
Neste guia, você aprenderá:
- O que é a Pydantic AI e o que a torna única como uma estrutura para a criação de agentes de IA.
- Por que a Pydantic AI combina bem com o servidor Web MCP da Bright Data para criar agentes que podem acessar a Web.
- Como integrar o Pydantic ao Web MCP da Bright Data para criar um agente de IA com o apoio de dados reais.
Vamos mergulhar de cabeça!
O que é IA Pydantic?
O Pydantic AI é uma estrutura de agente Python desenvolvida pelos criadores do Pydantic, a biblioteca de validação de dados mais amplamente usada para Python.
Em comparação com outras estruturas de agentes de IA, o Pydantic AI enfatiza a segurança de tipos, os resultados estruturados e a integração com dados e ferramentas do mundo real. Em detalhes, algumas de suas principais características são:
- Suporte para OpenAI, Anthropic, Gemini, Cohere, Mistral, Groq, HuggingFace, Deepseek, Ollama e outros provedores de LLM.
- Validação de saída estruturada por meio de modelos Pydantic.
- Depuração e monitoramento por meio do Pydantic Logfire.
- Injeção de dependência opcional para ferramentas, prompts e validadores.
- Respostas LLM em fluxo contínuo com validação de dados em tempo real.
- Suporte a vários agentes e gráficos para fluxos de trabalho complexos.
- Integração de ferramentas via MCP e incluindo chamadas HTTP.
- Fluxo Pythonic familiar para criar agentes de IA como aplicativos Python padrão.
- Suporte integrado para testes unitários e desenvolvimento iterativo.
A biblioteca é de código aberto e já alcançou mais de 11 mil estrelas no GitHub.
Por que combinar a IA Pydantic com um servidor MCP para recuperação de dados da Web?
Os agentes de IA criados com o Pydantic AI herdam as limitações do LLM subjacente. Isso inclui a falta de acesso a informações em tempo real, o que pode levar a respostas imprecisas. Felizmente, esse problema pode ser facilmente resolvido ao equipar o agente com dados atualizados e com a capacidade de realizar a exploração da Web em tempo real.
É aí que entra o Web MCP da Bright Data. Criado com base no Node.js, esse servidor MCP se integra ao conjunto de ferramentas de recuperação de dados prontas para IA da Bright Data. Essas ferramentas permitem que seu agente acesse o conteúdo da Web, consulte conjuntos de dados estruturados, pesquise na Web e interaja com páginas da Web em tempo real.
No momento, as ferramentas do MCP no servidor incluem:
| Ferramenta | Descrição |
|---|---|
scrape_as_markdown |
Extraia o conteúdo de um único URL de página da Web com opções avançadas de extração, retornando os resultados como Markdown. Pode contornar a detecção de bots e o CAPTCHA. |
mecanismo_de_busca |
Extraia resultados de pesquisa do Google, Bing ou Yandex, retornando dados SERP em formato markdown (URL, título, snippet). |
scrape_as_html |
Recupere o conteúdo de uma página da Web a partir de um URL com opções avançadas de extração, retornando o HTML completo. Pode contornar a detecção de bots e o CAPTCHA. |
Estatísticas da sessão |
Fornecer estatísticas sobre o uso da ferramenta durante a sessão atual. |
scraping_browser_go_back |
Navegue de volta para a página anterior na sessão do navegador de raspagem. |
scraping_browser_go_forward |
Navegue para a próxima página na sessão do navegador de raspagem. |
scraping_browser_click |
Executar uma ação de clique em um elemento específico por seletor. |
raspagem de links do navegador |
Recupera todos os links, incluindo texto e seletores, na página atual. |
scraping_browser_type |
Insira texto em um elemento especificado no navegador de raspagem. |
scraping_browser_wait_for |
Aguarde até que um determinado elemento fique visível na página antes de continuar. |
scraping_browser_screenshot (captura de tela do navegador) |
Captura uma captura de tela da página atual do navegador. |
scraping_browser_get_html |
Recupera o conteúdo HTML da página atual no navegador. |
scraping_browser_get_text |
Extrai o conteúdo do texto visível da página atual. |
Além disso, há mais de 40 ferramentas especializadas para coletar dados estruturados de uma ampla variedade de sites (por exemplo, Amazon, Yahoo Finance, TikTok, LinkedIn e outros) usando APIs do Web Scraper. Por exemplo, a ferramenta web_data_amazon_product reúne informações detalhadas e estruturadas de produtos da Amazon, aceitando um URL de produto válido como entrada.
Agora, dê uma olhada em como usar essas ferramentas de MCP no Pydantic AI!
Como integrar o Pydantic AI com o servidor Bright MCP em Python
Nesta seção, você aprenderá a usar o Pydantic AI para criar um agente de IA. O agente será equipado com recursos de raspagem, recuperação e interação de dados ao vivo do servidor Web MCP.
Como exemplo, demonstraremos como o agente pode recuperar dados de produtos da Amazon em tempo real. Lembre-se de que esse é apenas um dos muitos casos de uso possíveis. O agente de IA pode acessar qualquer uma das mais de 50 ferramentas disponíveis no servidor MCP para executar uma ampla gama de tarefas.
Siga este passo a passo guiado para criar seu agente de IA com tecnologia Gemini + Bright Data MCP usando o Pydantic AI!
Pré-requisitos
Para replicar o exemplo de código, verifique se você tem os seguintes itens instalados localmente:
- Python 3.10 ou superior.
- Node.js (recomendamos a versão LTS mais recente).
Você também precisará de:
- Uma conta da Bright Data.
- Uma chave de API Gemini (ou uma chave de API de outro provedor de LLM compatível, como OpenAI, Anthropic, Deepseek, Ollama, Groq, Cohere e Mistral).
Não se preocupe em configurar as chaves de API ainda. As etapas abaixo o orientarão na configuração das credenciais da Bright Data e da Gemini quando chegar a hora.
Embora não seja estritamente necessário, esse conhecimento prévio o ajudará a seguir o tutorial:
- Uma compreensão geral de como o MCP funciona.
- Familiaridade básica com o funcionamento dos agentes de IA.
- Algum conhecimento sobre o servidor Web MCP e suas ferramentas disponíveis.
- Conhecimento básico de programação assíncrona em Python.
Etapa 1: Crie seu projeto Python
Abra seu terminal e crie uma nova pasta para seu projeto:
mkdir pydantic-ai-mcp-agentA pasta pydantic-ai-mcp-agent conterá todo o código do seu agente de IA Python.
Navegue até a pasta recém-criada e configure um ambiente virtual dentro dela:
cd pydantic-ai-mcp-agent
python -m venv venvAgora, abra a pasta do projeto em seu IDE Python preferido. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Crie um arquivo chamado agent.py na raiz do seu projeto. Neste ponto, sua estrutura de pastas deve ter a seguinte aparência:
pydantic-ai-mcp-agent/
├── venv/
└── agent.pyO arquivo agent.py está vazio no momento, mas em breve conterá a lógica para integrar a IA do Pydantic ao servidor MCP da Web da Bright Data.
Ative o ambiente virtual usando o terminal em seu IDE. No Linux ou macOS, execute este comando:
source venv/bin/activateDe forma equivalente, no Windows, inicie:
venv/Scripts/activateEstá tudo pronto! Agora você tem um ambiente Python pronto para criar um agente de IA com acesso a dados da Web.
Etapa 2: Instalar o Pydantic AI
Em seu ambiente virtual ativado, instale todos os pacotes necessários do Pydantic AI com:
pip install "pydantic-ai-slim[google,mcp]" Isso instala o pydantic-ai-slim, uma versão leve do pacote completo do pydantic-ai que evita o uso de dependências desnecessárias.
Nesse caso, como você planeja integrar seu agente ao servidor Web MCP da Bright Data, precisará da extensão mcp. E como integraremos o Gemini como provedor de LLM, você também precisará da extensão google.
Observação: Para outros modelos ou provedores, consulte a documentação do modelo para ver quais dependências opcionais são necessárias.
Em seguida, adicione essas importações em seu arquivo agent.py:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderLegal! Agora você pode usar o Pydantic AI para a criação de agentes.
Etapa 3: Configurar a leitura das variáveis de ambiente
Seu agente de IA interagirá com serviços de terceiros, como Bright Data e Gemini, por meio da API. Não codifique suas chaves de API em seu código Python. Em vez disso, carregue-as a partir de variáveis de ambiente para aumentar a segurança e a capacidade de manutenção.
Para simplificar o processo, aproveite a biblioteca python-dotenv. Com seu ambiente virtual ativado, instale-a executando:
pip install python-dotenvEm seguida, em seu arquivo agent.py, importe a biblioteca e carregue as variáveis de ambiente com load_dotenv():
from dotenv import load_dotenv
load_dotenv()Isso permite que o script leia as variáveis de ambiente de um arquivo .env local. Portanto, vá em frente e crie um arquivo .env dentro da pasta do seu projeto:
pydantic-ai-mcp-agent/
├── venv/
├── agent.py
└── .env # <---------------Agora você pode acessar as variáveis de ambiente da seguinte forma:
env_value = os.getenv("<ENV_NAME>")Não se esqueça de importar o módulo os da biblioteca padrão do Python:
import osAqui vamos nós! Agora você está pronto para carregar chaves Api com segurança a partir do arquivo .env.
Etapa 4: começar a usar o servidor MCP da Bright Data
Se você ainda não o fez, crie uma conta na Bright Data. Se já tiver uma, basta fazer o login.
Em seguida, siga as instruções oficiais para configurar sua chave de API da Bright Data. Para simplificar, assumimos que você está usando um token com permissões de administrador nesta seção.
Instale o Web MCP da Bright Data globalmente via npm:
npm install -g @brightdata/mcpEm seguida, teste se tudo funciona com o comando Bash abaixo:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOu, no Windows, o comando PowerShell equivalente é:
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpNo comando acima, substitua o espaço reservado pelo espaço reservado com a API real da Bright Data que você recuperou anteriormente. Ambos os comandos definem a variável de ambiente API_TOKEN necessária e iniciam o servidor MCP por meio do pacote npm @brightdata/mcp.
Se tudo estiver funcionando corretamente, seu terminal exibirá registros semelhantes a este:

Na primeira vez que você iniciar o servidor MCP, ele criará automaticamente duas zonas padrão em sua conta da Bright Data:
mcp_unlocker: Uma zona para o Web Unlocker.mcp_browser: Uma zona para a API do navegador.
Essas duas zonas permitem que o servidor MCP execute todas as ferramentas que ele expõe.
Para verificar isso, faça login no painel da Bright Data e navegue até a página“Proxies & Scraping Infrastructure“. Você verá as seguintes zonas criadas automaticamente:
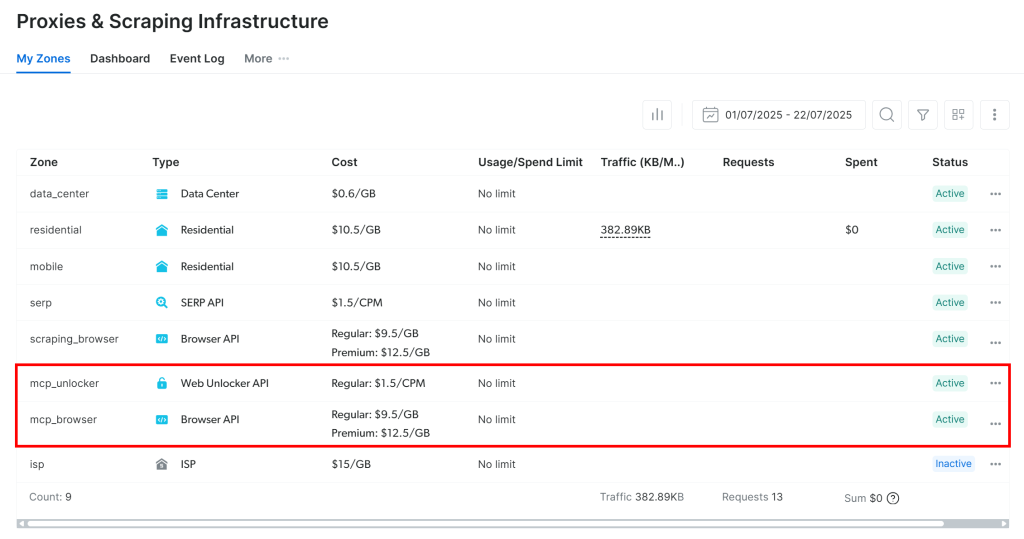
Observação: se você não estiver usando um token de API com permissões de administrador, terá que criar as zonas manualmente. De qualquer forma, você sempre pode especificar os nomes das zonas nos envs, conforme explicado na documentação oficial.
Por padrão, o Web MCP expõe apenas as ferramentas search_engine e scrape_as_markdown. Para desbloquear recursos avançados, como automação do navegador e extração de dados estruturados, é necessário ativar o Modo Pro definindo a variável de ambiente PRO_MODE=true.
Excelente! O Web MCP funciona como um encanto.
Etapa 5: Conectar-se ao Web MCP
Agora que você confirmou que seu computador pode executar o Web MCP, conecte-se a ele!
Comece adicionando sua chave da API da Bright Data ao arquivo .env:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Substitua o com a chave real da API da Bright Data que você obteve anteriormente.
Em seguida, leia-o no arquivo agent.py com:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Lembre-se de que o Pydantic AI oferece suporte a três métodos de conexão com um servidor MCP:
- Usando o transporte Streamable HTTP.
- Usando o transporte HTTP SSE.
- Executar o servidor como um subprocesso e conectar-se via
stdio.
Se você não estiver familiarizado com os dois primeiros métodos, leia nosso guia sobre SSE vs. Streamable HTTP para obter uma explicação mais detalhada.
Nesse caso, você deseja executar o servidor como um subprocesso (terceiro método). Para fazer isso, inicialize uma instância de MCPServerStdio conforme mostrado abaixo:
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)O que essas linhas de código fazem é essencialmente iniciar o Web MCP usando o mesmo comando npx que você executou anteriormente. Ele define a variável de ambiente API_TOKEN usando sua chave de API da Bright Data para autenticação. Além disso, ele ativa o PRO_MODE para que você tenha acesso a todas as ferramentas disponíveis, inclusive as avançadas.
Excelente! Agora você configurou com êxito a conexão com o Web MCP local no código.
Etapa nº 6: Configurar o LLM
Observação: esta seção refere-se ao Gemini, o LLM escolhido para o tutorial. No entanto, você pode adaptá-la facilmente ao OpenAI ou a qualquer outro LLM compatível, seguindo a documentação oficial.
Comece recuperando sua chave de API do Gemini e adicione-a ao seu arquivo .env da seguinte forma:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Substitua o pelo espaço reservado com sua chave de API real.
Em seguida, importe as bibliotecas Pydantic AI necessárias para a integração com o Gemini:
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderEssas importações permitem que você se conecte às APIs do Google e configure um modelo Gemini. Observe como você não precisa ler manualmente a GOOGLE_API_KEY do arquivo .env. O motivo é que o GoogleProvider usa o google-genai, que lê automaticamente a chave da API do GOOGLE_API_KEY env.
Agora, inicialize as instâncias do provedor e do modelo:
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)Incrível! Isso permitirá que o agente de IA Pydantic se conecte ao modelo gemini-2.5-flash por meio da API do Google, que é de uso gratuito.
Etapa nº 7: definir o agente de IA Pydantic
Defina um Pydantic AI Agent que use o LLM configurado anteriormente e se conecte ao servidor Web MCP:
agent = Agent(model, toolsets=[server])Perfeito! Com apenas uma única linha de código, você acabou de instanciar um objeto Agent. Isso representa um agente de IA que pode lidar com suas tarefas usando as ferramentas expostas pelo servidor Web MCP.
Etapa #8: Lançar seu agente
Para testar seu agente de IA, você precisa escrever um prompt que envolva uma tarefa de extração de dados da Web (na interação). Isso o ajuda a verificar se o agente usa as ferramentas da Bright Data conforme o esperado.
Um bom ponto de partida é pedir que ele recupere os dados do produto de uma página da Amazon, como este:
“Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/”
Normalmente, se você enviar uma solicitação como essa diretamente para a Gemini, uma das duas coisas acontecerá:
- A solicitação falharia devido aos sistemas anti-bot da Amazon (por exemplo, o Amazon CAPTCHA), que impedem o Gemini de acessar o conteúdo da página.
- Ele retornaria informações alucinadas ou inventadas sobre o produto, já que não pode acessar a página ativa.
Tente o prompt diretamente no Gemini. Você provavelmente receberá uma mensagem informando que não foi possível acessar a página da Amazon, seguida dos detalhes do produto fabricado, conforme abaixo:

Graças à integração com o servidor Web MCP, isso não deve acontecer em sua configuração. Em vez de falhar ou adivinhar, seu agente deve usar a ferramenta web_data_amazon_product para recuperar dados de produto estruturados e em tempo real da página da Amazon e, em seguida, retorná-los em um formato limpo e legível.
Como o método para interrogar o agente de IA Pydantic é assíncrono, envolva a lógica de execução em uma função assíncrona da seguinte forma:
async def main():
async with agent:
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())Não se esqueça de importar asyncio da biblioteca padrão do Python:
import asyncioMissão concluída! Tudo o que resta é executar o código completo e ver se o agente atende às expectativas.
Etapa nº 9: Juntar tudo
Este é o código final do agent.py:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProvider
from dotenv import load_dotenv
import os
import asyncio
# Load the environment variables from the .env file
load_dotenv()
# Read the API key from the envs for integration with the Bright Data Web MCP server
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Connect to the Bright Data Web MCP server
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)
# Configure the Google LLM model
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)
# Initialize the AI agent with Gemini and Bright Data's Web MCP server integration
agent = Agent(model, toolsets=[server])
async def main():
async with agent:
# Ask the AI Agent to perform a scraping task
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
# Get the result produced by the agent and print it
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())Uau! Graças à Pydantic AI e à Bright Data, em cerca de 50 linhas de código, você acabou de criar um agente de IA avançado com tecnologia MCP.
Execute o agente de IA com:
python agent.pyNo terminal, você deve ver uma saída como a seguinte:

Como você pode ver ao verificar a página do produto da Amazon mencionada no prompt, as informações retornadas pelo agente de IA são precisas:
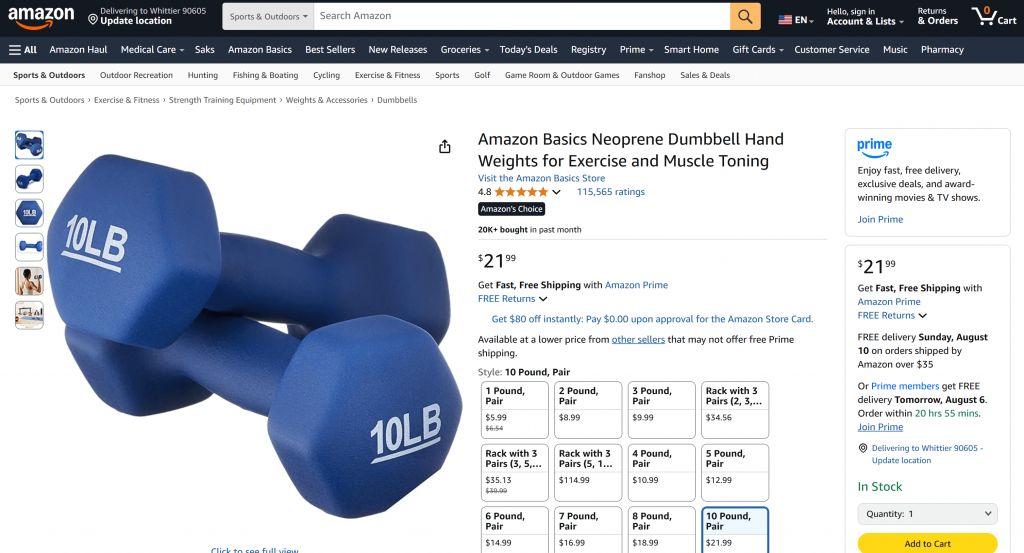
Isso ocorre porque o agente usou a ferramenta web_data_amazon_product fornecida pelo servidor Web MCP para recuperar dados de produtos novos e estruturados da Amazon no formato JSON.
E pronto! As expectativas foram atendidas, e a integração do Pydantic AI + MCP funcionou exatamente como planejado.
Próximas etapas
O agente de IA criado aqui é funcional, mas serve apenas como ponto de partida. Considere levá-lo para o próximo nível:
- Implementar um loop REPL para conversar com o agente na CLI ou integrá-lo a ferramentas de bate-papo da GUI, como o Gradio.
- Ampliação das ferramentas do Bright Data MCP com a definição de suas próprias ferramentas personalizadas.
- Adição de depuração e monitoramento usando o Pydantic Logfire.
- Transformando seu agente em um agente autônomo RAG em um fluxo de trabalho multiagente.
- Definição de validadores de função personalizados para integridade dos dados de saída.
Conclusão
Neste artigo, você aprendeu como integrar o Pydantic AI com o servidor Web MCP da Bright Data para criar um agente de IA capaz de acessar a Web. Essa integração é possível graças ao suporte incorporado do Pydantic AI para MCP.
Para criar agentes mais sofisticados, explore toda a gama de serviços disponíveis na infraestrutura de IA da Bright Data. Essas soluções podem alimentar uma ampla variedade de cenários agênticos.
Crie uma conta da Bright Data gratuitamente e comece a fazer experiências com nossas ferramentas de dados da Web prontas para IA!




