

Neste tutorial, você aprenderá:
- O que é o Firebase Studio e os recursos que ele oferece.
- Por que você precisa de um provedor de dados da Web da Amazon, como a Bright Data, para criar uma experiência na Web semelhante à do CamelCamelCamel.
- Como criar um aplicativo da Web de rastreamento de preços da Amazon com o Firebase Studio, usando dados da Amazon da API Amazon Scraper da Bright Data.
Vamos nos aprofundar!
O que é o Firebase Studio?
OFirebase Studio é um ambiente de desenvolvimento baseado em nuvem e alimentado por IA criado pelo Google. Seu principal objetivo é acelerar a criação e a implantação de aplicativos com qualidade de produção com IA. Em particular, ele fornece um espaço de trabalho abrangente em que a assistência de IA com tecnologia Gemini é integrada em todo o ciclo de vida do desenvolvimento.
Principais recursos
Alguns dos principais recursos disponíveis no Firebase Studio são:
- Ambiente de desenvolvimento baseado em nuvem: Oferece um espaço de trabalho de codificação completo com assistência de IA, incluindo sugestões, geração e explicações de código.
- Agente de prototipagem de aplicativos: Oferece suporte à prototipagem rápida de aplicativos, como aplicativos da Web Next.js, com suporte de IA, reduzindo a necessidade de codificação manual extensiva.
- Suporte para várias estruturas e linguagens: Trabalhe com tecnologias populares como Flutter, Go, Angular, Next.js e outras, usando as estruturas de sua preferência.
- Integração com os serviços do Firebase: Integra-se a serviços como Firebase App Hosting, Cloud Firestore e Firebase Authentication.
- Ferramentas para desenvolvimento e implantação: Suporte incorporado para emulação, teste, depuração e monitoramento do desempenho do aplicativo.
- Opções de importação e personalização: Importe projetos existentes do GitHub, GitLab, Bitbucket ou arquivos compactados e personalize-os totalmente com IA.
O que você precisa para criar um aplicativo Web do rastreador de preços da Amazon
CamelCamelCamel é um serviço on-line que rastreia os preços dos produtos da Amazon, fornecendo gráficos de histórico de preços e alertas de quedas de preços para ajudar os usuários a encontrar as melhores ofertas. Em termos simples, seu principal recurso é o rastreamento de preços da Amazon, que é exatamente o foco deste guia.
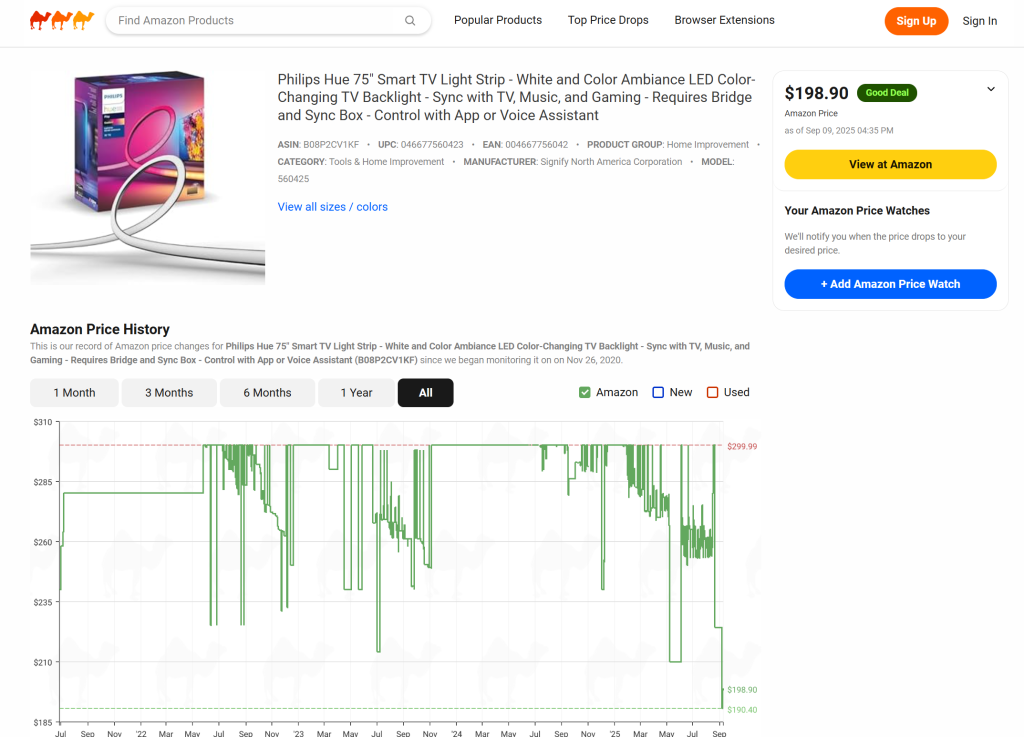
A ideia aqui é criar um aplicativo da Web que funcione como uma alternativa, implementando o rastreamento de preços da Amazon de forma simplificada. Normalmente, isso levaria dias (ou até meses) para ser desenvolvido, mas, graças ao Firebase Studio, você pode ter um protótipo funcional pronto e em execução em apenas alguns minutos.
Um grande desafio nessa tarefa é obter dados de produtos da Amazon. A raspagem da Amazon é notoriamente difícil devido a medidas anti-bot rigorosas como CAPTCHAs (lembre-se do notório CAPTCHA da Amazon) que podem bloquear a maioria das solicitações automatizadas:
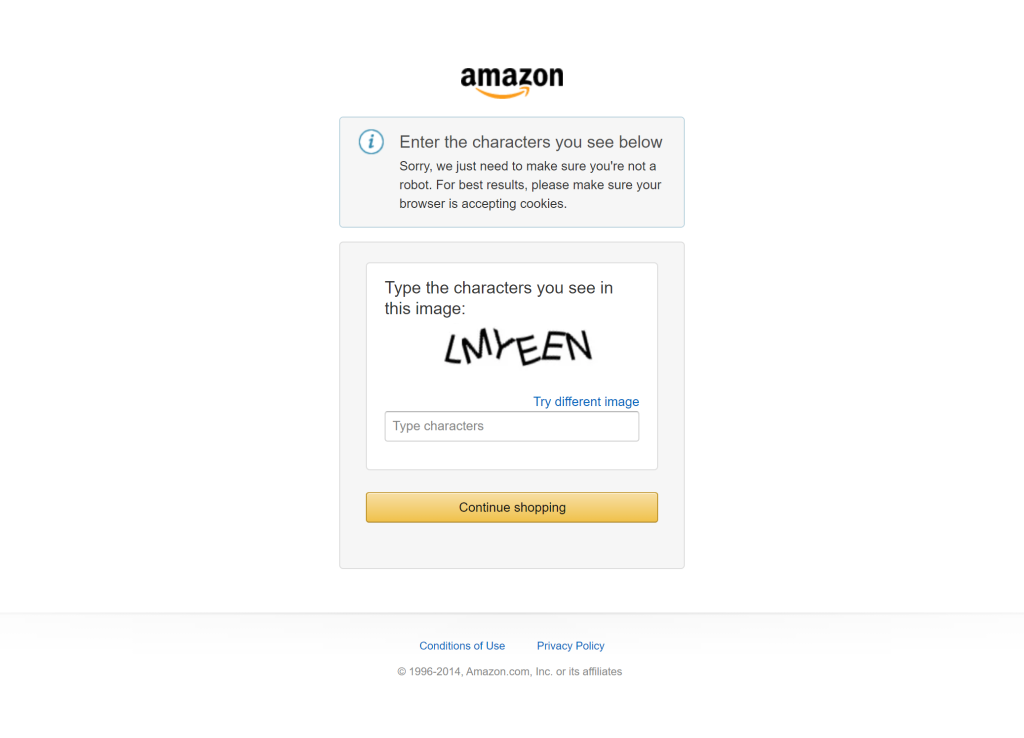
É aqui que a Bright Data entra em cena!
A Bright Data oferece um conjunto completo de soluções para obter dados da Web em formatos brutos e estruturados de praticamente qualquer site. Com a rotação de IP, a impressão digital do navegador, a Resolução de CAPTCHA e muitos outros aspectos essenciais tratados automaticamente, você não precisa se preocupar com bloqueios ou restrições.
Especificamente, usaremos os dados de produtos da Amazon retornados pela API Amazon Scraper da Bright Data. Isso permite que você recupere dados novos de produtos da Amazon simplesmente chamando um ponto de extremidade da API.
Veja como o Firebase Studio e a Bright Data trabalham juntos para criar rapidamente uma experiência na Web semelhante à do CamelCamelCamel!
Como criar um rastreador de preços da Amazon como o CamelCamelCamel no Firebase Studio
Siga as etapas abaixo para saber como criar um aplicativo da Web semelhante ao CamelCamelCamel que rastreia os preços da Amazon. Integre o Bright Data em seu protótipo do Firebase Studio!
Pré-requisitos
Para acompanhar este tutorial, certifique-se de que você tenha:
- Uma conta do Google
- Uma conta do Firebase Studio
- Uma chave de API Gemini
- Um banco de dados do Firestore configurado e pronto para ser conectado via API
- Uma conta da Bright Data com uma chave de API configurada
Observação: Não se preocupe em configurar tudo ainda, pois você será guiado pelas etapas à medida que avançarmos.
Você também precisará de:
- Conhecimento do desenvolvimento do Next.js em TypeScript
- Familiaridade com o funcionamento da API do Bright Data Scraper (consulte os documentos do Bright Data para obter mais detalhes)
Etapa 1: Configurar o Firebase Studio
Acesse o site do Firebase Studio e clique no botão “Get Started” (Iniciar):

Você será solicitado a fazer login com uma de suas contas do Google. Selecione uma delas e continue.
Uma vez conectado, você chegará à página de criação de aplicativos:
Aqui, você pode inserir um prompt para pedir à IA que inicialize o projeto para você. Ótimo!
Etapa 2: elaborar o prompt
Lembre-se de que seu objetivo aqui é criar uma alternativa ao CamelCamelCamel. Em termos simples, esse aplicativo da Web deve permitir que os usuários monitorem os preços dos produtos da Amazon a partir de uma lista de itens.
Ao trabalhar com uma solução como o Firebase Studio(ou v0), a engenharia de prompt é fundamental. Portanto, reserve um tempo para criar o melhor prompt possível. Para obter resultados de alta qualidade, você precisará de um prompt bem estruturado. Veja abaixo algumas práticas recomendadas:
- Concentre-se apenas nos recursos principais. Quanto mais você adicionar, maior será o risco de um código bagunçado e difícil de depurar.
- Indique claramente as tecnologias que deseja usar (front-end, back-end, banco de dados etc.).
- Mencione que você lidará com a integração do Bright Data mais tarde. Por enquanto, uma lógica simulada é suficiente.
- Use uma lista numerada para dividir as principais tarefas.
- Mantenha o prompt detalhado, mas conciso. Se ele for muito longo, a IA poderá ficar confusa.
Este é um exemplo de um prompt sólido que você pode usar:
## Objetivo
Criar um aplicativo da Web Next.js para rastrear os preços dos produtos da Amazon.
## Requisitos
### 1. Página de destino
- Uma página de índice com uma interface de usuário limpa e um formulário em que os usuários podem enviar um URL de produto da Amazon.
### 2. Manuseio de dados
- Quando um usuário envia um URL:
- Chame um endpoint de API simulado (representando o Amazon Scraper da Bright Data) para obter detalhes do produto:
- URL
- Título do produto
- Preço
- Imagem
- ASIN
- ...
- Armazene os dados desse produto no Firestore.
- Adicione o produto a um painel de produtos com uma lista de cartões mostrando cada produto. Quando clicado, cada cartão de produto deve levar a uma página específica do produto.
### 3. Rastreamento de preços
- Crie um trabalho agendado (por exemplo, uma vez por dia) que chame novamente a API Bright Data simulada para cada produto salvo.
- Salve cada novo registro de preço no Firestore, usando o ASIN do produto como ID e anexando ao seu histórico de preços.
### 4. Página do produto
- Na página do produto, exiba uma tabela com:
- Informações do produto (título, imagem, URL, etc.)
- Preço mais recente
- Histórico de preços (como linhas em uma tabela ou, idealmente, um gráfico simples mostrando a evolução do preço)
---
**Importante**:
- Implemente as chamadas externas da API Bright Data como funções simuladas que retornam JSON estático. Posteriormente, substituirei essas funções pela integração real da API.
## Pilha técnica
- Next.js com TailwindCSS para estilização
- Firestore como o banco de dados (com uma coleção chamada "products")
## Ações
Faça um andaime de toda a estrutura do projeto, com páginas, esquema do Firestore, funções de API simuladas e a função programada para atualizações diárias de preços.Observe como o prompt está escrito no formato Markdown, o que facilita a organização e a divisão da tarefa em seções. Além disso, os modelos de IA geralmente entendem Markdown muito bem.
O prompt de exemplo acima segue todas as práticas recomendadas e ajudará a IA a criar com êxito o aplicativo pretendido. Perfeito!
Etapa 3: Executar o prompt e explorar os primeiros resultados
Cole seu prompt na área de texto “Prototype an app with IA” (Prototipar um aplicativo com IA) no Firebase Studio e pressione Enter.
O agente de prototipagem de aplicativos do Firebase Studio gerará um projeto de aplicativo contendo todas as informações principais:
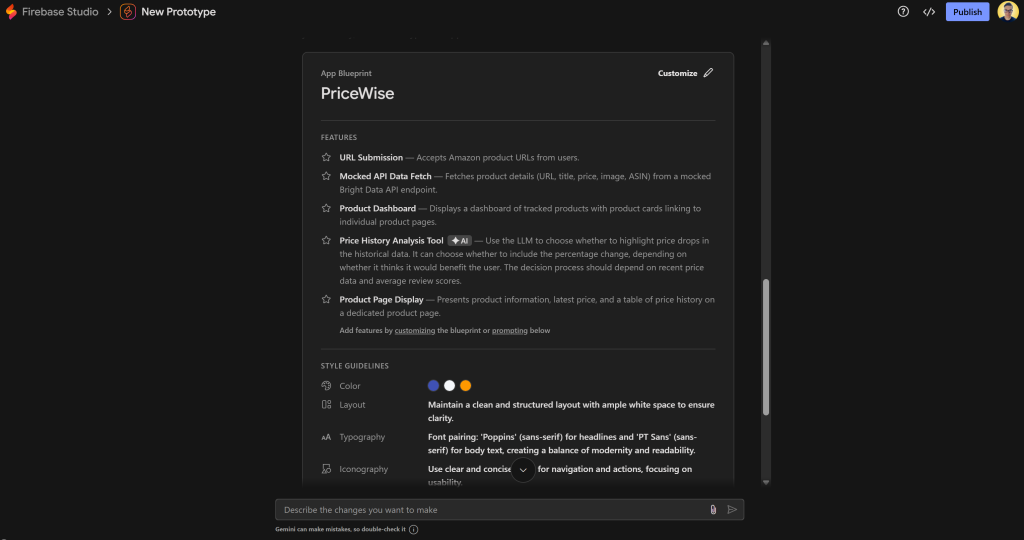
Sinta-se à vontade para personalizar e refinar o projeto para atender melhor às suas necessidades.
Quando estiver pronto, role a tela para baixo e clique no botão “Prototype this App” para instruir a IA a gerar o aplicativo:
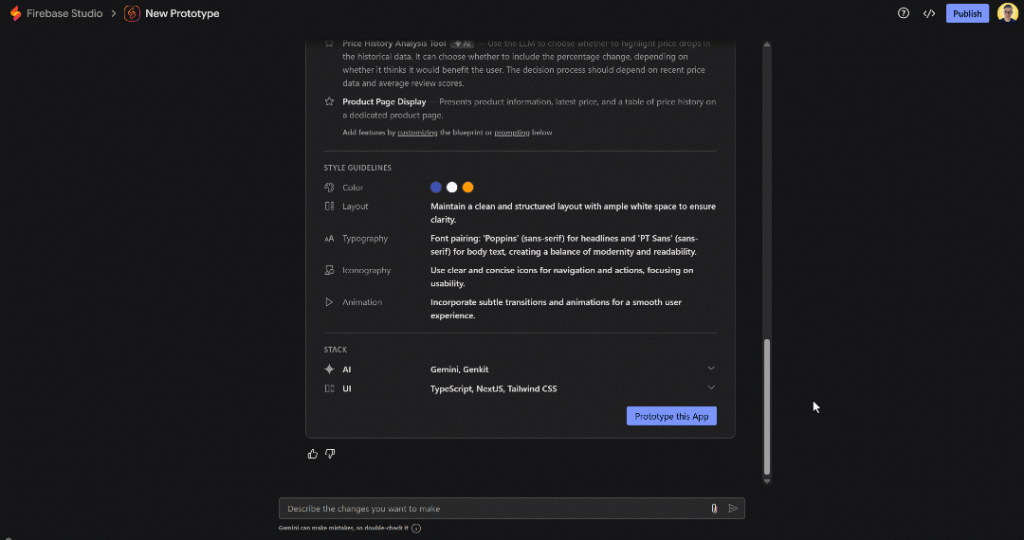
O Firebase Studio começará a criar os arquivos do seu projeto Next.js. Seja paciente, pois isso pode levar alguns minutos.
Quando o processo for concluído, você verá o protótipo em execução em uma janela de visualização:
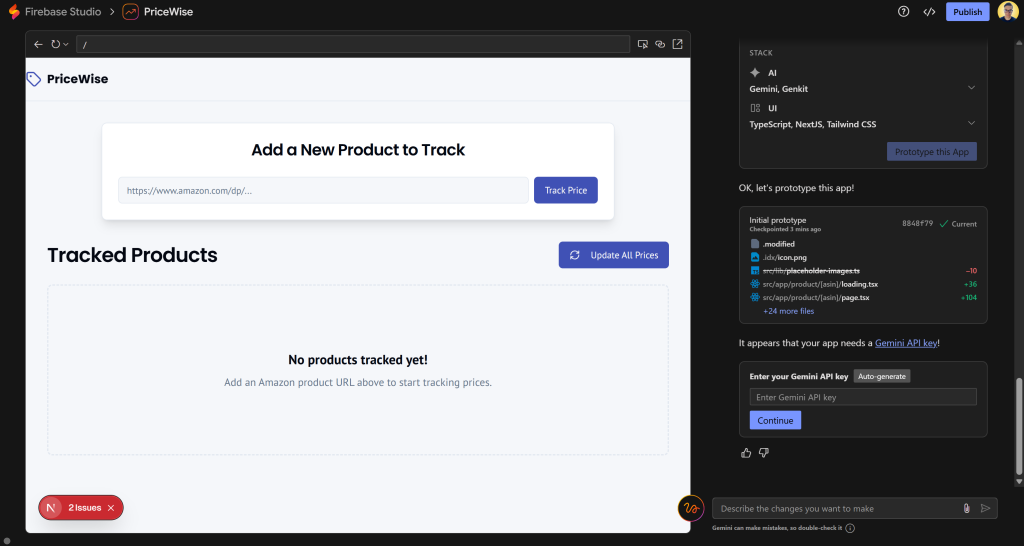
Observe como a interface do usuário do aplicativo se aproxima da estrutura que você descreveu em seu prompt. Esse já parece ser um resultado muito promissor!
Etapa 4: concluir a integração com o Gemini
No canto inferior esquerdo, você verá um prompt solicitando a conclusão da integração com o Gemini inserindo a chave da API do Gemini:
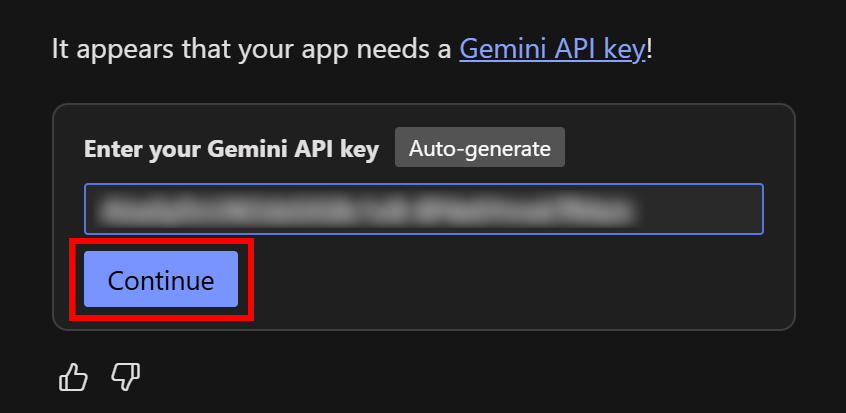
Recupere sua chave da API do Gemini no Google IA Studio, cole-a no campo e pressione o botão “Continue” (Continuar). Se tudo funcionar corretamente, você deverá receber uma mensagem de sucesso como esta:
Enquanto isso, o Firebase Studio deve terminar automaticamente de carregar seu ambiente de desenvolvimento (com base no Visual Studio Code). Caso contrário, acesse-o clicando no botão “Switch to Code”. O que você verá é o seguinte:
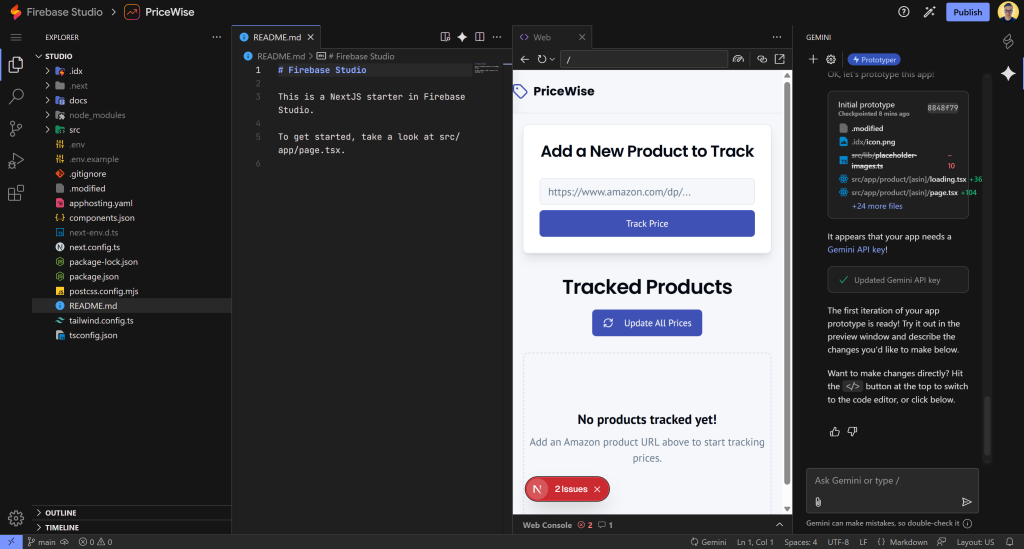
No lado direito, você verá um painel Gemini dentro de sua configuração de codificação. A partir daqui, você pode pedir ao Gemini dicas contextuais, novos recursos, correções e orientações enquanto constrói. Muito bem!
Etapa 5: Corrigir os problemas
Como você pode ver na guia de visualização “Web” (mostrada nas capturas de tela anteriores), o aplicativo atual tem dois problemas. Isso é completamente normal, pois o código gerado por IA raramente é perfeito e geralmente requer ajustes e correções.
Antes de prosseguir, examine os problemas relatados. Use os elementos visuais do Next.js no aplicativo para identificar o que está quebrado e conserte-os um a um. Afinal de contas, não faz muito sentido construir sobre um aplicativo quebrado.
Para depuração no lado do servidor, verifique os registros no painel “OUTPUT”. Pressione Ctrl + <backtick> para abrir a seção Terminal. Lá, mude para a guia “OUTPUT” e selecione o elemento “Previews”:
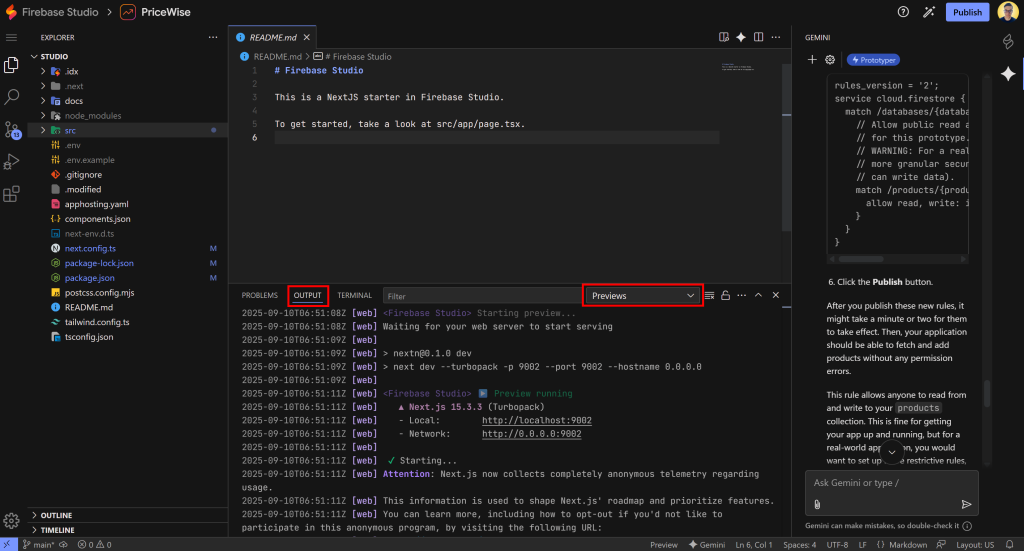
Lembre-se: você também pode pedir ajuda ao Gemini para corrigir esses problemas, informando-o diretamente sobre os erros que receber.
Depois de corrigir todos os problemas, seu aplicativo deverá ter a seguinte aparência:
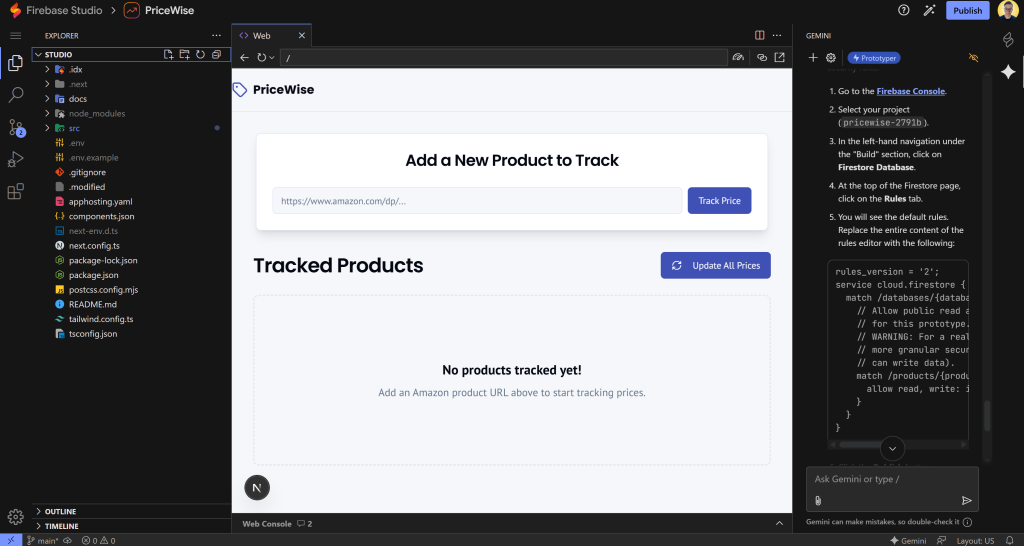
Observe que o indicador “Issues” (Problemas) no canto superior esquerdo desapareceu, o que significa que todos os problemas do Next.js foram resolvidos!
Etapa nº 6: Configurar o Firestore
Um dos excelentes recursos do Firebase Studio é que ele é executado diretamente no ambiente do Firebase, facilitando a integração com todos os outros produtos do Firebase.
Neste projeto, você precisará configurar um banco de dados do Firestore para que seu aplicativo possa ler e armazenar dados, mantendo o controle de seu estado. Isso é necessário porque o Firestore foi especificado como a tecnologia de banco de dados no prompt.
Dica: Para uma integração simplificada, você pode pedir ao Gemini que o oriente durante toda a tarefa.
Comece fazendo login no Firebase e criando um novo projeto:
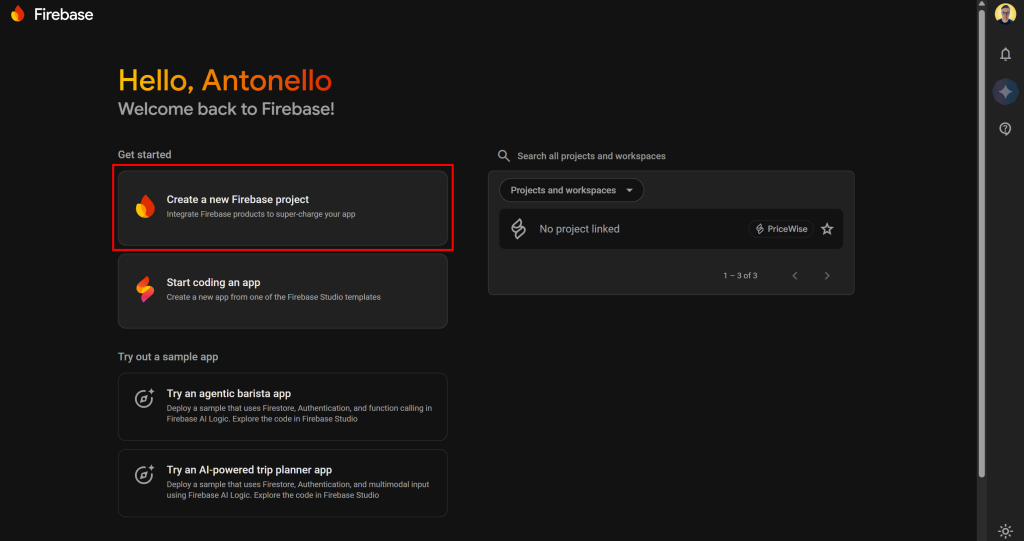
Dê um nome ao seu projeto e siga o assistente de criação de projeto. O Firebase começará a criar seu projeto:
Pressione o botão “+ add app” e selecione o ícone do aplicativo Web para inicializar um novo aplicativo Web do Firebase:

Dê um nome ao seu aplicativo Web e siga as instruções. No final, você receberá um snippet de conexão com a configuração do Firebase:
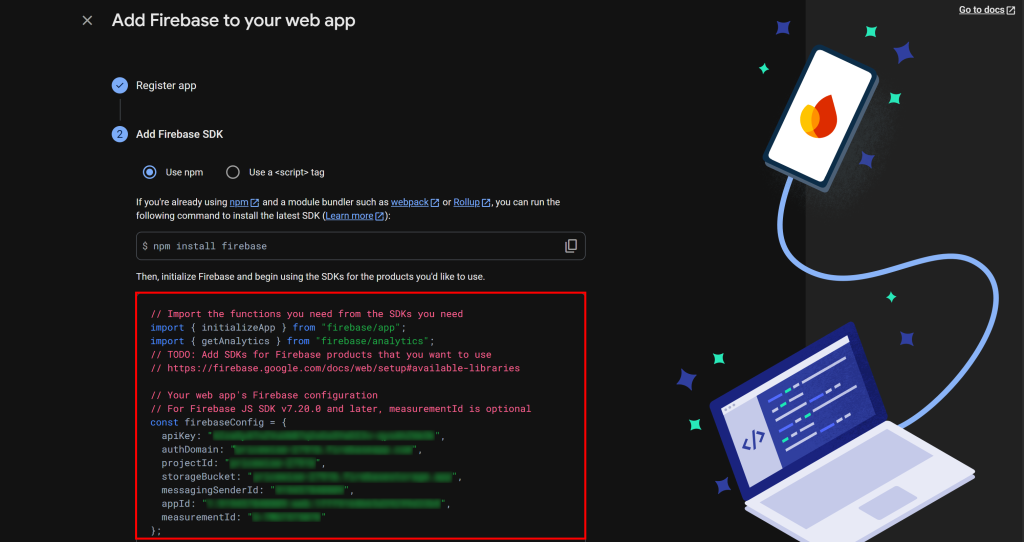
Salve essas credenciais do objeto firebaseConfig em um local seguro, pois você precisará delas para conectar seu aplicativo protótipo ao Firebase.
Em seguida, na página do seu projeto no Console do Firebase, na seção “Build” (Construir), selecione a opção “Firestore Database” (Banco de dados do Firestore):
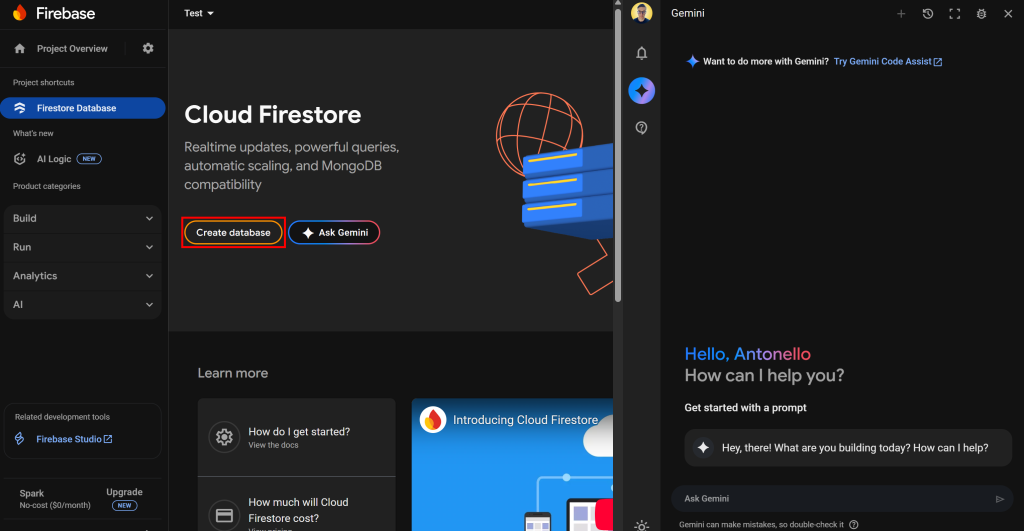
Clique no botão “Create database” (Criar banco de dados) e inicialize um banco de dados padrão no modo de produção:
Na parte superior da página do Firestore, acesse a guia “Rules” (Regras). Adicione as seguintes regras para permitir a leitura e a gravação:
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /{document=**} {
permitir leitura, gravação: se verdadeiro;
}
}
}Em seguida, clique em “Publish” (Publicar) para atualizar suas regras:
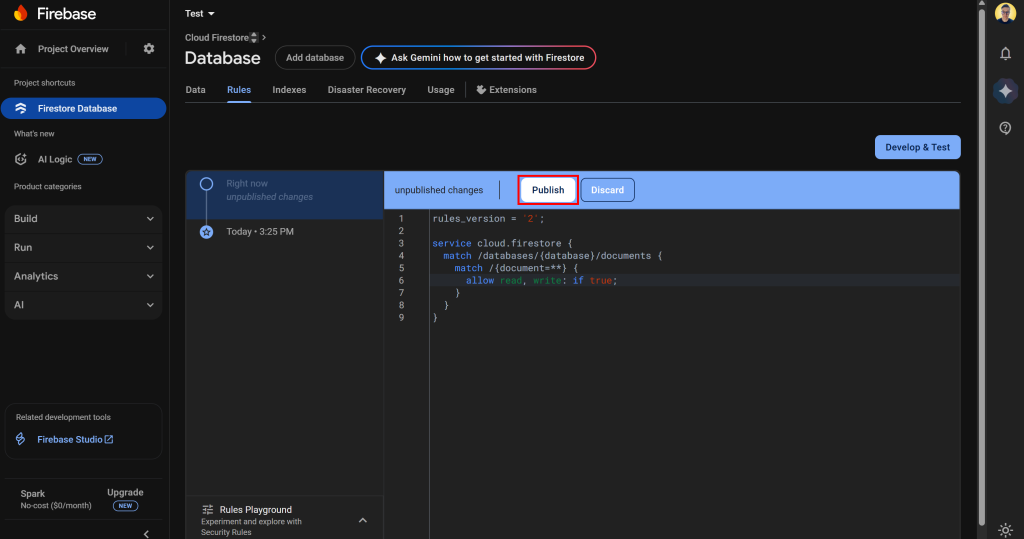
Observação: essas regras tornam seu banco de dados público, de modo que qualquer pessoa pode ler, modificar ou excluir dados. Isso é bom para um protótipo, mas na produção, você deve configurar regras mais seguras e granulares.
Crie uma nova coleção chamada products (o mesmo nome especificado no prompt):
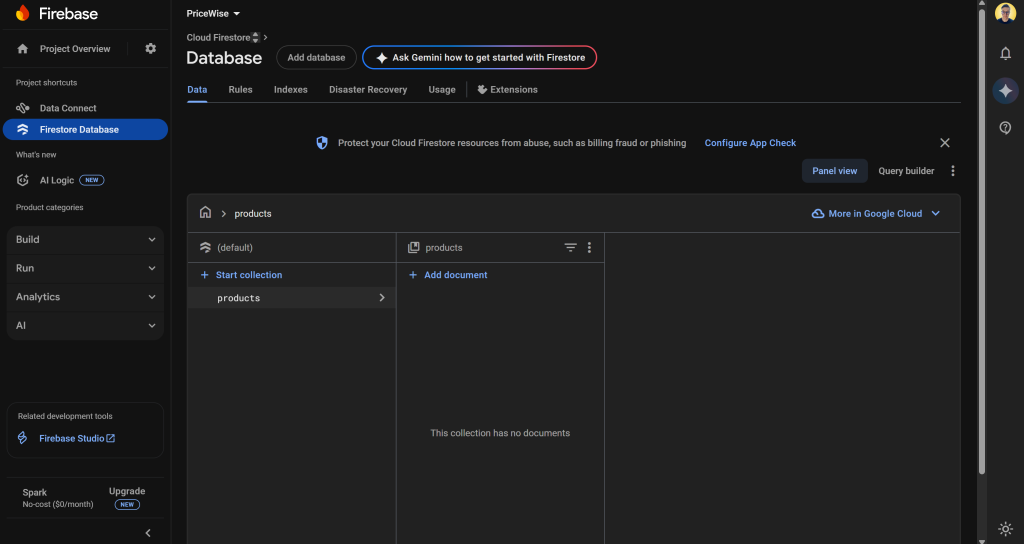
Prossiga criando uma nova entrada e definindo o campo asinc como uma chave de cadeia de caracteres. Depois de testar se seu aplicativo pode gravar com êxito no Firestore, lembre-se de excluir essa entrada de amostra.
Agora, no Console do Google Cloud, navegue até a página “API do Google Cloud Firestore“. Aqui, ative sua API:
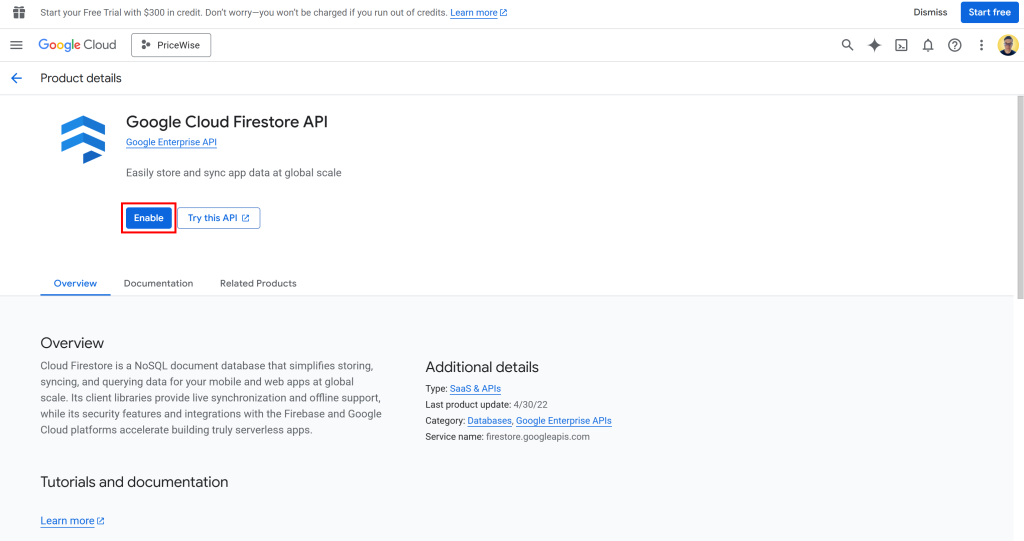
O campo apiKey fornecido no objeto firebaseConfig agora pode ser usado para se conectar ao seu banco de dados do Firestore.
Pronto! Agora você tem um banco de dados Firestore pronto para ser integrado ao seu aplicativo Firebase Studio.
Etapa 7: conectar-se ao Firestore
De volta ao Firebase Studio, inspecione seu projeto. Em algum lugar da sua estrutura de arquivos, você deve ver um arquivo para a conexão do Firestore. Nesse caso, é src/lib/firebase.ts:
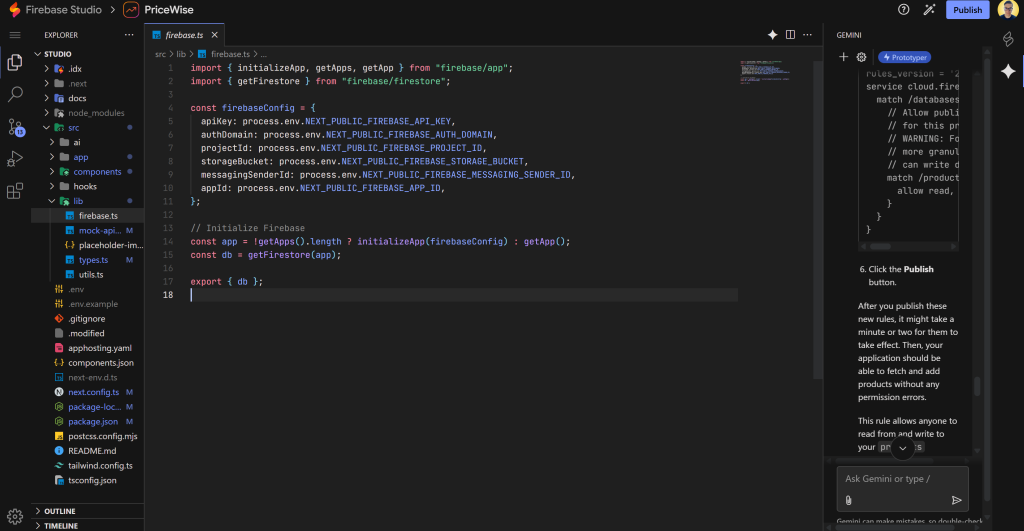
Como você pode ver, esse arquivo espera que as credenciais de conexão do Firebase sejam definidas nas variáveis de ambiente público do Next.js. Adicione-as ao arquivo .env (que deve ter sido criado pela IA; caso contrário, crie-o você mesmo):
NEXT_PUBLIC_FIREBASE_API_KEY="<SEU_FIREBASE_API_KEY>"
NEXT_PUBLIC_FIREBASE_AUTH_DOMAIN="<SEU_FIREBASE_AUTH_DOMAIN>"
NEXT_PUBLIC_FIREBASE_PROJECT_ID="<FIREBASE_PROJECT_ID>"
NEXT_PUBLIC_FIREBASE_STORAGE_BUCKET="<SEU_FIREBASE_STORAGE_BUCKET>"
NEXT_PUBLIC_FIREBASE_MESSAGING_SENDER_ID="<SEU_FIREBASE_MESSAGING_SENDER_ID>"
NEXT_PUBLIC_FIREBASE_APP_ID="<SEU_FIREBASE_APP_ID>"Observação: esses valores vêm do objeto firebaseConfig que você obteve anteriormente.
Na guia “Web”, execute uma reinicialização forçada para garantir que todas as alterações sejam recarregadas corretamente. Seu aplicativo Firebase agora deve ser capaz de se conectar ao Firestore.
Se quiser verificar se o aplicativo está operando corretamente na coleção de produtos, explore o código. Você deverá ver algo parecido com isto:
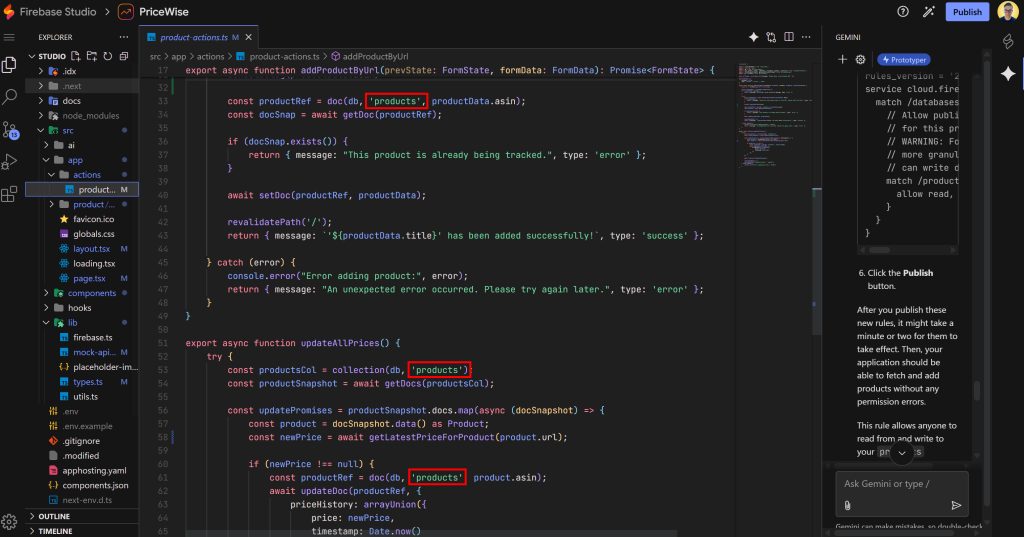
Observe que o aplicativo funciona na coleção de produtos como pretendido.
Legal! Um passo mais perto de concluir seu protótipo.
Etapa 8: Integrar dados brilhantes
Atualmente, a lógica de recuperação de informações e preços de produtos da Amazon é simulada (neste caso, em um arquivo src/lib/mock-api.ts ):
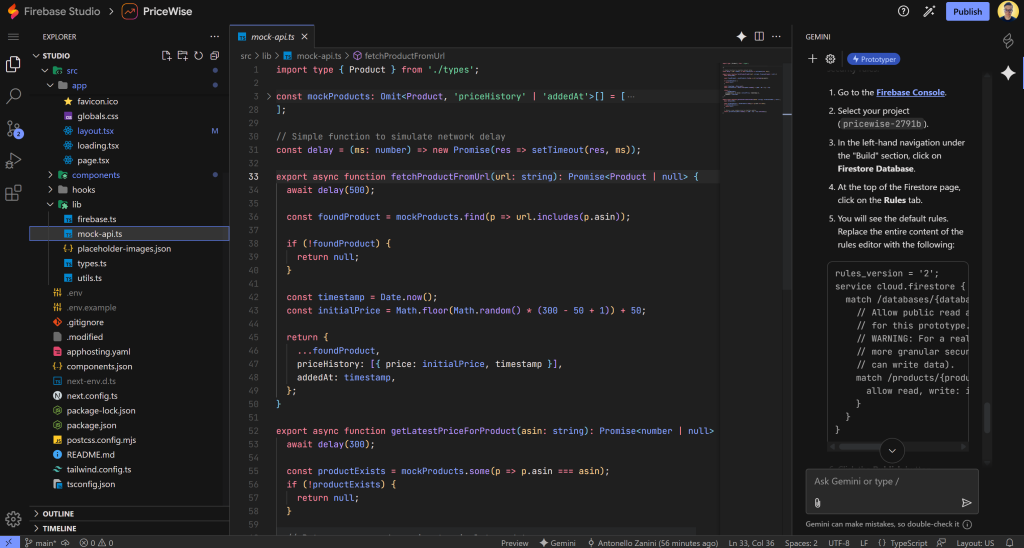
Esse arquivo contém as duas principais funções de recuperação de dados de baixo nível que são chamadas na lógica comercial dos botões “Track Price” e Update All Prices”:
Especificamente, o mock-api.ts define as duas funções:
fetchProductFromUrl(): Simula a busca de informações de produtos da Amazon a partir de um determinado URL de produto.getLatestPriceForProduct(): simula a obtenção do preço mais recente de um determinado produto da Amazon.
O que você precisa fazer em seguida é substituir essa lógica de simulação por chamadas reais para o Amazon Scraper da Bright Data via API.
Comece fazendo login na sua conta da Bright Data ou criando uma nova conta, caso ainda não o tenha feito. Navegue até a guia “API Request Builder” para o scraper “Amazon Products – Collect by URL“. Selecione a opção “Node (Axios)” para obter um trecho de código mostrando como chamar a API para recuperar dados do produto:
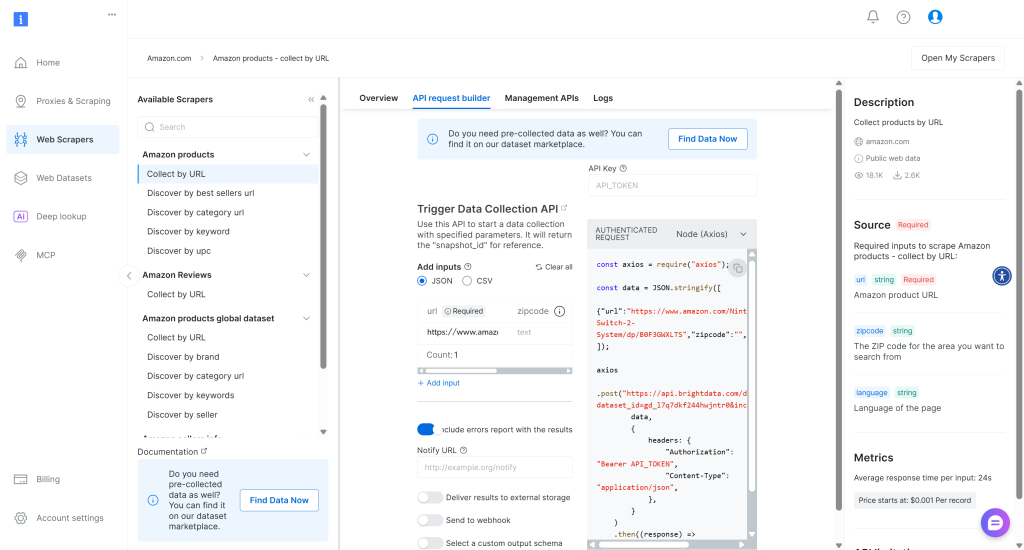
Se você não estiver familiarizado com o funcionamento das APIs do Web Scraper da Bright Data, vamos dar uma breve explicação.
Você começa acionando uma tarefa de raspagem usando o ponto de extremidade /trigger, que cria um instantâneo de raspagem para o URL do produto especificado. Depois que o instantâneo é iniciado, você verifica periodicamente seu status usando o ponto de extremidade snapshot/{snapshot_id} para ver se os dados raspados estão prontos. Quando estiverem prontos, você chamará a mesma API para obter os dados extraídos.
Essas APIs do Web Scraper podem ser chamadas programaticamente por meio da autenticação com sua chave de API do Bright Data. Siga o guia oficial para obter a chave e, em seguida, adicione-a ao seu arquivo .env da seguinte forma:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Basicamente, o que você precisa fazer é:
- Chamar o endpoint
/triggercom o URL do produto para iniciar uma nova tarefa de raspagem, autenticando usando o token da API da Bright Data. - Iniciar um processo de sondagem no
snapshot/{snapshot_id}para verificar periodicamente se o snapshot que contém os dados extraídos está pronto. - Quando o instantâneo estiver pronto, acesse os dados do produto Amazon.
Para começar, instale o cliente HTTP Axios em seu projeto com:
npm install axios
Em seguida, substitua o conteúdo de src/lib/mock-api.ts pela seguinte lógica:
'use server'
importar axios de 'axios';
importar type { Product } de './types';
// acessar sua chave da API da Bright Data a partir dos envs
const BRIGHT_DATA_API_KEY = process.env.BRIGHT_DATA_API_KEY;
// criar um cliente Axios personalizado para conexão com o
// Scraper amazônico de dados brilhantes
const client = axios.create({
headers: {
Authorization: `Bearer ${BRIGHT_DATA_API_KEY}`,
'Content-Type': 'application/json',
},
});
função assíncrona triggerAndPoll(url: string): Promise<Product> {
// aciona um novo snapshot
const triggerRes = await client.post(
'https://api.brightdata.com/datasets/v3/trigger',
[{
'url': url
}],
{
params: {
dataset_id: 'gd_l7q7dkf244hwjntr0', // ID do conjunto de dados da Amazon
include_errors: true, // para depuração
},
}
);
// obter o ID do snapshot
const snapshotId = triggerRes.data?.snapshot_id;
// tentar até 600 vezes recuperar os dados do instantâneo
const maxAttempts = 600;
let attempts = 0;
while (attempts < maxAttempts) {
try {
// verificar se os dados estão disponíveis
const snapshotRes = await client.get(
`https://api.brightdata.com/datasets/v3/snapshot/${snapshotId}`,
{
params: { format: 'json' },
}
);
// se os dados não estiverem disponíveis (a tarefa de raspagem ainda não terminou)
const status = snapshotRes.data?.status;
se (['running', 'building'].includes(status)) {
attempts++;
// esperar por 1 segundo
aguardar nova Promise((resolve) => setTimeout(resolve, 1000));
continue;
}
// se os dados estiverem disponíveis
return snapshotRes.data[0] as Product;
} catch (err) {
tentativas++;
// esperar por 1 segundo
aguardar nova Promise((resolve) => setTimeout(resolve, 1000));
}
}
throw new Error(
`Timeout after ${maxAttempts} seconds waiting for snapshot data`
);
}
export async function fetchProductFromUrl(url: string): Promise<Product | null> {
const productData = await triggerAndPoll(url);
const timestamp = Date.now();
const initialPrice = productData.final_price;
se (initialPrice) {
productData['priceHistory'] = [{ price: initialPrice, timestamp }]
}
return productData
}
export async function getLatestPriceForProduct(url: string): Promise<number | null> {
const productData = await triggerAndPoll(url);
return productData.final_price || null
}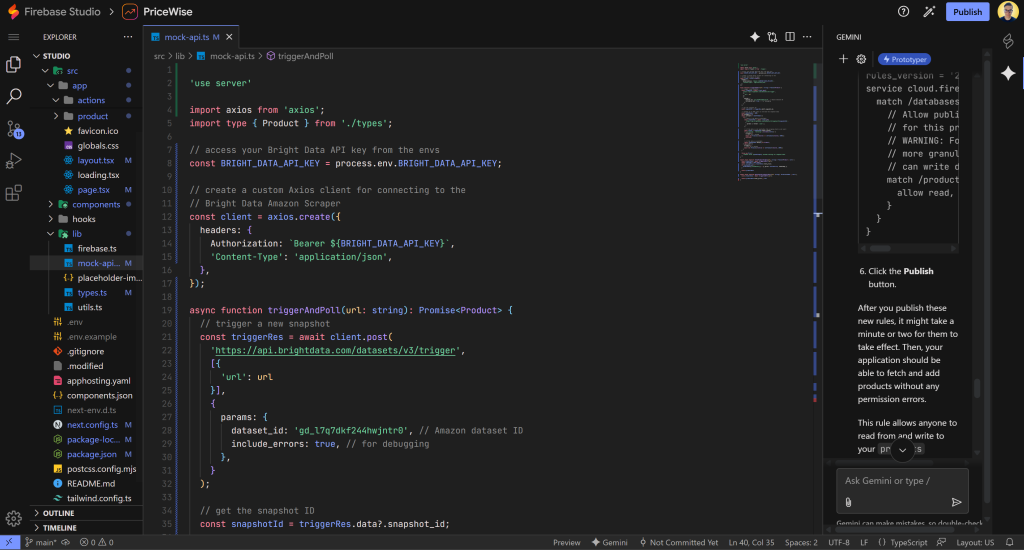
A nova implementação usa o Axios para se conectar ao Bright Data, aciona um instantâneo para um determinado URL, faz uma pesquisa até que os dados estejam prontos e retorna as informações do produto.
O utilitário triggerAndPoll() manipula toda a lógica de recuperação de dados da API Bright Data Scraper. fetchProductFromUrl() retorna o objeto de produto completo com um histórico de preço inicial, enquanto getLatestPriceForProduct() retorna apenas o preço atual lido do campo final_price.
Para entender quais campos são retornados pela API do Bright Data Amazon Scraper, explore a seção “Overview” (Visão geral) no seu painel:
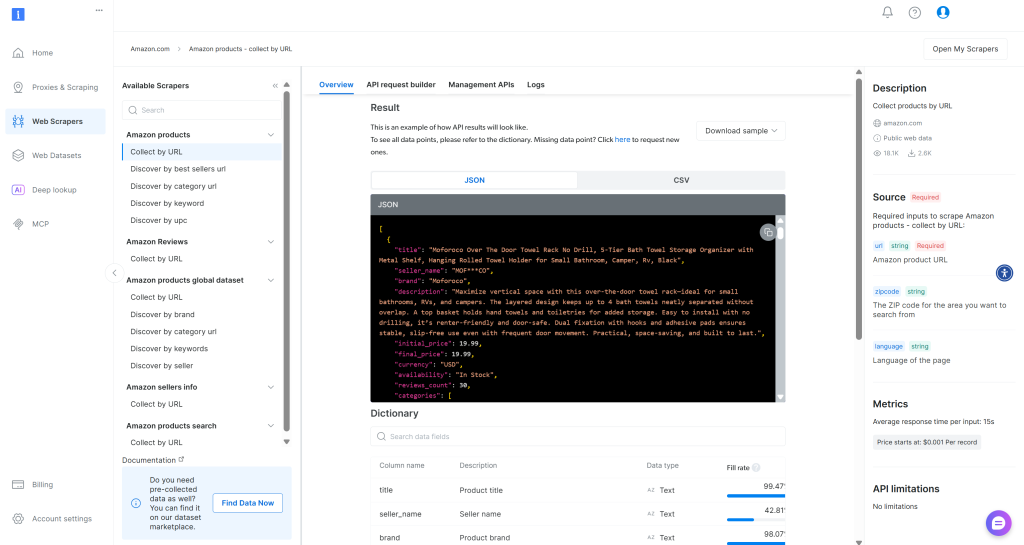
Envie o JSON de amostra para o Gemini e peça à IA para atualizar o tipo de produto TypeScript de acordo:
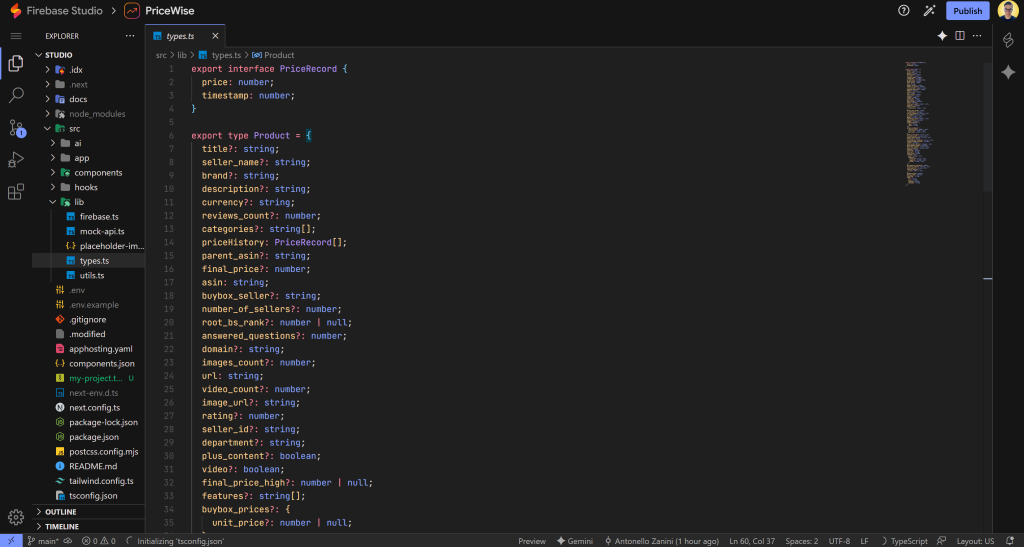
Fantástico! Não são necessárias outras etapas. Neste ponto, seu aplicativo deve estar totalmente funcional e pronto para testes, com dados de produtos ao vivo sendo obtidos e exibidos.
Etapa 9: testar o protótipo do aplicativo
Sua alternativa CamelCamelCamel agora está pronta. Você pode encontrar o código completo no repositório do GitHub que dá suporte a este artigo. Clone-o com:
git clone https://github.com/Tonel/price-wiseIsso não é nada mais do que um MVP(Minimal Viable Product, produto mínimo viável), mas é totalmente funcional o suficiente para explorar suas ideias e até mesmo estendê-lo para um aplicativo pronto para produção.
Para garantir que todas as atualizações em sua base de código sejam aplicadas, execute uma reinicialização forçada:

Em seguida, clique no ícone “Open in New Window” (Abrir em nova janela):

Agora você deve ter acesso ao protótipo do Firebase Studio em uma guia dedicada do navegador:
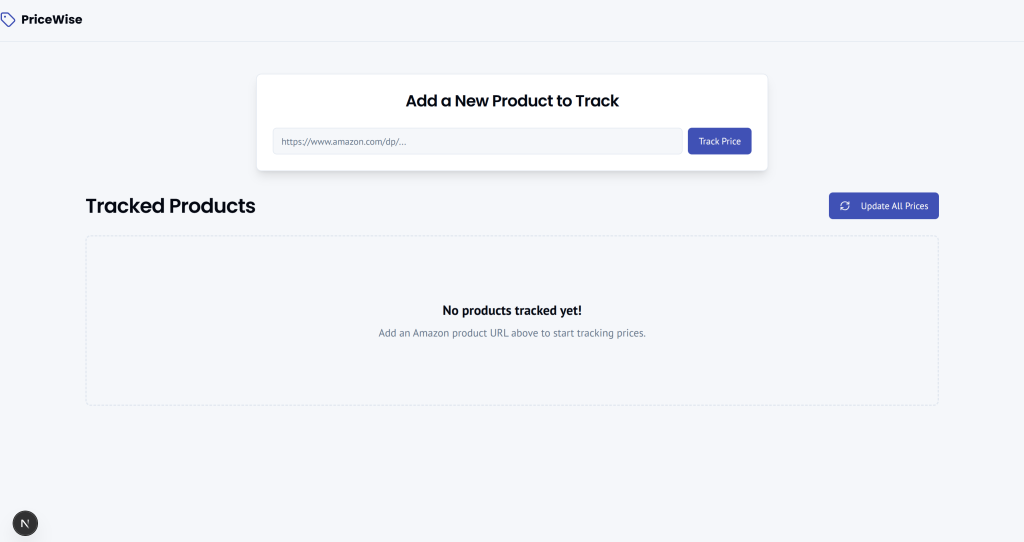
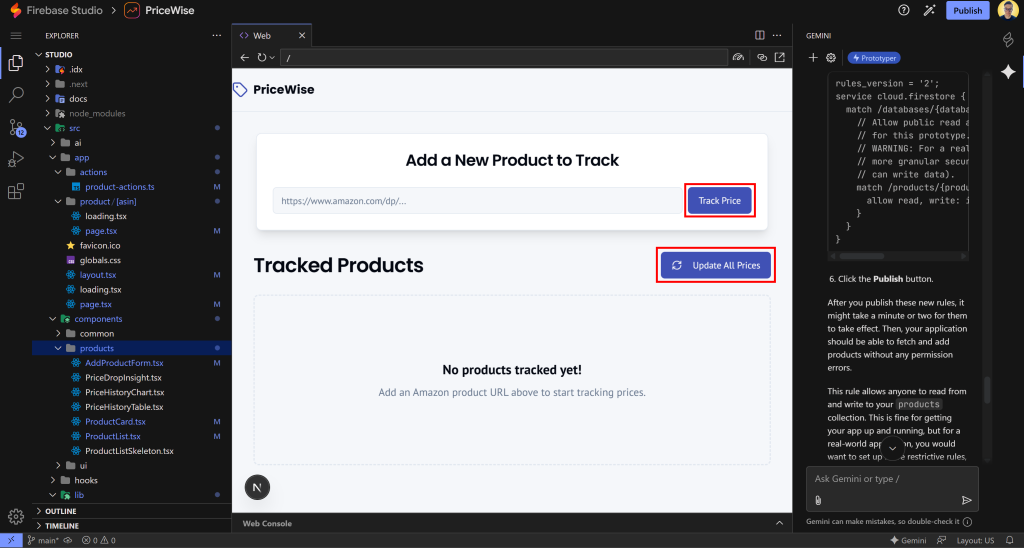
Teste o aplicativo da Web semelhante ao CamelCamelCamel colando o URL de um produto da Amazon e pressionando o botão “Track Price” (Rastrear preço):
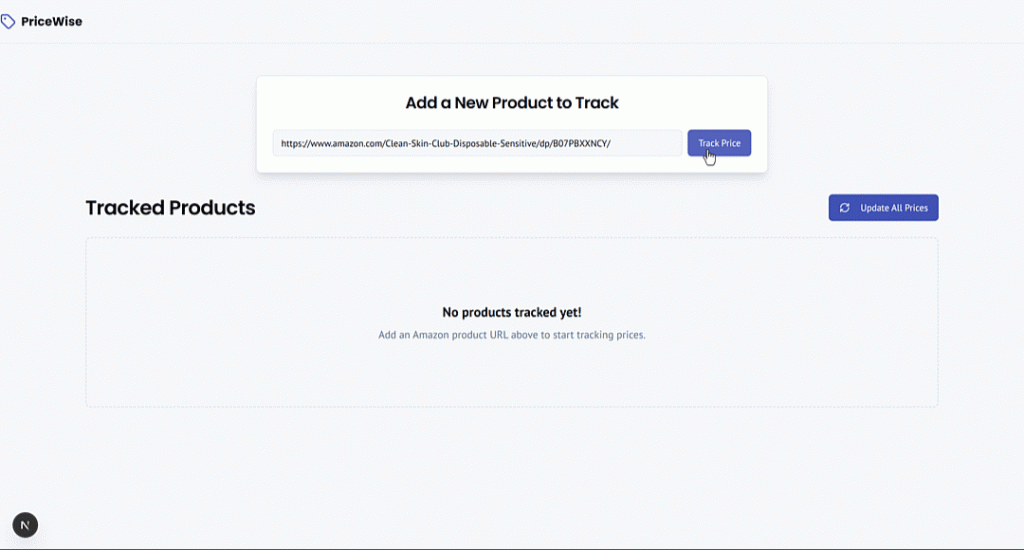
O produto será adicionado à seção “Tracked Products” (Produtos rastreados), exibindo os dados exatamente como aparecem na página da Amazon.
Isso demonstra o poder da API Bright Data Web Scraper, que recuperou com êxito os dados do produto em segundos.
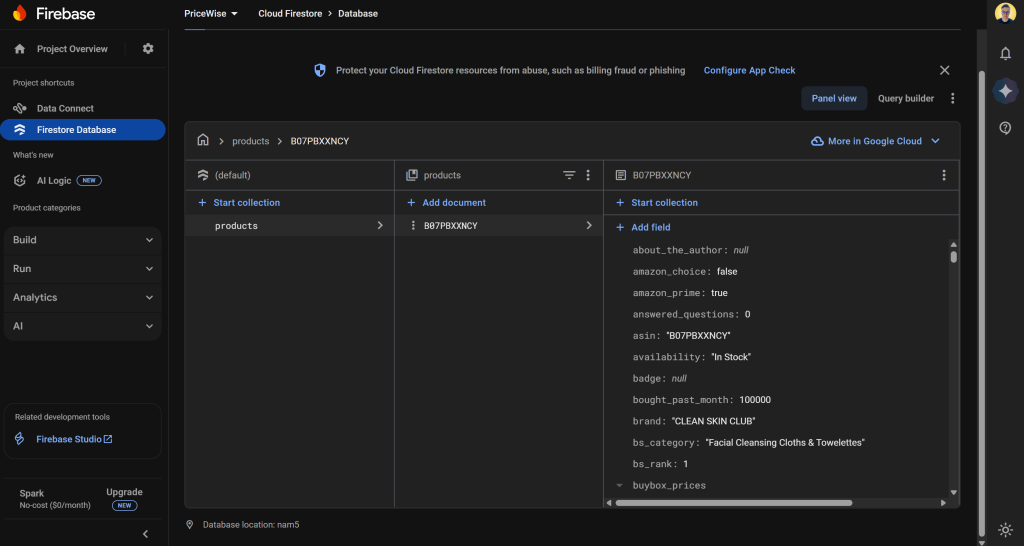
Verifique se os dados do produto foram armazenados no banco de dados do Firestore:
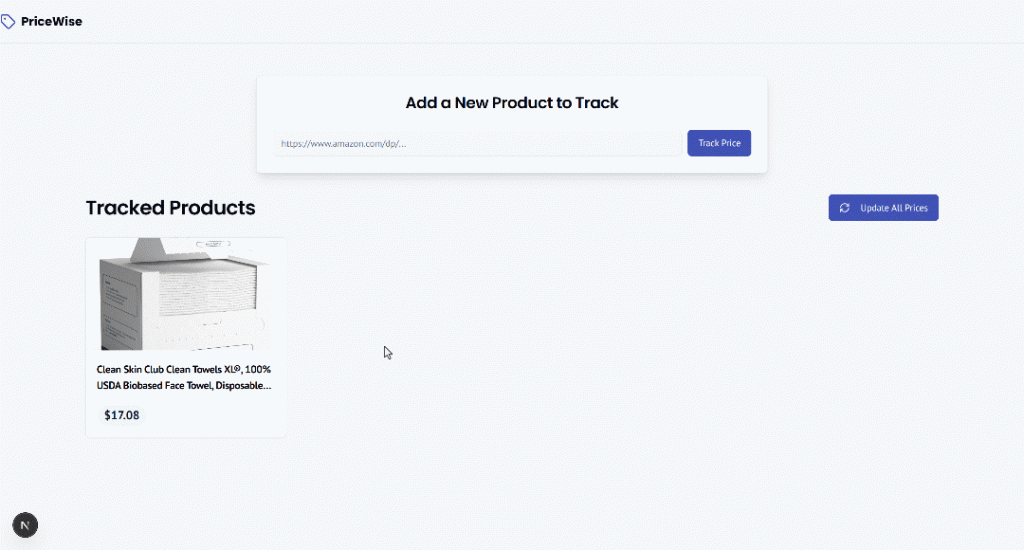
Agora, suponha que alguns dias se passaram e o preço flutuou. Visite a página do produto para ver o preço atualizado:
Mais detalhadamente, observe como a página do produto contém um gráfico e uma tabela que mostram a evolução do preço desse produto:
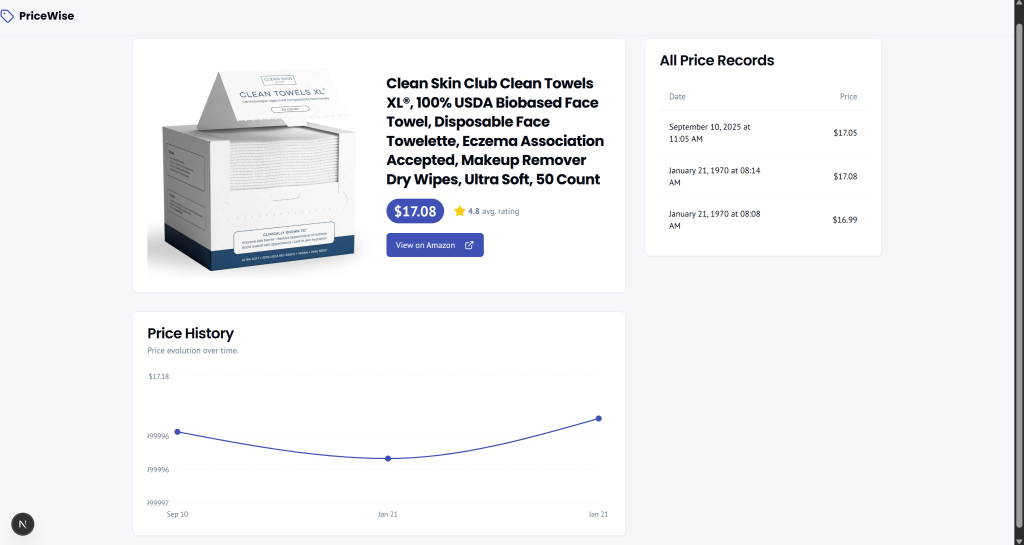
Impressionante, não é?
E pronto! Em apenas alguns minutos e com pouquíssimo código, você criou um aplicativo da Web no estilo CamelCamelCamel para rastreamento de preços de produtos da Amazon. Nada disso teria sido possível sem os recursos de dados da Web em tempo real da Bright Data e o ambiente de desenvolvimento simplificado do Firebase Studio.
Próximas etapas
O aplicativo criado aqui é apenas um protótipo. Para torná-lo pronto para produção, considere as seguintes etapas:
- Integrar a autenticação: Use o Firebase Authentication para adicionar rapidamente um sistema de login para que cada usuário possa salvar e monitorar seus próprios produtos.
- Adicione mais recursos: Continue a iteração no Gemini solicitando novos recursos ou baixe o código do projeto e integre manualmente a funcionalidade adicional.
- Torne seu aplicativo público: Publique seu aplicativo usando uma das opções de implantação oferecidas pelo Firebase Studio.
Conclusão
Nesta postagem do blog, você viu como os recursos de criação de aplicativos orientados por IA do Firebase Studio podem ajudá-lo a criar um site concorrente do CamelCamelCamel em apenas alguns minutos. Isso não seria possível sem uma fonte confiável e fácil de integrar de dados de produtos e preços da Amazon, como o Amazon Scraper da Bright Data.
O que criamos aqui é apenas um exemplo do que é possível quando você combina dados raspados com um aplicativo da Web dinâmico gerado por IA. Lembre-se de que uma abordagem semelhante pode ser aplicada a inúmeros outros casos de uso. Tudo o que você precisa são as ferramentas certas para acessar os dados que atendem às suas necessidades!
Por que parar aqui? Explore nossas APIs do Web Scraper, que fornecem pontos de extremidade dedicados para extrair dados da Web novos, estruturados e totalmente compatíveis de mais de 120 sites populares.
Inscreva-se hoje mesmo em uma conta gratuita da Bright Data e comece a construir com soluções de recuperação de dados da Web prontas para IA!





