

Neste artigo, aprenderemos sobre:
- Os desafios que os desenvolvedores enfrentam quando os dados extraídos de sites não são confiáveis ou estão desatualizados
- Identificar as causas de resultados ruins de raspagem
- Obter sugestões para garantir dados mais limpos e confiáveis
Vamos mergulhar de cabeça!
Algumas causas de dados imprecisos de Scraping de dados da Web
Antes de aprender a melhorar a precisão dos dados extraídos, você precisa conhecer algumas das causas desses problemas. Nesta seção, você conhecerá alguns dos problemas que pode encontrar durante a coleta de dados. Alguns deles são: conteúdo dinâmico, alterações frequentes no DOM etc.
Conteúdo renderizado em JavaScript criando lacunas de dados
Os sites com muito JavaScript carregam conteúdo de forma assíncrona após a resposta HTML inicial, deixando os scrapers HTTP tradicionais com estruturas de página incompletas. Quando você solicita uma página, recebe apenas o esqueleto HTML inicial antes da execução do JavaScript. As listas de produtos em sites de comércio eletrônico, os comentários de usuários em plataformas sociais e o conteúdo de rolagem infinita geralmente são carregados por meio de chamadas AJAX que ocorrem milissegundos ou segundos após o carregamento da página.
Essa incompatibilidade de tempo faz com que os Scrapers extraiam elementos de espaço reservado, spinners de carregamento ou contêineres vazios em vez de dados reais. O HTML extraído pode conter <div class="product-list" data-loading="true"></div> em vez das informações preenchidas do produto.
Evolução inconsistente da estrutura DOM

Os sites frequentemente modificam sua estrutura HTML sem manter a compatibilidade com versões anteriores para ferramentas automatizadas. Eles podem ter seletores CSS que funcionaram de forma confiável por meses e, de repente, retornam resultados vazios quando os desenvolvedores mudam os nomes das classes, reestruturam layouts ou movem elementos para contêineres pai diferentes. Seu Scraper pode ter como alvo os seletores .product-price que são renomeados para .item-cost durante a reformulação de um site.
Sistemas antibot que corrompem a coleta de dados
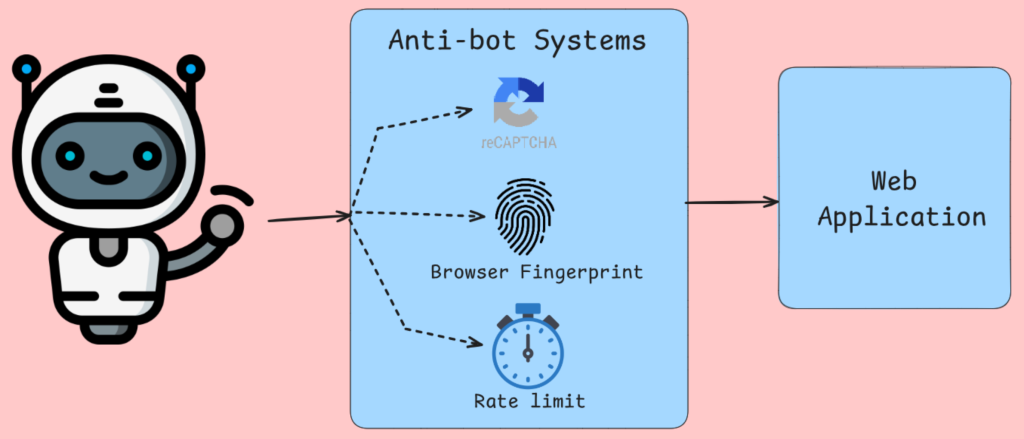
A detecção de bots não faz apenas o bloqueio de IP, analisando as impressões digitais do navegador, os movimentos do mouse e outras verificações bem conhecidas. Ferramentas como a Cloudflare e serviços semelhantes injetam desafios de JavaScript que exigem a execução do navegador para serem concluídos. Após a verificação do navegador, você receberá conteúdo alternativo ou páginas de erro para solicitações que falharem nesses testes. Seu Scraper recebe páginas CAPTCHA, mensagens de acesso negado ou dados deliberadamente enganosos em vez de conteúdo legítimo.
Os algoritmos de limitação de taxa rastreiam a frequência de solicitações por endereço IP, string de agente de usuário etc. Com essas informações, o Tráfego é estrangulado ou bloqueado se parecer uma atividade humana.
Problemas de renderização no lado do servidor
A renderização no servidor com estruturas como Next.js gera diferentes resultados de HTML com base em diferentes critérios. O mesmo URL pode retornar estruturas de conteúdo completamente diferentes, dependendo de fatores que seu Scraper não controla nem simula com precisão. O conteúdo personalizado, as informações com delimitação geográfica e os preços específicos do usuário criam cenários em que seu scraper vê dados diferentes dos usuários pretendidos.
As camadas de cache entre seu Scraper e os servidores de origem introduzem inconsistências temporais em que o conteúdo atualizado recentemente leva tempo para se propagar pelos nós de CDN. Seu Scraper pode recuperar preços de produtos obsoletos, níveis de estoque desatualizados ou páginas de erro armazenadas em cache que não refletem o estado atual do site. Servidores de borda em diferentes regiões geográficas podem servir diferentes versões em cache, tornando a consistência dos dados dependente de qual servidor responde às suas solicitações.
Corrupção de dados em nível de rede
Conexões de rede instáveis, problemas no servidor Proxy e problemas de resolução de DNS introduzem corrupção sutil de dados que é difícil de detectar por meio do tratamento de erros padrão. Os downloads de conteúdo parcial criam respostas HTML truncadas que são analisadas com êxito, mas perdem seções críticas da página. Seu Scraper pode receber os primeiros 80% de uma página de listagem de produtos, parecendo funcionar corretamente, mas perdendo sistematicamente itens que são carregados na parte inferior de páginas mais longas.
Os algoritmos de compactação ocasionalmente corrompem os dados durante a transmissão, especialmente ao usar Proxies rotativos com diferentes configurações de compactação.
Quais são os impactos de dados imprecisos nos aplicativos?
Dados imprecisos de Scraping de dados afetam os sistemas de maneiras que comprometem fundamentalmente a lógica de negócios e as experiências do usuário. A compreensão dessas falhas ajuda os desenvolvedores a criar pipelines de dados e camadas de validação mais resilientes.
Degradação do pipeline de análise
Os problemas de qualidade dos dados se manifestam de forma mais visível nos sistemas de análise, onde as agregações amplificam os erros subjacentes. Quando os dados de preços de comércio eletrônico extraídos contêm erros de análise que convertem “US$ 29,99” em “2.999” devido a falhas no tratamento do símbolo de moeda, os cálculos de preço médio perdem o sentido.
As uniões de bancos de dados podem falhar sem o seu conhecimento quando os identificadores de produtos extraídos contêm caracteres Unicode invisíveis ou espaços em branco à direita. Um sistema de rastreamento de produtos pode mostrar o mesmo item como entradas separadas, o que aumenta a contagem de estoque e distorce os modelos de previsão de demanda. Essas falhas de normalização estarão presentes em todos os seus processos de ETL e farão com que os relatórios downstream dupliquem a receita.
Falhas no sistema de tomada de decisões
Os sistemas de decisão automatizados criados com base em dados raspados podem fazer escolhas catastroficamente erradas quando a qualidade da entrada diminui. Os aplicativos de monitoramento de preços que dependem de dados de concorrentes extraídos de sites dinâmicos geralmente capturam valores de espaço reservado como “Carregando…” ou mensagens de erro de JavaScript em vez de preços reais. Quando essas cadeias de caracteres não numéricas ignoram as camadas de validação, os algoritmos de preços podem usar valores zero como padrão.
Se estiver trabalhando em um mecanismo de recomendação, ele sofrerá com Conjuntos de dados raspados incompletos em que determinadas categorias de produtos sistematicamente não são capturadas devido a problemas de paginação ou barreiras de autenticação. O viés de recomendação resultante em direção a categorias raspadas com sucesso cria câmaras de eco que reduzem a descoberta de diversos produtos pelo cliente, limitando, em última análise, o crescimento da receita e a satisfação do cliente.
Degradação do desempenho do aplicativo
Os aplicativos que consomem dados extraídos apresentam problemas de desempenho quando os problemas de qualidade dos dados criam operações ineficientes no banco de dados. Os campos de texto extraídos que contêm tags HTML sem escape podem interromper a indexação da pesquisa, causando varreduras de tabelas completas em vez de pesquisas de índices otimizados. A funcionalidade de pesquisa voltada para o usuário deixa de responder quando essas penalidades de desempenho se acumulam em várias consultas simultâneas.
As estratégias de invalidação de cache falham quando os dados extraídos contêm formatação inconsistente que impossibilita a detecção de duplicatas. As mesmas informações de produtos coletadas em momentos diferentes podem aparecer como entradas de cache separadas devido à variação no tratamento de espaços em branco, aumentando o uso da memória e reduzindo as taxas de acerto do cache. Essa poluição do cache força os aplicativos a fazer chamadas repetidas e caras ao banco de dados, prejudicando a capacidade de resposta geral do sistema.
Problemas de integração de dados
Os dados raspados raramente chegam de forma isolada. Em geral, eles se unem a bancos de dados internos e APIs de terceiros para criar Conjuntos de dados abrangentes. As incompatibilidades de esquema tornam-se comuns quando as estruturas de campo raspadas mudam inesperadamente devido à reformulação do site. Um sistema de catálogo de produtos pode perder especificações essenciais quando a lógica de raspagem não se adapta aos novos layouts de HTML, deixando os aplicativos downstream com informações incompletas sobre o produto que afetam os resultados de pesquisa e as decisões de compra do cliente.
As inconsistências de atualização de dados criam uma situação em que os dados extraídos refletem períodos de tempo diferentes dos dados internos relacionados. Os aplicativos financeiros que combinam dados de mercado extraídos com registros de transações internas podem produzir avaliações de portfólio incorretas quando os atrasos na extração fazem com que as informações de preço fiquem atrasadas em relação aos registros de data e hora das transações. Essas inconsistências temporais dificultam o estabelecimento de caminhos de auditoria precisos.
Diferentes maneiras de melhorar a precisão dos dados
A precisão dos dados no Scraping de dados depende da implementação de várias técnicas que trabalham em conjunto para abordar diferentes pontos de falha no pipeline de extração.
Lidar com conteúdo dinâmico com navegadores sem cabeça
Os raspadores tradicionais baseados em HTTP perdem partes substanciais dos dados porque muitos sites dependem muito do JavaScript para renderizar o conteúdo após o carregamento inicial da página. Navegadores sem cabeça, como o Puppeteer ou o Playwright, executam JavaScript exatamente como os navegadores comuns, garantindo que você capture todo o conteúdo gerado dinamicamente.
O Puppeteer oferece controle sobre a renderização de páginas por meio da integração com o Chrome DevTools Protocol. Você pode aguardar a conclusão de solicitações de rede específicas, monitorar alterações no DOM e até mesmo interceptar chamadas de API que preenchem o conteúdo. Essa abordagem é particularmente valiosa para aplicativos de página única que carregam dados por meio de solicitações AJAX após a renderização inicial.
Ao usar navegadores headless, desative imagens, CSS e plug-ins desnecessários para reduzir o consumo de memória e melhorar o tempo de carregamento. Configure o tamanho da janela de visualização adequadamente, pois alguns sites renderizam conteúdo diferente com base nas dimensões da tela.
Adapte-se rapidamente às mudanças na estrutura do site
As estruturas dos sites mudam com frequência e prejudicam os Scrapers que dependem de seletores CSS fixos ou expressões XPath. A criação de scrapers adaptáveis requer a implementação de estratégias de fallback e sistemas de monitoramento que detectem mudanças estruturais antes que elas causem perda de dados.
Crie hierarquias de seletores que tentem várias abordagens para localizar o mesmo elemento de dados. Comece com o seletor mais específico e volte progressivamente para os mais gerais.
classe AdaptiveSelector:
def __init__(self, selectors_list, element_name):
self.selectors = selectors_list
self.element_name = element_name
self.successful_index = 0
def extract_data(self, soup):
for i, selector in enumerate(self.selectors[self.successful_index:], self.successful_index):
elements = soup.select(selector)
if elements:
self.successful_index = i
return [elem.get_text(strip=True) for elem in elements]
raise ValueError(f "Nenhum seletor encontrado para {self.element_name}")
# Uso
price_selector = AdaptiveSelector([
'div.price-current .price-value', # Mais específico
'.price-current', # Intermediário
'[class*="price"]' # Falha ampla
], 'product_price')Implemente sistemas de detecção de alterações que comparem as impressões digitais da estrutura da página ao longo do tempo.
Validar e limpar dados extraídos
Os dados raspados brutos contêm muitas inconsistências que afetam a precisão de seus dados. Para corrigir isso, você precisa implementar um pipeline abrangente de validação e limpeza. Isso transforma dados confusos da Web em Conjuntos de dados confiáveis, adequados para o processamento downstream.
A validação de dados começa com a verificação do tipo e do formato. Os preços devem corresponder aos padrões de moeda, as datas devem ser analisadas corretamente e os campos numéricos devem conter números válidos.
import re
from datetime import datetime
from typing import Optional, Dict, Any
class DataValidator:
def __init__(self):
self.patterns = {
'price': re.compile(r'[$€£¥]?[d,]+.?d*'),
'email': re.compile(r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'),
'phone': re.compile(r'^+?[ds-()]{10,}$'),
'date': re.compile(r'd{4}-d{2}-d{2}|d{2}/d{2}/d{4}')
}
def validate_record(self, record: Dict[str, Any]) -> Dict[str, Any]:
cleaned_record = {}
for field, value in record.items():
if value is None or str(value).strip() == '':
cleaned_record[field] = None
continuar
cleaned_value = self._clean_field(field, str(value))
if self._is_valid_field(field, cleaned_value):
cleaned_record[field] = cleaned_value
else:
cleaned_record[field] = None
return cleaned_record
def _clean_field(self, field_name: str, value: str) -> str:
# Remove os espaços em branco extras
cleaned = re.sub(r's+', ' ', value.strip())
# lógica de limpeza
return cleaned
def _is_valid_field(self, field_name: str, value: str) -> bool:
if 'price' in field_name.lower():
return bool(self.patterns['price'].match(value))
elif 'email' in field_name.lower():
return bool(self.patterns['email'].match(value))
# Adicionar mais validações específicas de campo
return len(value) > 0Implemente a detecção de outlier para identificar Pontos de dados suspeitos que possam indicar erros de raspagem. Métodos estatísticos como a análise de intervalo interquartil ajudam a sinalizar preços, quantidades ou outros valores numéricos que estão fora dos intervalos esperados. Algoritmos de similaridade de strings podem detectar campos de texto corrompidos ou erros de extração.
Implemente tratamento de erros e novas tentativas
Falhas de rede, erros de servidor e exceções de análise são inevitáveis em operações de Scraping de dados. A criação de um web scraper com tratamento abrangente de erros evita que falhas individuais se transformem em colapsos completos do Scraper, enquanto os mecanismos de nova tentativa lidam automaticamente com problemas temporários.
O backoff exponencial fornece uma estratégia eficaz para lidar com a limitação de taxa e a sobrecarga temporária do servidor. Comece com atrasos curtos e aumente progressivamente os tempos de espera para as tentativas de nova tentativa subsequentes. Essa abordagem dá aos servidores tempo para se recuperarem e, ao mesmo tempo, evita padrões de novas tentativas agressivas que podem acionar medidas antibot.
importar asyncio
import aiohttp
from typing import Optional, Callable
class ResilientScraper:
def __init__(self, max_attempts=3, base_delay=1.0):
self.max_attempts = max_attempts
self.base_delay = base_delay
self.session = None
async def fetch_with_retry(self, url: str, parse_func: Callable) -> Optional[Any]:
for attempt in range(self.max_attempts):
try:
if attempt > 0:
delay = self.base_delay * (2 ** attempt)
await asyncio.sleep(delay)
async com self.session.get(url) as response:
if response.status == 200:
content = await response.text()
return parse_func(content)
elif response.status == 429: # Taxa limitada
continue
elif response.status >= 500: # Erro do servidor
continue
else: # Erro do cliente
retornar Nenhum
exceto (aiohttp.ClientError, asyncio.TimeoutError):
continue
return NoneOs padrões de disjuntor impedem que os Scrapers sobrecarreguem os serviços com falhas. Acompanhe as taxas de erro de domínios individuais e desative temporariamente as solicitações quando as taxas de falha excederem os limites aceitáveis. Essa abordagem protege seu scraper e o site de destino contra cargas desnecessárias durante interrupções.
Use Proxies rotativos e agentes de usuário
O bloqueio de IP representa um dos obstáculos mais comuns em um grande Scraping de dados. Proxies rotativos e agentes de usuário distribuem as solicitações entre diferentes fontes aparentes, tornando a detecção significativamente mais difícil e mantendo a velocidade de raspagem.
O Proxy rotativo requer um gerenciamento cuidadoso dos pools de conexão e da distribuição de solicitações. Evite usar o mesmo Proxy para solicitações consecutivas ao mesmo domínio, pois esse padrão continua sendo detectável. Em vez disso, implemente algoritmos de round-robin ou de seleção aleatória que garantam uma distribuição uniforme em seu Pool de proxies.
importar randômico
from typing import List, Dict, Optional
classe ProxyRotator:
def __init__(self, proxies: List[str], user_agents: List[str]):
self.proxies = proxies
self.user_agents = user_agents
self.failed_proxies = set()
def get_next_proxy_and_headers(self) -> tuple[Optional[str], Dict[str, str]]:
available_proxies = [p for p in self.proxies if p not in self.failed_proxies]
if not available_proxies:
self.failed_proxies.clear()
available_proxies = self.proxies
proxy = random.choice(available_proxies)
user_agent = random.choice(self.user_agents)
headers = {
'User-Agent': user_agent,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Connection': 'keep-alive'
}
return proxy, headers
def mark_proxy_failed(self, proxy: str):
self.failed_proxies.add(proxy)A rotação do agente de usuário deve imitar as distribuições realistas de navegadores encontradas nos dados de análise da Web. Ponderar a lista de agentes de usuário de acordo com as estatísticas reais de participação no mercado, garantindo que as variantes do Chrome apareçam com mais frequência do que os navegadores menos comuns. Inclua agentes de usuário móveis para sites que fornecem conteúdo diferente para dispositivos móveis.
Gerenciamento de proxy orientado por IA
Ao extrair dados, as proibições de IP tornam-se um desafio que pode interromper totalmente suas operações. Considere a possibilidade de raspar um site de viagens para obter preços de voos. Os sites podem detectar facilmente várias solicitações provenientes do mesmo endereço IP em alta velocidade, o que facilita a sinalização e o banimento do seu Scraper.
A solução está no gerenciamento de proxy orientado por IA em vez da rotação básica de proxy. Essa abordagem usa um pool de proxies para distribuir solicitações entre diferentes endereços IP, mascarando efetivamente sua identidade. Serviços profissionais como a Bright Data oferecem acesso a mais de 150 milhões de IPs residenciaisis de aproximadamente 195 países.
O gerenciamento inteligente de proxy oferece vários benefícios importantes. Ele garante o anonimato para que os sites não possam rastrear atividades suspeitas diretamente até você e implementa a limitação dinâmica da taxa que ajusta a frequência das solicitações para imitar o comportamento humano.
Essas estratégias trabalham juntas para criar Scrapers que mantêm a precisão dos dados em vários ambientes da Web. Navegadores sem cabeça capturam o conteúdo completo, seletores adaptativos lidam com alterações estruturais, pipelines de validação limpam os dados extraídos, o tratamento abrangente de erros evita falhas e o gerenciamento de proxy orientado por IA otimiza a entrega.
Ferramentas e práticas recomendadas para raspagem confiável
A seleção da ferramenta de raspagem correta depende da complexidade de seus sites-alvo e de seus requisitos de escalabilidade. Esta seção examina quatro categorias de ferramentas que abordam diferentes desafios técnicos no Scraping de dados.
Bibliotecas Python para conteúdo estático
A Beautiful Soup é excelente na análise de documentos HTML em que o conteúdo é carregado diretamente na resposta inicial do servidor. A biblioteca lida com HTML malformado de forma elegante e fornece métodos de navegação intuitivos para extrair dados de elementos aninhados. As solicitações combinam naturalmente com a Beautiful Soup para lidar com as propriedades do site que muitos sites exigem para o acesso adequado aos dados.
O Scrapy opera como uma estrutura completa, e não como uma simples biblioteca. Ele gerencia solicitações simultâneas por meio de seu agendador integrado e lida com cenários complexos de rastreamento por meio de sua arquitetura de pipeline. É possível usar seu sistema de middleware para processamento de solicitações personalizadas, rotação de agente de usuário e mecanismos de repetição automática.
Automação do navegador para conteúdo dinâmico
O Selenium controla navegadores reais por meio de protocolos WebDriver, o que o torna adequado para sites que dependem muito da execução de JavaScript para renderização de conteúdo. A ferramenta lida com interações do usuário, como envio de formulários, cliques em botões e paginação de rolagem que acionam o carregamento de conteúdo adicional. Você precisaria inserir explicitamente suas condições de espera para pausar a execução até que elementos específicos se tornem disponíveis ou atendam a determinados critérios.
O Playwright oferece recursos semelhantes de automação de navegador com características de desempenho aprimoradas e manipulação integrada de recursos modernos da Web. A funcionalidade de espera automática da ferramenta elimina a maioria dos problemas de tempo ao aguardar automaticamente que os elementos se tornem acionáveis antes de prosseguir com as interações. Os recursos de interceptação de rede do Playwright permitem monitorar as chamadas de API que preenchem o conteúdo da página, muitas vezes revelando métodos de acesso a dados mais eficientes do que a análise do HTML renderizado.
Soluções para navegadores sem cabeça
O Puppeteer visa especificamente os navegadores baseados no Chromium e oferece um bom controle sobre o comportamento do navegador por meio da integração com o DevTools Protocol. A ferramenta é excelente na geração de capturas de tela, PDFs e métricas de desempenho juntamente com a extração de dados. Ela tem interceptação de solicitações que você pode usar para bloquear recursos desnecessários, como imagens e folhas de estilo, e melhorar a velocidade de raspagem para extração focada em conteúdo.
O Playwright é um recurso entre navegadores, o que o torna valioso para a raspagem em diferentes mecanismos de renderização. O recurso codegen da ferramenta registra as interações do usuário e gera os scripts de automação correspondentes.
Plataformas de gerenciamento de proxy corporativo
A Bright Data oferece rotação de IPs residencialis em locais globais com recursos de persistência de sessão que mantêm identidades consistentes em sessões de raspagem em várias páginas. O serviço Web Unlocker lida automaticamente com medidas antibot comuns, incluindo a Resolução de CAPTCHA e a randomização de impressões digitais do navegador. Seu Navegador de scraping combina a rotação de proxy com instâncias de navegador pré-configuradas otimizadas para evitar a detecção.
Gerenciamento de solicitações e limitação de taxa
A implementação de estratégias de backoff evita a sobrecarga dos servidores de destino e, ao mesmo tempo, lida com falhas temporárias de forma elegante. Por exemplo, o urllib3, um dos principais clientes HTTP Python, oferece mecanismos de repetição com atrasos configuráveis entre as tentativas. A limitação de taxa personalizada usando algoritmos de token bucket garante que o espaçamento das solicitações corresponda à capacidade do servidor em vez de aplicar atrasos fixos que podem ser muito agressivos ou insuficientes.
O gerenciamento de sessões pode se tornar importante para sites que exigem autenticação ou mantêm o estado entre as solicitações. O armazenamento persistente de cookies e o gerenciamento de cabeçalhos garantem que os scrapers mantenham o acesso ao conteúdo protegido durante sessões de scraping prolongadas. O pooling de conexões reduz a sobrecarga ao reutilizar conexões de rede estabelecidas em várias solicitações para o mesmo domínio.
Validação de dados
Bibliotecas de validação de esquema, como a Pydantic, reforçam a consistência da estrutura de dados e capturam erros de análise antes que eles se propaguem pelos pipelines de processamento. A implementação da validação de soma de verificação para conteúdo raspado ajuda a detectar quando os sites modificam sua estrutura ou formatação de conteúdo, acionando alertas para manutenção do Scraper.
A escolha entre essas ferramentas depende de seus requisitos técnicos específicos. Por exemplo, os scrapers de conteúdo estático oferecem desempenho máximo para tarefas simples de extração, enquanto as ferramentas de automação do navegador lidam com cenários interativos complexos ao custo de um maior consumo de recursos.
Conclusão
Neste artigo, aprendemos sobre os desafios que os desenvolvedores enfrentam ao extrair dados de sites e, em seguida, identificamos os resultados de uma extração ruim. Por fim, aprendemos sobre as ferramentas e estratégias que podem ajudá-lo a resolver esses problemas.






