
Este guia mostra como conectar o Bright Data Web MCP ao LangGraph para criar um agente de pesquisa de IA que pode pesquisar, extrair e raciocinar sobre dados da web ao vivo.
Neste guia, você aprenderá como:
- Criar um agente LangGraph que controla seu próprio ciclo de raciocínio
- Dê a esse agente acesso à web ao vivo usando o nível gratuito do Bright Data Web MCP
- Conectar ferramentas de pesquisa e extração a um agente funcional
- Atualizar o mesmo agente com automação do navegador usando as ferramentas premium do Web MCP
Introdução ao LangGraph
O LangGraph permite que você crie aplicativos LLM em que o fluxo de controle é explícito e facilmente inspecionável, não oculto em prompts ou novas tentativas. Cada etapa se torna um nó. Cada transição é definida por você.
O agente funciona como um loop. O modelo LLM lê o estado atual e responde ou solicita uma ferramenta. Se ele chamar uma ferramenta (como pesquisa na web), o resultado é adicionado de volta ao estado e o modelo decide novamente. Quando tem informações suficientes, o loop termina.
Essa é a principal diferença entre fluxos de trabalho e agentes. Um fluxo de trabalho segue etapas fixas. Um agente faz um loop: decide, age, observa, decide novamente. Esse loop é a mesma base usada em sistemas RAG agenticos, onde a recuperação acontece dinamicamente, em vez de em pontos fixos.
O LangGraph oferece uma maneira estruturada de construir esse ciclo, com memória, chamada de ferramentas e condições explícitas de parada. Você pode ver todas as decisões que o agente toma e controlar quando ele para.
Por que usar o Bright Data Web MCP com o LangGraph
Os LLMs raciocinam bem, mas não conseguem ver o que está acontecendo na web no momento. Seu conhecimento se limita ao momento do treinamento. Portanto, quando um agente precisa de dados atuais, o modelo tende a preencher a lacuna com suposições.
O Bright Data Web MCP oferece ao seu agente acesso direto a dados da web em tempo real por meio de ferramentas de pesquisa e extração. Em vez de adivinhar, o modelo baseia suas respostas em fontes reais e atualizadas.
O LangGraph é o que torna esse acesso utilizável em uma configuração de agente. Um agente precisa decidir quando sabe o suficiente e quando deve buscar mais dados.
Com o Web MCP, quando o agente responde a uma pergunta, ele pode apontar as fontes que realmente usou, em vez de confiar na memória. Isso torna o resultado mais fácil de confiar e depurar.
Como conectar o Bright Data Web MCP a um agente LangGraph
O LangGraph controla o loop do agente. O Bright Data Web MCP dá ao agente acesso a dados da web em tempo real. O que resta é conectá-los sem adicionar complexidade.
Nesta seção, você configurará um projeto Python mínimo, conectará ao servidor Web MCP e exporá suas ferramentas a um agente LangGraph.
Pré-requisitos
Para acompanhar este tutorial, você precisa de:
- Python versão 3.11+
- Conta Bright Data
- Conta na plataforma OpenAI
Etapa 1: Gerar chave API OpenAI
O agente precisa de uma chave API LLM para raciocinar e decidir quando usar as ferramentas. Nesta configuração, essa chave vem da OpenAI.
Crie uma chave API no painel da plataforma OpenAI. Abra a página “Chaves API” e clique em “Criar nova chave secreta”.
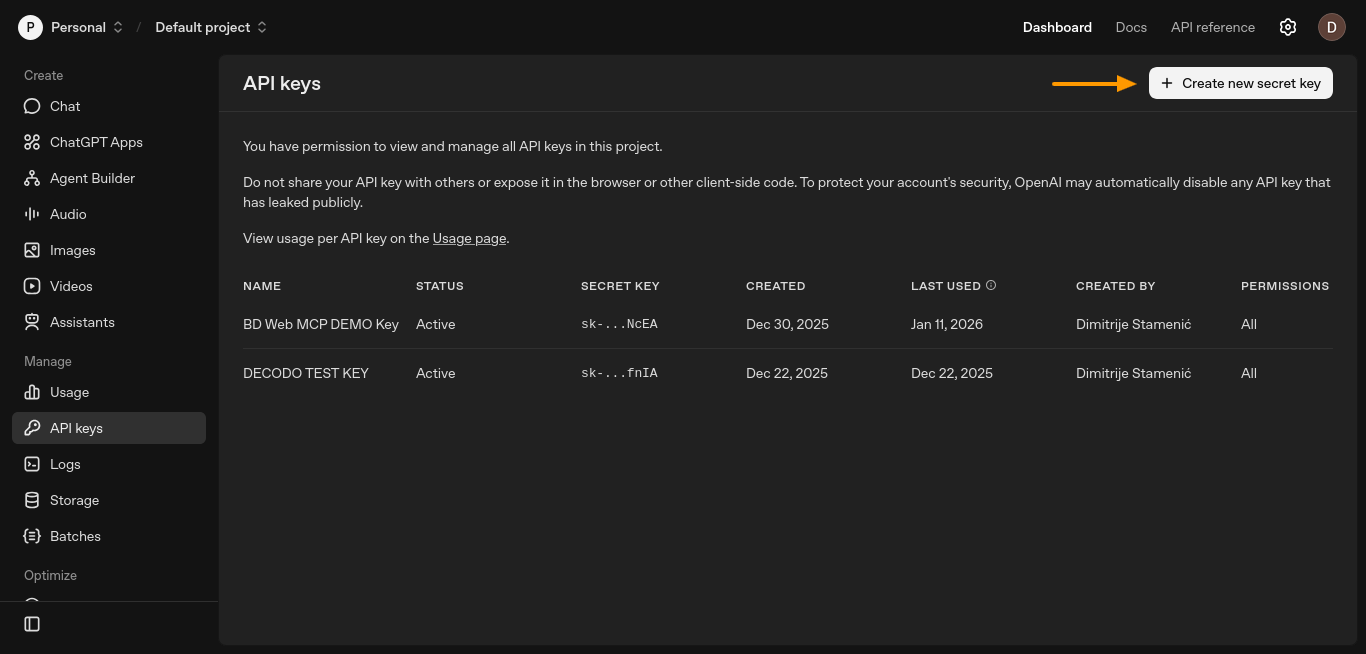
Isso abrirá uma nova janela onde você poderá configurar sua chave.
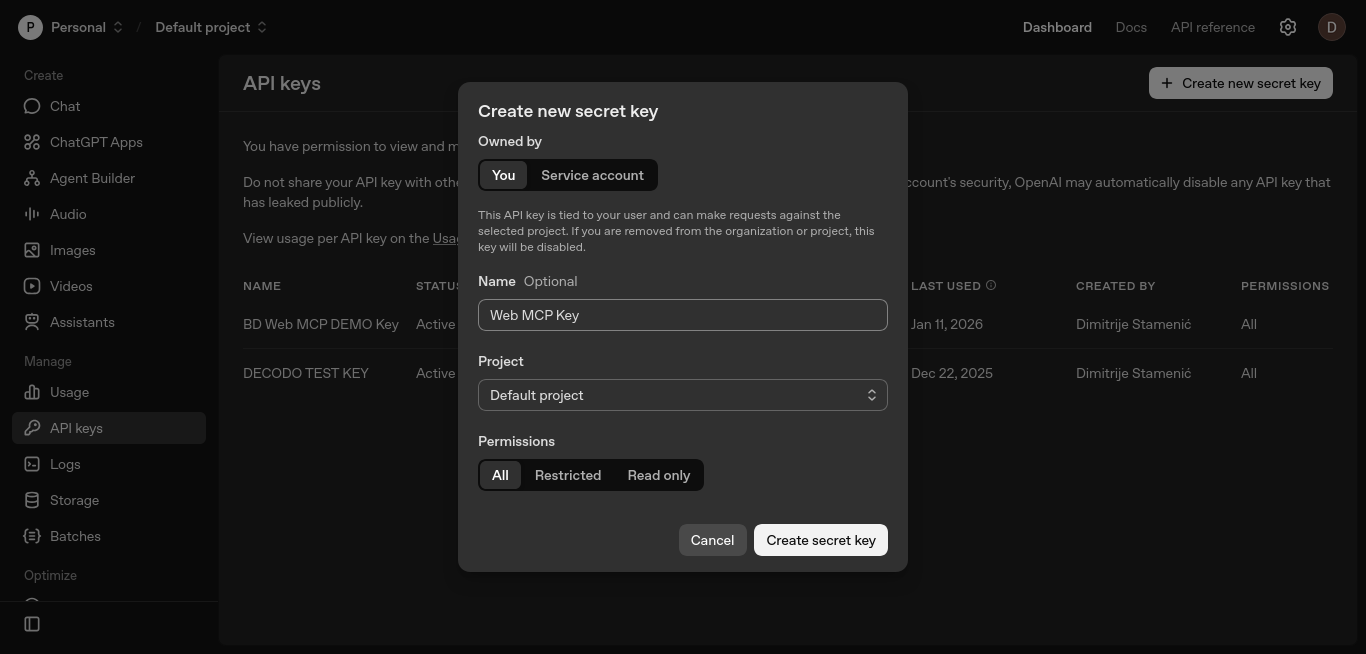
Mantenha as configurações padrão, nomeie a chave opcionalmente e clique em “Criar chave secreta”.
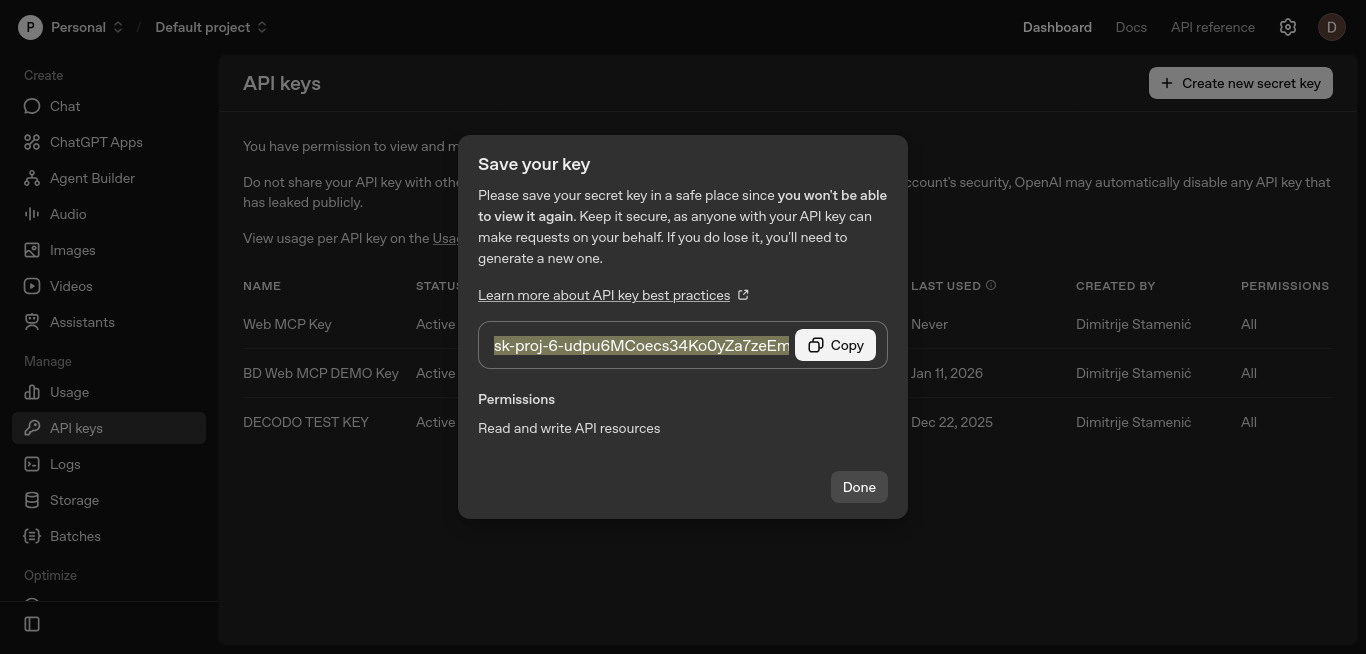
Copie a chave e armazene-a com segurança. Você a adicionará à variável de ambiente OPENAI_API_KEY nas próximas etapas.
Essa chave permite que o LangGraph chame o modelo LLM, que pode decidir quando invocar as ferramentas Web MCP.
Etapa 2: Gerar token da API Bright Data
Em seguida, você precisa de um token de API da Bright Data. Esse token autentica seu agente no servidor Web MCP e permite que ele chame ferramentas de pesquisa e scraping de dados.
Gere o token no painel da Bright Data. Abra “Configurações da conta”, vá para “Usuários e chaves API” e clique em “+ Adicionar chave”.
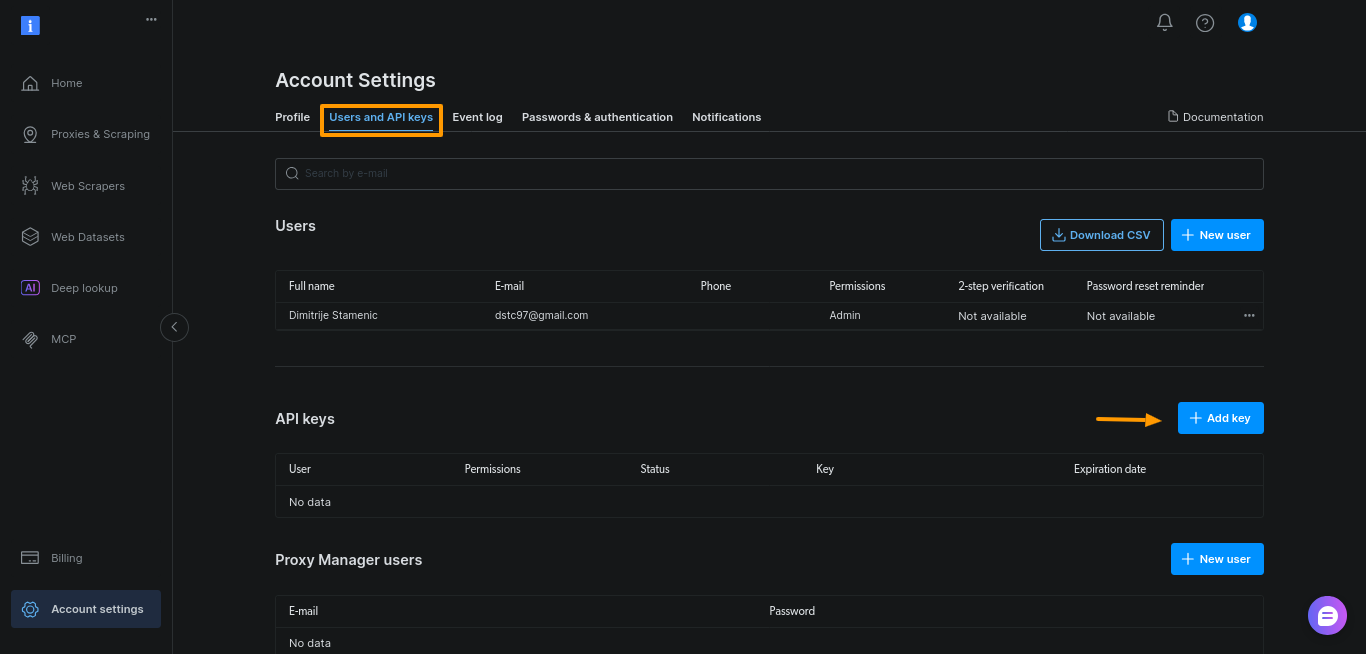
Para este guia, basta manter as configurações padrão e clicar em “Salvar”:
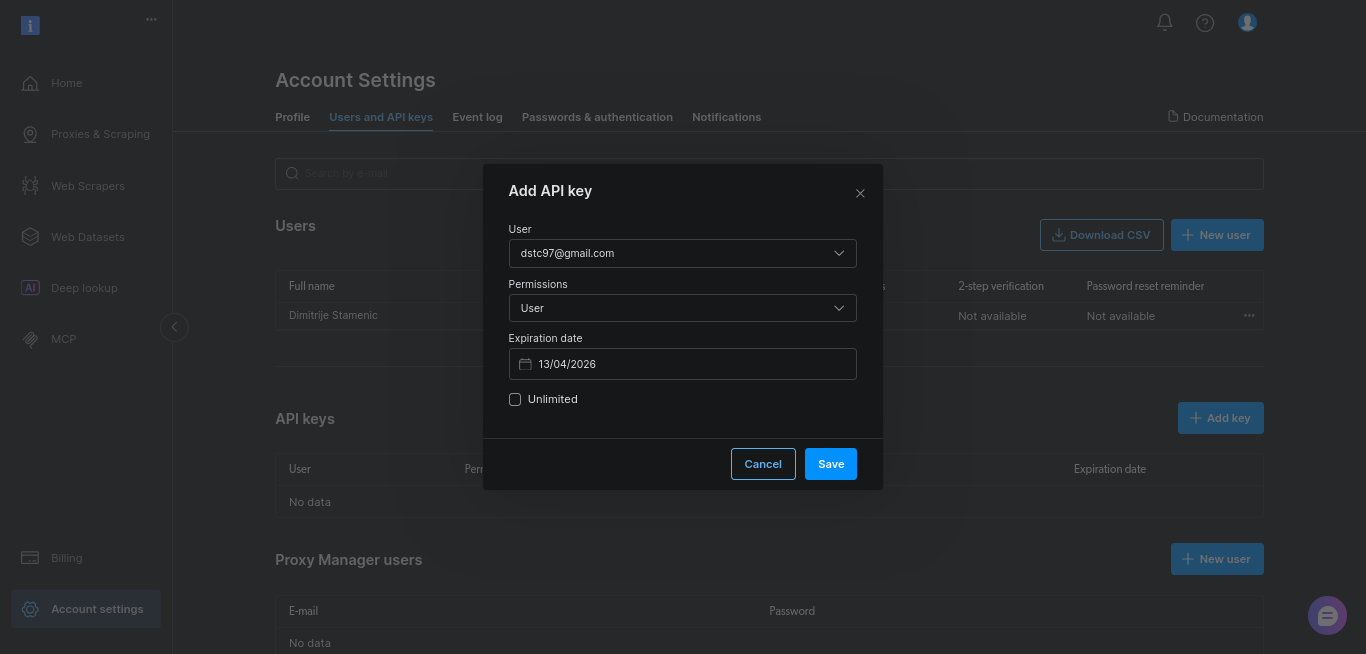
Copie a chave e armazene-a com segurança. Você a adicionará à variável de ambiente BRIGHTDATA_TOKEN nas próximas etapas.
Este token é o que dá ao seu agente permissão para acessar dados da web em tempo real através do Web MCP.
Etapa 3: Configure um projeto Python simples
Crie um novo diretório de projeto e ambiente virtual:
mkdir webmcp-langgraph-demo
cd webmcp-langgraph-demo
python3 -m venv webmcp-langgraph-venv Ative o ambiente virtual:
source webmcp-langgraph-venv/bin/activateIsso mantém as dependências isoladas e evita conflitos com outros projetos. Com o ambiente ativo, instale apenas as dependências necessárias. Esses são os mesmos adaptadores MCP usados nas integrações LangChain e LangGraph da Bright Data, portanto, a configuração permanece consistente à medida que seu agente cresce:
pip install
langgraph
langchain
langchain-openai
langchain-mcp-adapters
python-dotenvCrie um arquivo .env para armazenar suas chaves API:
touch .envCole a chave da API OpenAI e a chave Bright Data no arquivo .env:
OPENAI_API_KEY="sua-chave-openai-api"
BRIGHTDATA_TOKEN="sua-chave-brightdata-api"Mantenha o nome OPENAI_API_KEY inalterado. O LangChain o lê automaticamente, então você não precisa passar a chave no código.
Por fim, crie um único arquivo Python e defina o prompt do sistema que define a função do agente, os limites e as regras de uso da ferramenta:
# arquivo webmcp-langgraph-demo.py
SYSTEM_PROMPT = """Você é um assistente de pesquisa na web.
Tarefa:
- Pesquise o tópico do usuário usando os resultados da pesquisa do Google e algumas fontes.
- Retorne 6 a 10 pontos simples.
- Adicione uma pequena lista de "Fontes:" com apenas os URLs que você usou.
Como usar as ferramentas:
- Primeiro, acesse a ferramenta de pesquisa para obter os resultados do Google.
- Selecione de 3 a 5 resultados confiáveis e faça o scraping deles.
- Se o scraping falhar, tente um resultado diferente.
Restrições:
- Use no máximo 5 fontes.
- Dê preferência a documentos oficiais ou fontes primárias.
- Seja rápido: não faça uma pesquisa profunda.
"""Etapa 4: Configure os nós do LangGraph
Este é o núcleo do agente. Depois de entender esse loop, tudo o mais é detalhe de implementação.
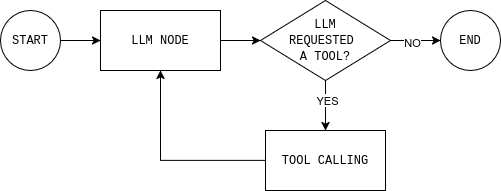
Antes de escrever o código, é útil entender o loop do agente que você está prestes a construir. O diagrama mostra um loop simples do agente LangGraph: o modelo lê o estado atual, decide se precisa de dados externos, chama uma ferramenta se necessário, observa o resultado e repete até conseguir responder.
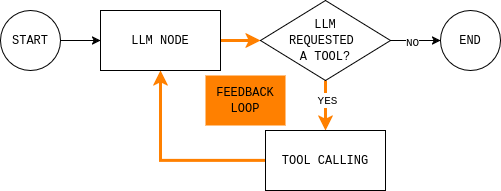
Para implementar esse loop, você precisa de dois nós (um nó LLM e um nó de execução de ferramenta) e uma função de roteamento que decide se deve continuar ou encerrar e dar uma resposta final.
O nó LLM envia o estado atual da conversa e as regras do sistema para o modelo e retorna uma resposta ou chamadas de ferramenta. O detalhe principal é que todas as respostas do modelo são anexadas ao MessagesState, para que as etapas posteriores possam ver o que o modelo decidiu e por quê.
def make_llm_call_node(llm_with_tools):
async def llm_call(state: MessagesState):
messages = [SystemMessage(content=SYSTEM_PROMPT)] + state["messages"]
ai_message = await llm_with_tools.ainvoke(messages)
return {"messages": [ai_message]}
return llm_callO nó de execução da ferramenta executa quaisquer ferramentas solicitadas pelo modelo e registra as saídas como observações. Essa separação mantém o raciocínio no modelo e a execução no código.
def make_tool_node(tools_by_name: dict):
async def tool_node(state: MessagesState):
last_ai_msg = state["messages"][-1]
tool_results = []
for tool_call in last_ai_msg.tool_calls:
tool = tools_by_name.get(tool_call["name"])
if not tool:
tool_results.append(
ToolMessage(
content=f"Ferramenta não encontrada: {tool_call['name']}",
tool_call_id=tool_call["id"],
)
)
continue
# As ferramentas MCP são normalmente assíncronas
observation = (
await tool.ainvoke(tool_call["args"])
if hasattr(tool, "ainvoke")
else tool.invoke(tool_call["args"])
)
tool_results.append(
ToolMessage(
content=str(observation),
tool_call_id=tool_call["id"],
)
)
return {"messages": tool_results}
return tool_nodePor fim, a regra de roteamento decide se o gráfico deve continuar em loop ou parar. Na prática, ela responde a uma única pergunta: o modelo solicitou ferramentas?
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
last_message = state["messages"][-1]
if getattr(last_message, "tool_calls", None):
return "tool_node"
return ENDEtapa 5: conecte tudo
Tudo nesta etapa fica dentro da função main(). É aqui que você configura credenciais, conecta-se ao Web MCP, vincula ferramentas, constrói o gráfico e executa uma consulta.
Comece carregando as variáveis de ambiente e lendo BRIGHTDATA_TOKEN. Isso mantém as credenciais fora do código-fonte e falha rapidamente se o token estiver ausente.
# Carregar variáveis de ambiente de .env
load_dotenv()
# Ler token Bright Data
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")Em seguida, crie um MultiServerMCPClient e aponte-o para o endpoint Web MCP. Esse cliente conecta o agente aos dados da web em tempo real.
# Conecte-se ao servidor Bright Data Web MCP
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})Observação: o Web MCP usa Streamable HTTP como transporte padrão, o que simplifica o streaming e as tentativas da ferramenta em comparação com configurações mais antigas baseadas em SSE. É por isso que a maioria das integrações MCP mais recentes padronizam esse transporte.
Em seguida, busque as ferramentas MCP disponíveis e indexe-as por nome. O nó de execução da ferramenta usa esse mapa para rotear as chamadas.
# Obtenha todas as ferramentas MCP disponíveis (pesquisa, scrape, etc.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}Inicialize o LLM e vincule as ferramentas MCP a ele. Isso permite a chamada da ferramenta.
# Inicialize o LLM e permita que ele chame as ferramentas MCP
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)Agora, construa o agente LangGraph mostrado anteriormente. Crie um StateGraph(MessagesState), adicione os nós LLM e ferramenta e conecte as arestas para corresponder ao loop.
# Construa o agente LangGraph
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Fluxo do gráfico:
# INÍCIO → LLM → (ferramentas?) → LLM → FIM
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()Por fim, execute o agente com um prompt real. Defina um recursion_limit para evitar loops infinitos.
# Exemplo de consulta de pesquisa
tópico = "O que é o Bright Data Web MCP?"
# Execute o agente
resultado = aguardar agente.ainvoke(
{
"mensagens": [
MensagemHumana(conteúdo=f"Pesquisar este tópico:n{tópico}")
]
},
# Evite loops infinitos
config={"recursion_limit": 12})
# Imprima a resposta final
print(result["messages"][-1].content)Veja como fica em main():
async def main():
# Carregar variáveis de ambiente de .env
load_dotenv()
# Ler token Bright Data
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")
# Conecte-se ao servidor Bright Data Web MCP
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})
# Buscar todas as ferramentas MCP disponíveis (pesquisa, scrape, etc.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}
# Inicializar o LLM e permitir que ele chame as ferramentas MCP
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# Construa o agente LangGraph
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Fluxo do gráfico:
# INÍCIO → LLM → (ferramentas?) → LLM → FIM
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agente = gráfico.compilar()
# Exemplo de consulta de pesquisa
tópico = "O que é o Protocolo de Contexto do Modelo (MCP) e como ele é usado com o LangGraph?"
# Executar o agente
resultado = aguardar agente.invocar(
{
"mensagens": [
MensagemHumana(conteúdo=f"Pesquisar este tópico:n{tópico}")
]
},
# Evitar loops infinitos
config={"recursion_limit": 12}
)
# Imprimir a resposta final
print(result["messages"][-1].content)Observação: você pode encontrar uma versão completa e executável deste agente neste repositório GitHub. Clone o repositório, adicione suas chaves API a um arquivo
.enve execute o script para ver o loop completo do LangGraph + Web MCP em ação.
Usando ferramentas pagas do Web MCP para superar os desafios do scraping de dados com automação do navegador
O scraping estático será interrompido assim que você sair das páginas renderizadas pelo servidor e entrar em sites com muito JavaScript ou orientados para interação. Essa é a mesma divisão entre estático e dinâmico que determina quando você precisa de um navegador real em vez de HTML bruto.
Ele também falha em páginas que exigem interação real do usuário (rolagem infinita, paginação acionada por botões), onde a automação do navegador se torna a única opção confiável.
O Web MCP expõe a automação do navegador de scraping e o scraping avançado como ferramentas MCP. Para o agente, elas são apenas opções adicionais quando ferramentas mais simples não são suficientes.
Habilite as ferramentas de automação do navegador no Web MCP
Como as ferramentas de automação do navegador do Web MCP não estão incluídas no plano gratuito, primeiro você precisa adicionar fundos à sua conta Bright Data no menu “Faturamento” na barra lateral esquerda.
Em seguida, habilite o grupo de ferramentas de automação do navegador para sua configuração MCP. Abra a seção “MCP” e clique em “Editar”:
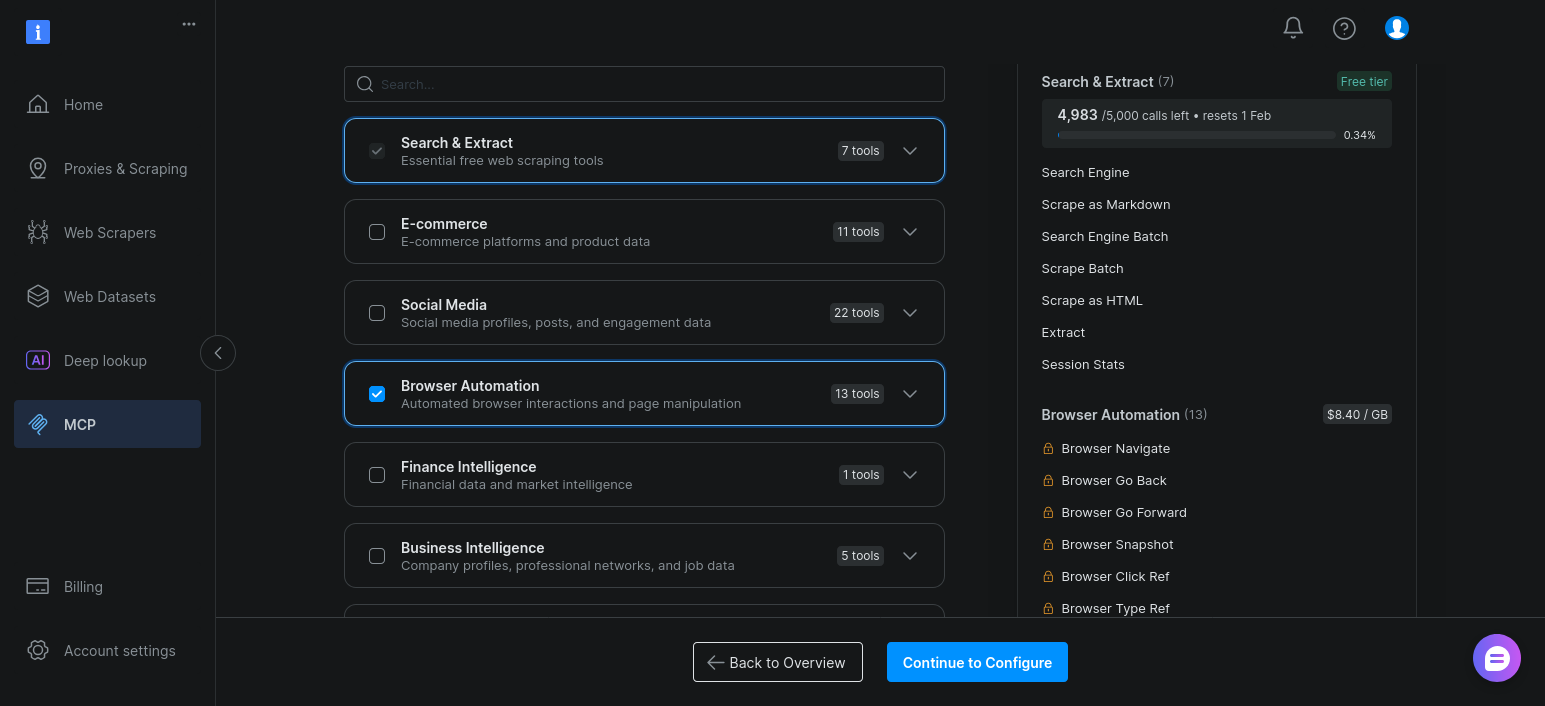
Agora basta ativar “Automação do navegador” e clicar em “Continuar para configurar”:
Mantenha as configurações padrão e clique em “Copiar e fechar”:
Depois de ativadas, essas ferramentas aparecem junto com as ferramentas de pesquisa e scrape quando o agente chama client.get_tools().
Estenda o LangGraph Agent existente para ferramentas de automação do navegador
O ponto principal aqui é simples: você não altera sua arquitetura LangGraph.
Seu agente já:
- Descobre ferramentas dinamicamente
- As vincula ao modelo
- Encaminhar a execução através do mesmo
LLM -> ferramenta ->loopde observação
Adicionar ferramentas de automação do navegador apenas altera quais ferramentas estão disponíveis.
Na prática, a única mudança é a URL de conexão do MCP. Em vez de se conectar ao endpoint básico, solicite os grupos avançados de ferramentas de scraping e automação do navegador de scraping:
# Habilitar scraping avançado e automação do navegador de scraping
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}&groups=advanced_scraping,browser"Quando você executa o script novamente, client.get_tools() retorna ferramentas adicionais baseadas no navegador. O modelo pode escolhê-las quando a extração estática retorna resultados escassos ou incompletos.
Conclusão
O LangGraph oferece um loop de agente claro e inspecionável com condições de estado, roteamento e parada que você controla. O Web MCP fornece a esse loop acesso confiável a dados reais da web sem inserir a lógica de scraping em prompts ou código.
O resultado é uma separação clara de interesses. O modelo decide o que fazer. O LangGraph decide como o loop funciona. A Bright Data lida com questões de pesquisa, extração e bloqueio. Quando algo falha, você pode ver onde falhou e por quê.
Tão importante quanto isso, essa configuração não o deixa em um beco sem saída. Você pode começar com ferramentas básicas do Web MCP para pesquisas rápidas e passar para ferramentas pagas do Web MCP quando o Scraping de dados falhar. A arquitetura do agente permanece a mesma. Apenas o alcance do agente se expande.






