
Neste tutorial, abordaremos:
- Como extrair resultados de pesquisa do Naver usando a API SERP da Bright Data
- Criar um Scraper personalizado do Naver com proxies da Bright Data
- Extraindo dados do Naver usando o Bright Data Scraper Studio (IA Scraper) com um fluxo de trabalho sem código
Vamos começar!
Por que coletar dados do Naver?
O Naver é a plataforma líder na Coreia do Sul e a principal fonte de pesquisa, notícias, compras e conteúdo gerado por usuários. Ao contrário dos mecanismos de pesquisa globais, o Naver exibe serviços proprietários diretamente em seus resultados, tornando-o uma fonte de dados essencial para empresas que visam o mercado coreano.
O scraping do Naver permite o acesso a dados estruturados e não estruturados que não estão disponíveis por meio de APIs públicas e são difíceis de coletar manualmente em grande escala.
Que dados podem ser coletados?
- Resultados de pesquisa (SERPs): classificações, títulos, trechos e URLs
- Notícias: editores, manchetes e registros de data e hora
- Compras: listas de produtos, preços, vendedores e avaliações
- Blogs e cafés: conteúdo gerado por usuários e tendências.
Principais casos de uso
- SEO e rastreamento de palavras-chave para o mercado coreano
- Monitoramento de marca e reputação em notícias e conteúdo de usuários
- Comércio eletrônico e análise de preços usando o Naver Shopping
- Pesquisa de mercado e tendências em blogs e fóruns
Com esse contexto estabelecido, vamos abordar a primeira abordagem e ver como extrair os resultados de pesquisa do Naver usando a API SERP da Bright Data.
Extraindo dados do Naver com a API SERP da Bright Data
Essa abordagem é ideal quando você deseja obter dados SERP do Naver sem precisar gerenciar Proxies, CAPTCHAs ou configurações do navegador.
Pré-requisitos
Para acompanhar este tutorial, você precisará de:
- Uma conta Bright Data
- Acesso à API SERP, Proxies ou Scraper Studio no painel da Bright Data
- Python 3.9 ou mais recente instalado
- Conhecimento básico de Python e conceitos de Scraping de dados
Para os exemplos de Scraper personalizado, você também precisará de:
- Playwright instalado e configurado localmente
- Chromium instalado via Playwright
Crie uma zona API SERP no Bright Data
No Bright Data, a API SERP requer uma zona dedicada. Para configurá-la:
- Faça login no Bright Data.
- Vá para API SERP no painel e crie uma nova zona API SERP.
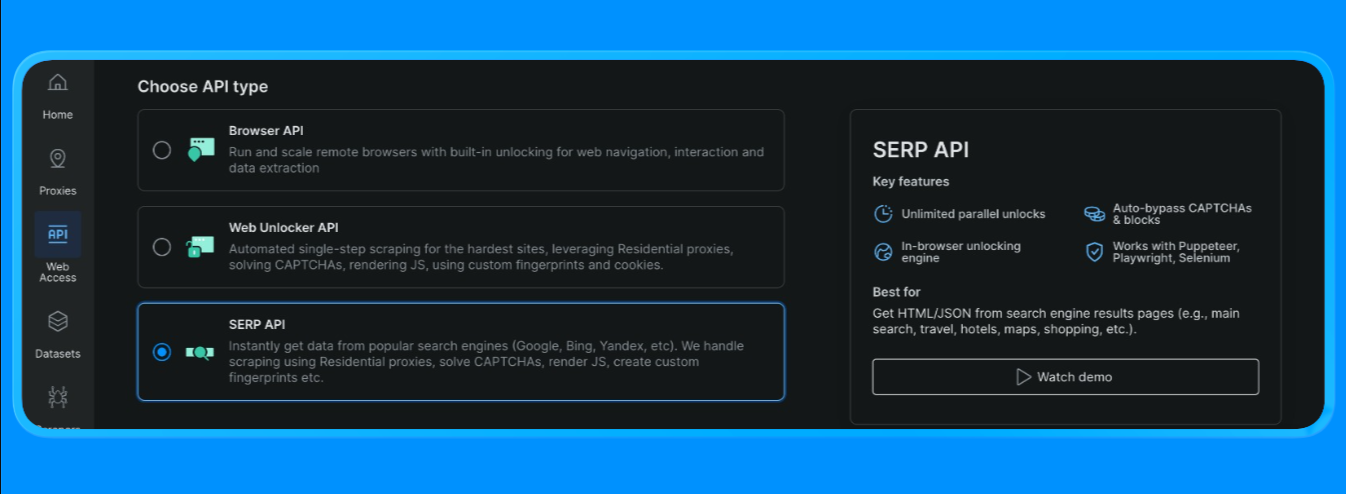
- Copie sua chave API.
Crie a URL de pesquisa do Naver
As SERPs do Naver podem ser solicitadas por meio de um formato de URL de pesquisa padrão:
- Ponto final base:
https://search.naver.com/search.naver - Parâmetro de consulta:
query=<sua palavra-chave>
A consulta é codificada em URL usando quote_plus() para que palavras-chave com várias palavras (como “tutoriais de aprendizado de máquina”) sejam formatadas corretamente.
Envie uma solicitação da API SERP (ponto final de solicitação da Bright Data)
O fluxo de início rápido da Bright Data usa um único endpoint (https://api.brightdata.com/request) onde você passa:
zona:o nome da sua zona da API SERPurl:a URL SERP do Naver que você deseja que a Bright Data busqueformat:defina como raw para retornar o HTML
A Bright Data também suporta modos de saída analisados (por exemplo, estrutura JSON via brd_json=1 ou “resultados principais” mais rápidos via opções data_format ), mas para esta seção do tutorial usaremos seu fluxo de Parsing HTML
Agora você pode criar um arquivo python e incluir os seguintes códigos
import asyncio
import re
from urllib.parse import quote_plus, urlparse
from bs4 import BeautifulSoup
from playwright.async_api import async_playwright, TimeoutError as PwTimeout
BRIGHTDATA_USERNAME = "seu_nome_de_usuário_brightdata"
BRIGHTDATA_PASSWORD = "sua_senha_brightdata"
PROXY_SERVER = "seu_host_proxy"
def clean_text(text: str) -> str:
return re.sub(r"s+", " ", (text or "")).strip()
def blocked_link(href: str) -> bool:
"""Bloquear anúncios/links utilitários; permitir blog.naver.com, pois queremos resultados de blog."""
if not href or not href.startswith(("http://", "https://")):
return True
netloc = urlparse(href).netloc.lower()
# bloquear redirecionamentos de anúncios + utilitários óbvios sem conteúdo
domínios_bloqueados = [
"ader.naver.com",
"adcr.naver.com",
"help.naver.com",
"keep.naver.com",
"nid.naver.com",
"pay.naver.com",
"m.pay.naver.com",
]
if any(netloc == d or netloc.endswith("." + d) for d in blocked_domains):
return True
# No modo blog, você pode:
# (A) permitir apenas domínios de blogs/postagens do Naver (mais "típicos do Naver")
permitidos = ["blog.naver.com", "m.blog.naver.com", "post.naver.com"]
retornar not any(netloc == d ou netloc.endswith("." + d) para d em permitidos)
def pick_snippet(container) -> str:
"""
Heurística: selecione um bloco de texto semelhante a uma frase próximo ao título.
"""
best = ""
for tag in container.find_all(["div", "span", "p"], limit=60):
txt = clean_text(tag.get_text(" ", strip=True))
if 40 <= len(txt) <= 280:
# evitar linhas semelhantes a trilhas de navegação
if "›" in txt:
continue
best = txt
break
return best
def extrair_resultados_do_blog(html: str, limite: int = 10):
soup = BeautifulSoup(html, "html.parser")
resultados = []
visto = conjunto()
# Os layouts do SERP do blog mudam; use vários fallbacks
seletores = [
"a.api_txt_lines", # wrapper de link de título comum
"a.link_tit",
"a.total_tit",
"a[href][target='_blank']",
]
para sel em seletores:
para a em soup.select(sel):
se a.name != "a":
continue
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
se len(title) < 5:
continue
if blocked_link(href):
continue
if href in seen:
continue
seen.add(href)
container = a.find_parent(["li", "article", "div", "section"]) or a.parent
snippet = pick_snippet(container) if container else ""
results.append({"title": title, "link": href, "snippet": snippet})
if len(results) >= limit:
return results
return results
async def scrape_naver_blog(query: str) -> tuple[str, str]:
# Blog vertical Naver
url = f"https://search.naver.com/search.naver?where=blog&query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
# Timeouts compatíveis com Proxy
page.set_default_navigation_timeout(90_000)
page.set_default_timeout(60_000)
# Bloquear recursos pesados para acelerar + reduzir travamentos
async def block_resources(route):
if route.request.resource_type in ("image", "media", "font"):
return await route.abort()
await route.continue_()
await page.route("**/*", block_resources)
# Tentar novamente uma vez (o Navers pode ser um pouco instável)
for attempt in (1, 2):
try:
await page.goto(url, wait_until="domcontentloaded", timeout=90_000)
await page.wait_for_selector("body", timeout=30_000)
html = await page.content()
await browser.close()
return url, html
except PwTimeout:
if attempt == 2:
await browser.close()
raise
await page.wait_for_timeout(1500)
if __name__ == "__main__":
query = "tutorial de aprendizado de máquina"
scraped_url, html = asyncio.run(scrape_naver_blog(query))
print("Extraído de:", scraped_url)
print("Comprimento do HTML:", len(html))
print(html[:200])
results = extract_blog_results(html, limit=10)
print("nResultados extraídos do Naver Blog:")
for i, r in enumerate(results, 1):
print(f"n{i}. {r['title']}n {r['link']}n {r['snippet']}")Usando a função fetch_naver_html(), enviamos uma URL de pesquisa do Naver para o endpoint de solicitação da Bright Data e recuperamos a página SERP totalmente renderizada. A Bright Data lidou com a rotação de IP e o acesso automaticamente, permitindo que a solicitação fosse bem-sucedida sem encontrar bloqueios ou limites de taxa.
Em seguida, realizamos o Parsing do HTML usando o BeautifulSoup e aplicamos uma lógica de filtragem personalizada para remover anúncios e módulos internos do Naver. A função extract_web_results() verificou a página em busca de títulos de resultados válidos, links e blocos de texto próximos, deduplicou-os e retornou uma lista limpa de resultados de pesquisa.
Ao executar o script, você obterá uma saída semelhante a esta: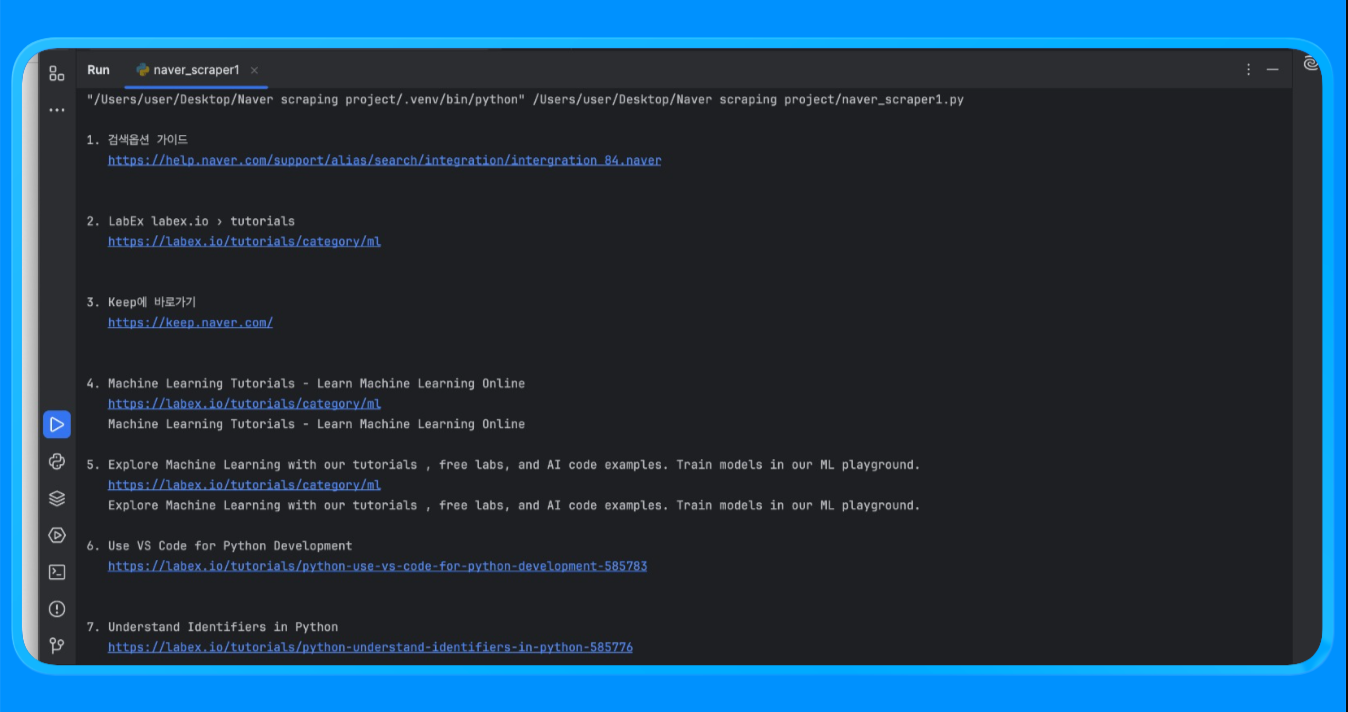
Esse método é usado para coletar resultados de pesquisa estruturados do Naver sem criar ou manter um Scraper personalizado.
Casos de uso comuns
- Classificação de palavras-chave e rastreamento de visibilidade no Naver
- Monitoramento de desempenho de SEO para mercados coreanos
- Análise de recursos SERP, como notícias, compras e posicionamento em blogs
Essa abordagem funciona melhor quando você precisa de esquemas de saída consistentes e altos volumes de solicitações com configuração mínima.
Com a extração em nível de SERP coberta, vamos passar para a criação de um Scraper personalizado do Naver usando proxies da Bright Data para um rastreamento mais profundo e maior flexibilidade.
Criação de um Scraper personalizado do Naver com proxies da Bright Data
Essa abordagem usa um navegador real para renderizar páginas do Naver enquanto encaminha o tráfego através de Proxies Bright Data. É útil quando você precisa de controle total sobre solicitações, renderização JavaScript e extração de dados em nível de página além dos SERPs.
Antes de escrever qualquer código, você precisa primeiro criar uma zona de Proxy e obter suas credenciais de Proxy no painel do Bright Data.
Para obter as credenciais de Proxy usadas neste script:
- Faça login na sua conta Bright Data
- No painel, vá para Proxies e clique em “Criar Proxy”
- Selecione Proxies de datacenter (estamos escolhendo essa opção para este projeto, a opção varia de acordo com o escopo e o caso de uso do projeto)
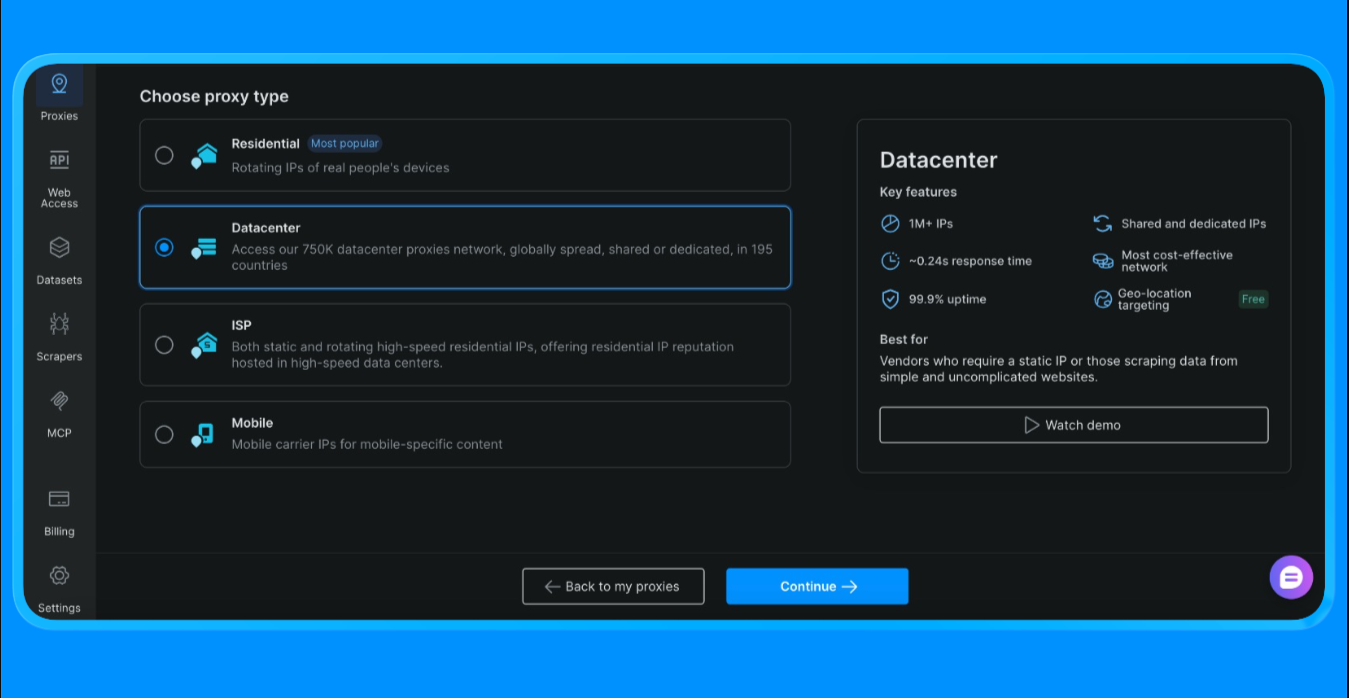
- Crie uma nova zona Proxy
- Abra as configurações da zona e copie os seguintes valores:
- Nome de usuário do Proxy
- Senha do Proxy
- Ponto de extremidade e porta do Proxy
Esses valores são necessários para autenticar as solicitações encaminhadas pela rede Proxy da Bright Data.
Adicione suas credenciais de Proxy da Bright Data ao script
Após criar a zona do Proxy, atualize o script com as credenciais que você copiou do painel.
BRIGHTDATA_USERNAMEcontém seu ID de cliente e o nome da zona ProxyBRIGHTDATA_PASSWORDcontém a senha da zona ProxyPROXY_SERVERaponta para o endpoint do Proxy da Bright Data
Depois que esses valores forem definidos, todo o tráfego do navegador iniciado pelo Playwright será roteado automaticamente pelo Bright Data.
Agora podemos prosseguir com a extração usando os seguintes códigos:
import asyncio
import re
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from playwright.async_api import async_playwright
BRIGHTDATA_USERNAME = "seu_nome_de_usuário"
BRIGHTDATA_PASSWORD = "sua_senha"
PROXY_SERVER = "seu_host_proxy"
def clean_text(s: str) -> str:
return re.sub(r"s+", " ", (s or "")).strip()
async def run(query: str):
url = f"https://search.naver.com/search.naver?query={quote_plus(query)}"
async com async_playwright() como p:
browser = aguardar p.chromium.launch(
headless=True,
Proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
await page.goto(url, wait_until="networkidle")
html = await page.content()
await browser.close()
soup = BeautifulSoup(html, "html.parser")
resultados = []
visto = set()
para a em soup.select("a[href]"):
href = a.get("href", "")
título = clean_text(a.get_text(" ", strip=True))
se len(título) < 8:
continue
if not href.startswith(("http://", "https://")):
continue
if any(x in href for x in ["ader.naver.com", "adcr.naver.com", "help.naver.com", "keep.naver.com"]):
continue
if href in seen:
continue
seen.add(href)
results.append({"title": title, "link": href})
if len(results) >= 10:
break
for i, r in enumerate(results, 1):
print(f"{i}. {r['title']}n {r['link']}n")
if __name__ == "__main__":
asyncio.run(run("machine learning tutorial"))A função scrape_naver_blog() abre o Naver Blog vertical, bloqueia recursos pesados, como imagens, mídia e fontes, para reduzir o tempo de carregamento e tenta novamente a navegação se ocorrer um tempo limite. Quando a página está totalmente carregada, ela recupera o HTML renderizado.
A função extract_blog_results() realiza o Parsing do HTML com o BeautifulSoup, aplica regras de filtragem específicas do blog para excluir anúncios e páginas utilitárias, permitindo domínios do blog Naver, e extrai uma lista limpa de títulos de blogs, links e trechos de texto próximos.
Depois de executar este script, você obtém o resultado:
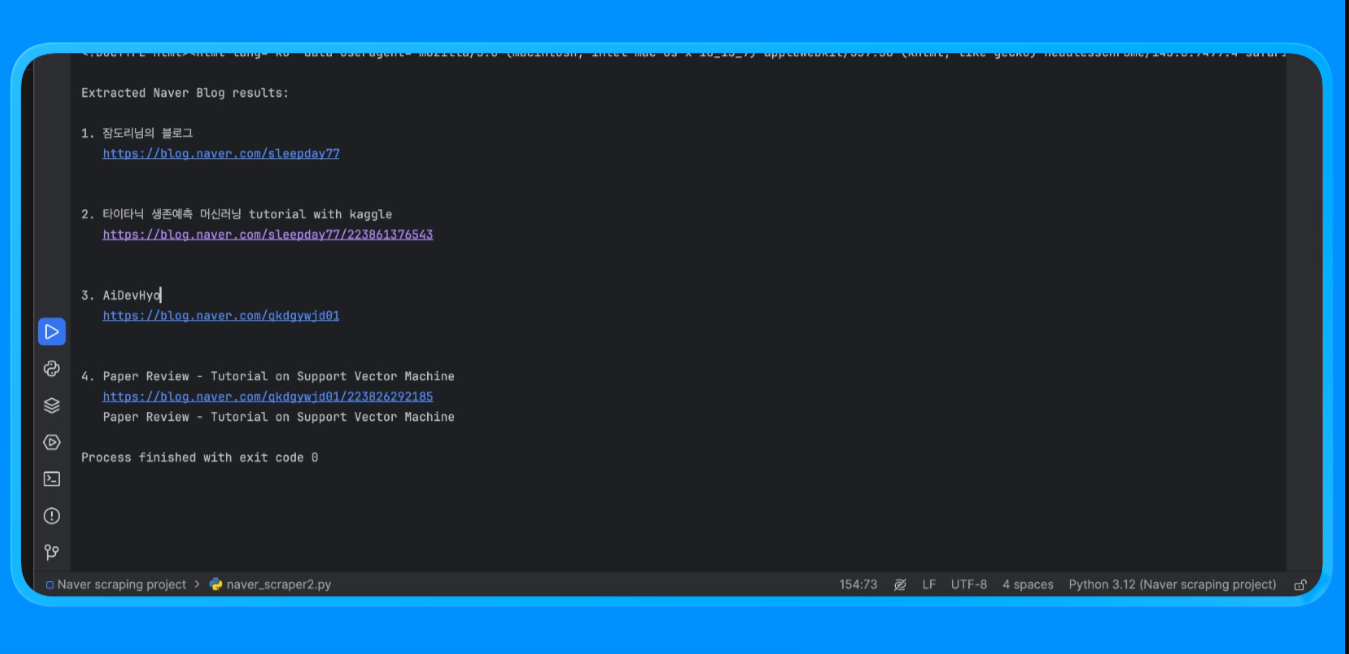
Este método é usado para extrair conteúdo de páginas do Naver que exigem renderização do navegador e lógica de Parsing personalizada.
Casos de uso comuns
- Extraindo conteúdo do Naver Blog e Cafe
- Coleta de artigos longos, comentários e conteúdo do usuário
- Extração de dados de páginas com muito JavaScript
Essa abordagem é ideal quando é necessário renderizar páginas, refazer tentativas e aplicar filtros refinados.
Agora que temos um Scraper personalizado funcionando através dos Proxies da Bright Data, vamos passar para a opção mais rápida para extrair dados sem escrever código. Na próxima seção, faremos o scraping do Naver usando o Bright Data Scraper Studio, o fluxo de trabalho sem código e alimentado por IA, construído na mesma infraestrutura.
Raspando o Naver com o Bright Data Scraper Studio (raspador de IA sem código)
Se você não deseja escrever ou manter código de raspagem, o Bright Data Scraper Studio oferece uma maneira sem código para extrair dados do Naver usando a mesma infraestrutura subjacente da API SERP e da rede de proxies.
Para começar:
- Faça login na sua conta Bright Data
- No painel, abra a opção “Scrapers” no menu à esquerda e clique em “Scraper studio”. Você verá um painel parecido com este:
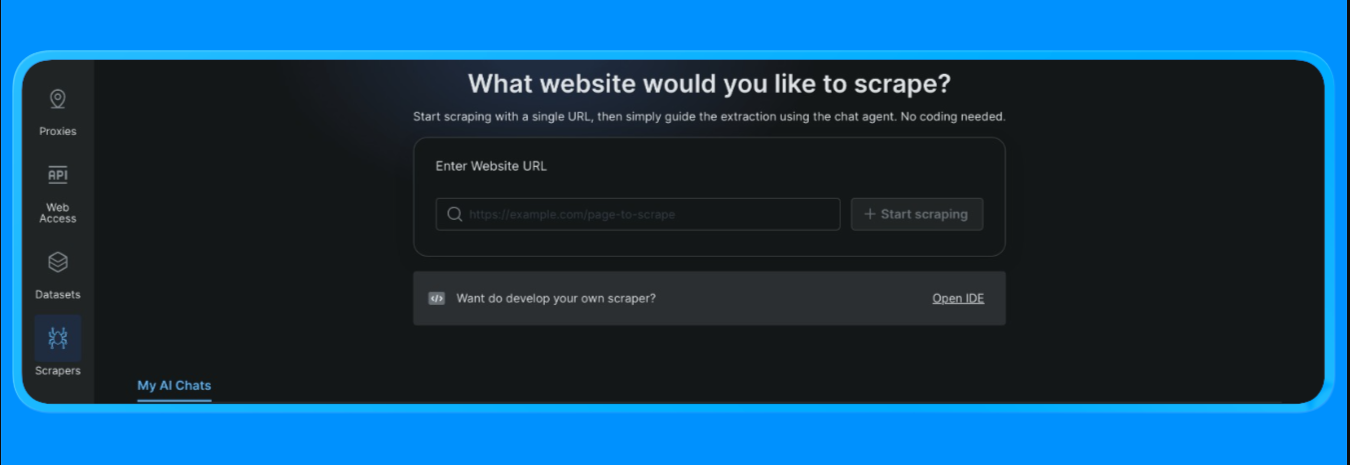
Insira a URL de destino que você deseja extrair e clique no botão “Iniciar extração”
O Scraper Studio então começa a extrair o site e fornece as informações de que você precisa.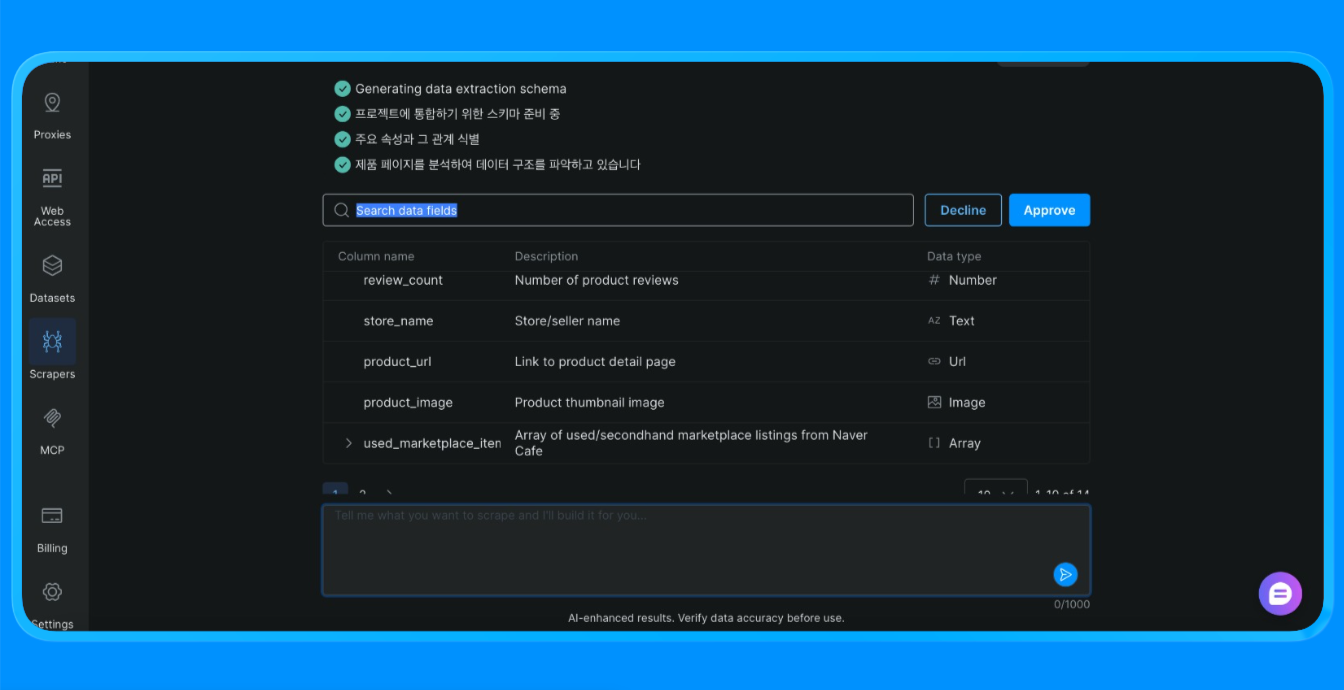
O Scraper Studio carregou a página do Naver através da infraestrutura da Bright Data, aplicou regras de extração visual e retornou dados estruturados que, de outra forma, exigiriam um scraper personalizado ou automação do navegador.
Casos de uso comuns
- Coleta de dados pontual
- Projetos de prova de conceito
- Equipes não técnicas coletando dados da web
O Scraper Studio é uma boa escolha quando a velocidade e a simplicidade são mais importantes do que a personalização.
Comparando as três abordagens de scraping do Naver
| Abordagem | Esforço de configuração | Nível de controle | Escalabilidade | Ideal para |
|---|---|---|---|---|
| API SERP da Bright Data | Baixo | Médio | Alta | Rastreamento de SEO, monitoramento de palavras-chave, dados SERP estruturados |
| Scraper personalizado com proxies Bright Data | Alto | Muito alto | Muito alto | Raspagem de blogs, páginas dinâmicas, fluxos de trabalho personalizados |
| Bright Data Scraper Studio | Muito baixo | Baixo a médio | Médio | Extração rápida, equipes sem código, prototipagem |
Como escolher:
- Use a API SERP quando precisar de resultados de pesquisa confiáveis e estruturados em escala.
- Use Proxies com um Scraper personalizado quando precisar de controle total sobre renderização, novas tentativas e lógica de extração.
- Use o Scraper Studio quando a velocidade e a simplicidade forem mais importantes do que a personalização.
Conclusão
Neste tutorial, abordamos três maneiras prontas para produção de fazer scraping do Naver usando o Bright Data:
- Uma API SERP gerenciada para dados de pesquisa estruturados
- Um scraper personalizado com Proxies para total flexibilidade e controle
- Um fluxo de trabalho sem código do Scraper Studio para extração rápida de dados
Cada opção é construída na mesma infraestrutura do Bright Data. A escolha certa depende de quanto controle você precisa, com que frequência planeja fazer a extração e se deseja escrever código.
Você pode explorar o Bright Data para obter acesso à API SERP, à infraestrutura de Proxy e ao Scraper Studio sem código, e escolher a abordagem que melhor se adapta ao seu fluxo de trabalho.
Para mais guias e tutoriais sobre Scraping de dados:
- Scraping de dados com Python: o guia completo
- Como fazer scraping em sites dinâmicos com Python
- Melhores APIs SERP para scraping de dados
- Scraping de dados com Playwright
- Melhores provedores de Proxy para Scraping de dados
- Os melhores provedores de Proxy residencial
- Bibliotecas de scraping de dados em Python
- Melhores serviços de Scraping de dados






