

Neste guia, você aprenderá:
- O que é a classificação de disparo zero e como ela funciona
- Prós e contras de seu uso
- Relevância dessa prática na raspagem da Web
- Tutorial passo a passo para implementar a classificação zero-shot em um cenário de raspagem da Web
Vamos mergulhar de cabeça!
O que é a classificação Zero-Shot?
A classificação zero-shot (ZSC) é a capacidade de prever uma classe que um modelo de aprendizado de máquina nunca viu durante sua fase de treinamento. Uma classe é uma categoria ou rótulo específico que o modelo atribui a um dado. Por exemplo, ele poderia atribuir a classe “spam” ao texto de um e-mail ou “gato” a uma imagem.
O ZSC pode ser classificado como uma instância de aprendizagem por transferência. A aprendizagem por transferência é uma técnica de aprendizagem de máquina em que você aplica o conhecimento obtido com a solução de um problema para ajudar a resolver um problema diferente, mas relacionado.
A ideia central da ZSC foi explorada e implementada em vários tipos de redes neurais e modelos de aprendizado de máquina por algum tempo. Ela pode ser aplicada a diferentes modalidades, incluindo:
- Texto: Imagine que você tenha um modelo treinado para entender a linguagem de forma ampla, mas nunca mostrou a ele um exemplo de “avaliação de produto para embalagem sustentável”. Com o ZSC, você pode pedir que ele identifique essas avaliações em uma pilha de texto. Ele faz isso entendendo o significado de suas categorias desejadas (rótulos) e combinando-as com o texto de entrada, em vez de depender de exemplos pré-aprendidos para cada rótulo específico.
- Imagens: Um modelo treinado em um conjunto de imagens de animais (por exemplo, gatos, cachorros, cavalos) pode ser capaz de classificar a imagem de uma zebra como um “animal” ou até mesmo um “animal listrado parecido com um cavalo” sem nunca ter visto uma zebra durante o treinamento.
- Áudio: Um modelo pode ser treinado para reconhecer sons urbanos comuns, como “buzina de carro”, “sirene” e “latido de cachorro”. Graças à ZSC, um modelo pode identificar um som para o qual nunca foi explicitamente treinado, como “martelo pneumático”, compreendendo suas propriedades acústicas e relacionando-as a sons conhecidos.
- Dados multimodais: A ZSC pode trabalhar com diferentes tipos de dados, como classificar uma imagem com base em uma descrição textual de uma classe que ela nunca viu, ou vice-versa.
Como o ZSC funciona?
A classificação zero-shot está ganhando interesse graças à popularidade dos LLMs pré-treinados. Esses modelos são treinados em grandes quantidades de dados orientados por IA, o que lhes permite desenvolver uma compreensão profunda da linguagem, da semântica e do contexto.
Para o ZSC, os modelos pré-treinados geralmente são ajustados em uma tarefa chamada NLI(Natural Language Inference, inferência de linguagem natural). A NLI envolve a determinação da relação entre duas partes do texto: uma “premissa” e uma “hipótese”. O modelo decide se a hipótese é uma implicação (verdadeira, dada a premissa), uma contradição (falsa, dada a premissa) ou neutra (não relacionada).
Em uma configuração de classificação zero-shot, o texto de entrada atua como premissa. Os rótulos das categorias candidatas são tratados como hipóteses. O modelo calcula qual “hipótese” (rótulo) é mais provável de ser associada à “premissa” (texto de entrada). O rótulo com a maior pontuação de associação é escolhido como a classificação.
Vantagens e limitações do uso da classificação Zero-Shot
É hora de explorar os benefícios e as desvantagens da ZSC.
Vantagens
O ZSC apresenta vários benefícios operacionais, incluindo:
- Adaptabilidade a novas classes: A ZSC abre a porta para a classificação de dados em categorias inéditas. Ele faz isso definindo novos rótulos sem exigir o retreinamento do modelo ou a coleta de exemplos de treinamento específicos para as novas classes.
- Menor exigência de dados rotulados: O método diminui a dependência de extensos conjuntos de dados rotulados para as classes-alvo. Isso reduz a rotulagem de dados – umgargalo comum em cronogramas e custos de projetos de aprendizado de máquina.
- Implementação eficiente do classificador: Novos esquemas de classificação podem ser configurados e avaliados rapidamente. Isso facilita ciclos de iteração mais rápidos em resposta à evolução dos requisitos.
Limitações
Embora eficiente, a classificação de disparo zero tem limitações, como
- Variabilidade de desempenho: Os modelos alimentados por ZSC podem apresentar menor precisão em comparação com os modelos supervisionados treinados extensivamente em conjuntos de classes fixas. Isso acontece porque a ZSC se baseia na inferência semântica em vez de treinamento direto em exemplos de classes-alvo.
- Dependência da qualidade do modelo: O desempenho da ZSC depende da qualidade e dos recursos do modelo de linguagem pré-treinado subjacente. Um modelo de base avançado geralmente leva a melhores resultados de ZSC.
- Ambiguidade e fraseado do rótulo: A clareza e a distinção dos rótulos dos candidatos influenciam a precisão. Rótulos ambíguos ou mal definidos podem resultar em um desempenho abaixo do ideal.
A relevância da classificação Zero-Shot no Web Scraping
O surgimento contínuo de novas informações, produtos e tópicos na Web exige métodos de processamento de dados adaptáveis. Tudo começa com a raspagem da Web, oprocesso automatizado de recuperação de dados de páginas da Web.
Os métodos tradicionais de aprendizado de máquina exigem categorização manual ou retreinamento frequente para lidar com novas classes em dados raspados, o que é ineficiente em escala. Em vez disso, a classificação zero-shot aborda os desafios impostos pela natureza dinâmica do conteúdo da Web, permitindo:
- Categorização dinâmica de dados heterogêneos: Os dados extraídos de diversas fontes podem ser classificados em tempo real usando um conjunto de rótulos definido pelo usuário, pertinente aos objetivos analíticos atuais.
- Adaptação a cenários de informações em evolução: Novas categorias ou tópicos podem ser incorporados ao esquema de classificação imediatamente, sem a necessidade de ciclos extensos de redesenvolvimento de modelos.
Portanto, os casos de uso típicos de ZSC em raspagem da Web são:
- Categorização dinâmica de conteúdo: Ao extrair conteúdo, como artigos de notícias ou listagens de produtos de vários domínios, o ZSC pode atribuir automaticamente itens a categorias predefinidas ou novas.
- Análise de sentimento para assuntos novos: Para análises de clientes raspadas de novos produtos ou dados de mídia social relacionados a marcas emergentes, a ZSC pode realizar a análise de sentimento sem exigir dados de treinamento de sentimento específicos para esse produto ou marca. Isso facilita o monitoramento oportuno da percepção da marca e a avaliação do feedback do cliente.
- Identificação de tendências e temas emergentes: Ao definir rótulos de hipóteses que representam novas tendências em potencial, o ZSC pode ser usado para analisar textos extraídos de fóruns, blogs ou mídias sociais para identificar a crescente prevalência desses temas.
Implementação prática da classificação Zero-Shot
Esta seção do tutorial o guiará pelo processo de aplicação da classificação zero-shot aos dados recuperados da Web. O site de destino será “Hockey Teams: Forms, Searching and Pagination” (Formulários, pesquisa e paginação):

Primeiro, um raspador da Web extrairá os dados da tabela acima. Em seguida, um LLM os classificará usando o ZSC. Para este tutorial, você usará o DistilBart-MNLI da Hugging Face: um LLM leve da família BART.
Siga as etapas abaixo e veja como atingir a meta desejada do ZSC!
Pré-requisitos e dependências
Para replicar este tutorial, você deve ter o Python 3.10.1 ou superior instalado em sua máquina.
Suponha que você chame a pasta principal do seu projeto de zsc_project/. Ao final desta etapa, a pasta terá a seguinte estrutura:
zsc_project/
├── zsc_scraper.py
└── venv/Onde:
zsc_scraper.pyé o arquivo Python que contém a lógica de codificação.venv/contém o ambiente virtual.
Você pode criar o diretório do ambiente virtual venv/ da seguinte forma:
python -m venv venvPara ativá-lo, no Windows, execute:
venvScriptsactivateDe forma equivalente, no macOS e no Linux, execute:
source venv/bin/activateNo ambiente virtual ativado, instale as dependências com:
pip install requests beautifulsoup4 transformers torchEssas dependências são:
solicitações: Uma biblioteca para fazer solicitações HTTP na Web.beautifulssoup4: uma biblioteca para analisar documentos HTML e XML e extrair dados deles. Saiba mais em nosso guia sobre raspagem da Web do BeautifulSoup.transformadores: Uma biblioteca da Hugging Face que fornece milhares de modelos pré-treinados.torch: PyTorch, uma estrutura de aprendizado de máquina de código aberto.
Maravilhoso! Agora você tem o que precisa para extrair os dados do site de destino e executar o ZSC.
Etapa 1: Instalação e configuração iniciais
Inicialize o arquivo zsc_scraper.py importando as bibliotecas necessárias e configurando algumas variáveis:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process O código acima faz o seguinte:
- Define o site de destino a ser extraído com
BASE_URL. CANDIDATES_LABELSarmazena uma lista de cadeias de caracteres que definem as categorias que o modelo de classificação de disparo zero usará para classificar os dados extraídos. O modelo tentará determinar qual desses rótulos descreve melhor cada parte dos dados da equipe.- Define o número máximo de páginas a serem extraídas e o número máximo de dados de equipes a serem recuperados.
Perfeito! Você tem tudo o que é necessário para começar a usar a classificação zero-shot em Python.
Etapa 2: Obter os URLs das páginas
Comece inspecionando o elemento de paginação na página de destino:

Aqui, você pode observar que os URLs de paginação estão contidos em um nó HTML .pagination.
Defina uma função para encontrar todos os URLs de página exclusivos da seção de paginação do site:
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urlsEssa função:
- Envia uma solicitação HTTP para o site de destino com o método
get(). - Gerencia a paginação com o método
select()do BeautifulSoup. - Itera por cada página, garantindo uma ordem consistente, com um loop
for. - Retorna a lista de todos os URLs exclusivos de página inteira.
Legal! Você criou uma função para buscar os URLs das páginas da Web das quais extrair dados.
Etapa nº 3: Extrair os dados
Comece inspecionando o elemento de paginação na página de destino:

Aqui, você pode ver que os dados das equipes a serem extraídos estão contidos em um nó HTML .table.
Crie uma função que pegue um URL de página única, obtenha seu conteúdo e extraia as estatísticas da equipe:
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_dataEssa função:
- Recupera os dados das linhas da tabela com o método
select(). - Processa cada linha da equipe com o loop
for row in table_rows:. - Retorna os dados obtidos em uma lista.
Muito bem! Você criou uma função para recuperar os dados do site de destino.
Etapa nº 4: Orquestrar o processo
Coordene todo o fluxo de trabalho nas etapas a seguir:
- Carregar o modelo de classificação
- Obter os URLs das páginas a serem coletadas
- Extrair dados de cada página
- Classificar o texto extraído com o ZSC
Faça isso com o código a seguir:
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")Este código:
- Carrega o modelo pré-treinado com o método
pipeline()e especifica sua tarefa com"zero-shot-classification". - Chama as funções anteriores e executa o ZSC real.
Perfeito! Você criou uma função que orquestra todas as etapas anteriores e executa a classificação de disparo zero real.
Etapa 5: Junte tudo e execute o código
Veja abaixo o que o arquivo zsc_scraper.py deve conter agora:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process per page
# Fetch page URLs
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urls
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_data
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")Muito bem! Você concluiu seu primeiro projeto de ZSC.
Execute o código com o seguinte comando:
python zsc_scraper.pyEsse é o resultado esperado:
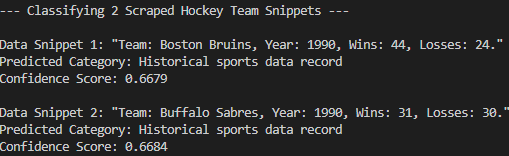
Como você pode ver, o modelo classificou corretamente os dados raspados no “Registro de dados esportivos históricos”. Isso não teria sido possível sem a classificação de tiro zero. Missão concluída!
Conclusão
Neste artigo, você aprendeu o que é classificação zero-shot e como aplicá-la em um contexto de raspagem da Web. Os dados da Web estão em constante mudança e não se pode esperar que um LLM pré-treinado saiba tudo com antecedência. A ZSC ajuda a preencher essa lacuna classificando dinamicamente novas informações sem retreinamento.
No entanto, o verdadeiro desafio está na obtenção de dados novos, já quenem todos os sites são fáceis de serem extraídos. É aí que entra a Bright Data, que oferece um conjunto de ferramentas e serviços poderosos projetados para superar os obstáculos da coleta de dados. Esses serviços incluem.
- Web Unlocker: Uma API que contorna as proteções antirrastreamento e fornece HTML limpo de qualquer página da Web com o mínimo de esforço.
- Navegador de raspagem: Um navegador controlável e baseado em nuvem com renderização de JavaScript. Ele lida automaticamente com CAPTCHAs, impressão digital do navegador, novas tentativas e muito mais para você. Integra-se perfeitamente ao Panther ou ao Selenium PHP.
- APIs do Web Scraper: Endpoints para acesso programático a dados estruturados da Web de dezenas de domínios populares.
Para o cenário de aprendizado de máquina, explore também nosso hub de IA.
Inscreva-se agora na Bright Data e comece sua avaliação gratuita para testar nossas soluções de raspagem!





