
Neste guia, você aprenderá:
- O que é o Puppeteer Real Browser
- Como ele funciona para evitar a detecção de bots e a resolução de CAPTCHA
- Como ele se compara ao Puppeteer básico
- Como usá-lo contra sistemas de detecção de bots do mundo real
- Suas principais alternativas
- Suas principais limitações
- Uma abordagem melhor para a automação do navegador anti-bot
Vamos começar!
O que é o Puppeteer Real Browser?
O Puppeteer Real Browser é uma biblioteca JavaScript que faz com que o navegador controlado pelo Puppeteer se comporte mais como um usuário real. Isso reduz a detecção de bots em serviços WAF como Cloudflare e similares. Ele também oferece suporte à Resolução de CAPTCHA, incluindo Cloudflare Turnstile.
A biblioteca amplia o Puppeteer com configurações personalizadas, ao mesmo tempo em que oferece suporte a Proxies e todos os outros recursos do Puppeteer básico. É de código aberto — com mais de 1 mil estrelas no GitHub, está disponível no npm como puppeteer-real-browser e oferece suporte ao Docker para implantação.
Observação: em fevereiro de 2026, o autor da biblioteca, mdervisaygan, anunciou que o projeto não receberia mais atualizações. Isso não significa que o Puppeteer Real Browser esteja necessariamente morto, pois os membros da comunidade podem continuar seu desenvolvimento por meio de um fork.
Como o Puppeteer Real Browser funciona?
Se você já trabalhou com ferramentas de automação de navegador como Puppeteer, Playwright ou Selenium, sabe que os navegadores controlados por essas ferramentas podem ser detectados por sistemas anti-bot. Isso é especialmente verdadeiro ao operar no modo headless — mesmo ao usar os melhores navegadores headless.
Os bloqueios acontecem porque as bibliotecas de automação configuram os navegadores de uma forma que os torna mais fáceis de controlar. As soluções anti-bot procuram essas configurações e “vazamentos” para determinar se as solicitações vêm de um ser humano real usando um navegador normal ou de um bot automatizado.
O Puppeteer Real Browser resolve esse problema usando o Rebrowser, uma coleção de patches para Puppeteer e Playwright projetados para impedir a detecção de automação.
O Rebrowser modifica o puppeteer-core diretamente, corrigindo o tempo de execução do navegador para remover vestígios semelhantes a bots deixados pelo Puppeteer. Essas alterações fazem com que o navegador pareça mais com uma sessão de usuário real, reduzindo as chances de ser bloqueado por sistemas antibots.
No entanto, WAFs como o Cloudflare ainda podem apresentar CAPTCHAs de um clique:
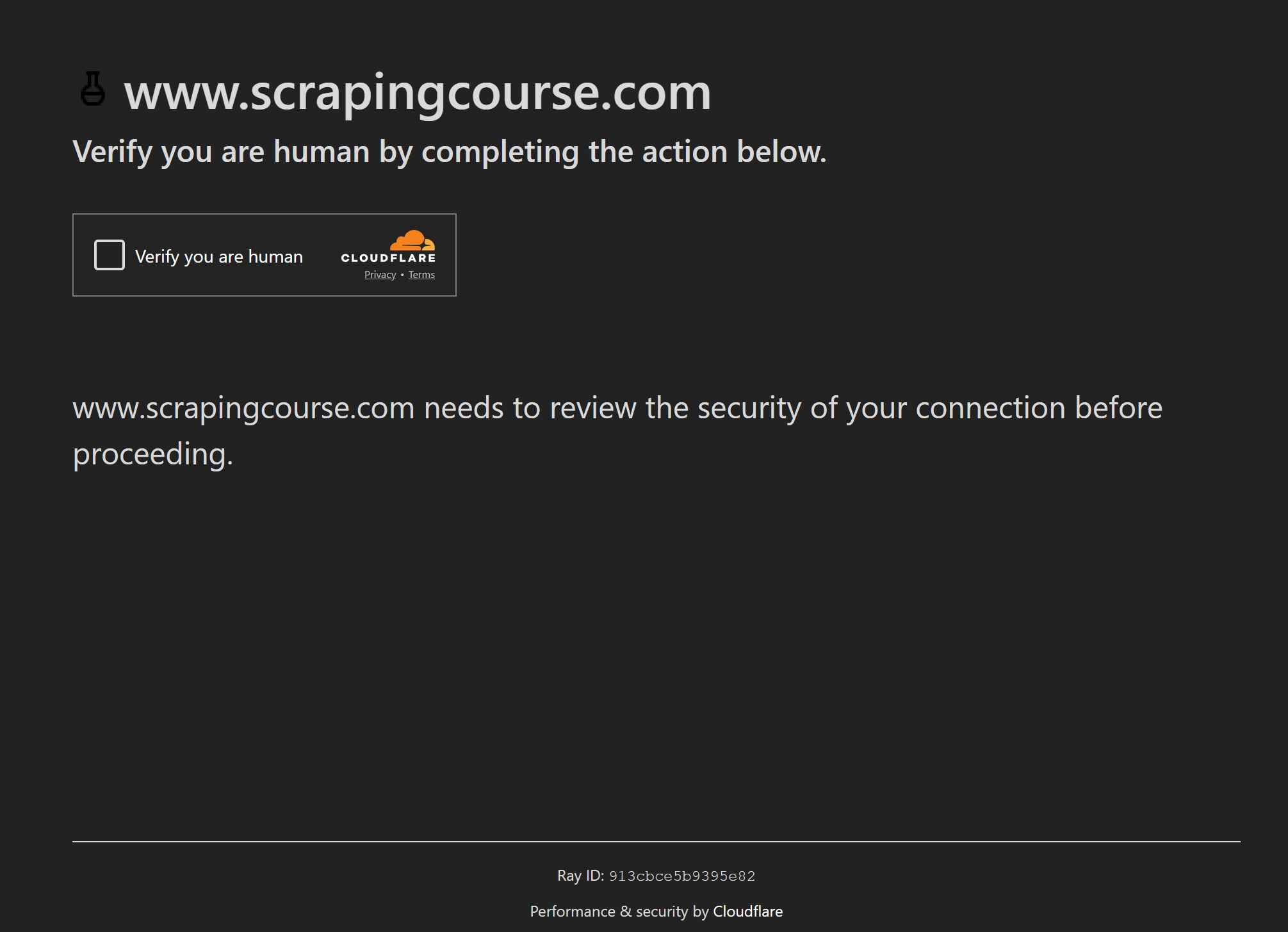
Nesse caso, o Puppeteer Real Browser conta com o ghost-cursor para interagir com CAPTCHAs como um usuário real faria. Trata-se de uma biblioteca JavaScript que gera movimentos do mouse semelhantes aos humanos no Puppeteer ou em qualquer plano 2D.
O problema é que os eventos do mouse do Puppeteer são frequentemente detectados como sintéticos devido ao comportamento não natural do cursor. O Puppeteer Real Browser corrige esse problema melhorando a forma como os valores .screenX e .screenY são tratados, tornando os movimentos do mouse mais naturais. Isso ajuda a enganar o Cloudflare Turnstile, o reCAPTCHA e outros CAPTCHAs de um clique, fazendo-os pensar que a interação é de um usuário humano real.
A biblioteca também inclui:
- Puppeteer Extra: para habilitar a extensão por meio de plug-ins
- Xvfb: para lidar com exibições de navegadores virtuais, ideal para ambientes sem monitor.
Resumindo, o Puppeteer Real Browser combina diferentes melhorias para criar uma ferramenta de automação furtiva e de alta fidelidade que imita usuários humanos, evitando a detecção.
Puppeteer Real Browser vs Puppeteer
Abaixo está uma tabela resumida comparando as duas tecnologias:
| Puppeteer | Puppeteer Real Browser | |
|---|---|---|
| Estrelas no GitHub | 1 mil estrelas | 89,7 mil estrelas |
| Biblioteca npm | puppeteer |
puppeteer-real-browser |
| downloads npm | ~3,6 milhões de downloads semanais | ~10 mil downloads semanais |
versãodo puppeteer-core |
Puppeteer-core padrão |
Rebrowser-puppeteer-core corrigido para remover vestígios de automação |
| Detecção anti-bot | Facilmente detectado por proteção avançada contra bots | Projetado para evitar sistemas de detecção de bots (Cloudflare, Akamai, etc.) |
| API | Padrão | A mesma API Puppeteer com extensões adicionais |
| Suporte a Proxy | Suporta proxies | Suporta proxies |
| Tratamento de CAPTCHA | Sem resolução de CAPTCHA integrada | Suporta resolução de CAPTCHA com um clique (por exemplo, Cloudflare Turnstile, reCAPTCHA) |
| Suporte a plug-ins | Sem suporte nativo a plugins | Integra-se com o puppeteer-extra para suporte a plugins |
| Manutenção e atualizações | Ativamente mantido pelo Google | Descontinuado pelo autor (fevereiro de 2026), mas pode continuar através da comunidade |
Como usar o Puppeteer Real Browser para contornar CATPCHAs
Para demonstrar os recursos do Puppeteer Real Browser, vamos testá-lo na página Anti-Bot Challenge do Scraping Course:
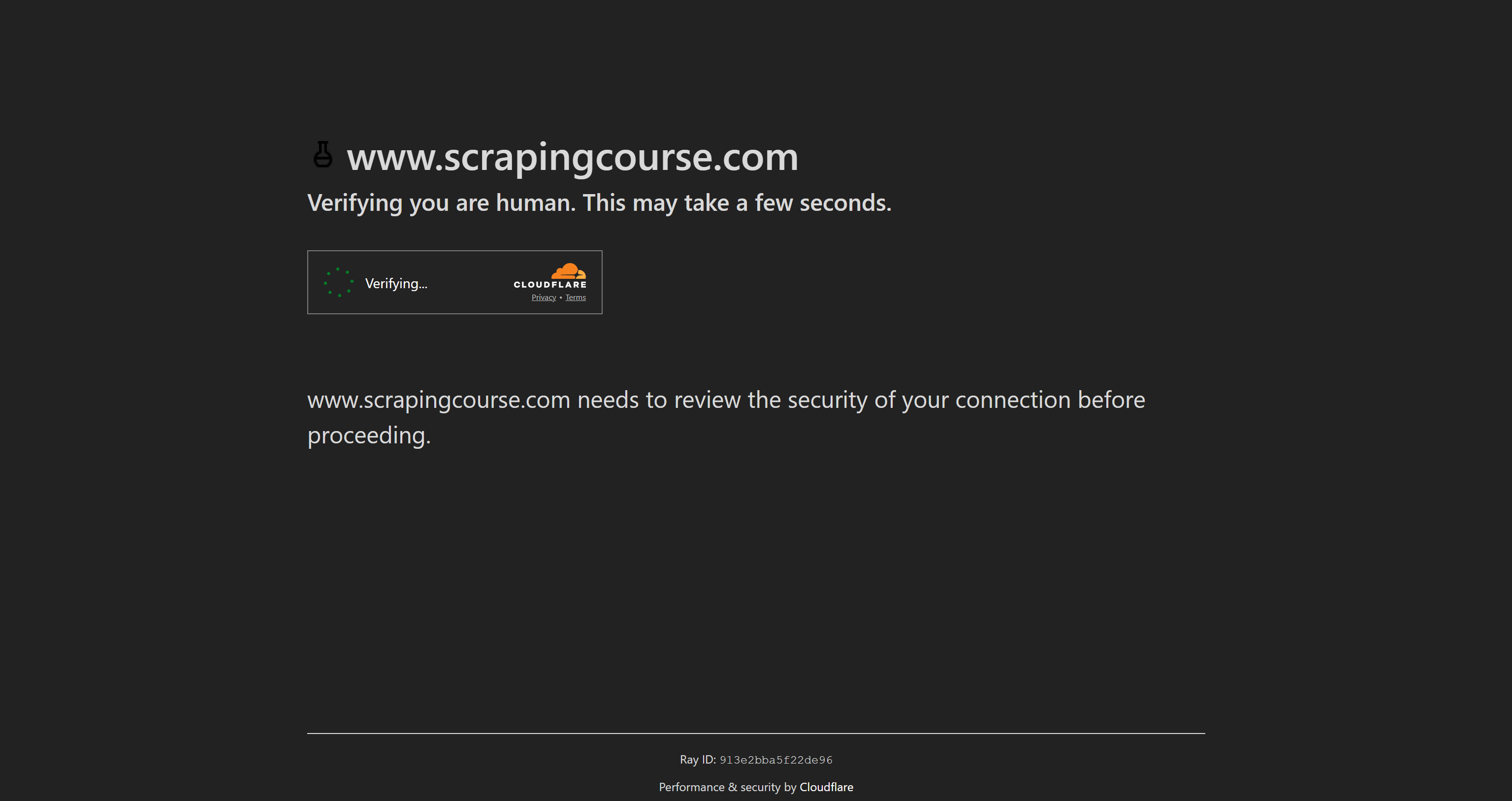
Esta página protegida pelo Cloudflare apresenta um CAPTCHA Turnstile de um clique. Nesta seção passo a passo, mostraremos como usar o Puppeteer Real Browser para realizar a resolução de CAPTCHA.
Para uma abordagem alternativa, consulte nosso guia sobre como contornar CAPTCHAs no Puppeteer. O essencial é saber que um script Puppeteer padrão que tente acessar essa página sempre encontrará o CAPTCHA Turnstile e será bloqueado.
Como você verá, o Puppeteer Real Browser é uma solução eficaz para contornar o Cloudflare e proteções anti-bot semelhantes!
Etapa 1: Instale o puppeteer-real-browser
Vamos supor que você já tenha um projeto Node.js configurado. Caso contrário, você pode criar um usando npm init.
Agora, navegue até a pasta do seu projeto e instale o puppeteer-real-browser com:
npm install puppeteer-real-browserNo Linux, você também precisa instalar o xvfb como uma dependência no nível do sistema. Para sistemas baseados em Debian, instale-o com:
sudo apt-get install xvfbÓtimo! Agora você está pronto para usar o Puppeteer Real Browser para contornar CAPTCHAs.
Etapa 2: configuração inicial
Em seu script JavaScript, importe connect do Puppeteer Real Browser:
const { connect } = require("puppeteer-real-browser");A função connect() permite que você estabeleça uma conexão com o mecanismo do navegador modificado dentro de uma função assíncrona:
(async () => {
const { browser, page } = await connect({
headless: false,
turnstile: true,
});
// lógica de scraping...
await browser.close();
})();Assim como no Puppeteer básico, você precisa chamar browser.close() para liberar recursos.
A função connect() no Puppeteer Real Browser aceita os seguintes parâmetros:
headless: O padrão éfalse. Outros valores como"new",truee"shell"podem ser usados, masfalseé o mais estável.args: Sinalizadores Chromium adicionais podem ser passados como uma matriz de strings. Veja os sinalizadores suportados.customConfig: O Puppeteer Real Browser é inicializado usandoo chrome-launcher. Quaisquer opções passadas aqui serão adicionadas como argumentos de inicialização diretos. Você pode usar isso para definiruserDataDirou um caminho personalizado do Chrome (chromePath).turnstile: Se fortrue, o Puppeteer Real Browser clica automaticamente nos CAPTCHAs do Cloudflare Turnstile.connectOption: Opções enviadas ao conectar-se ao Chromium usandopuppeteer.connect().disableXvfb: No Linux, quandoheadless: false, uma tela virtual (xvfb) é usada para executar o navegador. Defina comotruepara desativar isso e ver a janela real do navegador.ignoreAllFlags: Severdadeiro, todos os argumentos de inicialização padrão são substituídos, incluindo a página “Vamos começar” que aparece na primeira carga.plugins: Uma matriz de plug-ins Puppeteer Extra. Saiba mais na documentação oficial.
Todas as outras opções suportadas pela função acima vêm do método connect() do Puppeteer.
Como queremos ignorar o Cloudflare, a configuração principal neste exemplo é definir turnstile como true.
Etapa 3: conecte-se à página de destino
Use a função goto() da API Puppeteer para navegar até a página de destino:
await page.goto("https://www.scrapingcourse.com/antibot-challenge");Como turnstile está definido como true, o Puppeteer Real Browser aguardará automaticamente o carregamento do CAPTCHA do Cloudflare Turnstile e tentará resolvê-lo.
Etapa 4: aguarde a Resolução de CAPTCHA
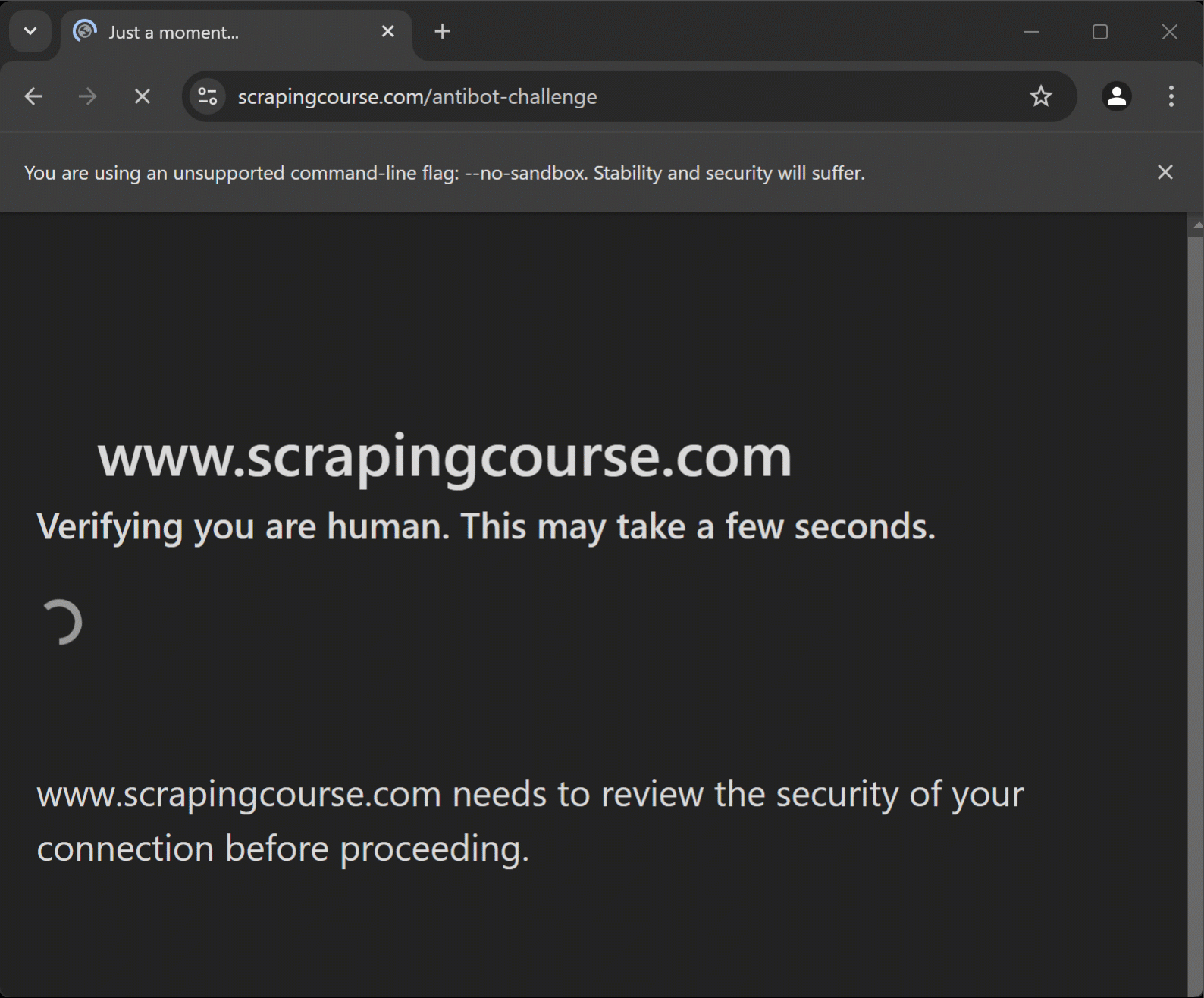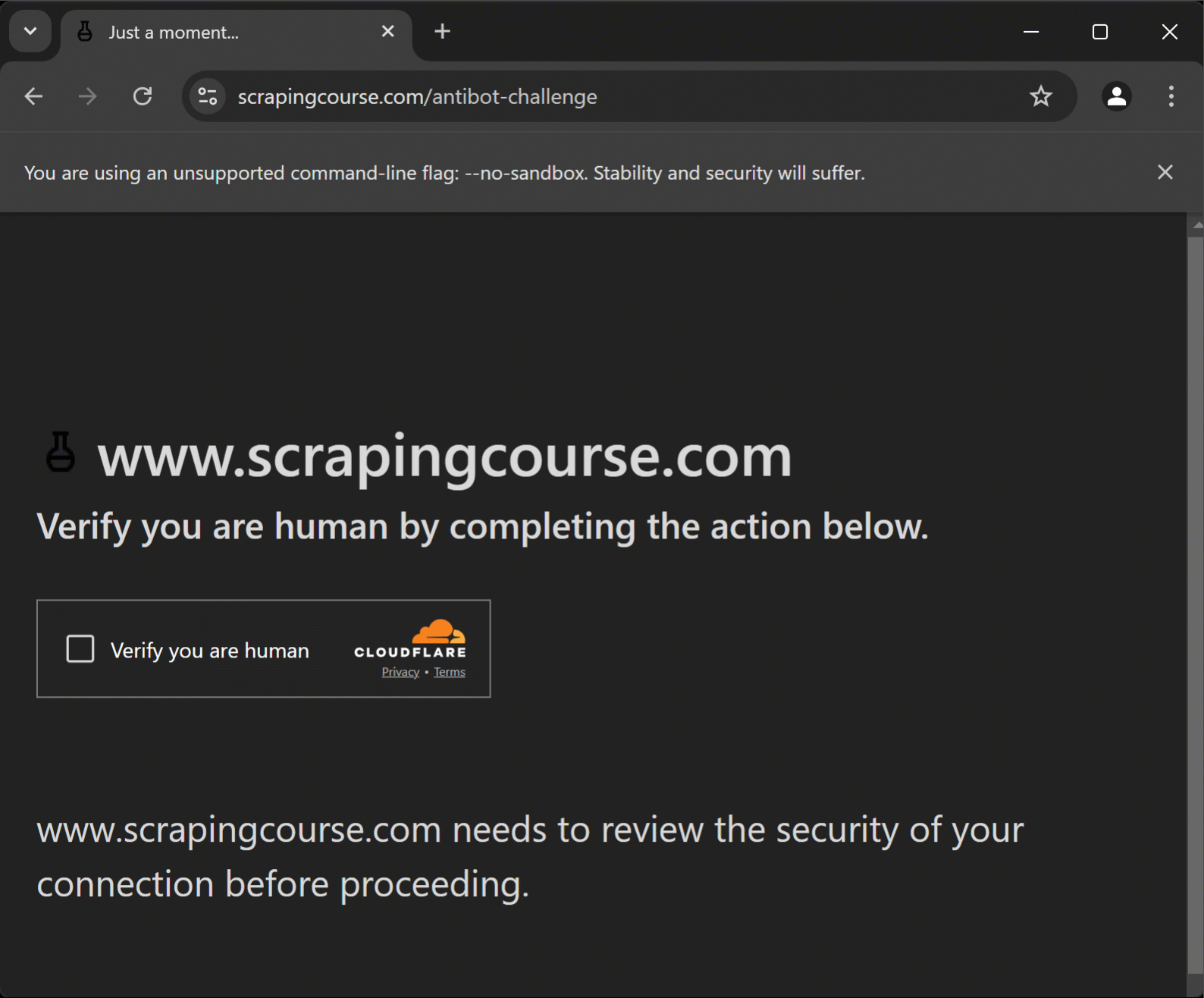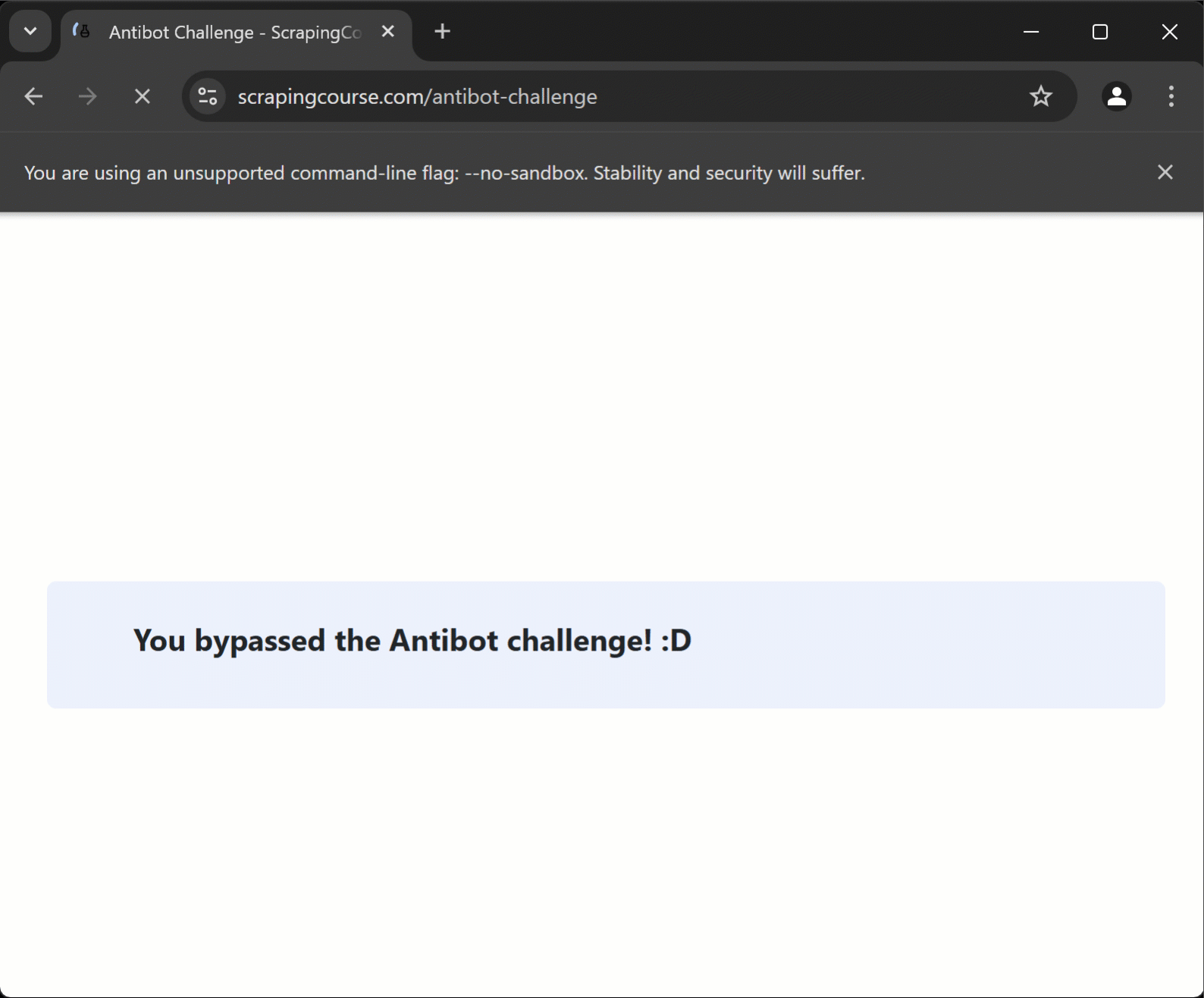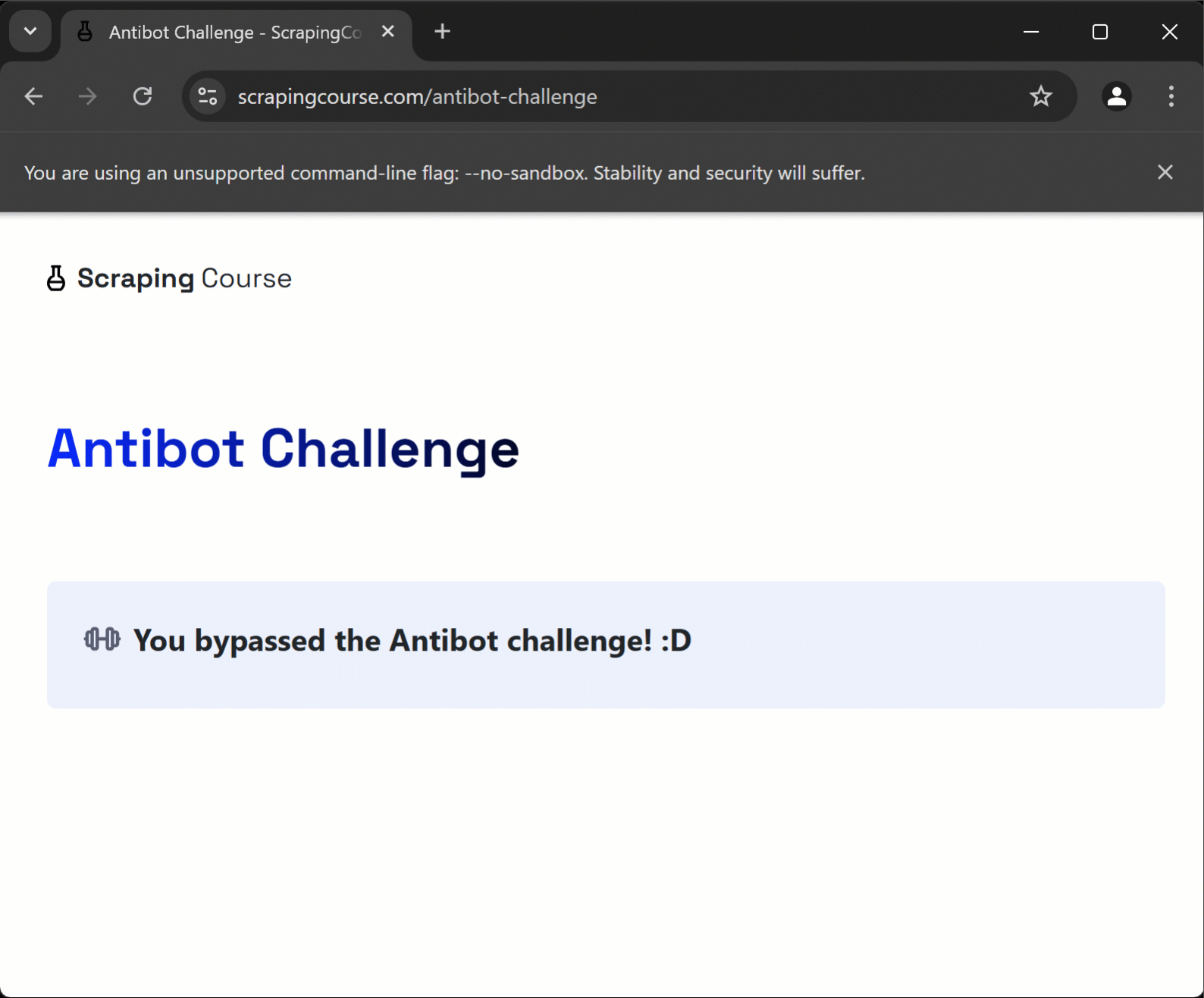
Se você abrir a página de destino no modo de navegação anônima e realizar a resolução de CAPTCHA manualmente, obterá o seguinte resultado:

Inspecione a mensagem usando o DevTools e você verá:
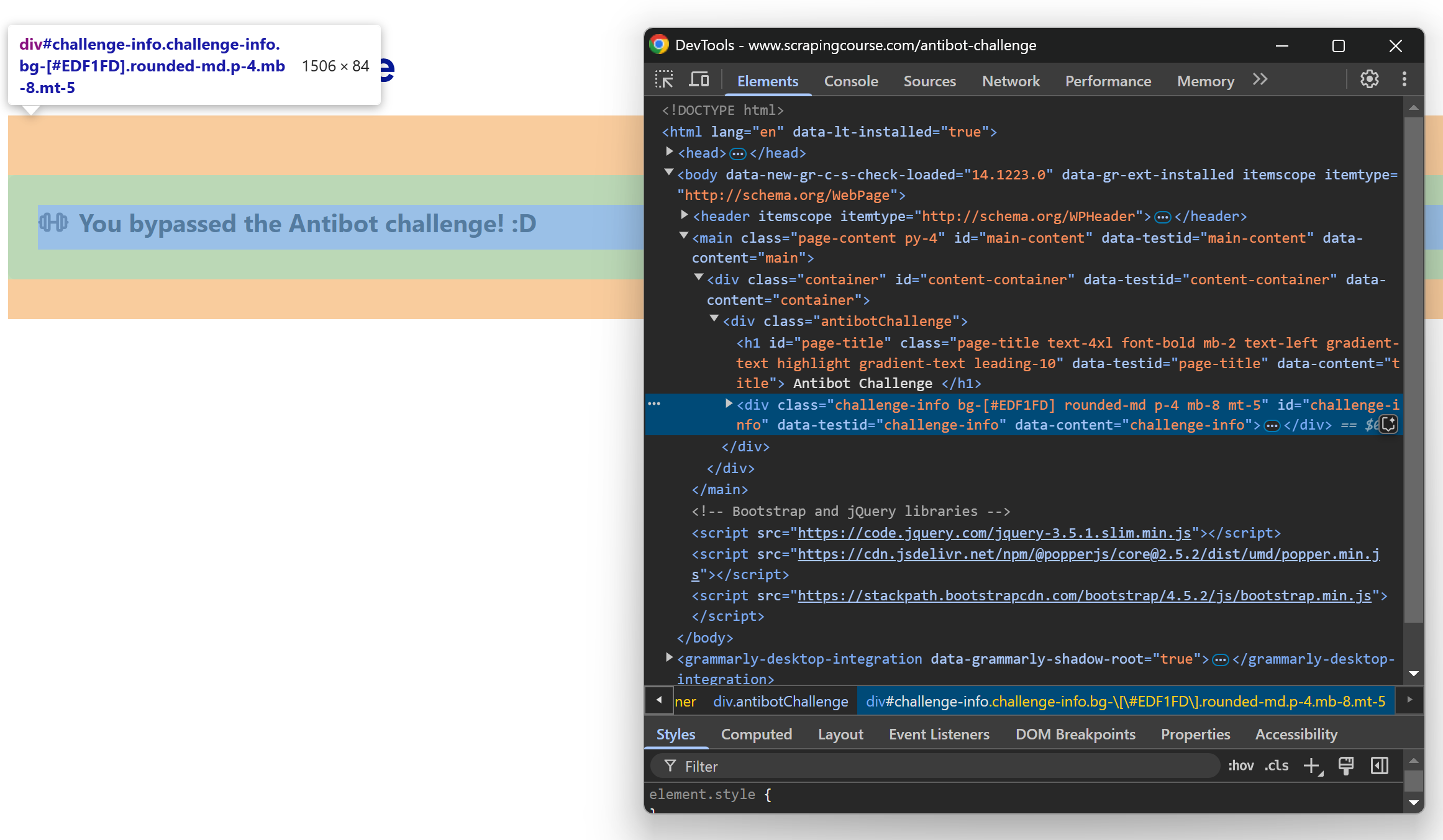
Observe que o elemento da mensagem pode ser selecionado usando o seletor CSS #challenge-info.
Agora, defina uma função personalizada para aguardar a alteração do DOM da página:
função delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}Essa função é necessária porque o puppeteer-real-browser não fornece um callback integrado para a resolução do CAPTCHA. Como esperamos que o Puppeteer Real Browser ignore o CAPTCHA com sucesso, o DOM da página será atualizado de acordo, e você precisará aguardar essas alterações.
Assim, você pode usar delay() para aguardar um período definido para permitir que a página seja totalmente atualizada, conforme abaixo:
await delay(10000);Em seguida, aguarde até que o elemento de mensagem de destino esteja na página:
await page.waitForSelector("#challenge-info", { timeout: 5000 });Em seguida, recupere e imprima seu conteúdo:
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Mensagem da página: "${challengeInfo}"`);Se tudo funcionar como esperado, o script deve exibir:
Mensagem da página: “Você passou no desafio Antibot! :D”Etapa 5: Junte tudo
Abaixo está o seu script final do Puppeteer Real Browser:
const { connect } = require("puppeteer-real-browser");
// função personalizada para implementar uma espera rígida
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}
(async () => {
// conecte-se ao navegador controlado
const { browser, page } = await connect({
headless: false,
turnstile: true, // habilitar o tratamento de CAPTCHA Turnstile
connectOption: {
defaultViewport: null, // tornar a janela de visualização tão grande quanto a janela do navegador
},
args: ["--start-maximized"], // iniciar o navegador em uma janela maximizada
});
// navegar para a página do desafio
await page.goto("https://www.scrapingcourse.com/antibot-challenge", {
waitUntil: "networkidle2", // aguardar até que a página esteja totalmente carregada e inativa
});
// aguarde até 10 segundos para que a resolução de CAPTCHA seja realizada
await delay(10000);
// aguarde até 5 segundos para que o elemento de informações do desafio apareça
await page.waitForSelector("#challenge-info", { timeout: 5000 });
// recupere e imprima o texto de informações do desafio
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Mensagem da página: "${challengeInfo}"`);
// fechar o navegador e liberar seus recursos
await browser.close();
})();Execute o código acima e ele abrirá um navegador que se comportará da seguinte maneira:
O script visita uma página protegida pelo Cloudflare, realiza automaticamente a resolução de CAPTCHA e, em seguida, chega à página de destino, extraindo dados dela.
Conforme desejado, o script produzirá este resultado no terminal:
Mensagem da página: “Você passou no desafio Antibot! :D”Fantástico! A resolução de CAPTCHA do Cloudflare foi realizada automaticamente.
Alternativas ao puppeteer-real-browser
Como o puppeteer-real-browser não é mais mantido, vale a pena explorar alternativas que oferecem recursos semelhantes, como:
- Puppeteer Stealth: um plugin para o Puppeteer Extra que aplica várias evasões para tornar a automação menos detectável. Ele modifica as impressões digitais do navegador, desativa vazamentos do WebRTC e imita o comportamento humano para contornar medidas anti-bot.
- Playwright Stealth: um plugin Playwright Extra que integra as mesmas técnicas de camuflagem semelhantes ao Puppeteer Stealth. Ele corrige APIs do navegador para evitar vazamentos de impressões digitais.
- SeleniumBase: uma estrutura de automação baseada em Selenium com recursos completos e recursos integrados de detecção anti-bot. Inclui técnicas de evasão de bot, falsificação de agente do usuário, tratamento de CAPTCHA e outras ferramentas para ajudar os scripts Selenium a contornar a proteção contra bots.
- undetected-chromedriver: Uma versão modificada do ChromeDriver que ajuda os scripts Selenium a contornar a detecção de bots. Ele remove sinalizadores de automação, ofusca propriedades do WebDriver e garante que o navegador se comporte mais como uma sessão operada por humanos.
Limitações do Puppeteer Real Browser
O Puppeteer Real Browser é uma poderosa ferramenta de automação de navegador anti-bot, mas tem algumas desvantagens. O autor é transparente sobre essas restrições, fornecendo informações claras sobre suas limitações.
As principais limitações são:
- Não é mais mantido: em fevereiro de 2026, o autor original anunciou que a biblioteca não receberá mais atualizações. Melhorias futuras dependerão de contribuições da comunidade, em vez de desenvolvimento ativo.
- Não é 100% indetectável: embora reduza a detecção de bots, sistemas anti-bot avançados ainda podem sinalizar o tráfego automatizado.
- Requer configuração adicional: os usuários podem precisar ajustar Proxy, cabeçalhos e outras configurações para obter o melhor desempenho e funcionalidade.
- Não é possível acessar funções no objeto janela: isso ocorre devido ao tempo de execução do navegador ser fechado pelo Rebrowser. Uma solução alternativa é injetar JavaScript na página usando puppeteer-intercept-and-modify-requests ou usando plug-ins do Chrome.
- Dependente de bibliotecas externas: a biblioteca depende de projetos de terceiros, como Rebrowser, Puppeteer Extra e ghost-cursor, que podem mudar ou ser descontinuados.
- Problemas com o reCAPTCHA: o reCAPTCHA v3 requer que uma sessão ativa do Google seja passada. Mesmo com um navegador indetectável, as tentativas de automação sem uma sessão válida provavelmente serão sinalizadas.
Automação perfeita do navegador anti-bot
As desvantagens mencionadas acima podem desencorajá-lo a considerar o Puppeteer Real Browser. Embora você possa tentar uma de suas alternativas, é provável que encontre desafios semelhantes.
O que importa é que a maioria das bibliotecas de automação de navegador anti-bot se concentra em corrigir navegadores, não na própria biblioteca de automação de navegador. Embora possam ser necessárias pequenas modificações no núcleo dessas bibliotecas, a maior parte do esforço é dedicada a corrigir mecanismos de navegador para evitar vazamentos de detecção.
Agora, imagine poder utilizar bibliotecas de automação de navegador padrão, como Playwright, Puppeteer e Selenium — contando com suas atualizações e APIs estáveis — para controlar um navegador escalável baseado em nuvem, projetado especificamente para o Scraping de dados. Essa é exatamente a experiência oferecida pelo Navegador de scraping da Bright Data!
O Navegador de scraping vem com um recurso integrado de desbloqueio de sites que lida automaticamente com o bloqueio para você. Ele se integra perfeitamente a uma rede Proxy de 400M+ monthly IPs, funciona com eficiência na nuvem e inclui um solucionador de CAPTCHA integrado.
Navegadores otimizados para scraping são a verdadeira solução para alcançar a automação do navegador anti-bot!
Conclusão
Neste artigo, você entendeu como lidar com a detecção de bots no Puppeteer usando o Puppeteer Real Browser. Essa biblioteca fornece uma versão corrigida do puppeteer-core para Scraping de dados sem ser bloqueado.
O problema é que o puppeteer-real-browser não é mais mantido. Portanto, embora possa funcionar hoje, pode não funcionar amanhã, pois as soluções anti-bot continuam evoluindo.
O problema não está na API do Puppeteer para controlar o navegador, mas nos próprios navegadores. A solução é um navegador baseado em nuvem, sempre atualizado e escalável, com funcionalidade anti-bot integrada, como o Navegador de scraping!
O Navegador de scraping da Bright Data é um navegador em nuvem altamente escalável que funciona com Puppeteer, Selenium, Playwright e outros. Ele lida com impressões digitais do navegador, resolução de CAPTCHA e novas tentativas automatizadas para você.
Além disso, ele alterna automaticamente o IP de saída a cada solicitação, graças a uma rede global de Proxies que inclui:
- Proxy de datacenter – Mais de 770.000 IPs de datacenter.
- Proxies residenciais – Mais de 150 milhões de IPs residencialis em mais de 195 países.
- Proxy ISP – Mais de 700.000 IPs de ISP.
Crie hoje mesmo uma conta gratuita na Bright Data para experimentar nosso Navegador de scraping ou testar nossos Proxies.





