

Perlé uma das linguagens mais populares e, graças à sua extensa coleção de módulos, é uma ótima opção para escrever Scrapers.
Neste artigo, discutiremos o seguinte:
- Como fazer Scraping de dados com Perl usando os seguintes métodos:
LWP::UserAgenteHTML::TreeBuilderWeb::ScraperMojo::UserAgenteMojo::DOMXML::LibXML
- Desafios do Scraping de dados da web com Perl
- Conclusão
Scraping de dados com Perl
Para acompanhar o artigo, certifique-se de ter a versão mais recente do Perl instalada. O código deste artigo foi testado com o Perl 5.38.2. Este artigo também pressupõe que você sabe comoinstalar módulos Perl usandoo cpanm.
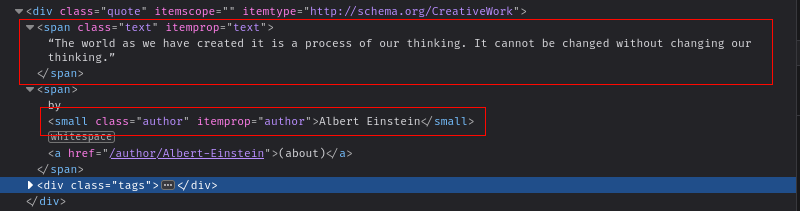
Neste artigo, você fará o scraping dosite Quotes to Scrapepara extrair as citações. Antes de fazer o scraping dos dados do site, você precisa entender como o HTML está estruturado. Abra o site no navegador e pressioneCTRL + Shift + I(Windows) ouCommand + Shift + C(Mac) para abrir a caixa de diálogoInspecionar Elemento.
Ao inspecionar os elementos, você verá que cada citação está armazenada em umdivcom a classequote. Cada citação contém umspancom a classetexte umpequenoelemento para armazenar o texto e o nome do autor, respectivamente:
Usando LWP::UserAgent e HTML::TreeBuilder
OLWP::UserAgentfaz parte doLWP, um grupo de módulos que interagem com a web. O móduloLWP::UserAgentpode ser usado para fazer uma solicitação HTTP a uma página da web e retornar o conteúdo HTML. Em seguida, você pode usar o móduloHTML::TreeBuilderdoHTML::Treepara analisar o HTML e extrair informações.
Para usar LWP::UserAgent e HTML::TreeBuilder, instale os módulos com os seguintes comandos:
cpanm Bundle::LWP
cpanm HTML::Tree
Crie um arquivo chamado lwp-and-tree-builder.pl. É aqui que você escreverá o código. Em seguida, cole as duas linhas a seguir nesse arquivo:
use LWP::UserAgent;
use HTML::TreeBuilder;
Este código instrui o interpretador Perl a incluir os módulos LWP::UserAgent e HTML::TreeBuilder.
Defina uma instância do LWP::UserAgent e defina o cabeçalho User-Agent como Quotes Scraper:
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
Defina a URL do site de destino e crie uma instância do HTML::TreeBuilder:
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
Agora você pode fazer a solicitação HTTP:
my $request = $ua->get($url) or die "Ocorreu um erro $!n";
Cole a seguinte instrução if-else que verifica se a solicitação foi bem-sucedida ou não:
if ($request->is_success) {
} else {
print "Não é possível analisar o resultado. " . $request->status_line . "n";
}
Se a solicitação for bem-sucedida, você pode começar a extrair os dados.
Use o método parse do HTML::TreeBuilder para analisar a resposta HTML. Cole o seguinte código dentro do bloco if:
$root->parse($request->content);
Agora, use o método look_down para encontrar os elementos div com a classe quote:
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
Itere sobre a matriz de citações, use look_down para encontrar o texto e o autor e imprima-os:
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
imprimir "$texto: $autor";
}
O código completo fica assim:
use LWP::UserAgent;
use HTML::TreeBuilder;
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $ua->get($url) or die "Ocorreu um erro $!n";
if ($request->is_success) {
$root->parse($request->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
} else {
print "Não é possível analisar o resultado. " . $request->status_line . "n";
}
Execute este código com perl lwp-and-tree-builder.pl e você deverá ver o seguinte resultado:
“O mundo como o criamos é um processo do nosso pensamento. Ele não pode ser mudado sem mudar nosso pensamento.”: Albert Einstein
“São nossas escolhas, Harry, que mostram quem realmente somos, muito mais do que nossas habilidades.”: J.K. Rowling
“Existem apenas duas maneiras de viver sua vida. Uma é como se nada fosse um milagre. A outra é como se tudo fosse um milagre.”: Albert Einstein
“A pessoa, seja homem ou mulher, que não tem prazer em um bom romance, deve ser intoleravelmente estúpida.”: Jane Austen
“A imperfeição é beleza, a loucura é genialidade e é melhor ser absolutamente ridículo do que absolutamente chato.”: Marilyn Monroe
“Tente não se tornar um homem de sucesso. Em vez disso, torne-se um homem de valor.”: Albert Einstein
“É melhor ser odiado pelo que você é do que ser amado pelo que você não é.”: André Gide
“Eu não falhei. Apenas descobri 10.000 maneiras que não funcionam.”: Thomas A. Edison
“Uma mulher é como um saquinho de chá; você nunca sabe o quão forte ele é até colocá-lo na água quente.”: Eleanor Roosevelt
“Um dia sem sol é como, você sabe, a noite.”: Steve Martin
Usando Web::Scraper
Web::Scraperé uma biblioteca de Scraping de dados inspirada noScrAPI do Ruby. Ela fornece uma linguagem específica de domínio (DSL) para extrair documentos HTML e XML. Confira este artigo para saber mais sobre Scraping de dados com Ruby.
Para usar o Web::Scraper, instale o módulo com cpanm Web::Scraper.
Crie um novo arquivo chamado web-scraper.pl e inclua os seguintes módulos necessários:
use URI;
use Web::Scraper;
use Encode;
Em seguida, você precisa definir um bloco de Scraper usando a DSL do módulo. A DSL facilita a definição de um Scraper em apenas algumas linhas. Comece definindo um bloco de Scraper chamado $quotes:
my $quotes = Scraper {
};
O método scraper define a lógica do scraper, que é executado quando o método scrape é chamado posteriormente. Dentro do bloco scraper, você usa o método process para encontrar elementos usando seletores CSS e executar uma função.
Comece encontrando todos os elementos div com a classe quote:
# Analise todos os `div` com a classe `quote`
process 'div.quote', "quotes[]" => Scraper {
};
Este código localiza todos os elementos div com a classe quote e os armazena na matriz quotes. Para cada elemento, ele executa o método Scraper, que você define usando o seguinte:
# E, em cada div, encontre `span` com a classe `text`
process_first "span.text", text => 'TEXT';
# obtenha `small` com a classe `author`
process_first "small", author => 'TEXT';
O método process_first encontra o primeiro elemento que corresponde ao seletor CSS. Aqui, você está encontrando o primeiro elemento span com a classe text e, em seguida, extraindo seu texto e armazenando-o na chave text. Para o nome do autor, você está encontrando o primeiro elemento small e extraindo o texto para armazenar na chave author.
O bloco completo do Scraper fica assim:
my $quotes = Scraper {
# Analisar todos os `div` com classe `quote`
process 'div.quote', "quotes[]" => Scraper {
# E, em cada div, encontrar `span` com classe `text`
process_first "span.text", text => 'TEXT';
# obter `small` com a classe `author`
process_first "small", author => 'TEXT';
};
};
Agora, chame o método scrape e passe a URL para iniciar a extração:
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
Por fim, itere sobre a matriz de citações e imprima o resultado:
# itere sobre a matriz
para meu $quote (@{$res->{quotes}}) {
imprimir Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
O código completo fica assim:
use URI;
use Web::Scraper;
use Encode;
my $quotes = scraper {
# Analise todos os `div` com a classe `quote`
process 'div.quote', "quotes[]" => scraper {
# E, em cada div, encontre `span` com a classe `text`
process_first "span.text", text => 'TEXT';
# obter `small` com classe `author`
process_first "small", author => 'TEXT';
};
};
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
# itere sobre a matriz
para meu $quote (@{$res->{quotes}}) {
imprima Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
Execute o código anterior com perl web-scraper.pl e você deverá obter o seguinte resultado:
“O mundo como o criamos é um processo do nosso pensamento. Ele não pode ser mudado sem mudar nosso pensamento.”: Albert Einstein
“São nossas escolhas, Harry, que mostram quem realmente somos, muito mais do que nossas habilidades.”: J.K. Rowling
“Existem apenas duas maneiras de viver sua vida. Uma é como se nada fosse um milagre. A outra é como se tudo fosse um milagre.”: Albert Einstein
“A pessoa, seja homem ou mulher, que não tem prazer em um bom romance, deve ser intoleravelmente estúpida.”: Jane Austen
“A imperfeição é beleza, a loucura é genialidade e é melhor ser absolutamente ridículo do que absolutamente chato.”: Marilyn Monroe
“Tente não se tornar um homem de sucesso. Em vez disso, torne-se um homem de valor.”: Albert Einstein
“É melhor ser odiado pelo que você é do que ser amado pelo que você não é.”: André Gide
“Eu não falhei. Apenas descobri 10.000 maneiras que não funcionam.”: Thomas A. Edison
“Uma mulher é como um saquinho de chá; você nunca sabe o quão forte ele é até colocá-lo na água quente.”: Eleanor Roosevelt
“Um dia sem sol é como, você sabe, a noite.”: Steve Martin
Usando Mojo::UserAgent e Mojo::DOM
Mojo::UserAgenteMojo::DOMfazem parte do frameworkMojolicious, um framework web em tempo real para Perl. Em termos de funcionalidade, eles são semelhantes aoLWP::UserAgente aoHTML::TreeBuilder.
Para usar Mojo::UserAgent e Mojo::DOM, instale os módulos usando o seguinte comando:
cpanm Mojo::UserAgent
cpanm Mojo::DOM
Crie um novo arquivo chamado mojo.pl e inclua os módulos Mojo::USeragent e Mojo::DOM:
use Mojo::UserAgent;
use Mojo::DOM;
Defina uma instância do Mojo::UserAgent e faça a solicitação HTTP:
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
Semelhante ao LWP::UserAgent, use o seguinte bloco if-else para verificar se a solicitação foi bem-sucedida:
if ($res->is_success) {
} else {
print "Não é possível parsar o resultado. " . $res->message . "n";
}
No bloco if, inicialize uma instância do Mojo::DOM:
my $dom = Mojo::DOM->new($res->body);
Use o método find para encontrar todos os elementos div com a classe quote:
my @quotes = $dom->find('div.quote')->each;
Itere sobre a matriz de citações e extraia o texto e os nomes dos autores:
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
A seguir está o código completo:
use Mojo::UserAgent;
use Mojo::DOM;
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
if ($res->is_success) {
my $dom = Mojo::DOM->new($res->body);
my @quotes = $dom->find('div.quote')->each;
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
imprimir "$text: $authorn";
}
} else {
imprimir "Não é possível analisar o resultado. " . $res->message . "n";
}
Execute este código com perl mojo.pl e você deverá obter o seguinte resultado:
“O mundo que criamos é um processo do nosso pensamento. Ele não pode ser mudado sem mudar nosso pensamento.”: Albert Einstein
“São nossas escolhas, Harry, que mostram quem realmente somos, muito mais do que nossas habilidades.”: J.K. Rowling
“Existem apenas duas maneiras de viver sua vida. Uma é como se nada fosse um milagre. A outra é como se tudo fosse um milagre.”: Albert Einstein
“A pessoa, seja homem ou mulher, que não tem prazer em um bom romance, deve ser intoleravelmente estúpida.”: Jane Austen
“A imperfeição é beleza, a loucura é genialidade e é melhor ser absolutamente ridículo do que absolutamente chato.”: Marilyn Monroe
“Tente não se tornar um homem de sucesso. Em vez disso, torne-se um homem de valor.”: Albert Einstein
“É melhor ser odiado pelo que você é do que ser amado pelo que você não é.”: André Gide
“Eu não falhei. Apenas descobri 10.000 maneiras que não funcionam.”: Thomas A. Edison
“Uma mulher é como um saquinho de chá; você nunca sabe o quão forte ele é até colocá-lo na água quente.”: Eleanor Roosevelt
“Um dia sem sol é como, você sabe, a noite.”: Steve Martin
Usando XML::LibXML
O módulo PerlXML::LibXMLé um wrapper em torno da bibliotecalibxml2. O móduloXML::LibXMLfornece um poderoso analisador XHTML com recursosXPath.
Use o cpanm para instalar o módulo:
cpanm XML::LibXML
Em seguida, crie um novo arquivo chamado xml-libxml.pl. Assim como no caso do HTML::TreeBuilder, você precisa usar uma biblioteca como LWP::UserAgent para fazer a solicitação HTTP ao site e buscar o conteúdo HTML, que você passa para XML::LibXML.
Cole o código a seguir, que configura o módulo LWP:UserAgent e busca o conteúdo HTML da página da web:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "Ocorreu um erro $!n";
if ($request->is_success) {
} else {
print "Não é possível analisar o resultado. " . $request->status_line . "n";
}
Dentro do bloco if, comece com o Parsing do documento HTML usando o método load_html:
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
A opção recover instrui o analisador a continuar analisando o HTML em caso de erro, e a opção suppress_errors faz com que o analisador não imprima erros de parsing HTML no console. Como os documentos HTML não são validados tão rigorosamente quanto um documento XHTML, é provável que você encontre erros de parsing não fatais. Essas opções mantêm o código funcionando caso esses erros ocorram.
Depois que o Parsing do HTML for realizado, você pode usar o método indnodes para encontrar os elementos com base em sua expressão XPath:
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
O código completo fica assim:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "Ocorreu um erro $!n";
if ($request->is_success) {
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
imprimir "$text: $authorn";
}
} else {
imprimir "Não é possível analisar o resultado. " . $request->status_line . "n";
}
Execute o código com perl xml-libxml.pl e você deverá ver o seguinte resultado:
“O mundo como o criamos é um processo do nosso pensamento. Ele não pode ser mudado sem mudar nosso pensamento.”: Albert Einstein
“São nossas escolhas, Harry, que mostram quem realmente somos, muito mais do que nossas habilidades.”: J.K. Rowling
“Existem apenas duas maneiras de viver sua vida. Uma é como se nada fosse um milagre. A outra é como se tudo fosse um milagre.”: Albert Einstein
“A pessoa, seja homem ou mulher, que não tem prazer em um bom romance, deve ser intoleravelmente estúpida.”: Jane Austen
“A imperfeição é beleza, a loucura é genialidade e é melhor ser absolutamente ridículo do que absolutamente chato.”: Marilyn Monroe
“Tente não se tornar um homem de sucesso. Em vez disso, torne-se um homem de valor.”: Albert Einstein
“É melhor ser odiado pelo que você é do que ser amado pelo que você não é.”: André Gide
“Eu não falhei. Apenas descobri 10.000 maneiras que não funcionam.”: Thomas A. Edison
“Uma mulher é como um saquinho de chá; você nunca sabe o quão forte ele é até colocá-lo na água quente.”: Eleanor Roosevelt
“Um dia sem sol é como, você sabe, a noite.”: Steve Martin
Você pode encontrar todo o código deste tutorial nesterepositório GitHub.
Desafios do Scraping de dados da Web em Perl
Embora o Perl facilite o Scraping de dados usando seus poderosos módulos, os desenvolvedores frequentemente se deparam com alguns problemas comuns que podem retardar ou impedir completamente o Scraping de dados da web. A seguir estão alguns dos desafios que você provavelmente enfrentará.
Lidando com a paginação
Os sites que lidam com um grande volume de dados nem sempre enviam todos os dados de uma só vez. Normalmente, os dados são enviados em várias páginas, e você precisa lidar com a paginação para garantir a extração de todos os dados. Existem duas etapas para lidar com a paginação:
- Verifique se existem outras páginas. Normalmente, você pode procurar um botãoPróxima páginana página ou tentar carregar a próxima página e procurar um erro.
- Se houver outras páginas, carregue a próxima página e faça o scraping.
Para sites estáticos, em que cada página tem seu próprio URL, você pode executar um loop e carregar novas páginas incrementando o parâmetro do número da página no URL. Ou, se estiver usando um módulo comoo WWW::Mechanize, você pode simplesmente seguir o URLda próxima página.
Aqui está o Scraper de citações modificado para lidar com a paginação usando WWW::Mechanize. Observe o uso de follow_link:
use WWW::Mechanize ();
use HTML::TreeBuilder;
use open qw( :std :encoding(UTF-8) );
my $mech = WWW::Mechanize->new();
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $mech->get($url);
my $next_page = $mech->find_link(text_regex => qr/Next/);
while ($next_page) {
$root->parse($mech->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach minha $citação (@citações) {
minha $texto = $citação->look_down(
_tag => 'span',
class => 'text'
)->as_text;
minha $autor = $citação->look_down(
_tag => 'small',
class => 'author'
)->as_text;
imprimir "$text: $authorn";
}
$mech->follow_link(url => $next_page->url);
$next_page = $mech->find_link(text_regex => qr/Next/);
}
Para lidar com sites dinâmicos que carregam a próxima página usando JavaScript, consulte nosso guia sobrecomo extrair dados de sites dinâmicos com Python ou continue lendo.
Proxy rotativo
Os proxies são comumente usados por scrapers de dados para proteger sua privacidade e anonimato e para evitar banimentos de endereços IP. Módulos comoLWP::UserAgenttêm a opção de definir proxies para scraping. No entanto, usar um único servidor proxy ainda corre o risco de ter o IP banido. É por isso que é recomendável usar vários servidores proxy e alterná-los. Aqui está um exemplo muito simples de como fazer isso usandoLWP::UserAgent.
Comece definindo uma matriz de Proxies. Em seguida, escolha um aleatoriamente e defina o Proxy usando o método Proxy:
my @proxies = ( 'https://proxy1.com', 'https://proxy2.com', 'http://proxy3.com' );
my $index = rand @proxies;
my $proxy = $proxies[$index];
$ua->proxy(['http', 'https'], $proxy);
Agora, você pode enviar uma solicitação normalmente. Se a solicitação falhar, isso provavelmente indica que o Proxy foi bloqueado, então você pode remover esse Proxy da lista, escolher um Proxy diferente e tentar novamente:
if(request->is_success) {
# Continue com a extração
} else {
# Remova o Proxy da lista
splice(@proxies, $index, 1);
# Tente novamente
}
Lidando com armadilhas honeypot
As armadilhas honeypotsão uma técnica comum empregada por administradores da web para capturar bots e Scrapers. Normalmente, eles usam links com a propriedadede exibiçãodefinida comonenhuma, o que os torna invisíveis para usuários humanos. Mas um bot pode detectá-los e seguir o link, que leva a uma página da web isca e afasta do produto principal.
Para resolver esse problema, verifique a propriedade de exibição dos links antes de segui-los. A seguir, apresentamos uma maneira de fazer isso usando HTML::TreeBuilder:
my @links = $root->look_down(
_tag => 'a',
);
foreach my $link (@qlinks) {
my $style = $link->attr('style');
if(defined $style && $style =~ /dislay: none/) {
# Honeypot detectado!
} else {
# Seguro para prosseguir
}
}
Resolução de CAPTCHA
Os CAPTCHAs ajudam a impedir o acesso não autorizado a um site. No entanto, eles também podem impedir que os Scrapers de dados coletem dados das páginas da web.
Para combater os CAPTCHAs, você pode usar um serviço como o Bright Data Web Unlocker, que realiza a resolução de CAPTCHA para você.
A seguir, um exemplo usando o Bright Data Web Unlocker para fazer uma solicitação HTTP:
use LWP::UserAgent;
my $agent = LWP::UserAgent->new();
$agent->Proxy(['http', 'https'], "http://brd-customer-hl_6d74fc42-zona-residential_proxy4:[email protected]:22225");
imprimir $agent->get('http://lumtest.com/myip.json')->content();
Quando você faz uma solicitação HTTP usando o Web Unlocker, ele realiza a resolução de CAPTCHA, evita medidas anti-bot e gerencia o Proxy para você.
Raspagem de sites dinâmicos
Até agora, todos os exemplos que você aprendeu aqui extraem sites estáticos. No entanto, aplicativos de página única (SPA) e outros sites dinâmicos precisam de técnicas mais avançadas.
Os sites dinâmicos usam JavaScript para carregar o conteúdo da página, o que significa que você precisa de ferramentas de scraping capazes de executar JavaScript.O Seleniumé uma dessas ferramentas que pode emular um navegador para executar sites dinâmicos. A seguir, um pequeno trecho de exemplo deste módulo em ação:
use Selenium::Remote::Driver;
my $driver = Selenium::Remote::Driver->new;
$driver->get('http://example.com');
my $elem = $driver->find_element_by_id('foo');
print $elem->get_text();
$driver->quit();
Conclusão
O Perl, graças à sua robusta coleção de módulos, é uma excelente linguagem para Scraping de dados. Neste artigo, você aprendeu como fazer Scraping de dados de páginas da web em Perl usando o seguinte:
LWP::UserAgenteHTML::TreeBuilderWeb::ScraperMojo::UserAgenteMojo::DOMXML::LibXML
No entanto, como você viu, o Scraping de dados enfrenta muitos desafios em cenários da vida real, quando os proprietários de sites estão determinados a impedir que os Scrapers façam scraping. Este artigo esclareceu alguns cenários comuns e como combatê-los. No entanto, pode ser tedioso e propenso a erros tentar resolver esses desafios sozinho. É aí quea Bright Datapode ajudar. Com os melhores serviços de Proxy, umNavegador de scraping,o Web Unlocker e a API Web Scraper definitiva, a Bright Data é uma solução abrangente para o Scraping de dados na web com facilidade. Comece um Teste grátis hoje mesmo!





