

Este tutorial ensinará como criar um script de Scraping de dados em Kotlin. Especificamente, você aprenderá:
- Por que o Kotlin é uma ótima linguagem para fazer scraping de um site
- Quais são as melhores bibliotecas de scraping do Kotlin.
- Como criar um Scraper Kotlin do zero.
Vamos começar!
O Kotlin é uma opção viável para Scraping de dados?
TL;DR: Sim, é! E pode até ser melhor do que Java!
Kotlin é uma linguagem de programação de uso geral, estaticamente tipada e multiplataforma, cuja biblioteca padrão depende da Biblioteca de Classes Java. O que torna Kotlin especial é sua abordagem concisa e divertida à codificação. É endossada pelo Google, que a escolheu como sua linguagem preferida para desenvolvimento Android.
Graças à sua interoperabilidade com a JVM, ele suporta todas as bibliotecas de scraping Java. Assim, você pode aproveitar o vasto ecossistema de bibliotecas Java, mas com uma sintaxe mais concisa e intuitiva. É uma situação em que todos ganham!
Além disso, o Kotlin vem com algumas bibliotecas nativas, que incluem analisadores HTML e bibliotecas de automação de navegadores, que simplificam a extração de dados. Explore algumas das mais populares!
Melhores bibliotecas de Scraping de dados para Kotlin
Aqui está uma lista de algumas das melhores bibliotecas de Scraping de dados para Kotlin:
- skrape{it}: uma biblioteca de testes HTML/XML e Scraping de dados baseada em Kotlin para parsing e interpretação de HTML. Ela inclui vários buscadores de dados que permitem que o skrape{it} atue tanto como um analisador HTML tradicional quanto como um navegador headless para renderização DOM do lado do cliente.
- chrome-reactive-kotlin: Um cliente DevTools Protocol de baixo nível escrito em Kotlin para controlar navegadores baseados em Chromium programaticamente.
- ksoup: uma biblioteca Kotlin leve inspirada no Jsoup. O Ksoup fornece métodos para analisar HTML, extrair tags, atributos e texto HTML, além de codificar e decodificar entidades HTML.
Não se esqueça de que o Kotlin é interoperável com Java. Isso significa que você pode usar qualquer outra biblioteca de Scraping de dados em Java. Uma delas é o Jsoup, um dos analisadores HTML mais populares disponíveis. Saiba mais em nosso guia sobre Scraping de dados com Jsoup.
Pré-requisitos
Siga as instruções abaixo para configurar seu ambiente Kotlin para Scraping de dados.
Configurar o ambiente
Para escrever e executar um aplicativo Kotlin em sua máquina, você precisa ter um JDK (Java Development Kit) instalado localmente. Baixe a versão LTS mais recente do JDK no site da Oracle, execute o instalador e siga o assistente de instalação. No momento da redação deste artigo, é o Java 21.
Em seguida, você precisará de uma ferramenta para gerenciar dependências e construir seu aplicativo Kotlin. Tanto o Gradle quanto o Maven são ótimas opções, então você pode escolher sua ferramenta de construção Java favorita. Como o Gradle suporta Kotlin como uma linguagem DSL (Domain-Specific Language), vamos optar pelo Gradle. Lembre-se de que você pode seguir facilmente o tutorial mesmo se for um usuário do Maven.
Baixe o Maven ou o Gradle e instale-o. O Gradle é particularmente sensível à versão do Java, portanto, certifique-se de baixar o pacote correto. O Gradle compatível com o Java 21 é igual ou superior à versão 8.5.
Por fim, você precisará de um IDE Kotlin. O Visual Studio Code com a extensão Kotlin Language e o IntelliJ IDEA Community Edition são duas ótimas opções gratuitas.
Pronto! Agora você tem um ambiente pronto para Kotlin!
Crie um projeto Kotlin
Crie uma pasta de projeto para seu projeto de Scraping de dados Kotlin e insira-a no terminal:
mkdir KotlinWebScraper
cd KotlinWebScraperAqui, chamamos o diretório de KotlinWebScraper, mas fique à vontade para dar o nome que quiser
Em seguida, execute o comando abaixo na pasta do projeto para criar um aplicativo Gradle:
gradle init --type kotlin-applicationDurante o procedimento, algumas perguntas serão feitas. Você deve escolher “Kotlin” como o DSL do script de compilação e dar ao seu aplicativo um nome de pacote adequado, como com.kotlin.scraper. Para as outras perguntas, as respostas padrão devem ser suficientes.
Isso é o que você verá no final do processo de inicialização:
Selecione o DSL do script de compilação:
1: Kotlin
2: Groovy
Insira a seleção (padrão: Kotlin) [1..2] 1
Nome do projeto (padrão: KotlinWebScraper):
Pacote de origem (padrão: kotlinwebscraper): com.kotlin.scraper
Insira a versão de destino do Java (mín. 8) (padrão: 21):
Gerar compilação usando novas APIs e comportamento (algumas funcionalidades podem mudar na próxima versão secundária)? (padrão: não) [sim, não]
> Tarefa: init
Para saber mais sobre o Gradle, explore nossos exemplos em https://docs.gradle.org/8.5/samples/sample_building_kotlin_applications.html
CONSTRUÇÃO BEM-SUCEDIDA em 2m 10s
2 tarefas acionáveis: 2 executadasFantástico! A pasta KotlinWebScraper agora conterá um projeto Gradle.
Abra a pasta no seu IDE Kotlin, aguarde a conclusão das tarefas em segundo plano necessárias e dê uma olhada no arquivo App.kt principal dentro do pacote com.kotlin.scraper. Ele deve conter o seguinte:
/*
* Este arquivo fonte Kotlin foi gerado pela tarefa 'init' do Gradle.
*/
package com.kotlin.scraping.demo
class App {
val greeting: String
get() {
return "Hello World!"
}
}
fun main() {
println(App().greeting)
}Este é um script Kotlin simples que imprime “Hello World!” no terminal.
Para verificar se ele funciona, execute o script com o seguinte comando Gradle:
./gradlew runAguarde até que o projeto seja compilado e executado, e você verá:
> Tarefa :app:run
Hello World!
CONSTRUÇÃO BEM-SUCEDIDA em 3s
3 tarefas acionáveis: 2 executadas, 1 atualizadaVocê pode ignorar as mensagens de log do Gradle. Concentre-se na mensagem “Hello World!”, que é exatamente o resultado esperado do script. Em outras palavras, sua configuração do Kotlin funciona conforme o esperado.
É hora de realizar o Scraping de dados da web com Kotlin!
Crie um script Kotlin para Scraping de dados
Nesta seção passo a passo, você verá como criar um Scraper em Kotlin. Em particular, você aprenderá como definir um script automatizado que extrai dados do site de sandbox de scraping Quotes.
Em um nível geral, o script de Scraping de dados Kotlin que você está prestes a codificar irá:
- Conectar-se à página de destino.
- Selecionar os elementos HTML de citações na página.
- Extrair os dados desejados deles.
- Repetir essa operação para todas as citações nos sites, visitando cada página de paginação.
- Exportar os dados coletados no formato CSV.
Esta é a aparência do site de destino:
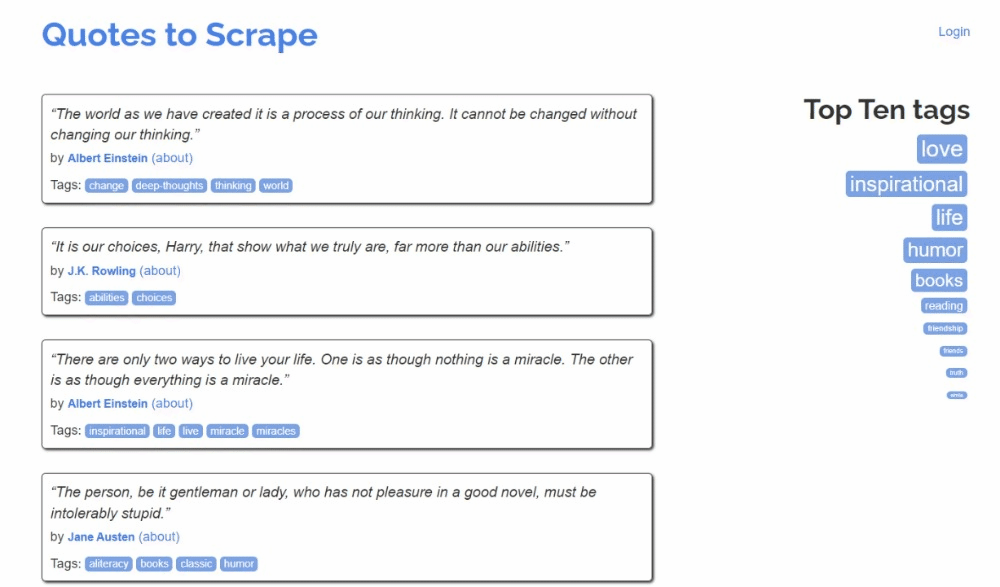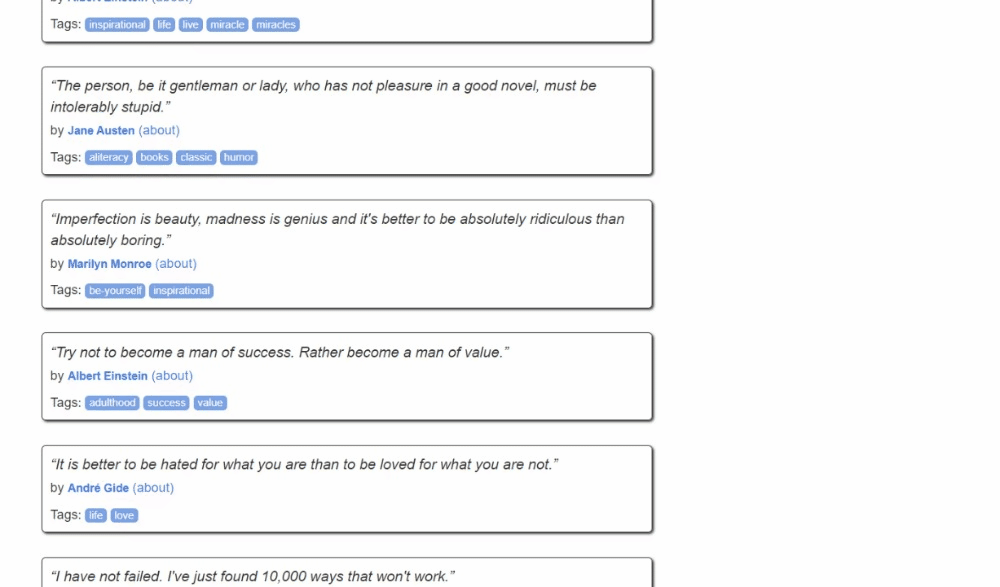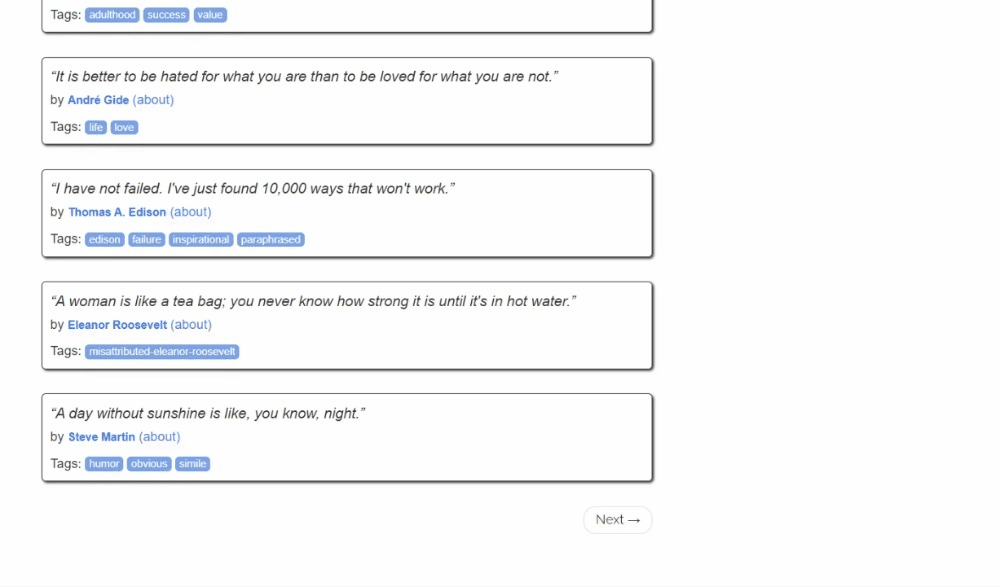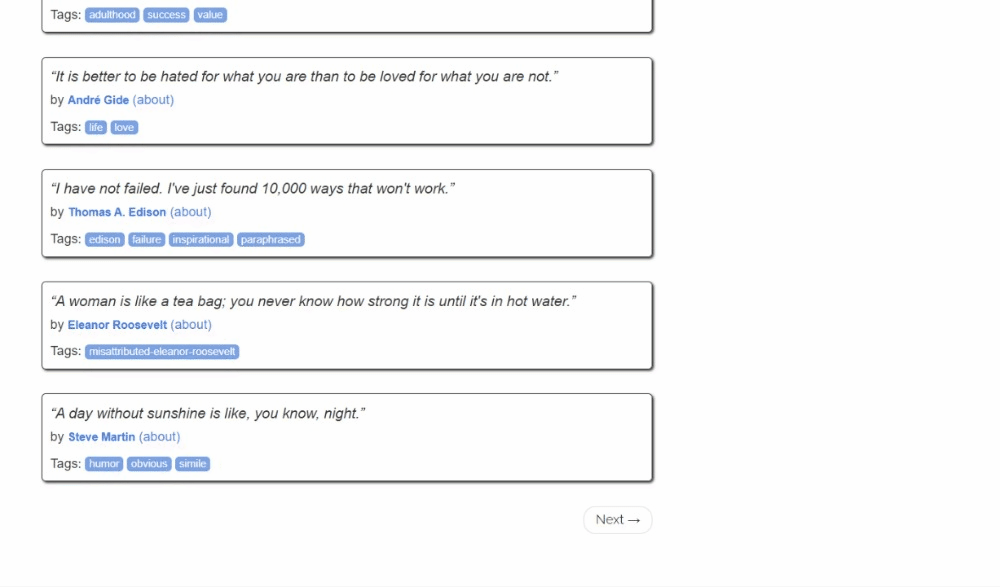
Siga as etapas abaixo e descubra como realizar Scraping de dados em Kotlin!
Etapa 1: Instale a biblioteca de scraping
A primeira coisa a fazer é descobrir quais bibliotecas de Scraping de dados Kotlin são mais adequadas para seus objetivos. Para isso, você deve inspecionar o site de destino.
Então, visite o site Quotes To Scrape sandbox no seu navegador. Clique com o botão direito do mouse em uma seção em branco e selecione a opção “Inspect” para abrir o DevTools. Acesse a guia “Network”, recarregue a página e explore a seção “Fetch/XHR”.
É isso que você deve ver:
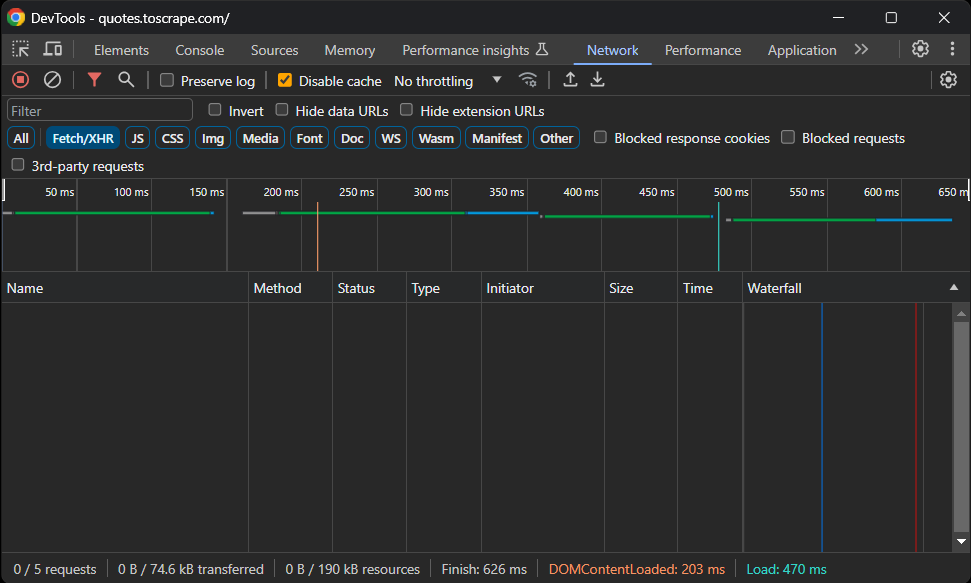
Sem solicitações AJAX! Em outras palavras, a página de destino não recupera dados dinamicamente via JavaScript. Isso significa que o servidor retorna páginas aos clientes com todos os dados de interesse incorporados no código HTML.
Consequentemente, uma biblioteca de Parsing HTML será suficiente. Você ainda pode usar uma ferramenta de automação do navegador, mas carregar e renderizar a página em um navegador só traria uma sobrecarga de desempenho e nenhum benefício real.
Portanto, o skrape{it} será uma ótima escolha para atingir o objetivo de Scraping de dados. Adicione-o às dependências do seu projeto com esta linha no objeto dependencies do seu arquivo build.gradle.kts:
implementation("it.skrape:skrapeit:1.2.2")Caso contrário, se você for um usuário do Maven, adicione estas linhas à tag <dependencies> no seu pom.xml:
<dependency>
<groupId>it.skrape</groupId>
<artifactId>skrapeit</artifactId>
<version>1.2.2</version>
</dependency>Se você estiver usando o IntelliJ IDEA, o IDE mostrará um botão para recarregar as dependências do projeto e instalar a nova biblioteca. Clique nele para instalar o skrape{it}.
Da mesma forma, você pode instalar manualmente a nova dependência com este comando Gradle:
./gradlew build --refresh-dependenciesO processo de instalação pode demorar um pouco, então seja paciente.
Em seguida, prepare-se para usar o skrape{it} em seu script App.kt adicionando as seguintes importações a ele:
import it.skrape.core.*
import it.skrape.fetcher.*Não se esqueça de que o kkrape{it} vem com muitos buscadores de dados. Aqui, importamos todos eles por uma questão de simplicidade. Ao mesmo tempo, você só precisará do HttpFetcher, um cliente HTTP clássico que envia uma solicitação HTTP para a URL fornecida e retorna uma resposta analisada.
Ótimo! Agora você tem tudo o que precisa para realizar Scraping de dados com Kotlin!
Etapa 2: baixe a página de destino e faça o Parsing do seu HTML
Em App.kt, remova a classe App e adicione as seguintes linhas na função main() para se conectar à página de destino usando skrape{it}:
skrape(HttpFetcher) {
// faça uma solicitação HTTP GET para a URL especificada
request {
url = "https://quotes.toscrape.com/"
}
}Nos bastidores, o skrape{it} usará a classe HttpFetcher mencionada anteriormente para fazer uma solicitação HTTP GET síncrona para a URL fornecida.
Se você quiser ter certeza de que o script está funcionando conforme o desejado, adicione a seguinte seção na definição skrape(HttpFetcher):
response {
// obtenha o código-fonte HTML e imprima-o
htmlDocument {
print(html)
}
}Isso informa ao skrape{it} o que fazer com a resposta do servidor. Especificamente, ele acessa a resposta analisada e, em seguida, imprime o código HTML da página.
Seu script de scraping App.kt Kotlin agora deve conter:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
fun main() {
skrape(HttpFetcher) {
// faça uma solicitação HTTP GET para a URL especificada
request {
url = "https://quotes.toscrape.com/"
}
response {
// obtenha o código-fonte HTML e imprima-o
htmlDocument {
print(html)
}
}
}
}Execute o script e ele imprimirá:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Citações para extrair</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- omitido por brevidade... -->Esse é exatamente o código HTML da página de destino. Muito bem!
Etapa 3: Inspecione o conteúdo da página
O próximo passo seria definir a lógica de extração. Mas como você pode fazer isso sem saber como selecionar os elementos na página? É por isso que é importante dar um passo a mais e inspecionar a estrutura da página de destino.
Abra Quotes To Scrape novamente no seu navegador. Clique com o botão direito do mouse em um elemento de citação e selecione “Inspect” para abrir o DevTools, conforme mostrado abaixo:
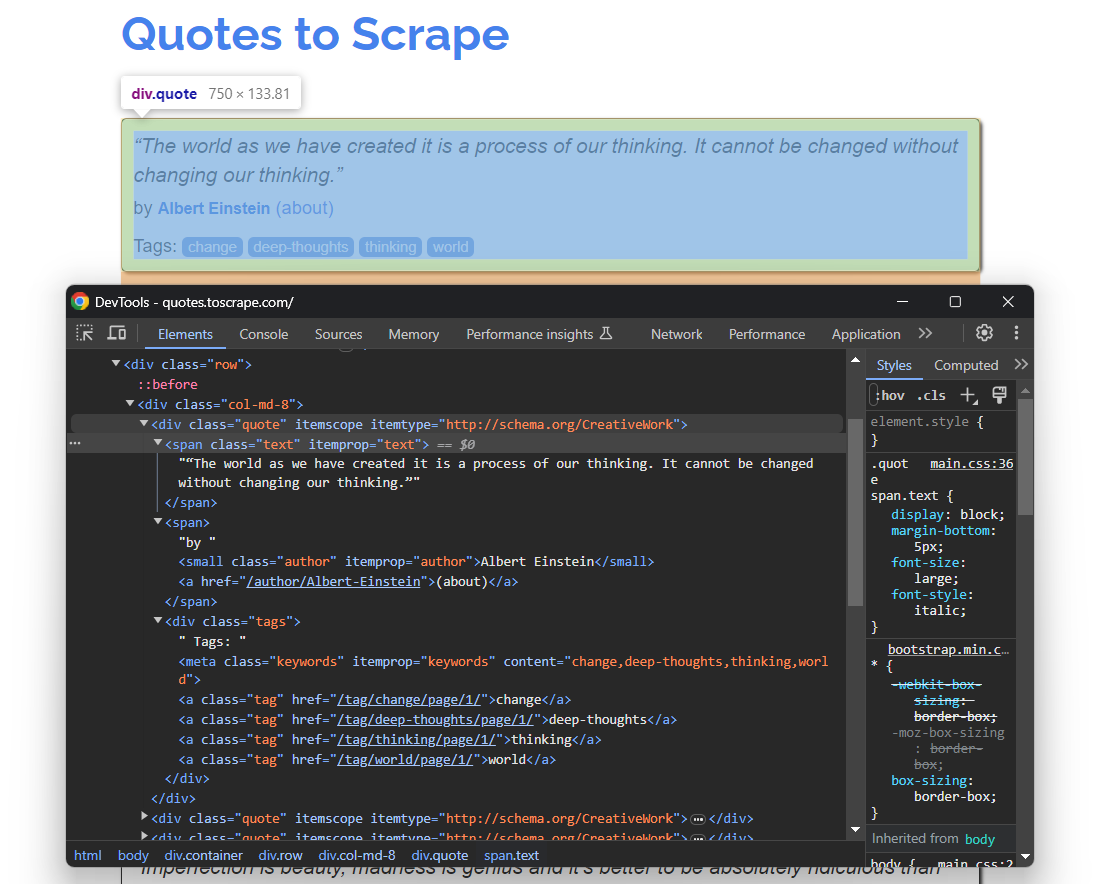
Aqui, você pode observar que cada cartão de citação é um elemento HTML .quote que envolve:
- Um elemento .text com o texto da citação.
- Um elemento .author com o nome do autor.
- Vários elementos .tag, cada um exibindo uma única tag.
Observe que nem todas as citações têm a seção de tags:

Os seletores CSS acima ajudarão você a selecionar os elementos DOM desejados da página para extrair dados deles. Você também precisará de uma classe onde armazenar esses dados. Portanto, adicione a seguinte definição de classe Quote no topo do seu script Kotlin de Scraping de dados:
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}Como a página contém várias citações, instancie uma Lista de objetos Quote em main():
val quotes: MutableList<Quote> = ArrayList()No final do script, quotes conterá todas as citações coletadas do site.
Use o que você entendeu e definiu aqui para implementar a lógica de scraping na próxima etapa!
Etapa 4: Implemente a lógica de scraping
O skrape{it} tem uma maneira peculiar de selecionar nós HTML em uma página. Para aplicar um seletor CSS na página, você precisa definir uma seção dentro do htmlDocument com o mesmo nome do seletor CSS:
skrape(HttpFetcher) {
// seção de solicitação...
response {
htmlDocument {
// selecione todos os elementos HTML ".quote" na página
".quote" {
// lógica de scraping...
}
}
}
}Dentro da seção “.quote”, você pode definir uma seção findAll. Ela conterá a lógica que será aplicada a cada nó HTML quote selecionado com o seletor CSS especificado. Em vez disso, findFirst irá obter apenas o primeiro elemento selecionado.
Nos bastidores, todas essas seções nada mais são do que funções lambda Kotlin. Por causa disso, você pode acessar o elemento DOM único com ele em uma seção forEach dentro de findAll. Se você não estiver familiarizado com isso, é o nome implícito de um único parâmetro em um lambda.
Segue uma lógica semelhante, mas com base em métodos e atributos. Você pode então implementar a lógica de raspagem para extrair os dados desejados de cada citação, instanciar um objeto Quote e adicioná-lo à lista de citações da seguinte maneira:
".quote" {
findAll {
forEach {
// lógica de scraping em um único elemento de citação
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// crie um objeto Quote e adicione-o à lista
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}Graças ao atributo text, você pode recuperar o texto interno de um elemento HTML. Como nem todos os elementos HTML de citação contêm tags, você precisa lidar com a ElementNotFoundException. Isso é gerado pelo findAll quando o seletor CSS fornecido não corresponde a nenhum nó na página.
Importe ElementNotFoundException com:
import it.skrape.selects.ElementNotFoundException
Junte todos os trechos e registre os dados contidos na matriz de citações:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
// defina uma classe para representar os dados extraídos em Kotlin
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// onde armazenar os dados coletados
val quotes: MutableList<Quote> = ArrayList()
skrape(HttpFetcher) {
// fazer uma solicitação HTTP GET para a URL especificada
request {
url = "https://quotes.toscrape.com/"
}
response {
htmlDocument {
// selecionar todos os elementos HTML ".quote" na página
".quote" {
findAll {
forEach {
// lógica de coleta em um único elemento de citação
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// criar um objeto Quote e adicioná-lo à lista
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
}
}
}
// registre os dados coletados
for (quote in quotes) {
println("Texto: ${quote.text}")
println("Autor: ${quote.author}")
println("Tags: ${quote.tags.joinToString("; ")}")
println()
}
}Observe o uso de joinToString() para mesclar a lista de tags em uma string separada por vírgulas.
Se você executar o script, obterá agora:
Texto: “O mundo que criamos é um processo do nosso pensamento. Ele não pode ser mudado sem mudar nosso pensamento.”
Autor: Albert Einstein
Tags: mudança; pensamentos profundos; pensamento; mundo
# omitido por brevidade...
Texto: “Um dia sem sol é como, você sabe, a noite.”
Autor: Steve Martin
Tags: humor; óbvio; comparaçãoUau! Você acabou de aprender como fazer Scraping de dados com Kotlin!
Etapa 5: Adicione a lógica de rastreamento
Você acabou de extrair dados de uma única página, mas a lista de citações está espalhada por várias páginas. Se você rolar a página até o final, verá um botão “Próximo →” com um link para a página seguinte:
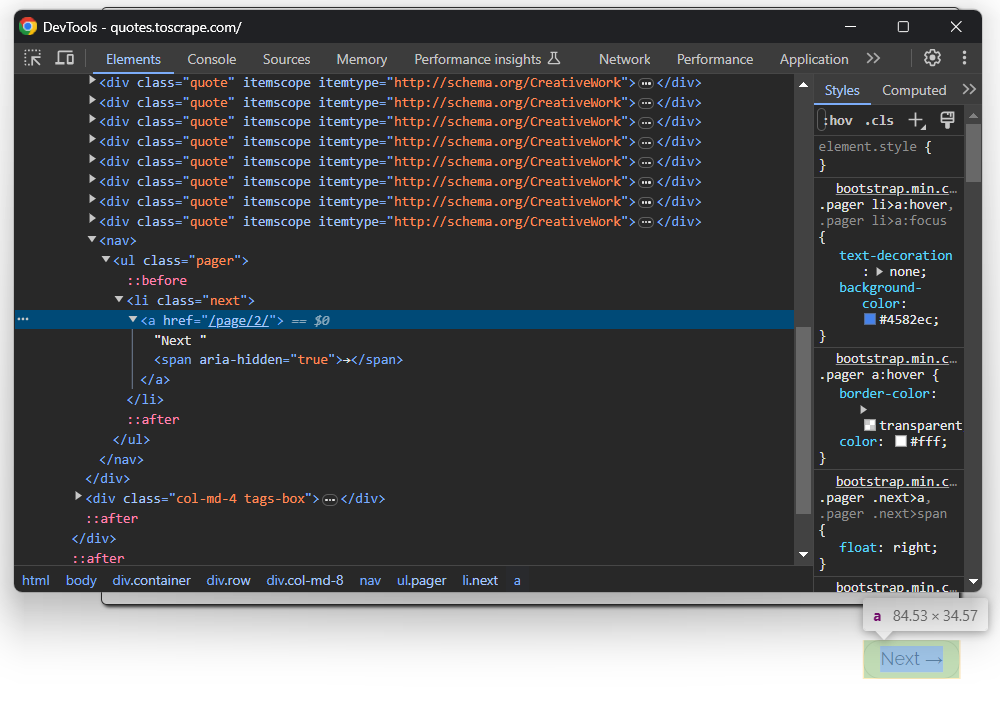
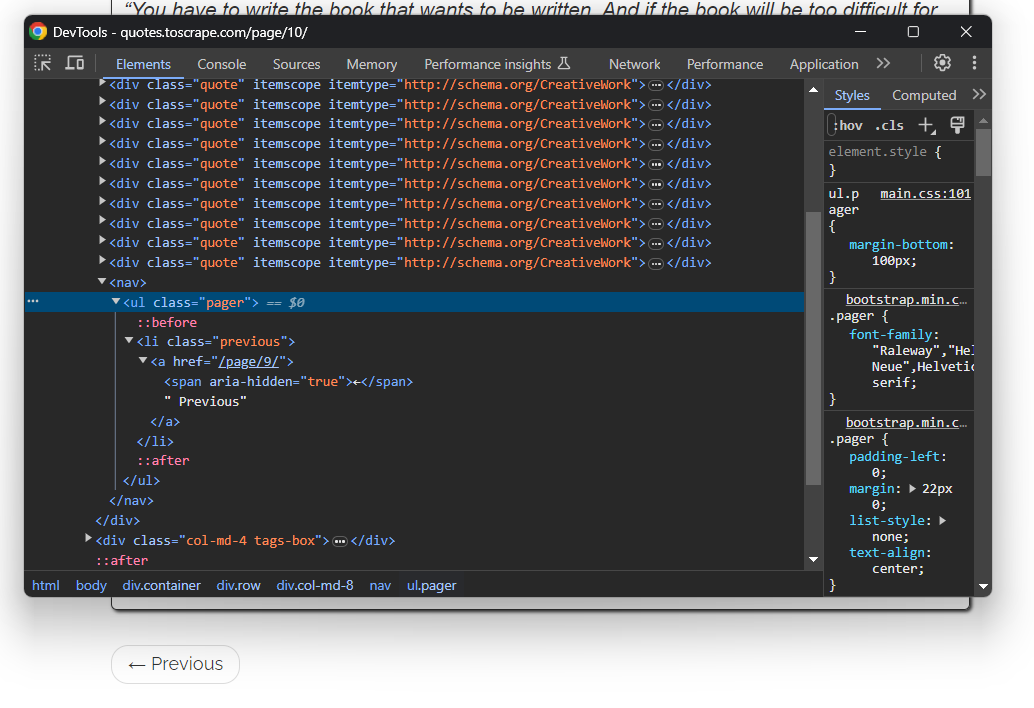
Isso vale para todas as páginas, exceto a última:
Para realizar o rastreamento da web em Kotlin e extrair cada citação do site, você precisa:
- Extrair todas as citações da página atual.
- Selecionar o elemento “Próximo →”, se houver, e extrair o URL da próxima página dele.
- Repetir a primeira etapa na nova página.
Implemente o algoritmo acima da seguinte maneira:
Em vez de extrair uma única página e parar, o script agora depende de um loop while. Isso continua a iterar até que não haja mais páginas para extrair. Isso acontece quando o seletor CSS .next levanta uma exceção ElementNotFoundException, o que significa que o botão “Próximo →” não está na página e, portanto, você está na última página de paginação do site.
Observe que a seção htmlDocument pode conter várias seções de seletores CSS. Cada uma será executada na ordem especificada. Se você iniciar o script Kotlin de Scraping de dados novamente, as citações agora armazenarão todas as 100 citações do site.
Ótimo! A lógica de Scraping de dados e rastreamento Kotlin está pronta. Resta apenas remover o código de registro com a lógica de exportação de dados.
Etapa 7: Exporte os dados coletados para CSV
Os dados coletados estão atualmente armazenados em uma lista de objetos Quote. Imprimir no terminal é útil, mas exportar para CSV é a melhor maneira de aproveitá-los ao máximo. Isso permitirá que outros membros da sua equipe filtrem, leiam e analisem esses dados.
O Kotlin fornece tudo o que você precisa para criar um arquivo CSV e preenchê-lo, mas usar uma biblioteca torna tudo mais fácil. Uma biblioteca nativa do Kotlin popular para ler e gravar arquivos CSV é o kotlin-csv.
Adicione-a às dependências do seu projeto em build.gradle.kts:
implementation("com.github.doyaaaaaken:kotlin-csv-jvm:1.9.3")Ou, se você estiver no Maven:
<dependency>
<groupId>com.github.doyaaaaaken</groupId>
<artifactId>kotlin-csv-jvm</artifactId>
<version>1.9.3</version>
</dependency>Instale a biblioteca e importe-a no seu arquivo App.kt:
import com.github.doyaaaaaken.kotlincsv.dsl.*Agora você pode exportar citações para um arquivo CSV com apenas algumas linhas de código:
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}Observe que List<String> é como um registro CSV é representado no kotlin-csv. Primeiro, defina um registro para a linha do cabeçalho. Em seguida, converta as citações para os dados desejados. Depois, inicialize um gravador CSV, crie um arquivo quotes.csv e preencha-o com writeRow() e writeRows().
Pronto! Agora só falta dar uma olhada no código final do seu script de Scraping de dados em Kotlin.
Etapa 8: Junte tudo
Aqui está o código final do seu Scraper Kotlin:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
import com.github.doyaaaaaken.kotlincsv.dsl.*
// defina uma classe para representar os dados extraídos em Kotlin
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// onde armazenar os dados coletados
val quotes: MutableList<Quote> = ArrayList()
// a URL da próxima página a ser visitada
var nextUrl: String? = "https://quotes.toscrape.com/"
// até que haja uma página para visitar
enquanto (nextUrl != nulo) {
skrape(HttpFetcher) {
// fazer uma solicitação HTTP GET para a URL especificada
solicitação {
url = nextUrl!!
}
response {
htmlDocument {
// selecionar todos os elementos HTML ".quote" na página
".quote" {
findAll {
forEach {
// lógica de scraping em um único elemento de citação
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch (e: ElementNotFoundException) {
null
}
// criar um objeto Quote e adicioná-lo à lista
val citação = Citação(
texto = texto,
autor = autor,
tags = tags
)
citações.adicionar(citação)
}
}
}
// lógica de rastreamento
tente {
".next a" {
findFirst {
nextUrl = "https://quotes.toscrape.com" + attribute("href")
}
}
} catch (e: ElementNotFoundException) {
nextUrl = null
}
}
}
}
}
// criar um arquivo "quotes.csv" e preenchê-lo
// com os dados coletados
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; "))
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}
}Dá para acreditar? Graças ao skrape{it}, você pode recuperar dados de um site inteiro com menos de 100 linhas de código!
Execute seu script Kotlin de Scraping de dados com:
./gradlew runSeja paciente enquanto o Scraper percorre cada página do site de destino. Quando terminar, um arquivo quotes.csv aparecerá no diretório raiz do seu projeto. Abra-o e você verá os seguintes dados:
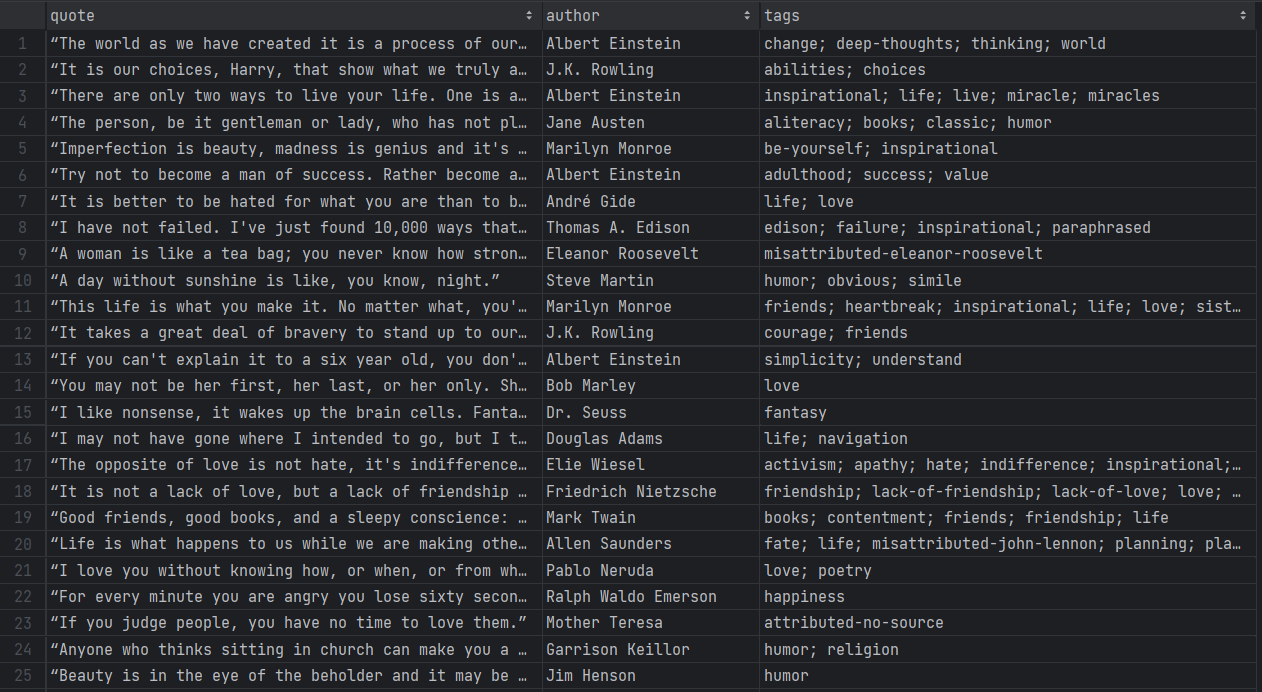
Et voilà! Você começou com dados não estruturados em páginas online e agora os tem em um arquivo CSV fácil de explorar!
Evite bloqueios de IP no Kotlin com um Proxy
Ao realizar Scraping de dados com Kotlin, um dos maiores desafios é ser bloqueado por tecnologias anti-bot. Esses sistemas podem detectar a natureza automatizada do seu script e banir seu IP. Dessa forma, eles interrompem sua operação de scraping.
Como evitar isso? Com um Proxy da web!
Siga as etapas abaixo e aprenda como integrar um Proxy Bright Data ao Kotlin.
Configure um Proxy na Bright Data
O Bright Data é o melhor servidor proxy do mercado, monitorando milhares de servidores proxy em todo o mundo. Quando se trata de rotação de IP, o melhor tipo de proxy a ser escolhido é um Proxy residencial.
Para começar, se você já tem uma conta, faça login no Bright Data. Caso contrário, crie uma conta gratuitamente. Você terá acesso ao seguinte painel do usuário:
Clique no botão “Ver produtos Proxy” conforme abaixo:
Você será redirecionado para a seguinte página “Proxies e Infraestrutura de scraping”:
Role para baixo, encontre o cartão “Proxies residenciais” e clique no botão “Começar”:
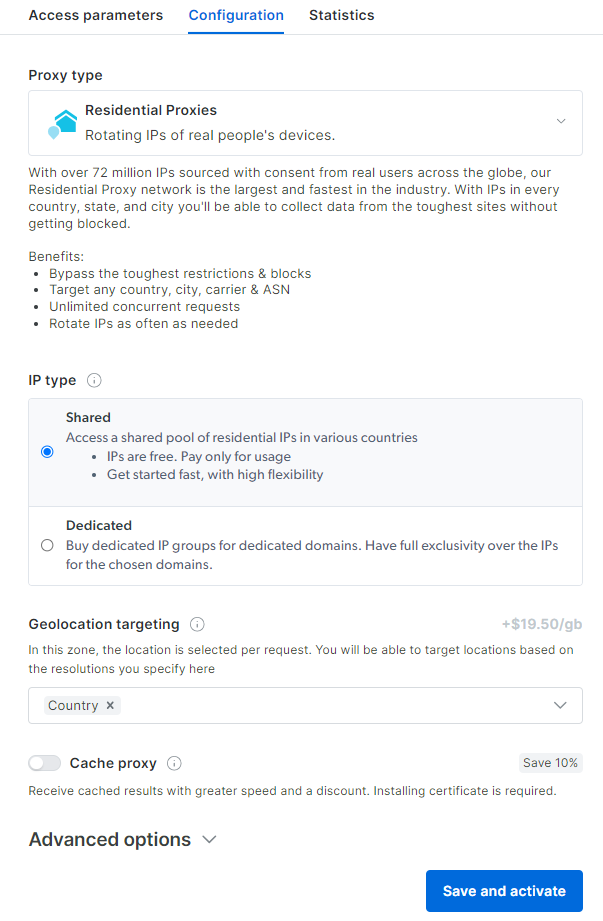
Você chegará ao painel de configuração do Proxy residencial. Siga o assistente guiado e configure o serviço de Proxy de acordo com suas necessidades. Se tiver alguma dúvida sobre como configurar o Proxy, entre em contato com o suporte 24 horas por dia, 7 dias por semana.
Vá para a guia “Parâmetros de acesso” e recupere o host, a porta, o nome de usuário e a senha do seu Proxy da seguinte maneira:
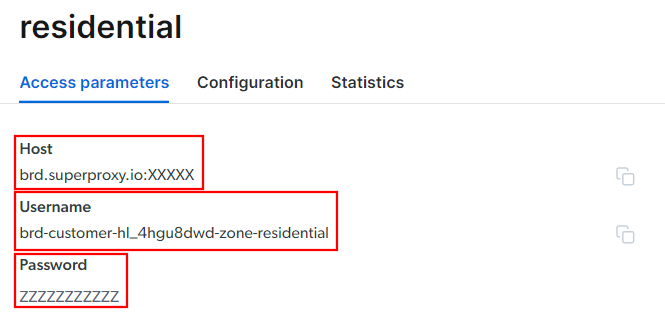
Observe que o campo “Host” já inclui a porta.
Isso é tudo o que você precisa para criar a URL do Proxy e usá-la no skrape{it}. Reúna todas as informações e crie uma URL com a seguinte sintaxe:
<Nome de usuário>:<Senha>@<Host>Por exemplo, neste caso, seria:
brd-customer-hl_4hgu8dwd-zona-residential:[email protected]:XXXXXAlterne “Proxy ativo”, siga as últimas instruções e você estará pronto para começar!

Integre o Proxy no Kotlin
O trecho para integração do Bright Data no skrape{it} ficará assim:
skrape(HttpFetcher) {
request {
url = "https://quotes.toscrape.com/"
proxy = proxyBuilder {
type = Proxy.Type.HTTP
host = "brd.superproxy.io"
port = XXXXX
}
authentication = basic {
username = "brd-customer-hl_4hgu8dwd-zone-residential"
password = "ZZZZZZZZZZ"
}
}
// ...
}Como você pode ver, tudo se resume ao uso das opções de Proxy e solicitação de autenticação. A partir de agora, o skrape{it} fará a solicitação para a URL especificada através do Proxy Bright Data. Adeus, bloqueios de IP!
Mantenha sua operação de Scraping de dados em Kotlin ética e respeitosa
O scraping de dados é uma maneira eficaz de coletar dados úteis para vários casos de uso. Lembre-se de que o objetivo final é recuperar esses dados, não danificar o site de destino. Portanto, você deve abordar essa tarefa com as devidas precauções.
Siga as dicas abaixo para realizar um Scraping de dados da Web Kotlin responsável:
- Visar apenas informações disponíveis publicamente: concentre-se em recuperar dados que são acessíveis publicamente no site. Evite páginas protegidas por credenciais de login ou outras formas de autorização. Rastrear dados privados ou confidenciais sem a devida permissão é antiético e pode levar a consequências legais.
- Respeite o arquivo robots.txt: todo site tem um arquivo robots.txt que define as regras sobre como os rastreadores automatizados devem acessar suas páginas. Para manter práticas éticas de scraping de dados, você deve seguir essas diretrizes. Saiba mais em nosso guia robots.txt para Scraping de dados.
- Limite a frequência de suas solicitações: fazer muitas solicitações em um curto espaço de tempo levará a uma sobrecarga do servidor, afetando o desempenho do site para todos os usuários. Isso também pode acionar medidas de limitação de taxa e fazer com que você seja bloqueado. Por esse motivo, evite sobrecarregar o servidor de destino adicionando atrasos aleatórios às suas solicitações.
- Verifique e cumpra os Termos de Serviço do site: antes de fazer scraping em um site, revise seus Termos de Serviço. Eles podem conter informações sobre direitos autorais, direitos de propriedade intelectual e diretrizes sobre como e quando usar seus dados.
- Confie em ferramentas de scraping confiáveis e atualizadas: selecione fornecedores conceituados e opte por ferramentas e bibliotecas que sejam bem mantidas e atualizadas regularmente. Só assim você poderá garantir que elas estejam em conformidade com os princípios éticos mais recentes de Scraping de dados Kotlin. Se tiver alguma dúvida, consulte nosso artigo sobre como escolher o melhor serviço de Scraping de dados.
Conclusão
Neste guia, você viu por que o Kotlin é uma ótima linguagem para Scraping de dados, especialmente quando comparado ao Java. Você também viu uma lista das melhores bibliotecas de Scraping do Kotlin. Em seguida, você aprendeu a usar o skrape{it} para construir um Scraper que extrai dados de várias páginas de um site real. Como você experimentou aqui, o Scraping de dados com Kotlin é simples e requer apenas algumas linhas de código.
O principal desafio para sua operação de scraping são as soluções anti-bot. Os sites adotam esses sistemas para proteger seus dados de scripts automatizados, bloqueando-os antes que eles possam acessar suas páginas. Contornar todos eles não é fácil e requer ferramentas avançadas. Felizmente, a Bright Data tem o que você precisa!
Estes são alguns dos produtos de scraping oferecidos pela Bright Data:
- Web Scraper API: APIs fáceis de usar para acesso programático a dados estruturados da web de dezenas de domínios populares.
- Navegador de scraping: um navegador controlável baseado em nuvem que oferece recursos de renderização JavaScript enquanto lida com impressões digitais do navegador, CAPTCHAs, tentativas automatizadas e muito mais para você. Ele se integra às bibliotecas de navegadores de automação mais populares, como Playwright e Puppeteer.
- Web Unlocker: uma API de desbloqueio que pode retornar perfeitamente o HTML bruto de qualquer página, contornando quaisquer medidas anti-scraping.
Não quer lidar com o Scraping de dados, mas ainda está interessado em dados online? Explore os Conjuntos de dados prontos para uso da Bright Data!




