

Nesta postagem do blog, você verá:
- O que é o AutoGPT e o que o torna especial como uma estrutura de criação de agentes de IA.
- Por que os agentes do AutoGPT se beneficiam do acesso a recursos de pesquisa na web, exploração, interação e extração de dados.
- Como a Bright Data pode ser integrada ao AutoGPT para fornecer exatamente esses recursos aos agentes de IA.
Vamos começar!
O que é o AutoGPT
O AutoGPT é uma plataforma de código aberto para criar, implantar e executar agentes de IA autônomos.
O que a destaca é sua interface baseada em blocos e de baixo código, a execução contínua de agentes e a capacidade de conectar ferramentas, APIs e fontes de dados em pipelines de automação de ponta a ponta.
Ao contrário de scripts simples, os agentes do AutoGPT podem ser executados de forma persistente, reagir a gatilhos e gerenciar tarefas com várias etapas. O projeto conta com o apoio de uma grande comunidade de código aberto. Ele alcançou uma popularidade impressionante no GitHub, com mais de 183 mil estrelas.
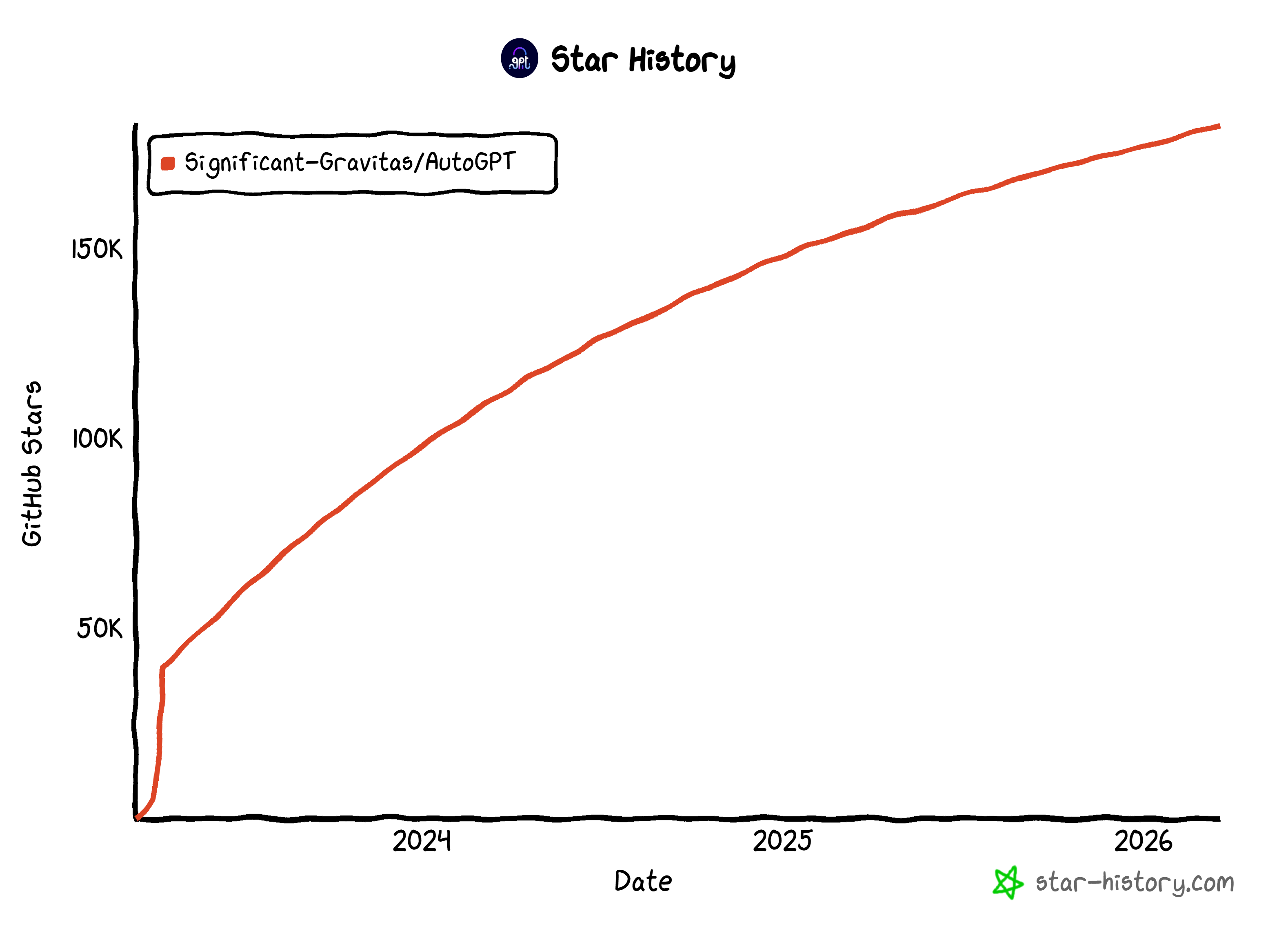
Essas estatísticas o tornam uma das estruturas de agentes de IA mais populares atualmente.
Por que integrar recursos de exploração da Web e recuperação de dados ao AutoGPT
Não há dúvida de que o AutoGPT é uma solução rica em recursos. No entanto, todos os agentes de IA baseados em LLM enfrentam limitações inerentes. Modelos de linguagem padrão são treinados em Conjuntos de dados estáticos, o que significa que seu conhecimento é fixado em um momento específico no tempo.
Isso pode resultar em informações desatualizadas, alucinações ou lacunas quando os agentes tentam realizar tarefas do mundo real que exigem dados atuais. Além disso, os LLMs não podem interagir com o mundo real, incluindo a web. Portanto, os agentes de IA básicos são limitados por essas restrições nativas.
O AutoGPT inclui ferramentas nativas para pesquisa na web, exploração e outras interações. No entanto, esses recursos integrados podem enfrentar dificuldades em termos de escala, confiabilidade e medidas sofisticadas contra bots, quando comparados a soluções de nível empresarial.
É aí que entra a Bright Data. Construída sobre uma das maiores redes de Proxies do mundo — com mais de 150 milhões de IPs em 195 países —, sua infraestrutura oferece 99,99% de tempo de atividade e simultaneidade ilimitada.
A integração da Bright Data ao AutoGPT permite que os agentes acessem conteúdo da web em tempo real, resultados de pesquisa e dados estruturados de qualquer site. Em detalhes, os principais produtos da Bright Data que podem aprimorar os fluxos de trabalho do AutoGPT incluem:
- Web Unlocker API: acesse o conteúdo de qualquer site em HTML bruto ou Markdown, contornando CAPTCHAs e proteções anti-bot.
- API SERP: Colete resultados de mecanismos de busca do Google, Bing, Yandex e muitos outros mecanismos de busca.
- Web Scraper APIs: Extraia dados estruturados de plataformas como Amazon, LinkedIn, Instagram e Yahoo Finance.
- API Crawl: Converta sites inteiros em Conjuntos de dados estruturados para processamento de IA posterior.
Ao combinar os recursos de agente do AutoGPT com as soluções da Bright Data, os agentes de IA podem recuperar informações em tempo real de forma autônoma e executar fluxos de trabalho complexos muito além das limitações dos LLMs padrão.
Como integrar a Bright Data ao AutoGPT: um guia passo a passo
Nesta seção guiada, você aprenderá a criar um agente de IA no AutoGPT que se integra ao Bright Data para recuperação de dados da web.
Especificamente, esse agente atuará como um assistente de favoritos, ajudando você a decidir se vale a pena salvar um artigo online para leitura posterior. Este é apenas um exemplo simples para demonstrar a integração, mas muitos outros casos de uso são possíveis.
Siga as instruções abaixo!
Pré-requisitos
Para hospedar o AutoGPT por conta própria, certifique-se de que seu sistema atenda aos seguintes requisitos de hardware:
- Sistema operacional: Linux (recomenda-se Ubuntu 20.04 ou mais recente), macOS (10.15 ou mais recente) ou Windows 10/11 com WSL2.
- CPU: recomenda-se 4 ou mais núcleos.
- RAM: Mínimo de 8 GB (recomenda-se 16 GB).
- Armazenamento: pelo menos 10 GB de espaço livre.
Você também deve ter estas ferramentas instaladas localmente em sua máquina:
- Docker Engine 20.10.0+
- Docker Compose 2.0.0+
- Git 2.30+
- Node.js 16.x+ (com npm 8.x+)
- Visual Studio Code 1.60+ ou qualquer editor de código moderno
Além disso, certifique-se de que os seguintes requisitos de rede sejam atendidos:
- Uma conexão estável à Internet.
- Acesso às portas necessárias (que serão configuradas via Docker).
- Capacidade de estabelecer conexões HTTPS de saída.
Para implementar o agente de IA no AutoGPT, você também precisará de:
- Uma conta Bright Data com uma zona de API do Web Unlocker configurada e uma chave de API definida.
- Uma chave de API de um dos provedores de LLM compatíveis com o AutoGPT (neste exemplo, usaremos o OpenAI).
Não se preocupe em configurar sua conta Bright Data ainda, pois você será orientado a fazê-lo em um capítulo dedicado.
Passo 1: Instale o AutoGPT localmente
Certifique-se de que seu sistema atenda aos pré-requisitos de hardware, software e rede. Além disso, verifique se o Docker está instalado e funcionando.
Para simplificar o processo de configuração para hospedar o AutoGPT por conta própria, a abordagem recomendada é usar o script oficial de instalação de uma linha. Isso instala todas as dependências necessárias, baixa o código mais recente e inicia o aplicativo para você.
No macOS ou Linux, execute o script de instalação de uma linha com:
curl -fsSL https://setup.agpt.co/install.sh -o install.sh && bash install.shDa mesma forma, no Windows, execute o seguinte comando no PowerShell:
powershell -c "iwr https://setup.agpt.co/install.bat -o install.bat; ./install.bat"O processo de instalação pode levar alguns minutos, então seja paciente. Quando terminar, você deverá ver uma saída semelhante à seguinte: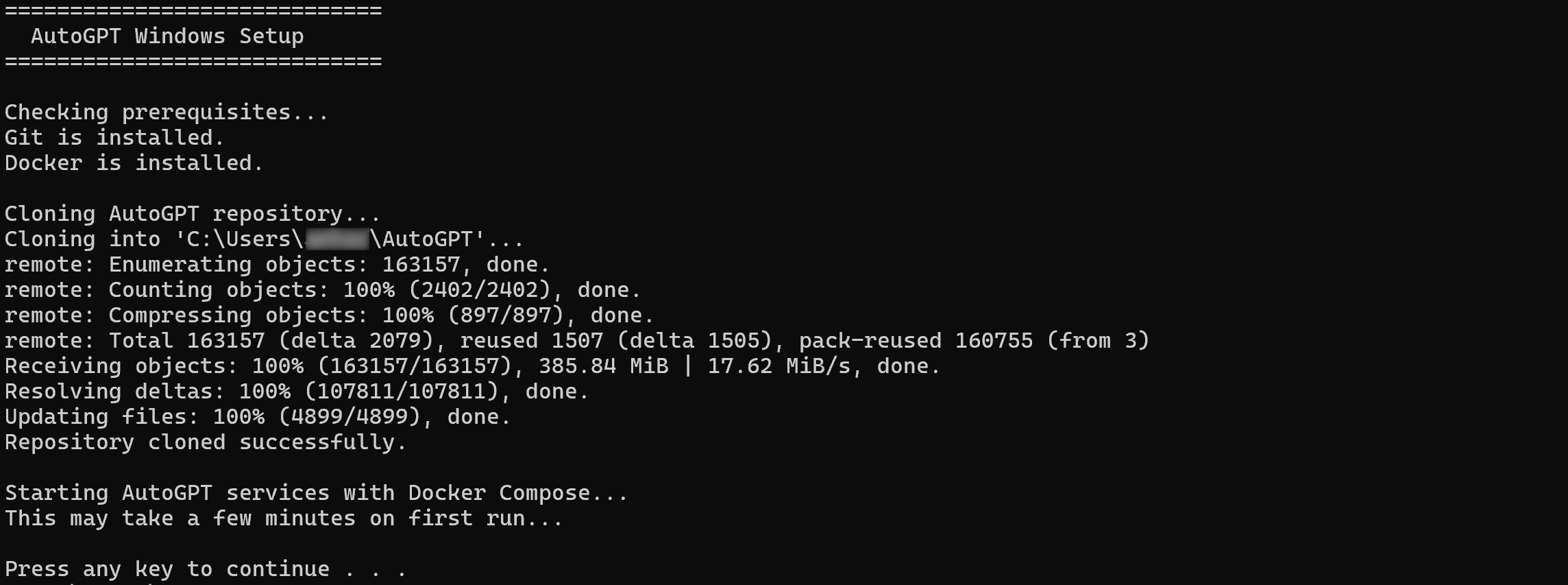
Ótimo! Neste ponto, o AutoGPT deve estar configurado com sucesso localmente e pronto para ser executado.
Passo 2: Inicie a plataforma
Navegue até a pasta de instalação:
cd AutoGPT/autogpt_platformEm seguida, copie o arquivo .env.default que vem com o repositório clonado para .env:
cp .env.default .envEste comando cria um arquivo .env no diretório autogpt_platform usando a configuração padrão. Modifique este arquivo para definir suas próprias variáveis de ambiente apenas se precisar de uma configuração personalizada. Caso contrário, mantenha os valores padrão.
Em seguida, inicie a plataforma AutoGPT com:
docker compose up -d --buildEste comando compila e inicia todos os serviços de back-end necessários definidos no arquivo docker-compose.yml no modo detached.
Assim que os serviços estiverem em funcionamento, verifique se tudo está funcionando acessando http://localhost no navegador.
Por padrão, os diferentes serviços do AutoGPT estão disponíveis em:
- Servidor de interface do usuário (front-end):
http://localhost. - Servidor WebSocket de back-end:
http://localhost:8001. - Servidor REST da API de execução:
http://localhost:8006.
Abaixo está o que você deve ver:
Inscreva-se criando sua conta. Após fazer login, você será direcionado ao Agent Builder no front-end do AutoGPT:
Ótimo! Agora você está pronto para criar seu primeiro agente e conectá-lo ao Bright Data.
Passo 3: Projete o fluxo de trabalho do agente de IA
O AutoGPT oferece vários blocos, cada um lidando com uma ação ou tarefa específica. Neste exemplo, você deseja construir um fluxo de trabalho de agente que:
- Aceite a URL de um artigo (de qualquer site) como entrada.
- Recupere o conteúdo do artigo em Markdown usando a API do Bright Data Web Unlocker.
- Envie o conteúdo para um LLM para gerar uma pontuação de 1 a 10 indicando o quão valioso o artigo é para ser marcado como favorito, bem como um comentário semelhante ao de um humano explicando a pontuação.
- Retorne a saída estruturada.

No AutoGPT, esse fluxo de trabalho pode ser implementado usando os seguintes blocos:
- Entrada do agente: Aceita a URL do artigo do usuário.
- Criar Dicionário: Cria o corpo da solicitação para a API do Bright Data Web Unlocker usando a URL fornecida.
- Enviar Solicitação Web Autenticada: Envia a solicitação para a API do Bright Data Web Unlocker e recupera o conteúdo do artigo.
- Gerador de Resposta Estruturada por IA: Passa o conteúdo do artigo para o LLM e gera uma avaliação estruturada do marcador (pontuação + comentário).
- Saída do agente: retorna o resultado estruturado final.
Perfeito! Agora que as etapas do fluxo de trabalho do agente estão claras, o próximo passo é implementá-lo. Mas primeiro, vamos começar com o Bright Data.
Etapa 4: Configure sua conta Bright Data
Conforme descrito anteriormente, o fluxo de trabalho do agente de IA que você deseja implementar depende do produto Web Unlocker da Bright Data. Para conectá-lo no AutoGPT, você precisa de uma conta Bright Data com a configuração da zona da API do Web Unlocker, além de uma chave de API.
Para obter orientações rápidas, consulte o artigo“Guia de Início Rápido paraa APIdo Web Unlocker da Bright Data”.Como alternativa, siga as etapas abaixo.
Se você não tiver uma conta na Bright Data, crie uma nova. Caso contrário, basta fazer login. Acesse o painel de controle e navegue até a página “Proxies & Scraping”. Dê uma olhada na tabela “My Zones”: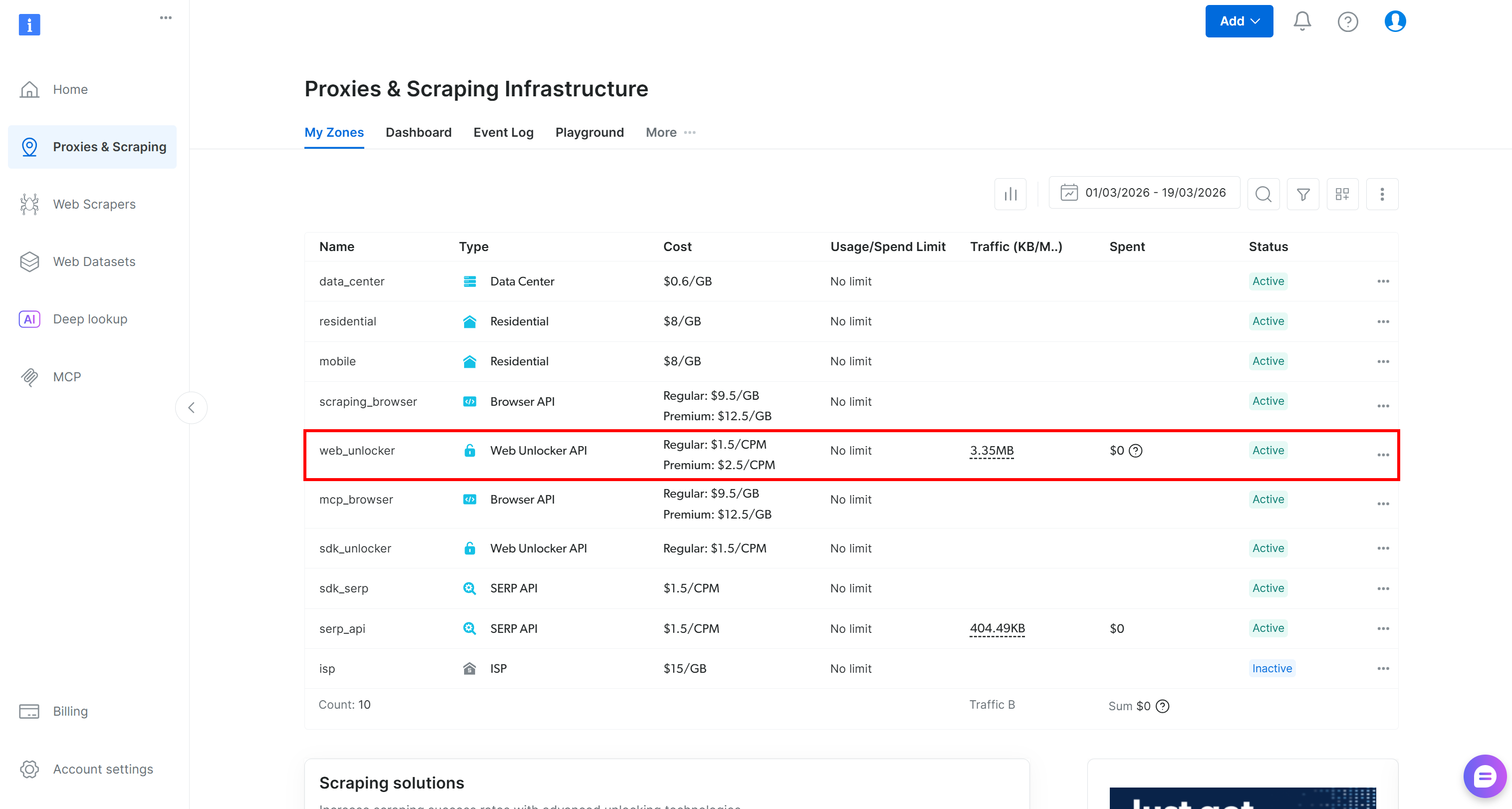
Se uma zona da API do Web Unlocker (por exemplo, web_unlocker) já existir na tabela, você está pronto para começar.
Se ela não estiver presente, você deve criar uma. Role até o cartão “API do Unblocker”, clique no botão “Criar zona” e siga o assistente.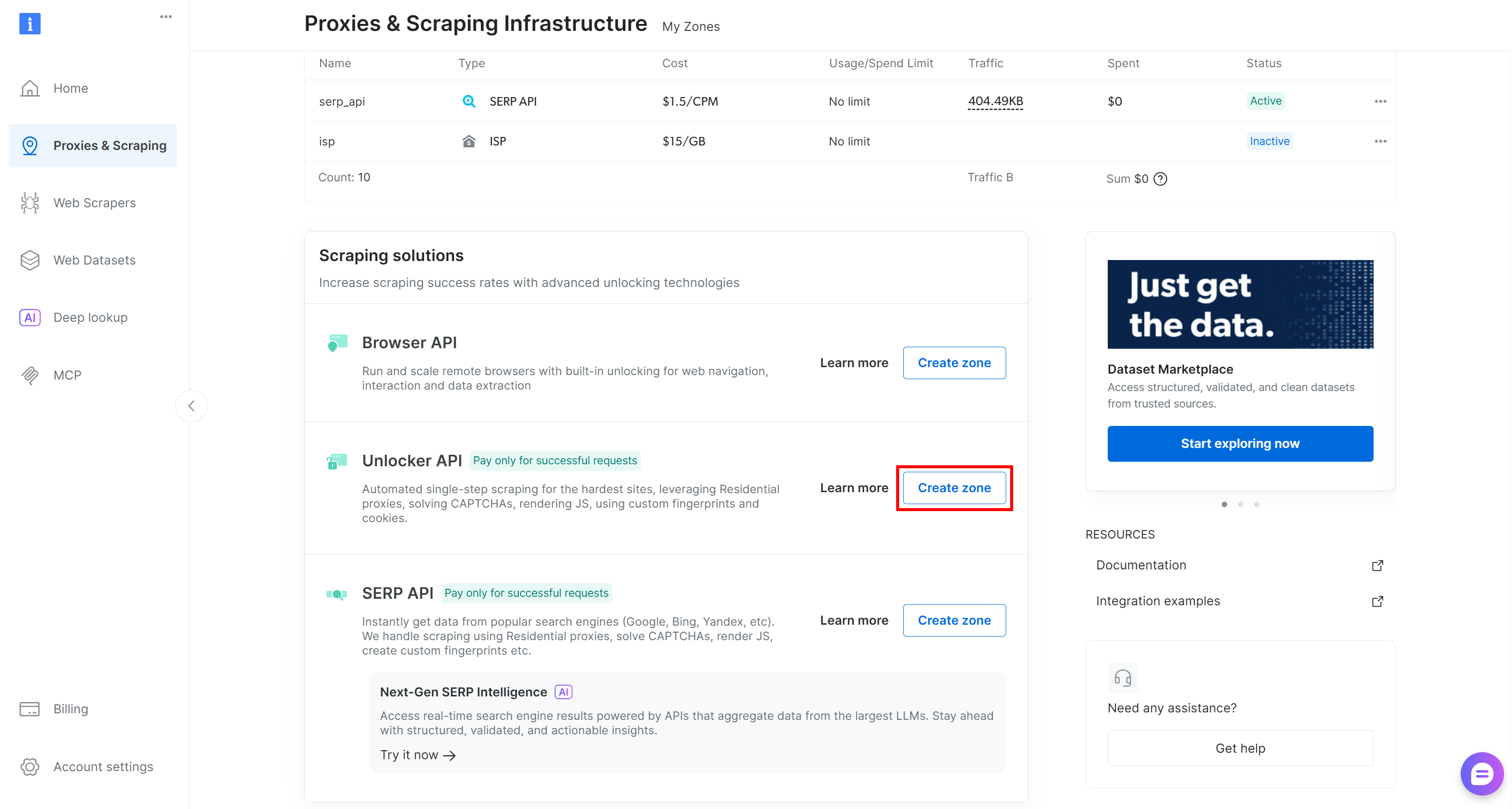
Dê um nome à sua zona com cuidado, pois você precisará dele mais tarde. Neste guia, vamos supor que a zona se chama web_unlocker.
Por fim, gere sua chave de API da Bright Data e guarde-a em local seguro. Você precisará dela para autenticar as solicitações HTTP feitas pelo AutoGPT à Bright Data.
É isso! Os pré-requisitos do Bright Data foram atendidos.
Passo 5: Inicialize o agente
Todo fluxo de trabalho do AutoGPT precisa de uma entrada e uma saída. Comece acessando a seção “Build” para abrir a página do Agent Builder:
Clique no botão “Save”, dê um nome ao seu agente, como “Bookmark Likelihood Evaluator”, e clique em “Save Agent”: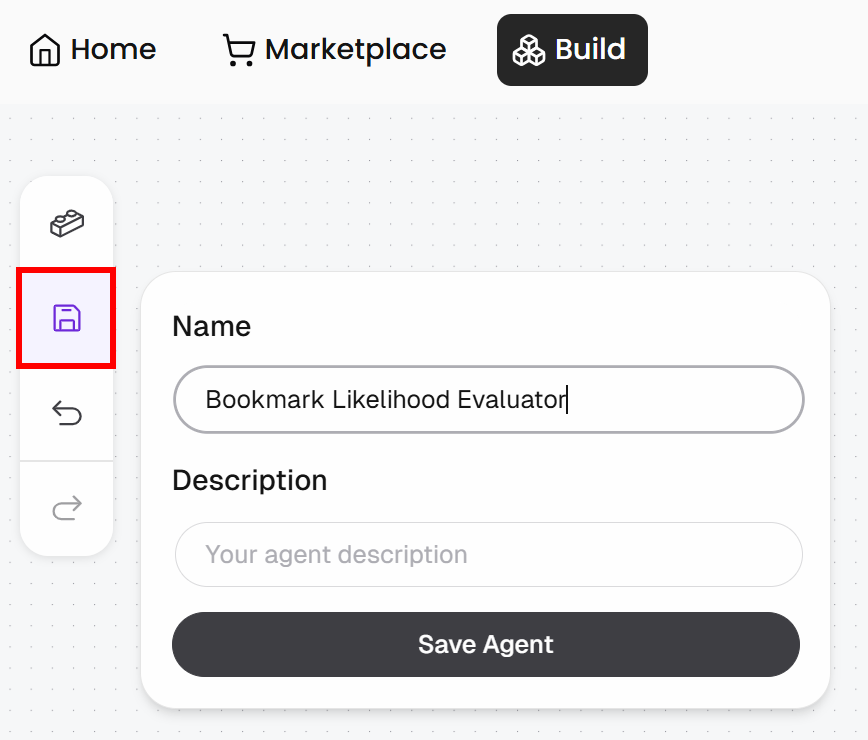
Na página do Agent Builder, pressione o botão “Blocks” à esquerda e adicione um bloco “Agent Input”: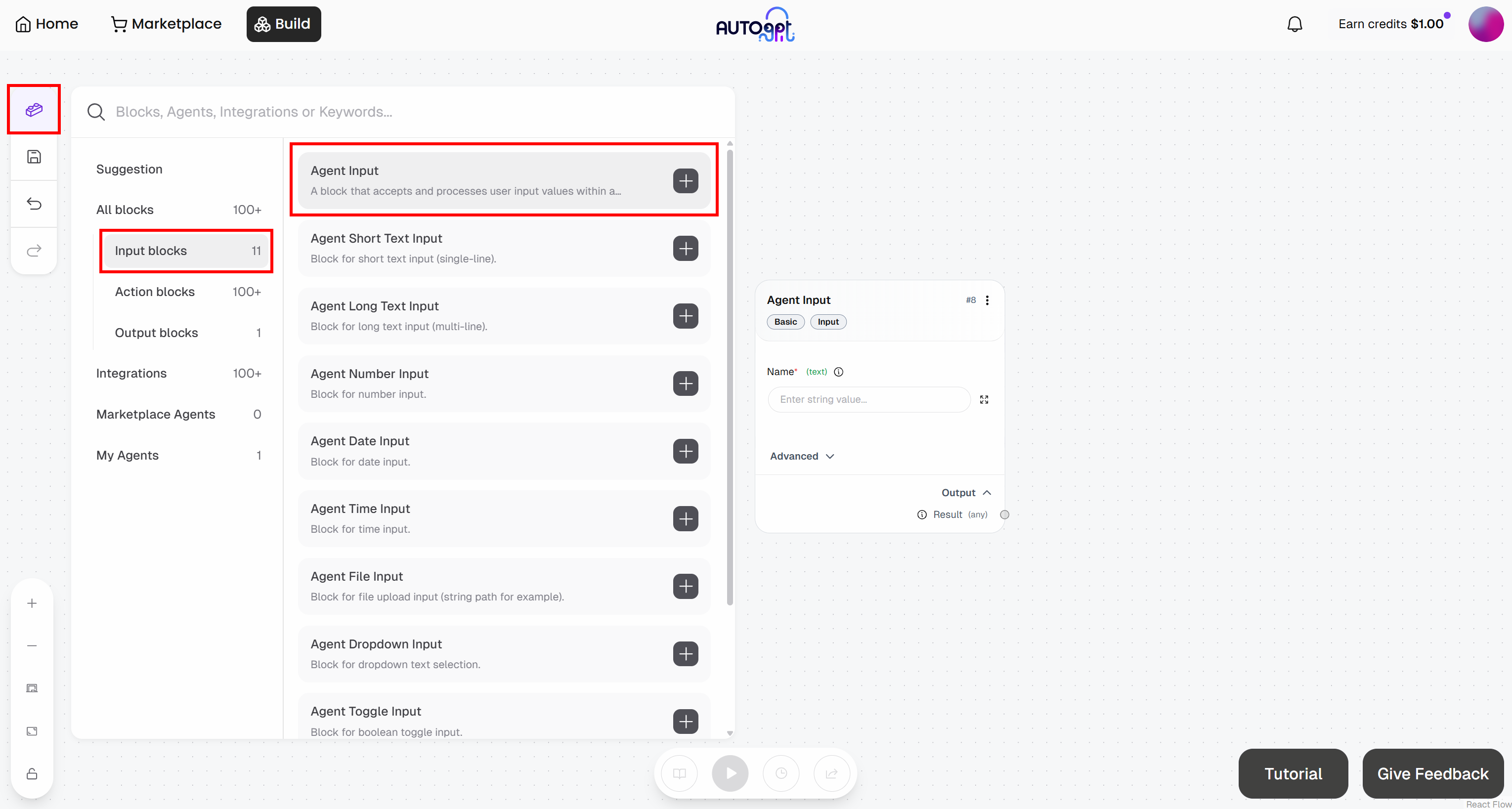
Da mesma forma, adicione um bloco “Agent Output”: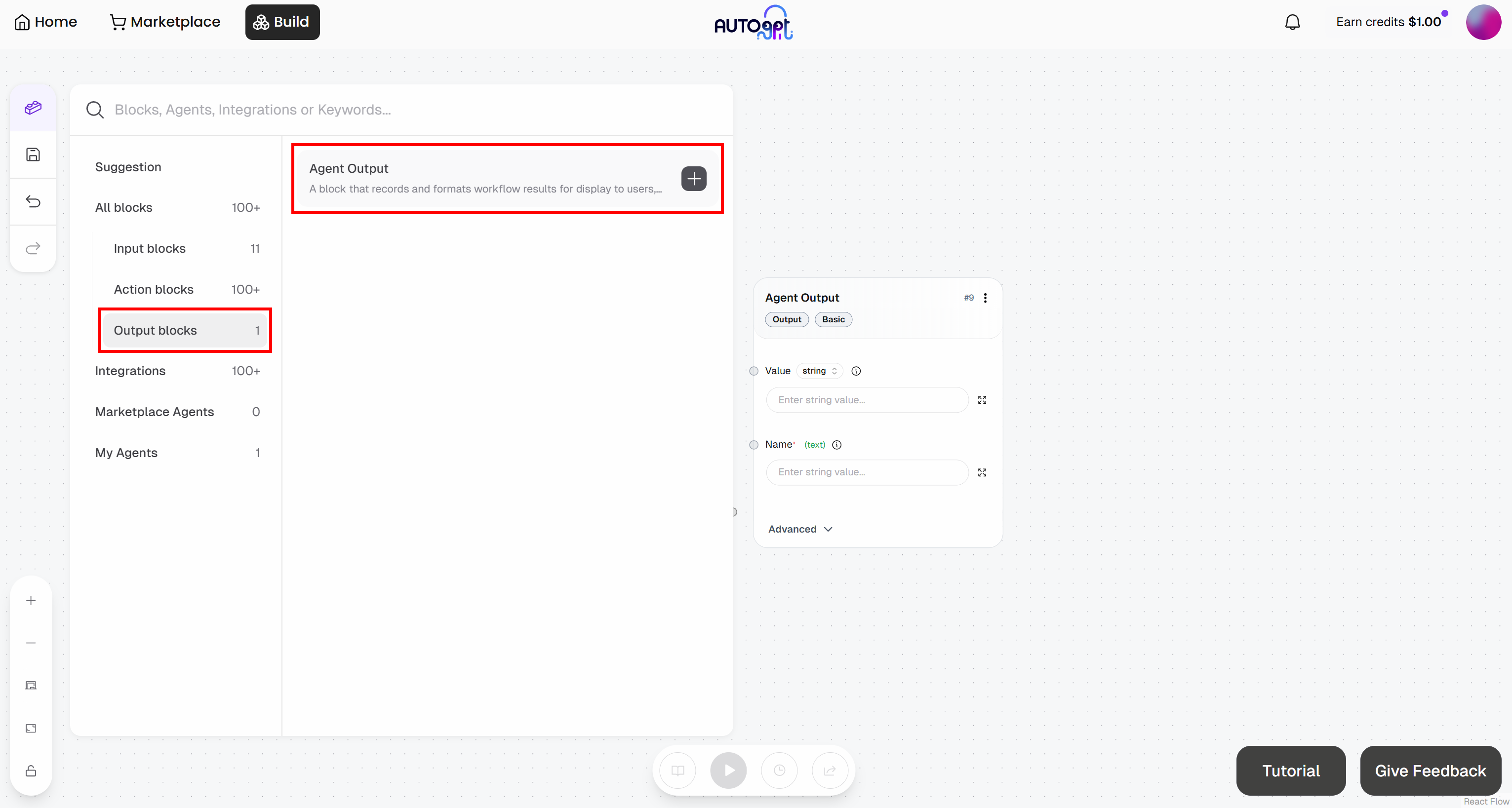
Configure os blocos da seguinte forma:
- Entrada do agente: nomeie-o como “URL do artigo”
- Bloco Saída do agente: nomeie-o como “Probabilidade de marcação”
Neste ponto, seu fluxo de trabalho de agente inicial deve ficar assim: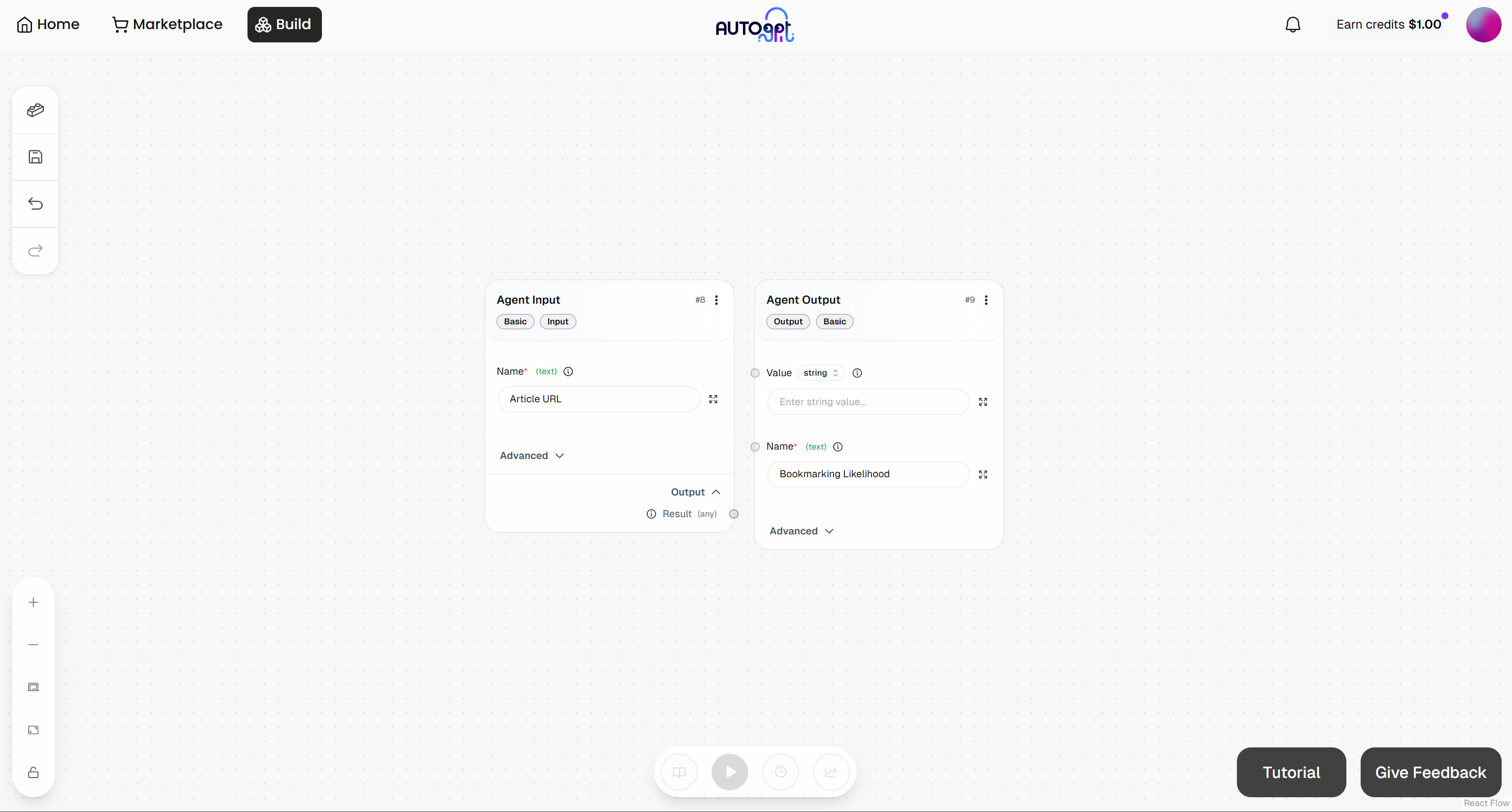
Ótimo! É hora de continuar definindo o restante do seu fluxo de trabalho de agente.
Passo 6: Faça a solicitação de scraping
Para realizar a solicitação HTTP à API do Bright Data Web Unlocker, você precisa de dois blocos:
- Criar Dicionário: Define o corpo da solicitação.
- Enviar solicitação web autenticada: Envia a solicitação autenticada para o endpoint do Web Unlocker nas APIs da Bright Data.
Comece adicionando o bloco “Criar dicionário”: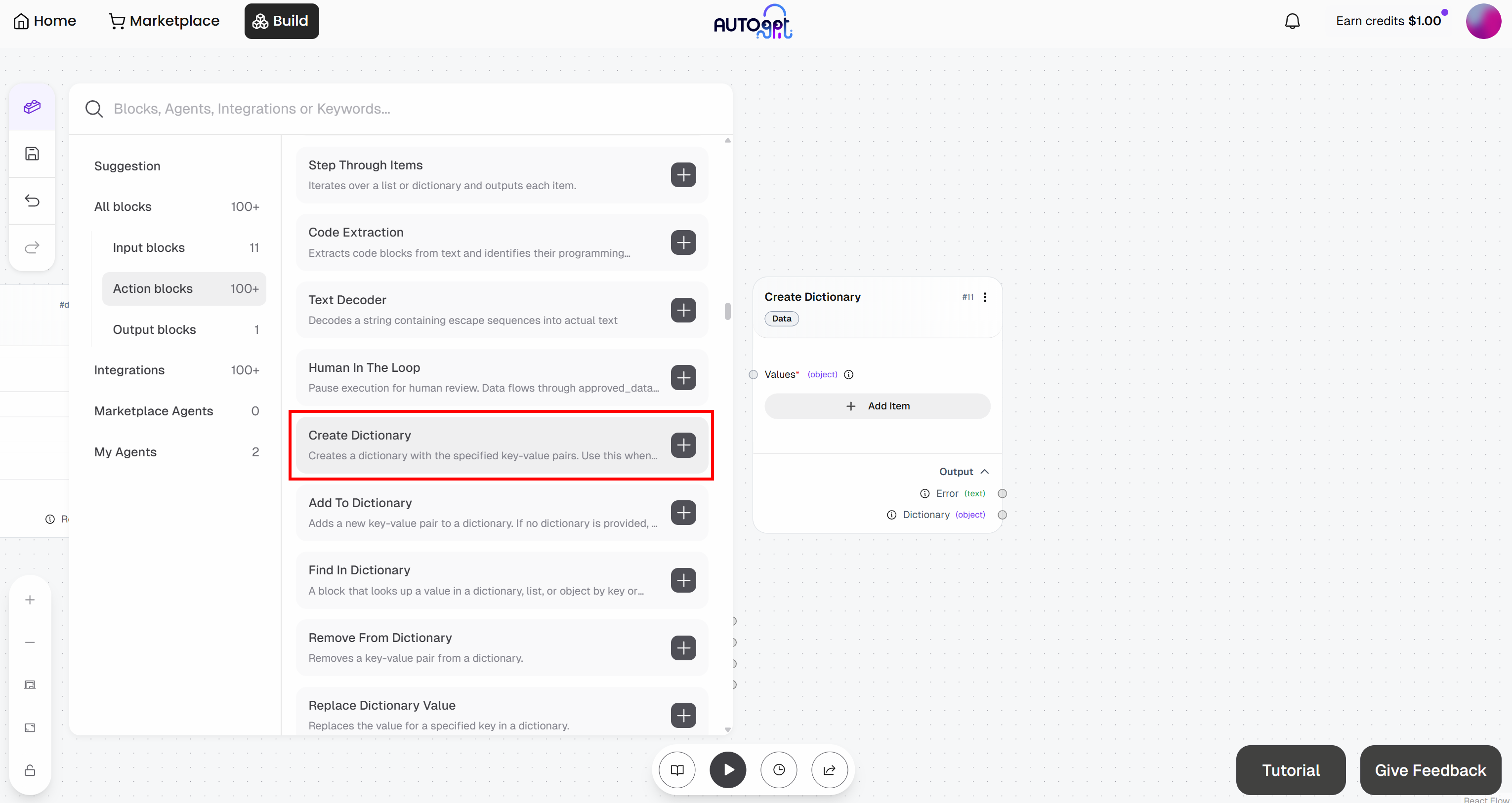
Em seguida, adicione o bloco “Enviar solicitação web autenticada”: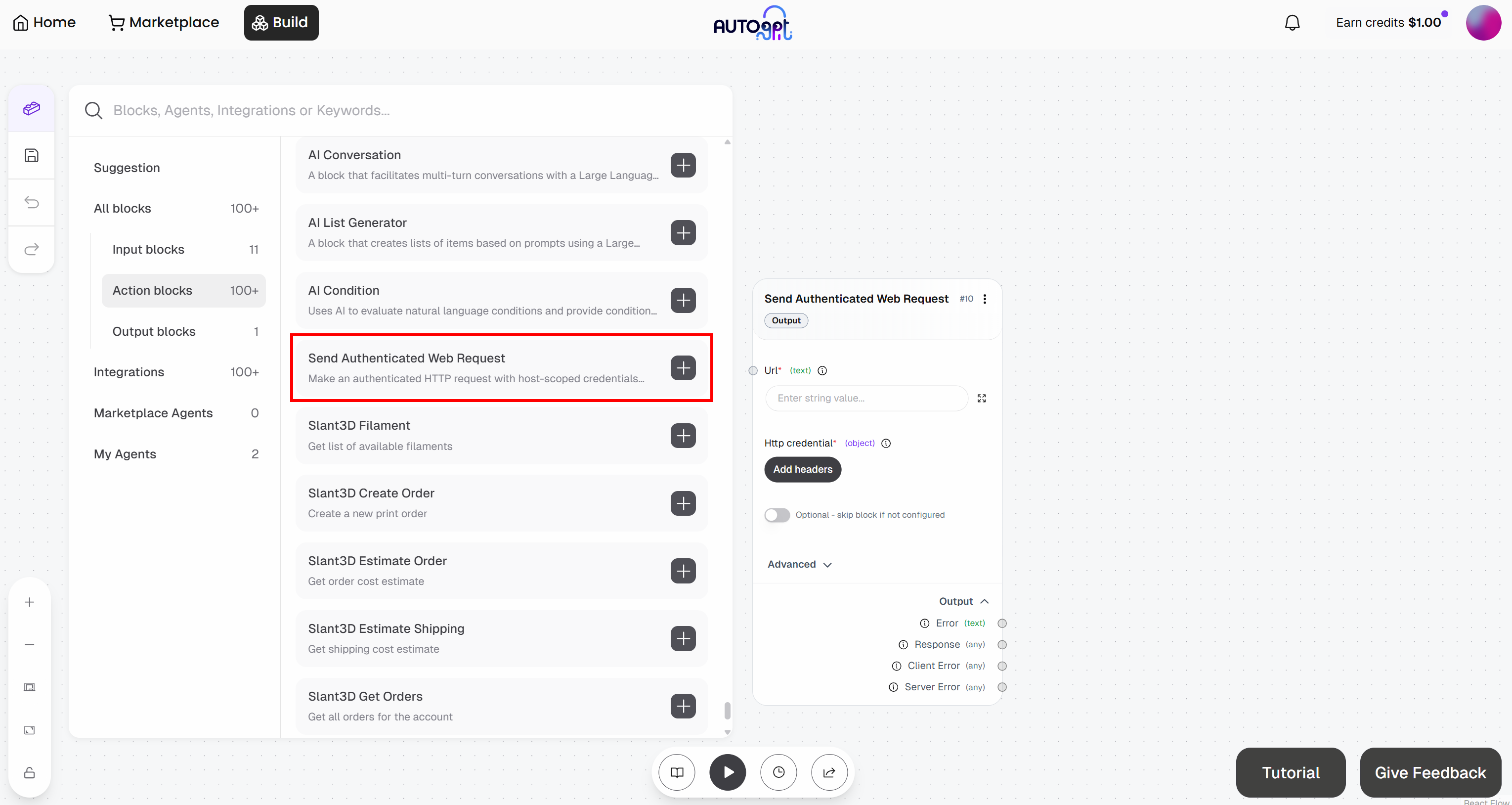
Prepare-se para configurar o bloco “Enviar solicitação web autenticada”. Isso enviará uma solicitação à API do Web Unlocker. Para obter mais detalhes sobre como esse endpoint funciona e como chamá-lo, consulte a documentação oficial.
Expanda o menu suspenso “Avançado” e preencha todo o bloco da seguinte forma:
- URL:
https://api.brightdata.com/request. - HttpMethod:
POST
Em seguida, clique no botão “Adicionar cabeçalhos” em “Credenciais HTTP”: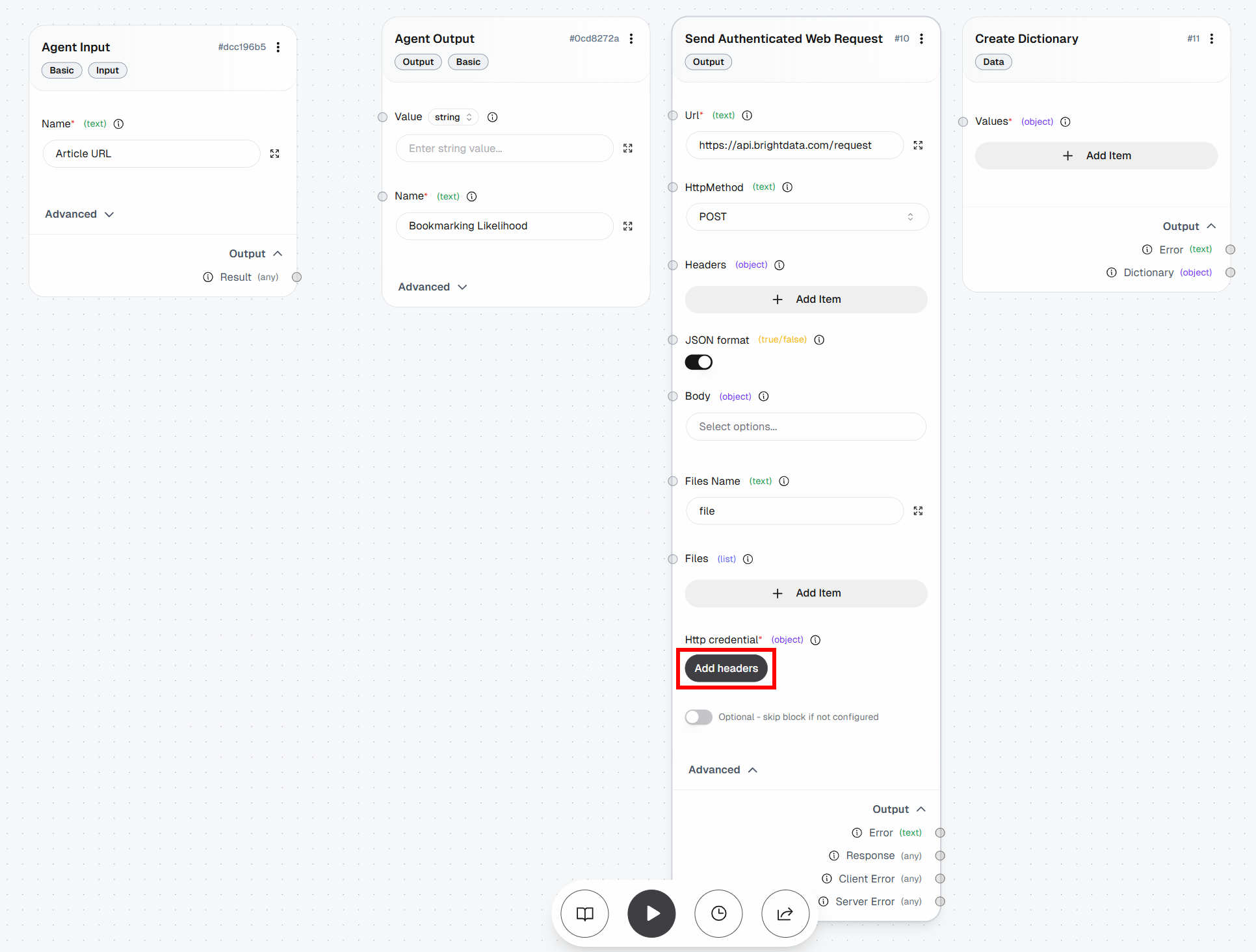
Configure a autenticação baseada em cabeçalho da seguinte forma:
- Nome do cabeçalho:
Authorization - Valor do cabeçalho:
Bearer <YOUR_BRIGHT_DATA_API_KEY>
Lembre-se de substituir o espaço reservado <YOUR_BRIGHT_DATA_API_KEY> pela sua chave de API da Bright Data.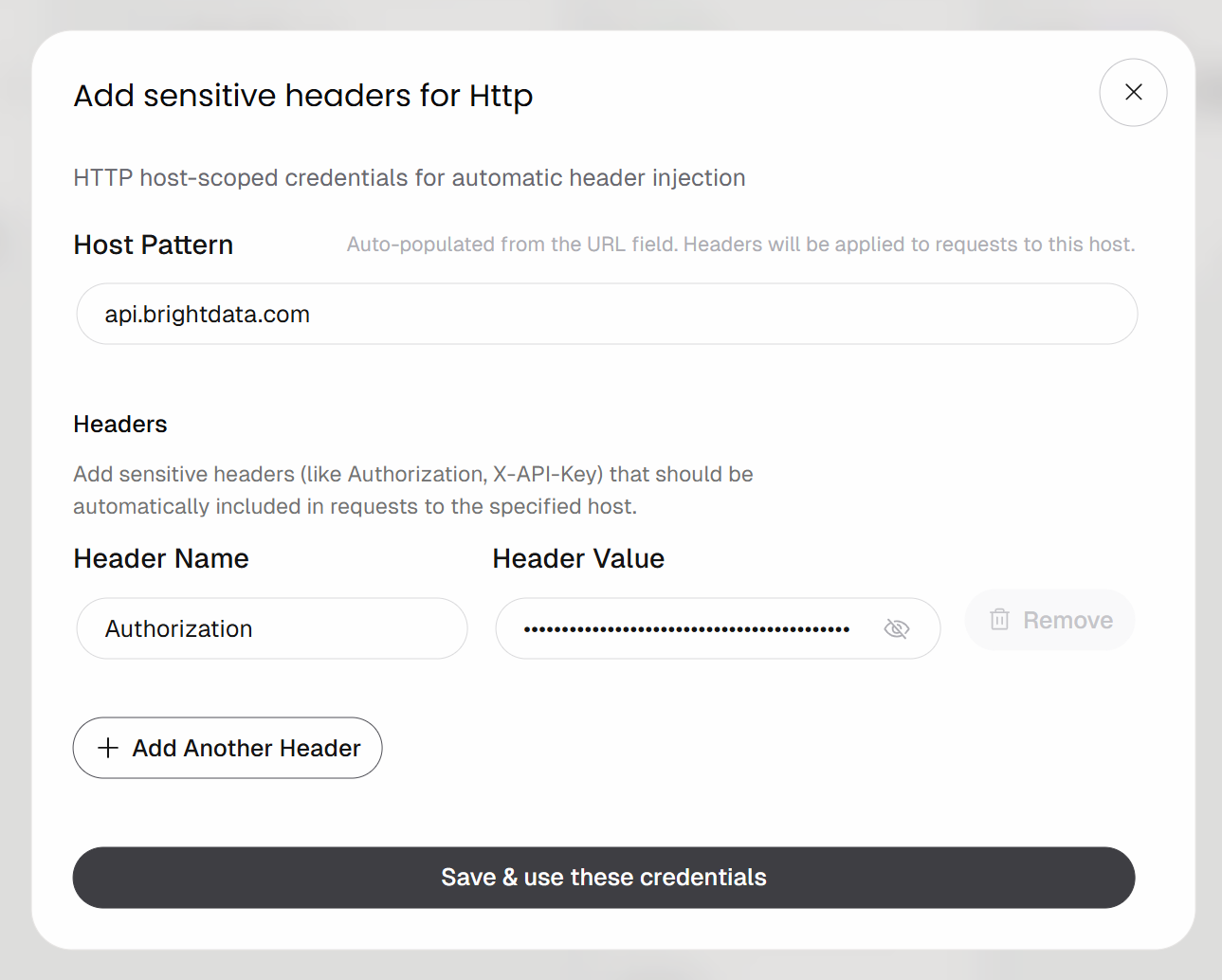
Clique no botão “Salvar e usar essas credenciais” para confirmar.
A solicitação POST será autenticada usando o cabeçalho Authorization. Esse é o método de autenticação recomendado para chamar as APIs da Bright Data.
Agora, você precisa definir o corpo da solicitação. Neste caso, você deseja uma carga JSON da seguinte forma:
{
"zone": "<YOUR_WEB_UNLOCKER_API_ZONE_NAME>",
"url": "<INPUT_URL>",
"format": "raw",
"data_format": "markdown"
}Isso instrui a API da Bright Data a usar sua zona da API do Web Unlocker (por exemplo, web_unlocker) em uma URL de destino, que será fornecida pelo bloco “Entrada do agente”. O parâmetro format: "raw" garante que a API retorne a saída diretamente no corpo da resposta, em vez de como uma estrutura JSON. O parâmetro data_format: "markdown" configura a API para extrair o conteúdo do artigo em Markdown, que é um formato ideal para a ingestão pelo agente de IA.
Para fazer isso, vá até o bloco “Create Dictionary” e clique em “Add Item”. Defina os seguintes campos:
Zona:<YOUR_WEB_UNLOCKER_API_ZONE_NAME>(por exemplo,"web_unlocker")url: (deixe em branco por enquanto, pois será preenchido dinamicamente)format:"raw"data_format:"markdown"
Em seguida, conecte a saída “Dicionário” do bloco “Criar Dicionário” à entrada “Corpo” do bloco “Enviar Solicitação Web Autenticada”: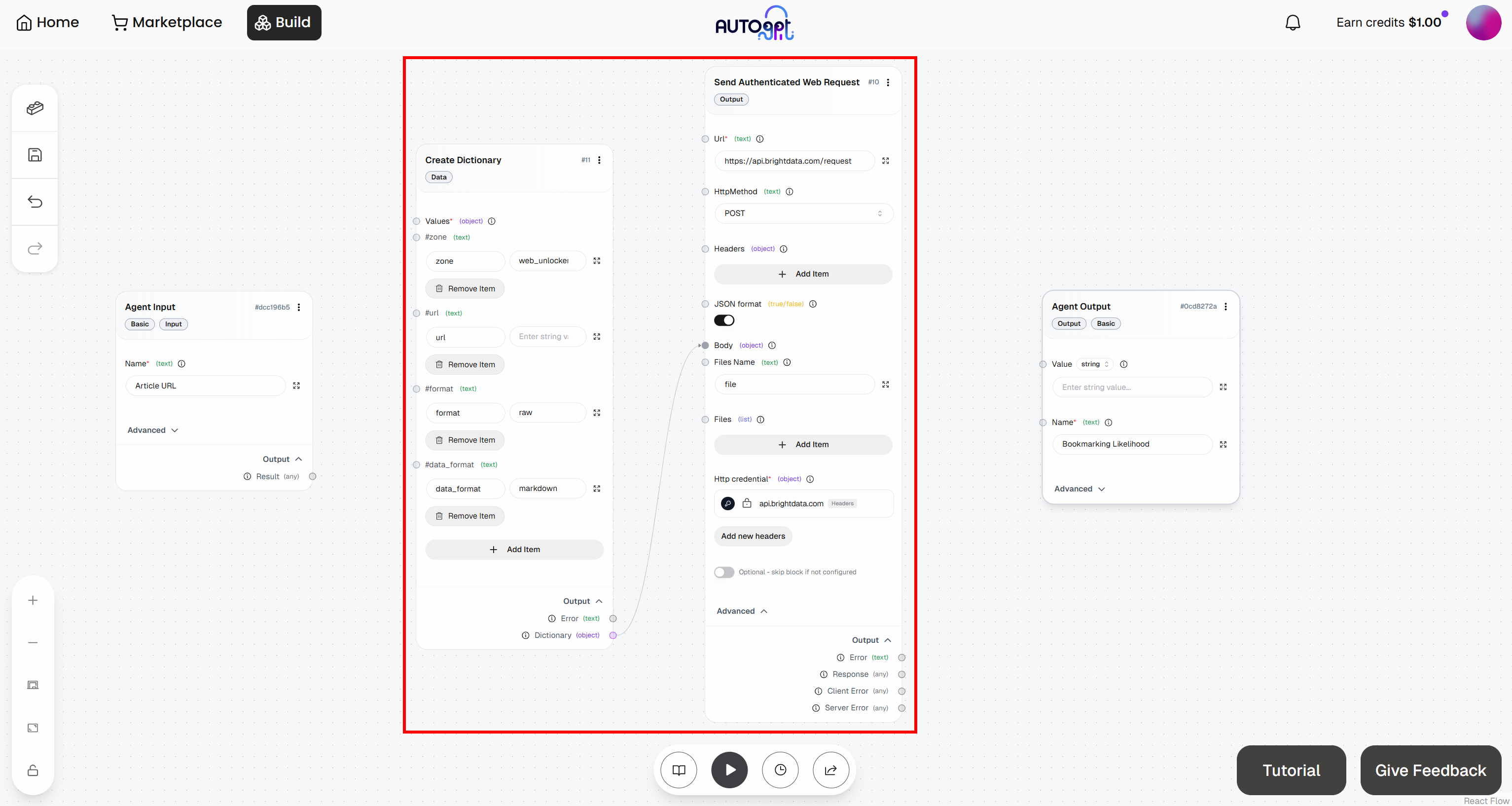
Ótimo! A integração do Bright Data no seu fluxo de trabalho do AutoGPT está concluída.
Passo 7: Adicione o mecanismo LLM
O último bloco que faltava é o mecanismo LLM, responsável por analisar o conteúdo Markdown recuperado por meio do Scraping de dados através da API Web Unlocker e atribuir a ele uma pontuação de bookmark.
Como você deseja que esse fluxo de trabalho avalie diferentes artigos ao longo do tempo, ele deve produzir uma saída consistente e estruturada.
Para atingir esse objetivo, use o bloco “IA Structured Response Generator”. Isso permite que você instrua um LLM a realizar uma tarefa e retornar resultados em um formato predefinido.
Comece adicionando este bloco ao seu fluxo de trabalho: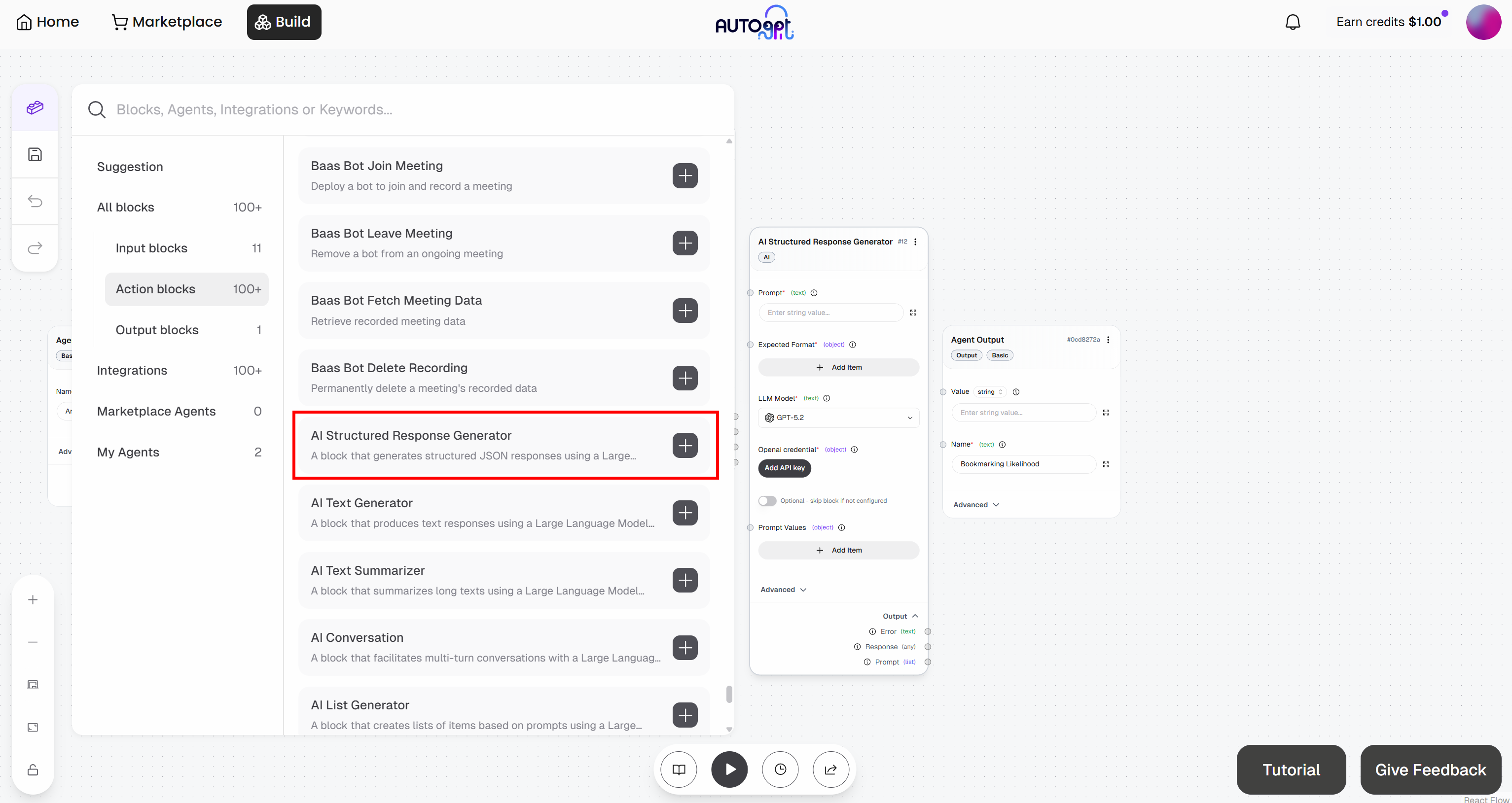
Conecte o bloco à sua conta OpenAI clicando no botão “Add API Key”. Forneça um nome para sua chave, cole sua chave API da OpenAI e clique em “Add API Key”: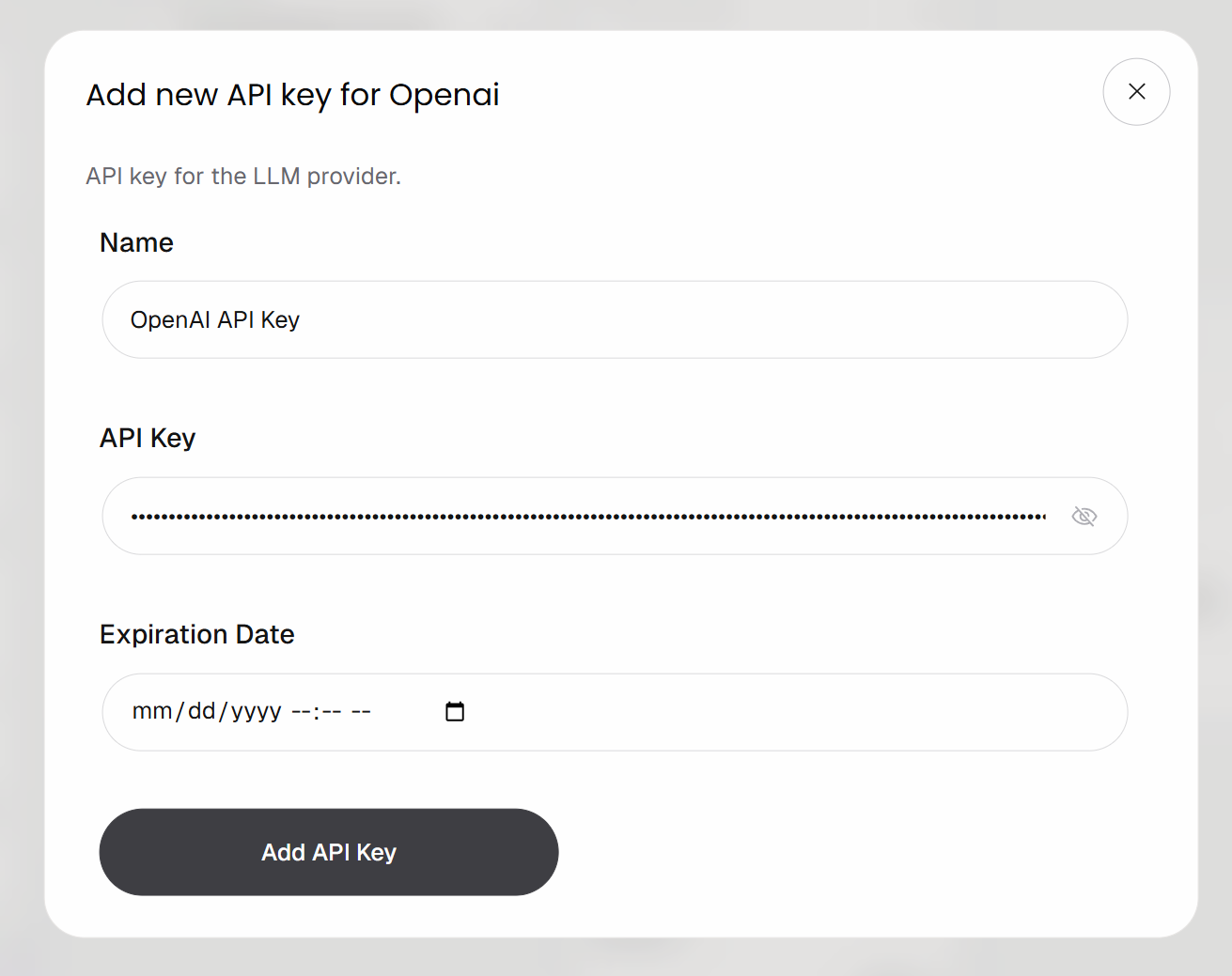
Seu bloco “Gerador de Respostas Estruturadas por IA” agora está autenticado e pronto para chamar o modelo OpenAI configurado.
Agora, preencha o bloco com o seguinte:
- Prompt:
Você é um avaliador de conteúdo especialista.
Sua tarefa é analisar o artigo a seguir e determinar se vale a pena salvá-lo nos favoritos para referência futura.
Artigo:
"{{article}}"
Avalie o artigo com base em:
- Utilidade prática (ele fornece insights acionáveis?)
- Profundidade (é superficial ou aprofundado?)
- Relação sinal-ruído (é conciso ou cheio de enrolação?)
- Reutilização (vale a pena revisitar mais tarde?)
Retorne um objeto JSON com:
- "score": um número inteiro de 1 a 10 (1 = não vale a pena salvar nos favoritos, 10 = deve ser salvo nos favoritos)
- "comment": uma explicação concisa e em linguagem natural (máximo de 1–2 frases)
Diretrizes:
- Seja crítico e evite supervalorizar
- Dê notas mais altas apenas para conteúdos com valor a longo prazo
- Evite comentários genéricos
- *Modelo*: GPT-5.1 Mini (ou qualquer outro modelo OpenAI de uso geral)No prompt, observe o espaço reservado {{article}}. Essa é uma variável que será substituída dinamicamente por um “Valor do Prompt”. Especificamente, ela será substituída pelo conteúdo Markdown retornado pelo bloco “Enviar Solicitação Web Autenticada”.
Para configurar um “Valor de Prompt”, clique em “Adicionar item” e defina uma variável chamada article. Em seguida, conecte a saída “Resposta” do bloco “Enviar Solicitação Web Autentificada” ao valor de prompt article: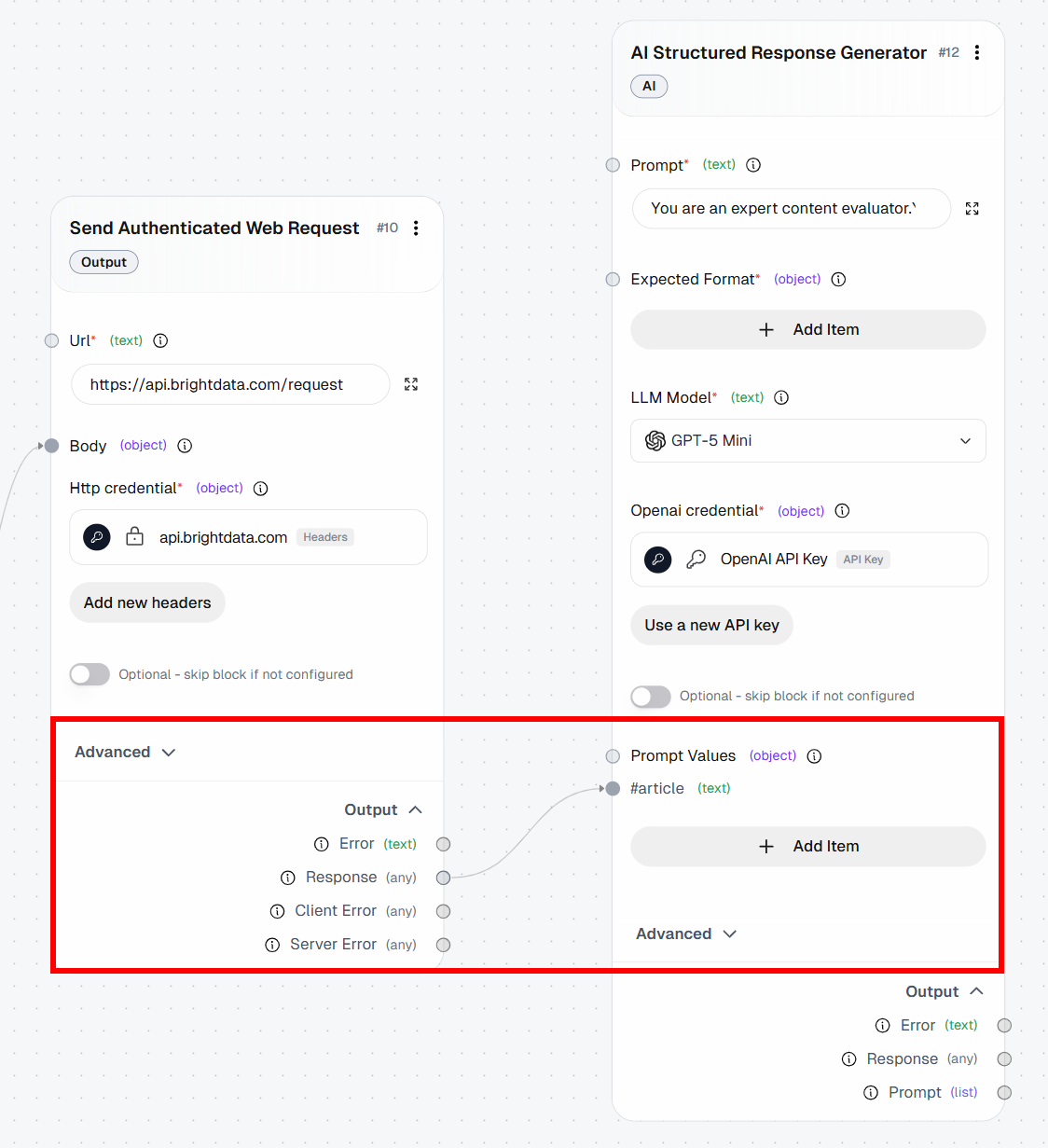
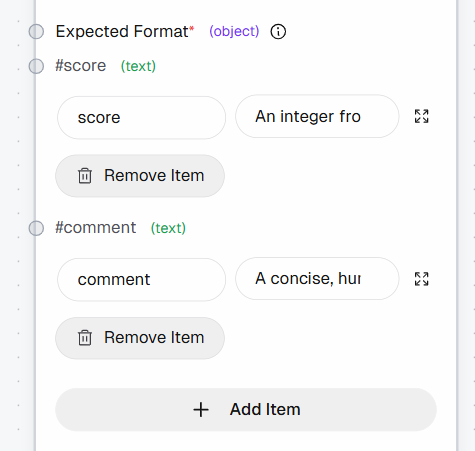
Em seguida, defina a saída estruturada adicionando os seguintes campos à seção “Formato esperado”:
pontuação: “Um número inteiro de 1 a 10 (1 = não vale a pena salvar nos favoritos, 10 = deve ser salvo nos favoritos)”comentário: “Uma explicação concisa e em linguagem natural (máximo de 1–2 frases)”
Ótimo! Seu fluxo de trabalho de agente AutoGPT com tecnologia Bright Data agora inclui todos os blocos de construção. Resta apenas conectá-los todos.
Etapa 8: Conecte todos os blocos
Para finalizar o fluxo de trabalho, conecte todos os blocos para criar um pipeline completo.
Comece conectando a saída “Resultado” do bloco “Entrada do Agente” ao campo url do bloco “Criar Dicionário”. Isso garante que a URL de entrada flua da entrada do fluxo de trabalho para a solicitação da API do Web Unlocker, que irá extrair a página e passar o resultado para o LLM para análise.
Por fim, conecte a saída “Resposta” do bloco “Gerador de resposta estruturada de IA” ao bloco “Saída do agente”. Isso encerra o fluxo de trabalho e completa o fluxo de dados.
Abaixo está como deve ficar seu fluxo de trabalho final do AutoGPT, aprimorado com recursos de Scraping de dados graças à Bright Data: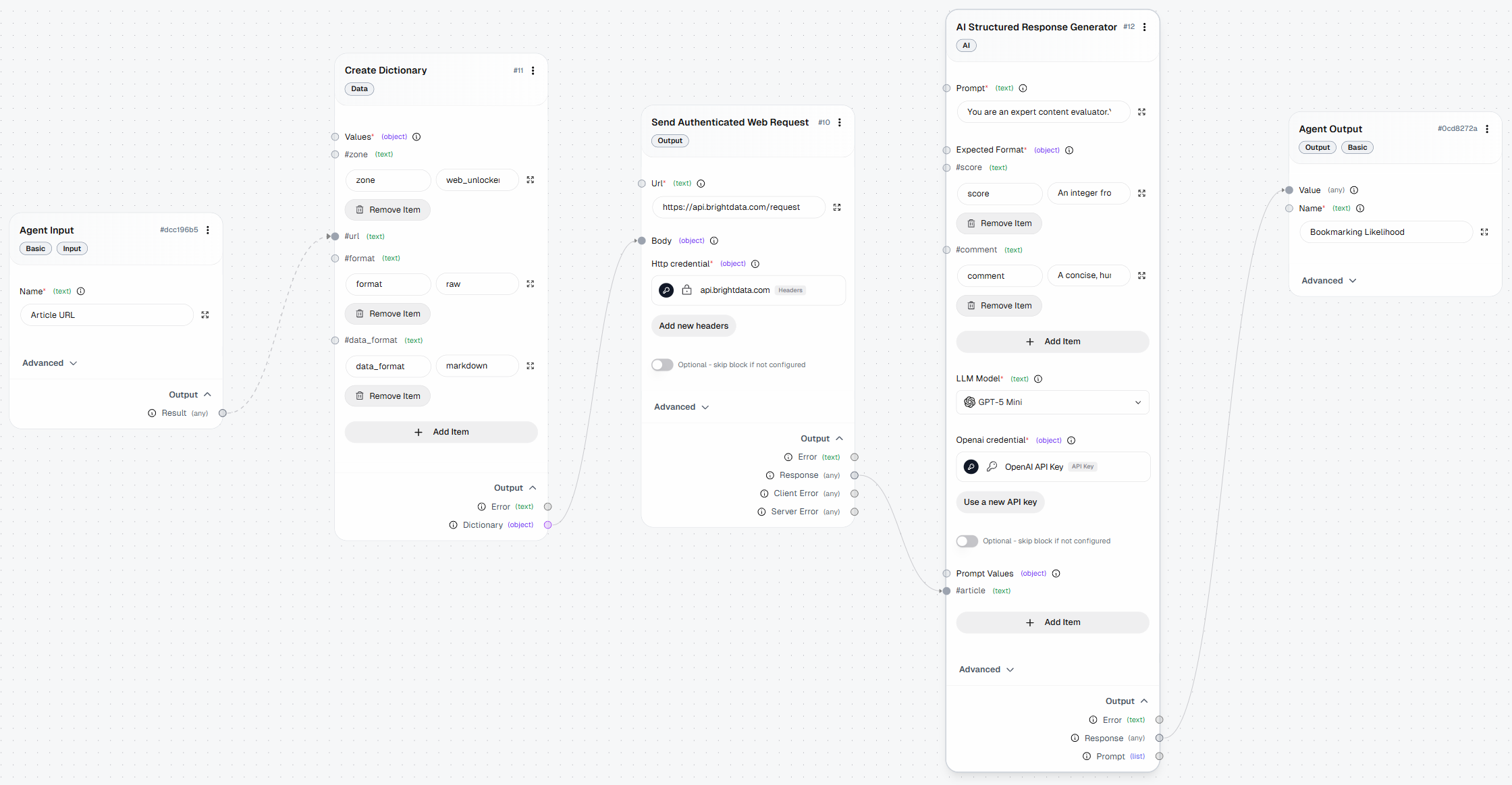
Passo 9: Teste o agente
Clique no botão “Executar agente” para iniciar seu fluxo de trabalho de agente e testá-lo: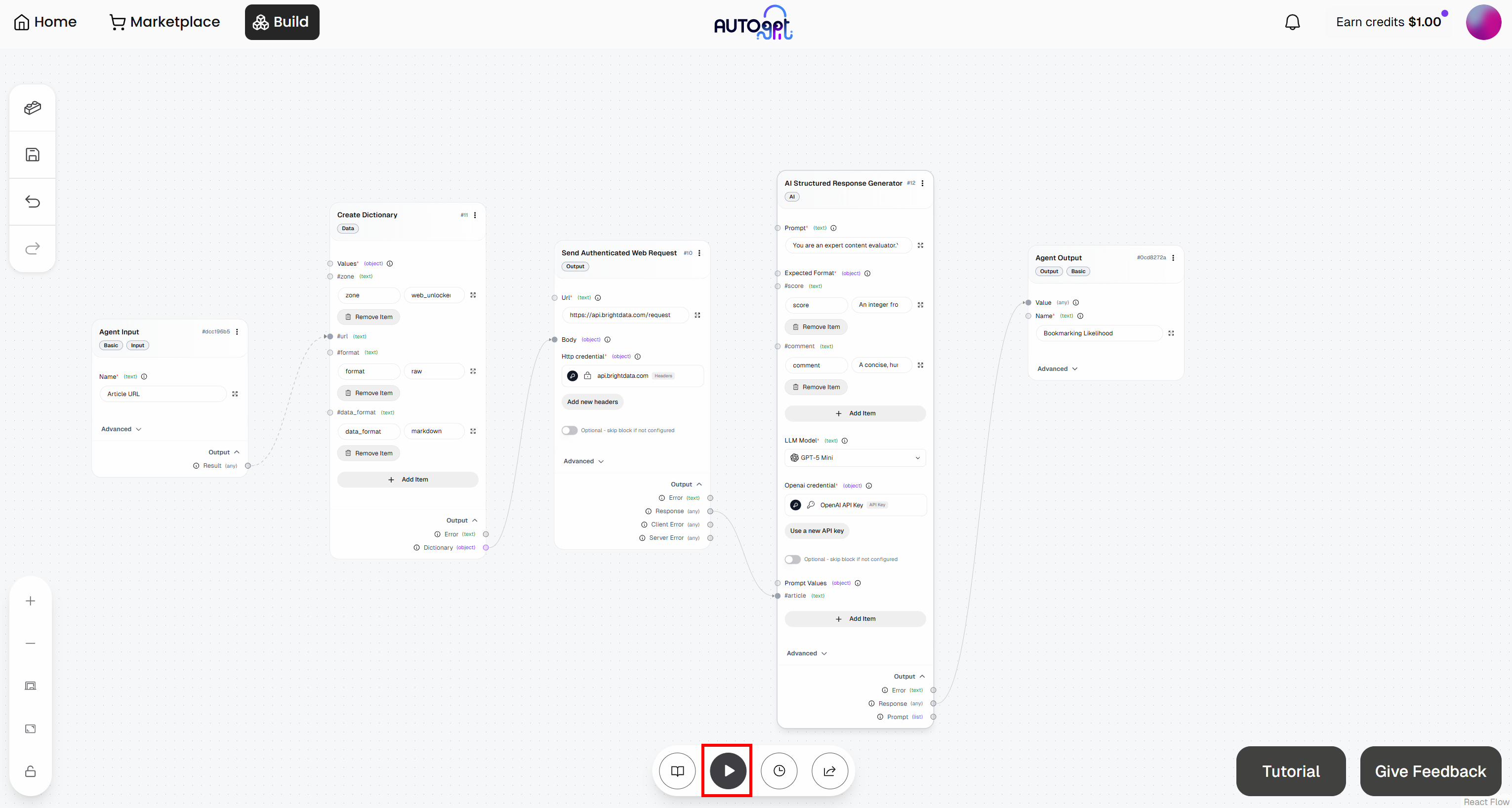
Será solicitado que você forneça a URL de entrada do fluxo de trabalho (ou seja, a URL do artigo). Cole uma postagem de blog como esta:
https://awealthofcommonsense.com/2024/03/whats-the-investment-case-for-gold/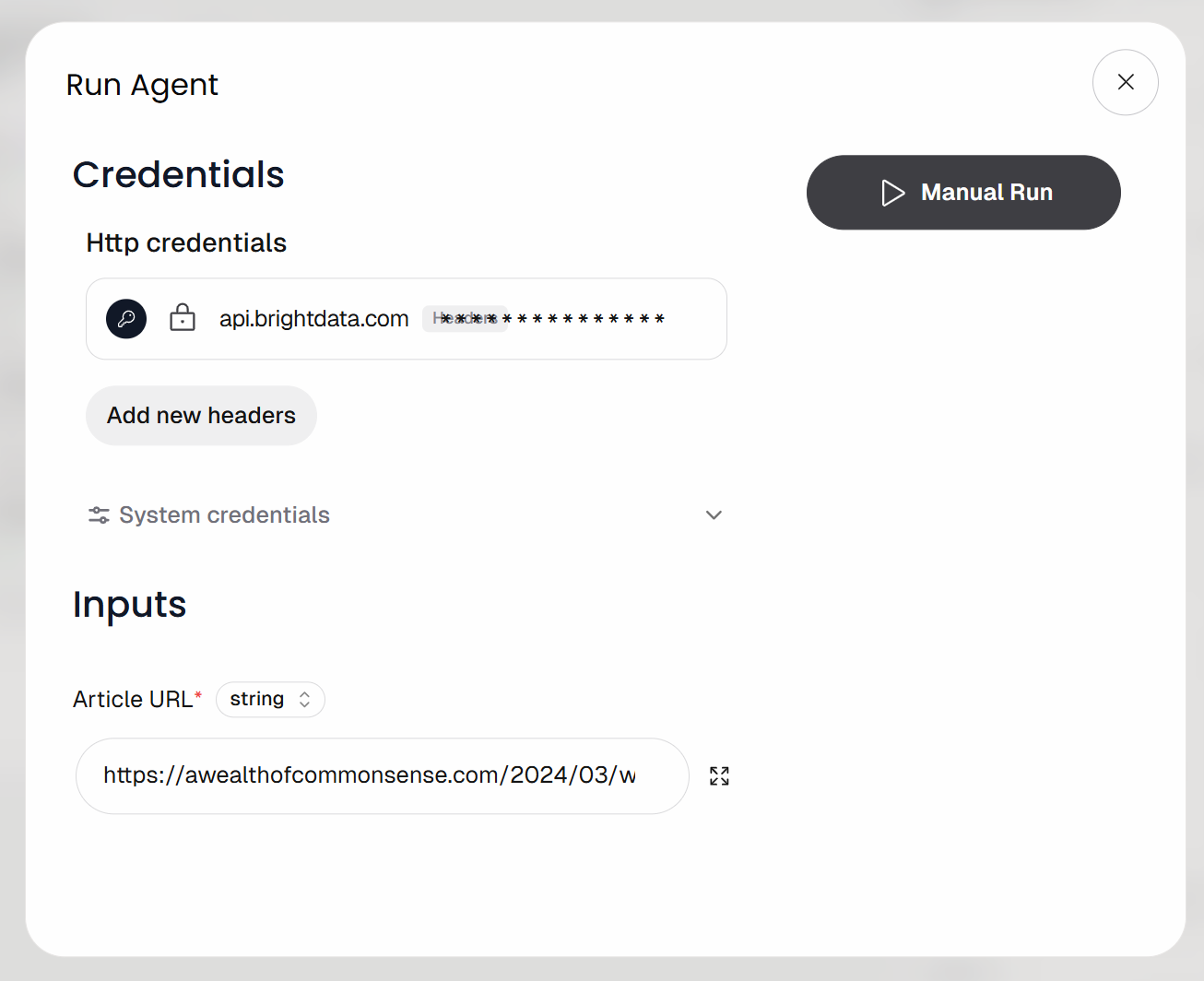
Em seguida, inicie o fluxo de trabalho clicando no botão “Execução manual”. É isso que você deve ver: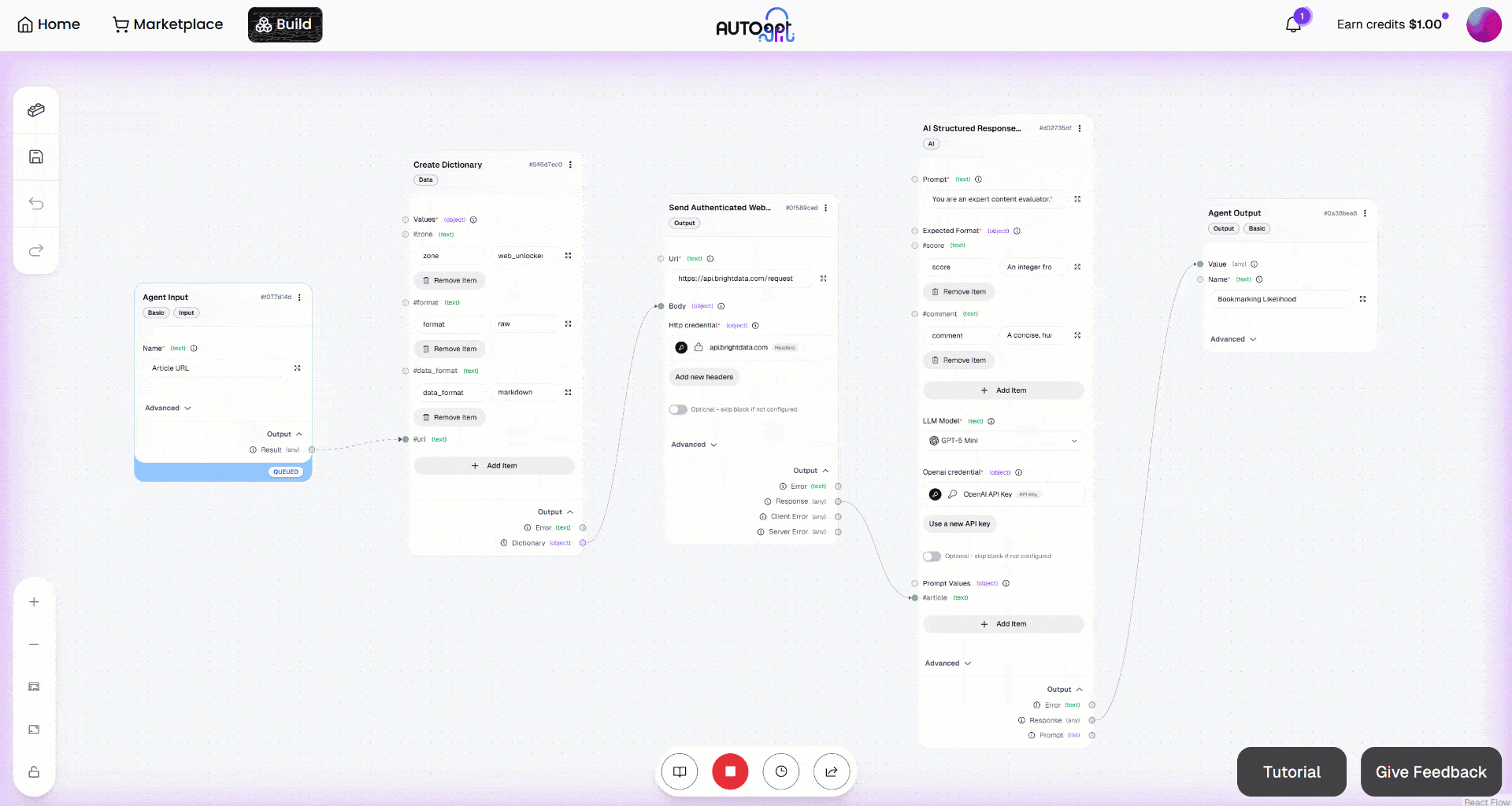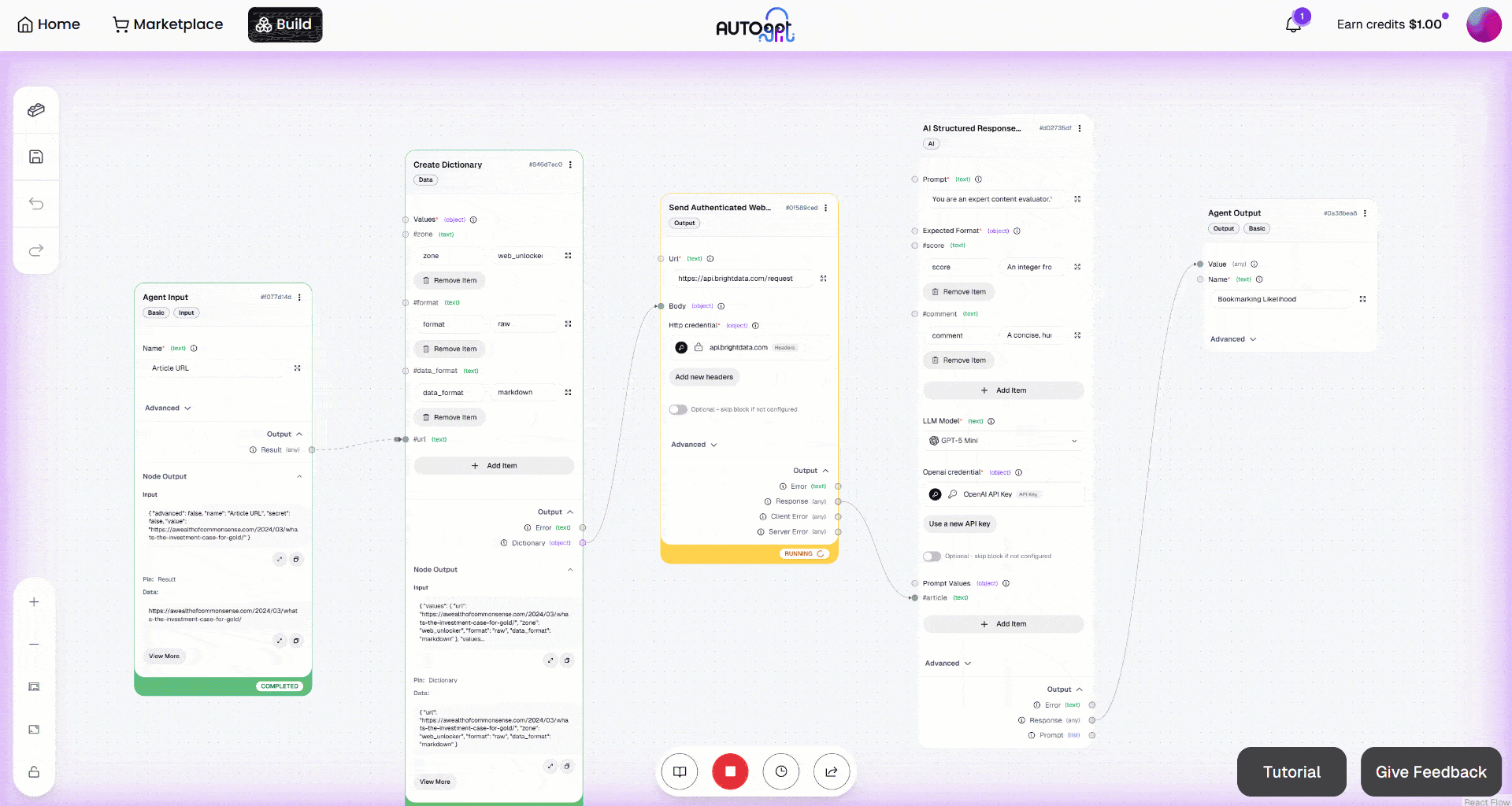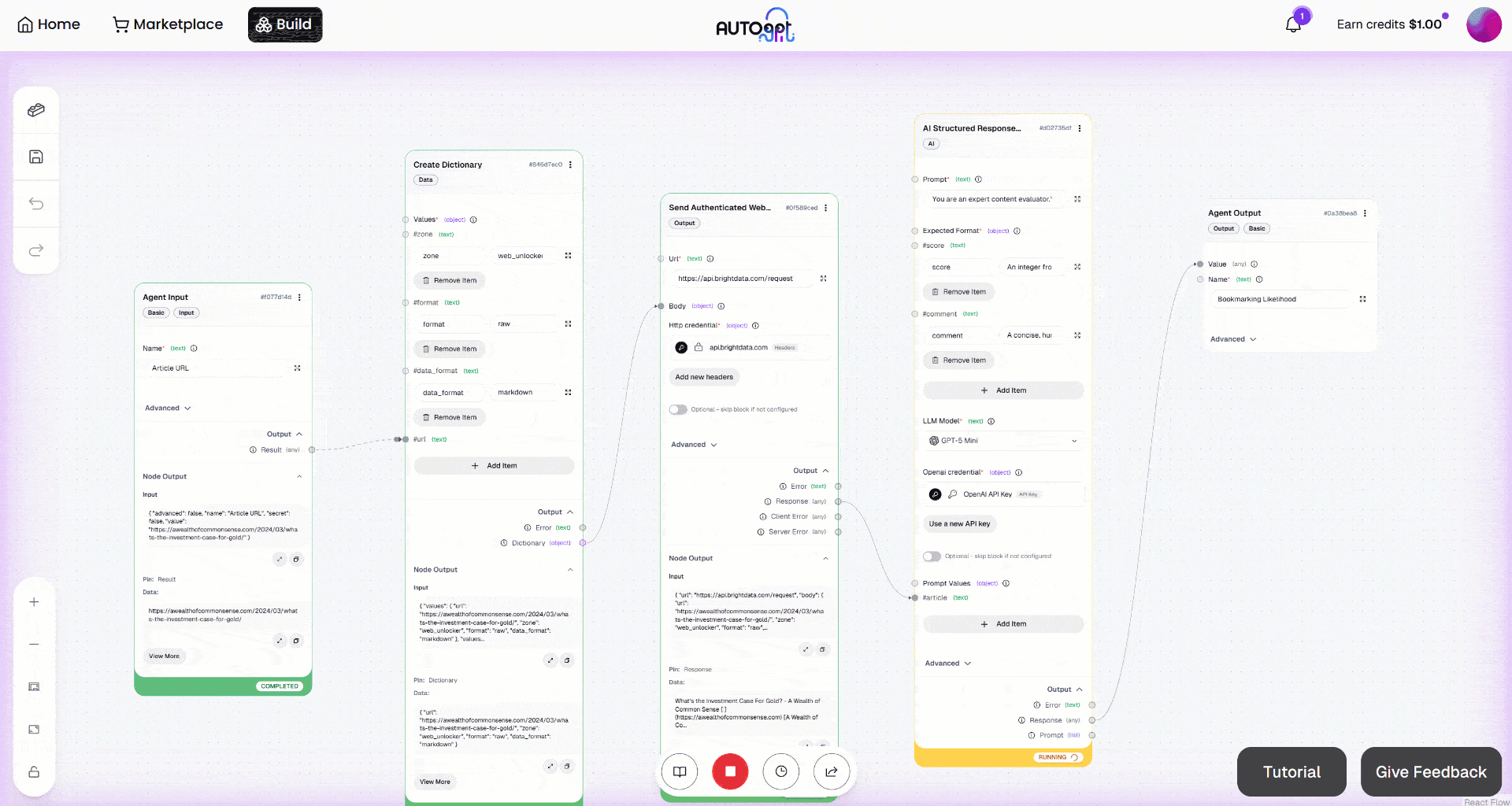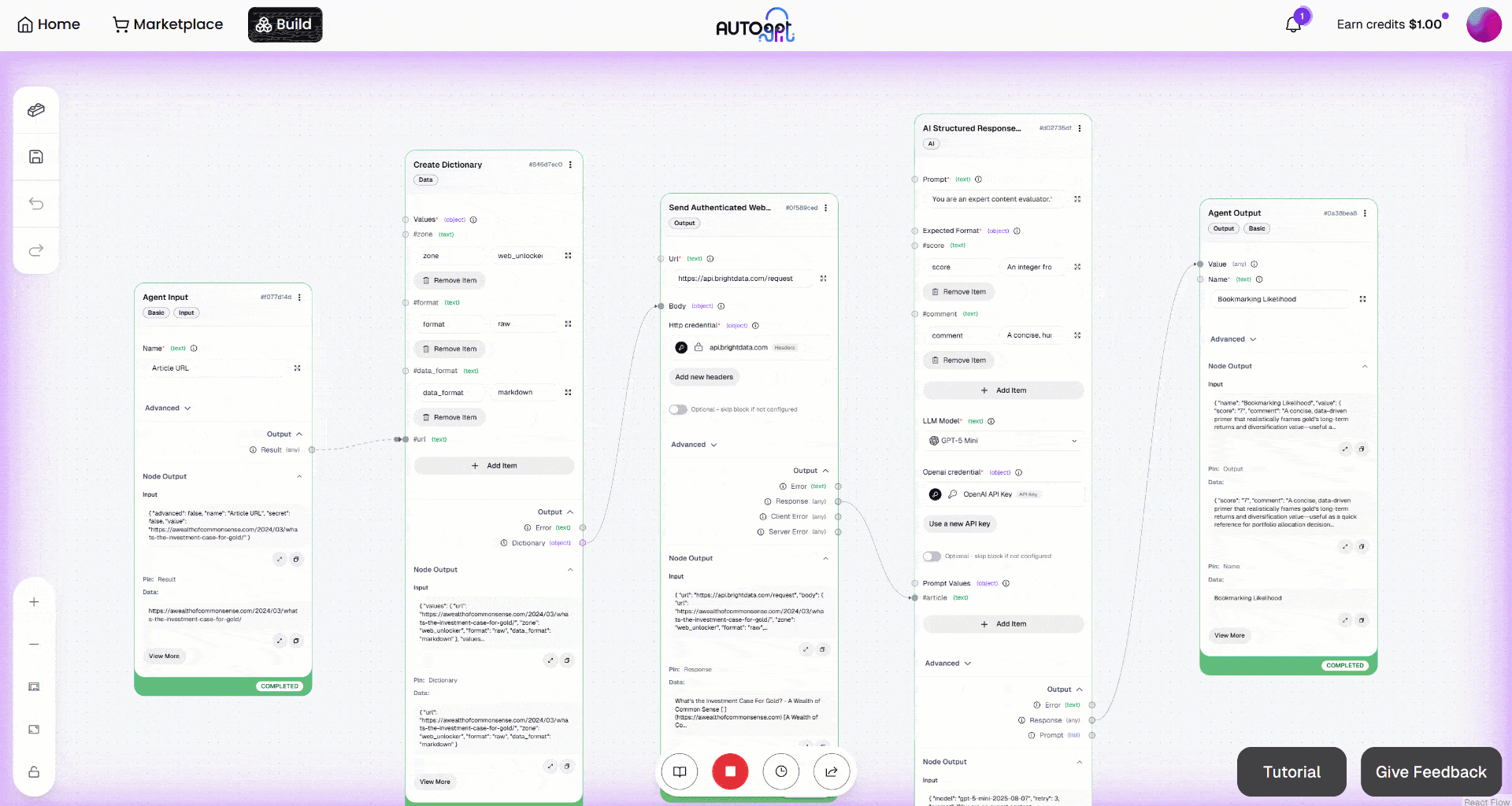
Expanda a saída no bloco “Saída do agente”. Você notará que o agente de IA produziu um resultado como este: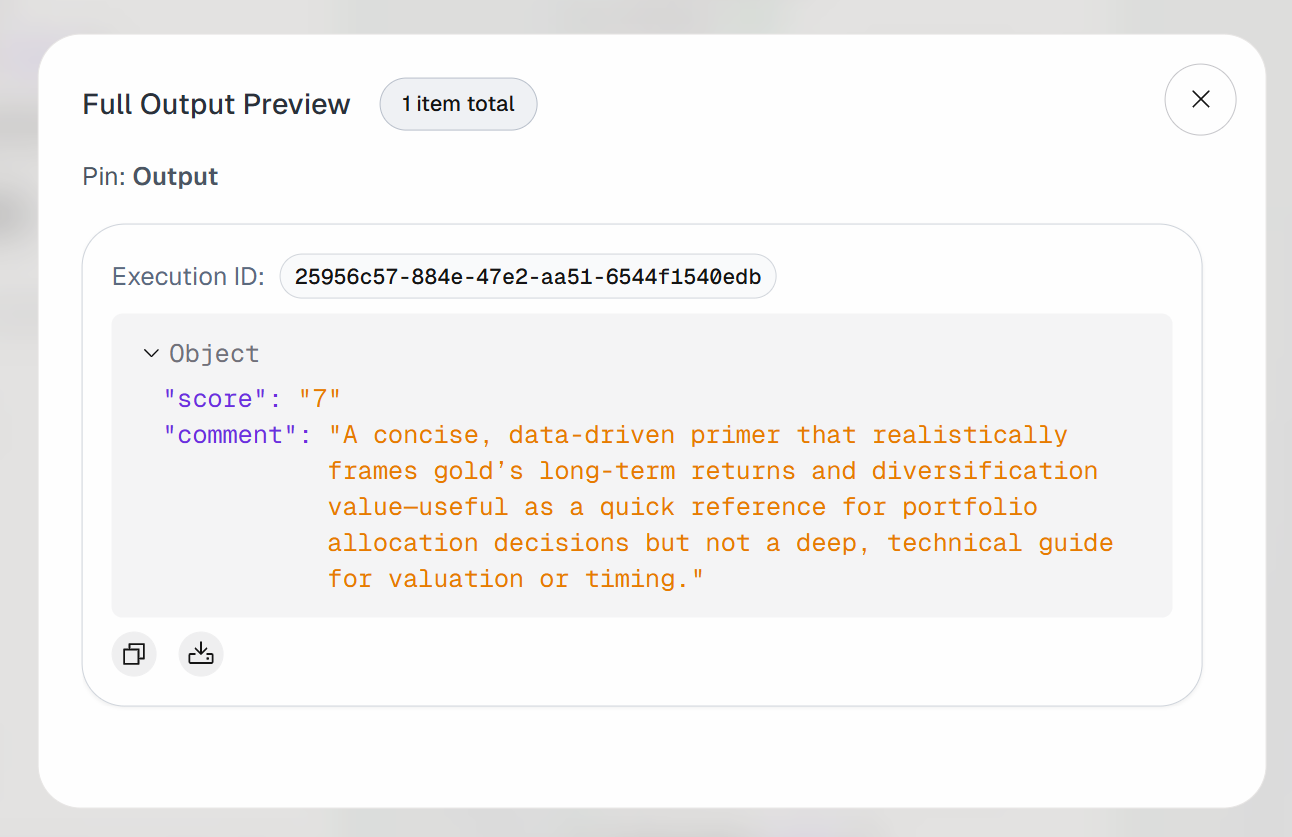
Assim, o artigo de entrada é considerado valioso o suficiente para ser marcado como favorito para leitura futura.
Se você inspecionar a saída do bloco “Send Authenticated Web Request”, observará:
Isso corresponde à versão Markdown do artigo de entrada de destino: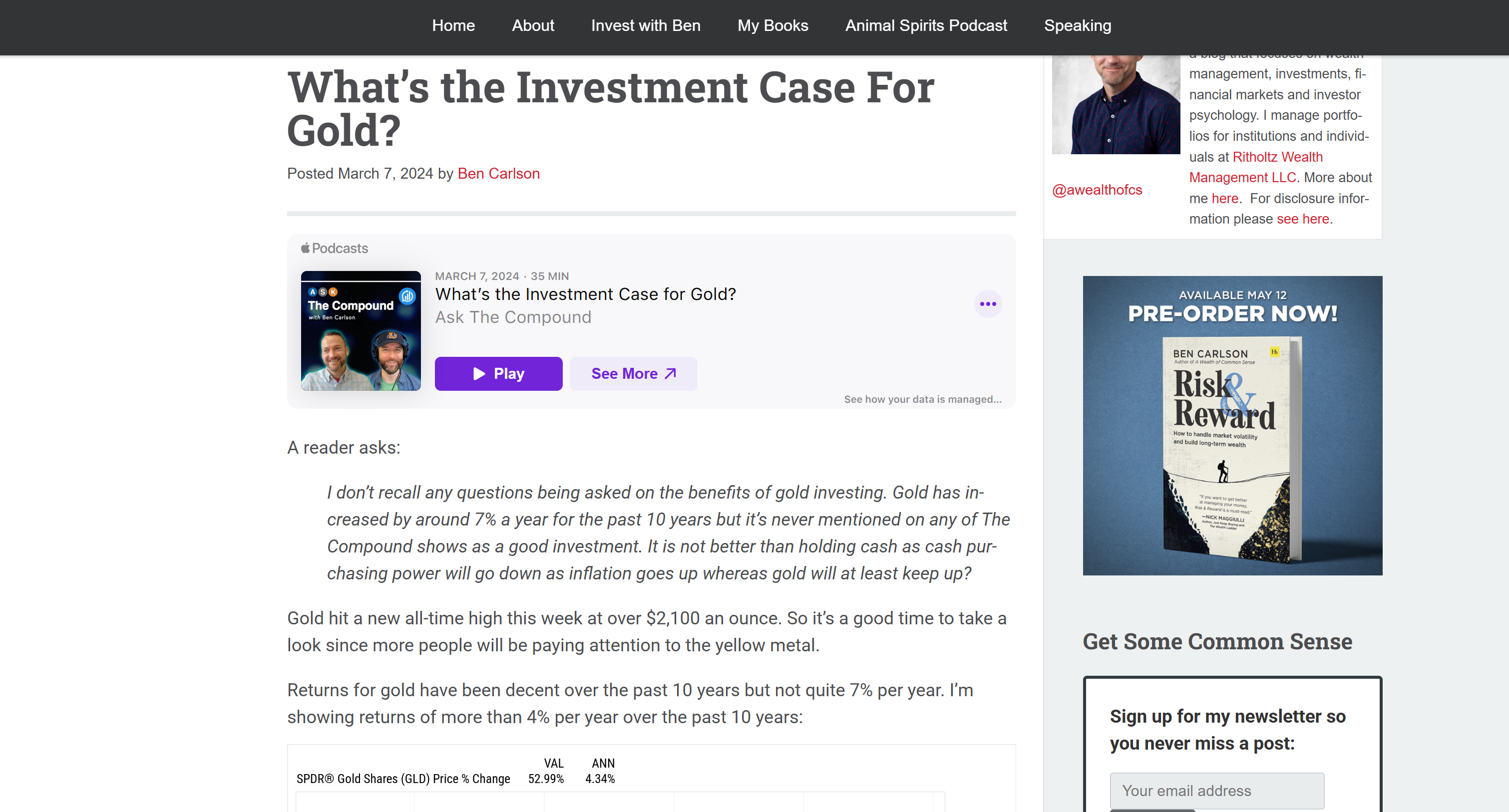
Isso confirma que a API do Bright Data Web Unlocker recuperou com sucesso o conteúdo da página rapidamente e em um formato que torna o processamento do LLM mais eficiente e eficaz.
Et voilà! Você acabou de criar um agente de IA no AutoGPT que se integra ao Bright Data para recuperação dinâmica de dados da web.
Próximos passos
Este foi um exemplo simples, mas tenha em mente que a integração AutoGPT + Bright Data pode ser ampliada para suportar fluxos de trabalho de agentes muito mais avançados.
Por exemplo, com uma abordagem semelhante, você pode conectar seu agente a outros produtos baseados na API da Bright Data para adicionar recursos de pesquisa e rastreamento na web. Da mesma forma, você pode integrar-se a APIs de scraping que fornecem feeds de dados diretos de vários domínios.
Para tornar seu agente mais poderoso, explore a ampla gama de recursos oferecidos pelo AutoGPT consultando a documentação oficial.
Conclusão
Nesta postagem do blog, você aprendeu como adicionar os recursos de exploração da web, interação, pesquisa e Scraping de dados da Bright Data ao AutoGPT. Isso capacita os agentes de IA a superar as principais limitações de conhecimento e interação típicas dos LLMs padrão.
Você viu como construir um agente de IA simples para recomendação de favoritos. Para criar fluxos de trabalho de agente mais complexos — que exigem acesso a feeds da web em tempo real, pesquisa na web ou interações na web — integre o AutoGPT com o conjunto completo de serviços da Bright Data para IA.
Crie uma conta gratuita na Bright Data hoje mesmo e comece a experimentar nossas soluções de dados da web preparadas para IA!






