

O Google Travel coleta dados agregados de viagens de toda a web para todos os tipos de categorias relacionadas a viagens, como voos, pacotes de férias e quartos de hotel. Comprar hotéis é difícil, e uma das maiores dificuldades é filtrar a confusão de listagens patrocinadas por anúncios e quartos aleatórios que simplesmente não se aplicam à sua pesquisa.
Se você não estiver interessado em fazer scraping, dê uma olhada em nossos Conjuntos de dados de viagens pré-criados. Com os Conjuntos de dados, nós fazemos o scraping para que você não precise fazer isso. Se você estiver pronto para fazer scraping, continue lendo!
Pré-requisitos
Para fazer scraping de dados de viagens, você precisará do Python e do Selenium, Requests ou AIOHTTP. Com o Selenium, faremos o scraping das informações dos hotéis diretamente do Google Travel. Com o Requests e o AIOHTTP, usaremos a API do Booking.com da Bright Data.
Se você estiver usando o Selenium, certifique-se de ter o webdriver instalado. Se você não estiver familiarizado com o Selenium, dê uma olhada neste guia para se familiarizar rapidamente.
Instale o Selenium
pip install selenium
Instale o Requests
pip install requests
Instale o AIOHTTP
pip install aiohttp
Depois de instalar a ferramenta de sua escolha, você estará pronto para começar.
O que extrair do Google Travel
Se você optar por extrair manualmente do Google Travel, precisará entender melhor quais dados estamos tentando extrair. Todos os nossos resultados de hotéis vêm incorporados em um elemento c-wiz personalizado do Google Travel.
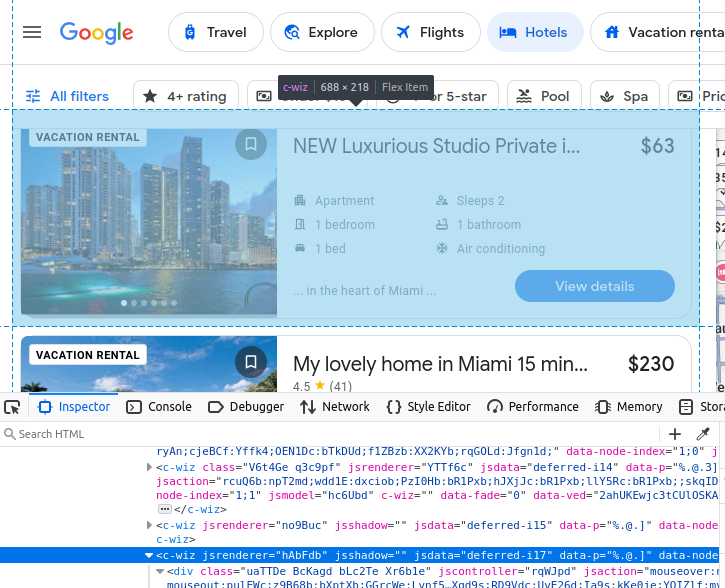
No entanto, há muitos elementos c-wiz na página. Cada um dos nossos cartões de hotéis contém um elemento a diretamente descendente de um div e deste elemento c-wiz. Podemos escrever um seletor CSS para encontrar todas as tags a descendentes desses elementos: c-wiz > div > a.
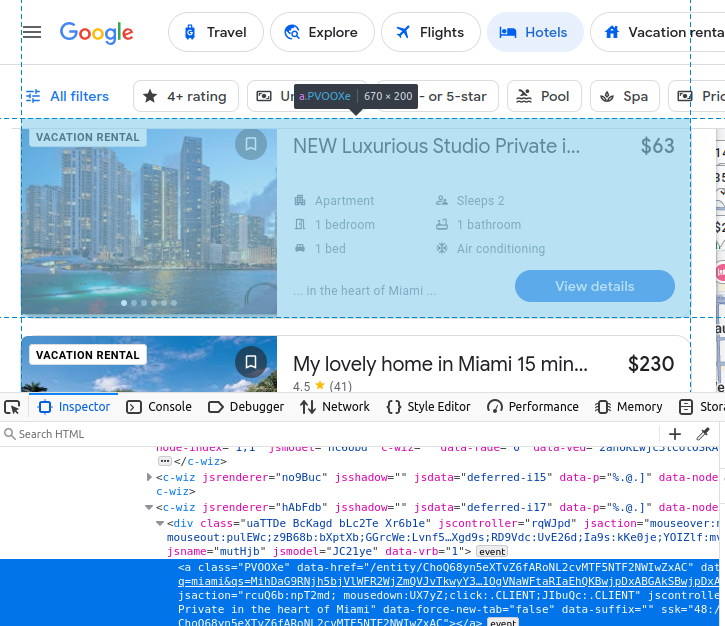
O nome da listagem vem incorporado em um h2.
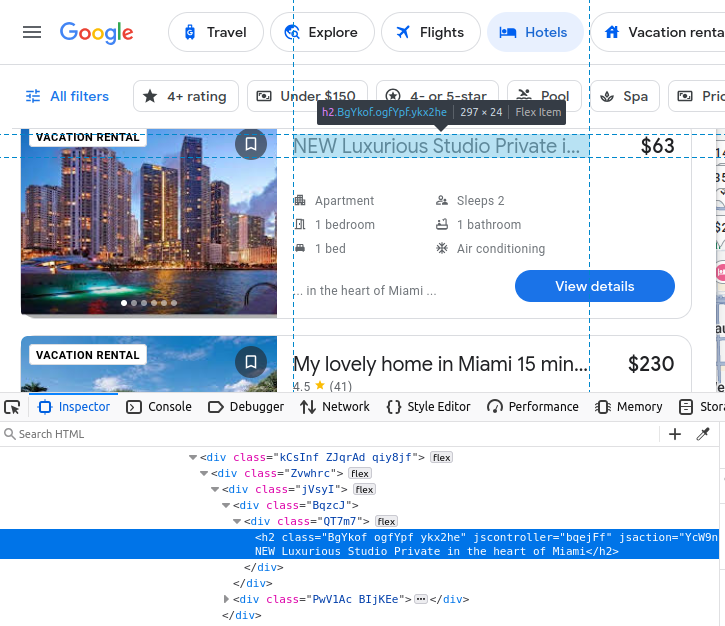
Nosso preço vem incorporado em um span.
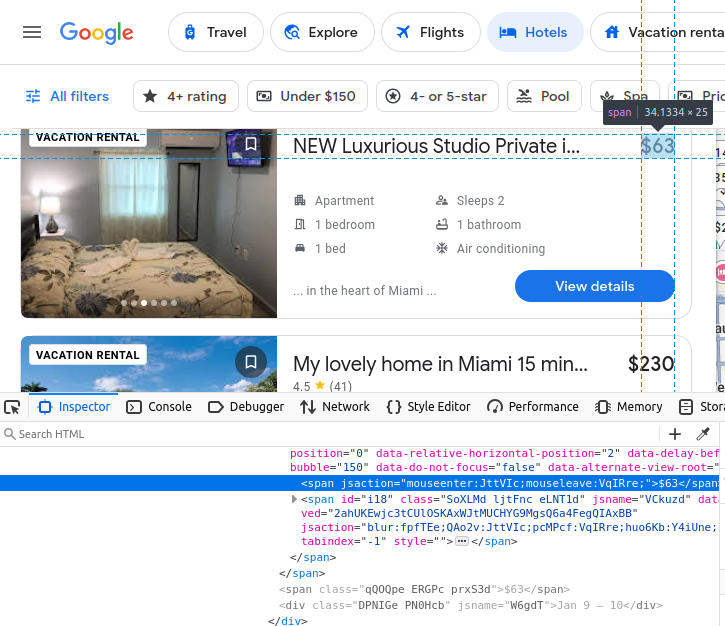
Nossas comodidades estão incorporadas em elementos li (lista).
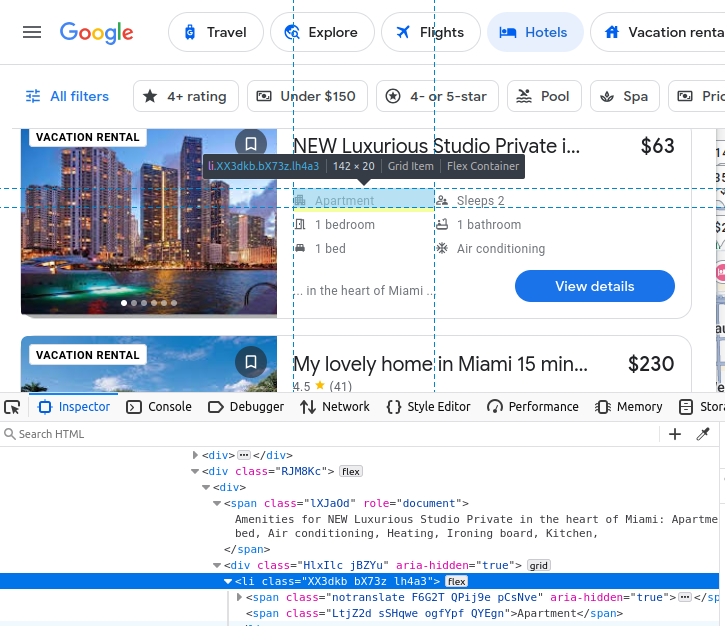
Depois de encontrar nosso cartão de hotel, podemos extrair todos os dados mencionados acima dele.
Extrair os dados com o Selenium
Extrair esses dados com o Selenium é relativamente simples, uma vez que você sabe o que procurar. No entanto, o Google Travel carrega nossos resultados dinamicamente, o que torna o processo um pouco delicado, dependente de esperas pré-configuradas, cliques do mouse e janelas personalizadas. Sem a janela personalizada, seus resultados não serão carregados corretamente.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import json
from time import sleep
OPTIONS = webdriver.ChromeOptions()
OPTIONS.add_argument("--headless")
OPTIONS.add_argument("--window-size=1920,1080")
def scrape_hotels(location, pages=5):
driver = webdriver.Chrome(options=OPTIONS)
actions = ActionChains(driver)
url = f"https://www.google.com/travel/search?q={location}"
driver.get(url)
done = False
found_hotels = []
page = 1
result_number = 1
enquanto página <= páginas:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(5)
hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")
imprimir(f"-----------------PÁGINA {página}------------------")
imprimir("ITENS ENCONTRADOS: ", len(links_de_hotéis))
para link_de_hotel em links_de_hotéis:
cartão_de_hotel = link_de_hotel.find_element(By.XPATH, "..")
tente:
info = {}
info["url"] = hotel_link.get_attribute("href")
info["rating"] = 0.0
info["price"] = "n/a"
info["name"] = hotel_card.find_element(By.CSS_SELECTOR, "h2").text
price_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span")
info["amenities"] = []
amenities_holders = hotel_card.find_elements(By.CSS_SELECTOR, "li")
para amenity em amenities_holders:
info["amenities"].append(amenity.text)
if "DEAL" in price_holder[0].text or "PRICE" in price_holder[0].text:
if price_holder[1].text[0] == "$":
info["price"] = price_holder[1].text
else:
info["price"] = price_holder[0].text
rating_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span[role='img']")
if rating_holder:
info["rating"] = float(rating_holder[0].get_attribute("aria-label").split(" ")[0])
info["result_number"] = result_number
if info not in found_hotels:
found_hotels.append(info)
result_number+=1
except:
continue
print("Total coletado:", len(found_hotels))
next_button = driver.find_elements(By.XPATH, "//span[text()='Next']")
if next_button:
print("botão seguinte encontrado!")
sleep(1)
actions.move_to_element(next_button[0]).click().perform()
page+=1
sleep(5)
else:
done = True
driver.quit()
com open("scraped-hotels.json", "w") como arquivo:
json.dump(hotéis encontrados, arquivo, indent=4)
se __name__ == "__main__":
PÁGINAS = 2
scrape_hotels("miami", páginas=PÁGINAS)
- Primeiro, criamos uma instância do
ChromeOptions. Usamos isso para adicionar nossos argumentos--headlesse--window-size=1920,1080.- Sem o tamanho de janela personalizado, os resultados não carregam corretamente, então acabamos raspando os mesmos resultados repetidamente.
- Quando iniciamos o navegador, usamos o argumento de palavra-chave
options=OPTIONS. Isso inicia o Chrome com nossas opções personalizadas. ActionChains(driver)nos fornece uma instânciaActionChains. Usamos isso mais tarde em nosso script para mover o cursor para o botãoAvançare clicar nele.- Usamos um loop
whilepara conter nosso tempo de execução. Quando a coleta terminar, sairemos desse loop. hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")nos fornece todos os links de hotéis na página. Encontramos seus elementos pai usando seu xpath:hotel_card = hotel_link.find_element(By.XPATH, "..").- Em seguida, examinamos e extraímos todos os dados individuais que vimos anteriormente:
- url:
hotel_link.get_attribute("href") - name:
hotel_card.find_element(By.CSS_SELECTOR, "h2").text - Ao procurar o preço, às vezes há elementos adicionais no cartão, como
DEALeGREAT PRICE. Para garantir que sempre obtenhamos o preço certo, extraímos os elementosspanem uma matriz. Se a matriz contiver essas palavras, pegamos o segundo elemento (price_holder[1].text) em vez do primeiro (price_holder[0].text). - Também usamos o método
find_elements()ao procurar a classificação. Se não houver classificação, atribuímos um valor padrão den/a. hotel_card.find_elements(By.CSS_SELECTOR, "li")gera nossos detentores de comodidades. Extraímos cada um deles usando seu atributode texto.
- url:
- Continuamos esse loop até termos extraído todas as páginas desejadas. Depois de obtermos nossos dados, definimos
donecomoTruee saímos do loop. - Fechamos o navegador de scraping e usamos
json.dump()para salvar todos os nossos dados coletados em um arquivo JSON.
Ao coletar hotéis do Google Travel, não encontramos nenhum problema de bloqueio, mas tudo é possível. Se você encontrar algum problema, oferecemos Proxies residenciais e um Navegador de scraping integrado para ajudar a superar qualquer obstáculo.
Extrair esses resultados com o Selenium é tedioso e delicado, mas totalmente viável.
Extraia os dados com a API de viagens da Bright Data
Às vezes, você não quer depender de um Scraper ou passar o dia todo lidando com seletores e localizadores. Tudo bem! Oferecemos vários tipos de dados de viagem. Você pode até extrair dados de hotéis usando nossa API do Booking.com. Tudo o que você precisa fazer é enviar algumas solicitações HTTP. Nós cuidamos do resto para que você possa continuar com o seu dia.
Solicitações
O código abaixo configura a API da Booking.com. Basta inserir sua chave API, local de viagem, data de check-in e data de check-out. Primeiro, ele faz uma solicitação à API para gerar os dados. Em seguida, ele verifica os dados repetidamente a cada 10 segundos até que nosso relatório esteja pronto. Depois de recebermos nossos dados, os salvamos convenientemente em um arquivo JSON.
import requests
import json
import time
def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/conjuntos_de_datos/v3/trigger"
#conjunto de dados booking.com
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
auth_token = api_key
#
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": localização,
"check_in": datas["check_in"],
"check_out": datas["check_out"],
"adults": 2,
"rooms": 1
}
]
response = requests.post(endpoint, headers=headers, json=payload)
if response.status_code == 200:
print("Solicitação bem-sucedida. Resposta:")
print(json.dumps(response.json(), indent=4))
return response.json()["snapshot_id"]
else:
print(f"Erro: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
#criar a url do snapshot
snapshot_url = f"https://api.brightdata.com/conjuntos-de-dados/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
imprimir(f"Pesquisando instantâneo para ID: {snapshot_id}...")
enquanto True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Instantâneo pronto. Baixando...")
snapshot_data = response.json()
#gravar o instantâneo em um novo arquivo json
com open(arquivo_de_saída, "w", codificação="utf-8") como arquivo:
json.dump(dados_do_instantâneo, arquivo, indentação=4)
imprimir(f"Instantâneo salvo em {arquivo_de_saída}")
break
elif resposta.status_code == 202:
imprimir("O instantâneo ainda não está pronto. Repetindo em 10 segundos...")
else:
print(f"Erro: {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "sua-chave-API-bright-data"
LOCATION = "Miami"
CHECK_IN = "2026-02-01T00:00:00.000Z"
CHECK_OUT = "2026-02-02T00:00:00.000Z"
DATES = {
"check_in": CHECK_IN,
"check_out": CHECK_OUT
}
snapshot_id = get_bookings(API_KEY, LOCATION, DATES)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)
get_bookings()recebe suaAPI_KEY,LOCATIONeDATES. Em seguida, faz uma solicitação dos dados e retorna osnapshot_id.- O
snapshot_idé muito importante. Precisamos dele para recuperar o instantâneo. - Depois que o
snapshot_idé gerado, a funçãopoll_and_retrieve_snapshot()verifica a cada 10 segundos se os dados estão prontos. - Quando os dados estão prontos, usamos
json.dump()para salvá-los em um arquivo JSON.
Ao executar o código, você deverá ver algo semelhante a isto no seu terminal.
Solicitação bem-sucedida. Resposta:
{
"snapshot_id": "s_m5moyblm1wikx4ntot"
}
Verificando o snapshot para o ID: s_m5moyblm1wikx4ntot...
O snapshot ainda não está pronto. Repetindo em 10 segundos...
O instantâneo ainda não está pronto. Repetindo em 10 segundos...
O instantâneo ainda não está pronto. Repetindo em 10 segundos...
O instantâneo ainda não está pronto. Repetindo em 10 segundos...
O instantâneo está pronto. Baixando...
Instantâneo salvo em snapshot-data.json
Então você obterá um arquivo JSON cheio de objetos como este.
{
"input": {
"url": "https://www.booking.com",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"rooms": 1
},
"url": "https://www.booking.com/hotel/us/ramada-plaze-by-wyndham-marco-polo-beach-resort.html?checkin=2025-02-01&checkout=2025-02-02&group_adults=2&no_rooms=1&group_children=",
"localização": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adultos": 2,
"crianças": nulo,
"quartos": 1,
"id": "55989",
"title": "Ramada Plaza by Wyndham Marco Polo Beach Resort",
"address": "19201 Collins Avenue",
"city": "Sunny Isles Beach (Florida)",
"review_score": 6.2,
"review_count": "1788",
"image": "https://cf.bstatic.com/xdata/images/hotel/square600/414501733.webp?k=4c14cb1ec5373f40ee83d901f2dc9611bb0df76490f3673f94dfaae8a39988d8&o=",
"preço_final": 217,
"preço_original": 217,
"moeda": "USD",
"tax_description": nulo,
"nb_livingrooms": 0,
"nb_kitchens": 0,
"nb_bedrooms": 0,
"nb_all_beds": 2,
"full_location": {
"description": "Esta é a distância em linha reta no mapa. A distância real de viagem pode variar.",
"main_distance": "11,4 milhas do centro da cidade",
"display_location": "Miami Beach",
"beach_distance": "À beira-mar",
"nearby_beach_names": []
},
"no_prepayment": false,
"free_cancellation": true,
"property_sustainability": {
"is_sustainable": false,
"level_id": "L0",
"facilities": [
"436",
"490",
"492",
"496",
"506"
]
},
"timestamp": "2026-01-07T16:43:24.954Z"
},
AIOHTTP
Com o AIOHTTP, podemos tornar esse processo um pouco mais rápido. Podemos acionar, pesquisar e baixar vários Conjuntos de dados simultaneamente. O código abaixo se baseia nos nossos conceitos do exemplo Requests acima, mas usa o poderoso aiohttp.ClientSession() para fazer várias solicitações de forma assíncrona.
import aiohttp
import asyncio
import json
async def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/conjuntos_de_dados/v3/trigger"
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
async com aiohttp.ClientSession(headers=headers) como sessão:
async com sessão.post(endpoint, json=payload) como resposta:
se resposta.status == 200:
dados_da_resposta = aguardar resposta.json()
imprimir(f"Solicitação bem-sucedida para localização: {localização}. Resposta:")
imprimir(json.dumps(response_data, indent=4))
retornar response_data["snapshot_id"]
else:
imprimir(f"Erro para localização: {location}. Status: {response.status}")
imprimir(await response.text())
retornar None
async def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file):
snapshot_url = f"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Pesquisando instantâneo para ID: {snapshot_id}...")
async with aiohttp.ClientSession(headers=headers) as session:
while True:
async with session.get(snapshot_url) as response:
if response.status == 200:
imprimir(f"Instantâneo para {output_file} está pronto. Baixando...")
snapshot_data = aguardar resposta.json()
# Salvar dados do instantâneo em um arquivo
com abrir(output_file, "w", codificação="utf-8") como arquivo:
json.dump(snapshot_data, arquivo, recuo=4)
imprimir(f"Instantâneo salvo em {output_file}")
break
elif resposta.status == 202:
imprimir(f"O instantâneo para {output_file} ainda não está pronto. Repetindo em 10 segundos...")
else:
imprimir(f"Erro ao consultar o instantâneo para {output_file}. Status: {response.status}")
imprimir(aguardar resposta.texto())
break
aguardar asyncio.sleep(10)
async def processar_localização(chave_api, localização, datas):
snapshot_id = aguardar obter_reservas(chave_api, localização, datas)
if snapshot_id:
output_file = f"snapshot-{location.replace(' ', '_').lower()}.json"
await poll_and_retrieve_snapshot(api_key, snapshot_id, output_file)
locais = ["Miami", "Key West"]
datas = {
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z"
}
# Processar todos os locais em paralelo
tarefas = [processar_local(chave_api, local, datas) para local em locais]
aguardar asyncio.gather(*tarefas)
se __name__ == "__main__":
asyncio.run(main())
- Agora, tanto
get_bookings()quantopoll_and_retrieve_snapshot()usam nosso objetoaiohttp.ClientSessionpara criar solicitações assíncronas ao servidor. process_location()é usado para processar todos os dados de um local.main()nos permite chamarprocess_location()em todos os locais simultaneamente.
Com o AIOHTTP, você pode acionar, pesquisar e baixar vários Conjuntos de dados ao mesmo tempo. Dessa forma, você não precisa esperar desnecessariamente pela conclusão de um relatório antes de gerar o próximo.
Dê uma olhada na saída. Como você pode ver, acionamos os dois relatórios. Em seguida, baixamos um relatório enquanto ainda aguardamos o outro. Em grande escala, isso economizará uma quantidade incrível de tempo.
Solicitação bem-sucedida para o local: Miami. Resposta:
{
"snapshot_id": "s_m5mtmtv62hwhlpyazw"
}
Solicitação bem-sucedida para o local: Key West. Resposta:
{
"snapshot_id": "s_m5mtmtv72gkkgxvdid"
}
Pesquisando instantâneo para ID: s_m5mtmtv62hwhlpyazw...
Pesquisando instantâneo para ID: s_m5mtmtv72gkkgxvdid...
O instantâneo para snapshot-miami.json ainda não está pronto. Repetindo em 10 segundos...
O instantâneo para snapshot-key_west.json ainda não está pronto. Repetindo em 10 segundos...
O instantâneo para snapshot-key_west.json ainda não está pronto. Repetindo em 10 segundos...
O instantâneo para snapshot-miami.json ainda não está pronto. Repetindo em 10 segundos...
O instantâneo para snapshot-key_west.json ainda não está pronto. Repetindo em 10 segundos...
O snapshot para snapshot-miami.json ainda não está pronto. Tentando novamente em 10 segundos...
O snapshot para snapshot-miami.json está pronto. Baixando...
O snapshot para snapshot-key_west.json ainda não está pronto. Tentando novamente em 10 segundos...
Snapshot salvo em snapshot-miami.json
O snapshot para snapshot-key_west.json ainda não está pronto. Repetindo em 10 segundos...
O snapshot para snapshot-key_west.json ainda não está pronto. Repetindo em 10 segundos...
O snapshot para snapshot-key_west.json ainda não está pronto. Repetindo em 10 segundos...
O snapshot para snapshot-key_west.json está pronto. Baixando...
Snapshot salvo em snapshot-key_west.json
Soluções alternativas da Bright Data
Além de nossas poderosas APIs Web Scraper, a Bright Data fornece conjuntos de dados prontos para uso, adaptados para atender a diversas necessidades. Entre nossos conjuntos de dados de viagem mais procurados estão:
- Conjuntos de datos de hotéis
- Conjuntos de datos da Expedia
- Conjuntos de datos de turismo
- Conjuntos de datos da Booking.com
- Conjuntos de datos do TripAdvisor
Com a Bright Data, você pode escolher entre Conjuntos de dados personalizados totalmente gerenciados ou autogerenciados, permitindo extrair dados de qualquer site público e personalizá-los de acordo com suas especificações exatas.
Conclusão
Ao fazer scraping de dados na web, você pode encontrar um tesouro de informações sobre hotéis no Google Travel. Se você prefere o modelo DIY com Selenium ou apenas deseja resultados rápidos e convenientes com a API da Booking.com, pode coletar esses dados para obter insights realmente valiosos. Se você deseja analisar preços históricos ou apenas comprar um quarto com eficiência, acaba de adicionar mais uma habilidade útil ao seu conjunto de habilidades tecnológicas!
Inscreva-se agora para experimentar os produtos da Bright Data gratuitamente.






