

Bright Data é a plataforma de scraping de dados mais completa do mercado. Ela combina a maior rede de proxies comercial com APIs de scraper estruturadas e conjuntos de dados prontos. Também inclui um Navegador de scraping, APIs SERP e integração com agentes de IA. Zyte é a alternativa mais antiga, nativa do Scrapy, construída em torno de uma única API de scraping gerenciada.
Zyte (anteriormente Scrapinghub) criou o Scrapy, o framework Python de código aberto. Atualmente vende três produtos: Zyte API, Zyte Data e Scrapy Cloud. Testamos ambas as plataformas e analisamos dados de benchmark independentes. Comparamos em taxa de sucesso, preços, profundidade de produtos e usabilidade real. Bright Data vence em todos os critérios, exceto em um caso específico de preço.
TL;DR: Bright Data vs. Zyte
Conclusão: Bright Data é a melhor escolha para a maioria das equipes. Pontua mais alto em sites protegidos, oferece muito mais produtos e tem preços previsíveis. Zyte é adequado para equipes nativas do Scrapy que fazem scraping de sites simples e desprotegidos. Os dados de benchmark abaixo são do teste independente de 2026 do Scrape.do.
| Recurso | Bright Data | Zyte |
|---|---|---|
| Taxa de sucesso | 98,87% | 91,43% |
| Escopo de produtos | APIs de Web Scraper, Web Unlocker, Navegador de scraping, API SERP, proxies, conjuntos de dados, MCP | Zyte API, Zyte Data, Scrapy Cloud |
| Acesso a proxies | Direto: residencial, datacenter, ISP em 195 países | Nenhum: gerenciado internamente pela Zyte API |
| Conjuntos de dados pré-construídos | Sim, 100+ domínios | Não |
| Integração com agentes de IA | Servidor MCP | Nenhuma |
| Modelo de preços | Fixo: $1,5/1K registros | Por nível de dificuldade do site: $0,06 a $16,08/1K |
| Nível gratuito | 5.000 registros/mês, sem cartão | $5 de crédito, cartão obrigatório |
| Ideal para | Confiabilidade em escala, conjuntos de dados, controle de proxy, agentes de IA | Equipes nativas do Scrapy em sites simples |
Taxa de Sucesso: Os Dados de Benchmark
A confiabilidade é o primeiro fator que importa no scraping. O benchmark de 2026 do Scrape.do testou ambas contra sete alvos difíceis. Esses incluíram Amazon, Indeed, Zillow, Google e X. Bright Data obteve 98,87%, o maior índice entre todos os provedores testados. Zyte obteve 91,43%.
Essa diferença de 7 pontos se acumula em escala. Em 100.000 solicitações, é a diferença entre 1.130 e 8.570 falhas. Cada falha significa computação desperdiçada e um novo rastreamento. Em sites protegidos, Bright Data é simplesmente mais confiável.
Os tempos de resposta foram próximos no teste, em torno de 10 a 11 segundos cada. A velocidade não é o diferencial aqui. A confiabilidade em alvos difíceis é o que importa.
Preços: Taxa Fixa vs. Níveis de Dificuldade
É aqui que as plataformas mais diferem em filosofia. Bright Data cobra uma taxa fixa única. Zyte cobra de acordo com a dificuldade do site alvo.
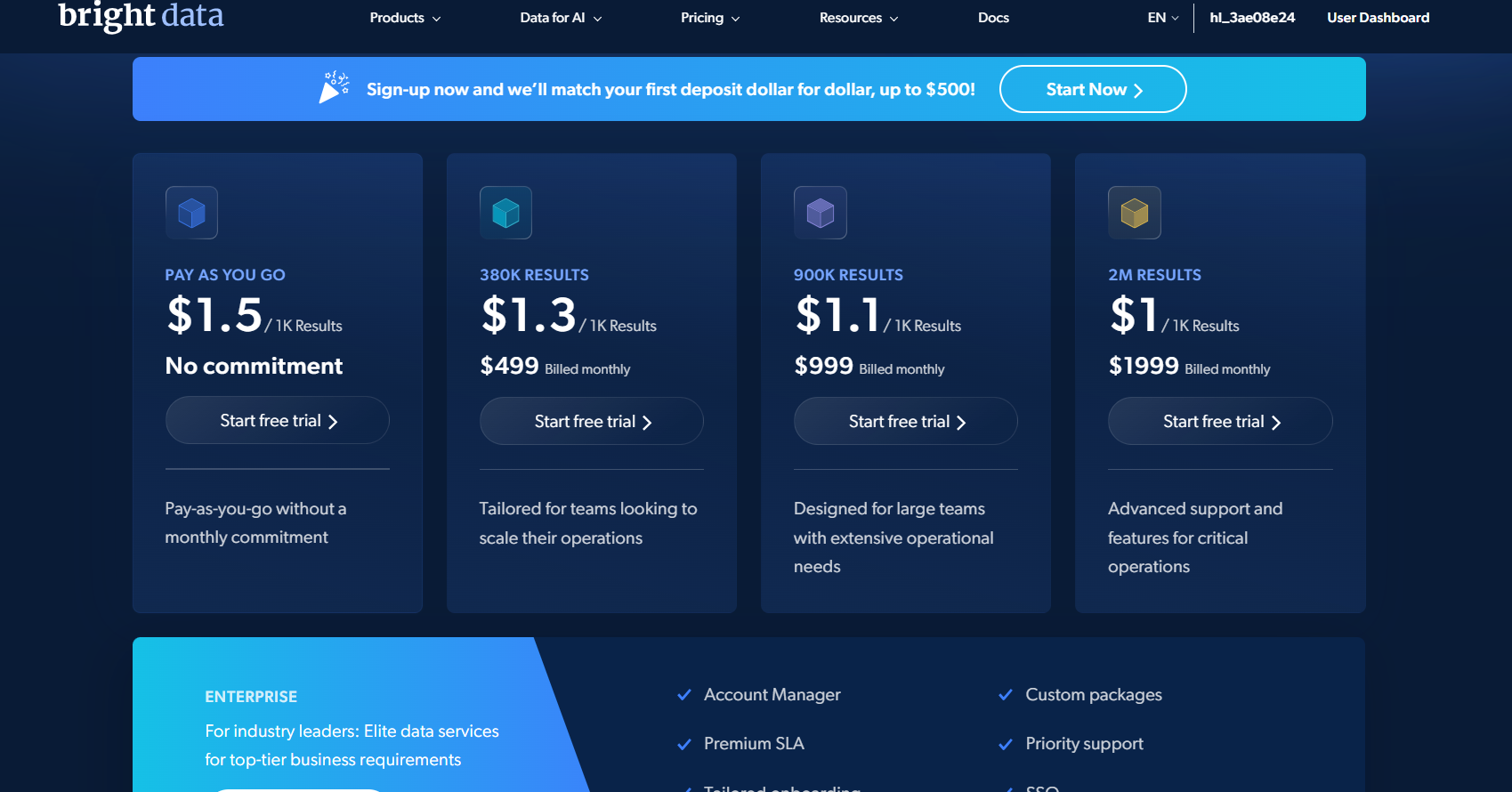
Bright Data: preços de taxa fixa
A API de Web Scraper da Bright Data custa $1,5 por 1.000 registros no pagamento por uso. Você paga apenas pelos resultados bem-sucedidos. O nível gratuito inclui 5.000 registros por mês sem cartão de crédito. O plano Scale custa $499 por mês para 384.000 registros.
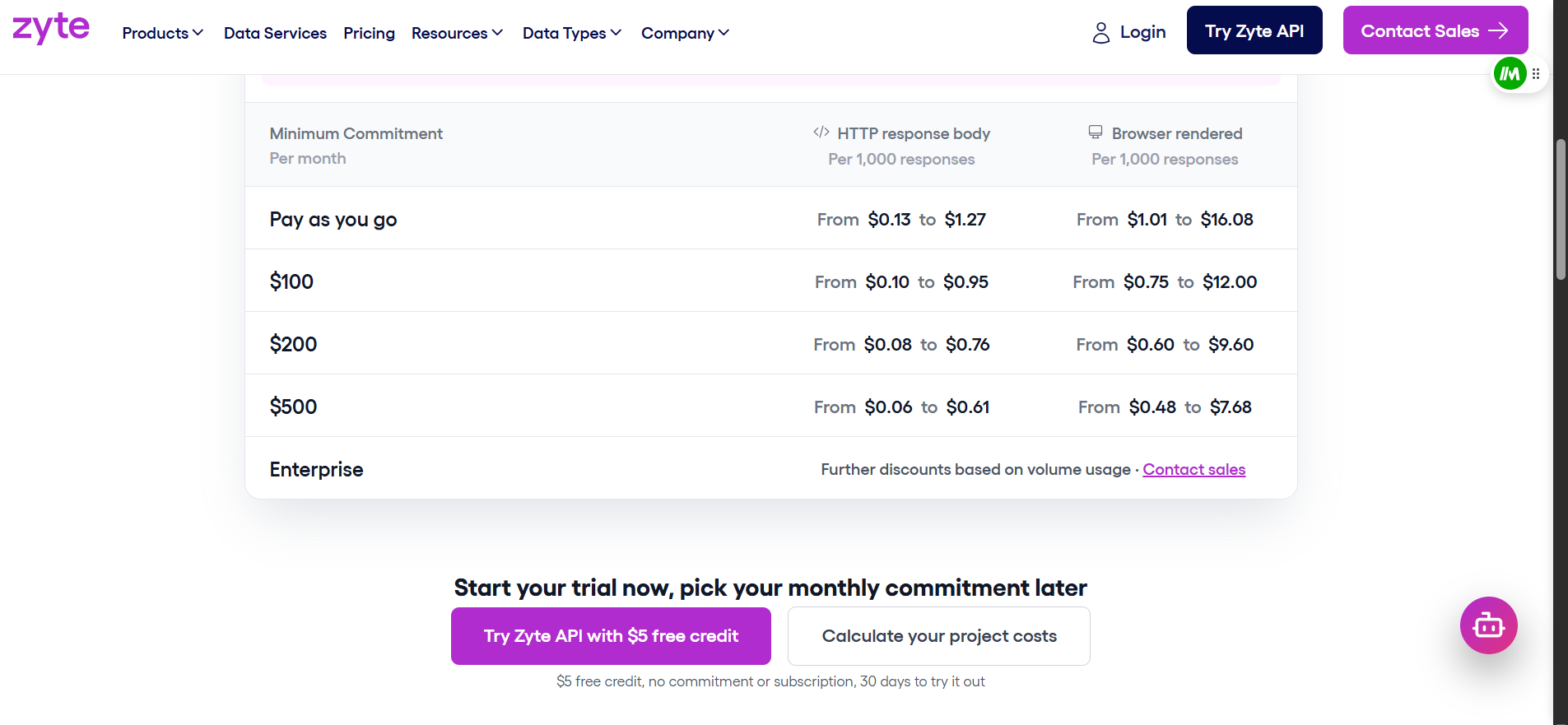
Zyte: cinco níveis de dificuldade
Zyte classifica cada site em cinco níveis de dificuldade. Solicitações HTTP variam de $0,06 a $1,27 por 1.000. Solicitações renderizadas pelo navegador variam de $0,48 a $16,08 por 1.000. A taxa exata depende do nível e do seu compromisso mensal.
A matemática dos preços na prática
Considere 100.000 solicitações contra um site difícil com renderização de navegador. Bright Data custa $150 no pagamento por uso. Zyte custa $402 em um nível intermediário e até $1.608 no nível mais difícil.
Agora considere 100.000 solicitações contra um site simples somente HTTP. Zyte custa apenas $13. Bright Data ainda custa $150. Zyte vence em sites triviais, mas esses raramente precisam de uma API de scraping paga.
O problema mais profundo é a previsibilidade. Muitas vezes você não sabe o nível de um site antes de fazer o scraping. O orçamento fica difícil quando os alvos abrangem vários níveis. A taxa fixa da Bright Data elimina completamente essa variável.
Profundidade de Produtos: Stack Completo vs. Uma API
Esta é a maior vantagem estrutural da Bright Data. Zyte oferece três produtos. Bright Data oferece uma stack completa de infraestrutura de dados. Sua rede abrange 400M+ IPs residenciais, 1,300,000+ IPs de datacenter e 1,300,000+ IPs ISP em 195 países.
O que Bright Data tem que Zyte não tem
1. Conjuntos de dados pré-construídos. Bright Data mantém conjuntos de dados prontos para uso em 100+ domínios. Esses incluem LinkedIn, Amazon, Zillow e Google Maps. Você consulta um conjunto de dados com filtros e recebe registros estruturados. Sem scraper, sem rastreamento, sem parsing.
Em nossos testes, a API de Filtro de Conjunto de Dados retornou 100 empresas do LinkedIn em 46,5 segundos. Cada registro continha dados firmográficos, histórico de financiamento e uma URL do Crunchbase. Zyte não tem equivalente. A mesma tarefa na Zyte exige construir e manter um scraper personalizado.

2. Acesso direto a proxies. Bright Data permite usar sua rede de proxies diretamente. Você controla o direcionamento por país, cidade e ASN. Zyte gerencia proxies internamente, então você não tem controle sobre tipo, localização ou rotação.
3. Navegador de scraping. O Navegador de scraping conecta seus scripts existentes de Playwright, Puppeteer ou Selenium à infraestrutura gerenciada. Ele cuida da rotação de proxies, resolução de CAPTCHA e fingerprints. Zyte exige que você reescreva essa lógica como solicitações de API.
4. API SERP. A API SERP retorna resultados de pesquisa estruturados do Google, Bing e outros. Zyte não tem produto de pesquisa dedicado.
5. Integração MCP. O servidor MCP fornece ferramentas nativas de dados web para agentes de IA. Agentes construídos com LangChain, CrewAI ou LlamaIndex podem chamá-lo diretamente. Zyte não tem integração MCP.
O que Zyte tem que Bright Data não tem
1. Scrapy Cloud. Zyte criou o Scrapy e opera o melhor host gerenciado para spiders Scrapy. Ele cuida de implantação, agendamento e monitoramento a partir de $9 por unidade por mês. Equipes com uso intensivo de Scrapy encontram um lar natural aqui.
2. Extração sem código com IA. A IA da Zyte retorna dados estruturados para tipos de página suportados sem seletores. Funciona bem para produtos, artigos e páginas de emprego. O Scraper Studio da Bright Data cobre a construção sem código, mas a abordagem zero-config da Zyte é mais fluida para esses esquemas.
3. Zyte Data. Zyte Data é um serviço de extração totalmente gerenciado a partir de $500 por mês. A equipe deles constrói e mantém o pipeline para você. Os conjuntos de dados da Bright Data são de autoatendimento, e não totalmente gerenciados.
Na Prática: API de Web Scraper da Bright Data
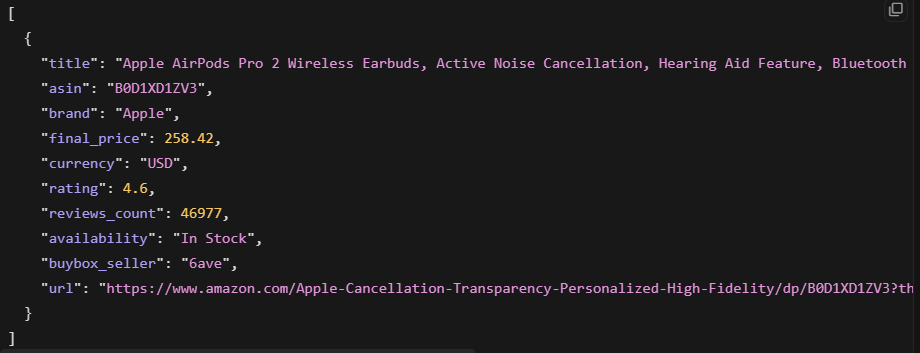
Bright Data retorna JSON estruturado diretamente. Você envia uma URL e recebe campos analisados de volta, sem HTML para processar:
import requests
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": "gd_l7q7dkf244hwjntr0", "format": "json"},
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json=[{"url": "https://www.amazon.com/dp/B0D1XD1ZV3"}],
)
product = response.json()
Isso retornou o título do produto, preço, avaliação, contagem de avaliações e disponibilidade. A saída foi um JSON estruturado limpo, pronto para uso.
Para sites sem um scraper pré-construído, o Web Unlocker retorna HTML desbloqueado para você analisar:
response = requests.post(
"https://api.brightdata.com/request",
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json={"zone": "YOUR_ZONE_NAME", "url": "https://example.com/page", "format": "json"},
)
html = response.json().get("body", "")
Web Unlocker cuida da seleção de proxy, resolução de CAPTCHA e novas tentativas. Você mantém o controle sobre o tipo de proxy e o direcionamento geográfico.
Na Prática: Como Funciona a Zyte API
Zyte API retorna HTML bruto ou renderizado pelo navegador, e você cuida do parsing:
import requests
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "browserHtml": True},
)
html = response.json().get("browserHtml")
A extração com IA da Zyte adiciona saída estruturada para esquemas suportados. Você define uma flag e ignora os seletores:
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "product": True},
)
product = response.json().get("product")
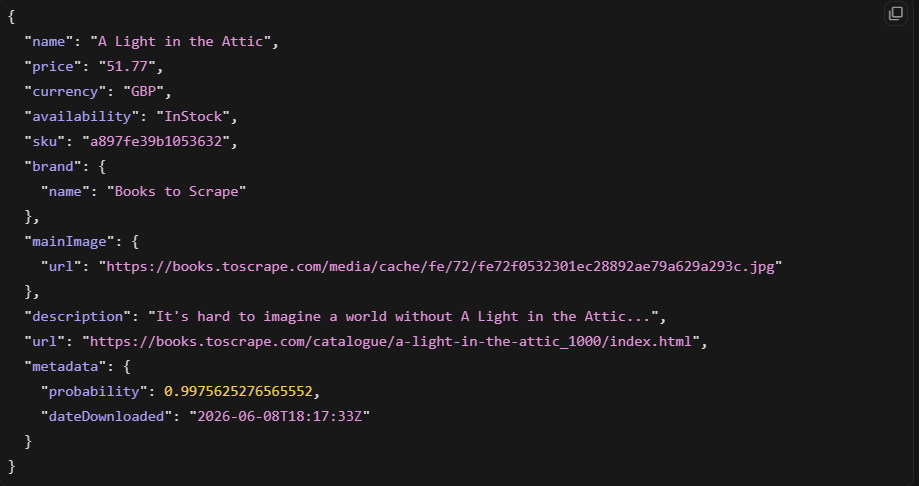
Isso retornou um objeto de produto limpo em nosso teste. A extração com IA é genuinamente útil para tipos de página suportados. O problema é que só funciona onde a Zyte tem modelos treinados.
Quando Escolher Cada Uma
- Escolha Bright Data para altas taxas de sucesso, conjuntos de dados pré-construídos, controle de proxy, agentes de IA e preços previsíveis
- Escolha Zyte se sua equipe é nativa do Scrapy e faz scraping principalmente de sites simples e desprotegidos
- Use ambas se você executa spiders Scrapy no Scrapy Cloud, mas precisa da Bright Data para alvos difíceis
Conclusão
Zyte é uma plataforma capaz para equipes nativas do Scrapy em sites simples. A diferença aparece quando o trabalho fica mais difícil. Bright Data pontua mais alto em sites protegidos, oferece muito mais produtos e tem preços sem incertezas.
Para dados confiáveis em escala, Bright Data é a base mais sólida e abrangente. É respaldada pela certificação ISO 27001 e conformidade com GDPR e CCPA. Veja o Trust Center para detalhes. Você também pode ler nossa comparação Bright Data vs. Apollo.
Inicie seu teste grátis hoje e teste a Bright Data em seus alvos mais difíceis.
Perguntas Frequentes
Bright Data ou Zyte é melhor para scraping de dados?
Bright Data é melhor para a maioria das equipes. Obteve 98,87% contra 91,43% da Zyte no benchmark de 2026 do Scrape.do. Também oferece muito mais produtos. Zyte é adequado para equipes nativas do Scrapy que fazem scraping de sites simples.
Como os preços de Bright Data e Zyte se comparam?
Bright Data cobra uma taxa fixa de $1,5 por 1.000 registros, com 5.000 gratuitos por mês. Zyte cobra por dificuldade do site, de $0,06 a $16,08 por 1.000 solicitações. Os preços da Bright Data são mais previsíveis.
Zyte tem conjuntos de dados pré-construídos como a Bright Data?
Não. Bright Data oferece conjuntos de dados prontos para 100+ domínios, incluindo LinkedIn e Amazon. Zyte não tem equivalente. Você teria que construir e manter esses scrapers por conta própria.
Posso usar meu código Scrapy ou Playwright existente?
Zyte opera o Scrapy Cloud, o melhor host gerenciado para spiders Scrapy. O Navegador de scraping da Bright Data conecta scripts existentes de Playwright, Puppeteer e Selenium à sua infraestrutura.
Qual devo escolher, Bright Data ou Zyte?
Escolha Bright Data para confiabilidade em escala, conjuntos de dados, controle de proxy e agentes de IA. Escolha Zyte se sua equipe é nativa do Scrapy e faz scraping principalmente de sites simples e desprotegidos.





