
Neste guia, abordaremos o uso e a arquitetura de um Scraper LLM universal para rastreamento de menções LLM. Este projeto combinará os seguintes Scrapers em uma única interface unificada:
Ao concluir este guia, você será capaz de realizar o seguinte.
- Acionar scrapers usando a API de Scraping de dados da Bright Data.
- Verificar a prontidão e baixar os resultados do Scraper.
- Usar o formato de saída da Bright Data para uma normalização sem esforço.
- Comparar prompts em vários LLMs simultaneamente para pesquisa e validação.
Quer começar imediatamente o projeto? Confira no GitHub.
Por que criar um Scraper LLM universal?
O comportamento de pesquisa mudou. Agora, os usuários fazem perguntas aos chatbots de IA e confiam nas respostas geradas, raramente voltando para continuar a pesquisa. Isso muda drasticamente as operações de SEO e inteligência de mercado: se sua marca não for mencionada nas saídas do chatbot, os clientes em potencial podem nunca descobri-la.
Agora, as empresas precisam aparecer não apenas nos resultados de pesquisa, mas também nas saídas dos modelos. Os Scrapers LLM pré-construídos da Bright Data fornecem saídas normalizadas dos modelos mais populares do mercado. Ao unificar essas APIs em uma única interface, as equipes podem comparar os resultados das recomendações em todos os principais LLMs.
Considere o prompt: Quem são os melhores provedores de Proxy residencial?
Consultar manualmente cada LLM e ler os resultados pode levar uma hora ou mais. Com resultados unificados, você encaminha a pergunta para vários LLMs simultaneamente e usa regex para determinar imediatamente se sua empresa aparece nas respostas.
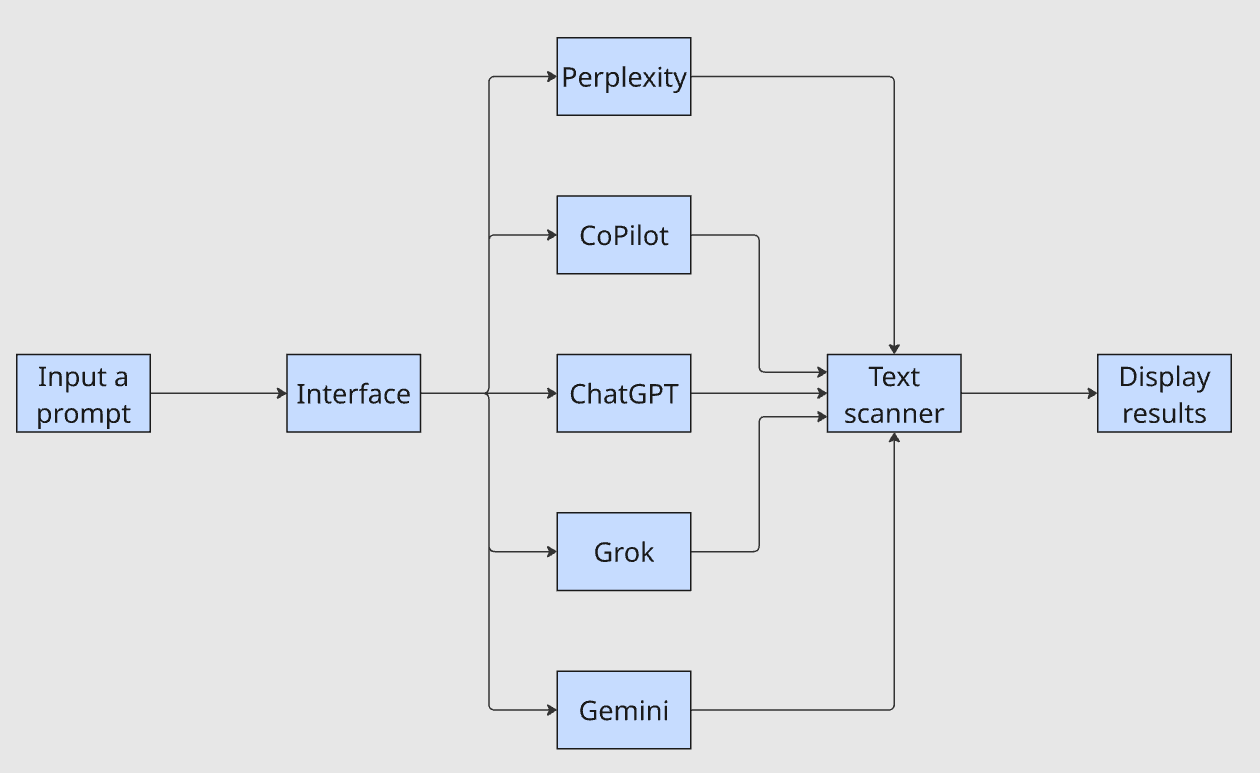
A interface recebe uma única solicitação, encaminha-a para cada LLM, canaliza as saídas por meio de um scanner de texto e exibe os resultados. A pergunta “Minha empresa aparece nos resultados?” agora leva minutos, em vez de uma hora.
Criando o software propriamente dito
Agora, precisamos criar o software propriamente dito. Criaremos a estrutura básica do nosso projeto. Em seguida, preencheremos o código à medida que avançamos. Esta seção não contém a base de código completa. Trata-se de uma análise conceitual, não de um passo a passo linha por linha.
Introdução
Podemos começar criando uma nova pasta de projeto.
mkdir universal-llm-scraper
cd universal-llm-scraperEm seguida, criamos um ambiente virtual para evitar conflitos de dependência.
python -m venv .venvEm seguida, você precisa ativar o ambiente virtual. O primeiro comando pode ser ativado no Linux ou macOS. Se você estiver no Windows, use o segundo comando.
Linux/macOS
source .venv/bin/activateWindows
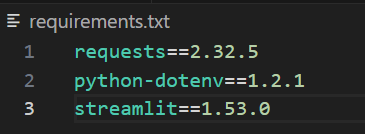
..venvScriptsActivate.ps1Por fim, crie um arquivo chamado requirements.txt e adicione as dependências que você vê abaixo. Você pode ajustar os números das versões. No entanto, essas versões funcionaram bem durante a compilação, então as fixamos para obter um comportamento reproduzível.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0Quando terminar, o arquivo ficará parecido com a imagem abaixo.
Para instalar essas dependências, basta executar o comando pip abaixo.
pip install -r requirements.txtModelos de IA como objetos
Em seguida, precisamos entender que todos os nossos modelos de IA funcionam como objetos. Cada um deles tem os seguintes atributos.
nome: um rótulo legível por humanos para o modelo.dataset_id: este é um identificador exclusivo para o Scraper.url: a URL real que usamos para acessar o modelo de IA.
Na classe abaixo, criamos esse mesmo objeto de modelo. Essa classe não precisa de métodos ou lógica. Se você estiver familiarizado com ciência da computação, ela é semelhante a uma estrutura antiga.
class AIModel:
def __init__(self, name: str, dataset_id: str, url: str):
self.name = name
self.dataset_id = dataset_id
self.url = url Escrevendo um recuperador de modelo
Em seguida, precisamos escrever um recuperador de modelo. Essa classe faz um trabalho mais pesado. O recuperador de modelo fornece uma camada de orquestração unificadora entre o Bright Data e o restante do nosso código. Ele usa sua chave API do Bright Data para autenticar com a API. Também temos uma variedade de métodos: get_model_response(), trigger_prompt_collection(), collect_snapshot() e write_model_output(). À medida que continuamos, preencheremos esses métodos.
class AIModelRetriever:
def __init__(self, api_token: str):
self.api_token = api_token
def get_model_response(self, model: AIModel, prompt: str):
pass
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
pass
def collect_snapshot(self, model: AIModel, snapshot_id: str):
pass
def write_model_output(self, model: AIModel, llm_response: dict):
passobter_resposta_do_modelo()
Este método será usado principalmente para orquestração. Ele usa trigger_prompt_collection() para iniciar um Scraper e retornar seu snapshot_id. Em seguida, collect_snapshot() é usado para consultar a API e retornar a resposta quando estiver pronta. Por fim, gravamos a resposta em um arquivo usando write_model_output().
def get_model_response(self, model: AIModel, prompt: str):
snapshot_id = self.trigger_prompt_collection(model, prompt)
if not snapshot_id:
raise RuntimeError(f"{model.name}: falha ao acionar o snapshot. Aguarde e tente novamente.")
llm_response = self.collect_snapshot(model, snapshot_id)
if not llm_response:
raise RuntimeError(f"Falha ao coletar o snapshot {snapshot_id} para {model.name}. Aguarde e tente novamente")
self.write_model_output(model, llm_response)trigger_prompt_collection()
Para acionar uma coleta, passamos nosso token de API para os cabeçalhos HTTP. Em seguida, tentamos uma solicitação POST para a API. Permitimos até três tentativas, pois falhas em HTTP podem ser imprevisíveis e as tentativas compensam isso. Se a resposta for boa, retornamos o snapshot_id. Se ocorrerem erros, continuamos tentando até esgotarmos as tentativas. Se excedermos as tentativas, saímos da função.
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
headers = {
"Authorization": f"Bearer {self.api_token}",
"Content-Type": "application/json",
}
data = json.dumps(
{"input":
[
{
"url": model.url,
"prompt": prompt,
"country":country,
}
],
})
tries = 3
while tries > 0:
resposta = None
tente:
resposta = requests.post(
f"https://api.brightdata.com/conjuntos_de_dados/v3/scrape?dataset_id={model.dataset_id}¬ify=false&include_errors=true",
headers=headers,
data=data,
timeout=POST_TIMEOUT
)
resposta.raise_for_status()
carga = resposta.json()
snapshot_id = carga["snapshot_id"]
retornar snapshot_id
exceto (ValueError, KeyError, TypeError, requests.RequestException) como e:
imprimir(f"falha ao acionar {model.name} snapshot: {e}")
tentativas -= 1
if response is not None and response.status_code >= 400:
print(f"Status: {response.status_code}")
print(response.text)
print("retries exceeded")
returncollect_snapshot()
Depois de obtermos nosso snapshot_id, verificamos a cada minuto se ele está pronto. A API retorna o código de status 202 se a coleta estiver em andamento. Quando o snapshot está pronto, ela retorna um 200. Quando recebemos qualquer outro código de status, lançamos um erro e entramos na lógica de repetição. Se as tentativas forem excedidas, saímos do método.
def collect_snapshot(self, model: AIModel, snapshot_id: str):
url = f"https://api.brightdata.com/conjuntos_de_dados/v3/snapshot/{snapshot_id}"
ready = False
llm_response = None
print(f"Aguardando {model.name} snapshot {snapshot_id}")
max_errors = 3
enquanto não estiver pronto e max_errors > 0:
headers = {"Authorization": f"Bearer {self.api_token}"}
tente:
response = requests.get(url, headers=headers, timeout=GET_TIMEOUT)
exceto requests.RequestException como e:
max_errors -= 1
imprimir(f"{model.name}: erro de pesquisa ({e})")
continuar
se response.status_code == 200:
imprimir(f"{model.name} instantâneo {snapshot_id} está pronto!")
pronto = True
llm_response = response.json()
retornar llm_response
elif response.status_code == 202:
sleep(60)
else:
max_errors-=1
imprimir("Erro ao se comunicar com o servidor")
imprimir(f"Erros máximos excedidos, instantâneo {snapshot_id} não pôde ser coletado")
retornarwrite_model_output()
Este é muito simples. Nós apenas o usamos para armazenar as saídas do nosso modelo. os.makedirs(OUTPUT_FOLDER, exist_ok=True) é usado para garantir que temos uma pasta de saídas. Em seguida, gravamos o arquivo na pasta de saídas e usamos model.name para nomear o arquivo.
def write_model_output(self, model: AIModel, llm_response: dict):
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
path = os.path.join(OUTPUT_FOLDER, f"{model.name}-output.json")
with open(path, "w", encoding="utf-8") as file:
json.dump(llm_response, file, indent=4, ensure_ascii=False)
print(f"Concluída a geração do relatório de {model.name} → {path}") Escrevendo um arquivo principal
Agora, vamos escrever um arquivo principal. Podemos usá-lo para executar os processos de back-end sem carregar a interface do usuário. run_one() nos permite executar o processo em um único modelo. Dentro de main(), usamos ThreadPoolExecutor() para executar essa função em várias threads simultaneamente. Em vez de realizar uma coleta por vez, podemos realizar uma coleta por thread para acelerar drasticamente nossos resultados.
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
MAX_WORKERS = 5
def run_one(model, retriever, prompt):
retriever.get_model_response(model, prompt)
return model.name
def main():
load_dotenv()
api_token = os.environ["BRIGHTDATA_API_TOKEN"]
prompt = "Por que o céu é azul?"
models = [chatgpt, perplexity, gemini, grok, copilot]
retriever = AIModelRetriever(api_token=api_token)
falhas = 0
com ThreadPoolExecutor(max_workers=min(MAX_WORKERS, len(modelos))) como pool:
futuros = {pool.submit(run_one, m, retriever, prompt): m para m em modelos}
para fut em as_completed(futuros):
modelo = futuros[fut]
tente:
name = fut.result()
print(f"{name}: concluído")
except Exception as e:
failures += 1
print(f"{model.name}: falha ({e})")
if failures == len(models):
raise SystemExit(1)
if __name__ == "__main__":
main()Você pode executar o arquivo principal usando o comando abaixo.
python main.pyA interface do usuário do Streamlit
A interface do usuário do Streamlit é muito semelhante ao nosso arquivo principal em termos de conceito. Ainda usamos várias threads para executar cada coleção. Nossas funções write_output() e sanitize_filename() são usadas apenas para nomes de arquivos mais limpos. Em vez de imprimir no terminal, criamos variáveis com o Streamlit para iniciar e exibir o aplicativo no seu navegador local.
Escrevendo a interface do usuário
import os
import json
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
import streamlit as st
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
OUTPUT_DIR = Path("output")
MAX_WORKERS = 5
def sanitize_filename(name: str) -> str:
return re.sub(r"[^A-Za-z0-9._-]+", "_", name).strip("_")
def write_output(model_name: str, payload: dict) -> Path:
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
path = OUTPUT_DIR / f"{sanitize_filename(model_name)}-output.json"
path.write_text(json.dumps(payload, indent=4, ensure_ascii=False), encoding="utf-8")
retornar caminho
def main():
st.set_page_config(page_title="Universal LLM Scraper", layout="wide")
st.title("Universal LLM Scraper")
load_dotenv()
api_token = os.getenv("BRIGHTDATA_API_TOKEN")
if not api_token:
st.error("Falta BRIGHTDATA_API_TOKEN. Adicione-o a um arquivo .env na raiz do projeto.")
st.stop()
models = [chatgpt, perplexity, gemini, grok, copilot]
model_names = [m.name for m in models]
model_by_name = {m.name: m for m in models}
with st.sidebar:
st.header("Configurações de execução")
prompt = st.text_area("Prompt", value="Quais são os melhores provedores de Proxy residencial?", height=120)
target_phrase = st.text_input("Frase-alvo a rastrear", value="Bright Data")
selected = st.multiselect("Modelos", options=model_names, default=model_names)
country = st.text_input("País (opcional)", value="")
save_to_disk = st.checkbox("Salvar resultados na saída/", value=True)
redact_terms = st.text_area("Termos da marca a ocultar (um por linha)", value="")
redact_mode = st.selectbox("Modo ocultar", ["Máscara", "Remover"], index=0)
run_clicked = st.button("Executar scrapes", type="primary", use_container_width=True)
if "results" not in st.session_state:
st.session_state.results = {} # model_name -> payload
if "errors" not in st.session_state:
st.session_state.errors = {} # nome_do_modelo -> str de erro
if "paths" not in st.session_state:
st.session_state.paths = {} # nome_do_modelo -> caminho salvo
def aplicar_redação(texto: str) -> str:
termos = [t.strip() for t in redact_terms.splitlines() if t.strip()]
if not termos:
retorne texto
padrão = re.compile(r"(" + "|".join(map(re.escape, termos)) + r")", flags=re.IGNORECASE)
if modo_redação == "Máscara":
retorne padrão.sub("███", texto)
retornar padrão.sub("", texto)
def extrair_texto_resposta(carga: dict) -> str | Nenhum:
se não for instância(carga, dict):
retornar Nenhum
se for instância(carga.get("texto_resposta"), str):
retornar carga["texto_resposta"]
if "data" in payload and isinstance(payload["data"], list) and payload["data"]:
first = payload["data"][0]
if isinstance(first, dict) and isinstance(first.get("answer_text"), str):
return first["answer_text"]
return None
def mentions_target(payload: dict) -> bool:
if not target_phrase:
return False
answer = extract_answer_text(payload)
if isinstance(answer, str):
return target_phrase.lower() in answer.lower()
# Fallback: se não conseguirmos encontrar answer_text, basta pesquisar a carga serializada
try:
blob = json.dumps(payload, ensure_ascii=False)
retorne target_phrase.lower() em blob.lower()
exceto Exception:
retorne False
# Layout: status + resultados
status_col, results_col = st.columns([1, 2], gap="large")
com status_col:
st.subheader("Status")
se run_clicked:
st.session_state.results = {}
st.session_state.errors = {}
st.session_state.paths = {}
se não estiver selecionado:
st.warning("Selecione pelo menos um modelo.")
st.stop()
retriever = AIModelRetriever(api_token=api_token)
status_boxes = {name: st.empty() for name in selected}
progress = st.progress(0)
done = 0
total = len(selected)
def run_one(model_name: str):
model = model_by_name[model_name]
payload = retriever.run(model, prompt, country=country)
return model_name, payload
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, total)) as pool:
futures = [pool.submit(run_one, name) for name in selected]
para fut em as_completed(futuros):
tente:
nome_do_modelo, carga = fut.result()
st.session_state.results[nome_do_modelo] = carga
status_boxes[nome_do_modelo].success(f"{nome_do_modelo}: concluído")
se salvar_em_disco:
caminho = write_output(nome_do_modelo, carga)
st.session_state.paths[model_name] = str(path)
except Exception as e:
err = str(e)
st.session_state.errors[f"job-{done+1}"] = err
st.error(err)
done += 1
progress.progress(done / total)
st.success("Execução concluída.")
# Mostrar arquivos salvos (se houver)
if st.session_state.paths:
st.caption("Arquivos salvos")
for k, v in st.session_state.paths.items():
st.write(f"- {k}: {v}")
if st.session_state.errors:
st.caption("Erros")
for k, v in st.session_state.errors.items():
st.write(f"- {k}: {v}")
with results_col:
st.subheader("Resultados")
if not st.session_state.results:
st.info("Clique em 'Executar scrapes' para coletar os resultados.")
st.stop()
tabs = st.tabs(list(st.session_state.results.keys()))
para tab, model_name em zip(tabs, st.session_state.results.keys()):
payload = st.session_state.results[model_name]
com tab:
texto_da_resposta = extrair_texto_da_resposta(carga)
mencionado = menções_alvo(carga)
st.markdown(f"**Frase alvo mencionada:** {'✅' se mencionada, caso contrário '❌'}")
se texto_da_resposta e isinstance(texto_da_resposta, str):
st.markdown("### Resposta")
st.text_area(
label="",
value=apply_redaction(answer_text),
height=260
)
else:
st.markdown("### JSON bruto")
st.json(payload)
if __name__ == "__main__":
main()Sim, app.py é mais longo que nosso arquivo principal. No entanto, existem apenas algumas diferenças importantes em relação ao main.py.
- Gerenciamento de estado: usando o Streamlit, armazenamos nossos resultados, erros e caminhos de arquivos em
st.session_state. Isso nos permite recuperá-los e exibi-los na interface do usuário. - Orquestração: em vez de codificar nossos prompts e coleções de modelos, eles são coletados e acionados a partir da interface do usuário.
- Inspeção de texto: inspecionamos nosso texto de resposta para ver se ele contém a frase alvo. Se a frase alvo estiver presente, exibimos um ✅. Se não estiver, exibimos um ❌.
Usando a interface do usuário
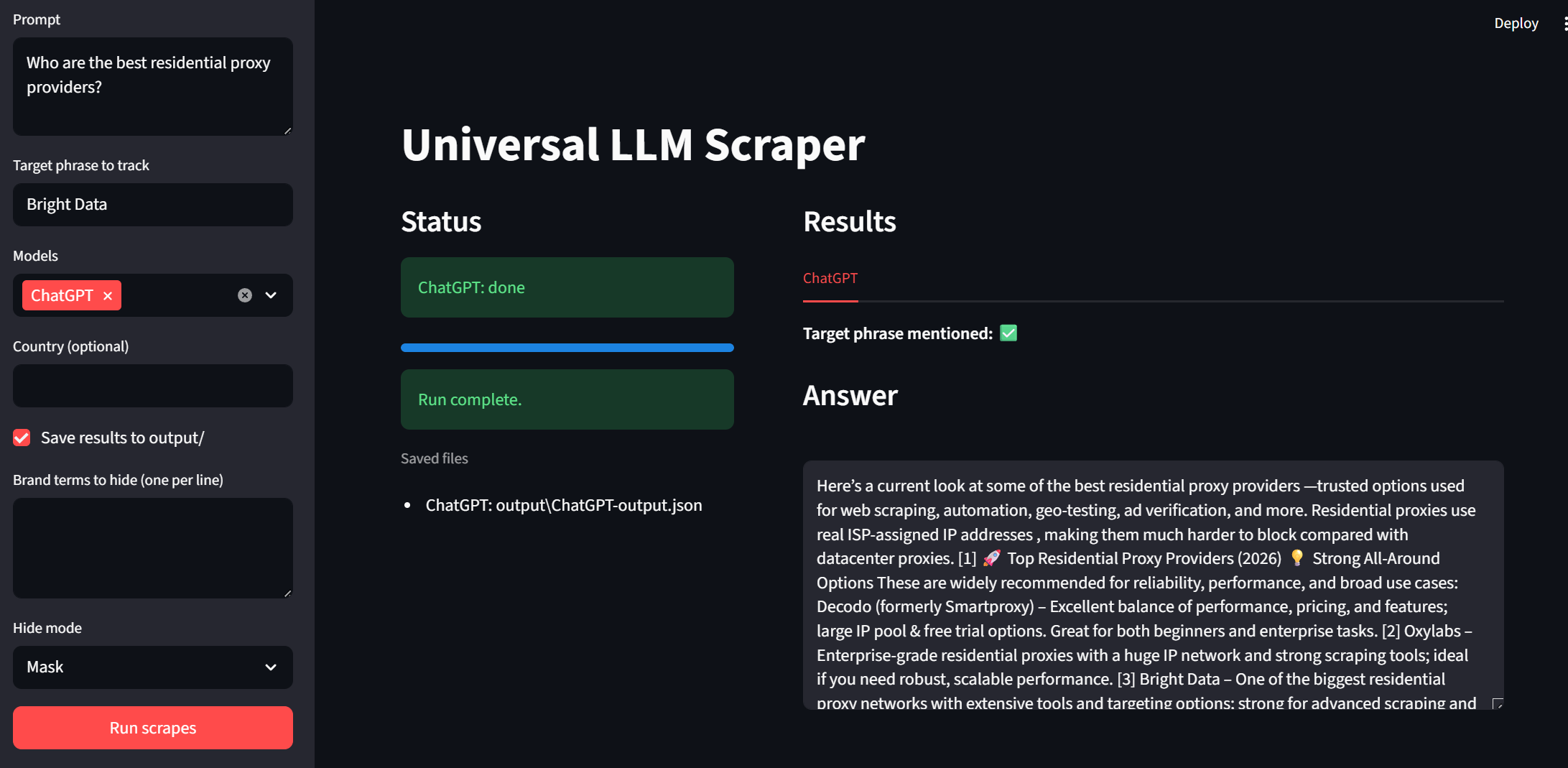
Agora, é hora de testar nossa interface do usuário. Você pode executar o aplicativo com o trecho abaixo.
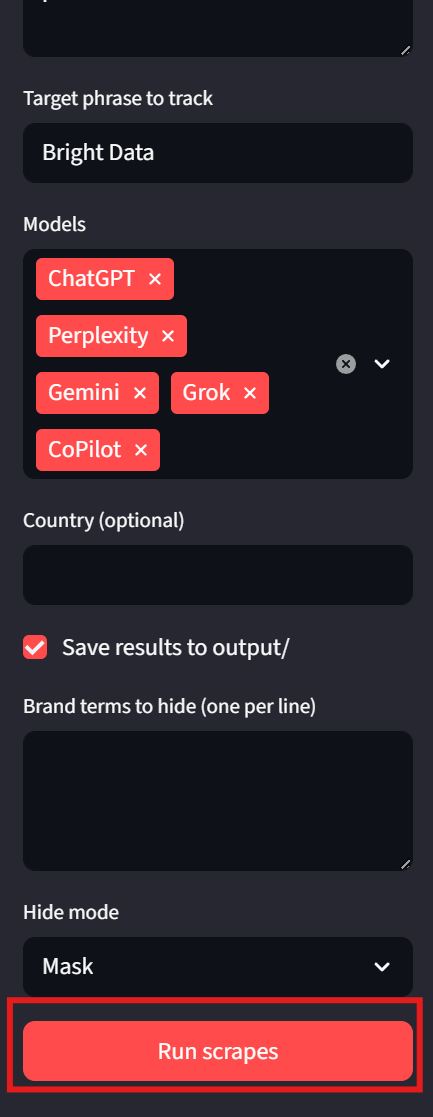
streamlit run app.pyDê uma olhada na barra lateral. Podemos inserir prompts e frases-alvo. Agora, os modelos podem ser selecionados usando um menu suspenso. “País” e “Salvar saída” são ajustes opcionais do lado do usuário. Para executar o programa, basta clicar no botão “Executar scrapes” na parte inferior.
Os resultados
Cada modelo aparece como uma guia própria nos resultados. Dessa forma, podemos revisar rapidamente os resultados. Nas imagens abaixo, a Bright Data recebeu uma marca de seleção verde para cada saída do modelo. Exemplo:
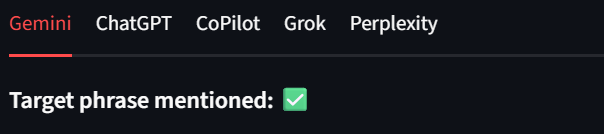
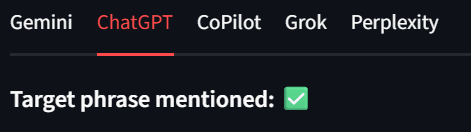
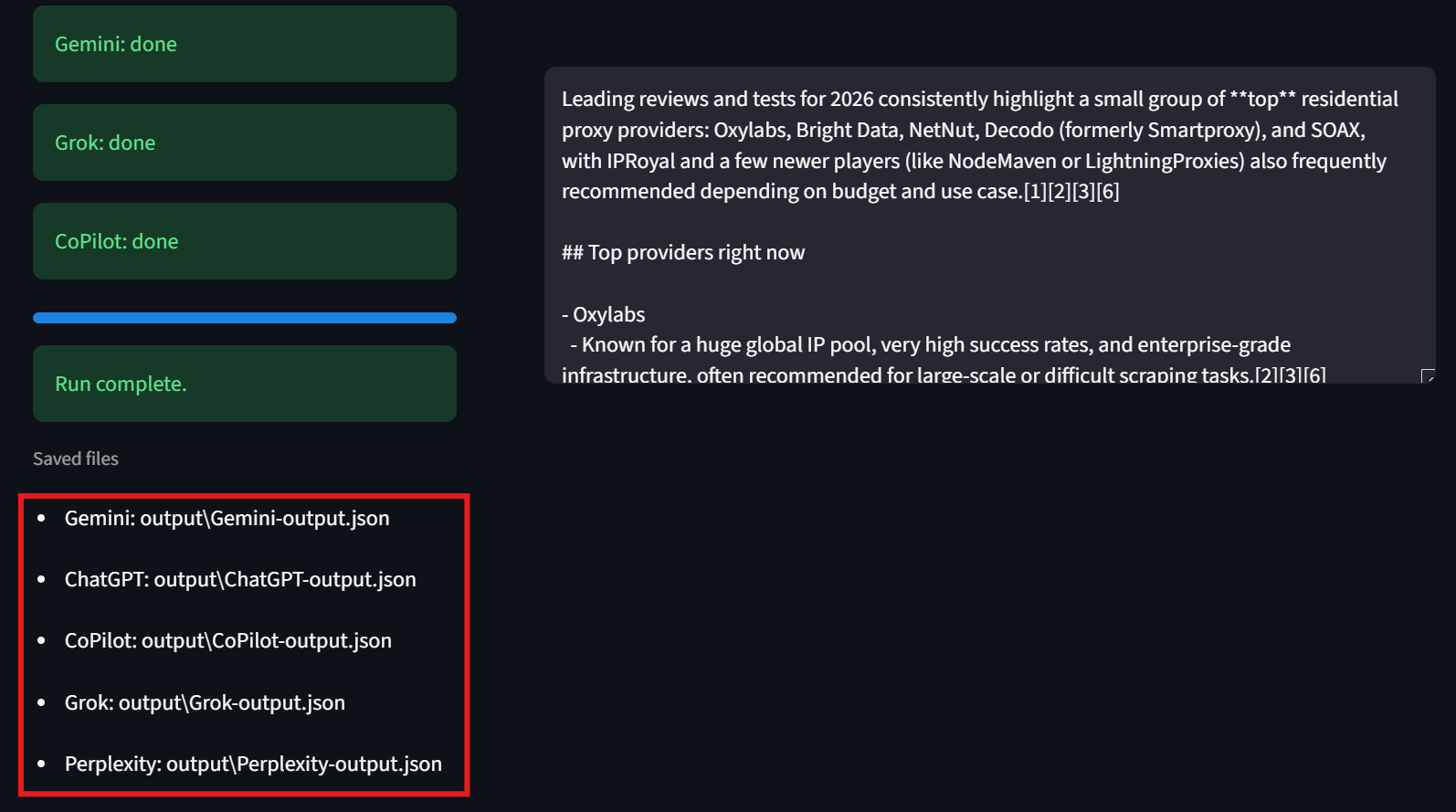
Os usuários também devem observar o canto inferior esquerdo da interface. Aqui, a interface do usuário exibe o caminho para cada um dos arquivos de resultados. Isso facilita a inspeção dos resultados brutos.
Levando para o próximo nível
Primeiro, precisamos de uma conta Supabase. Você pode acessar supabase.com e seguir as instruções. A Supabase oferece uma variedade de planos de preços para atender às suas necessidades. Para este projeto, o plano gratuito será suficiente. No entanto, à medida que seu banco de dados crescer, talvez seja necessário fazer um upgrade.
Você precisará de uma chave API. Depois de concluir a configuração da sua conta e do projeto, clique em Configurações do projeto na barra lateral. Vá para a guia Chaves API para recuperar sua chave API.
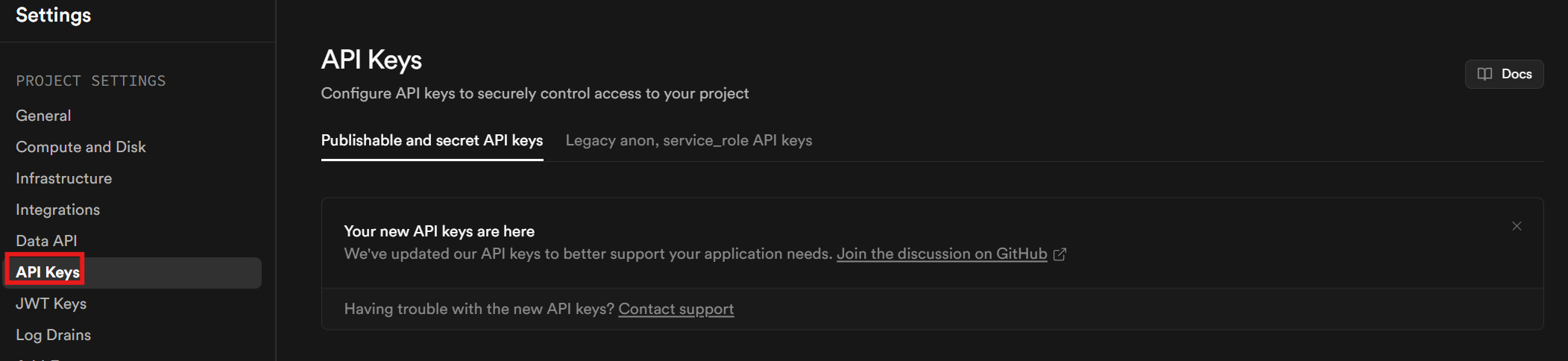
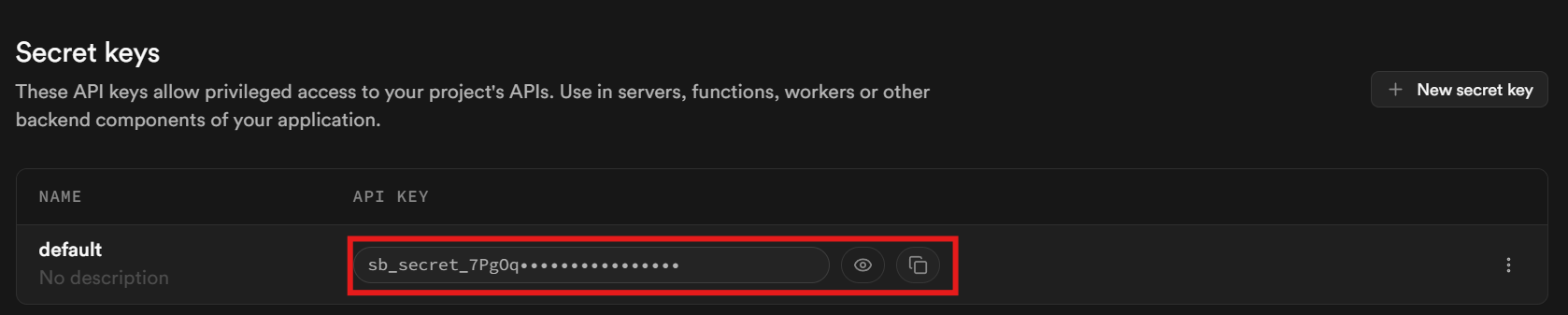
Role até a parte inferior da página. Sua chave está localizada na seção chamada “Chaves secretas”.
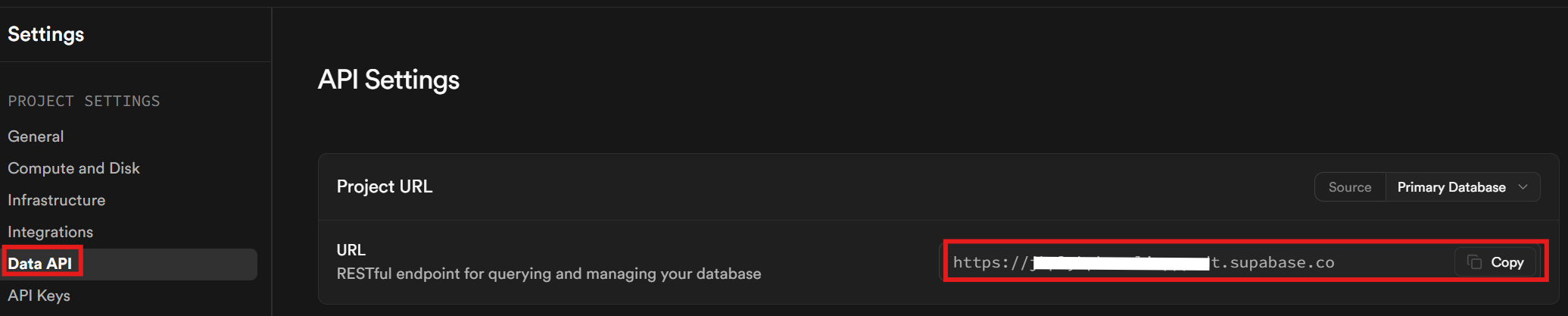
Por fim, na guia API de dados, recupere sua URL do Supabase. Essa é a URL que você usa para se comunicar com seu banco de dados.
Depois de obtermos nossas chaves, precisamos atualizar nosso arquivo de ambiente e nosso arquivo de requisitos. Seu novo arquivo de ambiente deve ficar assim.
BRIGHTDATA_API_TOKEN=<SUA-chave-API-bright-data>
SUPABASE_URL=<SUA-url-projeto-supabase>
SUPABASE_API_TOKEN=<SUA-chave-API-supabase>Nosso arquivo de requisitos agora tem a seguinte aparência.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0
supabase==2.27.2Criando as tabelas
Agora, precisamos criar nossas tabelas dentro do banco de dados. Usando a barra lateral, abra o editor SQL.
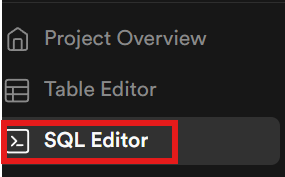
Execuções LLM
Cole o seguinte código SQL em um script e execute-o. Isso cria uma tabela chamada llm_runs. Cada vez que executarmos uma coleção, depositaremos os resultados aqui.
create table public.llm_runs (
id bigint gerado por padrão como identidade chave primária,
created_at_ts bigint não nulo, -- segundos unix
model_name texto não nulo,
prompt texto não nulo,
country texto nulo,
target_phrase texto nulo,
mentioned booleano não nulo padrão falso,
payload jsonb não nulo
);
criar índice se não existir llm_runs_created_at_ts_idx
em public.llm_runs (created_at_ts);
criar índice se não existir llm_runs_model_idx
em public.llm_runs (model_name);
criar índice se não existir llm_runs_target_idx
em public.llm_runs (target_phrase);Prompts
Também precisamos da capacidade de salvar prompts. O código abaixo cria uma tabela de prompts.
criar tabela public.prompts (
id bigint gerado por padrão como chave primária de identidade,
created_at_ts bigint não nulo,
texto do prompt não nulo,
is_active booleano não nulo padrão verdadeiro
);
criar índice se não existir prompts_created_at_ts_idx
em public.prompts (created_at_ts desc);
criar índice se não existir prompts_active_idx
em public.prompts (is_active);Agendamentos
Por fim, precisamos de uma tabela para armazenar as tarefas agendadas.
criar tabela public.schedules (
id bigint gerado por padrão como chave primária de identidade,
nome texto não nulo,
is_enabled booleano não nulo padrão verdadeiro,
next_run_ts bigint não nulo,
last_run_ts bigint nulo,
modelos jsonb não nulo padrão '[]'::jsonb,
country text null,
target_phrase text null,
only_active_prompts boolean not null default true,
locked_until_ts bigint null,
lock_owner text null,
repeat_every_seconds bigint not null default 86400
);
criar índice se não existir schedules_due_idx
em public.schedules (is_enabled, next_run_ts);
criar índice se não existir schedules_lock_idx
em public.schedules (locked_until_ts);Arquitetura atualizada
A base de código final agora é grande o suficiente para não caber mais em um tutorial. Em vez de despejar todos os arquivos aqui, vamos revisar alguns dos pontos principais por trás da conexão com o banco de dados, o executor headless e a interface do usuário Streamlit.
Interações com o banco de dados
Temos vários auxiliares de banco de dados, mas tudo se baseia principalmente na leitura e criação dentro do banco de dados. O código abaixo nos permite conectar-nos a todo o banco de dados.
def get_db() -> Cliente:
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_API_TOKEN") # mantenha a consistência com seu .env
if not url or not key:
raise RuntimeError("Missing SUPABASE_URL or SUPABASE_API_TOKEN in environment.")
return create_client(url, key)Para interagir efetivamente com o banco de dados, chamamos métodos adicionais além do get_db(). No próximo trecho, get_db() recupera o banco de dados. Em seguida, usamos db.table("llm_runs").insert(row).execute() para inserir novas linhas em nossa tabela llm_runs. Os prompts e auxiliares de programação seguem essa mesma lógica básica.
def save_run(
*,
model_name: str,
prompt: str,
country: str,
target_phrase: str,
mentioned: bool,
payload: dict,)
-> dict:
db = get_db()
row = {
"created_at_ts": int(time.time()),
"model_name": model_name,
"prompt": prompt,
"country": country or None,
"target_phrase": target_phrase or None,
"mentioned": bool(mentioned),
"payload": payload, # JSONB
}
res = db.table("llm_runs").insert(row).execute()
if not getattr(res, "data", None):
row["payload"] = {"ERROR": "FAILED RUN"}
res = db.table("llm_runs").insert(row).execute()
raise RuntimeError(f"Insert failed: {res}")
return res.data[0]Executor sem interface
Após criar a interface do usuário Streamlit, renomeamos main.py para headless_runner.py, pois o escopo do projeto foi ampliado. Não há mais um programa principal, mas sim dois scripts que são executados simultaneamente.
persist_run() verifica se há uma carga útil vazia da API. Se a carga útil estiver vazia, retornamos False e imprimimos uma mensagem no terminal sobre a inserção com falha. Se a carga útil contiver informações, usamos save_run() para inserir os resultados no banco de dados.
def persist_run(*, model_name: str, prompt: str, payload, target_phrase: str, country: str = "") -> bool:
if payload is None:
print(f"{model_name}: ignorando inserção no banco de dados (payload é None).")
return False
# Se você quiser tratar listas/dicionários vazios como "não salvar", mantenha isto:
if payload == {} or payload == []:
print(f"{model_name}: ignorando inserção no banco de dados (payload vazio). type={type(payload).__name__}")
return False
tente:
json.dumps(payload, ensure_ascii=False)
exceto TypeError como e:
imprimir(f"{model_name}: carga útil não serializável em JSON ({e}). Stringificando.")
payload = {"raw": json.dumps(payload, default=str, ensure_ascii=False)}
mentioned = mentions_target(payload if isinstance(payload, dict) else {"data": payload}, target_phrase)
tente:
save_run(
model_name=model_name,
prompt=prompt,
country=country,
target_phrase=target_phrase,
mentioned=mentioned,
payload=payload,
)
exceto Exception como db_err:
print(f"{model_name}: falha na inserção no banco de dados: {db_err}")
retornar mentionedAntes de prosseguir, há outro elemento importante do nosso executor headless que você precisa observar. Temos várias variáveis de ambiente opcionais que você pode usar como ajustes de configuração. O tempo de execução real do nosso programa é mantido dentro de um loop while simples. Dentro do loop de tempo de execução, verificamos continuamente se há novos trabalhos na programação. Sempre que um trabalho programado está prestes a ser executado, ele chama run_schedule_once() para iniciar a execução.
# ajuste estes sem alterações no banco de dados
tick_every_seconds = int(os.getenv("SCHED_TICK_SECONDS", "15")) # frequência de ativação
lock_seconds = int(os.getenv("SCHED_LOCK_SECONDS", "1800")) # duração do bloqueio enquanto uma tarefa é executada
drain_all_due = os.getenv("SCHED_DRAIN_ALL_DUE", "1") == "1" # executar todas as tarefas vencidas a cada tick
save_to_disk = os.getenv("SCHED_SAVE_TO_DISK", "0") == "1"
while True:
now_ts = int(time.time())
ran_any = False
# reivindicar e executar uma programação ou esvaziar todas as programações vencidas
enquanto Verdadeiro:
tente:
vencido = reivindicar_programação_vencida(now_ts=now_ts, proprietário_bloqueio=proprietário_bloqueio, segundos_bloqueio=segundos_bloqueio)
exceto Exceção como e:
imprimir(f"Falha ao reivindicar programação vencida: {e}")
vencido = Nenhum
if not due:
break
ran_any = True
try:
run_schedule_once(
schedule_row=due,
retriever=retriever,
available_models=available_models,
model_by_name=model_by_name,
save_to_disk=save_to_disk,
)
exceto Exception como e:
# Se algo explodir no meio da execução, NÃO avançamos a programação.
# O bloqueio expirará e a programação será retomada mais tarde.
imprimir(f"Execução da programação travou: {e}")
if not drain_all_due:
break
# atualizar a hora para a próxima solicitação
now_ts = int(time.time())
if not ran_any:
# opcional: logs mais silenciosos
print(f"[{int(time.time())}] Nenhuma programação vencida.")
time.sleep(tick_every_seconds)Para iniciar o executor headless, basta abrir um novo terminal e executar python headless_runner.py.
O aplicativo Streamlit
Nosso aplicativo Streamlit cresceu enormemente. Você ainda pode invocá-lo usando streamlit run app.py Agora ele tem cinco guias separadas. A página original “Run Scrapes” ainda aparece imediatamente em nosso painel.
Na guia “Prompts”, os usuários podem criar novos prompts e, opcionalmente, salvá-los para uso posterior. Na parte inferior desta página, os usuários podem configurar e executar execuções em massa.
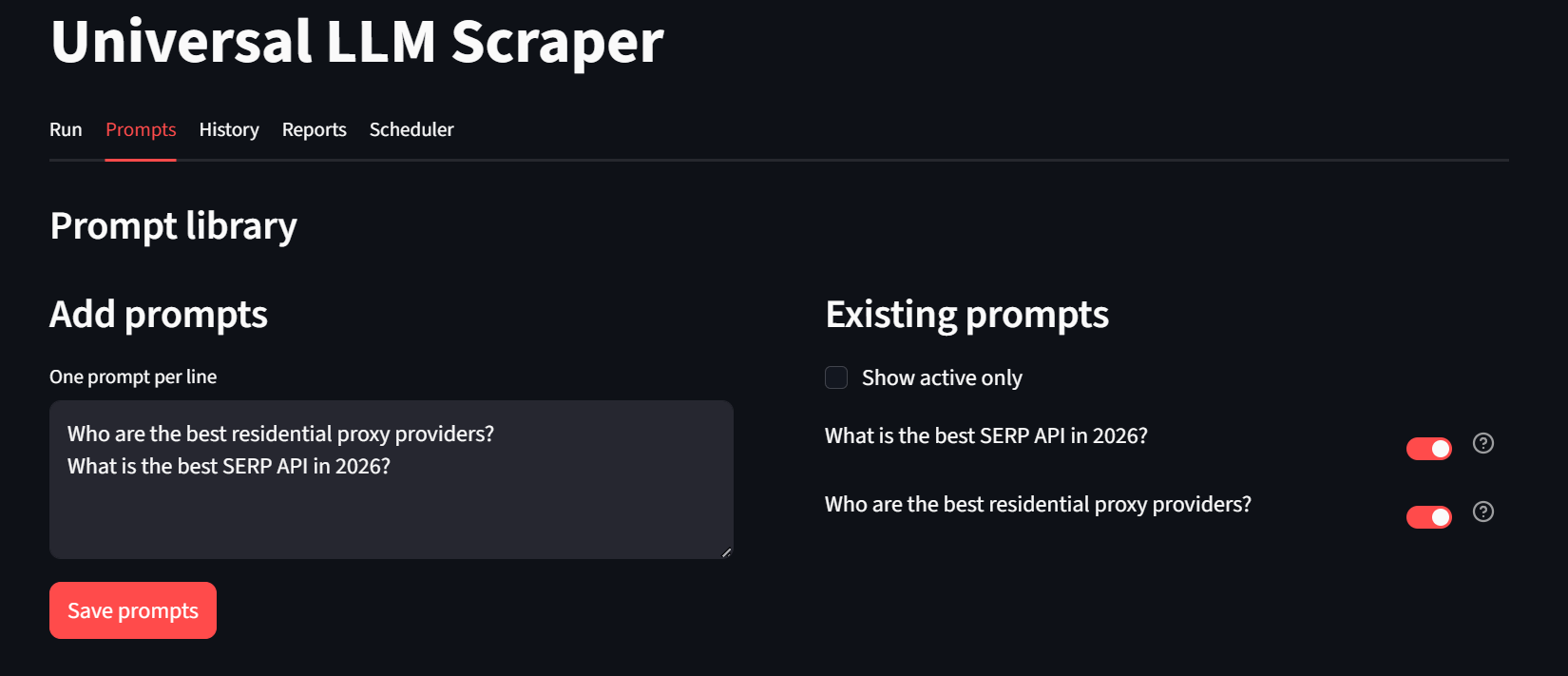
Usando a guia “History”, os usuários podem inspecionar o histórico detalhado de execuções. Na parte inferior desta página, os usuários também têm a opção de inspecionar cargas JSON brutas, se desejarem.
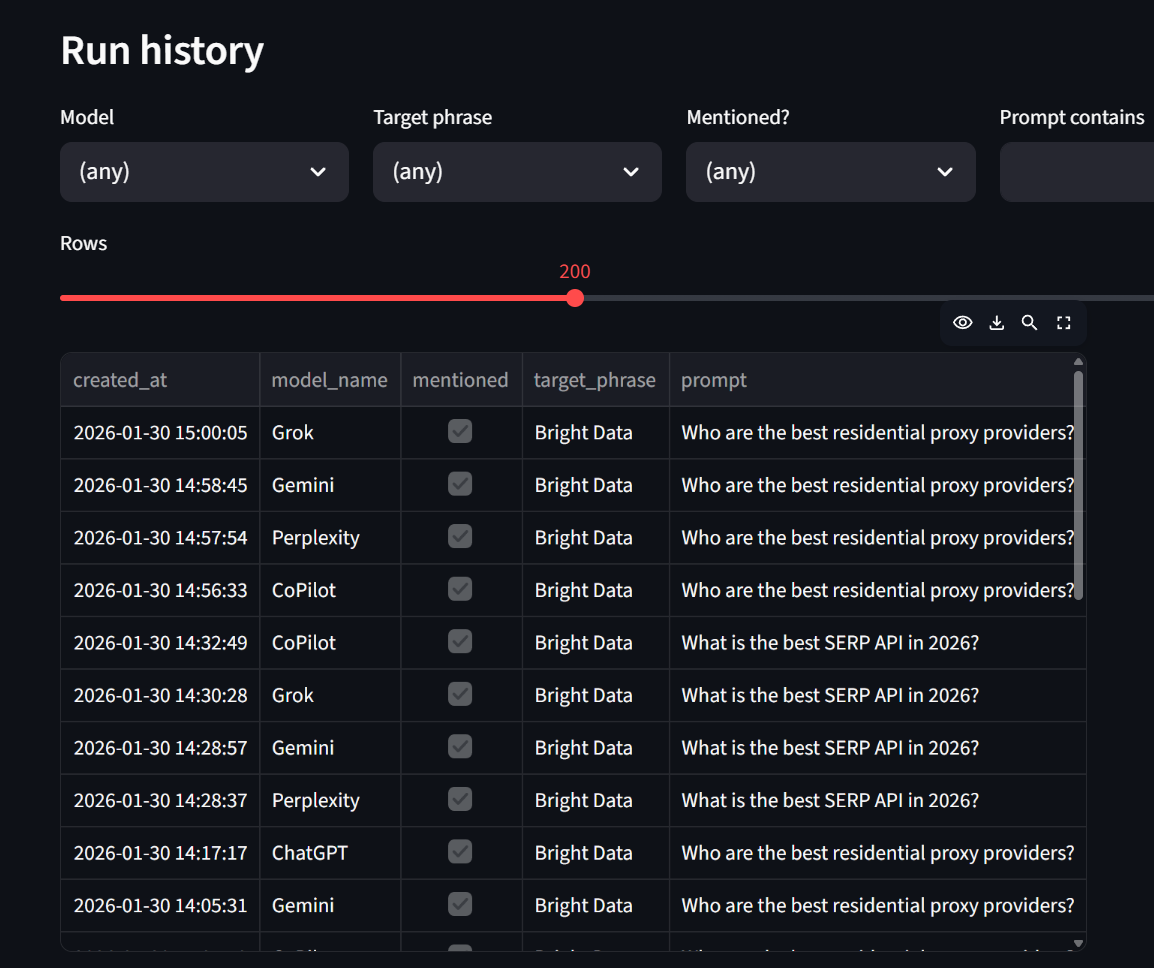
Nossa guia de relatórios permite que você veja as taxas de menção divididas por modelo. Como você pode ver, a Bright Data foi mencionada 100% das vezes por cada modelo aqui.
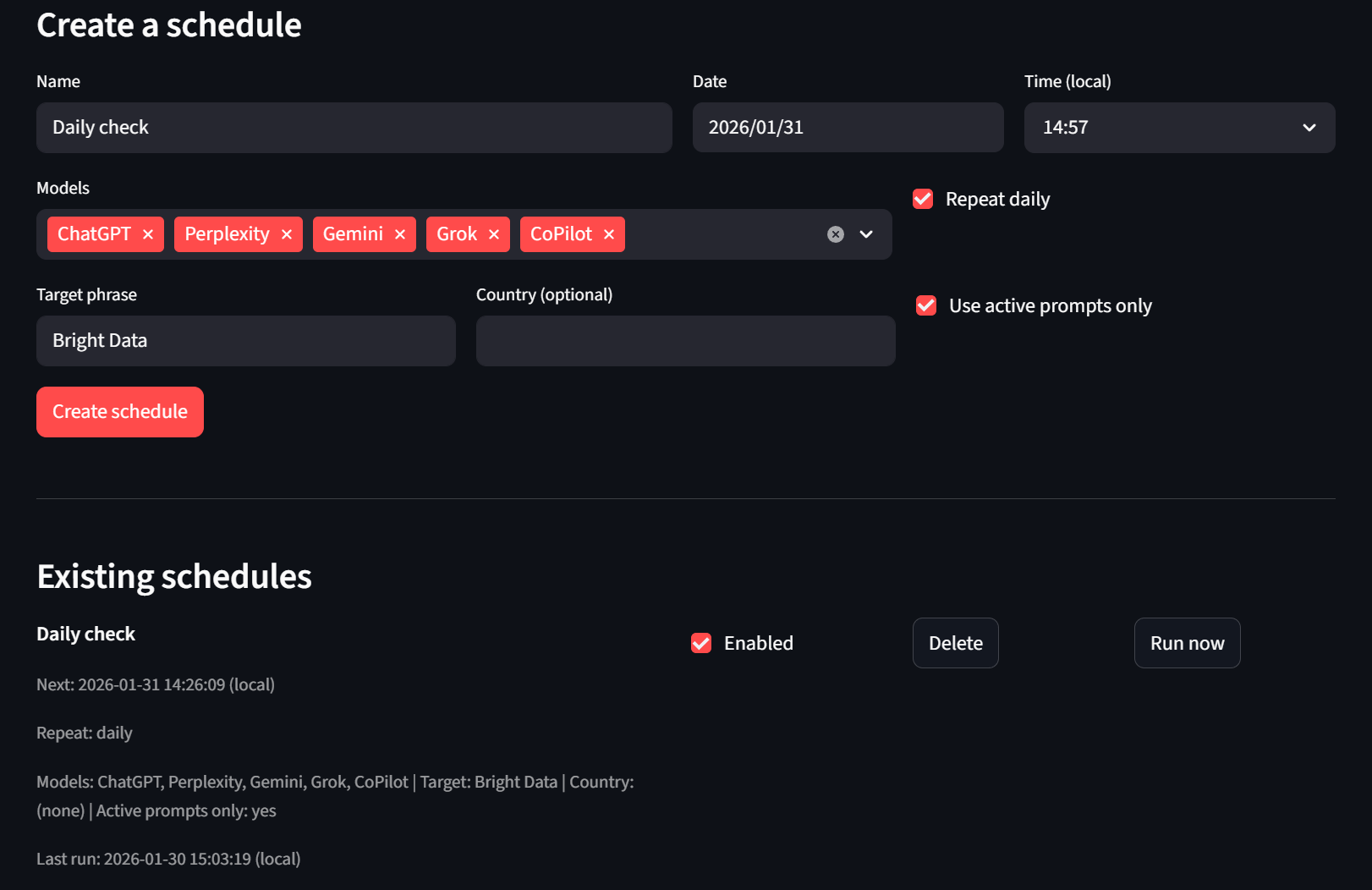
Por fim, temos a guia Agendador. Os usuários podem criar e excluir agendamentos. Se não quiserem esperar, também podem usar o botão “Executar agora” e o executor headless irá capturá-lo no próximo tick.
Conclusão
Se você construiu o protótipo no início deste artigo, já compreende os conceitos necessários para levar ferramentas como esta para a próxima fase.
A arquitetura demonstrada neste guia pode oferecer suporte a:
- Memória persistente e rastreamento histórico: armazene resultados ao longo do tempo para detectar tendências em como os modelos de IA mencionam sua marca, rastreie mudanças na classificação e identifique concorrentes emergentes.
- Centenas de prompts monitorados diariamente: automatize coletas programadas em milhares de variações de palavras-chave, categorias de produtos e comparações com concorrentes.
- Relatórios e análises automatizados: gere relatórios mostrando taxas de menção à marca, análise de sentimento, frequência de citação e posicionamento competitivo em todos os principais LLMs.
- Sistemas de alerta: acione notificações quando sua marca sair das recomendações ou quando os concorrentes ganharem visibilidade.
- Monitoramento multirregional: acompanhe como as respostas da IA variam por região geográfica para informar estratégias de marketing localizadas.
Para equipes empresariais que gerenciam a reputação da marca em grande escala, a capacidade de responder “Minha empresa está sendo recomendada pela IA?” em todos os principais modelos, para todas as consultas relevantes, todos os dias, não é mais opcional. É uma infraestrutura essencial.
As APIs Web Scraper da Bright Data fornecem feeds de dados normalizados e confiáveis que tornam esse nível de monitoramento possível. Esteja você rastreando ChatGPT, Perplexity, Gemini, Grok ou Microsoft Copilot, o esquema unificado elimina o atrito da integração e permite que sua equipe se concentre em insights, em vez de lidar com dados.
Pronto para construir seu próprio sistema de monitoramento de visibilidade de IA? Comece um teste grátis e veja como a Bright Data pode impulsionar sua estratégia de SEO de última geração.





