

Neste tutorial, você aprenderá:
- Como configurar o Snowflake para receber dados da infraestrutura de entrega da Bright Data.
- Configurar o conjunto de dados Goodreads Books para entrega diretamente em um stage interno do Snowflake.
- Acionar um snapshot e carregá-lo em uma tabela consultável, depois executar SQL em mais de 6 milhões de registros de livros.
Vamos começar!
Apresentando o Fluxo de Ingestão do Snowflake
Em alto nível, o pipeline tem três fases, cada uma abordada em sua própria seção:
- Configuração do Snowflake: Crie o banco de dados, stage, role e usuário de serviço contra o qual a Bright Data se autenticará. Esta é a parte com mais SQL, mas cada comando é fornecido completo e executado em ordem.
- Configuração da Bright Data: Escolha um conjunto de dados do marketplace, conecte-o ao seu ambiente Snowflake e acione um snapshot. A Bright Data envia os arquivos diretamente para seu stage interno.
- Carregar e consultar: Um único comando
COPY INTOmove os arquivos em stage para uma tabela estruturada. O restante é SQL padrão.
O resultado é uma tabela Snowflake totalmente consultável, preenchida com dados web estruturados, atualizada no agendamento que seu caso de uso exigir. Sem exportações CSV, sem código ETL personalizado.
Saiba mais sobre cada fase e como implementá-las!
1. Configuração do Snowflake
A Bright Data entrega arquivos autenticando-se diretamente na sua conta Snowflake. Isso requer um stage interno dedicado (uma zona de recepção para arquivos recebidos), uma role de serviço com acesso de escrita a esse stage e um usuário de serviço atribuído a essa role.
Usar objetos dedicados para esse fim mantém a ingestão separada de suas cargas de trabalho analíticas e facilita a auditoria, revogação ou rotação de credenciais posteriormente.
2. Configuração do Conjunto de Dados da Bright Data e Entrega de Snapshot
O Marketplace de Conjuntos de Dados da Bright Data contém conjuntos de dados pré-construídos e validados que cobrem Amazon, LinkedIn, Crunchbase, Glassdoor, listagens de hotéis, imóveis, ofertas de emprego e muito mais. Cada conjunto de dados vem com uma referência completa de campos para que você possa projetar seu schema do Snowflake antes de o primeiro byte chegar.
A entrega direta para o Snowflake está disponível para o produto Datasets. Se você estiver usando as APIs de Web Scraper, entregue os arquivos em um bucket S3 e carregue a partir de um stage externo.
Depois de configurar o Snowflake como destino de entrega, a Bright Data gerencia a transferência. Ela se autentica usando o usuário de serviço que você criou, coloca os arquivos em seu stage interno e registra a entrega no painel de controle. Você pode acionar snapshots sob demanda, em um agendamento ou via API de Conjuntos de Dados do Marketplace.
3. Carregar e Consultar
Com os arquivos no stage, um único comando COPY INTO os carrega em sua tabela. A partir daí, você consulta usando SQL padrão, sem sintaxe especial e sem novas ferramentas.
Configurando o Snowflake para Receber a Bright Data
Vamos começar a construir o pipeline preparando o lado do Snowflake. Todos os comandos desta seção são executados dentro da planilha SQL do Snowsight ou via SnowSQL. Execute este primeiro para garantir que você tenha os privilégios necessários para criar bancos de dados, roles e usuários:
USE ROLE ACCOUNTADMIN;Pré-requisitos
Para acompanhar esta seção, você deve ter:
- Uma conta Snowflake com privilégios
ACCOUNTADMINouSYSADMIN. - Familiaridade básica com a interface do Snowflake (Snowsight).
Passo #1: Criar um Banco de Dados e Schema
No Snowflake, um banco de dados é o contêiner de nível superior para todos os seus objetos de dados. Um schema fica dentro de um banco de dados e agrupa tabelas relacionadas, stages e outros objetos. Criar um banco de dados e schema dedicados para a Bright Data mantém seus objetos separados dos seus dados existentes e facilita o gerenciamento de permissões.
CREATE DATABASE IF NOT EXISTS bright_data_db;
CREATE SCHEMA IF NOT EXISTS bright_data_db.web_data;Você pode usar um banco de dados existente, se preferir. Substitua seu nome onde bright_data_db aparece nos comandos a seguir.
Passo #2: Criar um Warehouse Dedicado
No Snowflake, um warehouse é o cluster de computação que executa instruções SQL, incluindo COPY INTO. Ele é separado do armazenamento, o que significa que você paga apenas pela computação enquanto está ativa. Um warehouse dedicado para ingestão da Bright Data mantém esses custos de computação visíveis e evita que as cargas de trabalho de ingestão concorram com suas consultas analíticas por recursos.
CREATE WAREHOUSE IF NOT EXISTS bright_data_wh
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;AUTO_SUSPEND = 60 desliga o warehouse após 60 segundos de inatividade para que não fique ocioso entre as entregas. AUTO_RESUME = TRUE o reativa automaticamente quando o próximo COPY INTO for executado. XSmall lida confortavelmente com a maioria das entregas da Bright Data. Redimensione se os volumes crescerem.
Passo #3: Criar um Stage Interno Nomeado
No Snowflake, um stage é um local nomeado onde os arquivos ficam antes de serem carregados em uma tabela. Um stage interno nomeado fica dentro do próprio Snowflake. Nenhum bucket S3 ou armazenamento em nuvem externo é necessário.
Este stage é a ponte entre a Bright Data e sua tabela. Em vez de carregar dados diretamente em uma tabela linha por linha, a Bright Data deposita arquivos estruturados (Parquet ou JSON) no stage primeiro. O Snowflake então lê esses arquivos em massa via COPY INTO, o que é significativamente mais rápido e econômico do que inserções linha a linha. Também oferece um ponto de verificação: você pode inspecionar os arquivos no stage, verificar se estão corretos e escolher quando acionar o carregamento.
CREATE STAGE IF NOT EXISTS bright_data_db.web_data.bright_data_stage
COMMENT = 'Landing zone for Bright Data dataset deliveries';Passo #4: Criar uma Role e Conceder as Permissões Corretas
No Snowflake, uma role é uma coleção de privilégios que pode ser atribuída a usuários. Em vez de conceder permissões diretamente a um usuário, você as concede a uma role e atribui essa role ao usuário. Isso facilita a revogação ou modificação do acesso posteriormente sem mexer na conta do usuário.
Esta role concede à Bright Data exatamente o acesso de que ela precisa e nada mais.
CREATE ROLE IF NOT EXISTS bright_data_loader;
-- Allow the role to use the database and schema
GRANT USAGE ON DATABASE bright_data_db TO ROLE bright_data_loader;
GRANT USAGE ON SCHEMA bright_data_db.web_data TO ROLE bright_data_loader;
-- Allow the role to use and operate the warehouse
GRANT USAGE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
GRANT OPERATE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
-- Allow the role to write files into the stage
-- READ must be granted alongside WRITE; Snowflake requires it for COPY INTO ... FROM @stage
GRANT READ ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;
GRANT WRITE ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;Aqui está o que cada concessão faz e por que é necessária:
- USAGE no banco de dados e schema: Permite que a role veja e navegue até os objetos dentro deles. Sem isso, o Snowflake retornará um erro de “objeto não existe” mesmo que a role tenha privilégios no stage diretamente.
- USAGE no warehouse: Permite que a role execute instruções SQL no warehouse. É isso que permite que o
COPY INTOseja executado. - OPERATE no warehouse: Permite que a role retome o warehouse se ele tiver sido suspenso. Sem isso, um warehouse suspenso automaticamente não será reativado quando a Bright Data acionar um carregamento.
- READ no stage: Necessário para que o
COPY INTOleia os arquivos do stage e os carregue na tabela. - WRITE no stage: Necessário para que a Bright Data deposite arquivos no stage.
Passo #5: Criar o Usuário de Serviço da Bright Data
Um usuário de serviço é uma conta Snowflake criada para um sistema ou aplicação, e não para uma pessoa. Usar um usuário de serviço dedicado significa que o acesso da Bright Data é isolado de quaisquer contas de usuários humanos, e você pode rotacionar ou revogar suas credenciais sem afetar ninguém.
CREATE USER IF NOT EXISTS brightdata_svc
PASSWORD = 'YourStrongPasswordHere'
LOGIN_NAME = 'brightdata_svc'
DEFAULT_ROLE = bright_data_loader
DEFAULT_WAREHOUSE = bright_data_wh
DEFAULT_NAMESPACE = bright_data_db.web_data
MUST_CHANGE_PASSWORD = FALSE
DISABLED = FALSE
COMMENT = 'Service user for Bright Data dataset delivery';
GRANT ROLE bright_data_loader TO USER brightdata_svc;MUST_CHANGE_PASSWORD = FALSE impede que o Snowflake solicite a redefinição de senha no primeiro login, o que quebraria uma conexão automatizada. DEFAULT_ROLE, DEFAULT_WAREHOUSE e DEFAULT_NAMESPACE garantem que o usuário de serviço sempre se conecte com o contexto correto, independentemente de como a sessão for iniciada. A linha final atribui a role bright_data_loader a este usuário, concedendo exatamente os privilégios definidos no Passo #4.
Armazene o nome de usuário e a senha com segurança. Você os inserirá no painel de controle da Bright Data na próxima seção.
Passo #6: Adicionar IPs da Bright Data à Lista de Permissões (se você usar uma Política de Rede)
Se sua conta Snowflake aplicar uma Política de Rede, os servidores de entrega da Bright Data precisam ser adicionados à lista de permissões. Os IPs abaixo estavam atualizados no momento da redação. Verifique os intervalos mais recentes com o suporte da Bright Data ou sua documentação antes de aplicar, pois IPs estáticos podem mudar:
ALTER NETWORK POLICY your_policy_name
SET ALLOWED_IP_LIST = (
-- paste your existing allowed IPs here,
'35.169.71.210',
'34.233.211.38',
'44.194.183.74',
'54.243.177.151'
);Se sua conta não tiver uma Política de Rede ativa, ignore este passo.
Passo #7: Criar a Tabela de Destino
Este tutorial usa dados de livros do Goodreads como exemplo. O schema abaixo mapeia diretamente para os nomes de campos que o conjunto de dados Goodreads Books da Bright Data entrega em JSON:
CREATE TABLE IF NOT EXISTS bright_data_db.web_data.goodreads_books (
id VARCHAR, -- Goodreads book ID
name VARCHAR, -- book title
url VARCHAR,
author VARIANT, -- array: [{name, num_books, num_followers}]
star_rating FLOAT, -- average rating 1-5
num_ratings INT, -- total number of ratings
num_reviews VARCHAR, -- total reviews (may be formatted, e.g. "1,234")
summary VARCHAR, -- book description/blurb
genres VARIANT, -- array of genre strings
first_published VARCHAR, -- publication date as text
about_author VARIANT, -- object: {name, num_books, num_followers}
community_reviews VARIANT -- object: {5_stars, 4_stars, ...} with counts and percentages
);VARIANT é o tipo semiestruturado do Snowflake. Ele armazena arrays e objetos aninhados como estão e permite consultá-los usando notação de ponto e sintaxe de colchetes (author[0]:name, community_reviews['5_stars']:reviews_num). Isso evita o achatamento de campos aninhados complexos no momento do carregamento. Você pode fazer isso posteriormente com uma view ou um LATERAL FLATTEN quando souber quais subcampos precisa.
Algumas decisões de campo que vale entender:
authorcomo VARIANT: Cada livro pode ter múltiplos autores. O campo chega como um array de objetos. Armazená-lo como VARIANT preserva todos os dados do autor sem exigir uma tabela de junção separada.genrescomo VARIANT: Gênero também é um array. Um livro pode pertencer a vários gêneros. Achate-o comLATERAL FLATTEN(INPUT => genres)quando precisar consultar por gênero.num_reviewscomo VARCHAR: O dicionário de dados da Bright Data marca este campo como Texto em vez de Número, o que significa que pode chegar formatado (por exemplo,"1.234"em vez de1234). Converta-o no momento da consulta comTO_NUMBER(REPLACE(num_reviews, ',', ''))se precisar agregá-lo.community_reviewscomo VARIANT: Contém um detalhamento das avaliações por nível de estrelas, cada uma com uma contagem e uma porcentagem. Armazene como VARIANT e consulte níveis de estrelas específicos conforme necessário.
Nota: Se você escolher um conjunto de dados diferente do marketplace (empresas do LinkedIn, ofertas de emprego, produtos Amazon, etc.), ajuste o schema para corresponder à sua lista de campos. A Bright Data fornece uma referência completa de campos para cada conjunto de dados em sua página no painel de controle.
Excelente! Seu ambiente Snowflake agora está pronto para receber dados da Bright Data.
Configurando a Bright Data para Entregar ao Snowflake
Com o lado do Snowflake configurado, vamos configurar a Bright Data para enviar dados para ele.
Pré-requisitos
Para acompanhar esta seção, você deve ter:
- Uma conta Bright Data com uma assinatura ativa ou trial.
- Os detalhes de conexão do Snowflake da seção anterior: identificador de conta, nome de usuário, senha, banco de dados, schema, stage e nomes de warehouse.
Passo #1: Escolher um Conjunto de Dados
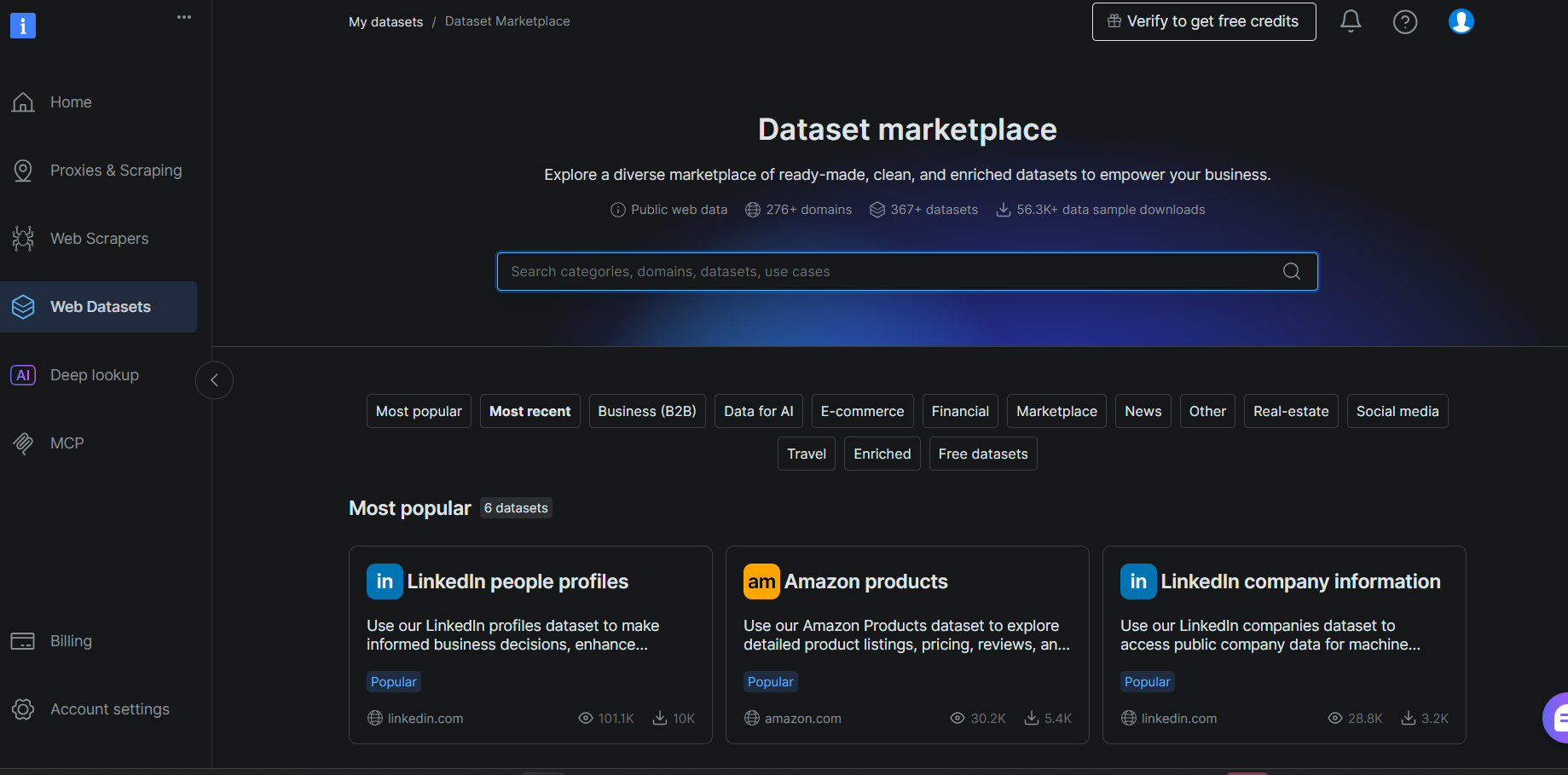
Faça login na sua conta Bright Data e navegue até Web Datasets > Dataset Marketplace. Pesquise por Goodreads e selecione o conjunto de dados Goodreads Books nos resultados.
Na página do conjunto de dados, revise a lista de campos no painel esquerdo. Observe como cada campo mapeia diretamente para uma coluna na tabela que você criou no Passo #7. Isso confirma que seu schema está correto antes de uma única linha chegar.
Passo #2: Configurar o Snowflake como Destino de Entrega
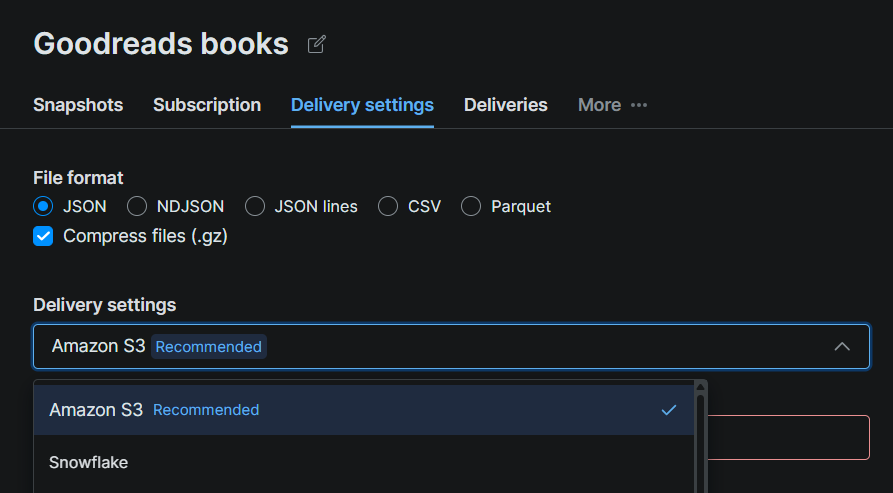
Clique na aba Delivery Settings na página do conjunto de dados e selecione Snowflake como destino. Preencha o formulário de conexão com os detalhes da sua configuração do Snowflake:
| Campo | Valor |
|---|---|
| Identificador de conta | URL da sua conta Snowflake (ex.: xy12345.us-east-1) |
| Banco de dados | bright_data_db |
| Schema | web_data |
| Stage | bright_data_stage |
| Warehouse | bright_data_wh |
| Role | bright_data_loader |
| Usuário | brightdata_svc |
| Senha | A senha que você definiu no Passo #5 |
Os três campos abaixo do formulário de conexão são opcionais e podem ser deixados com seus valores padrão para este tutorial:
- Nome do arquivo do conjunto de dados: Um prefixo personalizado para os arquivos que a Bright Data coloca em stage. Deixe em branco para usar a nomenclatura padrão.
- Tamanho do lote (número de registros): Quantos registros a Bright Data compacta em cada arquivo em stage. O padrão é adequado para a maioria das cargas de trabalho.
- Agrupar lotes em um arquivo (.tar): Combina todos os lotes em um único arquivo antes do stage. Deixe desmarcado a menos que seu pipeline exija especificamente um único arquivo por entrega.
Clique em Test Snowflake. Uma confirmação verde significa que a Bright Data pode se autenticar e gravar no seu stage. Depois que o teste passar, clique em Save.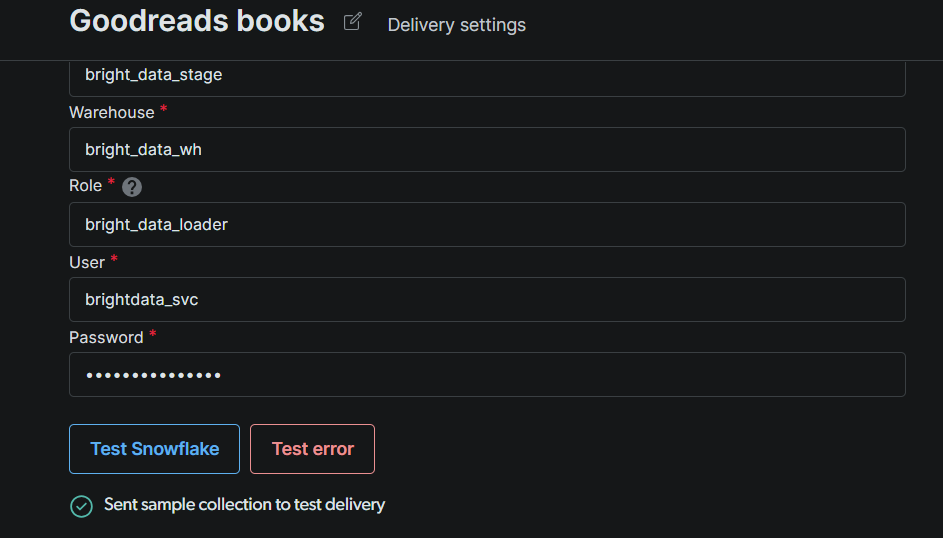
Nota: Se o teste falhar, verifique três coisas em ordem: (1) o formato do identificador de conta (o Snowflake espera orgname-accountname ou o formato legado accountid.region.cloud); (2) se o usuário de serviço tem todas as concessões do Passo #4, incluindo a atribuição de Role; (3) se os IPs da Bright Data estão na lista de permissões caso sua conta tenha uma Política de Rede ativa.
Passo #3: Solicitar um Snapshot
Na página do conjunto de dados, clique na aba Deliveries. Em seguida, clique em Add delivery + no canto superior direito. Isso abre um painel de configuração de entrega onde você seleciona seu destino (Snowflake), escolhe um snapshot ou intervalo de datas para entregar e confirma.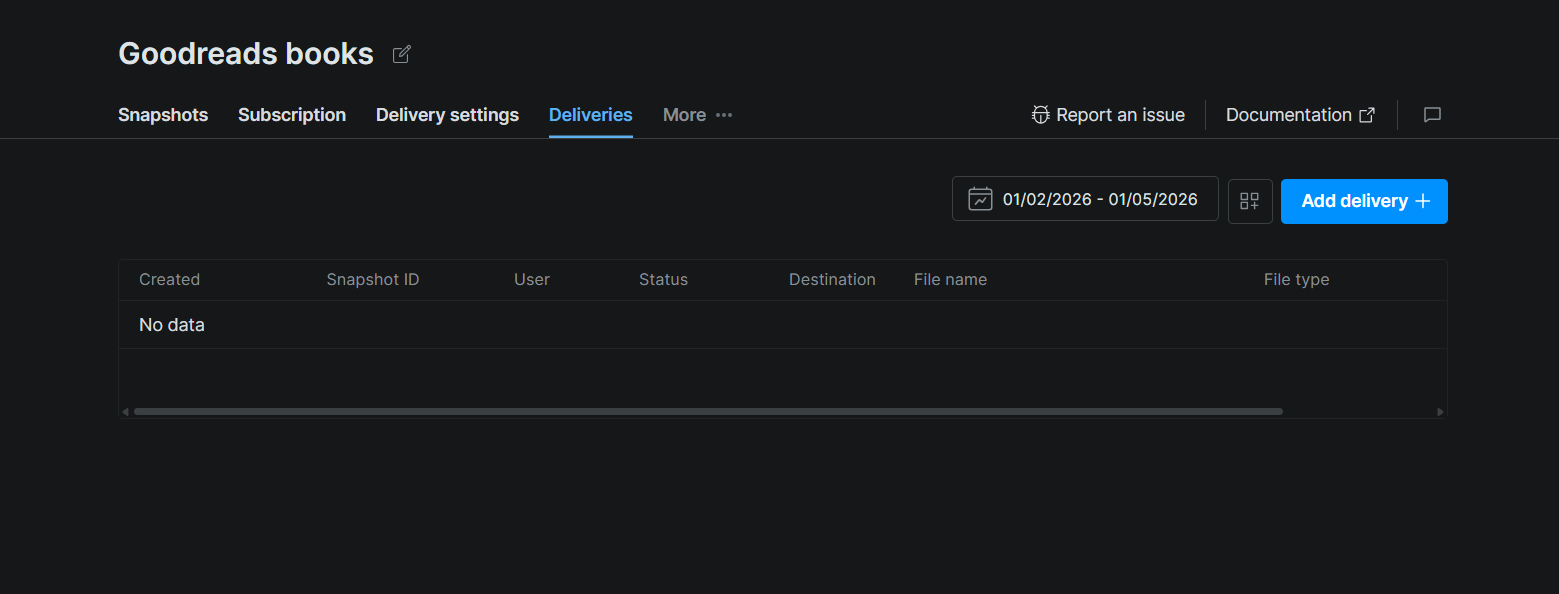
Após o envio, a entrega aparece na tabela com colunas para ID do Snapshot, Status, Destino, Nome do arquivo e Tipo de arquivo. O status passará de pendente para concluído quando a Bright Data terminar de enviar os arquivos para seu stage.
Para acionar entregas programaticamente, a API de Conjuntos de Dados do Marketplace usa um fluxo de duas etapas: primeiro chame a API de Filtro para criar um snapshot filtrado, depois chame Deliver Snapshot para enviá-lo ao seu stage do Snowflake.
Etapa 1: Criar um snapshot filtrado:
curl --request POST \
--url "https://api.brightdata.com/datasets/filter" \
--header "Authorization: Bearer YOUR_API_TOKEN" \
--header "Content-Type: application/json" \
--data '{
"dataset_id": "YOUR_DATASET_ID",
"filter": {
"operator": "and",
"filters": [
{"name": "star_rating", "operator": ">", "value": "4"},
{"name": "num_ratings", "operator": ">", "value": "1000"}
]
}
}'A resposta contém um snapshot_id. Passe-o para a próxima chamada.
Etapa 2: Entregar o snapshot ao seu stage do Snowflake:
curl --request POST \
--url "https://api.brightdata.com/datasets/snapshots/YOUR_SNAPSHOT_ID/deliver" \
--header "Authorization: Bearer YOUR_API_TOKEN" \
--header "Content-Type: application/json" \
--data '{
"destination": "snowflake"
}'A Bright Data usará o formato configurado para seu conjunto de dados por padrão. Se quiser especificá-lo explicitamente, adicione "format": "parquet" ou "format": "ndjson" ao corpo da requisição. Qualquer formato que chegar no stage é o que você passa para FILE_FORMAT no COPY INTO.
Consulte GET /datasets/snapshots/YOUR_SNAPSHOT_ID para verificar o status da entrega, ou monitore-o na aba Deliveries do painel de controle. Quando a coluna Status mostrar concluído, seus arquivos estão no stage e prontos para carregar. Ótimo!
Quando a entrega for concluída, você também receberá um e-mail com um link para a página do snapshot no painel de controle. Lá, você pode visualizar os primeiros 30 registros, verificar a contagem total de registros e baixar um relatório de resumo de custos. A $2,50 por 1.000 registros, o relatório mostra exatamente quantos registros chegaram e quanto custaram. Ótimo!
Carregando os Dados no Snowflake
O trabalho da Bright Data termina quando os arquivos chegam ao seu stage interno. Carregá-los na tabela é sua responsabilidade, e leva um único comando SQL. Essa separação vale entender: significa que você controla quando o carregamento é executado, qual tratamento de erros se aplica e com que frequência você atualiza a tabela.
Pré-requisitos
Para acompanhar esta seção, você deve ter:
- Concluído as seções de configuração do Snowflake e configuração da Bright Data acima.
- Confirmado que uma entrega de snapshot foi concluída (via e-mail ou pela página do snapshot no painel de controle da Bright Data).
Passo #1: Confirmar que os Arquivos Chegaram no Stage
Execute isto antes de qualquer outra coisa:
LIST @bright_data_db.web_data.bright_data_stage;Você deve ver um ou mais arquivos listados com seus tamanhos e timestamps. Se o stage estiver vazio, o snapshot ainda não terminou de ser entregue. Verifique seu status na página do snapshot no painel de controle da Bright Data.
Observe a extensão do arquivo nos resultados. O formato que a Bright Data usa para entrega determina o FILE_FORMAT que você passa para COPY INTO no próximo passo. Para snapshots acionados pela interface, a Bright Data normalmente entrega NDJSON a menos que você tenha especificado o contrário ao configurar a entrega. Para snapshots acionados via API usando o endpoint deliver-snapshot, o formato é o que você passou no corpo da requisição. Se você vir arquivos .parquet, use TYPE = 'PARQUET'. Se você vir arquivos .json ou .ndjson, use TYPE = 'JSON'.
Passo #2: Carregar os Arquivos na Tabela
Para arquivos Parquet:
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';Para arquivos JSON ou NDJSON:
COPY INTO bright_data_db.web_data.goodreads_books (
id, name, url, author, star_rating, num_ratings,
num_reviews, summary, genres, first_published,
about_author, community_reviews
)
FROM (
SELECT
$1:id::VARCHAR,
$1:name::VARCHAR,
$1:url::VARCHAR,
$1:author::VARIANT,
$1:star_rating::FLOAT,
$1:num_ratings::INT,
$1:num_reviews::VARCHAR,
$1:summary::VARCHAR,
$1:genres::VARIANT,
$1:first_published::VARCHAR,
$1:about_author::VARIANT,
$1:community_reviews::VARIANT
FROM @bright_data_db.web_data.bright_data_stage
)
FILE_FORMAT = (TYPE = 'JSON' STRIP_OUTER_ARRAY = TRUE)
ON_ERROR = 'CONTINUE';MATCH_BY_COLUMN_NAME (somente Parquet) mapeia nomes de colunas automaticamente para que a ordem não importe. ON_ERROR = CONTINUE ignora linhas malformadas em vez de abortar todo o carregamento.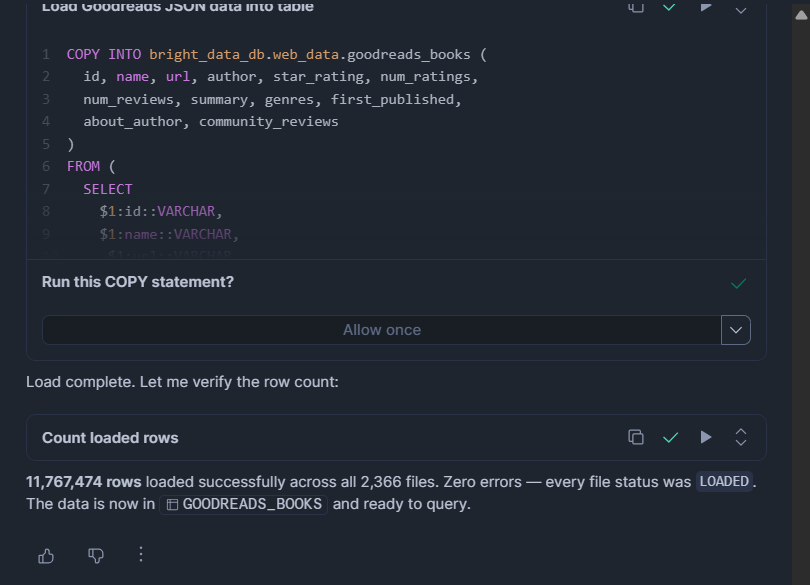
Passo #3: Verificar o Carregamento
-- Count the loaded rows
SELECT COUNT(*) FROM bright_data_db.web_data.goodreads_books;
-- Check for skipped rows or errors in the last hour
SELECT *
FROM TABLE(BRIGHT_DATA_DB.INFORMATION_SCHEMA.COPY_HISTORY(
TABLE_NAME => 'BRIGHT_DATA_DB.WEB_DATA.GOODREADS_BOOKS',
START_TIME => DATEADD(HOURS, -1, CURRENT_TIMESTAMP())
));COPY_HISTORY mostra linhas carregadas, linhas ignoradas, nomes de arquivos processados e a mensagem de erro exata para qualquer linha que falhou. Revise após cada carregamento, especialmente na primeira vez.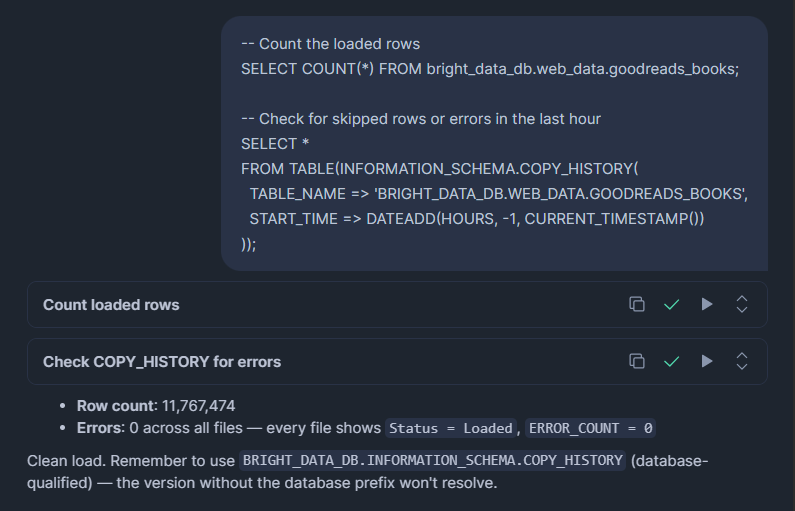
Consultando os Dados
Com os dados de livros do Goodreads no Snowflake, o valor está em entender tendências de leitura, desempenho de autores e popularidade de gêneros em escala, em milhões de títulos. As consultas abaixo refletem diretamente esses casos de uso.
Inspecionar os dados brutos
Antes de escrever consultas analíticas, verifique se os dados estão como esperado:
SELECT id, name, url, star_rating, num_ratings, first_published
FROM bright_data_db.web_data.goodreads_books
LIMIT 10;RESULTADO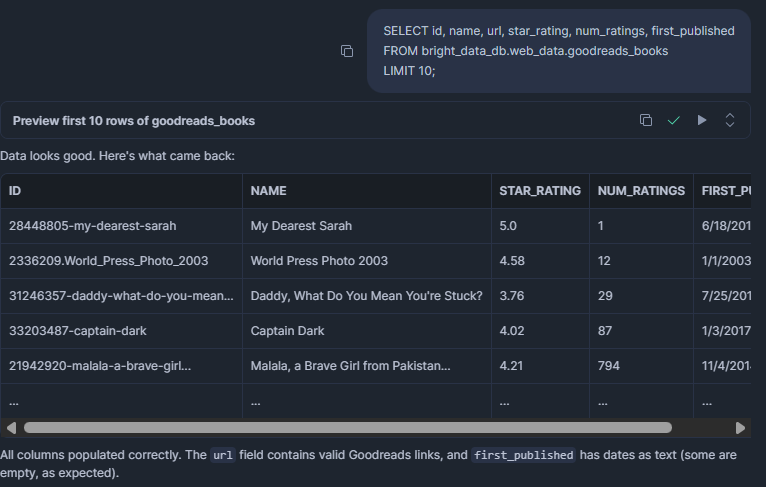
Quais livros têm a maior validação dos leitores?
Um star_rating alto por si só não é suficiente. Um livro com 4,8 estrelas de 12 pessoas diz muito pouco. Esta consulta exibe livros que são bem avaliados e amplamente lidos, combinação que indica que o livro tem genuína durabilidade.
SELECT
name,
author[0]:name::VARCHAR AS primary_author,
star_rating,
num_ratings,
first_published
FROM bright_data_db.web_data.goodreads_books
WHERE num_ratings > 10000
AND star_rating >= 4.5
ORDER BY num_ratings DESC
LIMIT 20;Resultado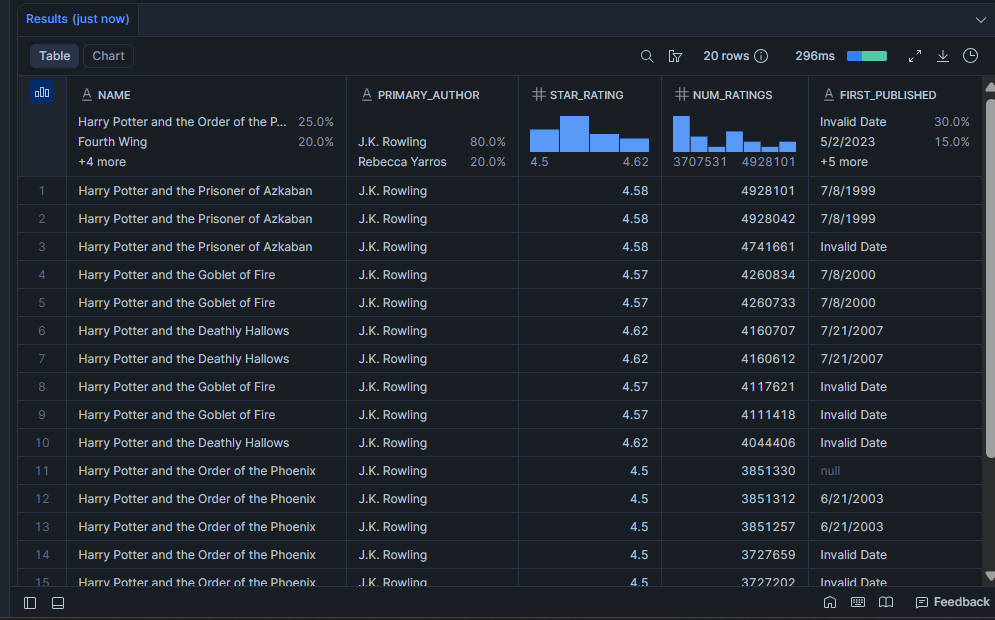
Quais gêneros têm mais títulos e a maior avaliação média?
Útil para entender onde a demanda dos leitores está concentrada. Um gênero com grande número de títulos, mas avaliação média baixa, pode estar saturado de entradas de baixa qualidade, o que é uma oportunidade para editoras ou mecanismos de recomendação.
SELECT
g.value::VARCHAR AS genre,
COUNT(*) AS book_count,
ROUND(AVG(star_rating), 2) AS avg_rating,
SUM(num_ratings) AS total_ratings
FROM bright_data_db.web_data.goodreads_books,
LATERAL FLATTEN(INPUT => genres) g
WHERE g.value IS NOT NULL
GROUP BY genre
ORDER BY total_ratings DESC
LIMIT 15;Resultado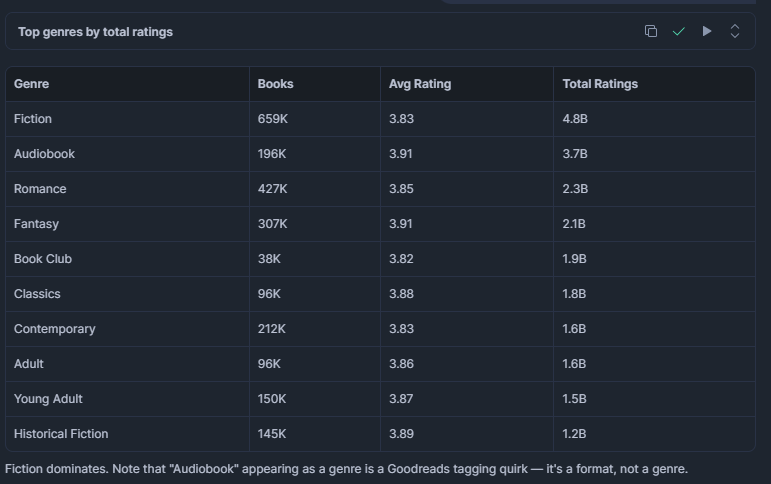
Quais são os autores com mais seguidores no conjunto de dados?
A contagem de seguidores de um autor é um indicador de audiência na plataforma. Combiná-la com a avaliação média dos livros mostra se os autores mais seguidos também são os mais respeitados, ou se contagem de seguidores e qualidade divergem.
about_author é um objeto simples em cada registro de livro, tornando-o direto para consultar sem indexação de array. Note que isso reflete o autor conforme descrito na página daquele livro específico, o que pode diferir ligeiramente de author (o array de autores creditados).
SELECT
about_author:name::VARCHAR AS author_name,
about_author:num_books::INT AS books_published,
about_author:num_followers::VARCHAR AS followers,
ROUND(AVG(star_rating), 2) AS avg_book_rating,
SUM(num_ratings) AS total_ratings_received
FROM bright_data_db.web_data.goodreads_books
WHERE about_author:name IS NOT NULL
GROUP BY author_name, books_published, followers
ORDER BY followers DESC NULLS LAST
LIMIT 20;Resultado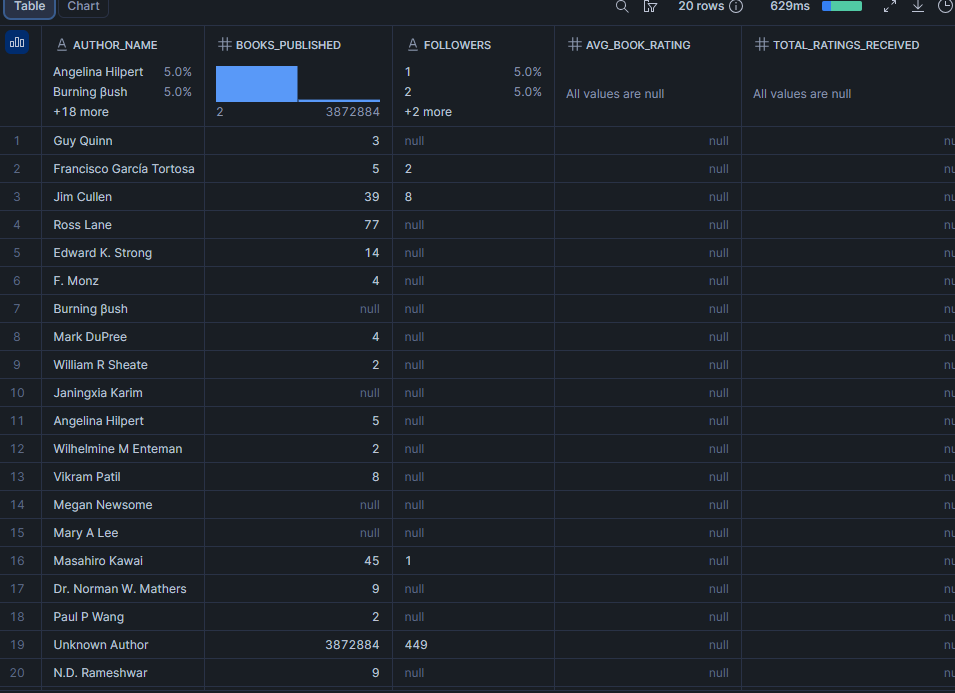
Nota: followers é ordenado como texto porque o campo de origem é VARCHAR (pode conter valores formatados como "12.3k"). Se seu conjunto de dados entregar um inteiro limpo, converta-o com TO_NUMBER(followers) e ordene numericamente.
Quão polarizador é um livro? Extraia o detalhamento de estrelas das avaliações da comunidade
Um livro com avaliação média alta, mas grande parcela de avaliações de 1 estrela, pode ser controverso em vez de universalmente amado. Esta consulta extrai a distribuição de avaliações para qualquer livro específico.
SELECT
name,
star_rating,
num_reviews,
community_reviews['5_stars']:reviews_num::INT AS five_star_count,
community_reviews['4_stars']:reviews_num::INT AS four_star_count,
community_reviews['3_stars']:reviews_num::INT AS three_star_count,
community_reviews['2_stars']:reviews_num::INT AS two_star_count,
community_reviews['1_stars']:reviews_num::INT AS one_star_count,
community_reviews['1_stars']:reviews_percentage::FLOAT AS one_star_pct
FROM bright_data_db.web_data.goodreads_books
WHERE id = 'YOUR_BOOK_ID'; -- substitute the Goodreads book IDnum_reviews fornece a contagem total de resenhas escritas junto com o detalhamento por estrelas, útil para distinguir livros que atraem opiniões escritas extensas daqueles que acumulam avaliações silenciosas por estrelas.
Et voilà! Agora você tem um pipeline funcional que extrai dados web estruturados da Bright Data e os torna consultáveis no Snowflake.
Automatizando Atualizações
Para uso em produção, você vai querer que novos snapshots sejam carregados automaticamente em vez de executar COPY INTO manualmente a cada vez. Comece com a Opção A. Só avance para a Opção B se precisar que a tabela seja atualizada em segundos após a conclusão da entrega.
Opção A: Snowflake Task para ingestão orientada por agendamento
Uma Snowflake Task executa o COPY INTO em um agendamento cron e não requer infraestrutura adicional. Defina um agendamento de entrega correspondente na Bright Data para que os arquivos estejam prontos no stage quando a task for executada.
CREATE TASK IF NOT EXISTS bright_data_db.web_data.load_goodreads_task
WAREHOUSE = bright_data_wh
SCHEDULE = 'USING CRON 0 6 * * * UTC'
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';
ALTER TASK bright_data_db.web_data.load_goodreads_task RESUME;Dica profissional: Na sua primeira execução automatizada, verifique o COPY_HISTORY após a task ser executada para confirmar que o horário do agendamento está alinhado com quando a Bright Data termina de entregar. Uma task que é executada antes da conclusão da entrega encontrará um stage vazio e carregará zero linhas.
Opção B: API REST do Snowpipe para ingestão orientada por eventos de baixa latência
O Snowpipe carrega arquivos do stage em segundos após chegarem, acionado programaticamente via seu endpoint REST insertFiles. Use isso apenas se seu caso de uso exigir atualização quase em tempo real. Ele adiciona complexidade de configuração significativa em comparação com a Opção A.
A configuração tem duas partes. Primeiro, crie o pipe:
CREATE PIPE IF NOT EXISTS bright_data_db.web_data.goodreads_pipe
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;Observe a ausência de AUTO_INGEST = TRUE. Para stages internos nomeados, a ingestão automática via mensagens em nuvem só está disponível para contas Snowflake hospedadas na AWS e atualmente é um recurso em versão prévia. A abordagem via API REST funciona em todas as plataformas de nuvem.
Segundo, conecte seu handler de webhook para listar os arquivos em stage e enviá-los ao Snowpipe quando um snapshot estiver pronto:
import snowflake.connector
from snowflake.ingest import SimpleIngestManager, StagedFile
SNOWFLAKE_ACCOUNT = "your-account-identifier"
SNOWFLAKE_USER = "brightdata_svc"
SNOWFLAKE_PASSWORD = "YourStrongPasswordHere"
PIPE_NAME = "bright_data_db.web_data.goodreads_pipe"
STAGE_NAME = "bright_data_db.web_data.bright_data_stage"
def handle_brightdata_webhook(snapshot_id: str):
# Step 1: list files that arrived in the stage
conn = snowflake.connector.connect(
account=SNOWFLAKE_ACCOUNT,
user=SNOWFLAKE_USER,
password=SNOWFLAKE_PASSWORD,
)
cursor = conn.cursor()
cursor.execute(f"LIST @{STAGE_NAME}")
staged_files = [StagedFile(row[0], None) for row in cursor.fetchall()]
cursor.close()
conn.close()
if not staged_files:
print(f"No files found in stage for snapshot {snapshot_id}")
return
# Step 2: tell Snowpipe to load them
ingest_manager = SimpleIngestManager(
account=SNOWFLAKE_ACCOUNT,
host=f"{SNOWFLAKE_ACCOUNT}.snowflakecomputing.com",
user=SNOWFLAKE_USER,
pipe=PIPE_NAME,
private_key=open("rsa_key.p8", "rb").read(), # Snowpipe REST requires key-pair auth
)
response = ingest_manager.ingest_files(staged_files)
print(f"Snowpipe response: {response}")Nota: A API REST do Snowpipe requer autenticação por par de chaves, não autenticação por senha. Gere um par de chaves RSA, atribua a chave pública ao brightdata_svc no Snowflake (ALTER USER brightdata_svc SET RSA_PUBLIC_KEY='...') e passe o caminho do arquivo de chave privada acima. Instale o SDK com pip install snowflake-ingest.
Conclusão
Neste artigo, você aprendeu como construir um pipeline completo de ingestão de dados web da Bright Data para o Snowflake. O fluxo de trabalho:
- Prepara o Snowflake com um banco de dados, stage, role e usuário de serviço dedicados contra os quais a Bright Data se autentica diretamente.
- Configura um conjunto de dados da Bright Data com o Snowflake como destino de entrega, sem necessidade de armazenamento intermediário.
- Aciona um snapshot via aba Deliveries do painel de controle ou pela API de Conjuntos de Dados, depois monitora o status da entrega até que os arquivos cheguem no stage.
- Carrega os arquivos em stage em uma tabela Snowflake estruturada com um único comando
COPY INTOe consulta os dados com SQL padrão.
A mesma configuração funciona para qualquer conjunto de dados no marketplace da Bright Data: produtos Amazon, empresas do LinkedIn, ofertas de emprego, listagens de hotéis, registros do Crunchbase e muito mais. Cada um segue o mesmo padrão de entrega; apenas o schema da tabela muda.
Crie uma conta gratuita na Bright Data hoje e comece a trazer dados web ao vivo para o seu ambiente Snowflake!





