

Neste artigo, abordaremos:
- O que é o servidor Playwright MCP e como ele pode ser usado para raspagem da Web
- As diferentes ferramentas disponíveis no servidor Playwright MCP
- Como o servidor Bright Data Web MCP pode oferecer uma alternativa mais simples para a raspagem da Web.
Vamos nos aprofundar!
O servidor Playwright MCP
O Playwright é amplamente conhecido como uma ferramenta de automação de navegador, geralmente usada para testar e automatizar tarefas de navegador. O Playwright MCP Server baseia-se nessa funcionalidade, só que desta vez foi projetado não para uso humano direto, mas para agentes de IA.
Ao executar o servidor, você pode conectar qualquer host MCP e conceder aos agentes de IA acesso ao kit completo de ferramentas de automação do Playwright.
Isso significa que seu agente de IA pode interagir com um navegador da Web exatamente como um ser humano faria, realizando ações como fazer compras on-line, buscar as últimas notícias, responder a e-mails e muito mais.
Neste artigo, nosso foco principal será a raspagem da Web. Com o Playwright MCP Server, você obtém as ferramentas de baixo nível necessárias não apenas para a automação do navegador, mas também para permitir que um LLM raspe e extraia dados diretamente da Web.
O servidor Playwright MCP
Como todo servidor MCP, o servidor Playwright MCP vem com um conjunto de ferramentas que podem ser expostas a um agente de IA. Essas ferramentas são mapeadas diretamente para as APIs do Playwright que os desenvolvedores já conhecem e usam. Vamos dar uma olhada em algumas das mais importantes:
- Browser_click: Permite que o agente de IA clique em elementos, assim como um ser humano usando um mouse.
- Browser_drag: Permite interações de arrastar e soltar.
- Browser_close (Fechar navegador): Fecha a instância do navegador.
- Browser_evaluate: Permite que o agente de IA execute o código JavaScript diretamente na página.
- Browser_file_upload: Lida com uploads de arquivos por meio do navegador.
- Browser_fill_form: Preenche formulários em uma página da Web.
- Browser_hover: Move o ponteiro do mouse sobre os elementos.
- Browser_navigate: Navega para qualquer URL.
- Browser_press_key: Simula o pressionamento de teclas, dando ao agente acesso total à entrada do teclado.
Com todas essas ferramentas à disposição do agente de IA, ele pode navegar facilmente pela Web e extrair dados. Vamos ver como podemos fazer isso.
Extração da Web com o servidor Playwright MCP
Nesta seção, executaremos uma tarefa de coleta de dados da Web usando o servidor Playwright MCP. Nosso agente de IA coletará as informações mais recentes sobre preços dos modelos do iPhone 16. Para simplificar, limitaremos a tarefa a uma única fonte: Best Buy.
Configuração do servidor
Para executar o servidor Playwright MCP, precisamos de um host MCP. Você pode usar qualquer host de sua escolha, como o Claude Desktop, o Cursor ou o Gemini CLI. Para este artigo, usaremos o VS Code.
O servidor Playwright MCP é um servidor MCP local implementado em Node.js, portanto, antes de prosseguir, verifique se você tem o Node instalado.
Para configurar o servidor, precisamos adicionar a seguinte configuração ao nosso host MCP:
{
"servers": {
"playwright": {
"comando": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Essa configuração se aplica à forma como os servidores MCP são configurados no VS Code, embora possa ser ligeiramente diferente em outros hosts MCP. Quando a configuração estiver concluída, nosso agente de IA terá acesso às ferramentas fornecidas pelo servidor. Com isso em mãos, podemos começar a raspagem.
Raspagem com o servidor MCP
A primeira etapa é navegar até o site da BestBuy. Para isso, basta instruir o agente de IA a abrir o site, e ele usará a ferramenta Browser_navigate para chegar lá.
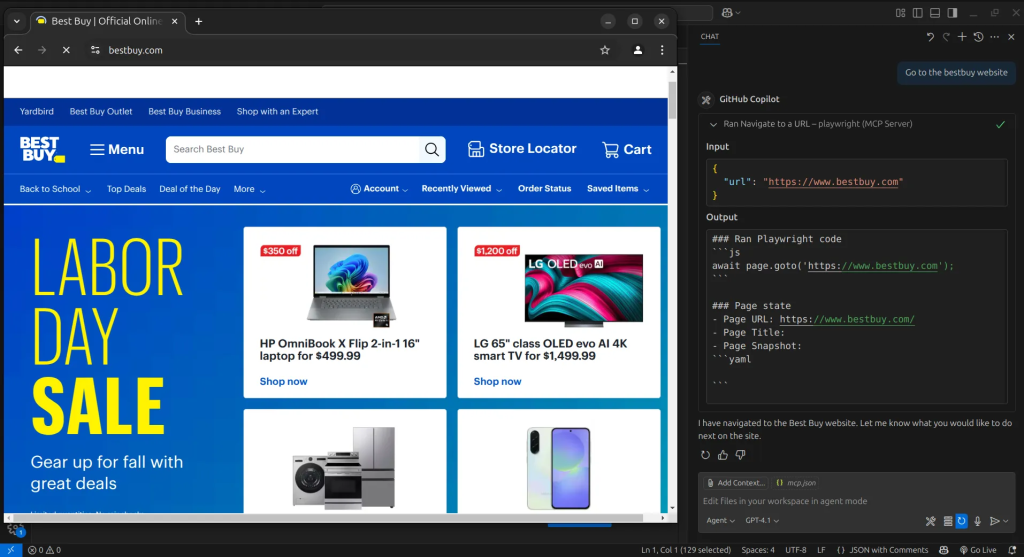
Em seguida, instruiremos o agente de IA a pesquisar o iPhone 16. Para isso, ele usará a ferramenta Browser_press_key para inserir a consulta de pesquisa.

Em seguida, o agente de IA usará a ferramenta Browser_click para clicar no botão de pesquisa.
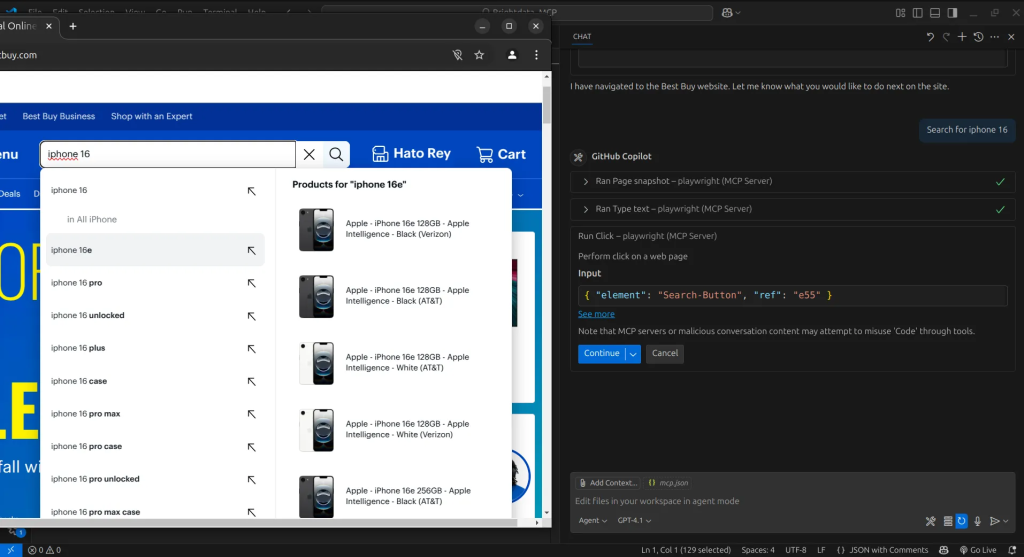
Com isso, obtemos nossos resultados. Em cada etapa, à medida que o agente navega na página, ele captura um instantâneo do estado atual. Podemos então usar esses instantâneos para instruir o agente a extrair as informações de que precisamos e organizá-las em um formato estruturado.
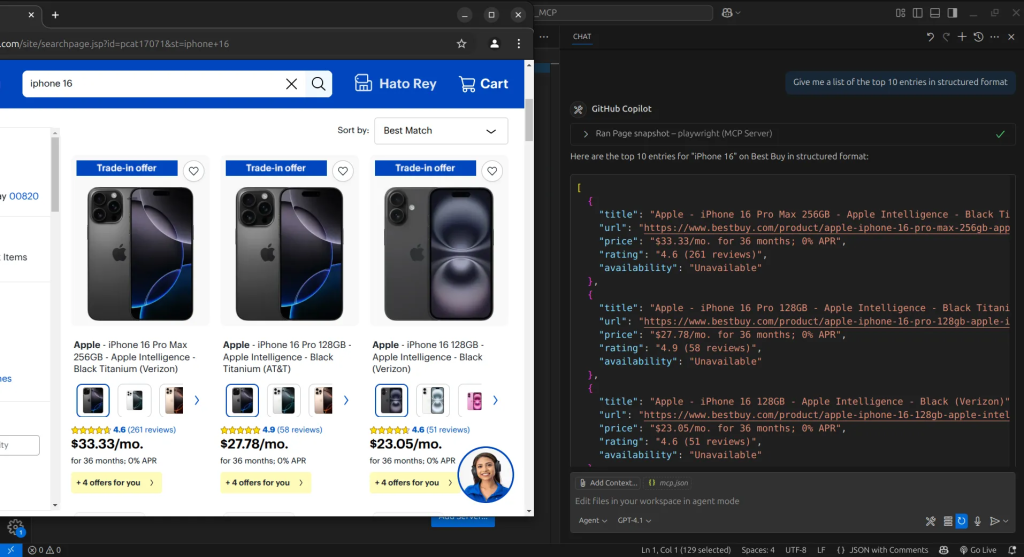
Com essa abordagem, conseguimos extrair o site com sucesso. No entanto, embora ela nos dê controle total para fazer quase tudo o que quisermos, ainda é de nível bastante baixo. Isso pode parecer excessivo se nosso único objetivo for extrair dados, pois talvez não precisemos dos recursos mais amplos de automação da Web.
A seguir, vamos explorar como o servidor MCP da Web da Bright Data pode realizar a mesma tarefa de uma perspectiva de nível muito mais alto.
Servidor MCP da Web da Bright Data: Um servidor MCP de raspagem da Web de alto nível
O servidor MCP Bright Data Web vem com uma série de ferramentas de alto nível criadas especificamente para raspagem da web. Isso inclui ferramentas para extrair dados de plataformas como a Amazon, recuperar perfis individuais e de empresas e até mesmo coletar perfis, postagens e carretéis do Instagram.
Diferentemente do Playwright MCP, que opera em um nível inferior, o servidor Bright Data Web MCP simplifica o processo de raspagem para seu agente de IA. Ele até mesmo lida com páginas da Web protegidas por detecção de bots ou CAPTCHA, dando ao seu agente acesso confiável onde os métodos tradicionais podem falhar.
Para este passo a passo, usaremos o servidor Bright Data Web MCP para executar a mesma tarefa que abordamos anteriormente com o Playwright MCP. Ele já vem pronto para uso e oferece duas ferramentas principais:
- Ferramenta de mecanismo de pesquisa
- Ferramenta de coleta de dados como markdown
Outras ferramentas podem ser desbloqueadas com a ativação do Modo Pro, mas, por enquanto, vamos nos limitar a essas duas. Você pode encontrar mais detalhes neste artigo.
Configuração do servidor
Ao contrário do servidor Playwright MCP, que é executado localmente, o servidor Bright Data Web MCP é um servidor MCP remoto. Isso significa que o processo de configuração é um pouco diferente. Veja a seguir como você pode configurá-lo no VS Code:
"BrightData": {
"url": "https://mcp.brightdata.com/mcp?token=YOUR_API_KEY",
}Para se conectar, você precisará de sua chave de API da Bright Data. Depois de configurado, seu agente estará pronto para começar a fazer a coleta.
Extração com o servidor MCP
Primeiro, instruiremos o agente a realizar uma pesquisa na Web sobre o preço do iPhone 16.

Em seguida, o agente usou a ferramenta de mecanismo de pesquisa do servidor para realizar a solicitação.

Depois de obter os resultados, instruímos o agente a extrair informações de um site de nossa escolha, neste caso, a Apple Store. Em seguida, o agente usa a ferramenta scrape data as markdown para extrair o conteúdo, retornando-o no formato markdown, que o agente pode processar e entender facilmente.
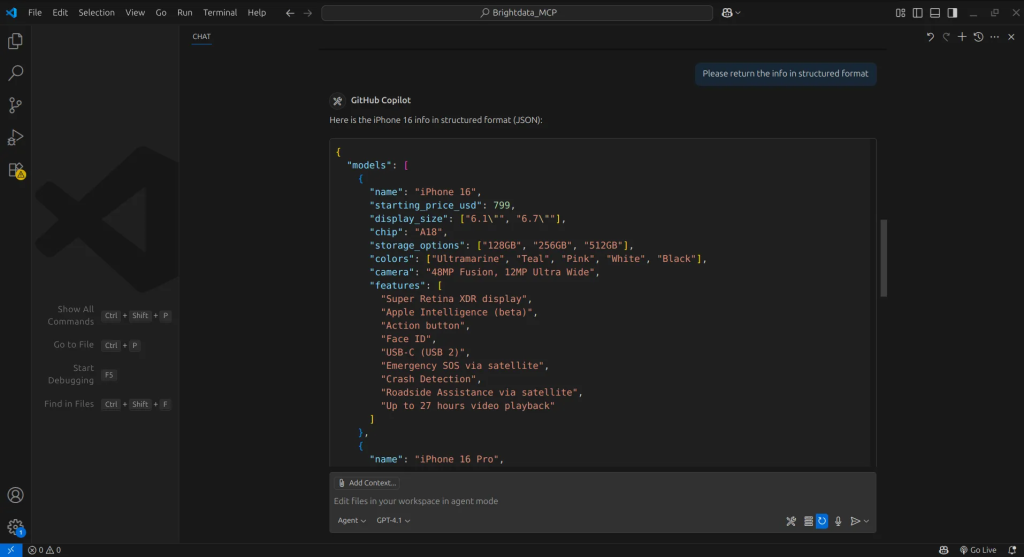
Com as informações extraídas, podemos instruir o agente a organizá-las em um formato estruturado e, assim, temos nossos dados.
Neste exemplo, usamos apenas duas ferramentas para concluir a tarefa de raspagem. No entanto, o servidor do Bright Data Web MCP também oferece ferramentas adicionais no Modo Pro que você pode explorar para casos de uso mais avançados. Você pode encontrar mais exemplos neste artigo detalhado.
Conclusão
Neste artigo, exploramos como os servidores MCP podem ser usados para raspar a Web com a ajuda de agentes de IA. Primeiro, analisamos o servidor Playwright MCP, que fornece acesso de baixo nível à automação do navegador, dando ao seu agente controle total sobre cada interação. Em seguida, exploramos o servidor Web MCP da Bright Data, que opera em um nível mais alto e equipa seu agente com ferramentas especializadas projetadas especificamente para raspagem da Web, mesmo em sites protegidos por detecção de bots.
Ambas as abordagens têm seus pontos fortes: o Playwright é ideal quando você precisa de um controle detalhado do navegador, enquanto a Bright Data simplifica o processo, permitindo que você se concentre apenas na extração das informações necessárias.
Agora é sua vez de experimentar os dois servidores MCP e decidir qual deles se adapta melhor ao seu próximo projeto.






