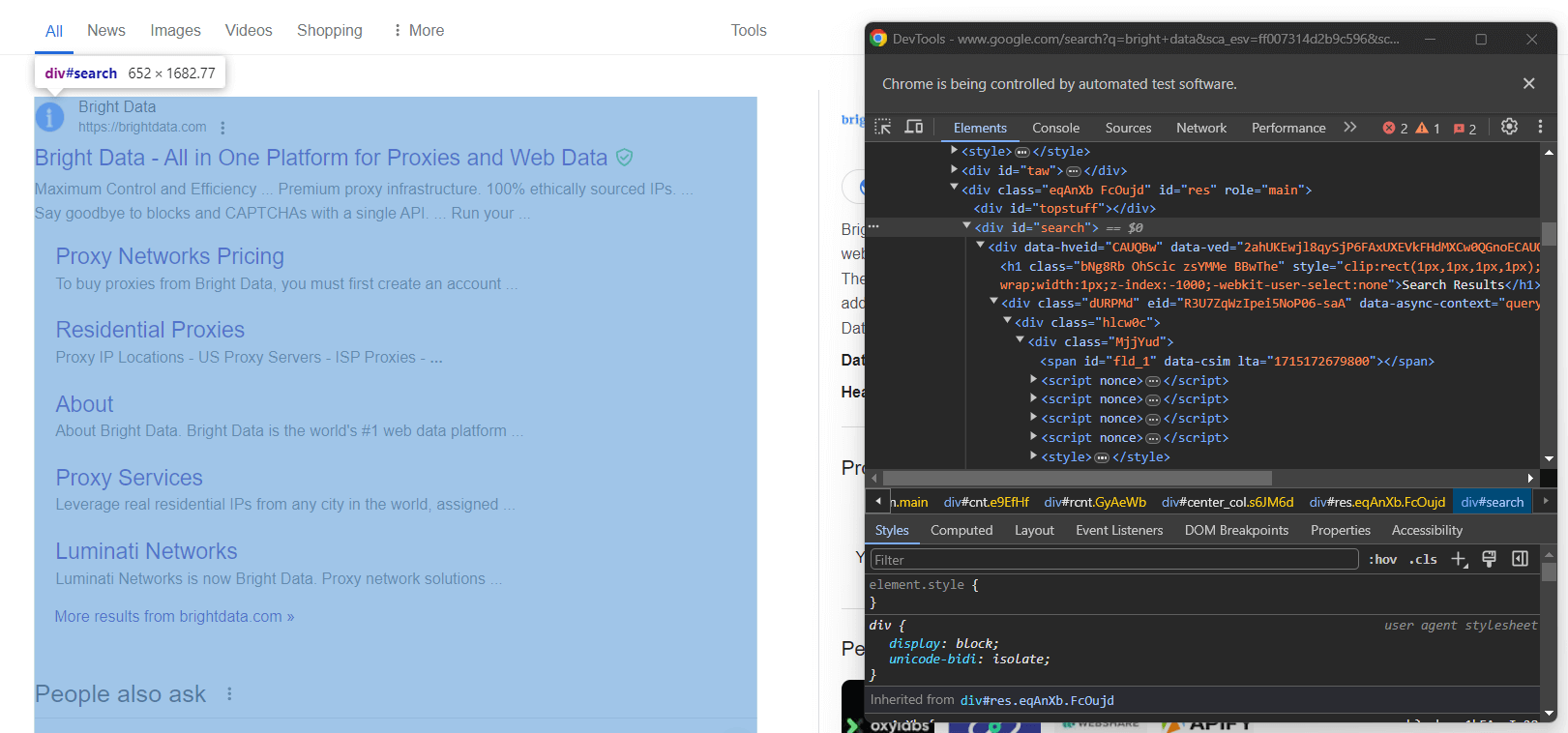
Como você pode ver, este é um elemento <div> que você pode selecionar com o seletor CSS abaixo:
#searchNão se esqueça de que as páginas do Google são dinâmicas. Portanto, você deve esperar que esse elemento esteja presente na página antes de interagir com ele. Faça isso com a seguinte linha:
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))WebDriverWait é uma classe especial oferecida pelo Selenium para implementar esperas explícitas. Em particular, ela permite que você espere que um evento específico ocorra na página.
Nesse caso, o script aguardará até 10 segundos para que o nó HTML #search esteja presente no nó. Dessa forma, você pode garantir que o SERP do Google tenha sido carregado conforme desejado.
O WebDriverWait requer algumas importações extras, portanto, adicione-as ao scraper.py:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECAgora, inspecione os elementos de pesquisa do Google:
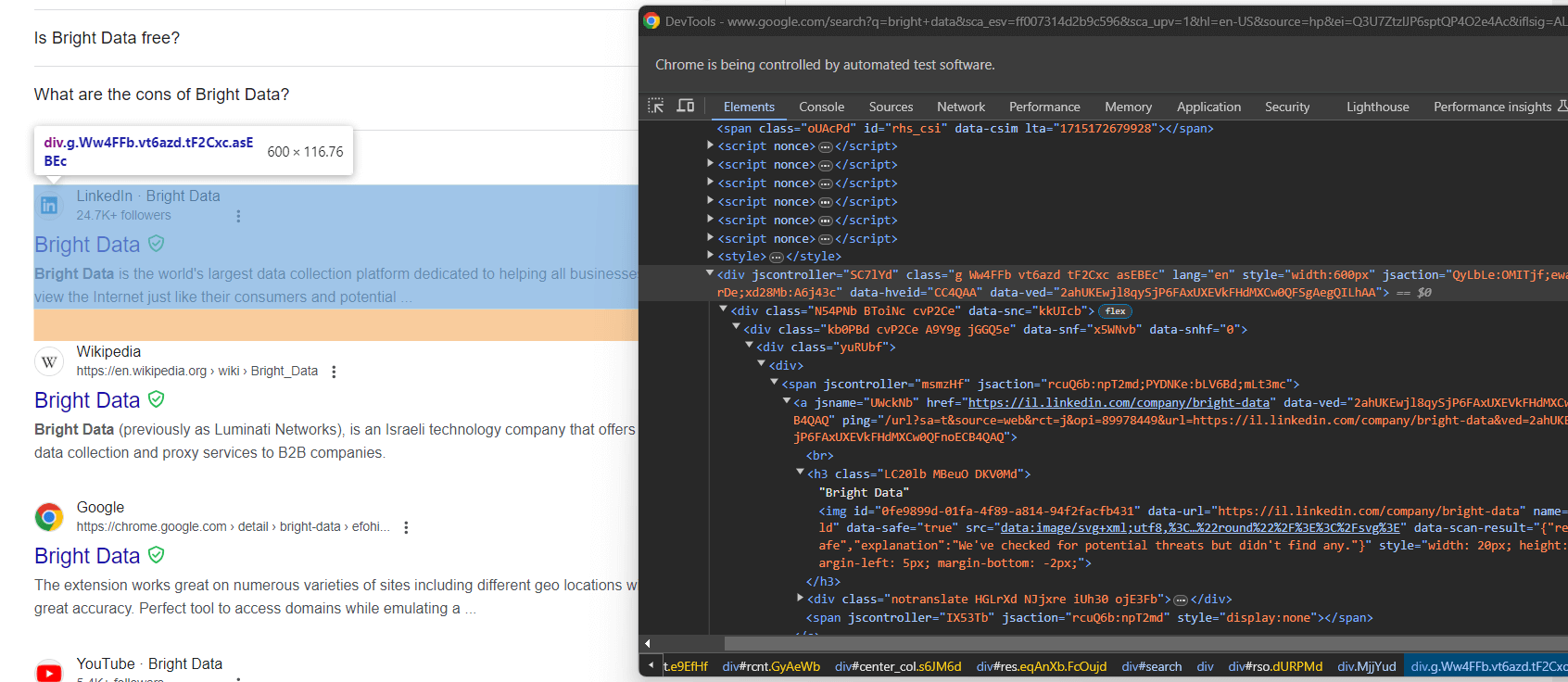
Novamente, selecioná-los por meio de classes CSS não é uma boa abordagem. Em vez disso, concentre-se em seus atributos HTML incomuns. Um seletor CSS adequado para obter os elementos de pesquisa do Google é:
div[jscontroller][lang][jsaction][data-hveid][data-ved]Isso identifica todos os <div> que têm os atributos jscontroller, lang, jsaction, data-hveid e data-ved.
Passe-o para find_elements() para selecionar todos os elementos de pesquisa do Google em Python via Selenium:
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")A lógica completa será:
# aguarde até 10 segundos para que o div de pesquisa apareça na página
# e selecione-o
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# selecione os elementos de pesquisa do Google no SERP
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")Ótimo! Você está a apenas um passo de extrair dados SERP em Python.
Etapa 8: extrair os dados da SERP
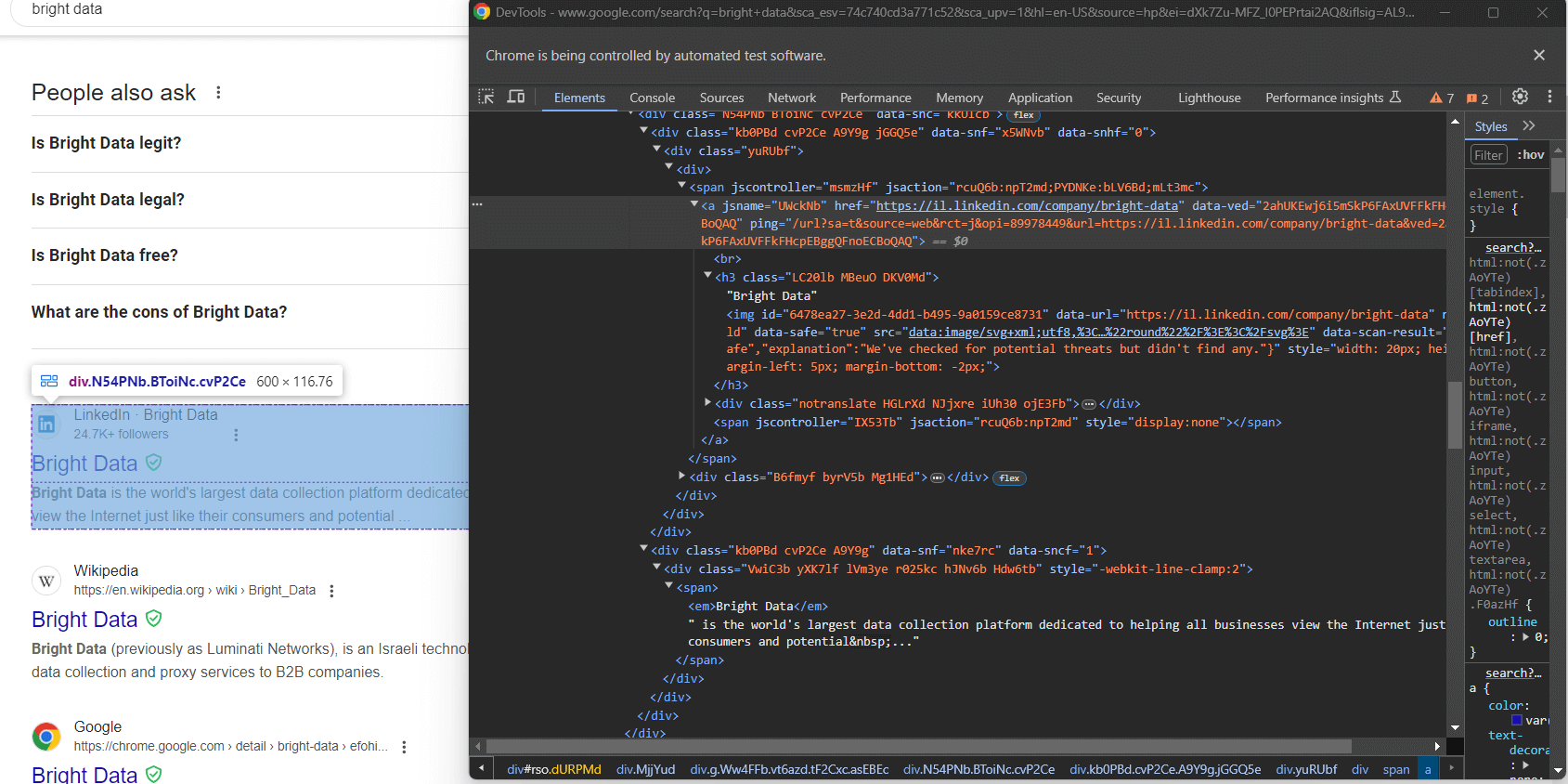
Nem todas as SERPs do Google são criadas da mesma forma. Em alguns casos, o primeiro resultado de pesquisa na página tem um código HTML diferente dos outros elementos de pesquisa:
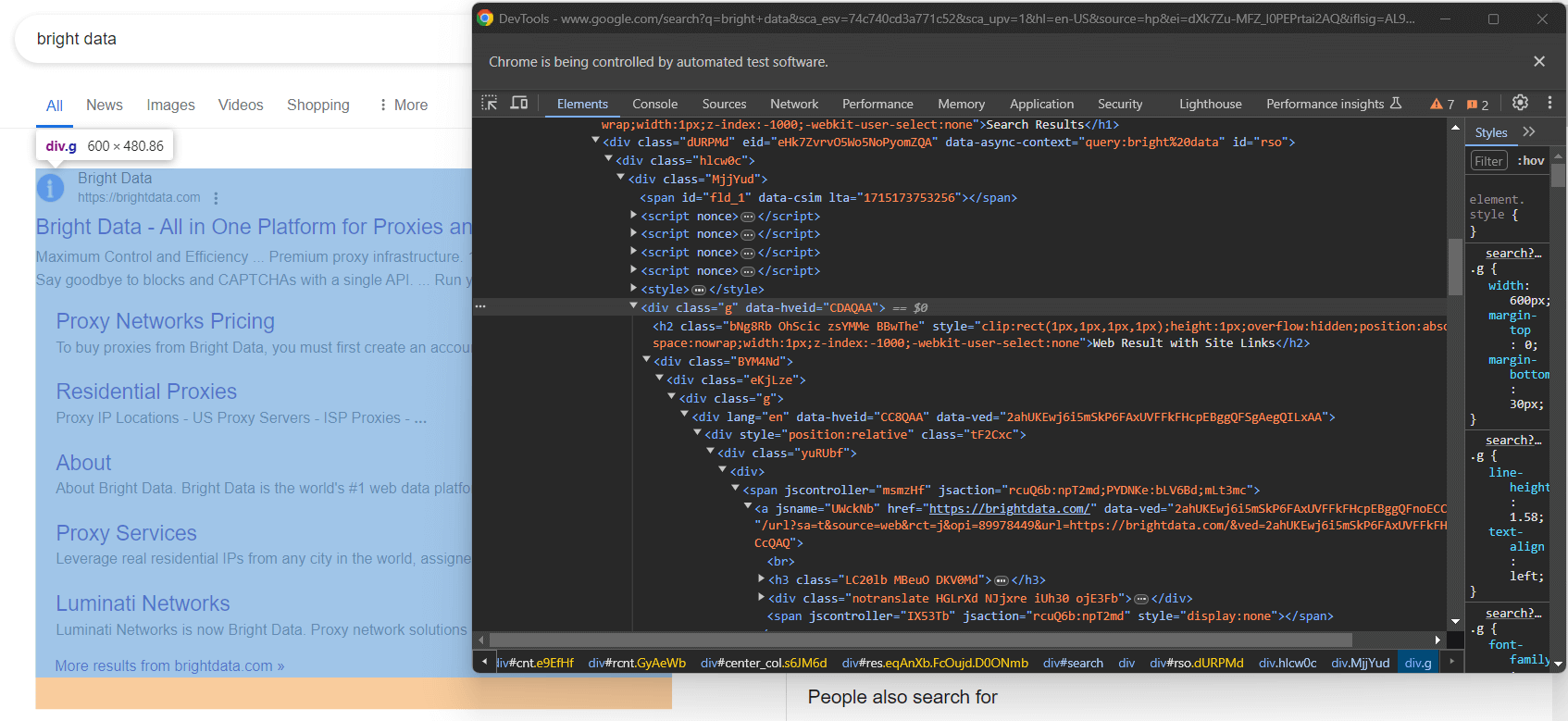
Por exemplo, neste caso, o primeiro elemento do resultado da pesquisa pode ser recuperado com este seletor CSS:
div.g[data-hveid]Além disso, o conteúdo de um elemento de pesquisa do Google é praticamente o mesmo. Isso inclui:
- O título da página em um nó
<h3>. - Uma URL para a página específica em um elemento
<a>que é o pai do<h3>acima. - Uma descrição no
[data-sncf='1'] <div>.
Como uma única SERP contém vários resultados de pesquisa, inicialize uma matriz onde armazenar seus dados coletados:
serp_elements = []Você também precisará de um número inteiro de classificação para acompanhar a classificação deles na página:
rank = 1Defina uma função para coletar elementos de pesquisa do Google em Python da seguinte maneira:
def scrape_search_element(search_element, rank):
# selecione os elementos de interesse dentro do
# elemento de pesquisa, ignorando os que estão faltando, e aplique
# a lógica de extração de dados
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
except NoSuchElementException:
title = None
tente:
# obtenha o elemento "a" que tem um filho "h3"
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
exceto NoSuchElementException:
url = None
tente:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
description = description_div.get_attribute("innerText")
exceto NoSuchElementException:
description = None
# retorne um novo elemento de dados SERP
retorne {
'rank': rank,
'url': url,
'title': title,
'description': description
}O Google tende a alterar bastante suas páginas SERP. Os nós dentro dos elementos de pesquisa podem desaparecer e você deve se proteger contra isso com instruções try ... catch. Mais especificamente, quando um elemento não está no DOM, find_element() gera uma exceção NoSuchElementException.
Importe a exceção:
from selenium.common import NoSuchElementExceptionObserve o uso do operador CSS has() para selecionar um nó com um filho específico. Saiba mais sobre isso na documentação oficial.
Agora, passe o primeiro elemento de pesquisa e os restantes para a função scrape_search_element(). Em seguida, adicione os objetos retornados à matriz serp_elements:
# raspar dados do primeiro elemento no SERP
# (se presente)
tente:
primeiro_elemento_de_pesquisa = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(primeiro_elemento_de_pesquisa, rank))
rank += 1
exceto NoSuchElementException:
pass
# extrair dados de todos os elementos de pesquisa na SERP
para google_search_element em google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1Ao final dessas instruções, serp_elements armazenará todos os dados SERP de interesse. Verifique isso imprimindo-os no terminal:
imprimir(serp_elements)Isso produzirá algo como:
[
{'rank': 1, 'url': 'https://brightdata.com/', 'title': 'Bright Data - Plataforma completa para Proxies e dados da web', 'description': None},
{'rank': 2, 'url': 'https://il.linkedin.com/company/bright-data', 'title': 'Bright Data', 'description': "Bright Data é a maior plataforma de coleta de dados do mundo dedicada a ajudar todas as empresas a ver a Internet da mesma forma que seus consumidores e potenciais..."},
# omitido por brevidade...
{'rank': 6, 'url': 'https://aws.amazon.com/marketplace/seller-profile?id=bf9b4324-6ee3-4eb3-9ca4-083e558d04c4', 'title': 'Bright Data - AWS Marketplace', 'description': 'A Bright Data é uma plataforma líder em coleta de dados, que permite aos nossos clientes coletar conjuntos de dados estruturados e não estruturados de milhões de sites...'},
{'rank': 7, 'url': 'https://techcrunch.com/2024/02/26/meta-desiste-de-ação-judicial-contra-a-empresa-de-Scraping-de-dados Bright Data...', 'title': 'Meta desiste de ação judicial contra a empresa de Scraping de dados Bright Data...', 'description': '26 de fevereiro de 2024 — A Meta desistiu do processo contra a empresa israelense de Scraping de dados Bright Data, após perder uma alegação importante no caso há algumas semanas.'}
]Incrível! Resta apenas exportar os dados coletados para CSV.
Etapa 9: Exporte os dados coletados para CSV
Agora que você sabe como fazer scraping no Google com Python, veja como exportar os dados recuperados para um arquivo CSV.
Primeiro, importe o pacote csv da biblioteca padrão do Python:
import csvEm seguida, use o pacote csv para preencher o arquivo de saída serp_data.csv com seus dados SERP:
header = ["rank", "url", "title", "description"]
with open("serp_data.csv", 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)Et voilà! Seu script de scraping do Google Python está pronto.
Etapa 10: Junte tudo
Este é o código final do seu script scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common import NoSuchElementException
import csv
def scrape_search_element(search_element, rank):
# selecione os elementos de interesse dentro do
# elemento de pesquisa, ignorando os que estão faltando, e aplique
# a lógica de extração de dados
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
exceto NoSuchElementException:
title = None
tente:
# obtenha o elemento "a" que tem um filho "h3"
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
exceto NoSuchElementException:
url = None
tente:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
descrição = description_div.get_attribute("innerText")
exceto NoSuchElementException:
descrição = None
# retorne um novo elemento de dados SERP
retorne {
'rank': rank,
'url': url,
'title': title,
'description': description
}
# opções para iniciar o Chrome no modo headless
options = Options()
options.add_argument('--headless') # comente durante o desenvolvimento local
# inicialize uma instância do web driver com as
# opções especificadas
driver = webdriver.Chrome(
service=Service(),
options=options)
# conecte-se ao site de destino
driver.get("https://google.com/?hl=en-US")
# selecionar os botões na caixa de diálogo de cookies
buttons = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] button")
accept_all_button = next((b for b in buttons if "Accept all" in b.get_attribute("innerText")), None)
# clicar no botão “Aceitar tudo”, se estiver presente
if accept_all_button is not None:
accept_all_button.click()
# selecionar o formulário de pesquisa do Google
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# selecione a área de texto dentro do formulário
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# preencha a área de texto com uma determinada consulta
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# enviar o formulário e realizar a pesquisa no Google
search_form.submit()
# aguardar até 10 segundos para que o div de pesquisa apareça na página
# e selecioná-lo
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# selecionar os elementos de pesquisa do Google na SERP
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")
# onde armazenar os dados coletados
serp_elements = []
# para acompanhar a classificação atual
classificação = 1
# extrair dados do primeiro elemento na SERP
# (se presente)
tente:
primeiro_elemento_de_pesquisa = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(primeiro_elemento_de_pesquisa, classificação))
classificação += 1
exceto NoSuchElementException:
passar
# extrair dados de todos os elementos de pesquisa na SERP
para google_search_element em google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1
# exportar os dados extraídos para CSV
header = ["rank", "url", "title", "description"]
com open("serp_data.csv", 'w', newline='', encoding='utf-8') como csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)
# fechar o navegador e liberar seus recursos
driver.quit()Uau! Com pouco mais de 100 linhas de código, você pode criar um Scraper do Google SERP em Python.
Verifique se ele produz os resultados esperados executando-o em seu IDE ou usando este comando:
python Scraper.pyAguarde até que a execução do Scraper termine e um arquivo serp_results.csv aparecerá na pasta raiz do projeto. Abra-o e você verá:

Parabéns! Você acabou de realizar um scraping do Google em Python.
Conclusão
Neste tutorial, você viu quais dados podem ser coletados do Google e por que os dados SERP são os mais interessantes. Em particular, você aprendeu a usar a automação do navegador para criar um Scraper SERP em Python usando o Selenium.
Isso funciona em exemplos simples, mas há três desafios principais ao fazer scraping no Google com Python:
- O Google muda constantemente a estrutura da página dos SERPs.
- O Google tem algumas das soluções anti-bot mais avançadas do mercado.
- Criar um processo de scraping eficaz que possa recuperar toneladas de dados SERP em paralelo é complexo e custa muito dinheiro.
Esqueça esses desafios com a API SERP da Bright Data. Essa API de última geração fornece um conjunto de endpoints que expõem dados SERP em tempo real de todos os principais mecanismos de pesquisa. A API SERP é baseada nosserviços de Proxy e nas soluções anti-bot da Bright Data, visando vários mecanismos de pesquisa sem esforço.
Faça uma chamada de API simples e obtenha seus dados SERP no formato JSON ou HTML graças à API SERP. Comece seu teste grátis hoje mesmo!





