
Neste extenso guia, discutiremos:
- Principais bibliotecas de raspagem da web em C#
- Pré-requisitos
- Raspagem de sítios web de conteúdo estático em C#
- Raspagem de sítios web de conteúdo dinâmico em C#
- O que fazer com os dados raspados
- Privacidade de dados com proxies
- Conclusão
Principais bibliotecas de raspagem da web em C#
A raspagem da web torna-se mais fácil quando se adotam as ferramentas certas. Vamos dar uma olhada nas melhores bibliotecas de raspagem de NuGet para C#:
HtmlAgilityPack: a biblioteca mais popular de raspadores em C#. OHtmlAgilityPackpermite-lhe descarregar páginas web, analisar o seu conteúdo HTML, selecionar elementos HTML e extrair dados dos mesmos.HttpClient: o cliente HTTP mais popular em C#. OHttpClienté particularmente útil quando se trata de rastejamento da web porque permite efetuar pedidos HTTP de forma fácil e assíncrona.- O
Selenium WebDriveré uma biblioteca que suporta várias linguagens de programação e permite-lhe escrever testes automatizados para aplicações web. Também pode ser utilizado para fins de raspagem da web. - O
Puppeteer Sharpé a porta C# do Puppeteer. O Puppeteer Sharp fornece capacidades de navegador sem cabeça e permite a raspagem de páginas de conteúdo dinâmico.
Neste tutorial, você verá como realizar a raspagem da web usando C# com HtmlAgilityPack e Selenium.
Pré-requisitos para raspagem da web com C#
Antes de escrever a primeira linha de código do seu raspador web de C#, é necessário cumprir alguns pré-requisitos:
- Visual Studio: a edição comunitária gratuita do Visual Studio 2022 é suficiente.
- .NET 6+: qualquer versão LTS maior ou igual a 6 é suficiente.
Se não cumprir um destes requisitos, clique no link acima para descarregar as ferramentas e siga o assistente de instalação para as configurar.
Agora você está pronto para criar um projeto de raspagem da web em C# no Visual Studio.
Configurar um projeto no Visual Studio
Abra o Visual Studio e clique na opção “Criar um novo projeto”.
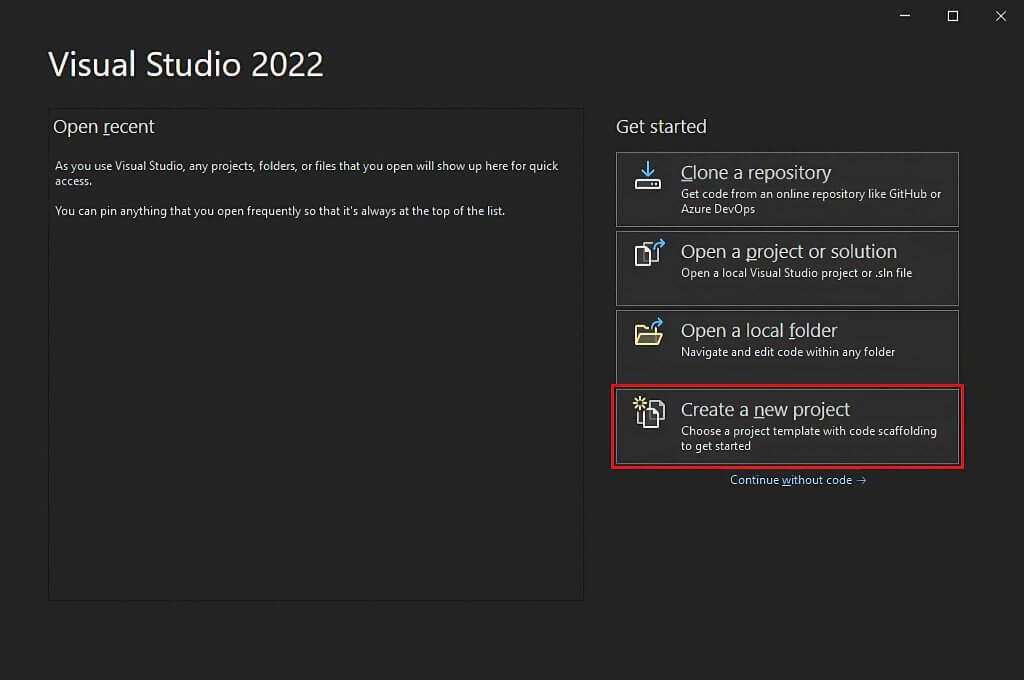
Na janela “Criar um novo projeto”, selecione a opção “C#” na lista pendente. Depois de especificar a linguagem de programação, selecione o modelo “Console App” (aplicação da consola) e clique em “Seguinte”.
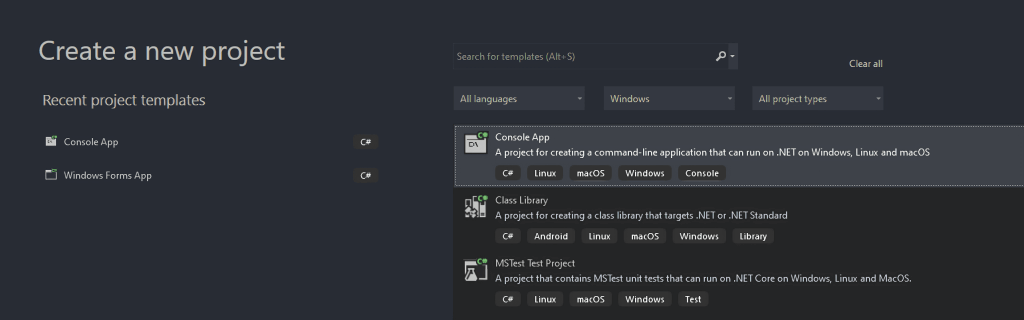
Em seguida, chame ao seu projeto StaticWebScraping, clique em “Selecionar” e escolha a versão .NET. Se você instalou o .NET 6.0, o Visual Studio já deve selecioná-la por você.
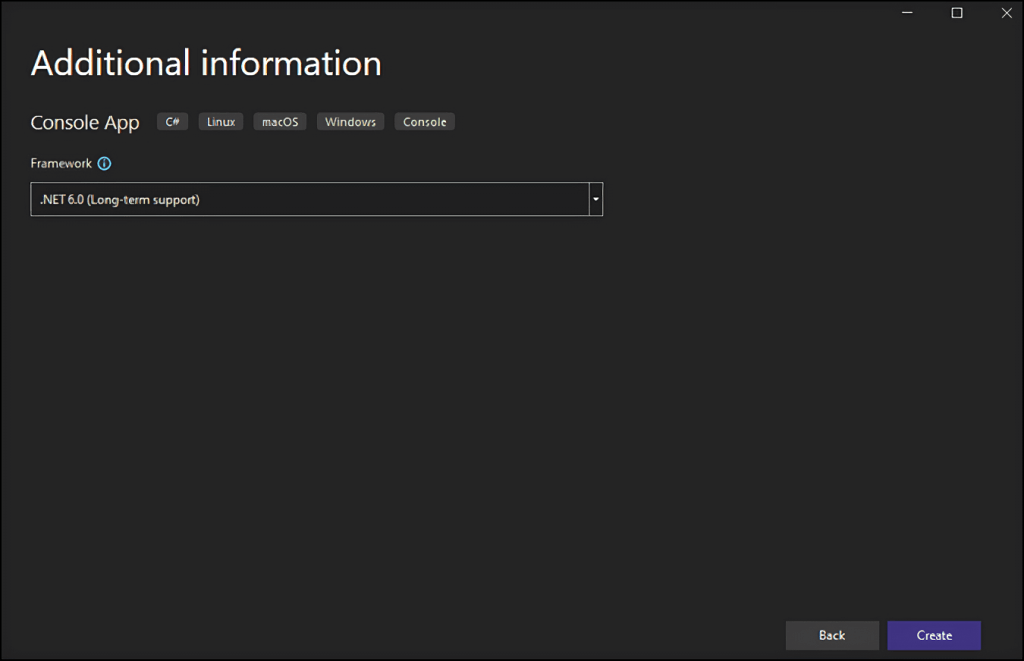
Clique no botão “Criar” para inicializar seu projeto de raspagem da web em C#. O Visual Studio inicializará uma pasta StaticWebScraping contendo um ficheiro App.cs por você. Este ficheiro irá armazenar a sua lógica de raspagem da web em C#:
namespace WebScraping {
public class Program {
public static void Main() {
// scraping logic...
}
}
}
Está na altura de perceber como se pode construir um raspador da web em C#!
Raspagem de sítios web de conteúdo estático em C#
Nos sítios web de conteúdo estático, o conteúdo das páginas web já está armazenado nos documentos HTML devolvidos pelo servidor. Isso significa que uma página web de conteúdo estático não executa pedidos XHR para recuperar dados ou requer que o JavaScript seja renderizado.
A raspagem de sítios web estáticos é bastante simples. Tudo o que você precisa fazer é:
- Instalar uma biblioteca C# de raspagem da web
- Descarregar a sua página web de destino e analisar o respetivo documento HTML
- Utilizar uma biblioteca de raspagem da web para selecionar os elementos HTML de interesse
- Extrair dados dos mesmos
Vamos aplicar todos estes passos à página da Wikipédia “Lista de episódios de SpongeBob SquarePants“:

O objetivo do raspador da web em C# que está prestes a construir é obter automaticamente todos os dados de episódios dessa página da Wikipédia de conteúdo estático.
Vamos começar!
Passo 1: Instalar o HtmlAgilityPack
O HtmlAgilityPack é uma biblioteca C# de código aberto que permite analisar documentos HTML, selecionar elementos do DOM e extrair dados dos mesmos. Basicamente, o HtmlAgilityPack oferece tudo o que é necessário para raspar um sítio web de conteúdo estático.
Para o instalar, clique com o botão direito do rato na opção “Dependências” sob o nome do seu projeto no “Gerenciador de Soluções”. Em seguida, selecione “Gerenciar pacotes NuGet”. Na janela do gerenciador de pacotes NuGet, procure por “HtmlAgilityPack” e clique no botão “Instalar” na seção direita da tela.
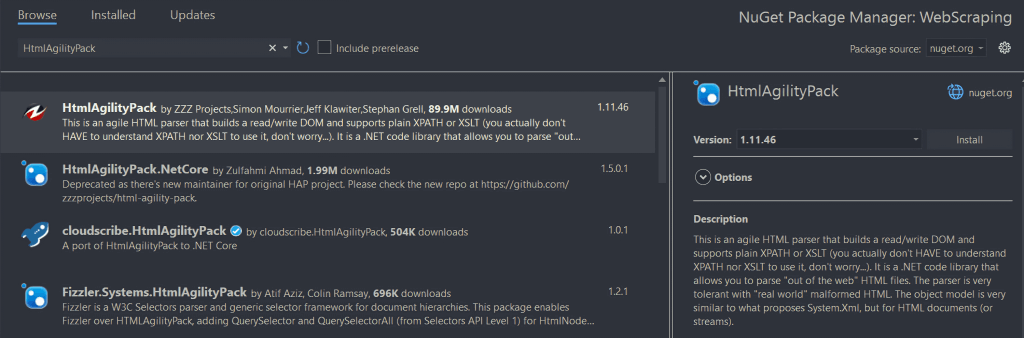
Uma janela emergente perguntará se concorda em fazer alterações no seu projeto. Clique em “OK” para instalar o HtmlAgilityPack. Agora você está pronto para executar a raspagem da web em C# em um sítio web estático.
Agora, adicione a seguinte linha no topo do seu ficheiro App.cs para importar o HtmlAgilityPack:
using HtmlAgilityPack;Passo 2: Carregar uma página web HTML
Pode ligar-se à página web de destino com o HtmlAgilityPack da seguinte forma:
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
A instância da classe HtmlWeb permite-lhe carregar uma página web graças ao seu método Load(). Nos bastidores, este método efetua um pedido HTTP GET para recuperar o documento HTML associado ao URL passado como parâmetro. Em seguida, Load() devolve uma instância de HtmlDocument do HtmlAgilityPack que pode utilizar para selecionar elementos HTML da página.
Passo 3: Selecionar elementos HTML
É possível selecionar elementos HTML de uma página web com seletores XPath. Em pormenor, o XPath permite-lhe selecionar um ou mais elementos específicos do DOM. Para obter o seletor XPath relacionado com um elemento HTML, clique com o botão direito do rato sobre ele, abra as ferramentas de inspeção no seu navegador, certifique-se de que está a selecionar o elemento do DOM de interesse, clique com o botão direito do rato no elemento do DOM e selecione “Copiar XPath”.
O objetivo do raspador da web em C# é extrair os dados associados a cada episódio. Portanto, extraia o seletor XPath aplicando o procedimento descrito acima a um elemento de episódio <tr>.
Isso retornará:
//*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr[2]
Lembre-se de que você deseja selecionar todos os elementos <tr> . Por isso, é necessário alterar o índice associado ao elemento da linha de seleção. Em pormenor, não se pretende raspar a primeira linha da tabela, uma vez que esta contém apenas cabeçalhos de tabela. No XPath, os índices começam a partir de 1, pelo que pode selecionar todos os elementos <tr> da primeira tabela de episódios na página, adicionando a sintaxe XPath position()>1.
Além disso, você deseja raspar dados das tabelas de todas as temporadas. Na página da Wikipédia, as tabelas que contêm dados sobre episódios vão da segunda à décima quinta tabela HTML contida no documento HTML. Portanto, é este o aspeto da cadeia XPath final:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
Agora, pode utilizar a função SelectNodes() oferecida pelo HtmlAgilityPack para selecionar os elementos HTML de interesse da seguinte forma:
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");Note que só pode chamar o método SelectNodes() a uma instância HtmlNode. Por isso, é necessário obter o nó HTML raiz do documento HTML com a propriedade DocumentNode.
Além disso, não se esqueça de que os seletores XPath são apenas um dos muitos métodos de que dispõe para selecionar elementos HTML de uma página web. Os seletores CSS são outra opção popular.
Passo 4: Extrair dados de elementos HTML
Primeiro, você precisa de uma classe personalizada onde armazenar os dados raspados. Crie um ficheiro Episode.cs na pasta WebScraping e inicialize-o da seguinte forma:
namespace StaticWebScraping {
public class Episode {
public string OverallNumber { get; set; }
public string Title { get; set; }
public string Directors { get; set; }
public string WrittenBy { get; set; }
public string Released { get; set; }
}
}
Como se pode ver, esta classe tem quatro atributos para armazenar todas as informações mais importantes a raspar sobre um episódio. Observe que OverallNumber é uma cadeia de caracteres porque o número do episódio de Bob Esponja sempre contém um caractere.
Agora, pode implementar a lógica C# de raspagem da web no seu ficheiro App.cs, como indicado abaixo:
using HtmlAgilityPack;
using System;
using System.Collections.Generic;
namespace StaticWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// downloading to the target page
// and parsing its HTML content
var document = web.Load(url);
// selecting the HTML nodes of interest
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new List<Episode>();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = HtmlEntity.DeEntitize(node.SelectSingleNode("th[1]").InnerText),
Title = HtmlEntity.DeEntitize(node.SelectSingleNode("td[2]").InnerText),
Directors = HtmlEntity.DeEntitize(node.SelectSingleNode("td[3]").InnerText),
WrittenBy = HtmlEntity.DeEntitize(node.SelectSingleNode("td[4]").InnerText),
Released = HtmlEntity.DeEntitize(node.SelectSingleNode("td[5]").InnerText)
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
Este raspador da web em C# percorre os nós HTML selecionados, cria uma instância da classe Episode para cada um deles e guarda-a na lista de episódios. Lembre-se de que os nós HTML de interesse são linhas de uma tabela. Por isso, é necessário selecionar alguns elementos com o método SelectSingleNode(). Em seguida, use o atributo InnerText para extrair os dados desejados para raspar deles. Observe o uso da função estática HtmlEntity.DeEntitize() para substituir os caracteres HTML especiais por suas representações naturais.
Passo 5: Exportar os dados raspados para CSV
Agora que aprendeu a fazer raspagem da web em C#, pode fazer o que quiser com os dados raspados. Um dos cenários mais comuns é converter os dados raspados num formato legível por humanos, como o CSV. Ao fazer isso, qualquer pessoa da sua equipe poderá explorar os dados raspados diretamente no Excel.
Vamos agora aprender como exportar dados raspados para CSV com C#.
Para facilitar as coisas, vamos utilizar uma biblioteca. CSVHelper é uma biblioteca .NET rápida, fácil de utilizar e poderosa para ler e escrever ficheiros CSV. Para adicionar a dependência CSVHelper, abra a seção “Gerenciar pacotes NuGet” no Visual Studio, procure “CSVHelper” e instale-o.
Pode utilizar o CSVHelper para converter os dados raspados em CSV, como indicado abaixo:
using CsvHelper;
using System.IO;
using System.Text;
using System.Globalization;
// scraping logic…
// initializing the CSV file
using (var writer = new StreamWriter("output.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// populating the CSV file
csv.WriteRecords(episodes);
}
Se não estiver familiarizado com a palavra-chave using, esta define um âmbito no final do qual os objetos nele contidos serão eliminados. Por outras palavras, using é excelente para lidar com recursos de ficheiros. Em seguida, a função WriteRecords() do CSVHelper encarrega-se de converter automaticamente os dados raspados em CSV e de os escrever no ficheiro output.csv.
Assim que seu raspador da Web C# terminar de ser executado, você verá um arquivo output.csv aparecer na pasta raiz do projeto. Abra-o no Excel e você verá os seguintes dados:
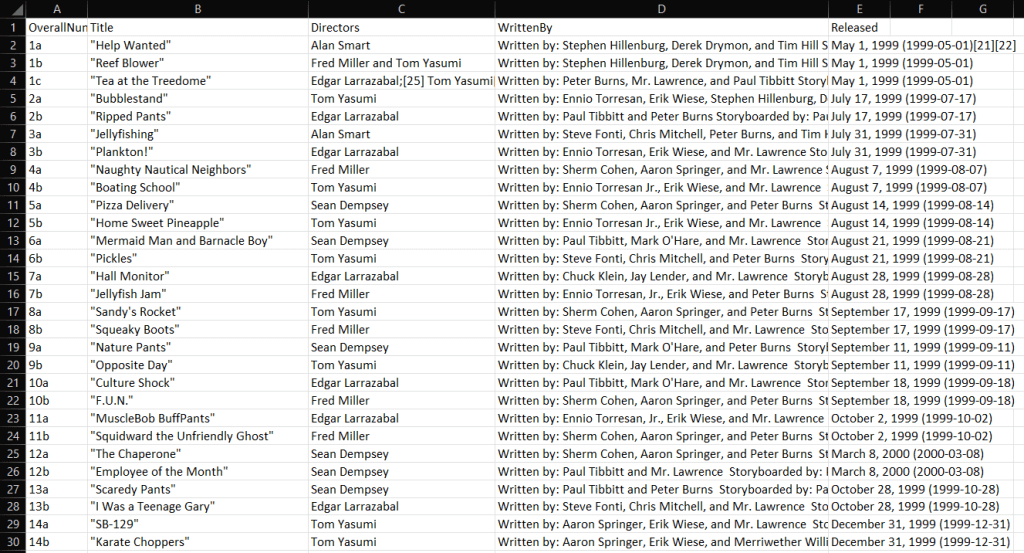
Et voilà! Acabou de aprender a fazer raspagem da web com C# em sítios web de conteúdo estático!
Raspagem de sítios web de conteúdo dinâmico em C#
Os sítios web de conteúdo dinâmico utilizam o JavaScript para obter dados de forma dinâmica através da tecnologia AJAX. Os documentos HTML associados a páginas de conteúdo dinâmico podem estar basicamente vazios. Ao mesmo tempo, contém scripts JavaScript que são responsáveis por recuperar e renderizar dados dinamicamente, no momento da renderização. Isso significa que, se você quiser extrair dados deles, precisará de um navegador para renderizar suas páginas. O motivo é que apenas um navegador pode executar JavaScript.
Raspar sítios web dinâmicos pode ser complicado e é definitivamente mais difícil do que raspar sítios estáticos. Em pormenor, você precisa de um navegador sem cabeça para raspar esses sítios. Se não estiver familiarizado com esta tecnologia, um navegador sem cabeça é um navegador sem GUI. Por outras palavras, se você quiser raspar sítios web de conteúdo dinâmico em C#, precisará de uma biblioteca que forneça recursos de navegador sem cabeça, como o Selenium.
Siga o parágrafo apresentado no início do artigo para configurar um novo projeto em C#. Desta vez, chame-o DynamicWebScraping.
Passo 1: Instalar Selenium
Selenium é uma estrutura de código aberto para testes automatizados que suporta várias linguagens de programação. Selenium fornece capacidades de navegador sem cabeça e permite-lhe dar instruções a um navegador web para executar ações específicas.
Para adicionar o Selenium às dependências do seu projeto, vá novamente à seção “Gerenciar pacotes NuGet”, procure “Selenium.WebDriver” e instale-o.
Importe o Selenium adicionando estas duas linhas no topo do seu ficheiro App.cs:
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
Passo 2: Ligar ao sítio web de destino
Uma vez que o Selenium abre o sítio web alvo num navegador, não é necessário efetuar manualmente um pedido HTTP GET. Tudo o que tem de fazer é utilizar o Selenium Web Driver da seguinte forma:
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
Aqui, você criou uma instância de driver da web do Chrome. Se você estiver usando outro navegador, adapte o código em conformidade, utilizando o driver do navegador correto. Depois, graças ao método Navigate() da variável driver, pode chamar o método GoToUrl() para se ligar à página web de destino. Em pormenor, esta função aceita um parâmetro URL e utiliza-o para visitar a página web associada ao URL no navegador sem cabeça.
Passo 3: Extrair dados de elementos HTML
Tal como vimos anteriormente, pode utilizar o seguinte seletor XPath para selecionar os elementos HTML de interesse:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
Utilize um seletor XPath no Selenium com:
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
Especificamente, o método de Selenium By.XPath() permite-lhe aplicar uma cadeia XPath para selecionar elementos HTML do DOM da página.
Agora, vamos supor que já definiu uma classe Episode.cs como anteriormente no espaço de nome DynamicWebScraping. Agora é possível criar um raspador da web em C# com o Selenium, conforme abaixo:
using System;
using System.Collections.Generic;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
namespace DynamicWebScraping {
public class Program {
public static void Main() {
// the URL of the target Wikipedia page
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// to initialize the Chrome Web Driver in headless mode
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// connecting to the target web page
driver.Navigate().GoToUrl(url);
// selecting the HTML nodes of interest
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
// initializing the list of objects that will
// store the scraped data
List<Episode> episodes = new();
// looping over the nodes
// and extract data from them
foreach (var node in nodes) {
// add a new Episode instance to
// to the list of scraped data
episodes.Add(new Episode() {
OverallNumber = node.FindElement(By.XPath("th[1]")).Text,
Title = node.FindElement(By.XPath("td[2]")).Text,
Directors = node.FindElement(By.XPath("td[3]")).Text,
WrittenBy = node.FindElement(By.XPath("td[4]")).Text,
Released = node.FindElement(By.XPath("td[5]")).Text
});
}
// converting the scraped data to CSV...
// storing this data in a db...
// calling an API with this data...
}
}
}
Como pode ver, a lógica de raspagem da web não muda muito em comparação com o que é feito com o HtmlAgilityPack. Em pormenor, graças aos métodos de Selenium FindElements() e FindElement(), é possível atingir o mesmo objetivo de raspagem de antes. O que muda verdadeiramente é que o Selenium executa todas estas operações num navegador.
Observe que em sítios de conteúdo dinâmico, talvez seja necessário aguardar que os dados sejam recuperados e renderizados. Isto pode ser conseguido com WebDriverWait.
Parabéns! Agora você aprendeu como realizar a raspagem da web em C# em sítios de conteúdo dinâmico. Só falta saber o que fazer com os dados raspados.
O que fazer com os dados raspados
- Armazene-os numa base de dados para os consultar sempre que necessário.
- Converta-os em JSON e utilize-os para chamar algumas APIs.
- Transformá-los em formatos legíveis por humanos, como CSV, para os abrir com Excel.
Estes são apenas alguns exemplos. O que realmente importa é que, depois de ter os dados raspados no código, pode utilizá-los como quiser. Normalmente, os dados raspados são convertidos num formato mais útil para a sua equipa de marketing, análise de dados ou vendas.
Mas não se esqueça de que a raspagem da web acarreta vários desafios!
Privacidade de dados com proxies
Se quiser evitar expor o seu IP, ser bloqueado e proteger a sua identidade, considere a adoção de proxies de raspagem da web. Um servidor proxy atua como uma porta de ligação entre a sua aplicação e o servidor do sítio web de destino, ocultando assim o seu IP.
Como resultado, um serviço proxy permite-lhe ultrapassar bloqueios de IP, raspar dados anonimamente e desbloquear conteúdos em todos os países. Existem diferentes tipos de proxy, e todos eles têm diferentes casos de utilização e objetivos. Certifique-se de que está a escolher o fornecedor de proxy certo.
Vamos agora analisar as vantagens que os proxies web podem trazer ao seu processo de raspagem da web.
Evitar a proibição de IP
Quando a sua aplicação de raspagem da web está a tentar aceder a um sítio web na Internet, o endereço IP de onde provém o pedido é público. Isto significa que os sítios web podem acompanhar esse fato e bloquear os usuários que fazem demasiados pedidos. É para isso que serve a deteção de bots. Se estiver a utilizar um proxy web, o servidor de destino verá o IP rotativo do proxy e não o seu. Assim, com os proxies, podemos contornar facilmente as proibições de IP.
Rotação de endereços IP
Os proxies premium geralmente oferecem funcionalidades de IP rotativo. Isso significa que toda vez que você entrar em contato com o servidor proxy, você receberá um novo endereço IP de um grande conjunto de IPs. Isto é ótimo para evitar que os sistemas antirraspagem o localizem.
Raspagem regional
Muitos sítios web alteram as suas informações com base no local de onde provém o pedido. Além disso, alguns deles só estão disponíveis em determinadas regiões. Raspar esses sítios para realizar pesquisas de mercado em todo o mundo pode ser um problema. Felizmente, é possível utilizar proxies anónimos para selecionar a localização do endereço IP de saída. Esta é uma excelente forma de coletar informações valiosas sobre produtos de sítios web internacionalizados.
Conclusão
Aqui, aprendeu a construir um raspador da web utilizando C#. Como viu, não são necessárias muitas linhas de código. Ao mesmo tempo, quando as suas páginas web alvo mudam, terá de atualizar o raspador em conformidade. Alguns sítios web fazem alterações à sua estrutura diariamente. É por isso que você deve tentar um IDE para Raspador da Web avançado. Os raspadores da Bright Data estão sempre atualizados, para que você possa se concentrar nos dados em vez de configurar seu raspador várias vezes.





