

Neste guia sobre análise de dados com Python, você verá:
- Por que usar Python para análise de dados
- Bibliotecas comuns para análise de dados com Python
- Um tutorial passo a passo para fazer análise de dados em Python
- O processo a ser seguido na análise de dados
Vamos mergulhar de cabeça!
Por que usar Python para análise de dados
A análise de dados geralmente é realizada com duas linguagens de programação principais:
- R: mais adequado para pesquisadores e estatísticos.
- Python: Melhor para todos os outros profissionais
Em particular, abaixo estão os principais motivos para usar o Python para análise de dados:
- Curva de aprendizado reduzida: O Python tem uma sintaxe simples e legível, o que o torna acessível tanto para iniciantes quanto para especialistas.
- Versatilidade: O Python pode lidar com uma variedade de tipos e formatos de dados, incluindo CSV, Excel, JSON, bancos de dados SQL, Parquet e outros. Além disso, ele é adequado para tarefas que vão desde a simples limpeza de dados até aplicativos complexos de aprendizado de máquina e aprendizado profundo.
- Escalabilidade: O Python é escalável e pode lidar tanto com pequenos conjuntos de dados quanto com tarefas de processamento de dados em grande escala. Por exemplo, bibliotecas como Dask e PySpark ajudam você a lidar com Big Data sem nenhum esforço.
- Suporte da comunidade: O Python tem uma comunidade grande e ativa de desenvolvedores e cientistas de dados que contribuem para seu ecossistema.
- Aprendizado de máquina e integração de IA: Python é a linguagem ideal para aprendizado de máquina e IA, com bibliotecas como TensorFlow, PyTorch e Keras que oferecem suporte a análises avançadas e modelagem preditiva.
- Reprodutibilidade e colaboração: Os Jupyter Notebooks ajudam a compartilhar e reproduzir trechos de análise de dados, o que é importante para a colaboração na ciência de dados.
- Ambiente único para diferentes finalidades: O Python oferece a possibilidade de usar o mesmo ambiente para diferentes finalidades. Por exemplo, você pode utilizar o mesmo Jupyter Notebook para extrair dados da Web e depois analisá-los. No mesmo ambiente, você também pode fazer previsões com modelos de aprendizado de máquina.
Bibliotecas comuns para análise de dados com Python
O Python é amplamente usado no campo da análise também por seu amplo ecossistema de bibliotecas. Aqui estão as bibliotecas mais comuns para análise de dados em Python:
- NumPy: Para cálculos numéricos e manipulação de matrizes multidimensionais.
- Pandas: Para manipulação e análise de dados, especialmente com dados tabulares.
- Matplotlib e Seaborn: Para visualização de dados e criação de gráficos interessantes.
- SciPy: Para computação científica e análise estatística avançada.
- Plotly: Para criar gráficos animados.
Veja-os em ação na seção guiada a seguir!
Análise de dados com Python: Um exemplo completo
Agora você sabe por que usar o Python para análise de dados e as bibliotecas comuns que dão suporte a essa tarefa. Siga este tutorial passo a passo para saber como realizar a análise de dados com Python.
Nesta seção, você analisará as informações de propriedades do Airbnb recuperadas de um conjunto de dados gratuito da Bright Data.
Requisitos
Para seguir este guia, você deve ter o Python 3.6 ou superior instalado em sua máquina.
Etapa 1: Configurar o ambiente e instalar as dependências
Suponha que você chame a pasta principal do seu projeto de data_analysis/. No final desta etapa, a pasta terá a seguinte estrutura:
data_analysis/
├── analysis.ipynb
└── venv/Onde:
analysis.ipynbé o Jupyter Notebook que contém todo o código de análise de dados Python.venv/contém o ambiente virtual do Python.
Você pode criar o diretório do ambiente virtual venv/ da seguinte forma:
python -m venv venvPara ativá-lo no Windows, execute:
venvScriptsactivateDe forma equivalente, no macOS/Linux, execute:
source venv/bin/activateNo ambiente virtual ativado, instale todas as bibliotecas necessárias:
pip install pandas jupyter matplotlib seaborn numpyPara criar o arquivo analysis.ipynb, primeiro você precisa entrar na pasta data_analysis/:
cd data_analysisEm seguida, inicialize um novo Jupyter Notebook com este comando:
jupyter notebookAgora você pode acessar o aplicativo Jupyter Notebook em http://locahost:8888 no seu navegador.
Crie um novo arquivo clicando na opção “New > Python 3 (ipykernel)”:
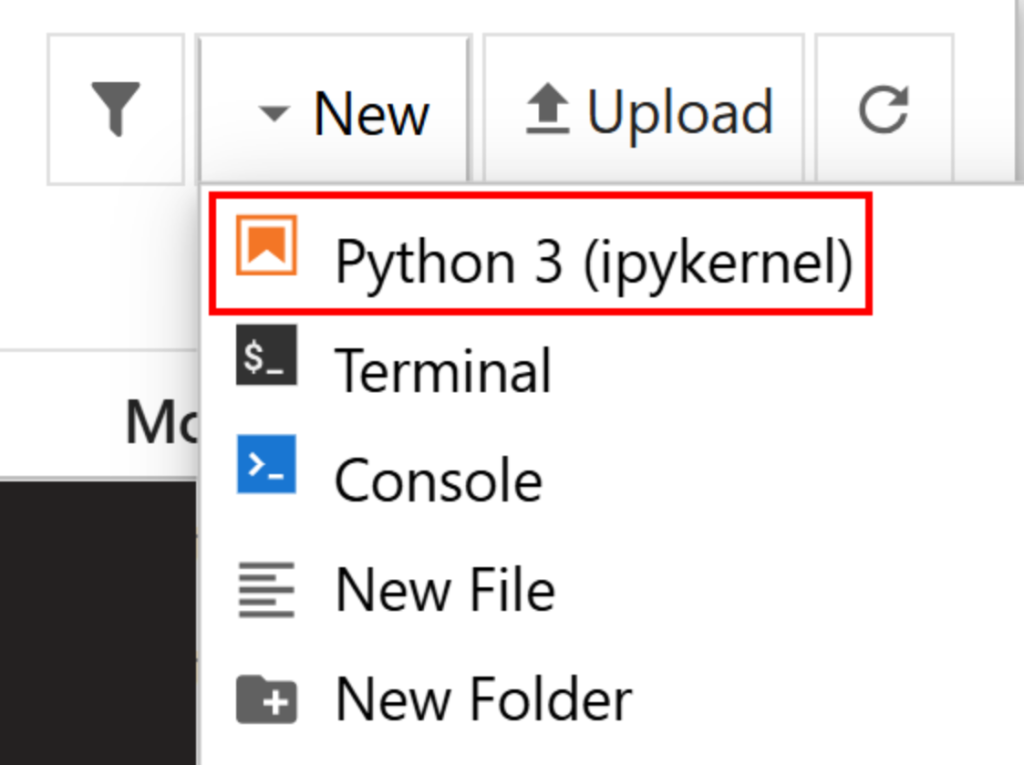
Por padrão, o novo arquivo será chamado untitled.ipynb. Você pode renomeá-lo no painel da seguinte forma:
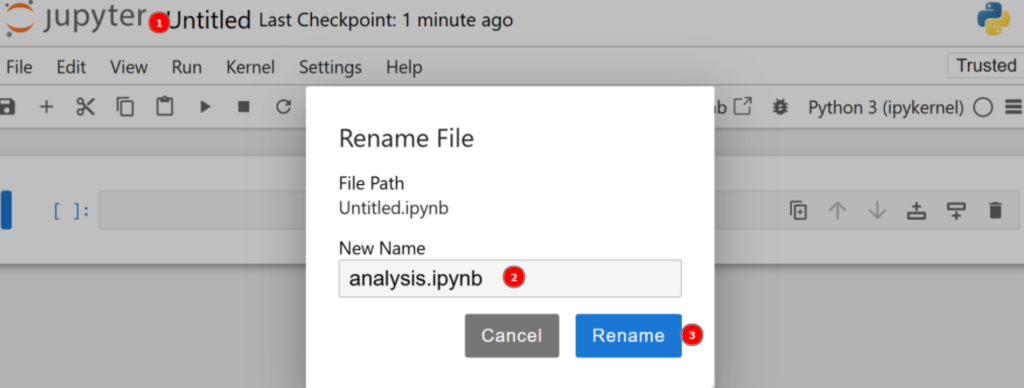
Ótimo! Agora você está totalmente preparado para a análise de dados com Python.
Etapa 2: Faça o download dos dados e abra-os
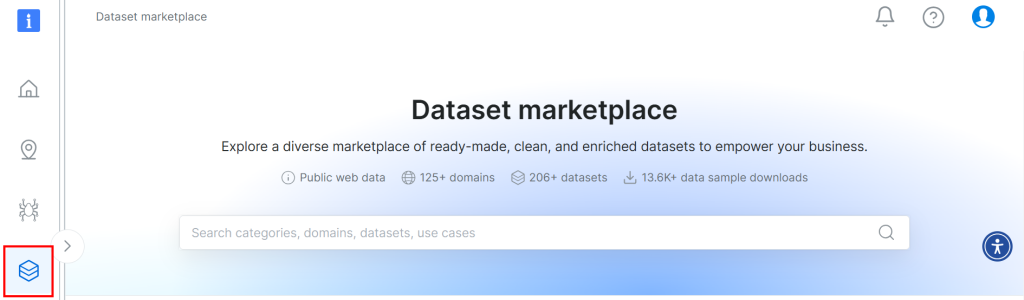
O conjunto de dados usado para este tutorial vem do mercado de conjuntos de dados da Bright Data. Para fazer o download, inscreva-se gratuitamente na plataforma e navegue até seu painel de usuário. Em seguida, siga o caminho “Web Datasets > Dataset” para acessar o mercado de conjuntos de dados:
Role a tela para baixo e procure o cartão “Informações sobre propriedades do Airbnb”:
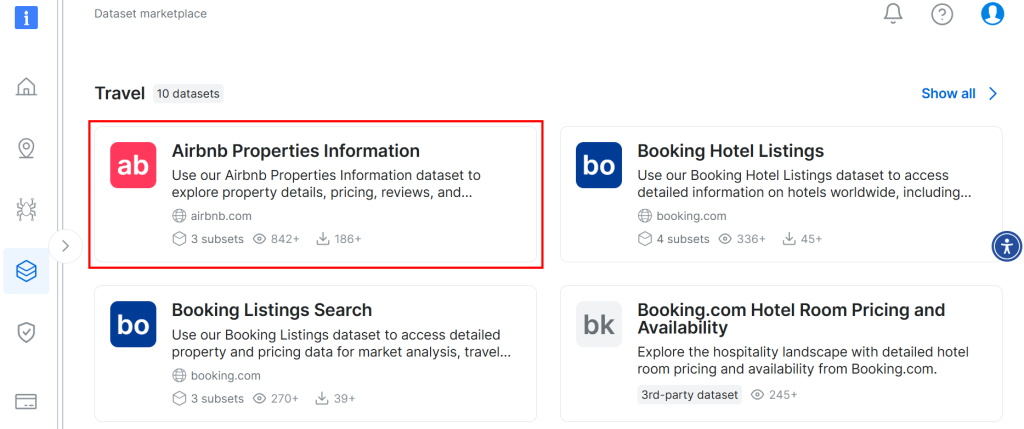
Para fazer o download do conjunto de dados, clique na opção “Download sample > Download as CSV”:
Agora você pode renomear o arquivo baixado, por exemplo, como airbnb.csv. Para abrir o arquivo CSV no Jupyter Notebook, escreva o seguinte em uma nova célula:
import pandas as pd
# Open CSV
data = pd.read_csv("airbnb.csv")
# Show head
data.head()Neste trecho:
- O método
read_csv()abre o arquivo CSV como um conjunto de dados do pandas. - O método
head()mostra as primeiras 5 linhas do conjunto de dados.
Abaixo está o resultado esperado:
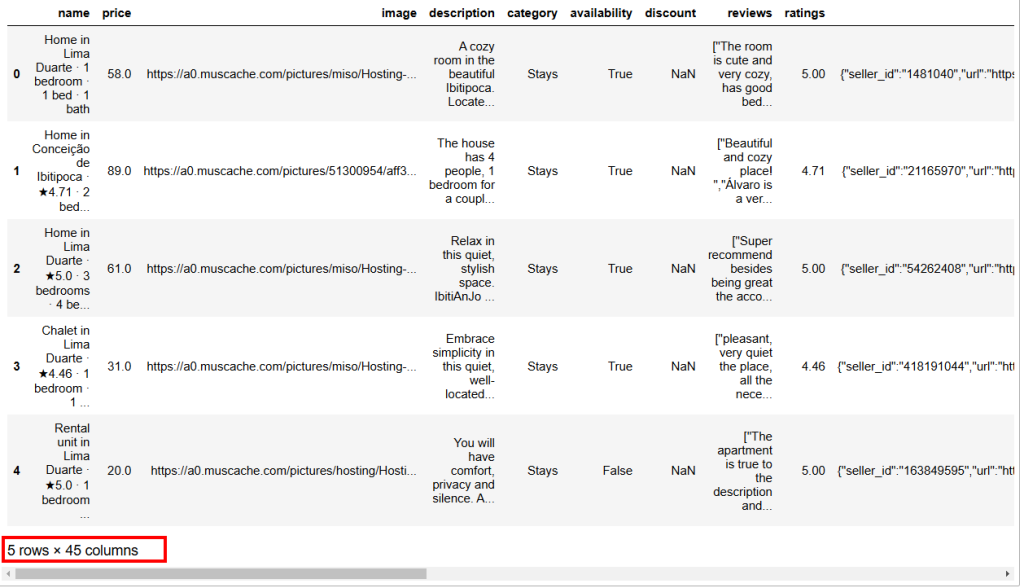
Como você pode ver, esse conjunto de dados tem 45 colunas. Para ver todas elas, você precisa mover a barra para a direita. No entanto, nesse caso, o número de colunas é alto, e apenas rolar a barra para a direita não permitirá que você veja todas as colunas, pois algumas foram ocultadas.
Para realmente visualizar todas as colunas, digite o seguinte em uma célula separada:
# Show all columns
pd.set_option("display.max_columns", None)
# Display the data frame
print(data)Etapa 3: Gerenciar NaNs
Em computação, NaN significa “Not a Number” (Não é um número). Ao realizar a análise de dados com Python, você pode encontrar conjuntos de dados com valores vazios, cadeias de caracteres onde deveria encontrar números ou células já rotuladas como NaN (veja, por exemplo, a coluna de desconto na imagem acima).
Como seu objetivo é analisar dados, você precisa tratar os NaNsadequadamente. Há três maneiras principais de fazer isso:
- Excluir todas as linhas que contêm
NaNs. - Substitua os
NaNsde uma coluna pela média calculada sobre os outros números da mesma coluna. - Busca de novos dados para enriquecer o conjunto de dados de origem.
Para simplificar, vamos seguir a primeira abordagem.
Primeiro, você precisa verificar se todos os valores da coluna de desconto são NaNs. Se forem, você pode excluir a coluna inteira. Para verificar isso, escreva o seguinte em uma nova célula:
import numpy as np
is_discount_all_nan = data["discount"].isna().all()
print(f"Is the 'discount' column all NaNs? {is_discount_all_nan}")Nesse trecho, o método isna().all() analisa os NaNsda coluna de desconto, que foi filtrada do conjunto de dados com data["discount"].
O resultado que você obterá é True, o que significa que a coluna discount **** pode ser descartada, pois todos os seus valores são NaNs. Para conseguir isso, escreva:
data = data.drop(columns=["discount"])O conjunto de dados original foi substituído por um novo sem a coluna de desconto.
Agora, você pode analisar todo o conjunto de dados e verificar se há algum outro NaN nas linhas, da seguinte forma:
total_nans = data.isna().sum().sum()
print(f"Total number of NaN values in the data frame: {total_nans}")O resultado que você receberá é:
Total number of NaN values in the data frame: 1248Isso significa que há 1.248 outros NaNsno quadro de dados. Para eliminar as linhas que contêm pelo menos um NaN, digite:
data = data.dropna()Agora, o quadro de dados não tem NaNse está pronto para a análise de dados do Python sem nenhuma preocupação com resultados distorcidos.
Para verificar se o processo foi bem-sucedido, você pode escrever:
print(data.isna().sum().sum())O resultado esperado é 0.
Etapa 4: Exploração de dados
Antes de visualizar os dados do Airbnb, você precisa se familiarizar com eles. Uma boa prática é começar visualizando as estatísticas de seu conjunto de dados da seguinte forma:
# Show statistics of the entire dataset
statistics = data.describe()
# Print statistics
print(statistics)Esse é o resultado esperado:
price ratings lat long guests
count 182.000000 182.000000 182.000000 182.000000 182.000000
mean 147.523352 4.804505 6.754955 -68.300942 6.554945
std 156.574795 0.209834 27.795750 24.498326 3.012818
min 16.000000 4.000000 -21.837300 -106.817450 2.000000
25% 50.000000 4.710000 -21.717270 -86.628968 4.000000
50% 89.500000 4.865000 30.382710 -83.479890 6.000000
75% 180.750000 4.950000 30.398860 -43.925480 8.000000
max 1003.000000 5.000000 40.481580 -43.801300 16.000000
property_id host_number_of_reviews host_rating hosts_year
count 1.820000e+02 182.000000 182.000000 182.000000
mean 1.323460e+17 3216.879121 4.776099 7.324176
std 3.307809e+17 4812.876819 0.138849 2.583280
min 3.089381e+06 2.000000 4.290000 1.000000
25% 3.107102e+07 73.000000 4.710000 6.000000
50% 4.375321e+07 3512.000000 4.710000 9.000000
75% 4.538668e+07 3512.000000 4.890000 9.000000
max 1.242049e+18 20189.000000 5.000000 11.000000
host_response_rate total_price
count 182.000000 182.000000
mean 98.538462 859.317363
std 8.012156 1498.684990
min 25.000000 19.000000
25% 100.000000 111.500000
50% 100.000000 350.000000
75% 100.000000 934.750000
max 100.000000 13165.000000 O método describe() relata as estatísticas relacionadas às colunas que têm valores numéricos. Essa é a primeira maneira de começar a entender seus dados. Por exemplo, a coluna host_rating relata as seguintes estatísticas interessantes:
- O conjunto de dados tem um total de 182 avaliações (o valor
da contagem). - A classificação máxima é 5, a mínima é 4,29 e a média é 4,77.
Ainda assim, as estatísticas acima podem não ser satisfatórias. Portanto, tente visualizar um gráfico de dispersão da coluna host_rating para ver se há algum padrão interessante que você possa querer investigar posteriormente. Veja como você pode criar um gráfico de dispersão com o seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
# Define figure size
plt.figure(figsize=(15, 10))
# Plot the data
sns.scatterplot(data=data, x="host_rating", y="listing_name")
# Labeling
plt.title("HOST RATINGS SCATTERPLOT", fontsize=20)
plt.xlabel("Host ratings", fontsize=16)
plt.ylabel("Houses", fontsize=16)
# Show plot
plt.show()O snippet acima faz o seguinte:
- Define o tamanho da imagem (em polegadas) com o método
figure(). - Cria um gráfico de dispersão usando o seaborn por meio do método
scatterplot()configurado com:Polylang placeholder do not modify
Esse é o resultado esperado:
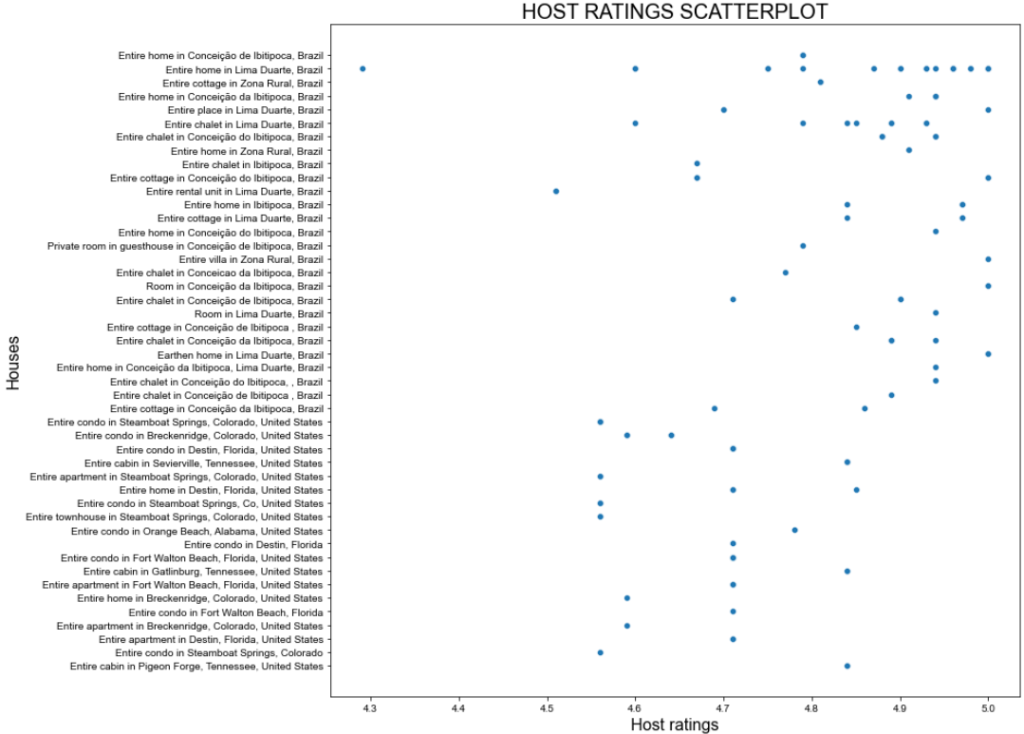
Ótimo enredo, mas podemos fazer melhor!
Etapa 5: Transformação e visualização de dados
O gráfico de dispersão anterior mostra que não há um padrão específico nas classificações dos anfitriões. No entanto, a maioria das classificações é superior a 4,7 pontos.
Imagine que você está planejando férias e quer se hospedar em um dos melhores lugares. Uma pergunta que você pode fazer a si mesmo é: “Quanto custa ficar em uma casa com uma classificação de pelo menos 4,8?”
Para responder a essa pergunta, primeiro você precisa transformar seus dados!
A transformação que você pode fazer é criar um novo quadro de dados em que a classificação seja maior que 4,8. Isso conterá a coluna listing_n``ame com os nomes dos apartamentos e a coluna total_price com seus preços.
Obtenha esse subconjunto e mostre suas estatísticas com:
# Filter the DataFrame
high_ratings = data[data["host_rating"] > 4.8][["listing_name", "total_price"]]
# Caltulate and print statistics
high_ratings_statistics = high_ratings.describe()
print(high_ratings_statistics)O snippet acima cria um novo quadro de dados chamado high_ratings da seguinte forma:
data["host_rating"] > 4.8filtra os valores maiores que 4.8 na colunahost_ratingsdo conjunto dedados.[["listing_name", "total_price"]]seleciona somente as colunaslisting_nameetotal_pricedo quadro de dadoshigh_ratings.
Abaixo está o resultado esperado:
total_price
count 78.000000
mean 321.061026
std 711.340269
min 19.000000
25% 78.250000
50% 116.000000
75% 206.000000
max 4230.000000As estatísticas mostram que o preço total médio dos apartamentos selecionados é de $321, com um mínimo de $19 e um máximo de $4230. Isso requer uma análise mais aprofundada!
Visualize um gráfico de dispersão dos preços das casas com classificações altas aplicando o mesmo snippet que você usou anteriormente. Tudo o que você precisa fazer é alterar as variáveis usadas no gráfico da seguinte forma:
# Define figure size
plt.figure(figsize=(12, 8))
# Plot the data
sns.scatterplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show grid for better visualization
sns.set_style("ticks", {'axes.grid': True})
# Show plot
plt.show()E este é o gráfico resultante:
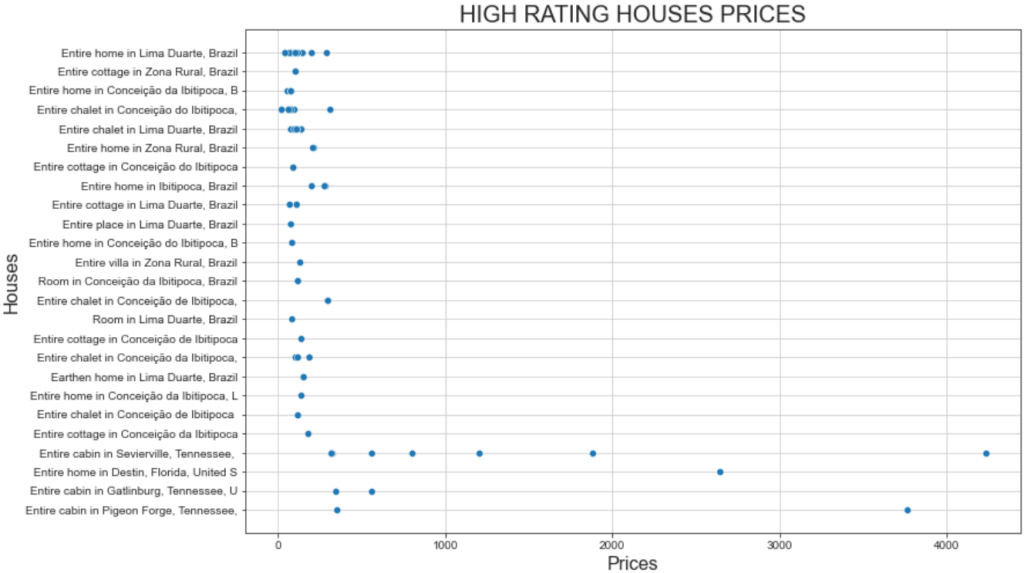
Esse gráfico mostra dois fatos interessantes:
- Os preços estão todos abaixo de US$ 500.
- A “Cabana inteira em Sevierville” e a “Cabana inteira em Pigeon” apresentam preços muito acima de US$ 1.000.
Uma maneira melhor de visualizar a faixa de preço é mostrar um gráfico de caixa. É assim que você pode fazer isso:
# Define figure size
plt.figure(figsize=(15, 10))
# Plotting the boxplot
sns.boxplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES - BOXPLOT', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show plot
plt.show()Dessa vez, o gráfico resultante será:
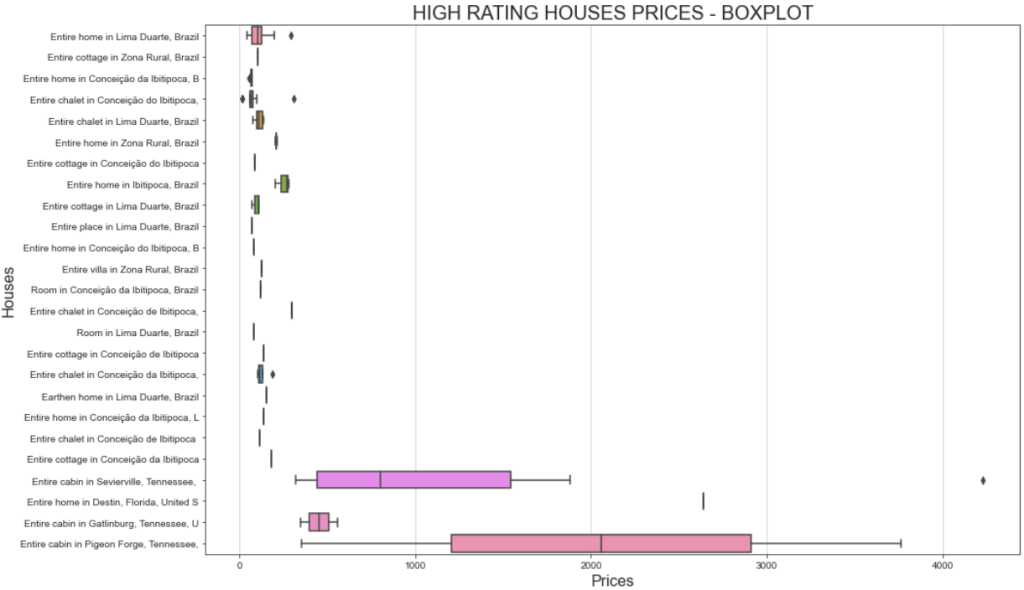
Se você estiver se perguntando por que a mesma casa pode ter custos diferentes, lembre-se de que você filtrou as classificações dos usuários. Isso significa que usuários diferentes pagaram de forma diferente e deixaram avaliações diferentes.
Além disso, a variação significativa de preço para a “Cabana inteira em Sevierville”, que varia de menos de US$ 1.000 a mais de US$ 4.000, pode ser devida à duração da estadia. Em detalhes, o conjunto de dados original inclui uma coluna chamada travel_details, que contém informações sobre a duração da estadia. A ampla faixa de preços pode indicar que alguns usuários alugaram a casa por um período prolongado. Uma análise mais profunda usando Python poderia ajudar a descobrir mais insights sobre isso!
Etapa 6: Investigações adicionais por meio da matriz de correlação
A análise de dados Python consiste em fazer perguntas e buscar respostas nos dados que você tem. Uma maneira eficaz de fazer essas perguntas é visualizar a matriz de correlação.
A matriz de correlação é uma tabela que mostra os coeficientes de correlação de diferentes variáveis. O coeficiente de correlação mais usado é o Coeficiente de Correlação de Pearson (PCC), que mede a correlação linear entre duas variáveis. Seus valores variam de -1 a +1, o que significa:
- +1: Se o valor de uma variável aumenta, a outra aumenta linearmente.
- -1 : Se o valor de uma variável aumenta, a outra diminui linearmente.
- 0: Não é possível dizer nada sobre a relação linear das duas variáveis (isso requer uma análise não linear).
Em estatística, os valores da correlação linear definem o seguinte:
- 0,1-0,5: baixa correlação.
- 0,6-1: alta correlação.
- 0: sem correlação.
Para exibir a matriz de correlação do quadro de dados, você pode digitar o seguinte:
# Set the images dimensions
plt.figure(figsize=(12, 10))
# Labeling
plt.title('CORRELATION MATRIX', fontsize=20)
plt.xticks(fontsize=16) # x-axis font size
plt.yticks(fontsize=16) # y-axis font size
# Applying mask
mask = np.triu(np.ones_like(numeric_data.corr()))
dataplot = sns.heatmap(numeric_data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})
#Add this code before creating the correlation matrix
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# Correlation matrix
dataplot = sns.heatmap(data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})O snippet acima faz o seguinte:
- O método
np.triu()é usado para diagonalizar uma matriz. Isso é usado para uma melhor visualização da matriz, de modo que ela seja mostrada como um triângulo e não como um quadrado. - O método
sns.heatmap()cria um mapa de calor. Ele também é usado para melhorar a visualização. Dentro dele, o métododata.corr()é o que realmente calcula os coeficientes de Pearson para cada coluna dosdadosdo quadro de dados.
Abaixo está o resultado que você obterá:

A ideia principal ao interpretar uma matriz de correlação é encontrar variáveis que tenham alta correlação, pois elas serão o ponto de partida para uma análise nova e mais profunda. Por exemplo:
- As variáveis
latelongtêm uma correlação de -0,98. Isso é esperado, pois a latitude e a longitude estão fortemente correlacionadas ao definir um local específico na Terra. - As variáveis
host_ratingelongtêm uma correlação de -0,69. Esse é um resultado interessante, o que significa que a classificação do anfitrião está altamente correlacionada com a variável longitude. Portanto, parece que as casas localizadas em uma determinada área do mundo têm altas classificações de host. - As variáveis
latelongtêm, respectivamente, uma correlação de 0,63 e -0,69 com opreço. Isso é suficiente para dizer que o preço por dia é altamente influenciado pela localização.
Em sua análise, você também deve procurar variáveis não correlacionadas. Por exemplo, o coeficiente das variáveis is_supperhost e preço é -0,18, o que significa que os superhosts não têm os preços mais altos.
Agora que os principais conceitos estão claros, é sua vez de explorar e analisar seus dados!
Etapa 7: Juntar tudo
Esta é a aparência final do Jupyter Notebook para análise de dados com Python:









Observe a presença de diferentes células, cada uma com sua saída.
O processo por trás da análise de dados com Python
A seção acima o guiou pelo processo de análise de dados com Python. Embora possa ter parecido uma abordagem passo a passo orientada pela oportunidade, na verdade ela foi construída com base nas práticas recomendadas a seguir:
- Recuperação de dados: Se você tiver a sorte de ter os dados de que precisa em um banco de dados, sorte sua! Caso contrário, você precisará recuperá-los usando métodos populares de obtenção de dados, como oweb scraping.
- Limpeza de dados: Manipular
NaNs, agregar dados e aplicar os primeiros filtros do conjunto de dados inicial. - Exploração de dados: A exploração de dados – às vezes também chamada de descoberta de dados – éa parte mais importante da análise de dados com Python. Ela requer a produção de gráficos básicos para ajudá-lo a entender como seus dados estão estruturados ou se seguem padrões específicos.
- Manipulação de dados: Depois de obter as principais ideias por trás dos dados que você está analisando, é preciso manipulá-los. Essa parte requer a filtragem de conjuntos de dados e, muitas vezes, a combinação de mais de dois conjuntos de dados em um só (como se você estivesse fazendo junções de tabelas no SQL).
- Visualização de dados: Esta é a parte final, na qual você apresenta visualmente seus dados fazendo vários gráficos nos conjuntos de dados manipulados.
Conclusão
Neste guia sobre análise de dados com Python, você aprendeu por que deve usar Python para analisar dados e quais bibliotecas comuns podem ser usadas para essa finalidade. Você também passou por um tutorial passo a passo e aprendeu o processo a seguir se quiser realizar a análise de dados em Python.
Você viu que o Jupyter Notebook o ajuda a criar subconjuntos de seus dados, visualizá-los e descobrir insights poderosos. Tudo isso enquanto mantém tudo estruturado no mesmo ambiente. Agora, onde você pode encontrar conjuntos de dados prontos para uso? A Bright Data tem o que você precisa!
A Bright Data opera uma rede proxy grande, rápida e confiável, usada por muitas empresas da Fortune 500 e por mais de 20.000 clientes. Ela é usada para recuperar dados da Web de forma ética e oferecê-los em um vasto mercado de conjuntos de dados, que inclui:
- Conjuntos de dados comerciais: Dados de fontes importantes como LinkedIn, CrunchBase, Owler e Indeed.
- Conjuntos de dados de comércio eletrônico: Dados da Amazon, Walmart, Target, Zara, Zalando, Asos e muitos outros.
- Conjuntos de dados de imóveis: Dados de sites como Zillow, MLS e outros.
- Conjuntos de dados de mídia social: Dados do Facebook, Instagram, YouTube e Reddit.
- Conjuntos de dados financeiros: Dados do Yahoo Finance, Market Watch, Investopedia e muito mais.
Crie uma conta gratuita na Bright Data hoje mesmo e explore nossos conjuntos de dados.






