
A filtragem de dados costumava ser um simples truque de banco de dados. Hoje, é um recurso comercial essencial que potencializa a IA, mantém você em conformidade e ajuda a superar os concorrentes.
Neste guia, você aprenderá:
- O que é filtragem de dados.
- Por que a filtragem de dados é importante.
- Por que você deve usar a filtragem de dados automatizada.
- Como o Deep Lookup facilita a filtragem de dados.
Vamos nos aprofundar!
O que é filtragem de dados?
A filtragem de dados é simplesmente mostrar a si mesmo somente os dados que realmente lhe interessam. Pense nisso como se estivesse usando um filtro de café que lhe dá apenas as coisas boas que você quer, não a borra. A mecânica é simples: você define regras (por exemplo, mostrar-me clientes na Califórnia) e o sistema exclui tudo o que não corresponde às regras.
Todos nós usamos a filtragem de dados em nossa vida cotidiana. Quando você pesquisa “fones de ouvido sem fio abaixo de US$ 100” na Amazon, você está filtrando. Quando sua equipe de marketing obtém uma lista de clientes que não compram há seis meses, ela está filtrando. Quando você classifica sua caixa de entrada por remetente, você está filtrando.
Embora o conceito seja simples, usar a filtragem de dados em escala em uma organização requer um sólido entendimento dos dados e das ferramentas certas. Hoje em dia, a filtragem de dados é importante para o sucesso de todas as organizações, e nós lhe diremos exatamente por quê.
Por que a filtragem de dados é importante
A filtragem é uma necessidade para dar sentido ao big data.
Atualmente, a maioria das empresas está sentada em minas de ouro de dados que nunca usarão. Não porque os dados não sejam valiosos, mas porque elas não conseguem vasculhá-los com eficiência para encontrar o que importa.
Pense da seguinte forma. Sua empresa provavelmente coleta centenas de pontos de dados sobre cada cliente. Mas quando chega a hora da crise e você precisa identificar seus segmentos mais valiosos, você realmente vai classificar manualmente 50.000 registros de clientes? É claro que não. Você pegará uma amostra, fará algumas suposições e torcerá pelo melhor.
Esse é exatamente o problema que a filtragem resolve. Veja por que a filtragem eficaz de dados é essencial:
- Eliminar o ruído: seus analistas param de perder tempo com dados irrelevantes e se concentram nos padrões que realmente mudam a situação.
- Acelerar tudo:conjuntos de dadosmenoressignificam consultas mais rápidas, insights mais rápidos e decisões que acontecem em dias em vez de semanas.
- Descubra padrões ocultos: Quando você remove a desordem, as tendências que eram invisíveis de repente se tornam óbvias.
- Economize dinheiro de fato: Menos dados para armazenar e processar significa menos custos de infraestrutura. Além disso, o tempo da sua equipe se torna infinitamente mais valioso.
- Mantenha-se em conformidade: Filtre automaticamente as informações confidenciais e você dormirá melhor sabendo que não está expondo acidentalmente os dados dos clientes.
Em resumo, a filtragem de dados é a ponte entre os dados brutos e a tomada de decisões informadas. A seguir, veremos como abordar a filtragem na prática e algumas técnicas padrão para uma filtragem eficaz.
Passo a passo da filtragem manual de dados usando dados do Amazon Marketplace
Deixe-me mostrar o que a maioria das equipes faz quando precisa filtrar dados. Usaremos um conjunto de dados real de produtos da Amazon (cortesia dos conjuntos de dados da Bright Data) para mostrar exatamente como isso funciona. Esse conjunto de dados inclui vários campos, como títulos de produtos, marcas, preços, classificações e muito mais, de diferentes categorias e regiões.
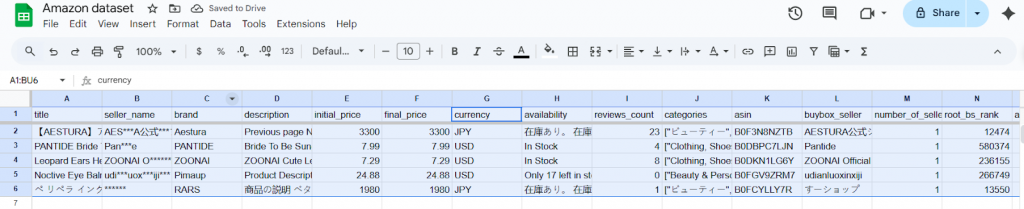
Diante de uma lista tão ampla, um profissional de dados precisaria isolar apenas os produtos relevantes para uma análise específica a fim de se concentrar em informações úteis. Para isso, ele precisaria usar as seguintes etapas:
- Comece filtrando todos os itens que não atendem aos critérios iniciais de interesse. Na prática, isso geralmente significa excluir produtos fora de sua categoria ou escopo de destino. Por exemplo, se estivermos interessados apenas em produtos de beleza, removeremos as entradas que pertencem a outras categorias.
- Usando uma ferramenta como o Planilhas Google ou o Excel, navegue até a guia Dados e clique em criar um filtro.

- Um filtro será exibido em cada coluna e você poderá usá-lo para personalizar o conjunto de dados o quanto quiser.
- Por exemplo, se você quiser filtrar os produtos por moeda e ter apenas produtos com preços em dólares americanos, vá até a coluna de preços e aplique esse filtro.

- Quando você desmarcar o JPY, o conjunto de dados mostrará somente produtos com preços em dólares americanos.
Na primeira vez que você faz isso, a sensação é muito boa. Você está no controle, pode ver exatamente o que está acontecendo e percebe padrões interessantes à medida que avança. “Veja só, os produtos ecologicamente corretos parecem ter classificações mais altas!”
Mas o que acontece na prática é o seguinte:
- Semana 1: Isso é ótimo! Adoro ter esse controle.
- Semana 4: Ok, isso está ficando repetitivo, mas ainda estou encontrando bons insights.
- Semana 12: Passei minha manhã inteira aplicando os mesmos filtros que usei ontem.
- Semana 24: Acho que esqueci de limpar o filtro anterior… será que esses números estão certos?
Muitos analistas brilhantes se esgotam fazendo exatamente isso. Não porque o trabalho não seja valioso, mas porque estão gastando 80% do tempo em tarefas mecânicas em vez de fazer análises reais.
Agora que você já sabe como filtrar dados manualmente, vamos analisar os prós e os contras de usar esse método.
Prós da filtragem manual
- A filtragem manual oferece feedback visual imediato, permitindo que você veja os resultados instantaneamente e ajuste os filtros de forma iterativa. Você pode identificar padrões inesperados ou problemas de qualidade de dados enquanto trabalha.
- Você também obtém a integração do contexto comercial que permite decisões diferenciadas. Ao filtrar os campos “customers_say” ou “top_review”, o julgamento humano identifica sentimentos e preocupações que os sistemas automatizados podem não perceber.
- Ele permite uma exploração flexível que dá suporte à análise orientada por descobertas. Você pode notar que os produtos com ‘climate_pledge_friendly’ = TRUE têm classificações mais altas, o que leva a novos insights estratégicos.
- Há uma baixa barreira de entrada, o que significa que qualquer membro da equipe familiarizado com planilhas pode realizar análises sem treinamento técnico ou ferramentas especializadas.
- É possível ter visibilidade da trilha de auditoria por meio de visualizações de filtro, e os critérios documentados garantem a reprodutibilidade da análise e a colaboração da equipe.
Contras da filtragem manual
- As limitações de escala tornam-se aparentes rapidamente. A filtragem de mais de 10.000 linhas no Google Sheets causa uma degradação perceptível no desempenho. Com milhões de produtos da Amazon, você está vendo apenas uma pequena amostra.
- A intensidade do tempo aumenta com a complexidade. A aplicação do processo de filtragem em oito etapas acima leva de 15 a 20 minutos para uma análise. Repetir isso diariamente ou em várias categorias torna-se insustentável.
- A probabilidade de erro humano aumenta com a repetição. A seleção acidental de operadores errados (maior que vs. menor que) ou o esquecimento de limpar filtros anteriores leva a análises incorretas.
- A inconsistência entre os usuários cria insights conflitantes. Dois analistas podem interpretar “vendedor de alta qualidade” de forma diferente, filtrando ‘nome_do_vendedor’ ou ‘classificação’ com limites diferentes.
- A reprodutibilidade limitada impossibilita a automação. Cada sessão de filtragem manual requer intervenção humana, impedindo relatórios programados ou painéis de controle em tempo real.
- O custo de oportunidade é significativo. Enquanto os analistas passam horas filtrando dados, os concorrentes que usam soluções automatizadas já agem com base nos insights. O tempo gasto com a filtragem mecânica poderia ser investido em análise estratégica e tomada de decisões.
Em geral, a filtragem manual de dados oferece um alto grau de controle e clareza para o analista, o que a torna adequada para análises exploratórias ou conjuntos de dados de pequena escala em que a compreensão das nuances é importante. Entretanto, sua ineficiência e os riscos de erro em dados de grande escala a tornam menos adequada para big data ou fluxos de trabalho de rotina.
Nesses casos, a transição para métodos ou ferramentas de filtragem automatizada é melhor, e vamos lhe dizer exatamente por quê.
Por que a filtragem automatizada de dados é mais inteligente, mais rápida e escalonável
Quando falamos de filtragem automatizada, não se trata apenas de velocidade. A automação não faz apenas o que você estava fazendo antes com mais rapidez, ela faz coisas que você literalmente não conseguiria fazer manualmente.
Lembra-se daquele conjunto de dados da Amazon com 73 campos diferentes? Manualmente, você poderia explorar de 5 a 10 combinações desses campos. Com a automação, você pode testar milhares de combinações em paralelo. Você pode descobrir que os produtos com emblemas favoráveis ao clima realmente têm uma retenção de clientes 23% melhor, mas somente em determinadas faixas de preço e somente quando vendidos por tipos específicos de vendedores.
Esses não são insights que você encontra por acaso. São insights que surgem quando você pode explorar sistematicamente todos os ângulos, e só é possível encontrá-los por meio da filtragem automatizada de dados.
A filtragem automatizada muda fundamentalmente o que é possível para um analista ou uma empresa, processando milhões de registros em segundos e aplicando centenas de combinações de filtros simultaneamente. Isso é feito codificando seus critérios como regras executáveis por máquina e executando-as em escala continuamente.
Em vez de clicar nas colunas, você pode definir filtros declarativos, aproximá-los o máximo possível da fonte e obter dados rápidos e reutilizáveis. Com a filtragem automatizada de dados, você pode explorar exaustivamente milhares de interações de campo em paralelo, revelando padrões que nunca caberiam no orçamento de exploração limitado de um ser humano e, em seguida, reproduzi-los quantas vezes quiser.
| Dimensão | Manual | Automatizada |
|---|---|---|
| Velocidade/latência | Ritmo humano; minutos a horas por execução | Ritmo de máquina; segundos a minutos em escala |
| Escalabilidade | Limitada pela interface do usuário e pela memória | Escalonamento horizontal (computação distribuída, pushdown) |
| Confiabilidade | Suscetível a erro humano | Determinística, testável, idempotente |
| Frescor | Lote, ad hoc | Programado ou streaming; é possível quase em tempo real |
| Consistência | Varia de acordo com o operador | Lógica com controle de versão; resultados reproduzíveis |
| Custo | Custo de mão de obra oculto; retrabalho | Otimizado para computação; cache e pushdown de predicados |
| Governança | Difícil de auditar | Linhagem, registro, aprovações, controles de acesso |
Uma das melhores ferramentas que você pode usar para filtragem automatizada de dados é o Deep Lookup da Brightdata, sobre o qual falaremos a seguir.
Apresentando o Deep Lookup: Filtrar dados com linguagem simples
O Deep Lookup é a ferramenta de pesquisa com tecnologia de IA da Bright Data que transforma solicitações em inglês simples em conjuntos de dados estruturados e precisos. Com o Deep Lookup, você pode solicitar exatamente o que precisa e recebê-lo de volta como uma tabela que pode ser usada.
Em vez de unir fontes ou escrever consultas complexas, você descreve as entidades que deseja (empresas, produtos, pessoas, notícias, propriedades), os filtros que elas devem atender e as colunas que deseja ver. O Deep Lookup cuida da filtragem, do enriquecimento e da estruturação nos bastidores para fornecer resultados prontos para análise.
Como funciona o Deep Lookup
O Deep Lookup incentiva um formato de prompt de duas linhas, como este:
- Localizar todos os … <entidades e condições>
- Mostrar: <colunas que você deseja>
Por exemplo, um exemplo de Deep Lookup seria parecido com este:
***Encontre todos os produtos de beleza e cuidados pessoais da Amazon com preço ≤ US$ 25 com classificação ≥ 4 e em estoque.***
***Mostrar: nome do produto, marca, preço atual, classificação, número de avaliações, URL do produto***
O Deep Lookup pega essa descrição e:
- Identifica as fontes de dados necessárias
- Aplica seus filtros no nível do banco de dados (não depois de fazer o download de tudo)
- Enriquece os resultados com contexto adicional
- Retorna um conjunto de dados limpo e estruturado que você pode usar imediatamente
Para consultas mais complexas, você pode usar uma abordagem mais estruturada:
FIND ALL: [tipos de entidades]
FILTROS:
- Condição nº 1
- Condição nº 2
MOSTRAR:
- Coluna nº 1 [Enriquecimento ou restrição]
- Coluna #2 [Enriquecimento ou restrição]
A principal diferença é que você está descrevendo a lógica comercial, não a implementação técnica. Você não precisa saber quais endpoints de API acessar, como lidar com a paginação ou onde encontrar dados de preços da concorrência.
Os conjuntos de dados que você recebe do Deep Lookup são selecionados, estruturados e fornecidos como Websets. Os Websets são verificados e totalmente citados, personalizáveis (escolha os campos exatos) e projetados para se manterem atualizados à medida que o Deep Lookup examina novas fontes.
Na prática, o fluxo é o seguinte:
- Faça sua pergunta
- Rastrear e raciocinar
- Obter resultados acionáveis.
Você pode personalizar os Websets por entidade, setor, geografia e campos de dados para corresponder ao seu caso de uso.
Conclusão
A esta altura, você já viu que a filtragem de dados é a forma de transformar informações confusas e esmagadoras em decisões claras. A filtragem manual gera intuição, mas a automação proporciona velocidade, consistência e a capacidade de revelar padrões que ninguém consegue encontrar uma coluna de cada vez.
É exatamente nesse ponto que a Bright Data ajuda. Com o Deep Lookup, você declara seus critérios em inglês simples e recebe um conjunto de dados limpo, estruturado e sempre atualizado que pode ser conectado a painéis, notebooks ou modelos. Em conjunto com os conjuntos de dados da Bright Data (como o conjunto de dados da Amazon neste guia), você passa da ideia ao insight e à produção sem manter pipelines frágeis.
Pronto para ver o que a filtragem automatizada pode fazer por seus dados? Experimente o Deep Lookup com uma conta gratuita da Bright Data. Use as regras de filtragem que você tem aplicado manualmente e veja quais insights você está perdendo.






