

Neste artigo, você aprenderá:
- O que é Scraping de dados com Camoufox e como ele reduz a detecção de bots baseada em impressões digitais.
- Como configurar o Camoufox com Proxies residenciais da Bright Data para uma extração de dados confiável.
- Onde o Camoufox tem um bom desempenho, onde ele falha em grande escala e quando mudar para o Navegador de scraping ou Web Unlocker da Bright Data para uso em produção.
O que é o Camoufox? Uma análise de seus principais recursos

O Camoufox é um navegador anti-detecção de código aberto construído sobre uma base Firefox modificada. Ele foi projetado para automação de navegadores e cenários de Scraping de dados em que navegadores headless padrão são facilmente identificados e bloqueados.
O Camoufox se concentra em reduzir a detecção, alterando o comportamento do navegador no nível do mecanismo, em vez de depender apenas de truques de JavaScript.
Principais recursos:
- Controle de impressão digital do navegador: o Camoufox modifica os atributos de impressão digital do navegador, como propriedades do navegador, interfaces gráficas, recursos de mídia e sinais de localidade. Essas alterações são aplicadas no nível do navegador, o que reduz as inconsistências que os sistemas anti-bot geralmente detectam.
- Patches furtivos no nível do mecanismo: o navegador anti-detecção Camoufox remove ou altera os indicadores de automação expostos pelas compilações padrão do navegador. Isso inclui o tratamento de propriedades que revelam estruturas de automação e evita assinaturas comuns de navegadores headless sem injetar scripts detectáveis no contexto da página.
- Isolamento e variabilidade da sessão: cada sessão do navegador Camoufox é isolada, permitindo que diferentes perfis de impressão digital sejam usados nas execuções. Isso ajuda a evitar a correlação entre as sessões ao raspar várias páginas ou reiniciar o navegador.
Instalação e configuração
Instale o Camoufox: o Camoufox é distribuído como um pacote Python e vem com um navegador baseado no Firefox. Isso evita a variação da versão do navegador, que aumenta a instabilidade da impressão digital.
pip install -U camoufox[geoip]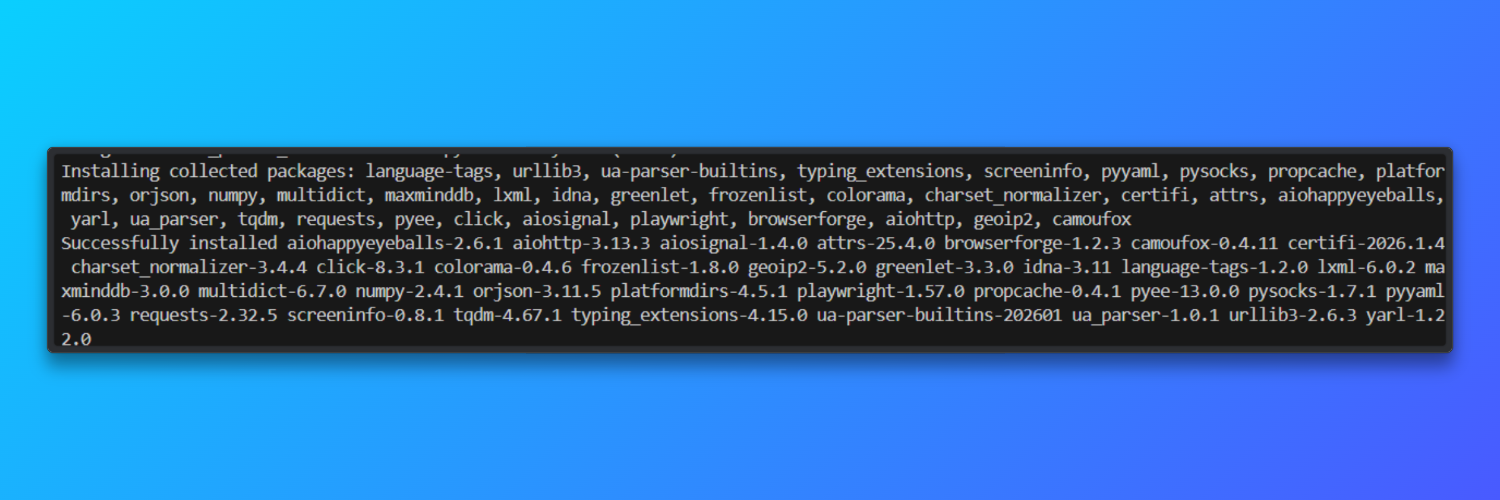
Baixe o navegador
camoufox fetch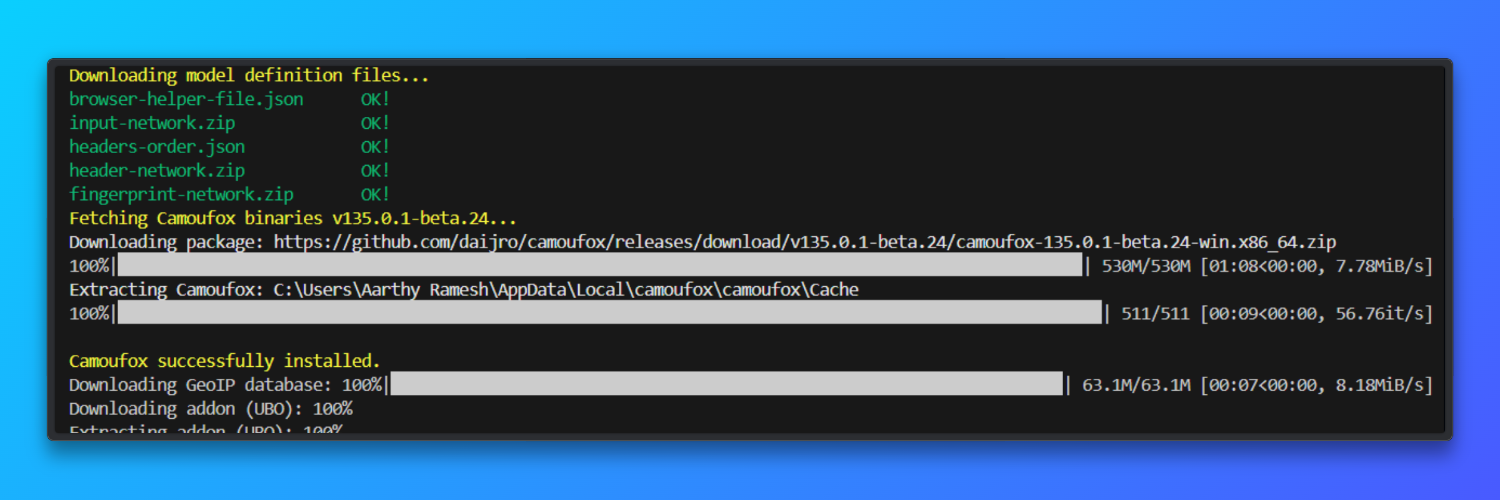
Requisitos de Python e sistema operacional: Python 3.9 ou mais recente é necessário no Windows e no macOS. Cada instância do Camoufox consome aproximadamente 200 MB de memória, o que limita a simultaneidade em sistemas com pouca RAM.
Ambiente virtual opcional (recomendado): o uso de um ambiente virtual evita conflitos de dependência que afetam o tratamento de SSL, a renderização de fontes ou APIs gráficas. Isso se aplica igualmente ao Windows e ao macOS.
python -m venv camoufox-envcamoufox-envScriptsactivate # Windowssource camoufox-env/bin/activate # macOSTutorial básico: Web scraping com Camoufox
Esta seção demonstra o fluxo de trabalho mínimo necessário para usar o Camoufox para Scraping de dados. O código inicia um navegador Camoufox, abre uma nova página e carrega uma URL exatamente como um usuário real. Ele aguarda até que todas as atividades de rede sejam concluídas para garantir que o conteúdo renderizado em JavaScript esteja disponível.
Uma captura de tela da página inteira é feita para confirmar visualmente que a renderização da página foi bem-sucedida. Por fim, o texto visível é extraído do corpo da página para verificar se o scraping funciona corretamente.
from camoufox.sync_api import Camoufox
with Camoufox(headless=True) as browser:
page = browser.new_page()
page.goto("<replace_with_a_link>")
page.wait_for_load_state("networkidle")
page.screenshot(path="page.png", full_page=True)
content = page.text_content("body")
print(content[:500])O script salva uma captura de tela chamada page.png no diretório do projeto, mostrando a página da web totalmente renderizada. O terminal imprime a primeira parte do texto visível da página, confirmando a extração bem-sucedida do conteúdo. Se a página carregar normalmente, nenhum erro será produzido.
O Camoufox é adequado para a prototipagem de fluxos de trabalho de scraping baseados em navegador, pois expõe o comportamento real do Firefox em vez de abstraí-lo.
Sua impressão digital nativa do navegador (nível C++) alcança cerca de 92% de sucesso quando combinada com Proxies residenciais de alta qualidade durante as primeiras sessões.
Como uma ferramenta de código aberto, é particularmente valiosa para aprender como os sistemas anti-bot modernos avaliam impressões digitais do navegador, cookies e estado da sessão.
Configurando proxies Bright Data com Camoufox
Esta seção explica como configurar corretamente os Proxies residenciais da Bright Data com o Camoufox para um Scraping de dados da web confiável e realista.
Por que os proxies residenciais são importantes
Os proxies residenciais encaminham as solicitações por meio de endereços IP reais de consumidores, em vez da infraestrutura do data center. Isso os torna significativamente mais eficazes para tarefas de Scraping de dados em que os sites monitoram ativamente os padrões de tráfego, a reputação do IP ou a origem da solicitação.
Muitos sites modernos implantam sistemas de mitigação de bots que bloqueiam rapidamente intervalos de IPs de nuvem ou data center. Os IPs residencialis reduzem esse risco porque se assemelham ao tráfego normal do usuário e são geograficamente consistentes com o comportamento real de navegação. Isso é especialmente importante ao fazer scraping de plataformas com muito conteúdo, páginas específicas de uma região ou sites que impõem limites de taxa e políticas de acesso.
Quando combinados com o Camoufox, os proxies residenciais oferecem duas vantagens principais: impressões digitais realistas do navegador e autenticidade no nível do IP. Essa combinação melhora as taxas de sucesso de carregamento de páginas, reduz a frequência de CAPTCHA e permite que os scrapers operem por mais tempo sem intervenção manual. Para pipelines de scraping de nível de produção, os proxies residenciais são um componente essencial da infraestrutura de scraping.
Configuração: Credenciais Bright Data + Configuração automática GeoIP
Faça login no painel da Bright Data e navegue até a seção Infraestrutura de Proxy. É aqui que todas as zonas de Proxy são criadas e gerenciadas.
Clique no botão Criar proxy para começar a configurar uma nova zona de Proxy. A Bright Data irá guiá-lo por um breve fluxo de configuração.
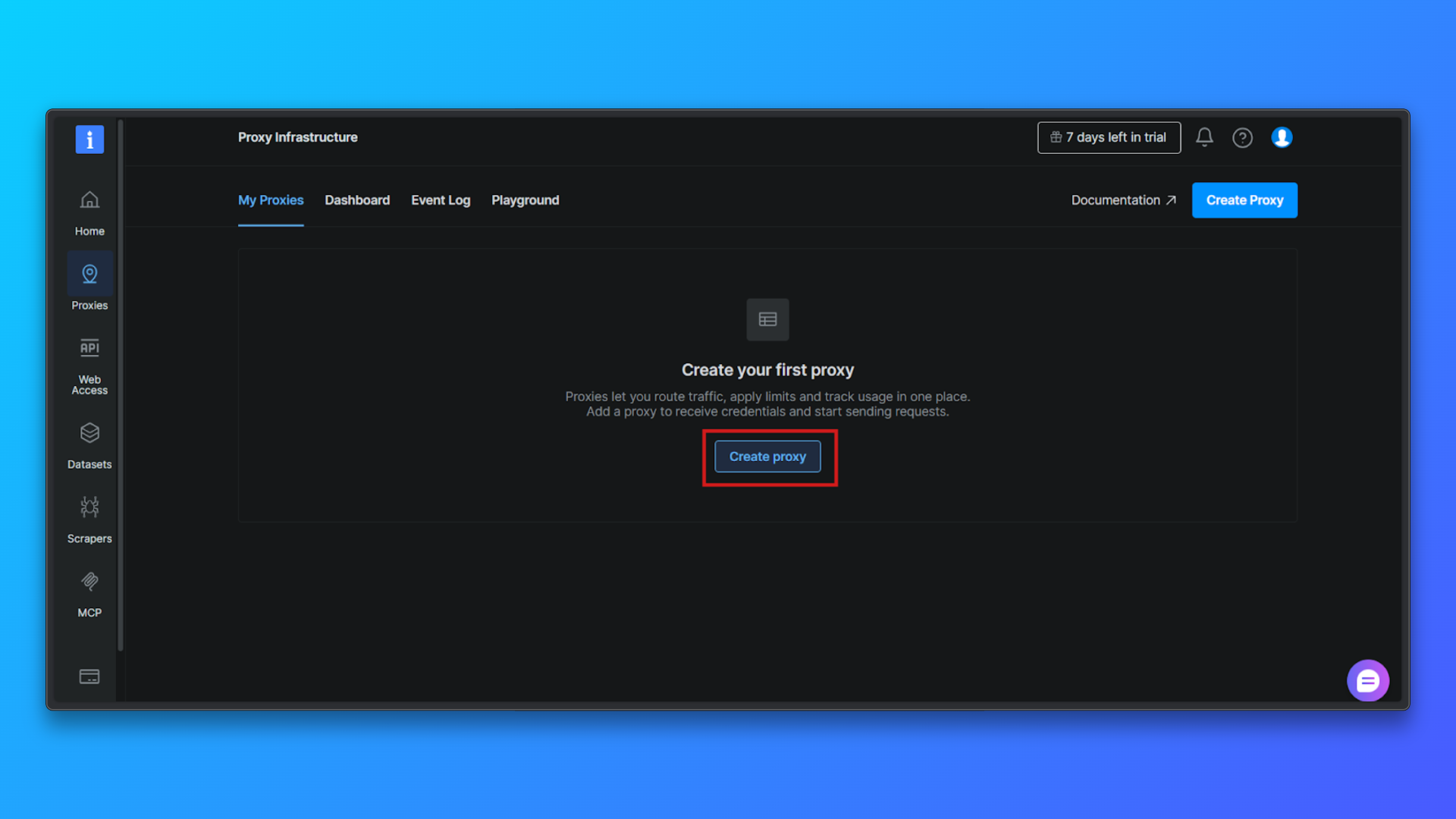
Escolha Tipo de proxy → Residencial: na lista de tipos de proxy, selecione Residencial. Os proxies residenciais encaminham o tráfego por meio de IPs residencialis reais, o que reduz significativamente a detecção em comparação com os proxies de datacenter.
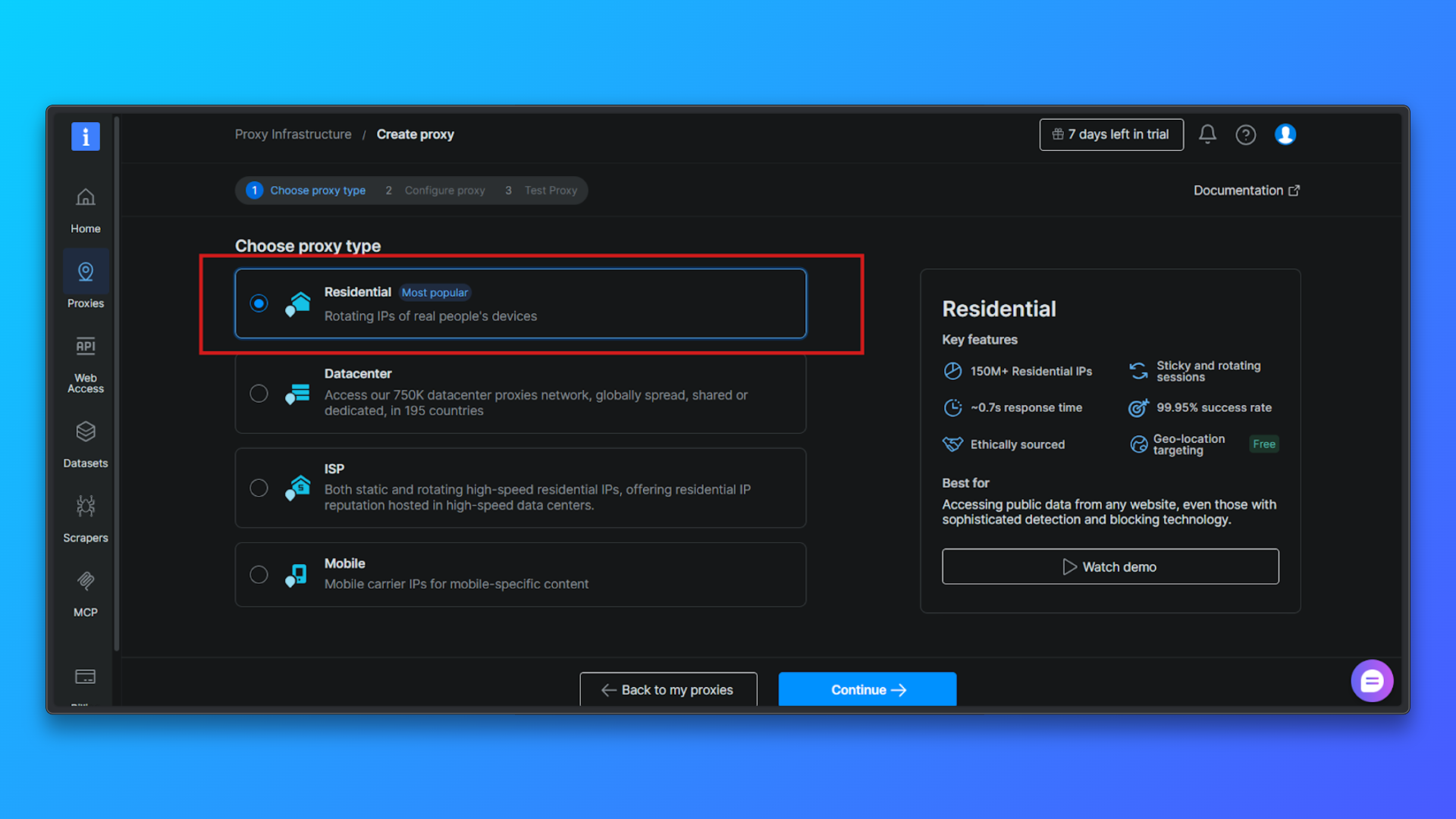
Configure o Proxy (opcional): você pode configurar opcionalmente: segmentação por país, comportamento da sessão, modo de acesso.
Para iniciantes, a configuração padrão é suficiente. Você pode prosseguir sem alterar as opções avançadas.
Clique em Continuar para criar a zona: confirme a configuração e conclua a instalação. A Bright Data criará uma zona de Proxy residencial e o redirecionará para a página Visão geral.
Revise as credenciais do Proxy na guia Visão geral: Na guia Visão geral, você verá:
- ID do cliente
- Nome da zona
- Nome de usuário
- Senha
- Host e porta do Proxy
- Modo de acesso
- Comando de terminal pronto para uso
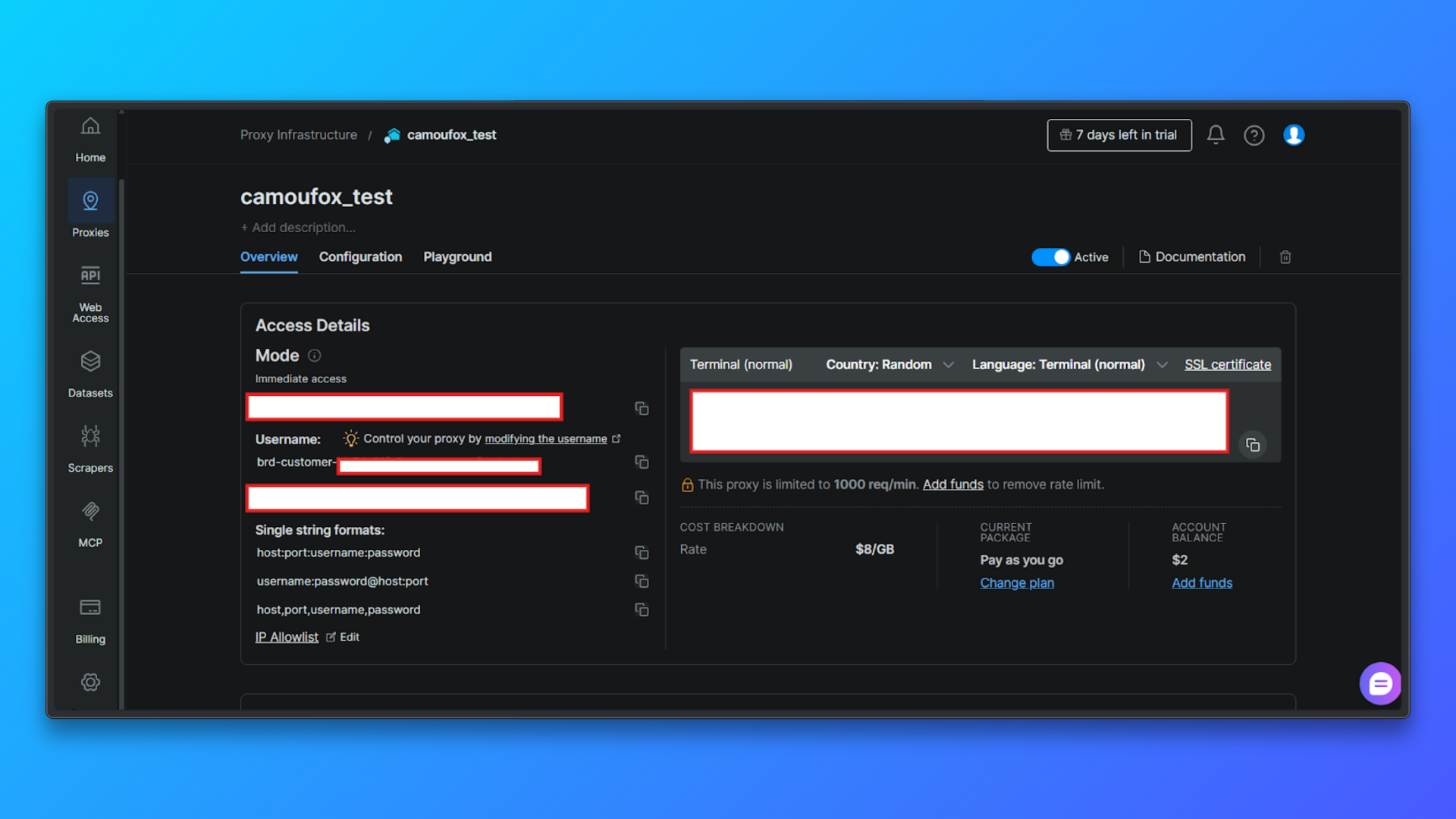
Esses valores serão necessários posteriormente ao configurar Proxies no código.
Validar credenciais usando o comando do terminal: Copie o comando do terminal (curl) fornecido no painel e execute-o localmente.
Este comando envia uma solicitação através do Proxy para o endpoint de teste da Bright Data e retorna:
- Status HTTP
- Resposta do servidor
- Detalhes do IP atribuído
- Informações sobre país, cidade e ASN
Uma resposta bem-sucedida confirma:
- As credenciais do Proxy são válidas
- A autenticação funciona
- O roteamento de IPs residenciais está ativo
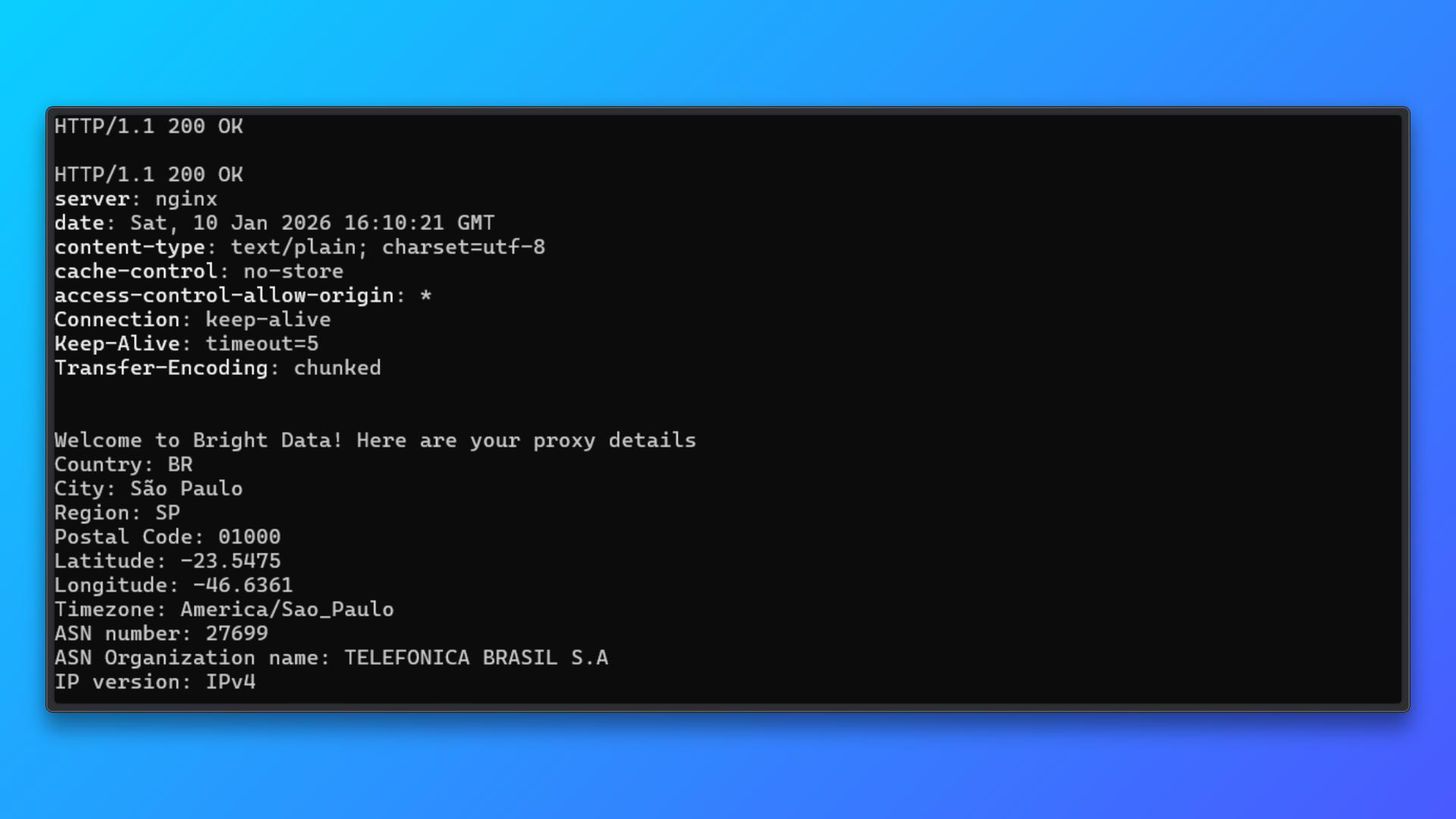
Esta etapa de validação isola problemas de configuração do Proxy antes de integrá-lo ao Camoufox ou a qualquer código de scraping.
A Bright Data permite o roteamento em nível de país diretamente através do nome de usuário. Isso significa que você não precisa gerenciar IPs manualmente.
O Camoufox pode, opcionalmente, alinhar o comportamento do navegador com a localização geográfica do Proxy usando geoip=True, o que melhora a consistência entre a localização do IP e os sinais do navegador.
Exemplo de código: Camoufox + Bright Data
Agora, vamos configurar os proxies Bright Data com o Camoufox.
Etapa 1: Importar Camoufox
from camoufox.sync_api import CamoufoxEtapa 2: Defina a configuração do Proxy Bright Data
Proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-Zona-<ZONE_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}O servidorpermanece constante para a Bright Data.- A segmentação por país é tratada no nome de usuário.
- As credenciais devem ser armazenadas com segurança em variáveis de ambiente para implantações reais.
Etapa 3: Inicie o Camoufox com o Proxy ativado
com Camoufox(
Proxy=Proxy,
geoip=True,
headless=True,)
como navegador:
página = browser.new_page(ignore_https_errors=True)
página.goto("https://example.com", wait_until="load")
print(página.title())Quando o script é executado com sucesso, o Camoufox inicia uma instância headless do Firefox roteada através dos Proxies residenciais Bright Data. O navegador carrega https://example.com e imprime o título da página no console.
Saída
Estratégia de rotação de Proxy
A Bright Data gerencia a rotação de IP no nível da rede, mas a eficácia da extração depende muito de como as sessões são estruturadas e reutilizadas no nível do navegador. A rotação de Proxy consiste em manter um comportamento de navegação realista em várias solicitações.
Ao usar IPs residencialis da Bright Data, os fluxos de trabalho de scraping normalmente alcançam cerca de 92% de carregamentos de página bem-sucedidos. Isso significa que a maioria das páginas carrega completamente sem ser bloqueada ou interrompida. Em comparação, configurações de scraping semelhantes usando Proxies de datacenter geralmente têm sucesso em apenas cerca de 50% das vezes, especialmente em sites que usam impressão digital, verificações de reputação de IP ou detecção de comportamento.
Abaixo estão as estratégias de rotação mais confiáveis para Scraping de dados na Web com Camoufox e Bright Data.
- Rotação baseada em sessão: em vez de alternar o IP para cada solicitação, uma única sessão do navegador é reutilizada para um número limitado de visitas à página. Após um limite fixo, como visitar várias páginas ou concluir uma tarefa lógica, a sessão é encerrada e uma nova é criada. Essa abordagem reflete a forma como usuários reais navegam em sites e ajuda a manter a consistência em cookies, cabeçalhos e padrões de navegação. A rotação baseada em sessão alcança um equilíbrio entre anonimato e realismo, tornando-a adequada para a maioria das cargas de trabalho de rastreamento e scraping.
- Rotação baseada em falhas: Nessa estratégia, as sessões são rotacionadas apenas quando algo dá errado. Se uma página não carregar, expirar ou retornar conteúdo inesperado, a sessão atual do navegador é descartada e uma nova é criada. Isso evita a rotação desnecessária durante solicitações bem-sucedidas, ao mesmo tempo que permite a recuperação de bloqueios ou rotas de Proxy instáveis. A rotação baseada em falhas é particularmente útil para rastreadores de longa duração, onde é esperada instabilidade ocasional da rede.
- Roteamento específico por país: a Bright Data permite o roteamento geográfico diretamente através do nome de usuário do Proxy. Ao incorporar um código de país nas credenciais da sessão, as solicitações são roteadas de forma consistente através de IPs de uma região específica. Isso é útil para acessar conteúdo bloqueado por região ou garantir que páginas localizadas retornem resultados corretos. Para obter melhores resultados, o comportamento de geolocalização do navegador deve permanecer alinhado com o país do Proxy para evitar sinais incompatíveis.
- Rastreamento com consciência de taxa: a rotação por si só não impede bloqueios se as solicitações forem enviadas de forma muito agressiva. O rastreamento com consciência de taxa introduz pausas intencionais entre as visitas às páginas e evita padrões de navegação rápidos. Mesmo com IPs residencialis, a extração muito rápida pode parecer anormal. Atrasos moderados combinados com a reutilização de sessões produzem padrões de tráfego que se assemelham muito mais ao comportamento real do usuário do que a rotação agressiva e de alta frequência.
- Evite rotação excessiva: a rotação de IPs em cada solicitação raramente é benéfica. A rotação excessiva pode criar padrões de tráfego não naturais, aumentar a sobrecarga da conexão e, às vezes, despertar suspeitas em vez de evitá-las. Na maioria dos casos, a reutilização moderada de sessões com rotação controlada leva a uma melhor estabilidade e taxas de sucesso mais altas a longo prazo.
Solução de problemas
- Erros SSL ou HTTPS: erros como avisos de certificado ou emissor podem ocorrer quando o tráfego HTTPS é roteado por Proxy. Sempre crie páginas com erros HTTPS ignorados para garantir que a navegação seja bem-sucedida.
- Tempo limite de carregamento da página: Proxies residenciais podem introduzir latência adicional. Aumente o tempo limite de navegação e evite esperar o carregamento completo da página se apenas parte do conteúdo for necessária.
- Falhas na autenticação do Proxy: verifique se o nome de usuário do Proxy segue o formato exigido pela Bright Data e se a porta e a senha corretas estão sendo usadas. Certifique-se de que a zona do Proxy esteja ativa no painel.
- Localização ou conteúdo de idioma incorreto: se as páginas retornarem conteúdo de uma região inesperada, confirme se o roteamento do país está especificado corretamente nas credenciais do Proxy e se o alinhamento de geolocalização está habilitado.
- CAPTCHAs frequentes ou bloqueios de acesso: isso geralmente indica um comportamento de scraping excessivamente agressivo. Reduza a frequência das solicitações, reutilize as sessões de forma mais eficaz e evite carregamentos paralelos de páginas em uma única instância do navegador.
- Conteúdo da página inconsistente ou parcial: algumas páginas carregam dados dinamicamente. Use condições de espera apropriadas e verifique se os elementos necessários estão presentes antes de extrair o conteúdo.
- Falhas ou desconexões inesperadas do navegador: reinicie a sessão do navegador periodicamente e limite as sessões de longa duração para evitar o esgotamento de recursos durante trabalhos de scraping prolongados.
- Bright Data Web Unlocker: para sites em que o Cloudflare bloqueia totalmente a automação do navegador, o Web Unlocker da Bright Data oferece um bypass automático do Cloudflare sem codificação, eliminando a necessidade de soluções alternativas no nível do navegador.
Projeto de comércio eletrônico do mundo real: Scraping de dados com Camoufox (código completo)
Este projeto demonstra o Scraping de dados da web baseado em navegador com o Camoufox em uma página de categoria de comércio eletrônico protegida pelo Cloudflare. O objetivo é extrair dados estruturados de produtos em várias páginas, lidando com falhas de navegação e paginação de maneira controlada e repetível.
Esse tipo de fluxo de trabalho é comum no Monitoramento de preços, análise de catálogos e Inteligência competitiva.
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
import time
# Configuração do Proxy Bright Data (mascarado)
Proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}
resultados = []
com Camoufox(
Proxy=Proxy,
headless=True,
geoip=True,)
como navegador:
# Crie uma nova página do navegador e permita a interceptação HTTPS
página = navegador.nova_página(ignorar_erros_https=True)
página.definir_tempo_limite_padrão(60000)
base_url = "https://books.toscrape.com/"
max_pages = 5
para page_number no intervalo (1, max_pages + 1):
tente:
imprimir(f"Raspando a página {page_number}")
# Navegar para a página
página.goto(
base_url,
wait_until="domcontentloaded"
)
# Localizar todos os cartões de produtos
livros = página.locator(".product_pod")
contagem = livros.count()
se contagem == 0:
imprimir("Nenhum produto encontrado, interrompendo rastreamento")
break
# Extrair dados de cada produto
para i no intervalo (contagem):
livro = livros.nth(i)
título = livro.localizador("h3 a").obter_atributo("título")
preço = livro.localizador(".preço_cor").texto_interno()
disponibilidade = livro.localizador(".disponibilidade").texto_interno().remover()
results.append({
"title": title,
"price": price,
"availability": availability,
"page": page_number,
})
# Adicionar um pequeno atraso para evitar padrões de solicitação agressivos
time.sleep(2)
exceto TimeoutError:
imprimir(f"Tempo limite na página {page_number}, pulando")
continuar
exceto Exception como e:
imprimir(f"Erro inesperado na página {page_number}: {e}")
quebrar
imprimir(f"nColetados {len(results)} livros")
# Visualizar alguns resultados
para item em resultados[:5]:
imprimir(item)O Camoufox inicia uma instância real do navegador Firefox, enquanto o Bright Data fornece IPs residencialis que se assemelham ao tráfego genuíno dos usuários.
O script navega até o site Books to Scrape, aguarda o carregamento do DOM da página e, em seguida, localiza cada cartão de produto na página.
De cada lista de livros, ele extrai campos estruturados, como título, preço e status de disponibilidade, e os armazena em uma lista Python para processamento posterior.
O código também inclui mecanismos básicos de resiliência necessários para a extração de dados no mundo real. Os tempos limite de navegação são tratados com elegância, erros inesperados interrompem o rastreamento com segurança e um pequeno atraso é adicionado entre os carregamentos da página para evitar padrões de tráfego agressivos.
Erros de interceptação HTTPS são explicitamente ignorados, o que é necessário ao rotear o tráfego do navegador por Proxies que encerram conexões TLS.
Resultado:
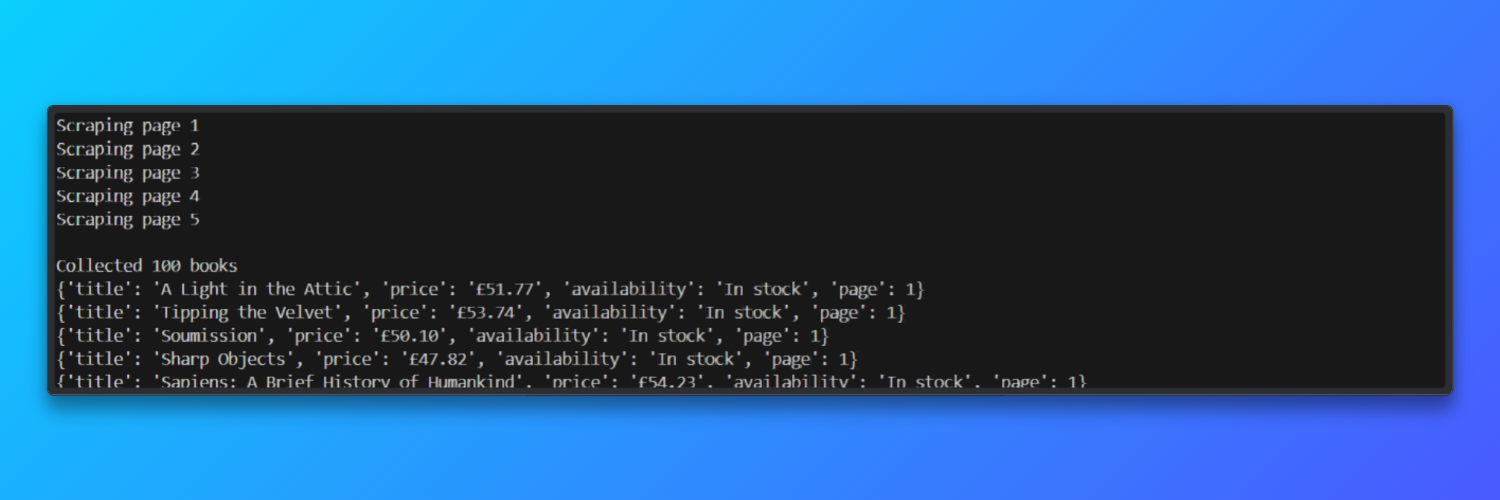
Em testes, o Scraper processou cinco páginas paginadas em aproximadamente 45 segundos e alcançou uma taxa de sucesso de carregamento de página de cerca de 92% ao usar Proxies residenciais da Bright Data.
Referências de desempenho e limitações
Esta seção resume o desempenho medido, as restrições práticas e as implicações de escalabilidade observadas ao usar o Camoufox com Proxies residenciais, e como essas restrições moldam a próxima etapa da arquitetura.
Referências medidas (observadas)
- Robustez da impressão digital: o Camoufox obtém uma pontuação de mais de 70% nos testes CreepJS, indicando forte resistência às verificações comuns de impressão digital do navegador para uma ferramenta de código aberto.
- Espaço de memória: ~200 MB de RAM por instância do navegador, o que limita diretamente o escalonamento horizontal em servidores típicos.
- Vida útil da sessão: os cookies expiram a cada 30-60 minutos, exigindo atualização manual ou reinicialização da sessão para manter o acesso.
- Taxa de sucesso com o tempo: ~92% na hora 1 → ~40% na hora 2 → ~10% na hora 3, à medida que as sessões envelhecem e os sistemas de detecção se adaptam.
- Contraste de infraestrutura: a Bright Data fornece mais de 175 milhões de IPs, 99,95% de tempo de atividade e 0 horas de manutenção do lado do usuário.
Limitações observadas em escala
À medida que o Scraping de dados da web com o Camoufox se prolonga ou se expande, várias restrições tornam-se evidentes:
- Expiração da sessão: os cookies geralmente expiram em 30 a 60 minutos, exigindo atualização manual ou reinicialização do navegador para manter o acesso.
- Uso de memória: cada instância do navegador consome cerca de 200 MB de RAM, o que limita a simultaneidade em servidores padrão.
- Limite de simultaneidade: em um servidor de 8 GB, os limites práticos são de cerca de 30 instâncias simultâneas do navegador antes que a estabilidade seja prejudicada.
- Diminuição da confiabilidade ao longo do tempo: as taxas de sucesso caem visivelmente à medida que as sessões envelhecem — ~92% na primeira hora, ~40% na segunda hora e ~10% na terceira hora sem intervenção.
- Carga operacional: manter resultados consistentes geralmente requer de 20 a 30 horas por mês de manutenção e ajuste ativos.
Para equipes que precisam de trabalhos de longa duração ou tempo de atividade previsível, essas limitações mudam o foco da lógica de scraping para o gerenciamento da infraestrutura.
Nesta fase, as soluções gerenciadas tornam-se uma alternativa prática. A infraestrutura da Bright Data oferece mais de 175 milhões de IPs residencialis, 99,95% de tempo de atividade e elimina a necessidade de gerenciamento manual de cookies e sessões.
Em ambientes de produção, isso normalmente resulta em mais de 99% de sucesso consistente, sem a degradação gradual observada na automação de navegadores autogerenciados.
Quando o tempo de manutenção e os custos de infraestrutura são incluídos, as configurações gerenciadas geralmente reduzem o custo mensal total em comparação com as abordagens DIY. (US$ 1.200/mês contra US$ 2.850 DIY (incluindo manutenção)).
Camoufox vs Puppeteer vs Bright Data (tabela comparativa)
A tabela abaixo compara o Camoufox com os Proxies residenciais Bright Data, Puppeteer e o Navegador de scraping Bright Data em relação aos fatores mais importantes em projetos reais de scraping.
| Recurso | Camoufox + Bright Data Proxies | Puppeteer | Bright Data Scraping Browser |
|---|---|---|---|
| Taxa de sucesso | ~92% de sucesso com Proxies residenciais | ~15–30% em sites protegidos | Mais de 99% de sucesso consistente |
| Esforço de configuração | Configuração média com ajuste de Proxy e impressão digital | Configuração alta com patches e plug-ins | Configuração baixa, pronto para usar |
| Gerenciamento de cookies | Atualização manual a cada 30–60 minutos | Manipulação totalmente manual | Gerenciamento automático de cookies |
| Limite de escalabilidade | ~30 navegadores simultâneos por servidor | ~50 navegadores simultâneos | Escalabilidade ilimitada |
| Manutenção/mês | 20–30 horas de manutenção contínua | 40–60 horas de manutenção | 0 horas necessárias |
| Custo (1 milhão de solicitações) | ~$2.850 incluindo uso de Proxy | ~$2.500 mais tempo de engenharia | ~$1.200 custo total |
Quando migrar para a Bright Data
Ignorar o anti-bot O navegador Camoufox é uma ótima opção para criar fluxos de trabalho de scraping em estágio inicial, mas não foi projetado para uso contínuo e de alto volume.
À medida que os projetos crescem, a expiração de cookies a cada 30-60 minutos, a diminuição das taxas de sucesso em longas execuções e a necessidade de reinicializações frequentes do navegador introduzem sobrecarga operacional.
O scraping de dados com o Camoufox exige uma taxa de sucesso consistente de mais de 99%, maior simultaneidade do que ~30 navegadores por servidor e desempenho previsível sem ajustes contínuos. Migrar para a Bright Data se torna o próximo passo prático.
As soluções de scraping gerenciadas da Bright Data lidam com impressões digitais do navegador, persistência de sessão, novas tentativas e dimensionamento automaticamente, o que elimina a manutenção manual e estabiliza pipelines de longa duração.
Principais conclusões
Este guia mostrou como o Scraping de dados com Camoufox funciona na prática, onde ele se destaca e onde aparecem seus limites. O Camoufox combinado com Proxies residenciais é adequado para prototipagem, experimentação e compreensão dos sistemas modernos de detecção de bots.
Para ambientes de produção onde confiabilidade, escala e eficiência de custo são importantes, uma infraestrutura de scraping gerenciada como a BrightData oferece um caminho operacional mais claro.
Se sua configuração do Camoufox Python já estiver funcional, mas exigir reinicializações frequentes, redefinições de sessão ou ajuste de Proxy, o fator limitante é a infraestrutura, e não a lógica de scraping.
Explore as Proxies residenciais e o Navegador de scraping da Bright Data para reduzir o esforço de manutenção e obter resultados estáveis e de nível de produção em escala.
Além disso, o Navegador de scraping da Bright Data atua como uma alternativa ao Camoufox em escala de produção, lidando automaticamente com impressões digitais, persistência de sessão e novas tentativas.
No geral, essa é uma das maiores, mais rápidas e mais confiáveis redes de Proxy orientadas para scraping do mercado.
Inscreva-se agora e comece seu teste gratuito de Proxy!






