
Os scrapers falham de três maneiras: o HTML está vazio porque o JavaScript renderiza a página, os seletores CSS param de corresponder após uma atualização de frontend, e as solicitações são bloqueadas por produtos anti-bot como o Cloudflare. O Scrapling é uma biblioteca Python de código aberto que resolve todos os três problemas. Este guia demonstra cada parte em sites reais e mostra quando um serviço de proxy gerenciado se torna necessário em escala de produção.
TL;DR
O Scrapling combina três classes de fetcher (HTTP, Chromium, Firefox stealth), um parser adaptativo que reencontra elementos após renomeações de classes e um spider no estilo Scrapy em uma única biblioteca Python para scraping de dados em produção.
- Escolha o fetcher mais barato que funcione; escale para StealthyFetcher em sites protegidos contra bots.
- Seletores adaptativos se recuperam de mudanças de markup se você criar uma impressão digital de uma página conhecida e válida primeiro.
- Para produção, encapsule a lógica de parsing em um Spider com checkpointing e um alarme de resultado vazio.
- Quando o stealth local se esgotar (reputação de IP, produtos anti-bot empresariais), mude para proxies residenciais ou um endpoint de desbloqueio gerenciado.
Por que Scrapling, se requests + BS4 já existe?
A combinação de requests e BeautifulSoup ainda funciona para páginas estáticas com markup estável. O problema começa assim que você implanta um Scraper que precisa continuar funcionando.
Os seletores param de corresponder quando uma equipe de frontend renomeia ou reestrutura elementos. As páginas são renderizadas no servidor neste trimestre e no cliente no próximo. Um site que você raspou por um ano de repente adiciona o Cloudflare Bot Management, e cada solicitação retorna uma página de desafio.
Nenhum desses são problemas incomuns, mas cada um precisa de sua própria solução. Combinar essas soluções em um script requests tende a produzir uma coleção frágil de blocos try/except e fallbacks de seletores. (Para trabalhos de baixo volume onde os seletores continuam mudando, uma passagem de extração por LLM sobre o HTML renderizado agora é uma alternativa viável. O Scrapling vale o custo de configuração quando o custo por página importa e você está renderizando em escala.)
O Scrapling consolida as correções comuns em uma única biblioteca:
- Três fetchers, uma API. Um cliente HTTP rápido com impersonação de fingerprint TLS (Fetcher), um navegador controlado por Playwright (DynamicFetcher), e um navegador stealth baseado no Camoufox, uma build do Firefox modificada que mascara sinais comuns de automação (StealthyFetcher). Todos eles retornam o mesmo objeto parser, então mudar de fetcher não significa reescrever o código de seletores.
- Seletores que sobrevivem a mudanças de markup. Salve a impressão digital estrutural de um elemento na primeira execução e, nas execuções subsequentes, o Scrapling pode localizar o mesmo elemento mesmo que classes, IDs ou posições tenham mudado.
- Um framework Spider integrado. Solicitações concorrentes, throttling por domínio, pausa e retomada, conformidade com robots.txt e exportação JSON/JSONL, tudo integrado.
- Rotação de Proxy integrada. Um helper ProxyRotator se integra com todos os tipos de sessão, com substituições por solicitação.
Os três fetchers mapeiam para três níveis de dificuldade, então a decisão de qual usar geralmente é óbvia depois de verificar o alvo:
| Se a página é… | Use este fetcher | Custo por solicitação (tempo, memória) |
|---|---|---|
| HTML estático, sem anti-bot | Fetcher | milissegundos, sem navegador |
| Renderizada por JavaScript, sem anti-bot | DynamicFetcher | segundos, memória do Chromium |
| Atrás do Cloudflare ou anti-bot similar | StealthyFetcher | segundos, memória do Camoufox |
O parser do Scrapling tem aproximadamente a mesma velocidade que o Parsel e o lxml, e é mais rápido que o BeautifulSoup para documentos grandes. Para um documento de 5.000 elementos, os benchmarks oficiais mostram cerca de 2 ms contra mais de 1,5 segundos para bs4 + lxml. Improvável de importar em pequena escala, mas se acumula quando você está fazendo parsing de milhões de páginas por mês.
Antes de escolher qualquer biblioteca de scraping de dados, faça uma verificação rápida: o alvo expõe uma API oficial, um feed RSS ou Atom, um sitemap, um embed JSON-LD ou um dump de dados público? Quando esses existem, uma chamada de API geralmente é mais rápida e barata do que o scraping de dados. O scraping de dados é a resposta certa quando não há API, quando a API é paga ou tem limite de taxa além do que o caso de uso pode suportar, ou quando os dados necessários não são expostos pela API.
O Scrapling não é a ferramenta certa para tudo:
- Em escala de cluster distribuído, clusters Scrapy e executores distribuídos específicos de framework escalam melhor.
- Para scrapes equivalentes a curl que requests e um seletor BeautifulSoup de 5 linhas já lidam, use esses.
- Quando você precisa de um Scraper gerenciado sem escrever código, uma plataforma no-code é mais adequada.
O melhor encaixe é o Scraper de produção que precisa continuar funcionando semana após semana: complexidade suficiente para que a manutenção importe, mas não tanto que você precise de um cluster.
O Scrapling tem licença BSD-3; este guia foi verificado na v0.4.7 (abril de 2026). Os nomes de API usados no guia são estáveis; verifique o changelog para versões mais recentes se seus padrões forem diferentes. As anotações de tipo cobrem a API pública, o que importa se você está canalizando respostas por um pipeline tipado.
Instalar o Scrapling
As dependências do fetcher são um opt-in explícito, então você não está instalando o Playwright e o Camoufox em uma máquina que só precisa do parser. Instale com os extras do fetcher e os binários do navegador:
# pip
pip install "scrapling[fetchers]"
# ou com uv (mais rápido, com suporte a lockfile)
uv pip install "scrapling[fetchers]"
scrapling installO primeiro comando instala a biblioteca mais os fetchers HTTP e de navegador. O segundo baixa os binários do navegador (Camoufox para StealthyFetcher, Chromium para DynamicFetcher) junto com as dependências de sistema que eles precisam. No Windows, execute o terminal como administrador na primeira vez para que os binários possam ser instalados em todo o sistema.
Para verificar se tudo foi instalado corretamente:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://httpbin.org/headers')
print(page.status, page.json()['headers']['User-Agent'])Uma instalação funcional imprime 200 e uma string User-Agent no estilo Chrome. Se o User-Agent parecer python-requests/x.x, você está executando a build somente de parser; reinstale com o extra [fetchers] para que o pip também instale curl_cffi (a biblioteca que fornece a impersonação TLS do Fetcher).
Mais dois extras são úteis de conhecer:
- scrapling[shell] adiciona um shell IPython interativo (scrapling shell), um conversor de curl para Scrapling e uma CLI scrapling extract para buscar conteúdo do terminal em uma linha. Por exemplo, scrapling extract get https://example.com out.md escreve a página (ou um subconjunto por seletor CSS) como Markdown.
- scrapling[all] instala tudo, incluindo o servidor MCP (Model Context Protocol) para integrações de agentes de IA; consulte a documentação do projeto.
scrapling[fetchers] cobre todos os exemplos abaixo.
Seu primeiro scrape: extrair citações de uma página estática
O sandbox padrão é quotes.toscrape.com, que renderiza dez citações por página em HTML simples renderizado pelo servidor. Não há JavaScript, sem anti-bot e sem limite de taxa, então é um bom primeiro teste para o caminho Fetcher:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/', stealthy_headers=True)
for quote in page.css('.quote'):
text = quote.css('.text::text').get()
author = quote.css('.author::text').get()
tags = quote.css('.tag::text').getall()
print(f"{author}: {text[:60]}... [{', '.join(tags)}]")Fetcher.get() retorna um objeto Response que também atua como handle do parser. Definir stealthy_headers=True faz o Scrapling enviar cabeçalhos de navegador realistas, incluindo User-Agent, Accept, Accept-Language e sec-ch-ua, em vez de um conjunto de cabeçalhos padrão python-requests. Desnecessário em um sandbox, mas sites de produção frequentemente filtram pela consistência dos cabeçalhos.
page.css(‘.quote’) retorna um container Selectors de todos os elementos correspondentes. O pseudo-elemento ::text é uma convenção do Scrapy/Parsel que extrai o nó de texto diretamente em vez da tag ao redor.
A saída se parece com isso:
Albert Einstein: "The world as we have created it is a process of our t... [change, deep-thoughts, thinking, world]
J.K. Rowling: "It is our choices, Harry, that show what we truly are,... [abilities, choices]
Albert Einstein: "There are only two ways to live your life. One is as t... [inspirational, life, live, miracle, miracles]
...Se você já usou o Scrapy antes, a API é intencionalmente familiar. Se você usou BeautifulSoup, o Scrapling também tem find_all e find_by_text:
quotes = page.find_all('div', class_='quote')
einstein = page.find_by_text('Einstein', partial=True)Raspe um alvo real: a página inicial do Hacker News
Sites sandbox servem apenas para prática. A mesma estrutura de código funciona em alvos reais, com duas mudanças: os seletores vêm da inspeção do markup real, e os dados precisam de mais limpeza. O Hacker News é um primeiro alvo real útil (HTML estável, sem anti-bot) e seu layout tem uma estrutura incomum que vale conhecer: cada história é uma linha , com os metadados (pontos, usuário, idade) na linha irmã imediatamente seguinte. O Scraper:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://news.ycombinator.com/', stealthy_headers=True)
stories = []
for athing in page.css('tr.athing'):
title = athing.css('.titleline a::text').get()
href = athing.css('.titleline a::attr(href)').get()
rank = athing.css('.rank::text').get()
# Os metadados ficam na próxima linha irmã
subline = athing.next.css('.subline')
points_text = subline.css('.score::text').get() or '0 points'
user = subline.css('.hnuser::text').get()
age = subline.css('.age a::text').get()
stories.append({
'rank': int(rank.rstrip('.')) if rank else None,
'title': title,
'url': href,
'points': int(points_text.split()[0]),
'user': user,
'age': age,
'id': athing.attrib.get('id'),
})
print(f"scraped {len(stories)} stories")
for s in stories[:3]:
print(f" {s['rank']}. [{s['points']:>4}] {s['title'][:55]} by {s['user']}")O trecho usa três padrões que os exemplos do sandbox não mostram:
- athing.next navega para o próximo elemento irmão, útil quando linhas estruturalmente relacionadas compartilham dados (um padrão comum em markup antigo baseado em tabelas).
- .attrib.get(‘id’) lê um atributo HTML bruto quando não há um atalho ::attr() conveniente.
- O valor padrão or ‘0 points’ cobre postagens de emprego, que aparecem na página inicial do Hacker News sem pontuação.
Alvos reais quase sempre têm essas pequenas irregularidades (campos ausentes, tipos de itens mistos, linhas malformadas ocasionais). Ajuste os seletores e adicione pequenos valores padrão; a estrutura do código permanece a mesma.
Escreva scrapers sem seletores usando find_similar
Às vezes você nem precisa escrever o seletor de linha. Comece pelo texto visível, suba até o container correto e deixe o Scrapling encontrar todos os elementos estruturalmente similares:
sample = page.find_by_text("1.") # o rótulo de rank na história #1
row = sample.find_ancestor(lambda e: e.tag == "tr") # suba até a linha da história
peers = row.find_similar() # encontre todas as linhas similares
print(f"Found {len(peers) + 1} story rows without writing a CSS selector for the row")Na página inicial ao vivo, isso imprime 30 (cada linha de história, localizada por similaridade estrutural com a que começamos). find_similar aceita um similarity_threshold opcional (padrão 0.2; valores mais baixos significam uma correspondência estrutural mais rígida) e uma lista ignore_attributes (padrão para href e src) para que diferenças de URL não impeçam a correspondência. Para sites onde o markup muda mais rápido do que você consegue manter os seletores, combinar find_by_text com find_similar se sustenta melhor do que perseguir nomes de classes.
Extrair tabelas: dados de países da Wikipedia
Tabelas são outra forma comum de dados do mundo real: figuras financeiras, estatísticas esportivas, listas de referência. A Wikipedia fornece suas tabelas de dados sob uma única classe table.wikitable, que é consistente em toda a enciclopédia, então o mesmo padrão de seletor funciona em quase todo lugar. O scrape de população de países:
from scrapling.fetchers import Fetcher
URL = 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)'
page = Fetcher.get(URL, stealthy_headers=True)
table = page.css('table.wikitable')[0]
countries = []
for row in table.css('tbody tr'):
cells = row.css('td')
if len(cells) < 3: # pula cabeçalho e linhas de agrupamento
continue
name = cells[0].css('a::attr(title)').get()
pop_text = cells[1].text.strip()
if not name or not pop_text:
continue
countries.append({
'country': name,
'population': int(pop_text.replace(',', '')),
})
print(f"scraped {len(countries)} country rows")
top = sorted(countries, key=lambda c: c['population'], reverse=True)[:3]
for c in top:
print(f" {c['country']:<20} {c['population']:>15,}")Dois padrões importam aqui. cells[0].css(‘a::attr(title)’).get() extrai o nome do país do atributo title do link, que é mais limpo do que .text porque ignora a bagunça de ícones de bandeira na mesma célula. O guard if len(cells) < 3 ignora as linhas irregulares de cabeçalho e agrupamento que aparecem em quase qualquer tabela HTML de terceiros.
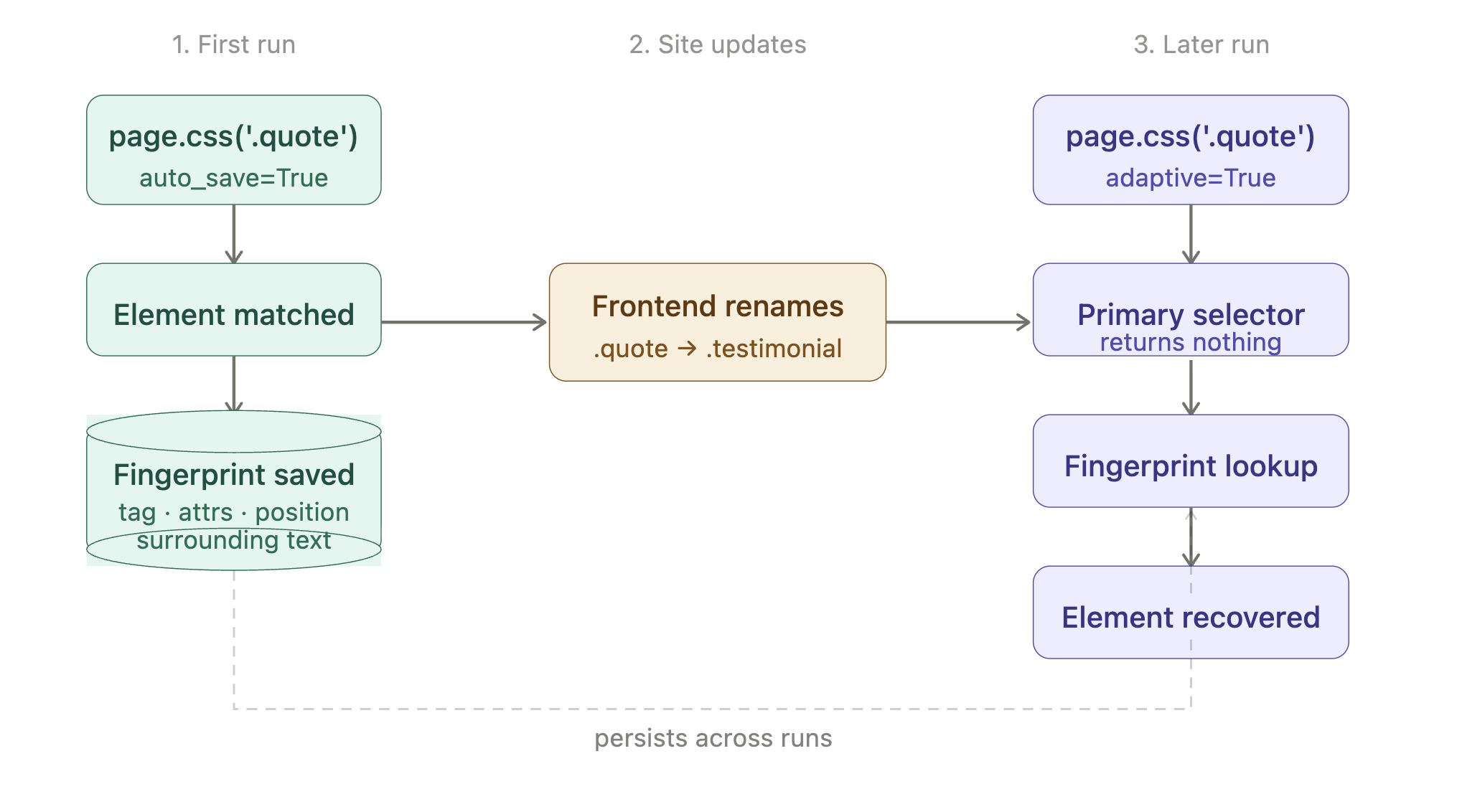
Seletores que sobrevivem a mudanças no site
Um site renomeia uma classe de .product-card para .product-tile. Seu Scraper começa a retornar resultados vazios. Você não percebe até que uma etapa posterior no seu pipeline reporte dados ausentes.
A resposta do Scrapling é uma opção de configuração mais dois flags. Cada um faz uma coisa:
| O que você escreve | Quando você escreve | O que faz |
|---|---|---|
| selector_config={‘adaptive’: True} na chamada do fetcher | Sempre (primeira E execuções posteriores) | Ativa o recurso. Sem isso, o Scrapling ignora silenciosamente os outros dois flags. |
| auto_save=True no .css() | Primeira execução | Registra a impressão digital estrutural do elemento correspondente (tag, atributos, posição, texto ao redor) em um pequeno arquivo SQLite local. |
| adaptive=True no .css() | Execuções posteriores | Se o seletor não retornar nada, usa a impressão digital salva para encontrar o elemento novamente. |
O ciclo de vida, do início ao fim:
Em código, fica assim:
from scrapling.fetchers import Fetcher
# Primeira execução: ative o adaptativo no fetcher, salve impressões digitais com auto_save
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', auto_save=True)
print(f"Found {len(quotes)} quotes on first run")
# Execução posterior: mesmo seletor, mais adaptive=True para o caminho de fallback.
# Se o site renomeou `.quote`, a impressão digital recupera os elementos.
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', adaptive=True)
print(f"Found {len(quotes)} quotes (recovered via fingerprint if needed)")O banco de dados de impressões digitais é armazenado ao lado do seu script, então o mesmo script reutiliza as impressões digitais salvas entre execuções. O padrão funciona da mesma forma em todos os fetchers: passe selector_config uma vez na chamada de fetch, depois use auto_save e adaptive nas chamadas .css().
Trate o arquivo de impressão digital como um artefato de migração: faça commit dele para execuções de CI reproduzíveis, monte-o como um volume no Docker e nunca execute auto_save=True contra uma página que você não verificou. Uma parede de CAPTCHA raspada com auto_save envenena a impressão digital, então execuções posteriores recuperam o elemento errado. Delete o arquivo para redefinir.
Limitação: a correspondência adaptativa só funciona quando o conteúdo do elemento permanece aproximadamente estável e apenas o markup muda. Se o site substituir a seção inteira por um recurso diferente, nenhum algoritmo pode recuperá-la. Mantenha alertas em conjuntos de resultados vazios para perceber quando um site mudou de uma forma que a impressão digital não consegue lidar.
Raspar páginas renderizadas por JavaScript
Muitos sites enviam um esqueleto HTML quase vazio e depois renderizam o conteúdo real no lado do cliente. A página de teste padrão para isso é quotes.toscrape.com/js, que serve as mesmas citações que a versão estática, mas as injeta via JavaScript. Se você apontar o Fetcher para ela, o resultado é previsível:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/js/')
print(page.css('.quote::text').getall())
# []Vazio. O texto está armazenado dentro de uma variável JavaScript var data = […] que o navegador executa no carregamento da página, e um cliente HTTP básico nunca executa esse script. A solução é usar DynamicFetcher, que controla uma instância real do Chromium internamente:
from scrapling.fetchers import DynamicFetcher
page = DynamicFetcher.fetch(
'https://quotes.toscrape.com/js/',
headless=True,
network_idle=True,
)
for quote in page.css('.quote'):
print(quote.css('.text::text').get())Dois flags nesse trecho importam. headless=True é o que você quer em um servidor. network_idle=True aguarda até que a atividade de rede tenha parado antes que o parser leia a página, o que captura a maioria das páginas renderizadas por JavaScript. Em SPAs com hidratação pesada (Next.js, Remix, SvelteKit), a rede pode ficar ociosa enquanto o React ainda está hidratando; para esses, passe wait_selector=”…” com um elemento conhecido e estável em vez disso, ou além disso.
Uma vez que o navegador tem a página, o restante da API é idêntico ao exemplo estático do Fetcher.
Cada sessão de navegador usa aproximadamente 1 GB de memória residente (a seção de escalonamento de produção tem o detalhamento). Para algumas centenas de páginas por dia, um worker de 2 GB resolve; acima de dezenas de milhares por dia, reutilize navegadores entre solicitações com DynamicSession, ou mova o trabalho para um Navegador de scraping gerenciado executando fora dos seus próprios servidores.
Contornar defesas anti-bot com StealthyFetcher
Produtos anti-bot modernos como Cloudflare Turnstile, DataDome e HUMAN Bot Defender (anteriormente PerimeterX) verificam dezenas de sinais para determinar se uma solicitação vem de um navegador real. A lista inclui impressões digitais de handshake TLS (JA3 e JA4 são os formatos comuns), ordenação de frames HTTP/2, propriedades do navigator (navigator.webdriver, listas de plugins, cabeçalhos de idioma), hashes de canvas e WebGL, e padrões de temporização. Uma vez que essas verificações estáticas passam, uma camada comportamental frequentemente assume (entropia de movimentos do mouse, cadência de rolagem, tempo de permanência). Uma sessão vanilla do Playwright ou Selenium expõe vários desses por padrão, razão pela qual “adicionei o Playwright e ainda estou sendo bloqueado” é uma pergunta comum em fóruns de scraping.
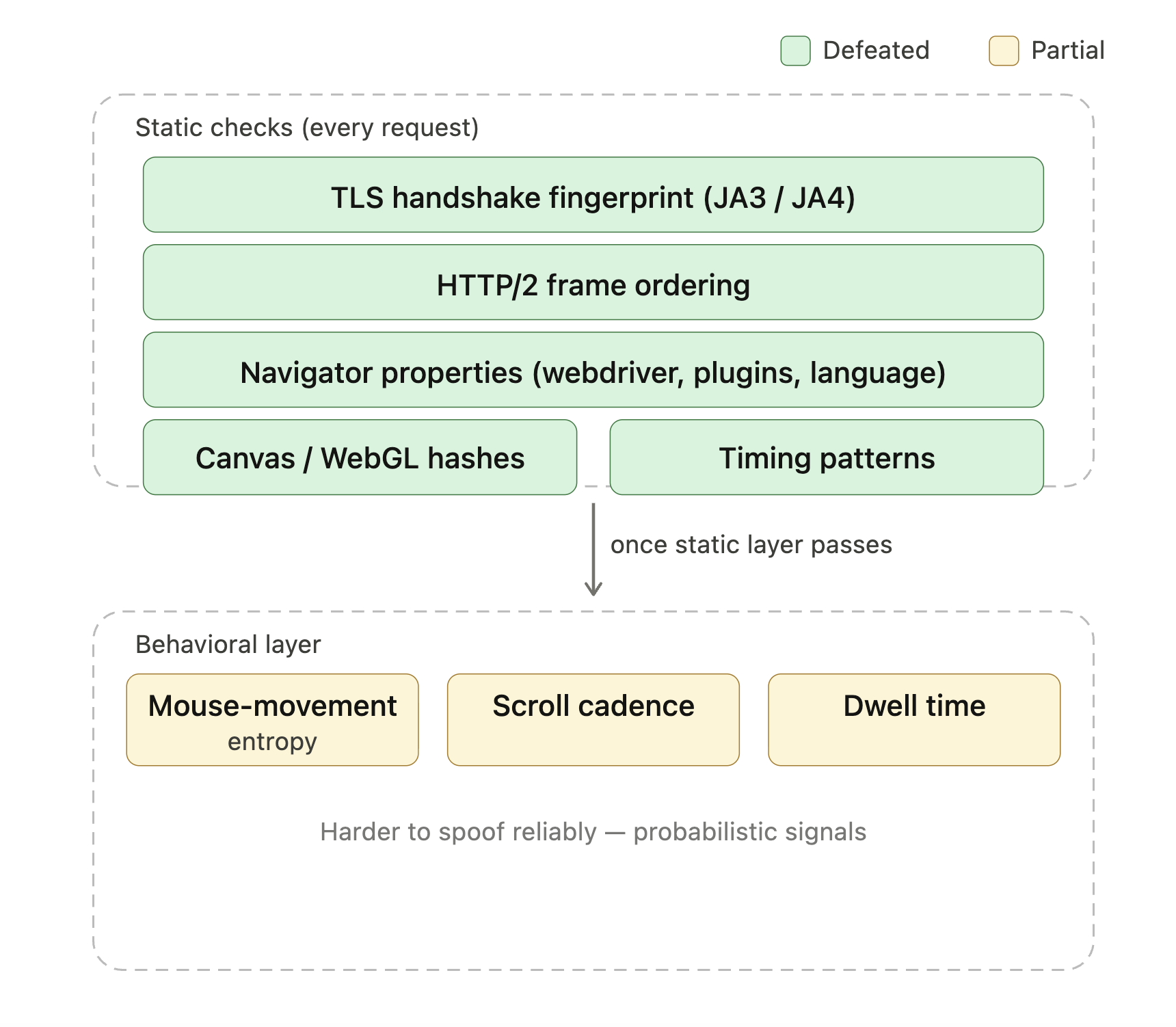
As camadas verdes são o que a base Camoufox do StealthyFetcher lida por conta própria; o amarelo é onde a pontuação comportamental entra e o desbloqueio gerenciado justifica seu custo.
O StealthyFetcher usa o Camoufox, uma build do Firefox modificada que mascara sinais comuns de automação, para derrotar as impressões digitais de navegador headless e Playwright que esses sistemas verificam. Para os níveis mais leves do Bot Management do Cloudflare, isso geralmente é suficiente por conta própria. Implantações de nível empresarial combinando Turnstile com pontuação comportamental ainda bloqueiam configurações stealth locais; é aí que o desbloqueio gerenciado se torna a resposta prática (abordado na seção de escalonamento de produção). Para sites que executam explicitamente desafios Turnstile, o Scrapling tem um flag solve_cloudflare que passa o desafio automaticamente:
from scrapling.fetchers import StealthyFetcher
page = StealthyFetcher.fetch(
'https://nopecha.com/demo/cloudflare',
headless=True,
solve_cloudflare=True,
network_idle=True,
)
links = page.css('#padded_content a::attr(href)').getall()
print(f"Found {len(links)} links past the challenge")A página nesse exemplo é uma demonstração pública do Cloudflare executando um desafio Turnstile real.
Alguns limites reais valem ser lembrados:
- O caminho solve_cloudflare funciona para desafios Turnstile gerenciados. Ele não promete lidar com todas as categorias de CAPTCHA. Desafios de grade de imagens (reCAPTCHA mais antigo, puzzles de imagem hCaptcha) precisam de um serviço de solver de terceiros (2Captcha, CapSolver) conectado a uma ação de página, ou um endpoint de desbloqueio gerenciado que lida com a camada de desafio de ponta a ponta.
- As técnicas de bypass stealth mudam frequentemente. Planeje uma verificação periódica em seus alvos reais, não uma configuração única.
- Os resultados também dependem da reputação do IP. Um IP de datacenter já sinalizado em um alvo não terá sucesso, independentemente de quão boa seja a impressão digital do navegador.
Para sites que não usam Cloudflare, obtenha os benefícios stealth sem o solver de desafios:
page = StealthyFetcher.fetch('https://example.com', headless=True)As proteções padrão de fingerprinting se aplicam, e solve_cloudflare não faz nada se não houver desafio para resolver.
Um padrão para conhecer: o bloqueio oculto
Sistemas anti-bot às vezes retornam um 200 OK com uma página de bloqueio disfarçada (uma parede de CAPTCHA, uma página de resultados vazia ou um intersticial “verificando se você é humano”) em vez de um 403 ou 503 explícito. Uma verificação de resultados vazios (mostrada no script pronto para produção) captura os casos óbvios. Para bloqueios ocultos onde a estrutura está intacta e apenas os dados estão errados, você vai querer uma verificação a nível de conteúdo: comparar o comprimento da resposta com uma linha de base, procurar strings reveladoras (“captcha”, “are you human”, “access denied” no corpo), ou amostrar os campos esperados de um item conhecido e estável. Nenhum é perfeito; juntos, capturam a maioria dos bloqueios silenciosos antes que dados ruins fluam para downstream.
O framework Spider expõe um hook is_blocked para isso: sobrescreva-o (também async def) e o Scrapling faz novas tentativas automáticas em respostas bloqueadas até max_blocked_retries (padrão 3):
class MySpider(Spider):
max_blocked_retries = 5
async def is_blocked(self, response: Response) -> bool:
body = (response.body or b'').lower()
return b'are you human' in body or b'captcha' in bodyAs contagens de tentativas bloqueadas aparecem em result.stats.blocked_requests_count após o crawl. Use este contador como sua métrica de alerta de produção.
Raspar páginas atrás de um login com FetcherSession
Alvos reais frequentemente requerem login. O padrão com FetcherSession é o fluxo padrão CSRF + cookie que você escreveria com requests + Session, apenas com o parser do Scrapling tratando a resposta. O sandbox Quotes-to-Scrape inclui um login funcional em /login, o que o torna um caso de teste simples:
from scrapling.fetchers import FetcherSession
with FetcherSession(impersonate='chrome') as session:
# 1. GET na página de login para pegar o token CSRF
login_page = session.get('https://quotes.toscrape.com/login')
csrf = login_page.css('input[name="csrf_token"]::attr(value)').get()
# 2. POST das credenciais. Cookies persistem na sessão automaticamente.
session.post(
'https://quotes.toscrape.com/login',
data={'csrf_token': csrf, 'username': 'demo', 'password': 'demo'},
)
# 3. Busca uma página bloqueada por login.
page = session.get('https://quotes.toscrape.com/')
if page.css('a[href="/logout"]').get():
print("Logged in OK")
# Páginas logadas neste sandbox mostram links extras do Goodreads por citação
print("first goodreads link:", page.css('a[href*="goodreads"]::attr(href)').get())Três coisas importam aqui:
- Use uma sessão, não chamadas individuais Fetcher.get(). FetcherSession persiste cookies (e qualquer Set-Cookie que o servidor retornar) entre solicitações; chamadas individuais Fetcher.get() não compartilham estado.
- Leia o token CSRF do formulário de login. A maioria dos frameworks modernos inclui um e rejeita solicitações POST sem ele. O nome do campo varia por framework: Django usa csrfmiddlewaretoken, Rails usa authenticity_token, e muitos SPAs enviam o token em um cabeçalho em vez disso, então inspecione o formulário antes de assumir um nome.
- Verifique se o login foi bem-sucedido antes de continuar. Verifique se há um link de logout, um nome de usuário na barra de navegação ou a ausência de um formulário de login. Se o login falhar sem um erro e você raspar a página pública, você obtém dados que parecem corretos, mas estão errados.
Para sites com 2FA, OAuth ou fluxos de login que emitem tokens de longa duração, a abordagem mais simples é fazer login uma vez manualmente (ou via API do site), capturar os cookies ou token resultantes e reutilizá-los. FetcherSession aceita um dict cookies={…} na construção para que você possa popular uma sessão a partir de cookies salvos.
Fetches concorrentes com AsyncFetcher
Quando você tem uma lista de URLs e precisa de todas elas, o Fetcher síncrono as serializa. AsyncFetcher expõe a mesma API como uma corrotina, para que você possa emitir todas as solicitações concorrentemente com asyncio.gather e deixar múltiplas viagens de rede rodarem em paralelo (o mesmo padrão que o scraping de dados assíncrono com AIOHTTP, com um parser já anexado):
import asyncio
from scrapling.fetchers import AsyncFetcher
URLS = [f'https://quotes.toscrape.com/page/{i}/' for i in range(1, 11)]
async def fetch_all():
tasks = [AsyncFetcher.get(u, stealthy_headers=True) for u in URLS]
pages = await asyncio.gather(*tasks)
return [q.css('.text::text').get()
for p in pages for q in p.css('.quote')]
quotes = asyncio.run(fetch_all())
print(f"scraped {len(quotes)} quotes")Nas mesmas 10 páginas de citações, isso reduz um fetch sequencial de 9 segundos para aproximadamente 1 segundo em uma conexão doméstica típica. FetcherSession em si também funciona sob async with, então você pode reutilizar cookies e cabeçalhos em chamadas assíncronas da mesma forma que no código síncrono. Para crawls completos com throttling, deduplicação e retomada, o framework Spider geralmente é a melhor escolha. AsyncFetcher importa quando você tem uma lista conhecida de URLs e quer apenas obtê-las em paralelo.
Uma armadilha: asyncio.gather(*tasks) puro relança a primeira exceção imediatamente, mas as outras tarefas continuam rodando em segundo plano; você perde acesso aos seus resultados sem parar o trabalho. Para listas de produção onde você quer sucesso parcial, passe return_exceptions=True e filtre os resultados, ou use asyncio.TaskGroup (3.11+), que cancela irmãos na primeira falha e dá tratamento de erro explícito por tarefa.
Construir um crawler de múltiplas páginas com o framework Spider
Um trabalho de scraping de dados real raramente é de uma página. Você segue a paginação, segue links de produtos, deduplica URLs, limita taxas de solicitação, escreve tudo em disco e retoma graciosamente se algo falhar. O Scrapling fornece um framework Spider para isso, com uma forma Spider/parse/yield que será familiar para usuários do Scrapy. Spiders que não dependem de middlewares, pipelines ou sinais do Scrapy portam de forma principalmente mecânica; o restante precisa de reescritas contra os hooks e a assinatura async parse do Scrapling.
Um crawler simples sobre books.toscrape.com, que tem um catálogo paginado de cinquenta páginas com cerca de mil livros:
from scrapling.spiders import Spider, Response
class BooksSpider(Spider):
name = "books"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5 # segundos entre solicitações por domínio
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
result = BooksSpider().start()
print(f"Scraped {len(result.items)} books")
result.items.to_jsonl("books.jsonl")Algumas coisas que este trecho faz que você construiria manualmente. concurrent_requests executa oito solicitações simultaneamente, o que no books.toscrape.com reduz um crawl completo de minutos para segundos. download_delay impõe uma lacuna por domínio para que você não sobrecarregue um único host. response.follow() resolve URLs relativas contra a página atual, o que remove um dos bugs de paginação mais comuns (esquecer de juntar um link next relativo). A assinatura async parse permite que você faça I/O por página (buscar páginas de detalhes, chamar APIs externas) sem bloquear o loop de crawl.
Dois métodos do parser valem conhecer. .re_first(pattern) em um resultado .css() retorna a primeira correspondência de regex, útil para extrair valores numéricos de texto formatado:
# transforma '£51.77' em 51.77 em uma expressão
price = float(book.css('.price_color::text').re_first(r'[d.]+'))E o container Selectors que .css() retorna tem um método .filter() que aceita um predicado, para que você possa refinar os dados que o Scrapling já tem sem escrever um segundo loop:
expensive = response.css('article.product_pod').filter(
lambda b: float(b.css('.price_color::text').re_first(r'[d.]+')) >= 50
)
yield {'count_over_50': len(expensive)}Útil quando o site não expõe um parâmetro de filtro de URL para o campo pelo qual você quer filtrar.
A exportação no final escreve um objeto JSON por linha, que é o que a maioria dos pipelines downstream espera. Você também pode usar .to_json() para um único array JSON, ou escrever seu próprio pipeline substituindo o hook process_item.
Para pipelines que precisam de itens à medida que são raspados em vez de esperar que todo o crawl termine, o Spider expõe .stream() como um gerador assíncrono:
import asyncio
async def main():
async for item in BooksSpider().stream():
await write_to_kafka(item) # ou qualquer outro sink downstream
asyncio.run(main())Para crawls mais longos, o mecanismo de pausa e retomada vale a pena configurar desde o início:
result = BooksSpider(crawldir="./crawl_data").start()Passe um crawldir e o Scrapling faz checkpoint das URLs visitadas e solicitações pendentes em disco. Pressione Ctrl+C e o crawl para graciosamente. Execute novamente com o mesmo crawldir e ele retoma de onde parou. Para um crawl de cinquenta páginas isso é desnecessário, mas para crawls de produção de longa duração (atualizações de catálogo, pesquisa de mercado, monitoramento de preços) é a diferença entre perder o progresso de um dia e não perder nada.
Se seu alvo requer os fetchers mais intensivos em recursos, o spider pode rotear solicitações por diferentes sessões por URL:
from scrapling.spiders import Spider, Request, Response
from scrapling.fetchers import FetcherSession, AsyncStealthySession
class HybridSpider(Spider):
name = "hybrid"
start_urls = ["https://example.com/catalog"]
def configure_sessions(self, manager):
manager.add("fast", FetcherSession(impersonate="chrome"))
manager.add("stealth", AsyncStealthySession(headless=True), lazy=True)
async def parse(self, response: Response):
for link in response.css('a::attr(href)').getall():
if "/protected/" in link:
yield Request(link, sid="stealth", callback=self.parse_protected)
else:
yield Request(link, sid="fast", callback=self.parse)
async def parse_protected(self, response: Response):
yield {"url": response.url, "title": response.css('h1::text').get()}Visualizado como um diagrama de roteamento:
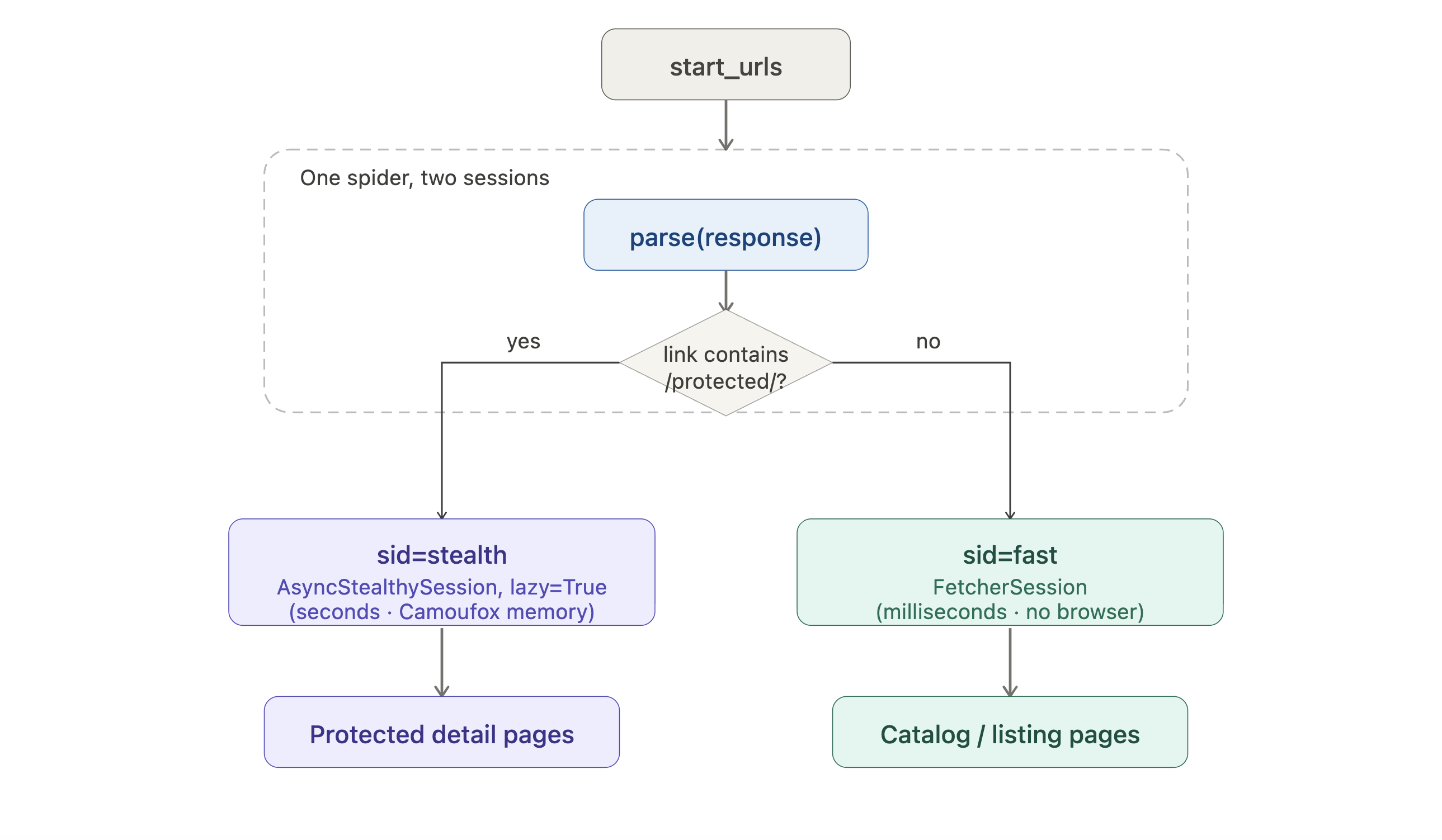
Páginas de listagem tomam o caminho HTTP barato; apenas páginas de detalhes protegidas pagam o custo do navegador. lazy=True adia a inicialização do navegador até que a primeira solicitação stealth realmente dispare, então um crawl que acaba atingindo apenas listagens nunca abre o Camoufox.
Alguns detalhes nesse exemplo não são óbvios pelo código. AsyncStealthySession e AsyncDynamicSession são sessões de navegador de longa duração. Reutilize-as em muitas solicitações, em vez de StealthyFetcher.fetch() ou DynamicFetcher.fetch() que iniciam um novo navegador a cada chamada.
configure_sessions recebe um manager (o registro de sessão do Spider); manager.add(name, session) registra uma sessão sob um nome para o qual você pode rotear posteriormente com Request(url, sid=name). O flag lazy=True na sessão stealth atrasa a abertura do navegador até que você faça a primeira solicitação stealth, então um crawl que apenas solicita páginas públicas nunca incorre na sobrecarga de inicialização do navegador.
A sessão fast usa o fetcher HTTP barato para as páginas de listagem, e apenas as páginas de detalhes protegidas requerem um navegador real. Esse tipo de roteamento é difícil de adicionar depois a um crawler de propósito geral.
Paginação em sites reais
Alvos reais raramente têm um link .next simples como o books.toscrape.com. Três padrões lidam com a maioria dos casos que você verá:
- Paginação numerada (por exemplo, ?page=1, 2, 3…) é a mais fácil. Gere as URLs em start_urls diretamente, ou produza objetos Request de parse em um loop.
- Scroll infinito geralmente depende de um endpoint XHR JSON. Abra DevTools → Network, role a página e procure a solicitação que retorna o próximo lote de itens. Então chame esse endpoint com Fetcher (muito mais barato do que renderizar cada scroll em um navegador).
- Botões “Carregar mais” precisam de um clique real dentro do navegador. DynamicFetcher e StealthyFetcher aceitam um callable page_action que recebe a página Playwright subjacente; clique no botão lá, aguarde o novo conteúdo, depois deixe o parser ler a página quando a função retornar:
from scrapling.fetchers import DynamicFetcher
def click_load_more(page):
# `page` é a Playwright sync Page subjacente.
for _ in range(5):
page.click("button.load-more")
page.wait_for_load_state("networkidle")
return page
result = DynamicFetcher.fetch(
"https://example.com/products",
page_action=click_load_more,
headless=True,
)
items = result.css(".product")Adapte o seletor e a contagem de cliques ao alvo. As classes de sessão assíncrona (AsyncDynamicSession, AsyncStealthySession) aceitam um equivalente assíncrono do mesmo callable.
Escalar o Scrapling para produção: proxies e desbloqueio
A arquitetura muda quando você está fazendo scraping de dados em um alvo de produção real em volume. Três restrições geralmente aparecem juntas:
- Reputação de IP. Um único IP residencial ou de datacenter que envia mil solicitações por hora para o mesmo site não se parece com um usuário real. A maioria dos alvos de produção limita a taxa, depois throttle, depois bloqueia. A solução é um pool de IPs, idealmente residenciais (conexões reais de consumidores) ou ISP (IPs de datacenter atribuídos por operadora que parecem residenciais para a pontuação anti-bot), que rotacionam por solicitação ou por sessão.
- Direcionamento geográfico. Alguns sites servem conteúdo diferente (ou preços diferentes) por país, estado ou cidade. Reproduzir essas visualizações precisa de proxies nesses locais.
- Anti-bot de nível CDN. Além do Turnstile básico do Cloudflare, o Akamai Bot Manager (e DataDome ou HUMAN em modo estrito) frequentemente bloqueia configurações stealth locais. Nesse ponto, um endpoint de desbloqueio gerenciado que mantém seu próprio pool de navegadores e solvers de desafios geralmente funciona melhor do que uma solução personalizada.
Tentativas, timeouts e erros transitórios
Erros de rede são inevitáveis em escala: resets de conexão, 503s ocasionais sob carga, 429s quando você está sendo limitado por taxa. FetcherSession aceita retries=, retry_delay= e timeout= na construção (padrões na v0.4.7: 3, 1 segundo, 30 segundos; confirme com help(FetcherSession) na sua versão instalada). Os fetchers de navegador (StealthyFetcher, DynamicFetcher) aceitam os mesmos parâmetros por fetch em cada chamada .fetch().
Para limites de taxa por alvo onde o servidor envia um cabeçalho Retry-After em um 429, leia esse cabeçalho no seu método parse e produza novamente o Request com um atraso. A tentativa padrão não respeita Retry-After, então depender dela faz você receber o mesmo 429 novamente.
Memória do navegador: números concretos de dimensionamento
Executar um navegador real é o custo de usar DynamicFetcher e StealthyFetcher. Em uma página de conteúdo típica (~200 KB HTML, sem SPA com muita mídia), uma única sessão Camoufox ou Chromium usa cerca de 700-900 MB de RAM no modo headless no Linux x86_64. O tamanho mal muda entre fetches na mesma sessão, então planeje para cerca de 1 GB por sessão de navegador concorrente ao dimensionar containers: um worker de 4 GB executa confortavelmente 3-4 sessões concorrentes, um worker de 8 GB lida com 6-8. Alvos mais pesados (páginas com muitas imagens, SPAs densas, sites que carregam dezenas de scripts de análise) empurram o custo por sessão para 1,2-1,5 GB. Reutilize suas sessões em vez de chamadas .fetch() únicas para não incorrer em atraso de inicialização do navegador em cada solicitação.
Dois flags de fetcher de navegador importam em volume de produção. block_ads=True ativa a lista de bloqueio integrada do Scrapling (cerca de 3.500 domínios de anúncios e rastreadores) e reduz o tempo de fetch em sites com muitos anúncios, ignorando solicitações de rede irrelevantes. dns_over_https=True roteia consultas DNS pelo endpoint DoH (DNS over HTTPS) do Cloudflare e ajuda a prevenir vazamentos de DNS quando você está roteando tráfego por um Proxy residencial. Ambos se aplicam a DynamicFetcher e StealthyFetcher (solicitações do fetcher HTTP não carregam recursos de página, então não precisam de nenhum dos flags).
Rotação de Proxy autogerenciada
O Scrapling tem um helper ProxyRotator que lida com o caso básico de rotação diretamente:
from scrapling.fetchers import FetcherSession
from scrapling.engines.toolbelt.proxy_rotation import ProxyRotator
rotator = ProxyRotator([
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
])
with FetcherSession(proxy_rotator=rotator) as session:
for url in target_urls:
page = session.get(url)
process(page)Para um pequeno projeto com um punhado de proxies estáticos, isso é tudo que você precisa. Para qualquer coisa maior, geralmente você quer um único endpoint que forneça um IP novo por solicitação (ou uma sessão sticky por usuário), e é aí que pagar por um provedor comercial faz sentido.
A rede de proxies residenciais da Bright Data se integra com o Scrapling usando o mesmo padrão de URL de Proxy: é um único endpoint de Proxy HTTP com autenticação por nome de usuário e senha, e o nome de usuário contém os parâmetros de roteamento que a rede precisa, incluindo país e ID de sessão sticky. Os valores vêm da página de Parâmetros de acesso da zona no painel da Bright Data.
Para executar o exemplo abaixo: cadastre-se em brightdata.com (teste gratuito, sem cartão necessário para começar), crie uma zona de Proxy residencial no painel e copie seu id, zona e senha na URL do Proxy. Os Proxies residenciais requerem uma verificação KYC única antes da ativação da zona. Aqui está uma configuração típica para rotação por solicitação:
from scrapling.fetchers import FetcherSession
# Substitua <id>, <zone> e <password> pelos valores do seu painel.
PROXY = "http://brd-customer-<id>-zone-<zone>:<password>@brd.superproxy.io:33335"
with FetcherSession(impersonate="chrome", verify=False) as session:
page = session.get(
"https://quotes.toscrape.com/",
proxy=PROXY,
stealthy_headers=True,
)Duas notas sobre esta configuração:
- Passe proxy= por solicitação, não no construtor FetcherSession. O proxy= por solicitação se comporta de forma consistente em todos os tipos de fetcher e é o caminho mais fácil para substituir por chamada. Isso se aplica a qualquer provedor, não apenas à Bright Data.
- Defina verify=False na sessão. A rede residencial da Bright Data encerra o salto do Proxy com uma cadeia de certificados autoassinada (padrão para serviços de Proxy residencial). A verificação é desabilitada apenas para o salto local ao Proxy; a conexão com o alvo ainda é TLS de ponta a ponta via método CONNECT do Proxy. O padrão mais limpo para produção é instalar o certificado CA da Bright Data no seu armazenamento de confiança e remover verify=False completamente; evite copiá-lo e colá-lo em caminhos de código que não passam pelo Proxy residencial.
Para sessões sticky (mesmo IP em múltiplas solicitações para manter um carrinho ou estado de login), o nome de usuário contém um ID de sessão, por exemplo brd-customer–zone–session-rand123. A lógica de rotação é executada no lado do provedor, e a biblioteca trata a URL como um Proxy HTTP regular.
A mesma integração do Scrapling funciona com outros tipos de Proxy da Bright Data (Proxies ISP para IPs de qualidade residencial em maior volume, Proxies móveis para visualizações exclusivas de mobile) com apenas o nome da zona na URL mudando.
Para os alvos mais difíceis, o padrão Web Unlocker vale conhecer. Em vez de executar seu próprio navegador stealth e atualizar impressões digitais sempre que um fornecedor lança uma nova verificação de detecção, você aponta o fetcher para um único endpoint; renderização, fingerprinting, rotação de IP e resolução de desafios acontecem remotamente. O Web Unlocker da Bright Data é construído em torno deste padrão, com direcionamento em nível de país e lógica de desbloqueio por domínio mantida pelo fornecedor. Seu código de parsing permanece o mesmo; apenas a linha de fetch muda.
O mesmo trade-off se aplica a alvos com muito JavaScript. Executar Camoufox ou Chromium localmente funciona para volume moderado. Quando você está gerenciando muitos containers de navegador, um Navegador de scraping gerenciado da Bright Data tira o desbloqueio e a manutenção de impressões digitais da sua equipe. O Navegador de scraping é um navegador remoto ao qual você se conecta por WebSocket usando o mesmo protocolo que o Playwright usa internamente, então ele se encaixa no mesmo caminho de código que um navegador Chromium local.
Duas notas práticas se aplicam ao escolher entre esses:
- Se o seu problema é “preciso de um IP diferente por solicitação para evitar limites de taxa”, Proxies residenciais mais o Fetcher ou StealthyFetcher local geralmente é suficiente. Você está pagando por IPs, não pelo trabalho de contornar bloqueios.
- Se o seu problema é “estou recebendo desafios CAPTCHA que não consigo resolver, e o site muda sua proteção a cada poucas semanas”, um endpoint de desbloqueio gerenciado geralmente economiza tempo de engenharia suficiente para justificar o custo maior por solicitação.
Um script Scrapling completo pronto para produção
Um BooksSpider básico roda bem em um sandbox. Cinco adições o tornam pronto para produção, marcadas com comentários numerados abaixo:
import logging
from datetime import datetime, timezone
from scrapling.spiders import Spider, Response
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s",
)
log = logging.getLogger("books")
class BooksSpider(Spider):
name = "books_production"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5
robots_txt_obey = True # 1. respeita robots.txt e Crawl-delay
async def parse(self, response: Response):
if response.status != 200: # 2. trata respostas não-200 explicitamente
log.warning("Non-200 status %s on %s", response.status, response.url)
return
books_on_page = response.css('article.product_pod')
if not books_on_page: # 3. detecta seletores desatualizados cedo
log.error("No books found on %s; selector may be outdated", response.url)
return
for book in books_on_page:
yield {
"scraped_at": datetime.now(timezone.utc).isoformat(), # 4. timestamp em cada linha
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
spider = BooksSpider(crawldir="./crawl_data") # 5. checkpoint para pausa/retomada
result = spider.start()
log.info("Scraped %d items", len(result.items))
result.items.to_jsonl("books.jsonl")O que cada adição oferece:
- robots_txt_obey respeita as diretivas robots.txt e Crawl-delay automaticamente.
- A verificação de status faz o spider registrar falhas do lado do servidor explicitamente em vez de tratá-las como “nenhum item encontrado”.
- A verificação de resultado vazio captura um seletor desatualizado na manhã seguinte em vez de três semanas depois, quando um relatório downstream não mostra dados.
- O timestamp registra quando cada linha foi raspada, para que reexecuções ao longo de dias não se misturem.
- crawldir significa que um Ctrl+C, um kernel panic ou uma conexão de rede perdida não destruirá o progresso do crawl.
Para mudar o mesmo script para Proxies residenciais, a única mudança é a sessão do fetcher. Para mudar para um endpoint Web Unlocker, mude a URL do Proxy para o serviço de desbloqueio. A lógica de parsing e o comportamento do spider permanecem idênticos.
Execute em um agendamento
Encapsule o script em cron, um timer systemd ou um orquestrador como Airflow ou Prefect. Use um crawldir por execução (por exemplo, ./crawl_data/$(date +%Y%m%d)) para que o estado de retomada de uma execução anterior não seja carregado para uma nova, e envie a saída para armazenamento durável em vez de deixá-la no disco da máquina worker. Destinos comuns: Parquet no S3 ou GCS lido por polars ou DuckDB para análise ad-hoc, ou uma tabela Postgres quando você precisa de buscas relacionais.
Para destinos além de arquivos JSONL, substitua os hooks on_start, on_scraped_item e on_close do Spider (todos os três são async def). Abra uma conexão de banco de dados ou produtor de fila de mensagens uma vez em on_start. Escreva cada item de on_scraped_item à medida que é produzido (retorne o item para encaminhá-lo, retorne None para descartá-lo). Limpe em on_close.
import asyncpg
from scrapling.spiders import Spider, Response
class BooksToPostgres(Spider):
name = "books_to_pg"
start_urls = ["https://books.toscrape.com/"]
async def on_start(self, resuming: bool = False) -> None:
self.db = await asyncpg.connect(DSN)
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
}
async def on_scraped_item(self, item):
await self.db.execute(
"INSERT INTO books (title, price) VALUES ($1, $2)",
item["title"], item["price"],
)
return item # encaminha downstream também
async def on_close(self) -> None:
await self.db.close()Quando o scraping quebra: uma lista de verificação de depuração
Scrapers de produção falham de formas que testes unitários não detectam. Algumas verificações rápidas lidam com a maioria dos problemas.
Abra o navegador no modo visível. Passe headless=False para StealthyFetcher.fetch() ou DynamicFetcher.fetch() e observe a página renderizar. Desafios CAPTCHA, cadeias de redirecionamento, redirecionamentos geo-IP e páginas de detecção anti-bot frequentemente só ficam óbvios quando você pode ver o que está acontecendo. Execute localmente; para servidores headless, salve uma captura de tela via page_action em vez disso.
Salve o HTML da resposta em disco. Quando um seletor não retorna nada, salve a resposta bruta e abra-a em um navegador:
page = Fetcher.get('https://example.com')
with open('debug.html', 'wb') as f:
f.write(page.body)Depois compare o que o parser recebeu com o que você esperava. Na maioria das vezes, o que você raspou acaba sendo uma parede de CAPTCHA, um redirecionamento para outro idioma ou uma página de resultados vazios que parece idêntica ao caso de sucesso à primeira vista. O HTML mostra a verdade mesmo quando o código de status é enganoso.
Use o shell interativo. Instale scrapling[shell] e execute scrapling shell. Ele carrega uma sessão IPython com o Scrapling pré-importado mais dois helpers úteis: uncurl(…) analisa um comando curl (do Copy as cURL do DevTools) em um objeto Request do Scrapling para que você possa inspecionar exatamente o que está sendo enviado, e curl2fetcher(…) analisa e executa, retornando uma Response analisada. Clique com o botão direito em qualquer chamada XHR no DevTools, copie como cURL, cole dentro do shell e você tem um fetch Scrapling funcional.
Faça engenharia reversa de um seletor a partir de um elemento que você já tem. Se você encontrou um elemento através de find_by_text, navegação ou qualquer outro lugar, as propriedades .generate_css_selector e .generate_xpath_selector (nota: propriedades, não métodos) fornecem um seletor reutilizável para ele:
einstein = page.find_by_text("Albert Einstein")
print(einstein.generate_css_selector)
# body > div > div:nth-of-type(2) > div > div > span:nth-of-type(2) > smallA saída não é legível por humanos, mas é reutilizável e sobrevive a mudanças de conteúdo que não movem o elemento.
Uma nota sobre o que verificar primeiro. Quando um Scraper que funcionou ontem quebra hoje, trabalhe da verificação mais rápida para a mais lenta: verificação de resultado vazio (“o seletor não retornou nada”), HTML salvo (“a página sequer renderizou?”), depois headless=False (“o site está desafiando o navegador?”).
Itere em parse() sem enviar outra solicitação ao alvo. Defina development_mode = True e development_cache_dir = “./_dev” na sua classe Spider:
class MySpider(Spider):
name = "iter"
start_urls = ["https://target.example.com/"]
development_mode = True
development_cache_dir = "./_dev"
async def parse(self, response):
...A primeira execução acessa a rede e armazena em cache todas as respostas em disco; execuções posteriores reproduzem do cache (cerca de 50 ms versus 1,2 segundos nos sites sandbox, aproximadamente 24x mais rápido). Enquanto você está ajustando seletores e limpando dados, você não precisa mais esperar pela rede em cada execução de teste. Defina development_mode de volta para False antes de implantar.
Próximos passos
Escolha um alvo real que você queria raspar e comece com o fetcher mais leve que funciona para ele. Fetcher lida com HTML estático; use DynamicFetcher quando o conteúdo é renderizado por JavaScript, StealthyFetcher quando o site fica atrás do Cloudflare ou de um fornecedor anti-bot comparável.
Para qualquer coisa que você planeja manter em execução, defina esses padrões desde o início:
- Encapsule a lógica de parsing em um Spider com crawldir, robots_txt_obey=True e uma verificação de resultado vazio em cada página.
- Ative selector_config={‘adaptive’: True} e auto_save=True na primeira execução para que a impressão digital estrutural esteja em disco antes que o site mude seu markup.
- Defina download_delay para pelo menos 0,5-1 s em infraestrutura compartilhada e leia o cabeçalho Retry-After no seu método parse para qualquer resposta 429.
Quando o stealth local não for mais suficiente (reputação de IP, escalonamento de concorrência, anti-bot de nível CDN), mude para um Proxy residencial ou um endpoint de desbloqueio gerenciado adicionando um único argumento proxy= em cada chamada de fetch. Qualquer provedor que exponha um Proxy HTTP com autenticação básica funciona da mesma forma.
Para a referência completa, consulte a documentação oficial.
FAQ
Posso usar o Scrapling em um produto comercial?
Sim. O Scrapling tem licença BSD-3-Clause, então você pode incluí-lo em produtos comerciais, backends SaaS ou ferramentas internas sem royalties ou um nível pago. Você só paga por serviços opcionais de terceiros que escolher, como um Proxy residencial ou um solver de CAPTCHA. Nenhum recurso no próprio Scrapling é bloqueado por licença.
Como o Scrapling se compara ao Playwright ou Selenium?
O Scrapling é construído especificamente para scraping de dados; Playwright e Selenium são ferramentas gerais de automação de navegador. O Scrapling encapsula uma build Camoufox com patches stealth (controlada via Playwright), tentativas, reutilização de sessão e seletores adaptativos, então você escreve menos código de cola e evita as impressões digitais Chromium-CDP que o Playwright vanilla expõe.
O Scrapling resolve CAPTCHAs?
Parcialmente. StealthyFetcher passa desafios Cloudflare Turnstile gerenciados quando solve_cloudflare=True. Outras categorias (hCaptcha de grade de imagens, CAPTCHAs de áudio, empresariais personalizados) precisam de um solver de terceiros (2Captcha, CapSolver) ou um endpoint de desbloqueio gerenciado que lida com a camada de desafio de ponta a ponta.
O Scrapling pode funcionar com o Scrapy?
Sim. O parser do Scrapling usa a mesma sintaxe de pseudo-elemento (::text, ::attr(href)) que o Parsel, então um Selector do Scrapling funciona dentro de um callback do Scrapy com a maioria dos seletores inalterados. A forma Spider/parse/yield é mantida; spiders sem middlewares ou pipelines pesados portam de forma principalmente mecânica.
Preciso de um serviço de Proxy para usar o Scrapling?
Não, o Scrapling funciona sem Proxy em trabalhos pequenos. Em volume de produção, use o ProxyRotator integrado do Scrapling com uma lista estática quando quiser controle total, ou um endpoint residencial, ISP ou móvel gerenciado quando precisar de IPs novos por solicitação ou direcionamento em nível de país.
O Scrapling pode rodar dentro do Docker?
Sim. O projeto fornece uma imagem Docker oficial com todas as dependências de navegador pré-instaladas. Para StealthyFetcher e DynamicFetcher, a imagem oficial economiza cerca de uma hora de fazer o Camoufox e o Chromium funcionarem em um container personalizado. Para o Fetcher básico, qualquer imagem Python padrão funciona.





