

O Scraping de dados é uma forma programática de coletar dados de sites, e há inúmeros casos de uso para o Scraping de dados, incluindo Pesquisa de mercado, Monitoramento de preços, análise de dados e geração de leads.
Neste tutorial, você verá um caso de uso prático focado em uma dificuldade comum dos pais: coletar e organizar as informações enviadas pela escola. Aqui, você se concentrará nas tarefas de casa e nas informações sobre o almoço escolar.
A seguir está o diagrama da arquitetura aproximada do projeto final:
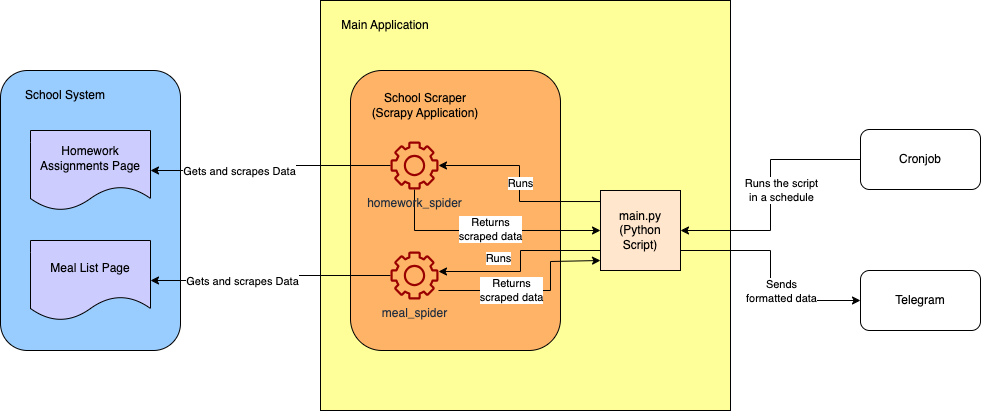
Pré-requisitos
Para acompanhar este tutorial, você precisa do seguinte:
- Python 3.10+
- ambiente virtual que tenha sido ativado
- Scrapy CLI 2.11.1
- Visual Studio Code
Por motivos de privacidade, você usará este site fictício de um sistema escolar: https://systemcraftsman.github.io/scrapy-demo/website/.
Crie o projeto
No seu terminal, crie o diretório base do projeto (você pode colocá-lo em qualquer lugar):
mkdir school-scraper
Navegue até a pasta recém-criada e crie um novo projeto Scrapy executando o seguinte comando:
cd school-Scraper &
scrapy startproject school_Scraper
A estrutura do projeto deve ficar assim:
school-scraper
└── school_scraper
├── school_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
O comando anterior cria dois níveis de diretórios school_scraper. No diretório interno, há um conjunto de arquivos gerados automaticamente: middlewares.py, onde você pode definir middlewares do Scrapy; pipelines.py, onde você pode definir pipelines personalizados para modificar seus dados; e settings.py, onde você pode definir a configuração geral para seu aplicativo de scraping.
Mais importante ainda, há uma pasta spiders onde seus spiders estão localizados. Spiders são classes Python que podem ser utilizadas para raspar um site específico de uma maneira específica. Eles seguem o princípio de separação de interesses dentro do sistema de raspagem, permitindo a criação de um spider dedicado para cada tarefa de raspagem.
Como você ainda não tem um spider gerado, essa pasta está vazia, mas na próxima etapa, você irá gerar seu primeiro spider.
Crie o Homework Spider
Para extrair dados de tarefas de casa de um sistema escolar, você precisa criar um spider que primeiro faça login no sistema e, em seguida, navegue até a página de tarefas de casa para extrair os dados:
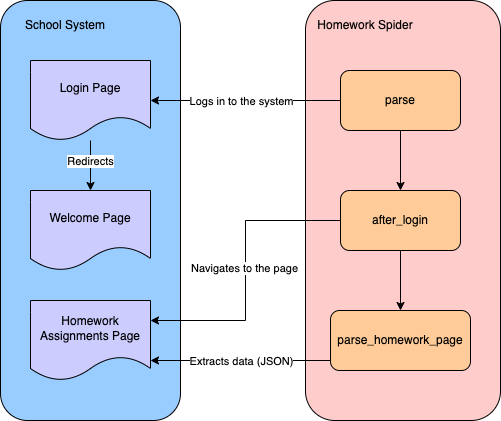
Você usará o Scrapy CLI para criar um spider para Scraping de dados. Navegue até o diretório school-scraper/school_scraper do seu projeto e execute o seguinte comando para criar um spider chamado HomeworkSpider na pasta spiders:
scrapy genspider homework_spider systemcraftsman.github.io/scrapy-demo/website/index.html
OBSERVAÇÃO: não se esqueça de executar todos os comandos relacionados ao Python ou ao Scrapy em seu ambiente virtual ativado.
O comando scrapy genspider gera o spider. O próximo parâmetro é o nome do spider (ou seja, homework_spider), e o último parâmetro define a URL inicial do spider. Dessa forma, systemcraftsman.github.io é reconhecido como um domínio permitido pelo Scrapy.
Sua saída deve ficar assim:
Aranha 'homework_spider' criada usando o modelo 'basic' no módulo:
school_scraper.spiders.homework_spider
Um arquivo chamado homework_spider.py deve ser criado no diretório school_scraper/spiders e deve ficar assim:
class HomeworkSpiderSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
Renomeie o nome da classe para HomeworkSpider para eliminar o Spider redundante no nome da classe. A função parse é a função inicial que inicia a extração. Neste caso, trata-se do login no sistema.
NOTA: O formulário de login em
https://systemcraftsman.github.io/scrapy-demo/index.htmlé um formulário de login fictício que consiste em algumas linhas de JavaScript. Como a página é HTML, ela não aceita nenhuma solicitação POST, e uma solicitação HTTP GET é usada para simular o login.
Atualize a função parse da seguinte maneira:
...código omitido...
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
Aqui, você cria uma solicitação de formulário para enviar o formulário de login dentro da página index.html. O formulário enviado deve redirecionar para o welcome_page_url definido e deve ter uma função de retorno de chamada para continuar o processo de raspagem. Você adicionará a função de retorno de chamada after_login em breve.
Defina o welcome_page_url adicionando-o no topo da classe onde outras variáveis são definidas:
...código omitido...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
...código omitido...
Em seguida, adicione a função after_login logo após a função parse na classe:
...código omitido...
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
...código omitido...
A função after_login verifica se o status da resposta é 200, o que significa que foi bem-sucedida. Em seguida, ela navega até a página de tarefas e chama a função de retorno de chamada parse_homework_page, que você definirá na próxima etapa.
Defina o homework_page_url adicionando-o no topo da classe onde as outras variáveis são definidas:
...código omitido...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
...código omitido...
Adicione a função parse_homework_page após a função after_login na classe:
...código omitido...
def parse_homework_page(self, response):
if response.status == 200:
data = {}
linhas = resposta.xpath('//*[@class="table table-file"]//tbody//tr')
para linha em linhas:
se self._get_item(linha, 4) == self.date_str:
se self._get_item(linha, 2) não estiver em dados:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
...código omitido...
A função parse_homework_page verifica se o status da resposta é 200 (ou seja, bem-sucedido); em seguida, ela analisa os dados da lição de casa, que são fornecidos em uma tabela HTML.
A função verifica o código HTTP 200 e, em seguida, usa o XPath para extrair cada linha de dados. Depois de extrair cada linha, a função itera sobre os dados e extrai os itens específicos usando a função privada _get_item, que você precisa adicionar à sua classe Spider.
A função _get_item deve ficar assim:
...código omitido...
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
A função _get_item obtém o conteúdo de cada célula usando XPath junto com os números da linha e da coluna. Se uma célula tiver mais de um parágrafo, a função os itera e acrescenta cada parágrafo.
A função parse_homework_page também requer que um date_str seja definido, que você deve definir como 12.03.2024, pois essa é a data que você tem em seu site estático.
NOTA: Em um cenário da vida real, você deve definir a data dinamicamente, pois os dados do site seriam dinâmicos.
Defina o date_str adicionando-o no topo da classe onde outras variáveis são definidas:
...código omitido...
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
...código omitido...
O arquivo final homework_spider.py fica assim:
import scrapy
from scrapy import FormRequest, Request
class HomeworkSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str
No diretório school-scraper/school_scraper, execute o seguinte comando para verificar se ele extraiu os dados da lição de casa com sucesso:
scrapy crawl homework_spider
Você deverá ver a saída extraída entre os outros registros:
...saída omitida...
2024-03-20 01:36:05 [scrapy.core.scraper] DEBUG: Extraído de <200 https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html>
{'MATHS': "Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.n", 'ENGLISH': 'Leia a história "Manny and His Monster Manners" nas páginas 100-107 do seu Diário de Leitura e complete as atividades nas páginas 108 e 109 de acordo com a história.nnLeia a história "Manny and His Monster Manners" nas páginas 100-107 do seu Diário de Leitura e complete as atividades nas páginas 108 e 109 de acordo com a história. "Manny and His Monster Manners" nimli hikayeyi okuyunuz ve 108 ve 109'uncu sayfalarındaki aktiviteleri hikayeye göre tamamlayınız.n'}
2024-03-20 01:36:05 [scrapy.core.engine] INFO: Fechando spider (concluído)
...saída omitida...
Parabéns! Você implementou seu primeiro spider. Vamos criar o próximo!
Crie o spider da lista de refeições
Para criar um spider que rastreia a página da lista de refeições, execute o seguinte comando no diretório school-scraper/school_scraper:
scrapy genspider meal_spider systemcraftsman.github.io/scrapy-demo/website/index.html
A classe spider gerada deve ficar assim:
class MealSpiderSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass
O processo de criação do spider meal é muito semelhante ao da criação do spider da lição de casa. A única diferença é a página de scraping HTML.
Para economizar tempo, substitua todo o conteúdo em meal_spider.py pelo seguinte:
import scrapy
from datetime import datetime
from scrapy import FormRequest, Request
class MealSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
url_da_página_da_refeição = "https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html"
data_str = "13.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
retornar FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
retornar Request(url=self.meal_page_url,
callback=self.parse_meal_page
)
def parse_meal_page(self, response):
if response.status == 200:
data = {"BREAKFAST": "", "LUNCH": "", "SALAD/DESSERT": "", "FRUIT TIME": ""}
week_no = datetime.strptime(self.date_str, '%d.%m.%Y').isoweekday()
rows = response.xpath('//*[@class="table table-condensed table-yemek-listesi"]//tr')
chave = ""
tente:
para linha em linhas[1:]:
se self._get_item(linha, semana_no) em dados.keys():
chave = self._get_item(linha, semana_no)
caso contrário:
dados[chave] = self._get_item(linha, semana_no, "n")
finalmente:
retorne dados
def _get_item(self, row, col_number, seperator=""):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for i, content in enumerate(contents):
item_str = item_str + content + seperator
return item_str
Observe que as funções parse e after_login são quase iguais. A única diferença é o nome da função de retorno de chamada parse_meal_page, que analisa o HTML da página de refeições usando uma lógica XPath diferente. A função também recebe ajuda de uma função privada chamada _get_item, que funciona de maneira semelhante à criada para o dever de casa.
A maneira como a tabela é usada nas páginas de lição de casa e lista de refeições é diferente, portanto, o Parsing e o tratamento dos dados também são diferentes.
Para verificar o meal_spider, execute o seguinte comando no diretório school-scraper/school_scraper:
scrapy crawl meal_spider
Sua saída deve ser semelhante a esta:
...saída omitida...
2024-03-20 02:44:42 [scrapy.core.scraper] DEBUG: Raspado de <200 https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html>
{'BREAKFAST': 'PANCAKE n KREM PEYNİR n SÜZME PEYNİR nnKAKAOLU FINDIK KREMASI n SÜTn', 'LUNCH': 'TARHANA ÇORBAnEKŞİLİ KÖFTEnERİŞTEn', 'SALAD/DESSERT': 'AYRAN n KIRMIZILAHANA SALATA n ROKALI GÖBEK SALATA n', 'FRUTAS': 'FINDIK& KURU ÜZÜM n'}
2024-03-20 02:44:42 [scrapy.core.engine] INFORMAÇÃO: Fechando spider (concluído)
...saída omitida...
NOTA: Como os dados são provenientes de um site original, nenhum deles foi traduzido para manter o formato original.
Formate os dados
Os Scrapers que você criou para as tarefas de casa e a página de listas de refeições estão prontos para extrair os dados no formato JSON. No entanto, você pode querer formatar os dados acionando os spiders programaticamente.
Em aplicativos Python, o arquivo main.py normalmente serve como ponto de entrada onde você inicializa seu aplicativo invocando seus componentes principais. No entanto, neste projeto Scrapy, você não criou um ponto de entrada porque a CLI do Scrapy fornece uma estrutura pré-construída para implementar os spiders, e você pode executá-los através da mesma CLI.
Para formatar os dados nesse cenário, você criará um programa básico de linha de comando Python que recebe argumentos e faz a extração de dados de acordo com eles.
Crie um arquivo chamado main.py no diretório raiz do seu projeto Scraper com o seguinte conteúdo:
import sys
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from school_scraper.school_scraper.spiders.homework_spider import HomeworkSpider
from school_scraper.school_scraper.spiders.meal_spider import MealSpider
results = []
class ResultsPipeline(object):
def process_item(self, item, spider):
results.append(item)
def _prepare_message(title, data_dict):
if len(data_dict.items()) == 0:
return None
message = f"===={title}====n----------------n"
for key, value in data_dict.items():
message = message + f"==={key}===n{value}n----------------n"
return message
def main(args=None):
if args is None:
args = sys.argv
settings = get_project_settings()
settings.set("ITEM_PIPELINES", {'__main__.ResultsPipeline': 1})
process = CrawlerProcess(settings)
if args[1] == "homework":
process.crawl(HomeworkSpider)
process.start()
print(_prepare_message("HOMEWORK ASSIGNMENTS", results[0]))
elif args[1] == "meal":
process.crawl(MealSpider)
process.start()
print(_prepare_message("LISTA DE REFEIÇÕES", results[0]))
if __name__ == "__main__":
main()
O arquivo main.py tem uma função principal e é a função de ponto de entrada para sua aplicação. Quando você executa o main.py, o método principal é invocado. O método principal recebe um argumento de matriz chamado args, que você pode usar para enviar argumentos ao programa.
O main.py começa verificando o valor de args e configura as definições do rastreador Scrapy, definindo um pipeline chamado ResultsPipeline. Como você pode ver, o ResultsPipeline é definido neste arquivo, mas você define os pipelines no pacote pipelines.
O ResultsPipeline simplesmente obtém os resultados e os anexa a uma matriz chamada results. Isso significa que a matriz results pode ser usada como entrada para a função privada _prepare_message, que é usada para preparar a mensagem formatada. Isso é feito por spider na função principal, e a distinção se torna possível com o segundo argumento da matriz args, que representa o tipo de spider. Se o tipo de spider for homework, o processo do rastreador chama o HomeworkSpider e o inicia. Se o tipo de spider for meal, o processo do rastreador chama o MealSpider e o inicia.
Quando um spider é iniciado, o ResultsPipeline injetado anexa os dados na matriz de resultados, e a função principal pode usá-los para cada spider chamando _prepare_message, que ajuda a formatar a saída de dados.
No diretório principal do projeto, execute o main.py recém-implementado com o seguinte comando para recuperar as tarefas de casa:
python main.py homework
Sua saída deve ficar assim:
...saída omitida...
====TAREAS DE CASA====
----------------
===MATEMÁTICA===
Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.
----------------
===INGLÊS===
Leia a história “Manny and His Monster Manners” nas páginas 100-107 do seu Diário de Leitura e complete as atividades nas páginas 108 e 109 de acordo com a história.
Leia a história “Manny and His Monster Manners” nas páginas 100-107 do seu Diário de Leitura e complete as atividades nas páginas 108 e 109 de acordo com a história.
----------------
...saída omitida...
Para obter a lista de refeições do dia, execute o comando python main.py meal. Sua saída ficará assim:
...saída omitida...
====LISTA DE REFEIÇÕES====
----------------
===CAFÉ DA MANHÃ===
PANQUECA
QUEIJO CREMOSO
QUEIJO FURADO
CREME DE NOGA COM CACAU
LEITE
----------------
===ALMOÇO===
TARHANA ÇORBA
EKŞİLİ KÖFTE
ERİŞTE
----------------
===SALADA/SOBREMESA===
AYRAN
KIRMIZILAHANA SALATA
ROKALI GÖBEK SALATA
----------------
===FRUTAS===
FINDIK& KURU ÜZÜM
----------------
...saída omitida...
Dicas para superar obstáculos comuns no Scraping de dados da web
Parabéns! Se você chegou até aqui, você criou oficialmente um Scraper Scrapy.
Embora seja fácil criar um Scraper da web com o Scrapy, você pode enfrentar alguns obstáculos durante a implementação, como CAPTCHAs, bloqueios de IP, gerenciamento de sessões ou cookies e sites dinâmicos. Vamos dar uma olhada em algumas dicas para lidar com esses diferentes cenários:
Sites dinâmicos
Os sites dinâmicos fornecem conteúdo variado aos visitantes com base em fatores como configuração do sistema, localização, idade e gênero. Por exemplo, duas pessoas que visitam o mesmo site dinâmico podem ver conteúdos diferentes, personalizados para elas.
Embora o Scrapy possa extrair conteúdo dinâmico da web, ele não foi projetado para isso. Para extrair conteúdo dinâmico, você precisaria programar o Scrapy para ser executado regularmente, salvando e comparando os resultados para rastrear as alterações nas páginas da web ao longo do tempo.
Em certos casos, o conteúdo dinâmico nas páginas da web pode ser tratado como estático, especialmente quando essas páginas são atualizadas apenas ocasionalmente.
CAPTCHAs
Geralmente, os CAPTCHAs são imagens dinâmicas com caracteres alfanuméricos. Os visitantes da página devem inserir os valores correspondentes da imagem CAPTCHA para passar no processo de validação.
Os CAPTCHAs são usados em páginas da web para garantir que o visitante da página seja humano (em oposição a um spider ou bot) e, muitas vezes, para impedir o Scraping de dados.
O sistema escolar fictício com o qual você trabalhou aqui não usa um sistema CAPTCHA, mas se você acabar encontrando um, pode criar um middleware Scrapy que baixa o CAPTCHA e o converte em texto usando uma biblioteca OCR.
Manipulação de sessão e cookie
Quando você abre uma página da web, você entra em uma sessão dentro do sistema dessa página. Essa sessão retém suas informações de login e outros dados relevantes para reconhecê-lo em todo o sistema.
Da mesma forma, você pode rastrear informações sobre um visitante da página da web usando um cookie. No entanto, ao contrário dos dados da sessão, os cookies são armazenados no computador do visitante, e não no servidor do site, e os usuários podem excluí-los se desejarem. Como resultado, você não pode usar cookies para manter uma sessão, mas pode usá-los para várias tarefas de suporte em que a perda de dados não é crítica.
Podem surgir situações em que você precise manipular a sessão de um usuário ou atualizar seus cookies. O Scrapy pode lidar com ambas as situações, seja por meio de seus recursos integrados ou de bibliotecas de terceiros compatíveis.
Banimento de IP
O banimento de IP, também conhecido como bloqueio de endereço IP, é uma técnica de segurança em que um site bloqueia endereços IP específicos. Essa técnica é normalmente usada para impedir que bots ou spiders acessem informações confidenciais, garantindo que apenas usuários humanos possam acessar e processar os dados. Junto com CAPTCHAs, as empresas usam o banimento de IP para impedir atividades de Scraping de dados.
Nesse cenário, o sistema escolar não usa um mecanismo de banimento de IP. No entanto, se eles tivessem implementado um, você precisaria adotar estratégias como usar um IP dinâmico ou ocultar seu endereço IP atrás de um Proxy para continuar fazendo scraping do site deles.
Conclusão
Neste artigo, você aprendeu como criar spiders para fazer login e realizar Parsing de tabelas usando XPath no Scrapy. Além disso, você aprendeu como acionar os spiders programaticamente para obter um melhor controle dos dados.
Você pode acessar o código completo deste tutorial neste repositório GitHub.
Para aqueles que desejam ampliar os recursos do Scrapy e superar os obstáculos de scraping, a Bright Data oferece soluções personalizadas para dados da web pública. A integração da Bright Data com o Scrapy aprimora os recursos de scraping, os serviços de Proxy ajudam a evitar banimentos de IP e o Web Unlocker simplifica o manuseio de CAPTCHAs e conteúdo dinâmico, tornando a coleta de dados com o Scrapy mais eficiente.
Registre-se agora e converse com um de nossos especialistas em dados sobre nossas soluções de scraping.





