

Aumentar a operação de scraping local de 1.000 para 100.000 páginas geralmente significa mais servidores, Proxies e trabalho operacional. Os sites de destino ficam mais difíceis de fazer scraping. Os custos de infraestrutura estão aumentando. As equipes gastam mais tempo consertando Scrapers do que lançando recursos. Em grande escala, o scraping deixa de ser um script e se torna infraestrutura de scraping.
A escolha entre scraping local e em nuvem afeta três coisas: custo, confiabilidade e velocidade de entrega.
TL;DR
- O scraping local é executado em suas máquinas. Você tem controle total, mas precisa realizar manutenção manual.
- O scraping na nuvem é executado em uma infraestrutura remota com autoescala e rotação de IP integrada.
- Escolha a extração local para menos de 1.000 páginas ou dados regulamentados e apenas internos.
- Escolha o scraping na nuvem para mais de 10.000 páginas, sites bloqueados ou monitoramento 24 horas por dia, 7 dias por semana.
- O bloqueio de IP é o principal gargalo, 68% das equipes o citam como seu principal desafio.
- Em grande escala, o cloud scraping pode reduzir os custos totais em até 70%, eliminando a sobrecarga de DevOps.
- A Bright Data oferece mais de 150 milhões de IPs residencialis, 99,9% de tempo de atividade e execução sem manutenção.
O que é scraping local?
Scraping local significa que você é responsável por toda a pilha — código, IPs, navegadores, mas também falhas e tempo de inatividade. Você executa seus scripts de scraping em sua infraestrutura de scraping e gerencia todo o pipeline sozinho.
Não há camada de infraestrutura gerenciada, então, quando algo quebra, você conserta.
Como funciona o scraping local
O scraping local segue um loop de execução simples. Seu script envia solicitações, recebe respostas e extrai dados de HTML ou páginas renderizadas.
As solicitações se originam do seu próprio endereço IP ou de Proxies que você configura. Quando os sites bloqueiam o tráfego, você precisa alternar os IPs e tentar novamente as solicitações manualmente.
Um cliente HTTP simples é suficiente para páginas estáticas, mas para sites com muito JavaScript, você precisa executar navegadores headless localmente para renderizar o conteúdo antes de extraí-lo.
Além de tudo isso, com o scraping local, você normalmente precisa lidar manualmente com CAPTCHAs e outras medidas antibot.
Isso funciona em pequena escala, mas à medida que o volume cresce, o script simples com o qual você começou rapidamente se torna um sistema de infraestrutura complexo que você deve operar e manter.
Vantagens do scraping local
Como o scraping local mantém a execução inteiramente dentro do seu ambiente, ele é ótimo se você precisa de:
- Controle total da execução: você gerencia o tempo de solicitação, cabeçalhos, lógica de Parsing e armazenamento.
- Sem dependência de terceiros: o scraping é executado sem infraestrutura ou provedores externos.
- Proteção de dados confidenciais: os dados permanecem dentro da sua rede.
- Forte valor de aprendizagem: você trabalha diretamente com cabeçalhos, cookies, limites de taxa e falhas.
- Baixo custo de configuração para trabalhos pequenos: um script e um laptop são suficientes para o scraping de baixo volume de sites desprotegidos.
Limitações do scraping local
O scraping local se torna mais difícil de manter à medida que os requisitos de volume e confiabilidade aumentam:
- Baixa escalabilidade: volumes maiores exigem a compra de servidores e largura de banda adicionais.
- Bloqueio de IP: você deve obter, alternar e substituir proxies à medida que os sites bloqueiam o tráfego.
- Interrupções de CAPTCHA: a resolução manual interrompe a automação; os solucionadores automatizados aumentam o custo e a latência.
- Execução pesada do JavaScript no navegador: sites com muito JavaScript exigem navegadores locais que consomem CPU e memória significativas.
- Manutenção contínua: as alterações no site e as atualizações de detecção exigem correções frequentes no código e reimplantação.
- Confiabilidade frágil: falhas interrompem a coleta de dados até que você intervenha.
Exemplo: Scraping local em Python
É assim que o scraping local com Python se parece em pequena escala:
import requests
from bs4 import BeautifulSoup
def scrape_products(url):
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
return [
{
"name": item.find("h3").text.strip(),
"price": item.find("span", class_="price").text.strip(),
}
para item em soup.select(".product-card")
]
produtos = scrape_products("https://example.com/products")Este script é executado localmente e usa seu endereço IP real. Ele processa algumas centenas de páginas sem problemas em sites desprotegidos.
Mas observe o que está faltando: não há rotação de Proxy, tratamento de CAPTCHA, lógica de repetição ou monitoramento. Adicionar esses recursos pode facilmente sobrecarregar o script e dificultar sua execução e manutenção.
O que é cloud scraping?
O cloud scraping transfere a execução para fora do seu aplicativo. Você envia solicitações para a API de um provedor e recebe os dados extraídos em resposta. O provedor lida com a operação da rede de Proxy e toda a Infraestrutura de scraping necessária.
Plataformas como a Bright Data operam essa infraestrutura em escala de produção.
Como funciona o cloud scraping
O cloud scraping segue um modelo de solicitação-execução-resposta:
- Você envia uma solicitação de scraping por meio da API de um provedor.
- O provedor encaminha a solicitação por meio de sua rede Proxy, em infraestrutura remota, não em suas máquinas.
- Quando um site requer JavaScript, a solicitação é executada em um navegador gerenciado. A página renderizada é processada antes da extração de dados.
- Solicitações com falha acionam novas tentativas com base na lógica definida pelo provedor.
- Os desafios CAPTCHA são detectados e resolvidos dentro da camada de execução.
- Você recebe os dados extraídos como resposta.
Aqui está uma visão geral simplificada de como funciona a extração de dados na nuvem: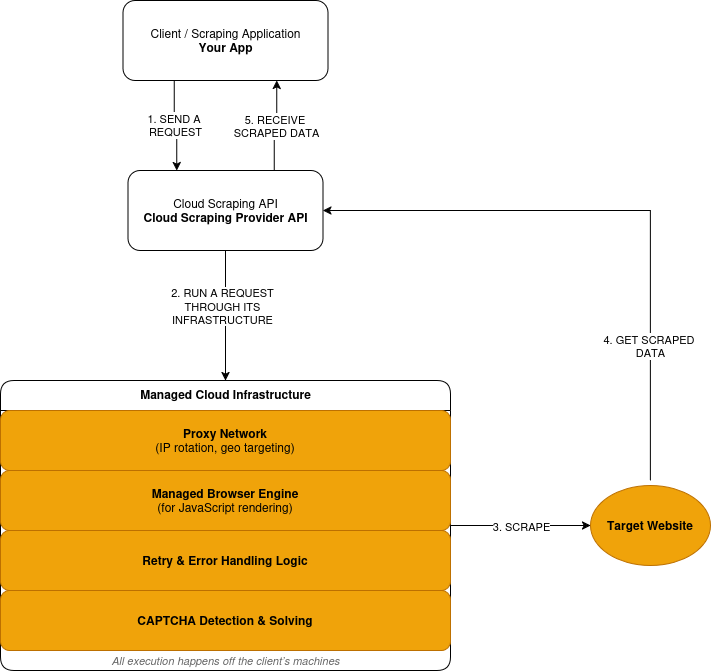
Vantagens do cloud scraping
O cloud scraping favorece a escala, a confiabilidade e a redução da propriedade operacional:
- Execução gerenciada: as solicitações são executadas em uma infraestrutura operada pelo provedor.
- Escalabilidade integrada: o volume aumenta sem que você precise adquirir novos servidores.
- Tratamento anti-bot integrado: a rotação de IP e as tentativas ocorrem automaticamente.
- Infraestrutura do navegador incluída: o provedor de scraping lida com a renderização de JavaScript.
- Escopo de manutenção reduzido: as alterações no site não exigem mais reimplantação constante.
- Custos baseados no uso: preços baseados no volume de solicitações.
Vantagens e desvantagens do scraping na nuvem
O Cloud Scraping reduz a responsabilidade operacional, mas introduz dependências externas. Parte do controle sai dos limites da sua aplicação.
- Controle de baixo nível reduzido: o tempo, a escolha do IP e as tentativas seguem a lógica do provedor.
- Dependência de terceiros: a disponibilidade e a execução ficam fora do seu sistema.
- Os custos variam de acordo com o uso: um volume alto aumenta os gastos.
- Depuração externa: falhas exigem visibilidade e suporte do provedor.
- Restrições de conformidade: alguns dados não podem sair de ambientes controlados.
Exemplo: Scraping de alto volume com o Bright Data Web Unlocker
Esta é a mesma tarefa de scraping executada por meio de uma camada de execução baseada em nuvem.
import requests
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer API_KEY',
}
payload = {
'zone': 'web_unlocker1',
'url': 'https://example.com/products',
'format': 'json'
}
response = requests.post('https://api.brightdata.com/request', json=payload, headers=headers)
print(response.json())À primeira vista, isso parece semelhante ao exemplo de scraping local. Ainda é uma única solicitação HTTP. A diferença está onde a solicitação é executada.
Com a API Bright Data Web Unlocker, a solicitação é executada em uma infraestrutura gerenciada. A rotação de IP, a detecção de bloqueios e as tentativas de repetição ocorrem fora do seu aplicativo.
Raspagem na nuvem x raspagem local: comparação direta
Veja como o scraping local e o scraping na nuvem se comparam em relação aos fatores que realmente afetam seu projeto.
| Fator | Scraping local | Cloud Scraping | Vantagem da Bright Data |
|---|---|---|---|
| Infraestrutura | Configuração DIY | Totalmente gerenciado | Rede global em 195 países |
| Escalabilidade | Limitada | Autoescalável para bilhões/mês | Bilhões de solicitações/mês |
| Bloqueio de IP | Alto risco | Rotação automática | Mais de 150 milhões de IPs residencialis |
| Manutenção | Manual | Gerenciada pelo provedor | Monitoramento 24 horas por dia, 7 dias por semana |
| Modelo de custo | Fixo + oculto | Pagamento conforme o uso | Redução de custos de até 70% |
| Anti-bot | Faça você mesmo | Integrado | 99,9% de sucesso do CAPTCHA |
| Conformidade | Faça você mesmo | Varia | SOC2, GDPR, CCPA |
Discriminação de custos: raspagem local vs. na nuvem
O scraping local parece barato até você contabilizar tudo o que é necessário para mantê-lo funcionando. O maior custo aqui não são os servidores, mas os engenheiros que mantêm o scraping em vez de enviar recursos.
O scraping na nuvem transfere esses custos para um preço por solicitação.
Componentes do custo do scraping local
O scraping local tem custos fixos que se acumulam ao longo do tempo.
- Servidores: máquinas virtuais, largura de banda, armazenamento.
- Proxies: assinaturas de IP residenciais ou móveis.
- Resolução de CAPTCHA: serviços de resolução de terceiros.
- Manutenção: tempo de engenharia para correções e atualizações.
- Tempo de inatividade: dados perdidos durante falhas.
Esses custos existem independentemente de você fazer scraping ou não.
Componentes do custo do scraping na nuvem
O scraping na nuvem usa preços variáveis vinculados ao uso.
- Solicitações: Preços por solicitação ou por página.
- Renderização: custo mais alto para execução de JavaScript.
- Transferência de dados: cobranças baseadas na largura de banda.
Infraestrutura, Proxies e manutenção estão todos incluídos.
Comparação de custos
| Fator de custo | Raspagem local | Scraping na nuvem | Bright Data |
|---|---|---|---|
| Capacidade do servidor | Custo mensal fixo | Incluído | Incluído |
| Infraestrutura de Proxy | Assinatura separada | Incluído | Pool de IPs com mais de 150 milhões |
| Resolução de CAPTCHA | Serviço separado | Incluído | Incluído |
| Esforço de manutenção | Tempo de engenharia contínuo | Gerenciado pelo provedor | Manutenção zero |
| Impacto do tempo de inatividade | Absorvido pela sua equipe | Reduzido pelo provedor | 99,9% de tempo de atividade SLA |
Exemplo de custo real
Considere uma carga de trabalho que extrai 500.000 páginas por mês de sites protegidos.
Configuração local:
- Servidores e largura de banda: US$ 300/mês
- Proxies residenciais: US$ 1.250/mês
- Resolução de CAPTCHA: US$ 150/mês
- Manutenção de engenharia: US$ 3.000/mês
- Total: US$ 4.700/mês
Configuração da nuvem:
- Solicitações com renderização: US$ 1.500/mês
- Transferência de dados: US$ 50/mês
- Total: US$ 1.550/mês
A abordagem em nuvem reduz o custo mensal em cerca de 70% nessa escala.
O ponto de equilíbrio
- Abaixo de 5.000 páginas/mês: o local geralmente ganha
- Entre 5.000 e 10.000 páginas: os custos convergem
- Acima de 10.000 páginas: a nuvem normalmente custa menos
Acima desse ponto, os custos locais crescem linearmente. Os custos da nuvem variam de forma previsível com o uso.
Quando usar a extração local
O scraping local é a escolha certa quando todas as seguintes condições são verdadeiras:
- Você faz scraping em menos de 1.000 páginas por execução
- Os sites de destino têm proteção mínima contra bots
- Os dados não podem sair do seu ambiente
- Você aceita a manutenção manual
- A raspagem não é crítica para os negócios
Fora dessas condições, os custos e os riscos aumentam rapidamente.
Quando usar o scraping na nuvem
O scraping na nuvem é adequado quando qualquer uma das seguintes condições se aplica:
- O volume excede 10.000 páginas por mês
- Os sites implementam proteção agressiva contra bots
- É necessária a renderização JavaScript
- Os dados devem ser atualizados continuamente
- A confiabilidade é mais importante do que o controle de execução
Nesse ponto, a propriedade da infraestrutura se torna um passivo.
Como a Bright Data simplifica a extração de dados na nuvem
A Bright Data define onde o scraping é executado e quais camadas você não opera mais. Ela lida com a infraestrutura de scraping que torna o scraping caro para executar e manter:
- Acesso à rede: roteamento de solicitações por meio de infraestrutura de Proxy gerenciada
- Execução do navegador: navegadores remotos para sites com muito JavaScript.
- Mitigação anti-bot: rotação de IP, detecção de bloqueios e novas tentativas.
- Tratamento de falhas: controle de execução e lógica de repetição.
- Manutenção: atualizações contínuas à medida que os sites e as defesas mudam.
- Controle de sessão: mantenha sessões fixas entre solicitações.
- Precisão geográfica: país, cidade, operadora ou ASN de destino.
- Gerenciamento de impressões digitais: reduza a detecção por meio de impressões digitais no nível do navegador.
- Controle de tráfego: reduza, aumente ou distribua a carga com segurança.
Caminhos e ferramentas de execução
A Bright Data expõe essa infraestrutura por meio de ferramentas distintas, dependendo de suas necessidades.
API do navegador de scraping
Use o Navegador de scraping quando os sites exigirem renderização JavaScript ou interação semelhante à do usuário. Sua lógica Selenium ou Playwright existente é executada em navegadores hospedados pela Bright Data, em vez de instâncias locais.
A Bright Data substitui os clusters de navegadores locais, o gerenciamento do ciclo de vida e o ajuste de recursos.
API Web Unlocker
Use o Web Unlocker para scraping baseado em HTTP em sites protegidos. A Bright Data encaminha as solicitações por meio de uma infraestrutura de Proxy adaptável e aplica o tratamento de bloqueios integrado.
Isso elimina a necessidade de obter proxies, alternar IPs ou escrever lógica de repetição em seu código.
API Scraper (Conjuntos de dados pré-construídos)
Use APIs para Web Scraper para plataformas padronizadas, como Amazon, Google, LinkedIn e muito mais. Ele oferece mais de 150 Scrapers pré-construídos para todas as principais plataformas de comércio eletrônico e mídias sociais.
A Bright Data retorna dados estruturados sem automação do navegador ou analisadores personalizados. Isso elimina a manutenção do Scraper específico do site para fontes de dados comuns.
O que desaparece da sua pilha
Ao usar a Bright Data, você não opera mais:
- Pools de proxies ou lógica de rotação de IP
- Clusters de navegadores locais ou autogerenciados
- Serviços de resolução de CAPTCHA
- Código personalizado de repetição e detecção de bloqueio
- Correções contínuas para alterações no site e na detecção
Esses custos operacionais se acumulam rapidamente em configurações locais e de nuvem DIY.
Bright Data vs outras ferramentas de scraping em nuvem
As plataformas de cloud scraping não são intercambiáveis. A escolha certa depende da quantidade de scraping que você faz, do nível de proteção dos alvos e da infraestrutura que você está disposto a operar.
Comparação direta
| Provedor | Escala | Pool de IP | Conformidade | Ideal para |
|---|---|---|---|---|
| Bright Data | Empresas (bilhões) | Mais de 150 milhões | SOC2, GDPR, CCPA | Produção em grande escala |
| ScrapingBee | Pequena-média | Limitada | Parcial | Projetos simples |
| Octoparse | Baseado em GUI | Pequeno pool | Limitado | Usuários não técnicos |
Onde a Bright Data se encaixa
A Bright Data é adequada para cargas de trabalho em que a extração de dados é contínua e operacionalmente importante.
Isso inclui casos em que:
- O volume excede 10.000 páginas por mês
- Os alvos utilizam defesas modernas contra bots
- É necessária a renderização em JavaScript
- Os dados alimentam sistemas ou análises a jusante
- Falhas de scraping causam impacto nos negócios
Nesses casos, a propriedade da infraestrutura gera mais custos e riscos do que a simplicidade da API.
Quando outras ferramentas são suficientes
Ferramentas de nuvem mais leves funcionam quando as restrições são menores.
Serviços baseados em API são adequados para:
- Trabalhos de scraping pequenos ou periódicos
- Sites com proteção limitada
- Cargas de trabalho em que falhas ocasionais são aceitáveis
Ferramentas baseadas em GUI são adequadas para:
- Usuários não técnicos
- Coleta de dados pontual ou manual
- Tarefas exploratórias ou ad hoc
Essas ferramentas reduzem o esforço de configuração, mas não removem os limites operacionais em escala.
Como escolher
A decisão reflete os limites anteriores de custo e uso:
- Se a extração de dados for pequena, pouco frequente ou não crítica, ferramentas mais simples geralmente são suficientes
- Se a extração de dados for contínua, protegida ou crítica para os negócios, a infraestrutura gerenciada é importante
Conclusão
Comece com a extração local para aprender. Executar um Scraper em sua própria máquina ensina como funcionam as solicitações, o Parsing e as falhas. Para trabalhos pequenos com menos de 1.000 páginas, essa abordagem geralmente é suficiente.
Mude para o scraping na nuvem quando a escala ou a proteção alterarem a equação de custos. Quando o volume excede 10.000 páginas por mês, os alvos implantam defesas modernas contra bots ou os dados precisam ser atualizados continuamente, a propriedade da infraestrutura se torna uma restrição.
O scraping local oferece controle e responsabilidade. O scraping na nuvem troca um pouco do controle por execução previsível, menor risco operacional e custos escaláveis.
Para cargas de trabalho de produção, a infraestrutura de scraping na nuvem é infraestrutura. Você não executaria seus próprios servidores CDN ou de e-mail em escala. A infraestrutura de scraping segue a mesma lógica.
Se o seu caso de uso se encaixa nesse perfil, plataformas como a Bright Data permitem que você mantenha a lógica de extração enquanto transfere a execução e a manutenção para fora da sua pilha.
Perguntas frequentes: Scraping na nuvem x scraping local
O que é scraping local?
O scraping local é executado em máquinas que você controla. Você mesmo gerencia solicitações, Proxies, navegadores, novas tentativas e falhas. Funciona melhor para tarefas pequenas e pouco frequentes em sites com proteção leve.
O que é scraping na nuvem?
O scraping na nuvem é executado em uma infraestrutura operada por terceiros. Você envia solicitações para uma API e recebe os dados extraídos em resposta. O provedor de scraping lida com a execução, o dimensionamento, a rotação de IP, a Resolução de CAPTCHA, a superação de medidas anti-bot e muito mais.
Quando devo mudar do scraping local para o scraping na nuvem?
Mude quando ocorrer qualquer uma das seguintes situações:
- Bloqueios de IP aparecem após volume limitado de solicitações
- CAPTCHAs interrompem a automação
- O volume excede 10.000 páginas por mês
- A renderização de JavaScript se torna necessária
- Falhas de scraping afetam os sistemas downstream
Nesse ponto, a propriedade da infraestrutura se torna um passivo.
O scraping na nuvem é mais caro do que o scraping local?
As configurações locais acumulam custos de servidor, Proxy, manutenção e tempo de inatividade. O preço da nuvem varia de acordo com o uso e elimina as despesas fixas com infraestrutura.
- Em pequena escala, o scraping local costuma ser mais barato
- Em grande escala, o scraping na nuvem normalmente custa menos
O scraping na nuvem consegue lidar com sites com muito JavaScript?
Sim. As plataformas na nuvem operam navegadores gerenciados que executam JavaScript remotamente.
O scraping local exige que você mesmo execute navegadores headless, o que limita a simultaneidade e aumenta a manutenção.
Como o scraping na nuvem reduz o bloqueio de IP?
Os provedores de nuvem operam grandes redes de Proxy e gerenciam o roteamento de solicitações. A rotação de IP e a lógica de repetição ocorrem no nível da infraestrutura.
O scraping na nuvem é adequado para dados confidenciais ou regulamentados?
Nem sempre. Algumas cargas de trabalho não podem sair de ambientes controlados devido a políticas ou regulamentações. Mas a Bright Data oferece soluções de scraping totalmente compatíveis com SOC2, GDPR e CCPA.
Posso misturar scraping local e na nuvem?
Sim, mas a complexidade aumenta.
Algumas equipes desenvolvem e testam Scrapers localmente e, em seguida, executam cargas de trabalho de produção na nuvem. Isso requer a manutenção de dois ambientes de execução e o tratamento das diferenças entre eles.
A maioria das equipes escolhe uma abordagem com base em suas principais restrições.
Que tipo de equipes se beneficiam mais com plataformas de scraping na nuvem, como a Bright Data?
Equipes que executam o scraping como um sistema contínuo ou crítico para os negócios. Isso inclui cargas de trabalho com alto volume, alvos protegidos, renderização JavaScript ou largura de banda de engenharia limitada.






