

Neste artigo, você aprenderá:
- O que é o Langfuse e o que ele oferece.
- Por que as empresas e os usuários precisam dele para monitorar e rastrear agentes de IA.
- Como integrá-lo a um agente de IA complexo e realista, criado com o LangChain, que se conecta ao Bright Data para recursos de pesquisa e Scraping de dados na web.
Vamos começar!
O que é o Langfuse?
Langfuse é uma plataforma de engenharia LLM de código aberto e baseada em nuvem que ajuda a depurar, monitorar e melhorar aplicativos de modelos de linguagem grandes. Ela fornece observabilidade, rastreamento, gerenciamento de prompts e ferramentas de avaliação que dão suporte a todo o fluxo de trabalho de desenvolvimento de IA.
Seus principais recursos incluem:
- Observabilidade e rastreamento: obtenha visibilidade profunda de seus aplicativos LLM com rastreamentos, visões gerais de sessão e métricas como custo, latência e taxas de erro. Isso é fundamental para entender o desempenho e diagnosticar problemas.
- Gerenciamento de prompts: um sistema com controle de versão para criar, gerenciar e iterar prompts de forma colaborativa, sem mexer na base de código.
- Avaliação: ferramentas para avaliar o comportamento do aplicativo, incluindo coleta de feedback humano, pontuação baseada em modelo e testes automatizados em relação a Conjuntos de dados.
- Colaboração: oferece suporte a fluxos de trabalho em equipe com anotações, comentários e insights compartilhados.
- Extensibilidade: totalmente open source, com opções de integração flexíveis em diferentes pilhas de tecnologia.
- Opções de implantação: disponível como um serviço hospedado na nuvem (com um nível gratuito) ou como uma instalação auto-hospedada para equipes que precisam de controle total sobre os dados e a infraestrutura.
Por que integrar o Langfuse ao seu agente de IA
Monitorar agentes de IA com o Langfuse é fundamental, especialmente para empresas. Só assim você pode atingir o nível de observabilidade, controle e confiabilidade que os ambientes de produção exigem.
Afinal, em cenários reais, os agentes de IA interagem com dados confidenciais, lógica de negócios complexa e APIs externas. Portanto, você precisa de uma maneira de rastrear e entender exatamente como o agente se comporta, quanto custa e quão confiável é seu desempenho.
O Langfuse fornece rastreamento de ponta a ponta, métricas detalhadas e ferramentas de depuração que permitem que equipes (mesmo não técnicas) monitorem cada etapa de um fluxo de trabalho de IA, desde entradas rápidas até decisões de modelos e chamadas de ferramentas.
Para as empresas, isso significa menos pontos cegos, resolução mais rápida de incidentes e maior conformidade com a governança interna e as regulamentações externas. Além disso, o Langfuse também oferece suporte ao gerenciamento e à avaliação de prompts, permitindo que as equipes criem versões, testem e otimizem prompts em escala.
Como usar o Langfuse para rastrear um agente de IA de rastreamento de conformidade criado com LangChain e Bright Data
Para demonstrar os recursos de rastreamento e monitoramento do Langfuse, primeiro você precisa de um agente de IA para instrumentar. Por esse motivo, criaremos um agente de IA do mundo real usando o LangChain, com tecnologia das soluções Bright Data para pesquisa e Scraping de dados na web.
Observação: o Langfuse e o Bright Data oferecem suporte a uma ampla variedade de estruturas de agentes de IA. O LangChain foi escolhido aqui apenas por motivos de simplicidade e demonstração.
Este agente de IA pronto para uso corporativo lidará com tarefas relacionadas à conformidade ao:
- Carregar um documento PDF interno que descreve um processo empresarial (por exemplo, fluxos de trabalho de processamento de dados).
- Analisar o documento com um LLM para identificar os principais aspectos regulatórios e de privacidade.
- Realizar pesquisas na web por tópicos relacionados usando a API SERP da Bright Data.
- Acessar as páginas principais (priorizando sites governamentais) no formato Markdown por meio da API Bright Data Web Unlocker.
- Processar as informações coletadas e fornecer insights atualizados para ajudar a evitar problemas regulatórios.
Em seguida, este agente será conectado ao Langfuse para rastrear informações de tempo de execução, métricas e outros dados relevantes.
Para uma arquitetura de alto nível deste projeto, consulte o seguinte projeto esquemático: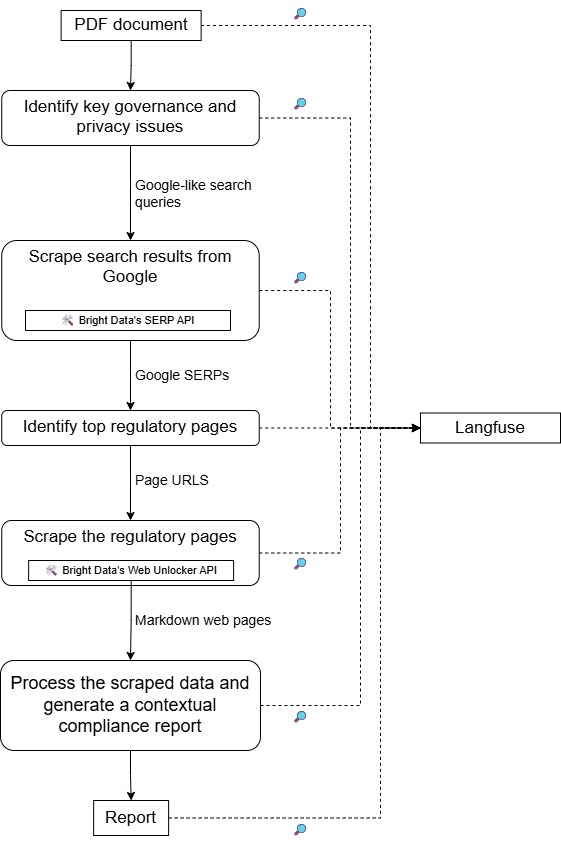
Siga as instruções abaixo!
Pré-requisitos
Antes de começar, certifique-se de ter o seguinte:
- Python 3.10 ou superior instalado em sua máquina.
- Uma chave API OpenAI.
- Uma conta Bright Data com zonas API SERP e Web Unlocker configuradas, juntamente com uma chave API.
- Uma conta Langfuse com chaves API públicas e secretas configuradas.
Não se preocupe em configurar as contas Bright Data e Langfuse agora, pois você será orientado nas etapas abaixo. Também é útil ter um conhecimento básico sobre instrumentação de agentes de IA para ver como o Langfuse rastreia e gerencia dados de tempo de execução.
Etapa 1: Configure seu projeto de agente de IA LangChain
Execute o seguinte comando em seu terminal para criar uma nova pasta para seu projeto de agente de IA LangChain:
mkdir compliance-tracking-IA-agentEste diretório compliance-tracking-ai-agent/ representa a pasta do projeto para o seu agente de IA, que você irá instrumentar posteriormente através do Langfuse.
Navegue até a pasta e crie um ambiente virtual Python dentro dela:
cd compliance-tracking-IA-agent
python -m venv .venvAbra a pasta do projeto no seu IDE Python preferido. Tanto o Visual Studio Code com a extensão Python quanto o PyCharm são opções válidas.
Dentro da pasta do projeto, crie um script Python chamado agent.py:
compliance-tracking-IA-agent/
├─── .venv/
└─── agent.py # <------------Atualmente, agent.py está vazio. É aqui que você definirá posteriormente seu agente de IA por meio do LangChain.
Em seguida, ative o ambiente virtual. No Linux ou macOS, execute no seu terminal:
source venv/bin/activateDe forma equivalente, no Windows, execute:
venv/Scripts/activateDepois de ativado, instale as dependências do projeto com este comando:
pip install langchain langchain-openai langgraph langchain-brightdata langchain-community pypdf python-dotenv langfuseEssas bibliotecas abrangem o seguinte escopo:
langchain,langchain-openaielanggraph: para construir e gerenciar um agente de IA alimentado por um modelo OpenAI.langchain-brightdata: para integrar o LangChain aos serviços Bright Data usando ferramentas oficiais.langchain-communityepypdf: fornecem APIs para ler e processar arquivos PDF por meio da bibliotecapypdfsubjacente.python-dotenv: para carregar segredos de aplicativos, como chaves de API para provedores terceirizados, a partir de um arquivo.env.langfuse: para instrumentar seu agente de IA para coletar rastreamentos e telemetria úteis, seja na nuvem ou localmente.
Pronto! Agora você tem um ambiente de desenvolvimento Python totalmente configurado para construir seu agente de IA.
Etapa 2: Configurar a leitura de variáveis de ambiente
Seu agente de IA se conectará a serviços de terceiros, incluindo OpenAI, Bright Data e Langfuse. Para evitar o hardcoding de credenciais em seu script e torná-lo pronto para produção para uso empresarial, configure o script para lê-las de um arquivo .env. É exatamente por isso que instalamos python-dotenv!
Em agent.py, comece adicionando a seguinte importação:
from dotenv import load_dotenvEm seguida, crie um arquivo .env na pasta do seu projeto:
compliance-tracking-IA-agent/
├─── .venv/
├─── agent.py
└─── .env # <------------Este arquivo armazenará todas as suas credenciais, chaves de API e segredos.
Em agent.py, carregue as variáveis de ambiente de .env com esta linha de código:
load_dotenv()Ótimo! Agora seu script pode ler com segurança os valores do arquivo .env.
Etapa 3: Prepare sua conta Bright Data
As ferramentas LangChain Bright Data funcionam conectando-se aos serviços Bright Data configurados em sua conta. Especificamente, as duas ferramentas necessárias para este projeto são:
BrightDataSERP: recupera resultados de mecanismos de pesquisa para encontrar páginas da web regulatórias relevantes. Ele se conecta à API SERP da Bright Data.BrightDataUnblocker: acessa qualquer site público, mesmo que seja restrito geograficamente ou protegido por bot. Isso permite que o agente extraia conteúdo de páginas da web individuais e aprenda com elas. Ele se conecta à API Web Unblocker da Bright Data.
Em outras palavras, para usar essas duas ferramentas, você precisa de uma conta Bright Data com uma zona API SERP e uma zona Web Unblocker API configuradas. Vamos configurá-las!
Se você ainda não tem uma conta Bright Data, comece criando uma. Caso contrário, faça login. Vá para o seu painel e navegue até a página “Proxies & Scraping”. Lá, verifique a tabela “Minhas zonas”: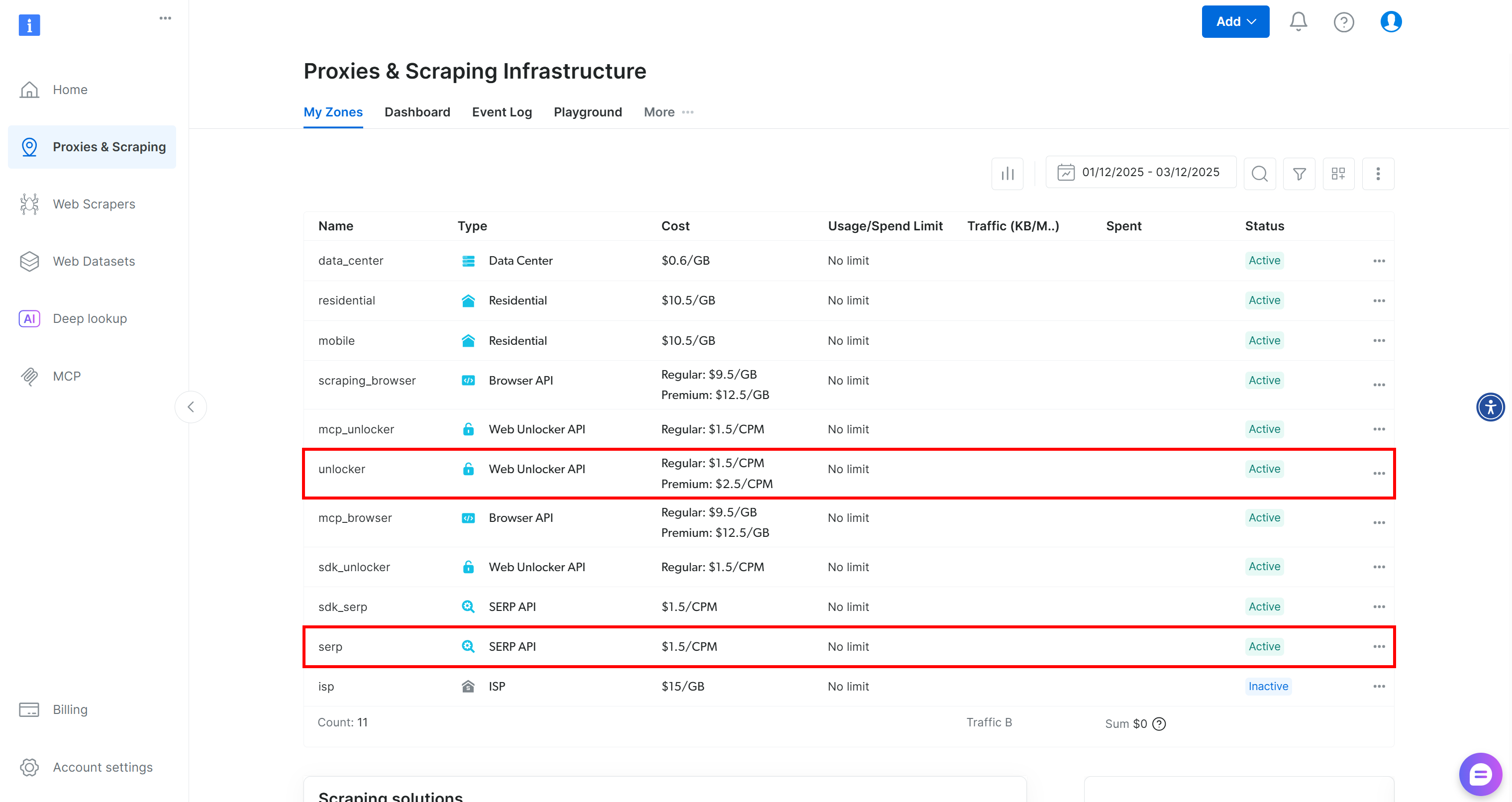
Se a tabela já contiver uma zona da API Web Unlocker chamada unlocker e uma zona da API SERP chamada serp, você está pronto para começar. Isso porque:
- A ferramenta
BrightDataSERPLangChain se conecta automaticamente a uma zona API SERP chamadaserp. - A ferramenta
BrightDataUnblockerLangChain se conecta automaticamente a uma zona da API Web Unblocker chamadaweb_unlocker.
Para obter mais detalhes, consulte a documentação do Bright Data x LangChain.
Se você não tiver essas duas zonas necessárias, poderá criá-las facilmente. Role para baixo nos cartões “Unblocker API” e “API SERP”, pressione o botão “Criar zona” e siga o assistente para adicionar as duas zonas com os nomes necessários: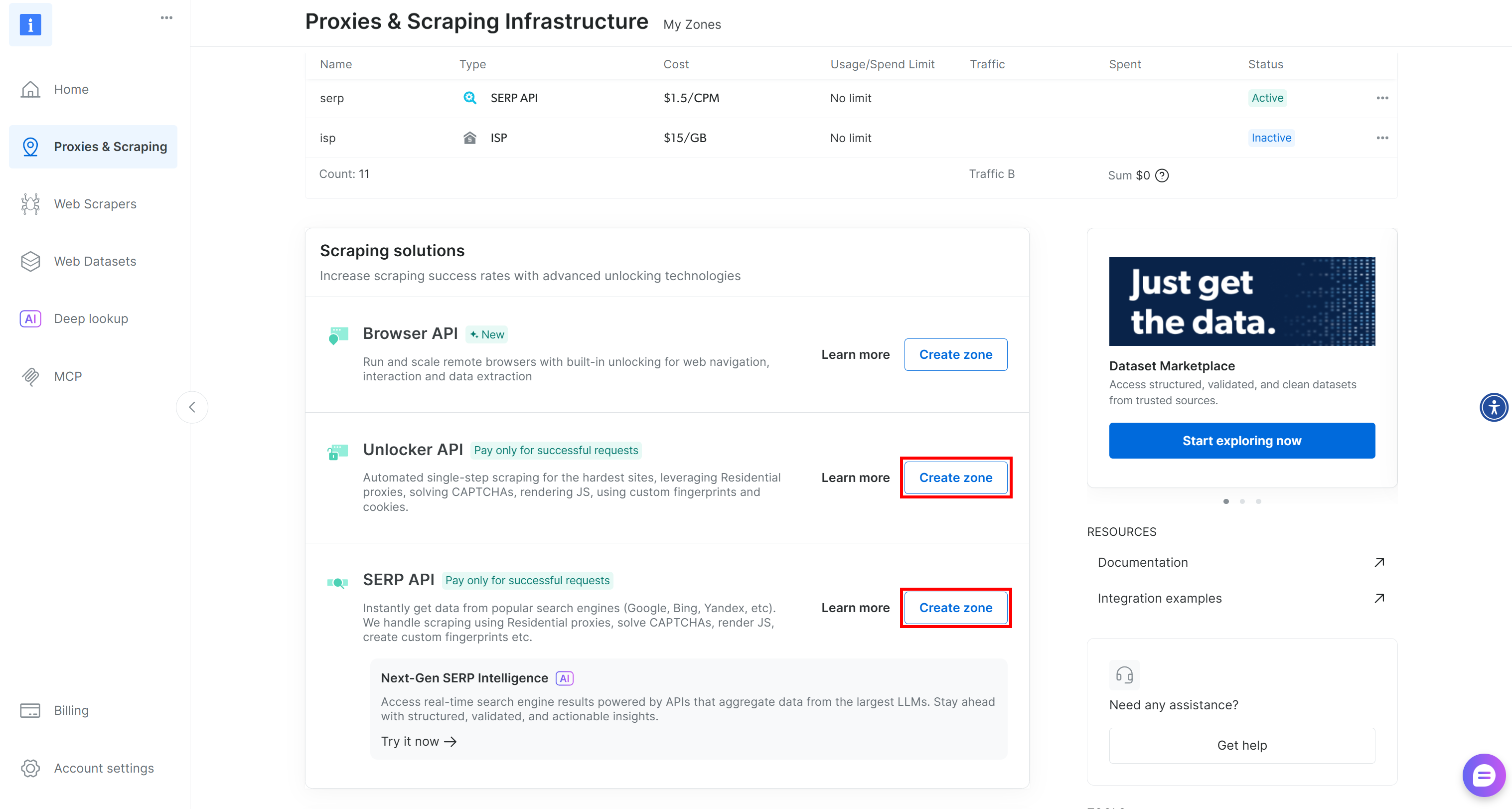
Para obter orientações passo a passo, consulte estas duas páginas de documentação:
Por último, você precisa informar às ferramentas LangChain Bright Data como se conectar à sua conta. Isso é feito usando sua chave API Bright Data, que é utilizada para autenticação.
Gere sua chave API da Bright Data e armazene-a em seu arquivo .env desta forma:
BRIGHT_DATA_API_KEY="<SUA_CHAVE_API_BRIGHT_DATA>"É isso! Agora você tem todos os pré-requisitos necessários para conectar seu script LangChain às soluções da Bright Data por meio das ferramentas oficiais.
Etapa 4: Configure as ferramentas LangChain Bright Data
No seu arquivo agent.py, prepare as ferramentas LangChain Bright Data da seguinte maneira:
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker() Observação: você não precisa especificar manualmente sua chave API Bright Data. Ambas as ferramentas tentam lê-la automaticamente da variável de ambiente BRIGHT_DATA_API_KEY, que você definiu anteriormente no seu arquivo .env.
Etapa 5: integrar o LLM
Seu agente de IA para rastreamento de conformidade precisa de um cérebro, que é representado por um modelo LLM. Neste exemplo, o provedor LLM escolhido é o OpenAI. Portanto, comece adicionando sua chave API OpenAI ao arquivo .env:
OPENAI_API_KEY="<SUA_CHAVE_API_OPENAI>"Em seguida, no arquivo agent.py, inicialize a integração LLM desta forma:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-5-mini",
) Observação: o modelo configurado aqui é o GPT-5 Mini, mas você pode usar qualquer outro modelo OpenAI.
Se você não quiser usar o OpenAI, siga os guias oficiais do LangChain para se conectar a qualquer outro provedor LLM.
Ótimo! Agora você tem tudo o que precisa para definir um agente de IA LangChain.
Etapa 6: definir o agente de IA
Um agente LangChain requer um LLM, algumas ferramentas opcionais e um prompt do sistema para definir o comportamento do agente.
Combine todos esses componentes em um agente LangChain assim:
from langchain.agents import create_agent
# Defina o prompt do sistema que instrui o agente sobre sua tarefa focada em conformidade e privacidade
system_prompt = """
Você é um especialista em rastreamento de conformidade. Sua função é analisar documentos em busca de possíveis problemas regulatórios e de privacidade.
Sua análise é apoiada pela pesquisa de regras atualizadas e fontes confiáveis online usando as ferramentas da Bright Data, incluindo a API SERP e o Web Unlocker.
Forneça insights precisos e prontos para uso corporativo, garantindo que todas as descobertas sejam apoiadas por citações do documento original e de fontes externas confiáveis.
"""
# Lista de ferramentas disponíveis para o agente
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Defina o agente de IA
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)A função create_agent() cria um tempo de execução do agente baseado em gráfico usando LangGraph. Um gráfico é composto por nós (etapas) e arestas (conexões) que definem como o agente processa as informações. O agente se move por esse gráfico, executando diferentes tipos de nós. Para obter mais detalhes, consulte a documentação oficial.
Basicamente, a variável agente agora representa seu agente de IA com integração Bright Data para rastreamento e análise de conformidade. Fantástico!
Etapa 7: Inicie o agente
Antes de iniciar o agente, você precisa de um prompt descrevendo a tarefa de rastreamento de conformidade e o documento a ser analisado.
Comece lendo o documento PDF de entrada:
from langchain_community.document_loaders import PyPDFDirectoryLoader
# Carregar todos os documentos PDF da pasta de entrada
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Carregar todas as páginas de todos os PDFs na pasta de entrada
docs = loader.load()
# Combinar todas as páginas dos PDFs em uma única string para análise
internal_document_to_analyze = "nn".join([doc.page_content for doc in docs])Isso usa o carregador de documentos da comunidade pypdf do LangChain para ler todas as páginas dos PDFs na sua pasta input/ e agregar seu texto em uma única variável de string.
Adicione uma pasta input/ dentro do diretório do seu projeto:
compliance-tracking-IA-agent/
├─── .venv/
├─── input/ # <------------
├─── agent.py
└─── .envEssa pasta conterá os arquivos PDF que o agente analisará quanto a questões relacionadas à privacidade, regulamentação ou conformidade.
Supondo que sua pasta input/ contenha um único documento, a variável internal_document_to_analyze conterá seu texto completo. Agora, isso pode ser incorporado a um prompt que instrui claramente o agente a realizar a tarefa de análise:
from langchain_core.prompts import PromptTemplate
# Defina um modelo de prompt para orientar o agente durante o fluxo de trabalho
prompt_template = PromptTemplate.from_template("""
Dado o seguinte conteúdo PDF:
1. Peça ao LLM para analisá-lo a fim de identificar os principais aspectos importantes que vale a pena explorar em termos de privacidade.
2. Traduza esses aspectos em até 3 consultas de pesquisa muito curtas (não mais do que 5 palavras), concisas e específicas, adequadas para o Google.
3. Realize pesquisas na web para essas consultas usando a ferramenta API SERP da Bright Data (pesquisando páginas em inglês, limitadas aos Estados Unidos).
4. Acesse até as 5 principais páginas da web, que não sejam PDF (dando prioridade a sites governamentais) no formato de dados Markdown usando a ferramenta Web Unlocker da Bright Data.
5. Processe as informações coletadas e crie um relatório final conciso que inclua citações do documento original e insights das páginas rastreadas para evitar problemas regulatórios.
CONTEÚDO DO PDF:
{pdf}
""")
# Preencha o modelo com o conteúdo dos PDFs
prompt = prompt_template.format(pdf=internal_document_to_analyze)Por fim, passe o prompt para o agente e execute-o:
# Transmita a resposta do agente enquanto rastreia cada etapa com o Langfuse
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()Missão cumprida! Seu agente LangChain IA com tecnologia Bright Data agora está pronto para lidar com tarefas de análise de documentos e pesquisa regulatória de nível empresarial.
Etapa 8: Comece a usar o Langfuse
Você chegou a um ponto em que seu agente de IA está implementado. Normalmente, é nesse momento que você deseja adicionar o Langfuse para rastreamento e monitoramento da produção. Afinal, você geralmente instrumenta agentes que já estão em funcionamento.
Comece criando uma conta no Langfuse. Você será redirecionado para a página “Organizações”, onde precisará criar uma nova organização. Para fazer isso, clique no botão “Nova organização”: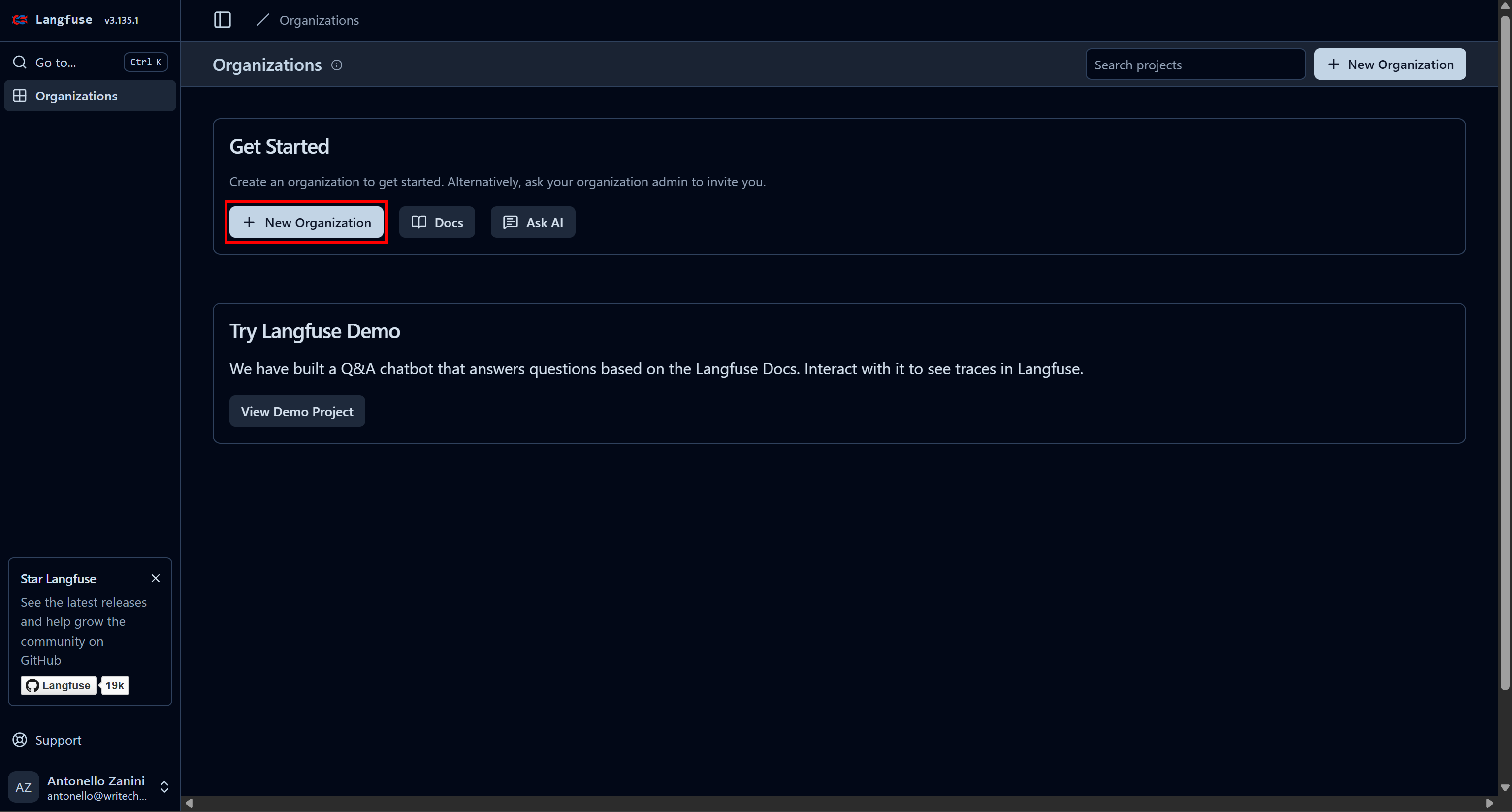
Dê um nome à sua organização e continue pelo assistente até a etapa final “Criar projeto”: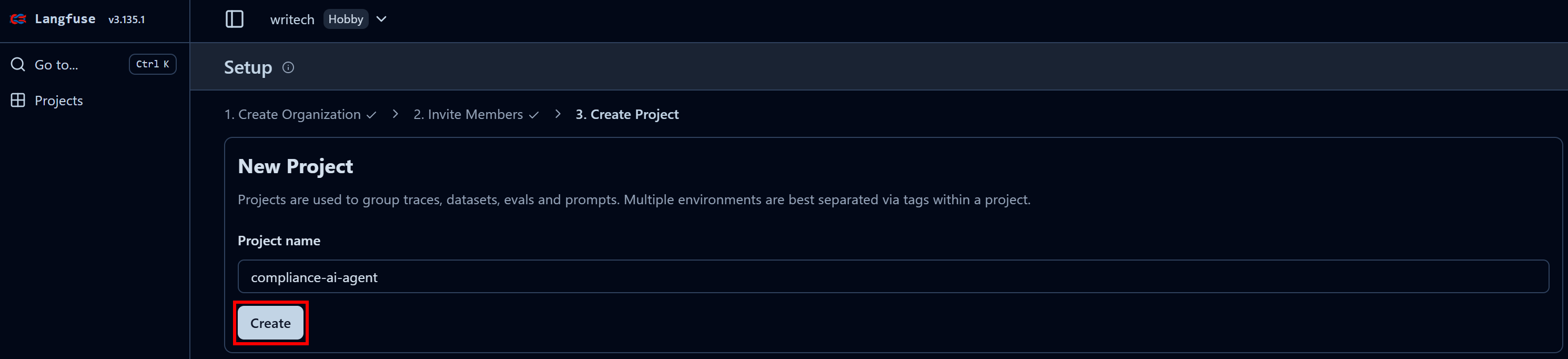
Na última etapa, nomeie seu projeto como “compliance-tracking-IA-agent” e pressione o botão “Criar”. Você será redirecionado para a visualização “Configurações do projeto”. A partir daí, navegue até a página “Chaves API”: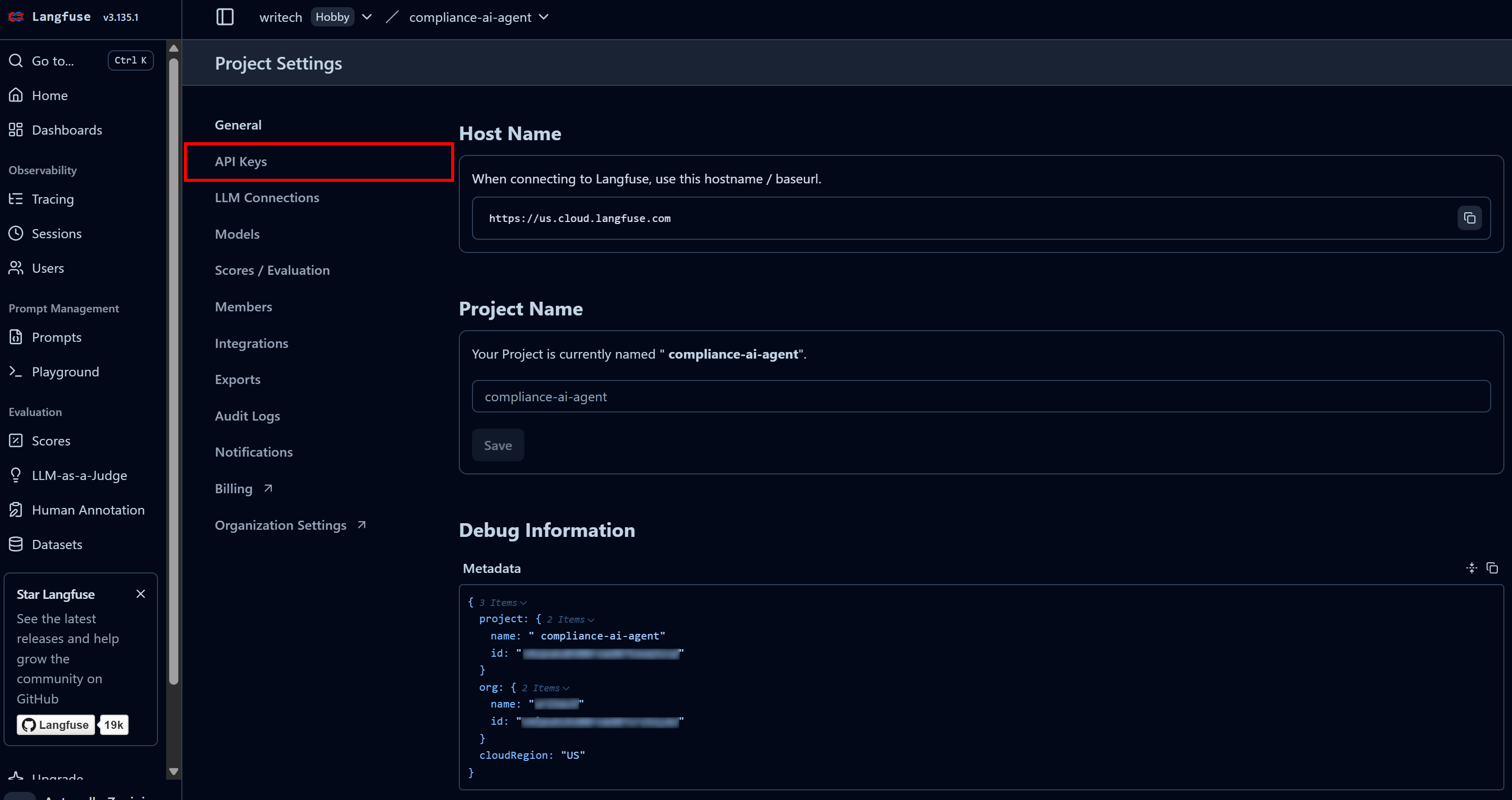
Na seção “Chaves API do projeto”, clique em “Criar novas chaves API”: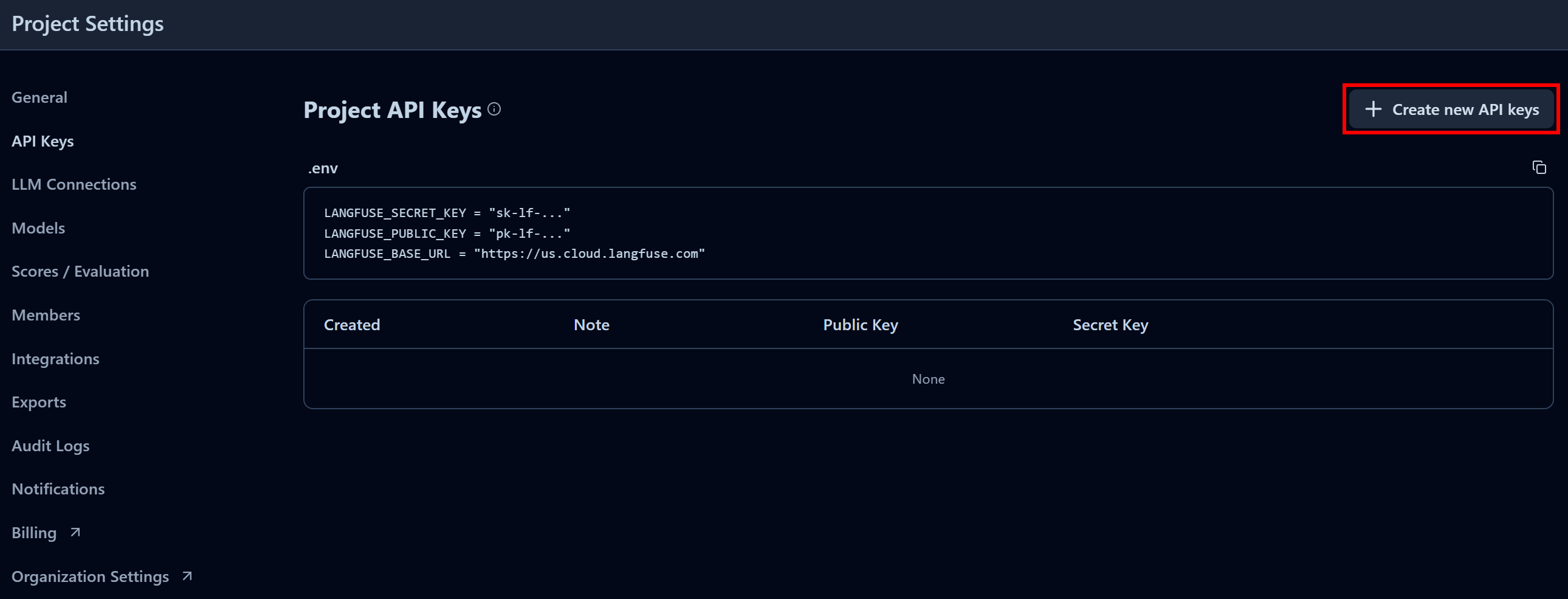
Na janela modal que aparece, dê um nome à sua chave API e clique em “Criar chaves API”: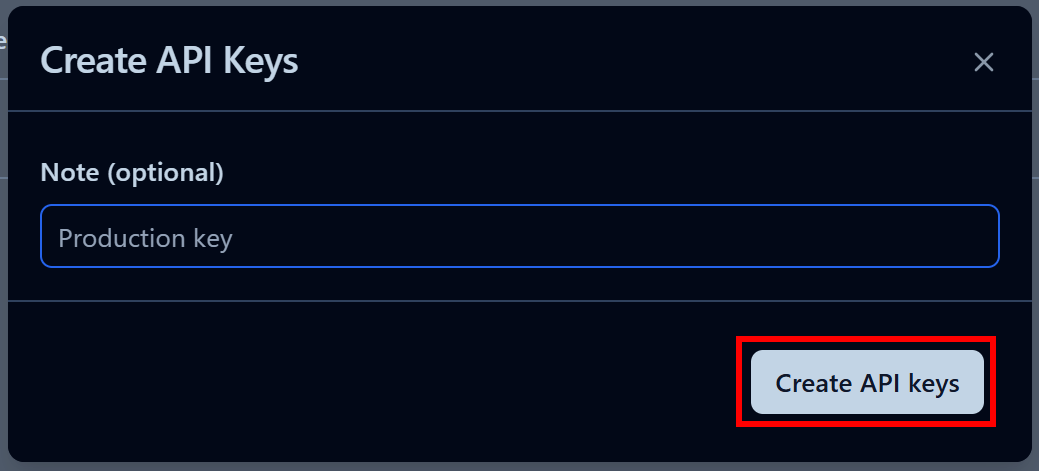
Você receberá uma chave API pública e secreta. Para uma integração rápida, clique no botão “Copiar para a área de transferência” na seção “.env”: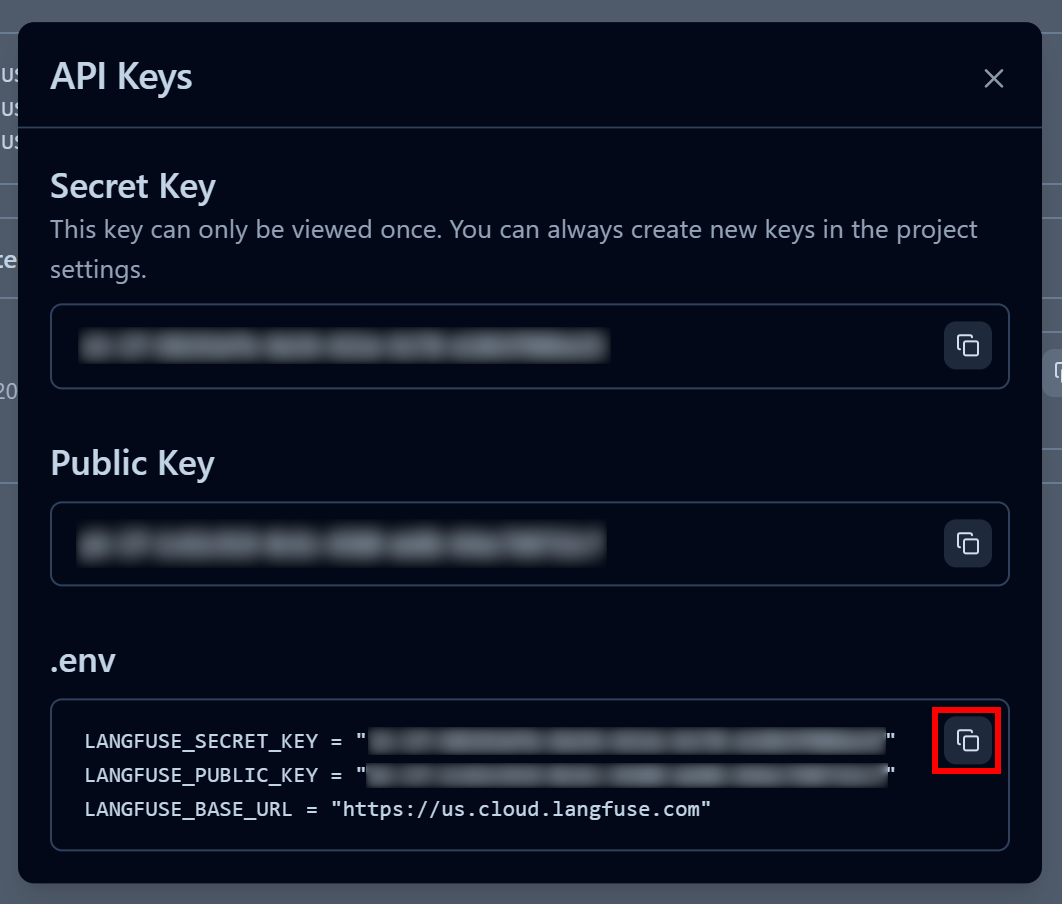
Em seguida, cole as variáveis de ambiente copiadas no arquivo .env do seu projeto:
LANGFUSE_SECRET_KEY = "<SUA_CHAVE_SECRETA_LANGFUSE>"
LANGFUSE_PUBLIC_KEY = "<SUA_CHAVE_PÚBLICA_LANGFUSE>"
LANGFUSE_BASE_URL = "<SUA_URL_BASE_LANGFUSE>"Ótimo! Agora seu script pode se conectar à sua conta Langfuse Cloud e enviar informações de rastreamento úteis para monitoramento e observabilidade.
Etapa 9: Integrar o rastreamento do Langfuse
O Langfuse oferece suporte completo ao LangChain (assim como a muitas outras estruturas de construção de agentes de IA), portanto, não é necessário nenhum código personalizado.
Para conectar seu agente de IA LangChain ao Langfuse, tudo o que você precisa fazer é inicializar o cliente Langfuse e criar um manipulador de retorno de chamada:
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Inicializar o cliente Langfuse para rastreamento e observabilidade
langfuse = get_client()
# Criar um manipulador de retorno de chamada Langfuse para capturar as interações do agente Langchain
langfuse_handler = CallbackHandler()
Em seguida, passe o manipulador de retorno de chamada Langfuse ao invocar o agente:
para step em agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Integração Langfuse
):
step["messages"][-1].pretty_print()Pronto! Seu agente de IA LangChain agora está totalmente instrumentado. Todas as informações de tempo de execução serão enviadas para o Langfuse e poderão ser visualizadas no aplicativo web.
Etapa 10: Código final
Seu arquivo agent.py agora deve conter:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_core.prompts import PromptTemplate
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Inicializar o cliente Langfuse para rastreamento e observabilidade
langfuse = get_client()
# Criar um manipulador de retorno de chamada Langfuse para capturar as interações do agente Langchain
langfuse_handler = CallbackHandler()
# Inicializar as ferramentas Bright Data
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker()
# Inicializar o modelo de linguagem grande
llm = ChatOpenAI(
model="gpt-5-mini",)
# Definir o prompt do sistema que instrui o agente sobre sua tarefa focada em conformidade e privacidade
system_prompt = """
Você é um especialista em rastreamento de conformidade. Sua função é analisar documentos em busca de possíveis questões regulatórias e de privacidade.
Sua análise é apoiada pela pesquisa de regras atualizadas e fontes autorizadas online usando as ferramentas da Bright Data, incluindo a API SERP e o Web Unlocker.
Forneça insights precisos e prontos para uso corporativo, garantindo que todas as descobertas sejam apoiadas por citações do documento original e de fontes externas autorizadas.
"""
# Lista de ferramentas disponíveis para o agente
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Defina o agente de IA
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)
# Carregar todos os documentos PDF da pasta de entrada
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Carregar todas as páginas de todos os PDFs na pasta de entrada
docs = loader.load()
# Combinar todas as páginas dos PDFs em uma única string para análise
documento_interno_a_ser_analisado = "nn".join([doc.page_content for doc in docs])
# Definir um modelo de prompt para orientar o agente durante o fluxo de trabalho
modelo_de_prompt = PromptTemplate.from_template("""
Dado o seguinte conteúdo em PDF:
1. Peça ao LLM para analisá-lo e identificar os principais aspectos importantes que valem a pena explorar em termos de privacidade.
2. Traduza esses aspectos em até 3 consultas de pesquisa muito curtas (não mais do que 5 palavras), concisas e específicas, adequadas para o Google.
3. Realize pesquisas na web para essas consultas usando a ferramenta API SERP da Bright Data (pesquisando páginas em inglês, limitadas aos Estados Unidos).
4. Acesse até as 5 principais páginas da web, que não sejam PDF (dando prioridade a sites governamentais) no formato de dados Markdown usando a ferramenta Web Unlocker da Bright Data.
5. Processe as informações coletadas e crie um relatório final conciso que inclua citações do documento original e insights das páginas rastreadas para evitar problemas regulatórios.
CONTEÚDO DO PDF:
{pdf}
""")
# Preencha o modelo com o conteúdo dos PDFs
prompt = prompt_template.format(pdf=internal_document_to_analyze)
# Transmita a resposta do agente enquanto rastreia cada etapa com o Langfuse
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Integração com Langfuse
):
step["messages"][-1].pretty_print()Uau! Em apenas cerca de 75 linhas de código Python, você acabou de criar um agente de IA pronto para uso corporativo para análise regulatória e de conformidade, graças ao LangChain, Bright Data e Langfuse.
Etapa 11: Execute o agente
Lembre-se de que seu agente de IA precisa de um arquivo PDF para funcionar. Para este exemplo, suponha que você deseja executar a análise regulatória no seguinte documento:
Este é um documento de amostra, no estilo empresarial, que descreve, em alto nível, as práticas de processamento de dados do usuário aplicadas por uma empresa.
Salve-o como user-data-processing-workflow.pdf e coloque-o dentro da pasta input/ no diretório do seu projeto:
Dessa forma, o script poderá acessá-lo e incorporá-lo ao prompt do agente.
Execute o agente LagnChain IA com:
python agent.py No terminal, você verá rastros das chamadas das ferramentas Bright Data, como este: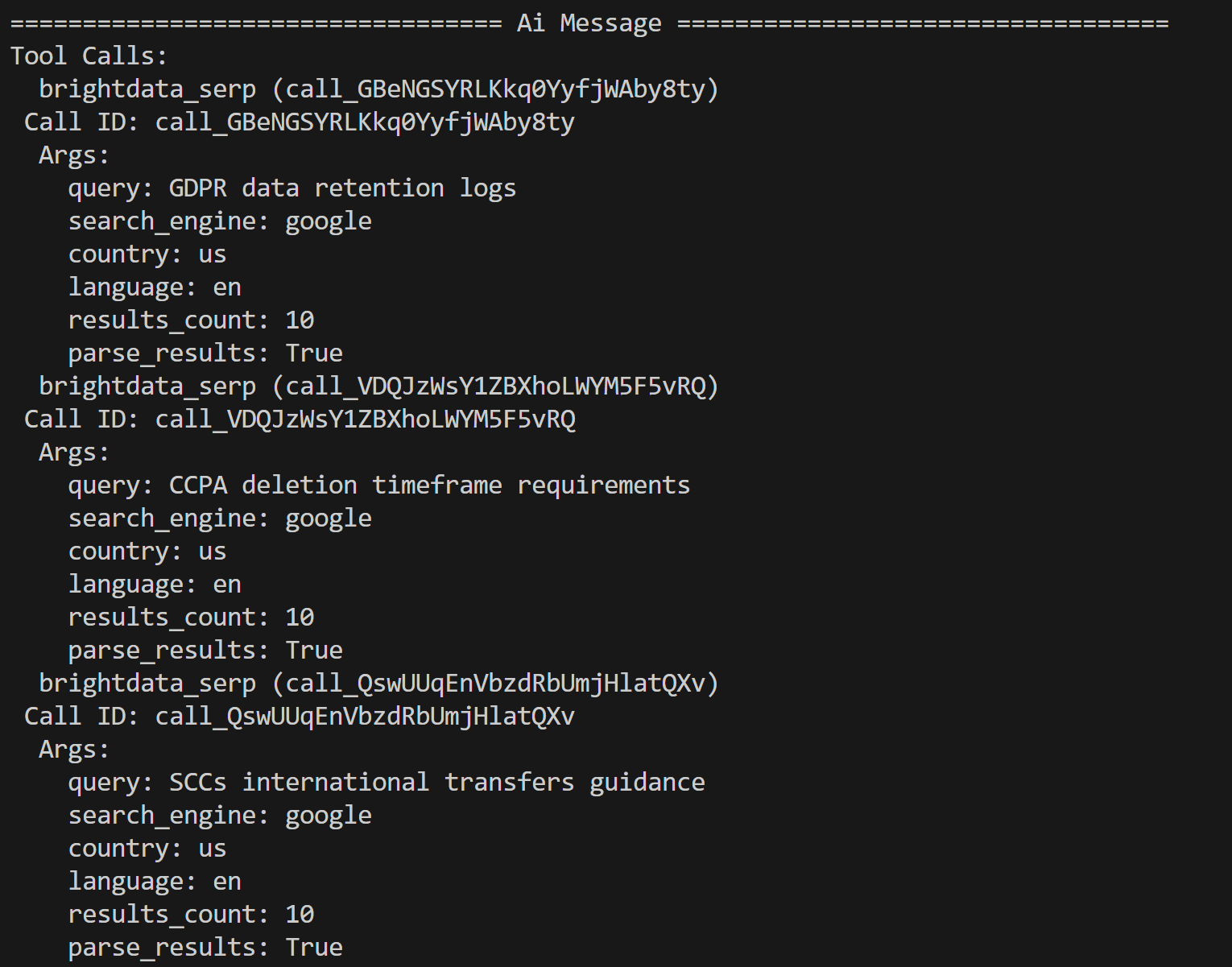
O agente de IA identificou as três consultas de pesquisa a seguir para pesquisa adicional com base no conteúdo do PDF:
- “Registros de retenção de dados do GDPR”
- “Requisitos de prazo de exclusão da CCPA”
- “Orientação sobre transferências internacionais SCCs”
Essas consultas são contextuais a possíveis questões regulatórias e de privacidade destacadas pelo LLM no documento de entrada.
A partir dos resultados retornados pela API SERP da Bright Data — que contém os resultados de pesquisa do Google para essas consultas —, o agente seleciona as páginas principais e as extrai por meio da ferramenta API Web Unblocker: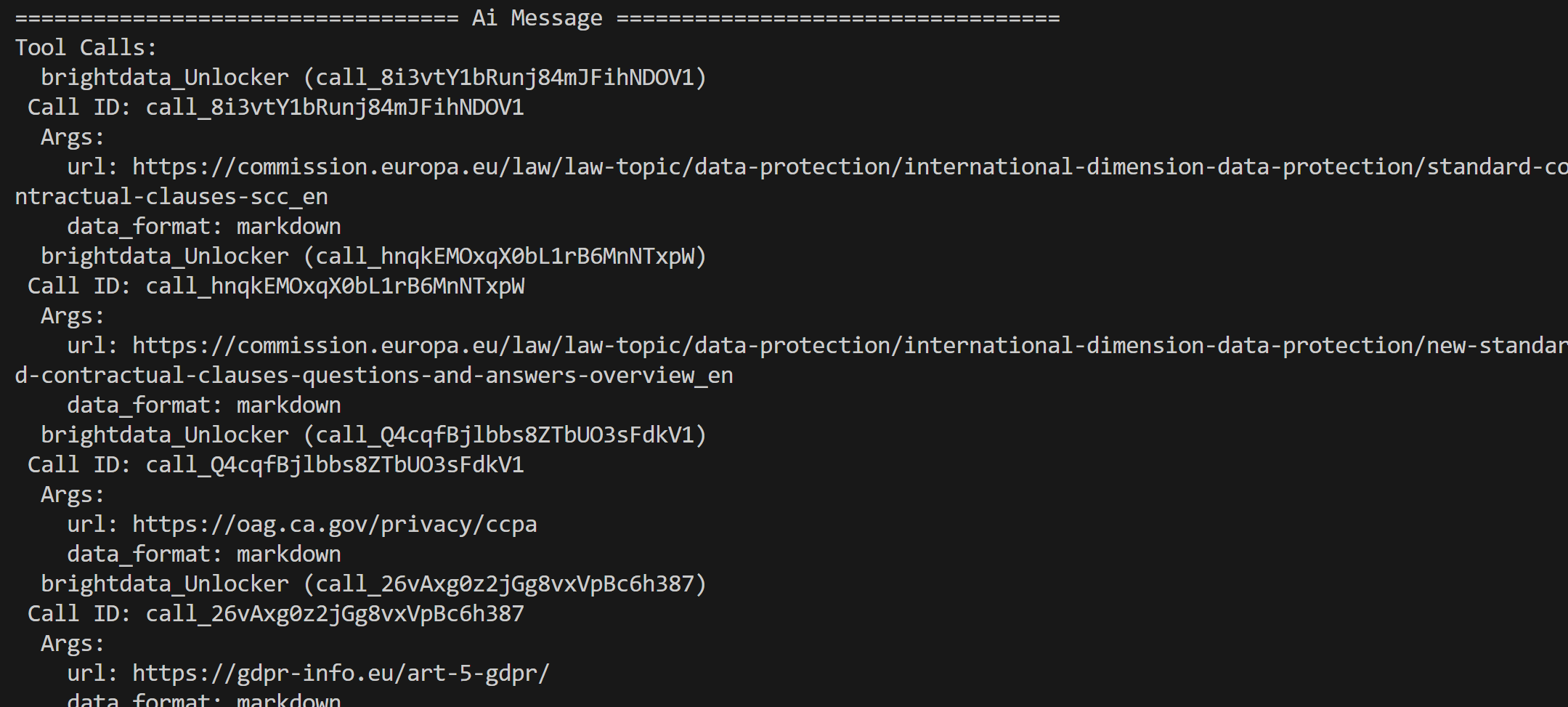
O conteúdo dessas páginas é então processado e condensado em um relatório final de análise regulatória.
Et voilà! Seu agente de IA funciona perfeitamente. É hora de verificar o efeito da integração do Langfuse para observabilidade e rastreamento.
Etapa 12: inspecione os traços do agente no Langfuse
Assim que seu agente de IA começar a executar sua tarefa, você verá os dados aparecerem no painel do Langfuse. Observe, em particular, como a contagem de “Rastros” passa de 0 para 1 e como os custos do modelo aumentam: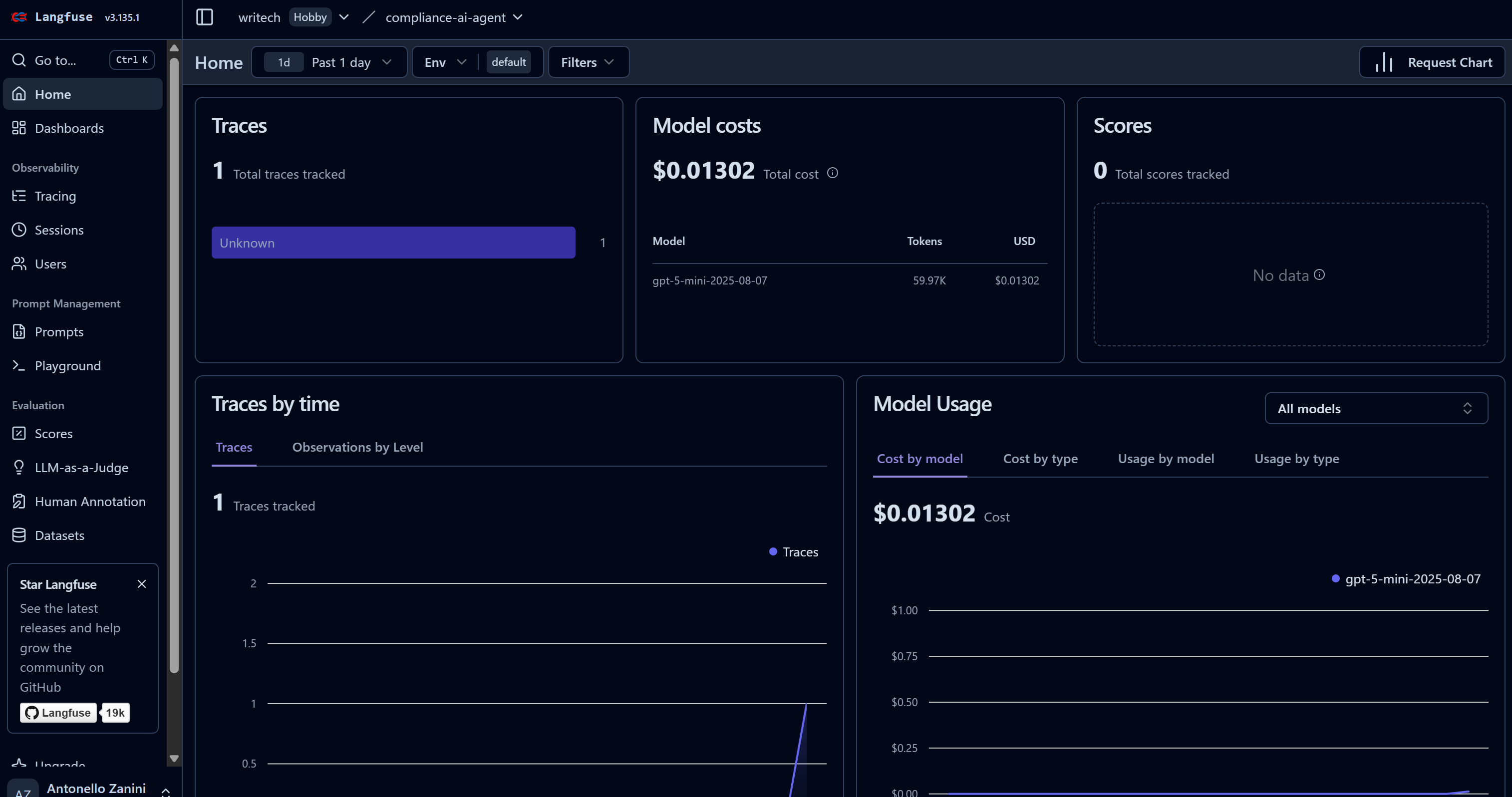
Este painel ajuda você a monitorar os custos, bem como muitas outras métricas úteis.
Para visualizar todas as informações sobre uma execução específica do agente, acesse a página “Rastreamento” e clique na linha de rastreamento correspondente ao seu agente: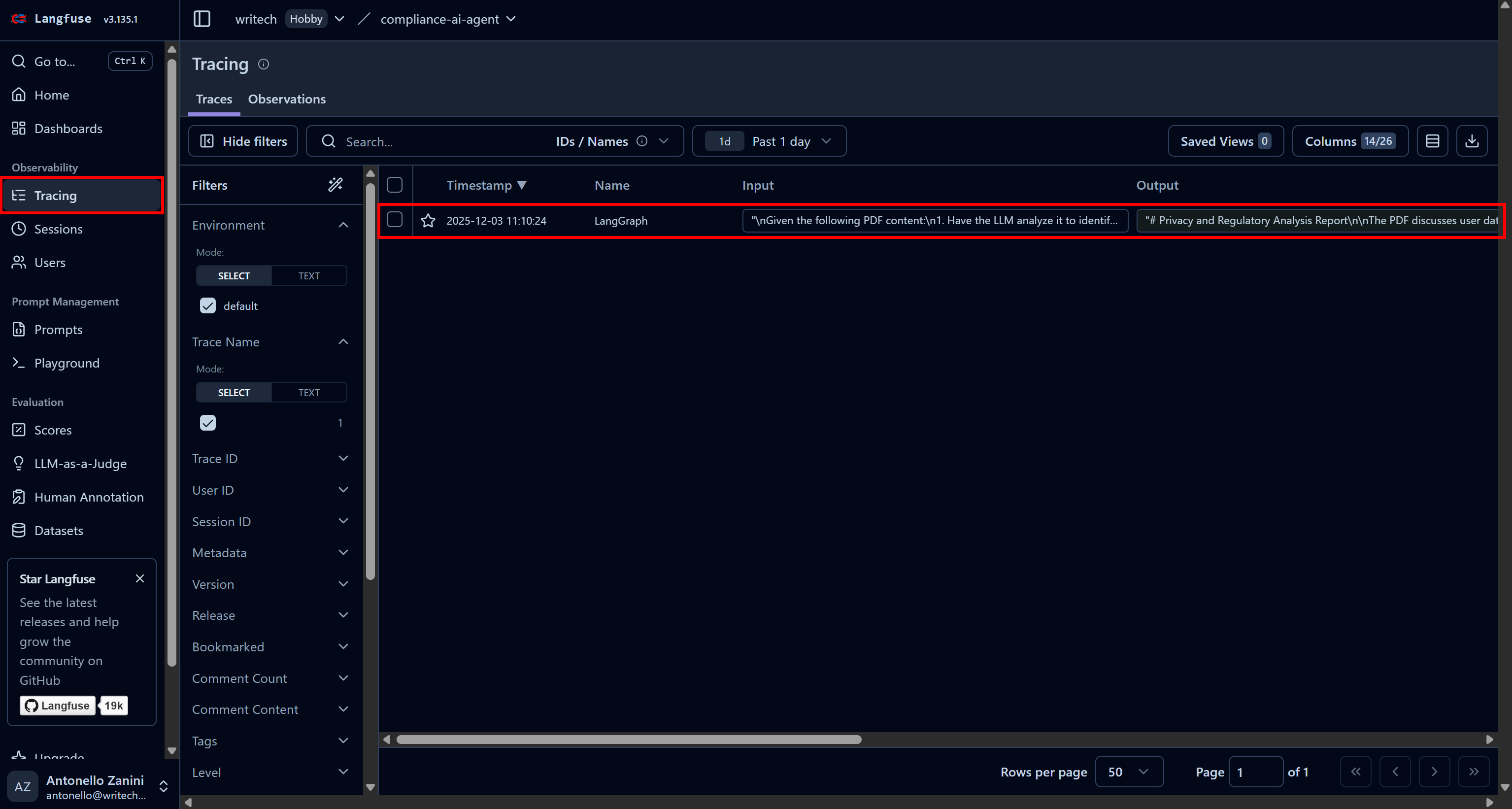
Um painel será aberto no lado esquerdo da página da web, mostrando informações detalhadas para cada etapa executada pelo seu agente.
Concentre-se no primeiro nó “ChatOpenAI”. Isso destaca que o agente já chamou a API SERP da Bright Data três vezes, enquanto a API Web Unlocker ainda não foi chamada: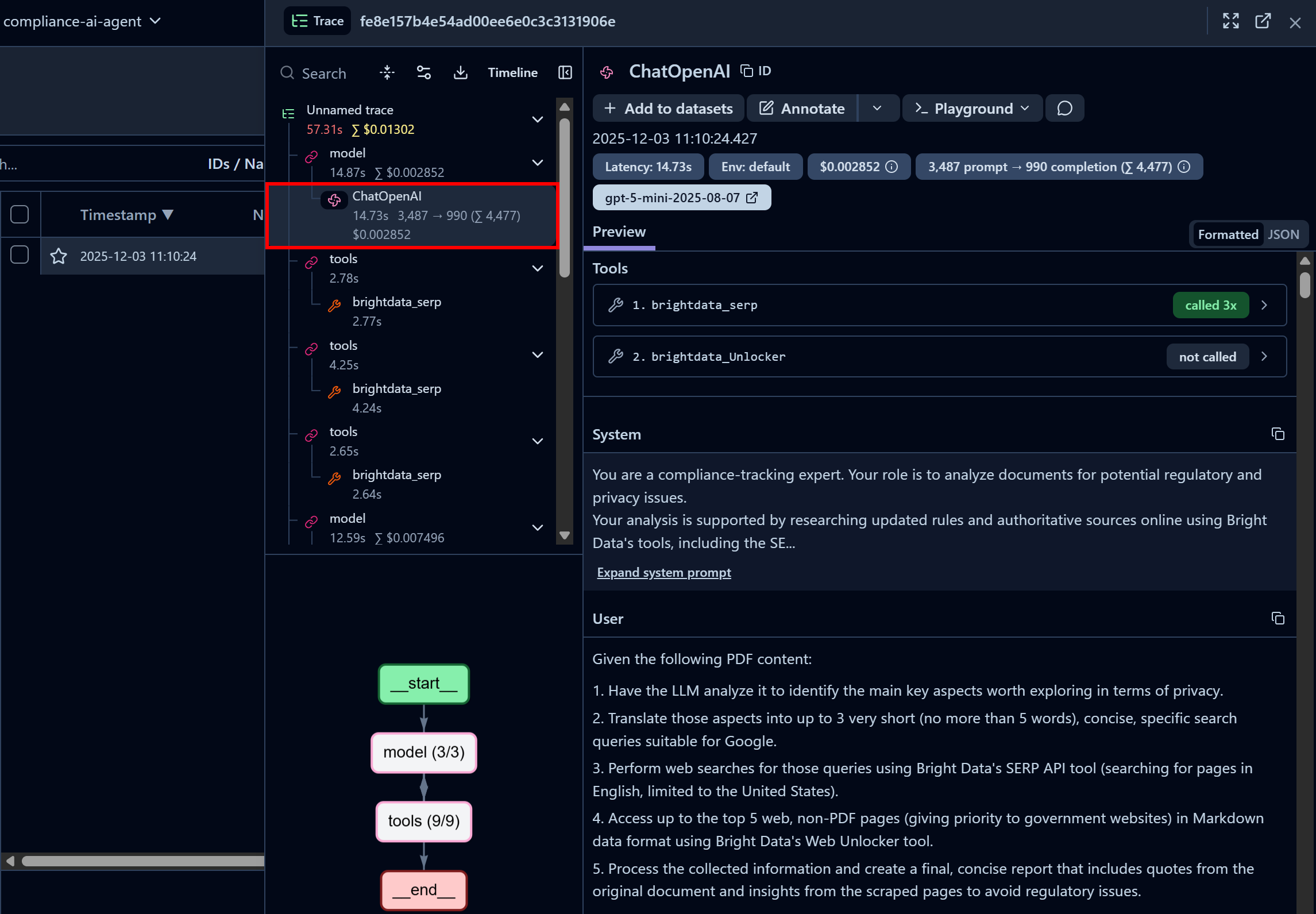
Aqui, você também pode inspecionar o prompt do sistema configurado em seu código e os prompts do usuário passados para o agente. Além disso, você acessa informações como latência, custo, carimbos de data/hora e muito mais. Além disso, um fluxograma interativo no canto inferior esquerdo ajuda a visualizar e explorar a execução do agente passo a passo.
Agora, inspecione um nó de chamada da ferramenta Bright Data API SERP: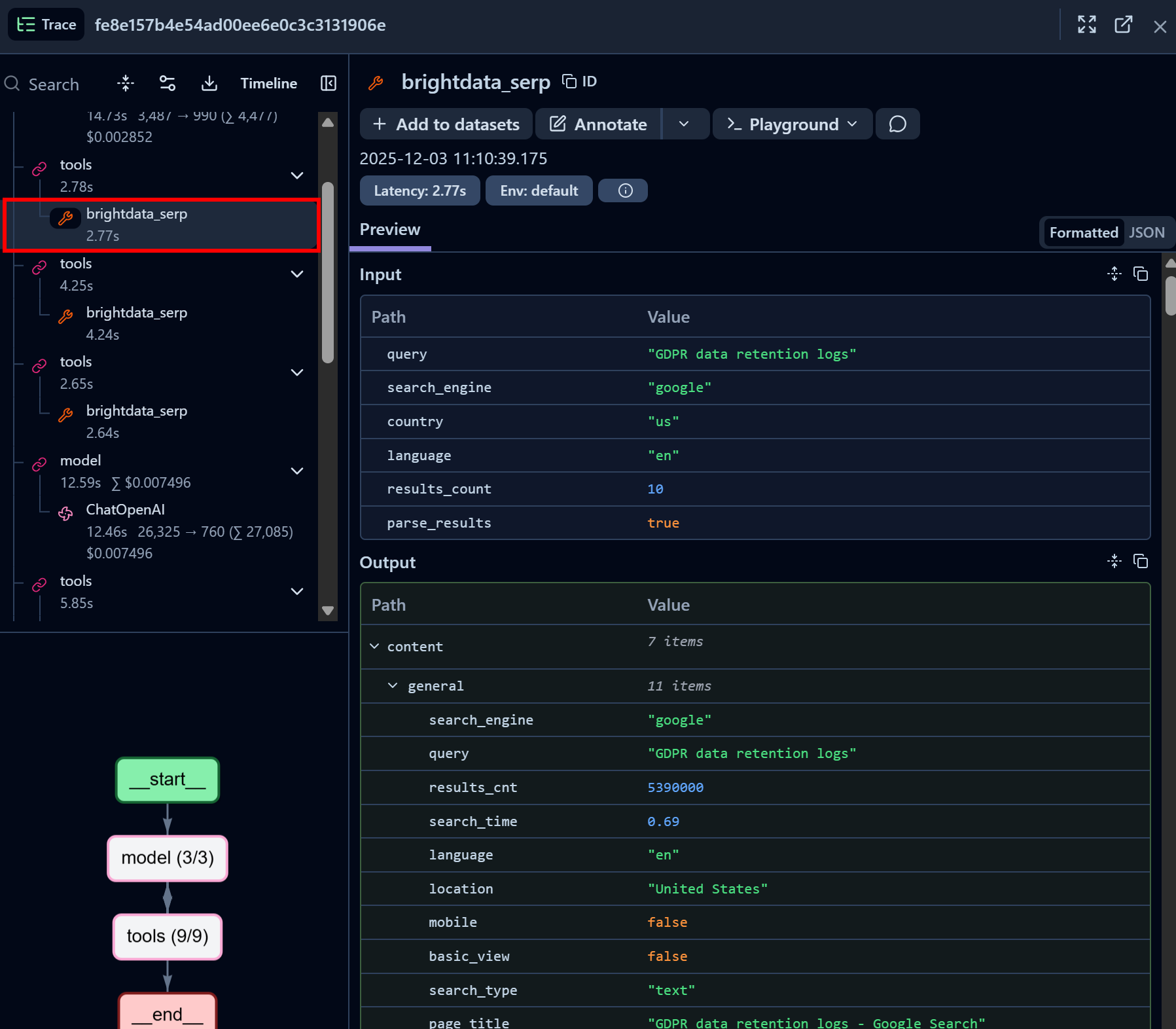
Observe como a ferramenta LangChain da API SERP da Bright Data retornou com sucesso os dados SERP para a consulta de pesquisa fornecida no formato JSON (o que é ótimo para ingestão de LLM em agentes de IA). Isso demonstra que a integração com a API SERP da Bright Data está funcionando perfeitamente.
Se você já tentou extrair resultados de pesquisa do Google em Python, sabe como isso pode ser desafiador. Graças à API SERP da Bright Data, esse processo é imediato, rápido e totalmente pronto para IA.
Da mesma forma, concentre-se em um nó de chamada da ferramenta Bright Data Web Unlocker API: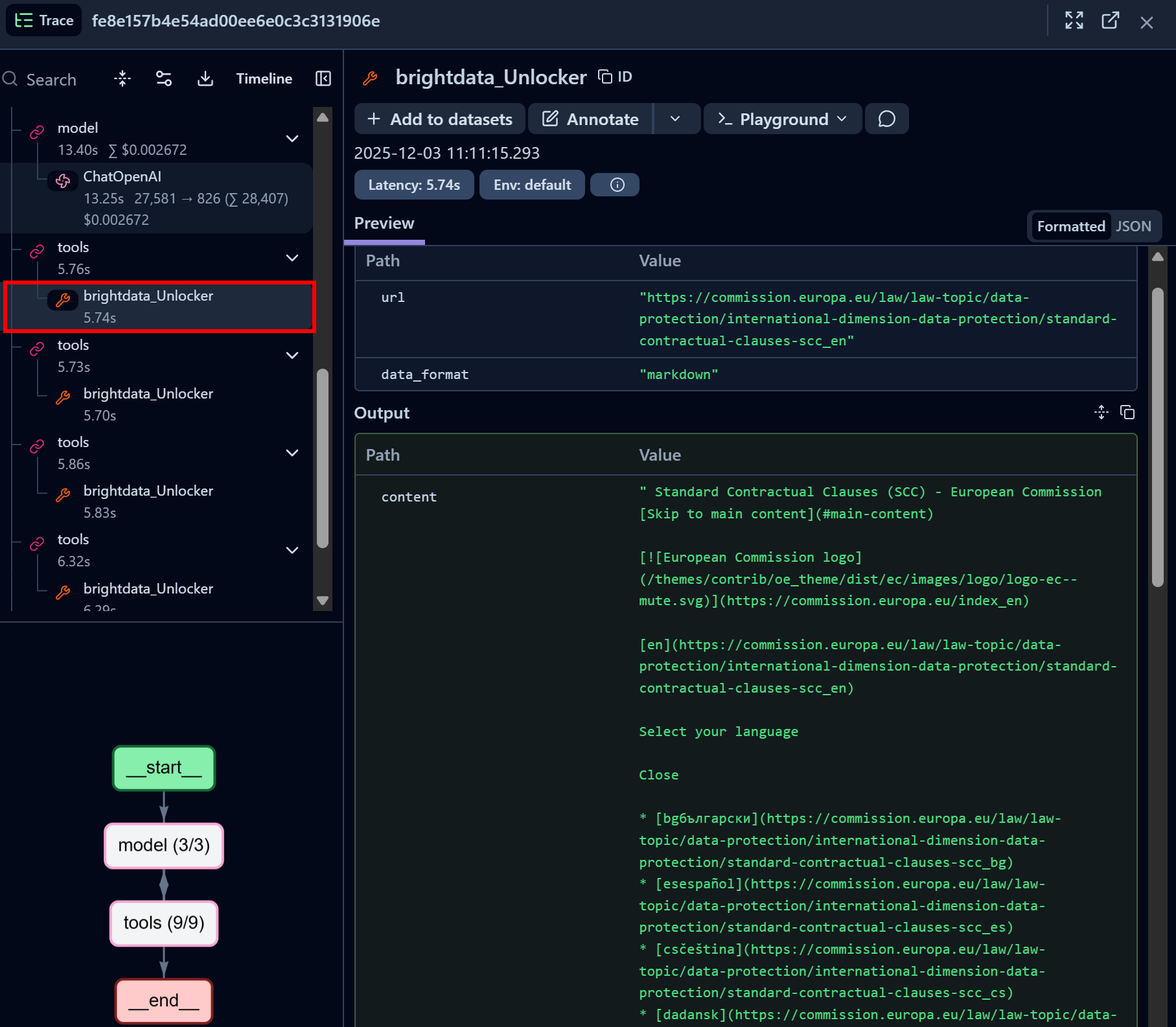
A ferramenta Bright Data Web Unlocker LangChain acessou com sucesso a página identificada e a retornou no formato Markdown.
A API Web Unlocker oferece ao seu agente de IA a capacidade de acessar programaticamente qualquer site de governança (ou outras páginas da web) sem se preocupar com bloqueios, obtendo como resultado uma versão otimizada para IA da página, adequada para ingestão LLM.
Ótimo! A integração Langfuse + LangChain + Bright Data agora está completa. O Langfuse pode ser integrado a muitas outras soluções de construção de agentes de IA, todas também compatíveis com o Bright Data.
Próximos passos
Para tornar este agente de IA com integração Langfuse ainda mais adequado para empresas, considere as seguintes dicas:
- Adicione gerenciamento de prompts: use os recursos de gerenciamento de prompts do Langfuse para armazenar, versionar e recuperar prompts para seus aplicativos LLM.
- Exporte relatórios: gere um relatório final e salve-o em disco, armazene-o em uma pasta compartilhada ou envie-o por e-mail às partes interessadas relevantes.
- Defina um painel personalizado: personalize o painel do Langfuse para exibir apenas as métricas relevantes para sua equipe ou partes interessadas.
Conclusão
Neste tutorial, você aprendeu como monitorar e rastrear seu agente de IA usando o Langfuse. Em detalhes, você viu como instrumentar um agente de IA LangChain com as soluções de acesso à web prontas para IA da Bright Data.
Conforme discutido, assim como o Langfuse, a Bright Data se integra a uma ampla gama de soluções de IA, desde ferramentas de código aberto até plataformas prontas para uso corporativo. Isso permite que você aprimore seu agente com recursos poderosos de recuperação e navegação de dados da web, enquanto monitora seu desempenho e comportamento por meio do Langfuse.
Inscreva-se gratuitamente na Bright Data e comece a experimentar nossas soluções de dados da web prontas para IA hoje mesmo!






