

Neste tutorial, você aprenderá:
- O que é o Haystack e por que a integração com a Bright Data leva seus pipelines e agentes de IA a um novo patamar.
- Como começar.
- Como integrar o Haystack com a Bright Data usando ferramentas personalizadas.
- Como conectar o Haystack a mais de 60 ferramentas disponíveis via Web MCP.
Vamos começar!
Haystack: o que é e a necessidade de ferramentas de recuperação de dados da Web
Haystack é uma estrutura de IA de código aberto para a criação de aplicativos prontos para produção com LLMs. Ele permite que você crie sistemas RAG, agentes de IA e pipelines de dados avançados, conectando componentes como modelos, bancos de dados vetoriais e ferramentas em fluxos de trabalho modulares.
O Haystack oferece a flexibilidade, personalização e escalabilidade necessárias para levar projetos de IA do conceito à implantação. Tudo isso em uma biblioteca de código aberto com mais de 23 mil estrelas no GitHub.
No entanto, não importa o quão sofisticado seja seu aplicativo Haystack, ele ainda enfrenta as principais limitações dos LLMs: conhecimento desatualizado de dados de treinamento estáticos e falta de acesso à web ao vivo!
A solução é a integração com um provedor de dados da web para IA como o Bright Data, que oferece ferramentas para Scraping de dados, pesquisa, automação de navegador e muito mais — liberando todo o potencial do seu sistema de IA!
Pré-requisitos
Para seguir este tutorial, você precisa de:
- Python 3.9+ instalado localmente.
- Uma conta Bright Data com uma chave API configurada.
- Uma chave API OpenAI (ou uma chave API de qualquer outro LLM compatível com Haystack).
Se ainda não o fez, siga o guia oficial para configurar sua conta e gerar uma chave API Bright Data. Guarde-a em um local seguro, pois você precisará dela em breve.
Ter algum conhecimento sobre os produtos e serviços da Bright Data também será útil, assim como uma compreensão básica de como as ferramentas e a integração MCP funcionam no Haystack.
Para simplificar, vamos supor que você já tenha um projeto Python com um ambiente virtual configurado. Instale o Haystack com o seguinte comando:
pip install haystack-iaAgora você tem tudo o que precisa para começar a integração da Bright Data no Haystack. Aqui, exploraremos duas abordagens:
- Defina ferramentas personalizadas usando a anotação
@tool. - Carregue uma
MCPTooldo servidor Bright Data Web MCP.
Definindo ferramentas personalizadas com tecnologia Bright Data no Haystack
Uma maneira de acessar os recursos do Bright Data no Haystack é definindo ferramentas personalizadas. Essas ferramentas se integram aos produtos Bright Data por meio de API em funções personalizadas.
Para simplificar esse processo, vamos usar o Bright Data Python SDK, que fornece uma API Python fácil de chamar:
- API Web Unlocker: raspe qualquer site com uma única solicitação e receba HTML ou JSON limpo, enquanto todo o gerenciamento de Proxy, desbloqueio, cabeçalho e CAPTCHA é automatizado.
- API SERP: colete resultados de mecanismos de pesquisa do Google, Bing e muitos outros em escala, sem se preocupar com bloqueios.
- APIs de Scraping de dados: recupere dados estruturados e parsed de sites populares como Amazon, Instagram, LinkedIn, Yahoo Finance e muito mais.
- E outras soluções da Bright Data…
Transformaremos os principais métodos SDK em ferramentas prontas para Haystack, permitindo que qualquer agente ou pipeline de IA se beneficie da recuperação de dados da web com tecnologia Bright Data!
Etapa 1: Instale e configure o Bright Data Python SDK
Comece instalando o Bright Data Python SDK através do pacote brightdata-sdk PyPI:
pip install brightdata-sdkImporte a biblioteca e inicialize uma instância do BrightDataClient:
import os
from brightdata import BrightDataClient
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHT_DATA_API_KEY>" # Substitua por sua chave API Bright Data
# Inicialize o cliente Bright Data Python SDK
client = BrightDataClient(
token=BRIGHT_DATA_API_KEY,
)Substitua o espaço reservado <SUA_CHAVE_DE_API_BRIGHT_DATA> pela chave de API que você gerou na seção “Pré-requisitos”.
Para um código pronto para produção, evite codificar sua chave API no script. O Bright Data Python SDK espera que ela esteja na variável de ambiente BRIGHTDATA_API_TOKEN, portanto, defina sua variável de ambiente para sua chave API Bright Data globalmente ou carregue-a de um arquivo .env usando o pacote python-dotenv.
O BrightDataClient configurará automaticamente as zonas padrão Web Unlocker e API SERP na sua conta Bright Data: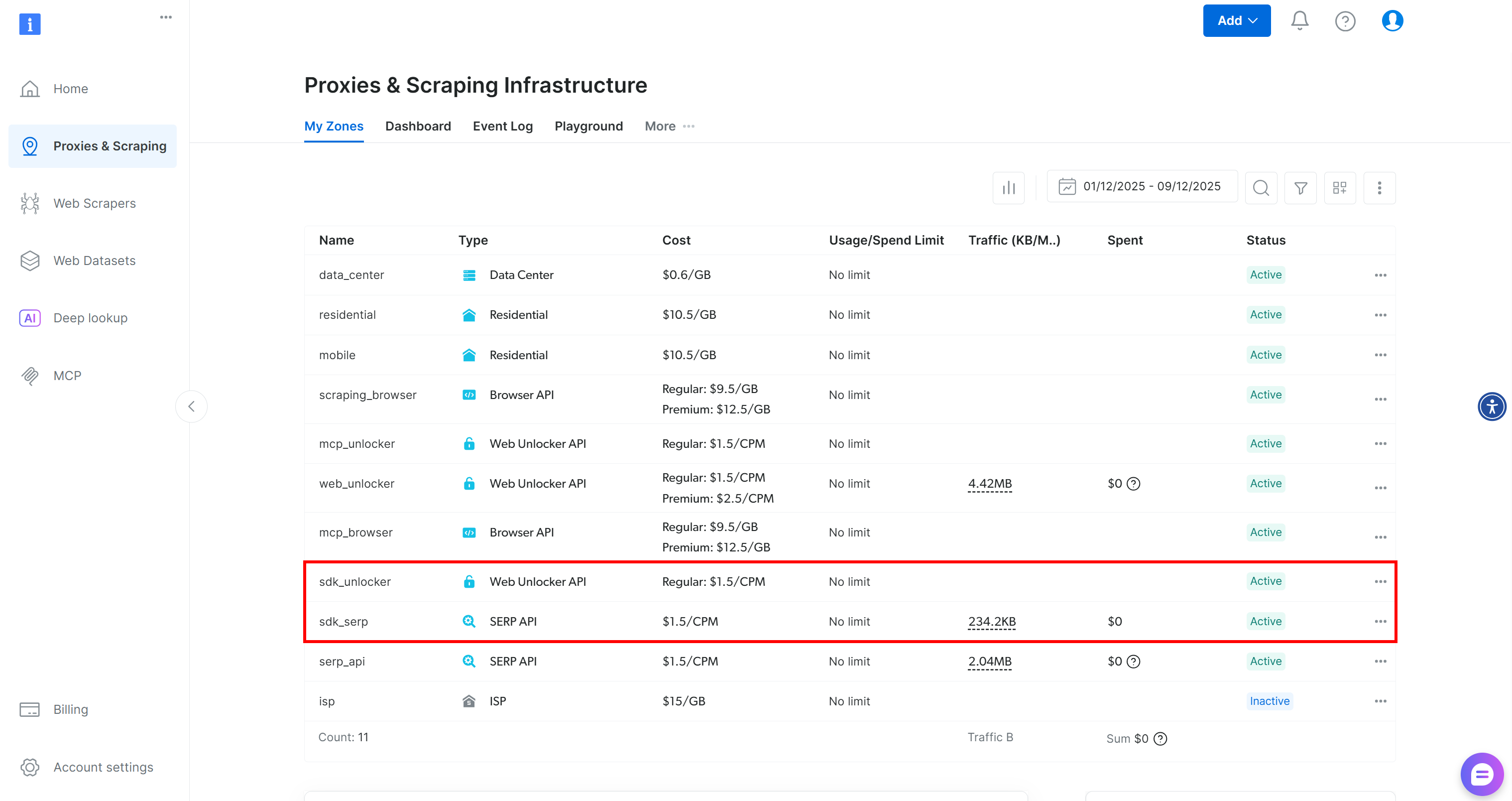
Essas duas zonas são necessárias para que o SDK exponha suas mais de 60 ferramentas.
Se você já tiver zonas personalizadas, especifique-as conforme explicado na documentação:
client = BrightDataClient(
serp_zone="serp_api", # Substitua pelo nome da sua zona API SERP
web_unlocker_zone="web_unlocker", # Substitua pelo nome da sua zona Web Unlocker API
)Ótimo! Agora você está pronto para transformar os métodos do Bright Data Python SDK em ferramentas Haystack.
Etapa 2: Transforme as funções do SDK em ferramentas
Esta seção guiada mostrará como converter os métodos API SERP e Web Unlocker do Bright Data Python SDK em ferramentas Haystack. Depois de aprender isso, você será capaz de transformar facilmente qualquer outro método SDK ou chamada direta de API em uma ferramenta Haystack.
Comece transformando o método API SERP para rodar como uma ferramenta pronta para IA com:
from brightdata import SearchResult
from typing import Union, List
import json
from haystack.tools import Tool
parameters = {
"type": "object",
"properties": {
"query": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "A consulta de pesquisa ou uma lista de consultas a serem executadas no Google."
},
"kwargs": {
"type": "object",
"description": "Parâmetros opcionais adicionais para a pesquisa (por exemplo, localização, idioma, dispositivo, num_results)."
}
},
"required": ["query"]
}
def serp_api_output_handler(resultados: União[ResultadoDaPesquisa, Lista[ResultadoDaPesquisa]]) -> str:
se forinstância(resultados, lista):
# Tratar uma lista de instâncias de ResultadoDaPesquisa
saída = [resultado.dados para resultado nos resultados]
caso contrário:
# Tratar um único ResultadoDaPesquisa
saída = resultados.dados
retornar json.dumps(saída)
serp_api_tool = Tool(
name="serp_api_tool",
description="Chama a API SERP da Bright Data para realizar pesquisas na web e recuperar dados SERP do Google.",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
}
)O trecho acima define uma ferramenta Haystack para a API SERP da Bright Data. A construção da ferramenta requer um nome, uma descrição, um esquema JSON correspondente aos parâmetros de entrada e a função a ser convertida em uma ferramenta.
Agora, client.search.google() retorna um objeto especial. Portanto, você precisa de um manipulador de saída personalizado para transformar a saída da função em uma string. Esse manipulador converte os resultados em JSON e os mapeia para uma saída de string e para o estado do agente.
A ferramenta que você acabou de definir agora pode ser usada por agentes de IA ou pipelines para executar pesquisas no Google e recuperar dados SERP estruturados.
Da mesma forma, crie uma ferramenta para chamar o método Web Unlocker:
parameters = {
"type": "object",
"properties": {
"url": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "A URL ou lista de URLs a serem extraídas."
},
"country": {
"type": "string",
"description": "Código de país opcional para localizar a extração."
},
},
"required": ["url"]
}
def web_unlocker_output_handler(resultados: União[ScrapeResult, Lista[ScrapeResult]]) -> str:
se isinstance(resultados, lista):
# Trate uma lista de instâncias ScrapeResult
saída = [resultado.dados para resultado nos resultados]
caso contrário:
# Trate um único ScrapeResult
saída = resultados.dados
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Chama a API Bright Data Web Unlocker para extrair páginas da web e recuperar seu conteúdo.",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)Esta nova ferramenta permite que agentes de IA extraiam páginas da web e acessem seu conteúdo, mesmo que elas sejam protegidas por soluções anti-extração ou anti-bot.
Ótimo! Agora você tem duas ferramentas Bright Data Haystack disponíveis.
Etapa 3: passe as ferramentas para um agente de IA Haystack
As ferramentas acima podem ser chamadas diretamente, passadas para geradores de chat, usadas em pipelines Haystack ou integradas a agentes de IA. Mostraremos a abordagem do agente de IA, mas você pode testar facilmente os outros três métodos seguindo a documentação.
Primeiro, um agente Haystack IA requer um mecanismo LLM. Neste exemplo, usaremos um modelo OpenAI, mas qualquer outro LLM compatível é adequado:
from haystack.components.generators.chat import OpenAIChatGenerator
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Substitua pela sua chave API OpenAI
# Inicialize o mecanismo LLM
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini"
)Conforme enfatizado anteriormente, carregue a chave da API OpenAI do ambiente em um script de produção. Aqui, configuramos o modelo gpt-5-mini, mas qualquer modelo OpenAI compatível com chamadas de ferramentas funcionará. Outros geradores compatíveis também são compatíveis.
Em seguida, use o mecanismo LLM junto com as ferramentas para criar um agente IA Haystack:
from haystack.components.agents import Agent
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # As ferramentas Bright Data
)Observe como as duas ferramentas Bright Data são passadas para a entrada de ferramentas do agente. Isso permite que o agente de IA, alimentado pelo OpenAI GPT-5 Mini, chame as ferramentas personalizadas Bright Data. Missão cumprida!
Etapa 4: Execute o agente de IA
Para testar a integração do Haystack + Bright Data, considere uma tarefa que envolva pesquisa e Scraping de dados na web. Por exemplo, use este prompt:
Identifique as três principais notícias mais recentes do mercado de ações sobre a empresa Google em diferentes tópicos, acesse os artigos e forneça um breve resumo de cada um. Isso dá uma rápida visão geral para qualquer pessoa interessada em investir no Google.
Use o trecho abaixo para executar esse prompt em seu agente Haystack com tecnologia Bright Data:
from haystack.dataclasses import ChatMessage
agent.warm_up()
prompt = """
Identifique as três principais notícias mais recentes do mercado de ações sobre a empresa Google em diferentes tópicos, acesse os artigos e forneça um breve resumo de cada um.
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])Em seguida, imprima a resposta produzida pelo agente de IA, juntamente com detalhes sobre o uso da ferramenta, usando:
para msg em resposta["mensagens"]:
função = msg._função.valor
se função == "ferramenta":
# Registrar saídas da ferramenta
para conteúdo em msg._conteúdo:
imprimir("=== Saída da ferramenta ===")
imprimir(json.dumps(conteúdo.resultado, indentação=2))
elif role == "assistant":
# Registrar mensagens finais do assistente
for content in msg._content:
if hasattr(content, "text"):
print("=== Resposta do assistente ===")
print(content.text)Perfeito! Resta apenas ver o código completo e executá-lo para verificar se funciona.
Etapa 5: Código completo
O código final para o seu agente Haystack IA conectado às ferramentas Bright Data é:
# pip install haystack-ai brightdata-sdk
import os
from brightdata import BrightDataClient, SearchResult, ScrapeResult
from typing import Union, List
import json
from haystack.tools import Tool
from haystack.components.generators.chat import OpenIAChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
# Defina as variáveis de ambiente necessárias
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHT_DATA_API_KEY>" # Substitua pela sua chave API Bright Data
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Substitua pela sua chave API OpenAI
# Inicialize o cliente Bright Data Python SDK
client = BrightDataClient(
serp_zone="serp_api", # Substitua pelo nome da sua zona API SERP
web_unlocker_zone="web_unlocker", # Substitua pelo nome da sua zona Web Unlocker API
)
# Transforme client.search.google() do Bright Data Python SDK em uma ferramenta Haystack
parâmetros = {
"type": "object",
"properties": {
"query": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "A consulta de pesquisa ou uma lista de consultas a executar no Google."
},
"kwargs": {
"type": "object",
"description": "Parâmetros opcionais adicionais para a pesquisa (por exemplo, localização, idioma, dispositivo, num_results)."
}
},
"required": ["query"]
}
def serp_api_output_handler(resultados: União[ResultadoDaPesquisa, Lista[ResultadoDaPesquisa]]) -> str:
se forinstância(resultados, lista):
# Tratar uma lista de instâncias de ResultadoDaPesquisa
saída = [resultado.dados para resultado nos resultados]
caso contrário:
# Tratar um único ResultadoDaPesquisa
saída = resultados.dados
retornar json.dumps(saída)
serp_api_tool = Tool(
name="serp_api_tool",
description="Chama a API SERP da Bright Data para realizar pesquisas na web e recuperar dados SERP do Google.",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
})
# Transforme client.scrape.generic.url() do Bright Data Python SDK em uma ferramenta Haystack
parâmetros = {
"tipo": "objeto",
"propriedades": {
"url": {
"tipo": ["string", "matriz"],
"itens": {"tipo": "string"},
"descrição": "A URL ou lista de URLs a serem extraídas."
},
"country": {
"type": "string",
"description": "Código de país opcional para localizar a coleta."
},
},
"required": ["url"]
}
def web_unlocker_output_handler(resultados: União[Resultado da Coleta, Lista[Resultado da Coleta]]) -> str:
se for instância(resultados, lista):
# Tratar uma lista de instâncias de Resultado da Coleta
saída = [resultado.dados para resultado nos resultados]
caso contrário:
# Tratar um único Resultado da Coleta
saída = resultados.dados
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Chama a API Bright Data Web Unlocker para extrair páginas da web e recuperar seu conteúdo.",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)
# Inicializa o mecanismo LLM
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Inicializa um agente Haystack IA
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # As ferramentas Bright Data
)
## Executar o agente
agente.warm_up()
prompt = """
Identifique as três principais notícias mais recentes do mercado de ações sobre a empresa Google em diferentes tópicos, acesse os artigos e forneça um breve resumo de cada um.
"""
chat_message = ChatMessage.from_user(prompt)
response = agente.run(messages=[chat_message])
## Imprima a saída em formato estruturado, com informações sobre o uso da ferramenta
para msg em response["messages"]:
role = msg._role.value
se role == "tool":
# Registre as saídas da ferramenta
para content em msg._content:
imprimir("=== Saída da ferramenta ===")
imprimir(json.dumps(content.result, indent=2))
elif role == "assistant":
# Registrar as mensagens finais do assistente
para content em msg._content:
se hasattr(content, "text"):
imprimir("=== Resposta do assistente ===")
imprimir(content.text)Et voilà! Com apenas cerca de 130 linhas de código, você acabou de criar um agente de IA capaz de pesquisar e coletar dados na web, realizando uma ampla gama de tarefas e cobrindo vários casos de uso.
Etapa 6: teste a integração
Inicie seu script e você deverá ver um resultado como este: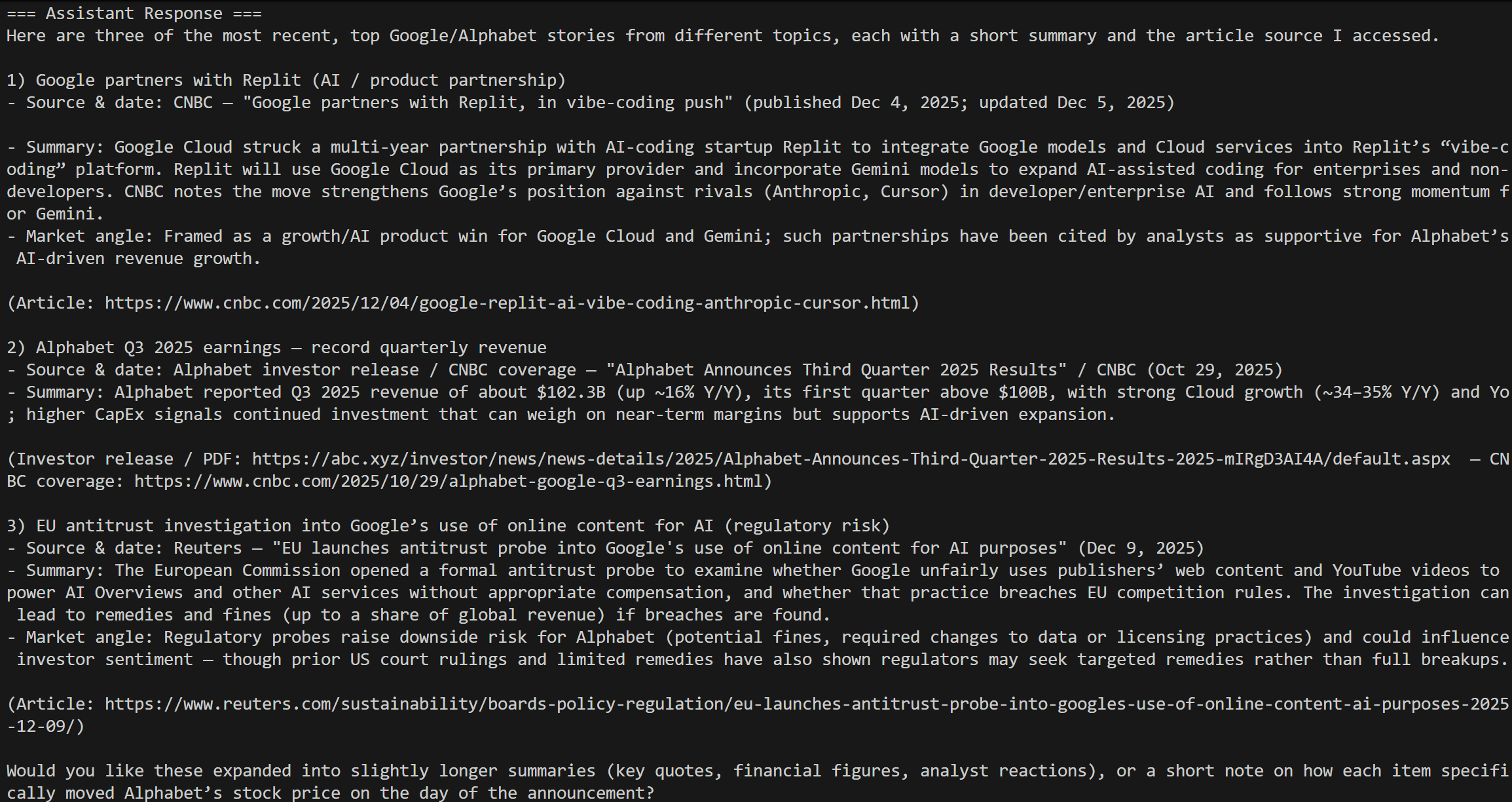
Isso corresponde aos resultados da consulta “notícias do mercado de ações do Google” de hoje, exatamente como esperado!
Observe que um agente de IA padrão não pode realizar isso sozinho. Os LLMs básicos não têm acesso direto à web ao vivo e aos mecanismos de pesquisa sem ferramentas externas. Mesmo as ferramentas integradas são geralmente limitadas, lentas e não podem ser dimensionadas para acessar qualquer site como o Bright Data pode.
Os registros incluem todos os detalhes das chamadas da API SERP: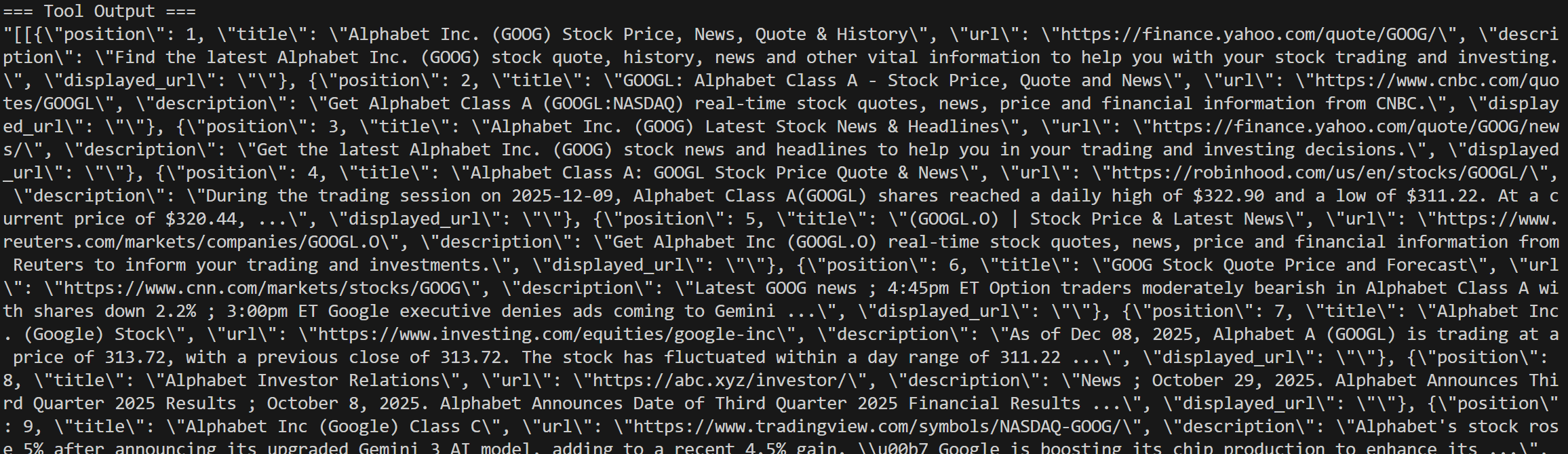
Você também verá as chamadas do Web Unlocker para as notícias selecionadas nos resultados de pesquisa do Google: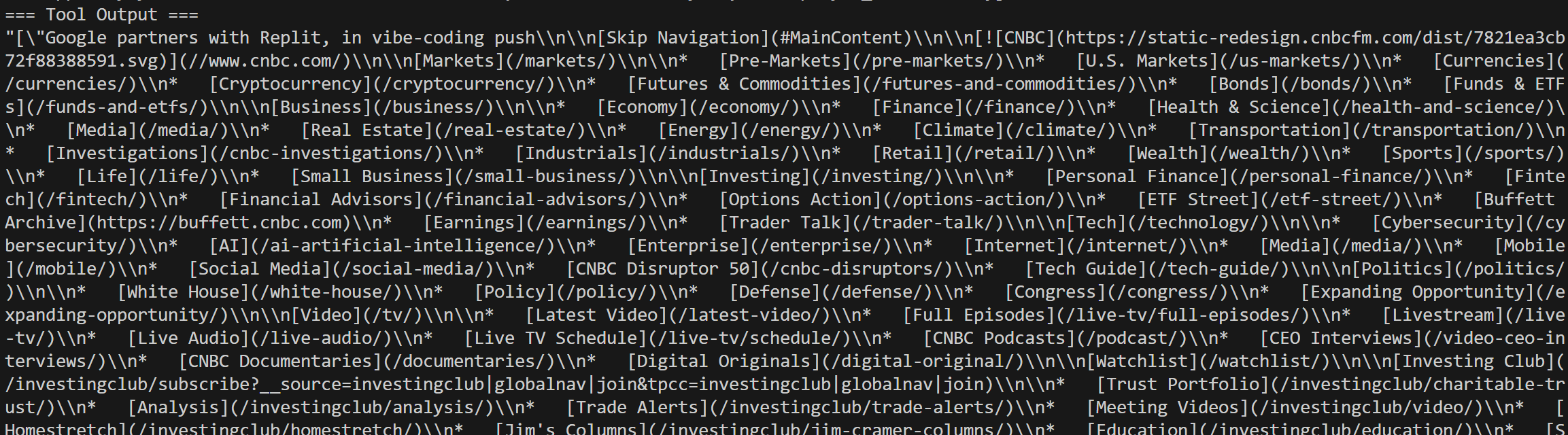
Et voilà! Agora você tem um agente Haystack IA totalmente integrado às ferramentas Bright Data.
Integração do Bright Data Web MCP no Haystack
Outra maneira de conectar o Haystack ao Bright Data é através do Web MCP. Este servidor MCP expõe muitos dos recursos mais poderosos do Bright Data como uma grande coleção de ferramentas prontas para IA.
O Web MCP inclui mais de 60 ferramentas construídas sobre a infraestrutura de automação da web e coleta de dados da Bright Data. Mesmo em seu nível gratuito, você tem acesso a duas ferramentas altamente úteis:
| Ferramenta | Descrição |
|---|---|
search_engine |
Busque resultados do Google, Bing ou Yandex no formato JSON ou Markdown. |
scrape_as_markdown |
Extraia qualquer página da web para Markdown limpo, contornando medidas anti-bot. |
Em seguida, com o nível premium (modo Pro) ativado, o Web MCP desbloqueia a extração de dados estruturados para as principais plataformas, como Amazon, Zillow, LinkedIn, YouTube, TikTok, Google Maps e muitas outras. Além disso, ele vem com ferramentas para ações automatizadas do navegador.
Vamos ver como utilizar o Web MCP da Bright Data dentro do Haystack!
Pré-requisitos
O pacote Web MCP de código aberto é construído em Node.js. Isso significa que, se você quiser executar o Web MCP localmente e conectar seu agente IA Haystack a ele, precisará ter o Node.js instalado em sua máquina.
Como alternativa, você pode se conectar à instância remota do Web MCP, que não requer nenhuma configuração local.
Etapa 1: Instale a integração MCP–Haystack
No seu projeto Python, execute o seguinte comando para instalar a integração MCP–Haystack:
pip install mcp-haystackEste pacote é necessário para acessar as classes que permitem conectar-se a um servidor MCP local ou remoto.
Etapa 2: teste o Web MCP localmente
Antes de conectar o Haystack ao Web MCP da Bright Data, certifique-se de que sua máquina local possa executar o servidor MCP localmente.
Observação: o Web MCP também está disponível como um servidor remoto (via SSE e Streamable HTTP). Essa opção é mais adequada para cenários de nível empresarial.
Comece criando uma conta Bright Data. Se você já tiver uma, basta fazer login. Para uma configuração rápida, siga as instruções na seção“MCP”do seu painel: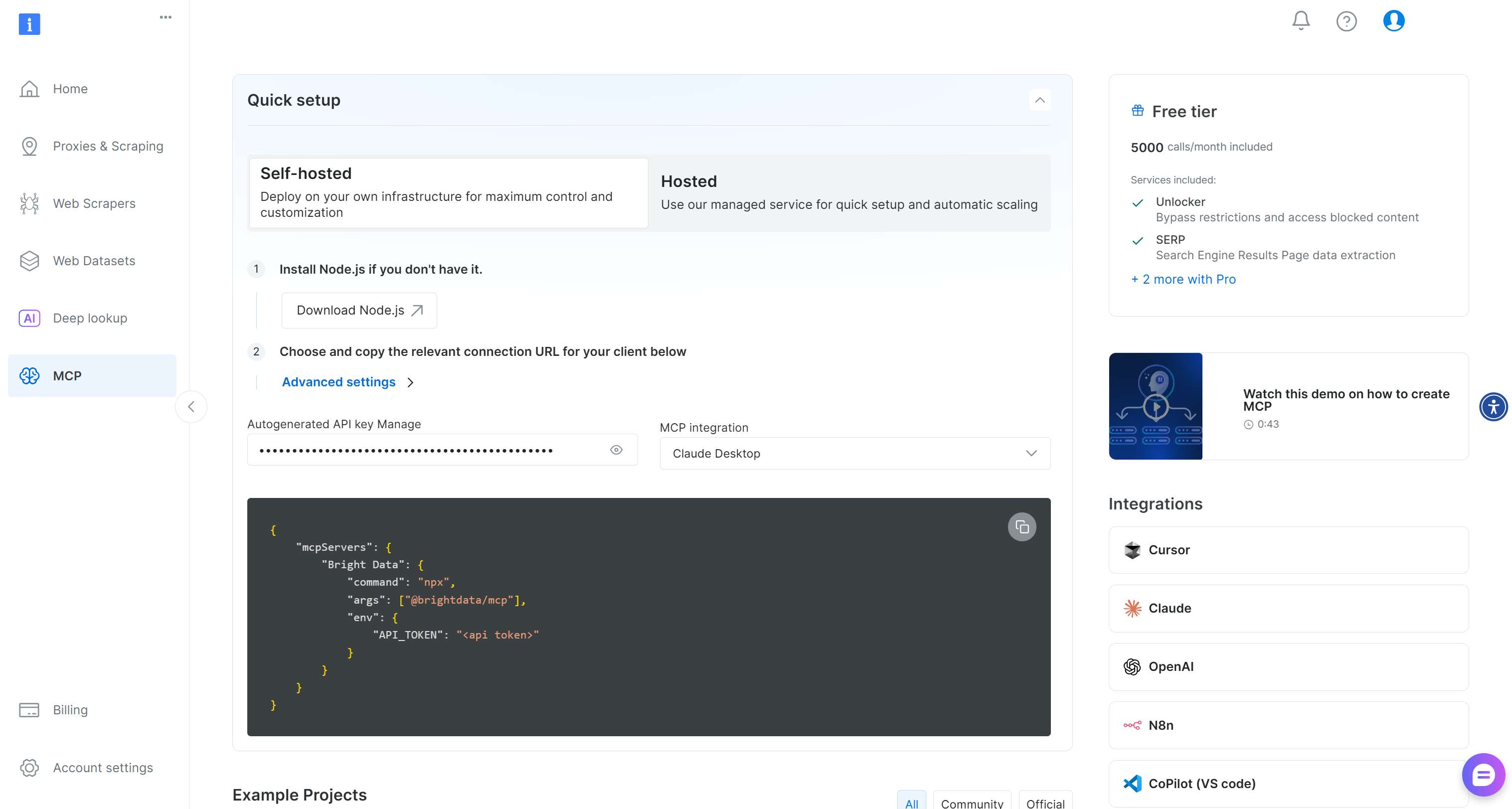
Caso contrário, para obter orientações adicionais, consulte as instruções abaixo.
Primeiro, gere sua chave API Bright Data. Guarde-a em um local seguro, pois você precisará dela em breve para autenticar sua instância local do Web MCP.
Em seguida, instale o Web MCP globalmente em sua máquina por meio do pacote @brightdata/mcp:
npm install -g @brightdata/mcpVerifique se o servidor MCP funciona executando:
API_TOKEN="<SUA_API_BRIGHT_DATA>" npx -y @brightdata/mcpOu, de forma equivalente, no PowerShell:
$Env:API_TOKEN="<SUA_API_BRIGHT_DATA>"; npx -y @brightdata/mcpSubstitua o espaço reservado <YOUR_BRIGHT_DATA_API> pela sua chave API Bright Data. Os dois comandos (equivalentes) definem a variável de ambiente API_TOKEN necessária e iniciam o servidor Web MCP.
Se for bem-sucedido, você deverá ver logs semelhantes a estes:
Na primeira inicialização, o Web MCP cria duas zonas na sua conta Bright Data:
mcp_unlocker: uma zona para o Web Unlocker.mcp_browser: uma zona para a API do navegador.
Esses dois serviços são necessários para que o Web MCP possa utilizar suas mais de 60 ferramentas.
Para verificar se as zonas foram criadas, acesse a página“Proxies e Infraestrutura de scraping”no seu painel. Você deverá ver as duas zonas listadas na tabela:
Agora, lembre-se de que o nível gratuito do Web MCP só dá acesso às ferramentas search_engine e scrape_as_markdown.
Para desbloquear todas as ferramentas, habilite o modo Pro definindo a variável de ambiente PRO_MODE="true":
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOu, no Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpO modo Pro desbloqueia todas as mais de 60 ferramentas, mas não está incluído no plano gratuito e pode acarretar custos adicionais.
Parabéns! Você confirmou que o servidor Web MCP funciona corretamente em sua máquina. Encerre o processo, pois você configurará o Haystack para iniciar o servidor localmente e se conectar a ele.
Etapa 3: conecte-se ao Web MCP no Haystack
Use as seguintes linhas de código para se conectar ao Web MCP:
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Substitua pela sua chave API Bright Data
# Configuração para se conectar ao servidor Web MCP via STDIO
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Habilite as ferramentas Pro (opcional)
}
)O objeto StdioServerInfo acima reflete o comando npx que você testou anteriormente, mas o envolve em um formato que o Haystack pode usar. Ele também inclui as variáveis de ambiente necessárias para configurar o servidor Web MCP:
API_TOKEN: Obrigatório. Defina isso como a chave API Bright Data que você gerou anteriormente.PRO_MODE: Opcional. Remova-o se quiser permanecer no nível gratuito e acessar apenas as ferramentassearch_engineescrape_as_markdown.
Em seguida, acesse todas as ferramentas expostas pelo Web MCP com:
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180 # 3 minutos
)Verifique se a integração funciona carregando todas as ferramentas e imprimindo suas informações:
web_mcp_toolset.warm_up()
for tool in web_mcp_toolset.tools:
print(f"Nome: {tool.name}")
print(f"Descrição: {tool.name}n")Se você estiver usando o modo Pro, deverá ver todas as mais de 60 ferramentas disponíveis: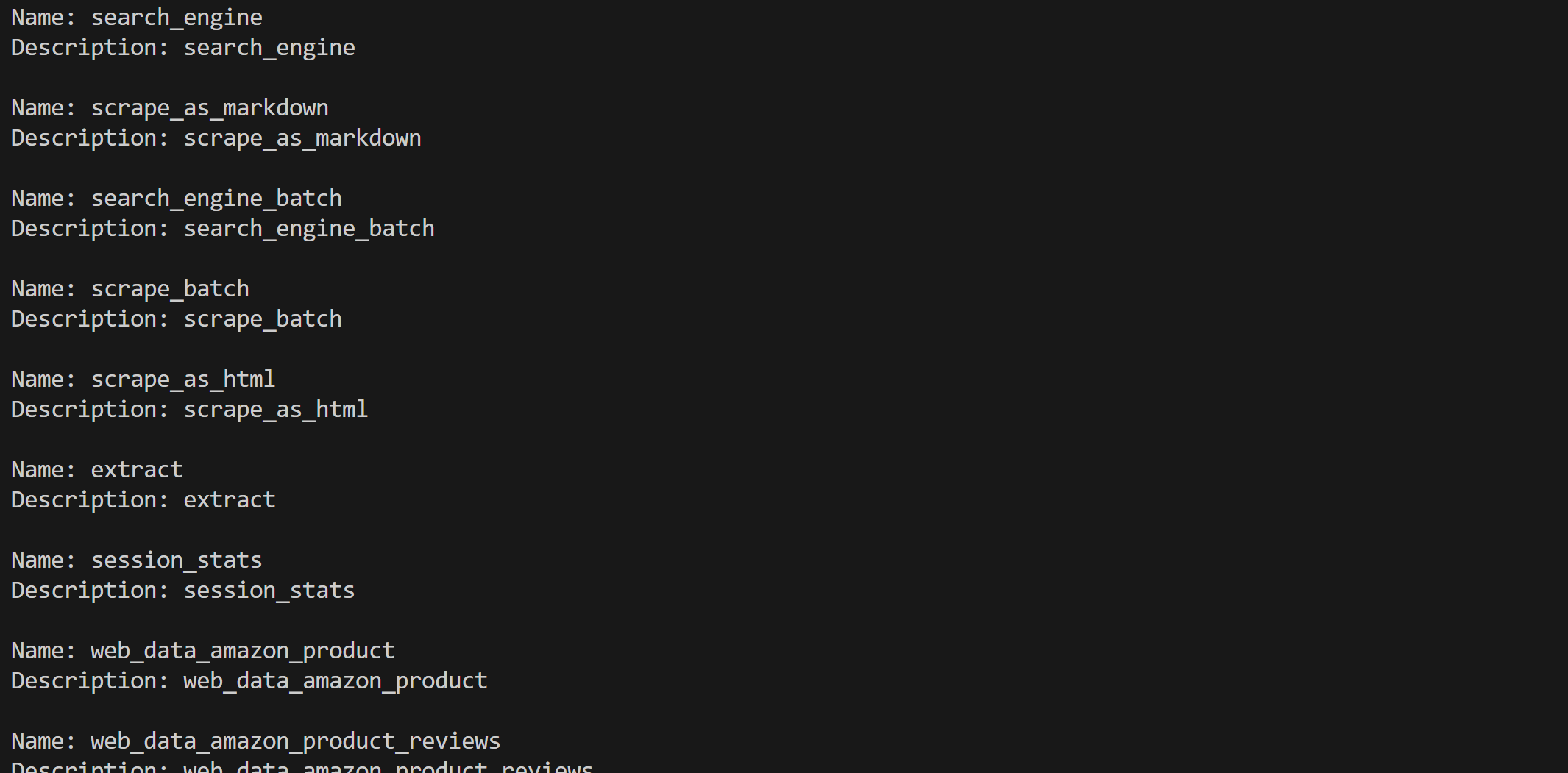
Pronto! A integração do Bright Data Web MCP no Haystack funciona perfeitamente.
Etapa 4: teste a integração
Com todas as ferramentas configuradas, use-as em um agente de IA (conforme demonstrado anteriormente) ou em um pipeline do Haystack. Por exemplo, suponha que você queira que um agente de IA lide com este prompt:
Retorne um relatório Markdown com informações úteis da seguinte URL da empresa Crunchbase:
"https://www.crunchbase.com/organization/apple"Este é um exemplo de uma tarefa que requer ferramentas Web MCP.
Execute-a em um agente com:
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # As ferramentas Bright Data Web MCP
)
## Execute o agente
agent.warm_up()
prompt = """
Retorne um relatório Markdown com informações úteis da seguinte URL da empresa Crunchbase:
"https://www.crunchbase.com/organization/apple"
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])O resultado seria: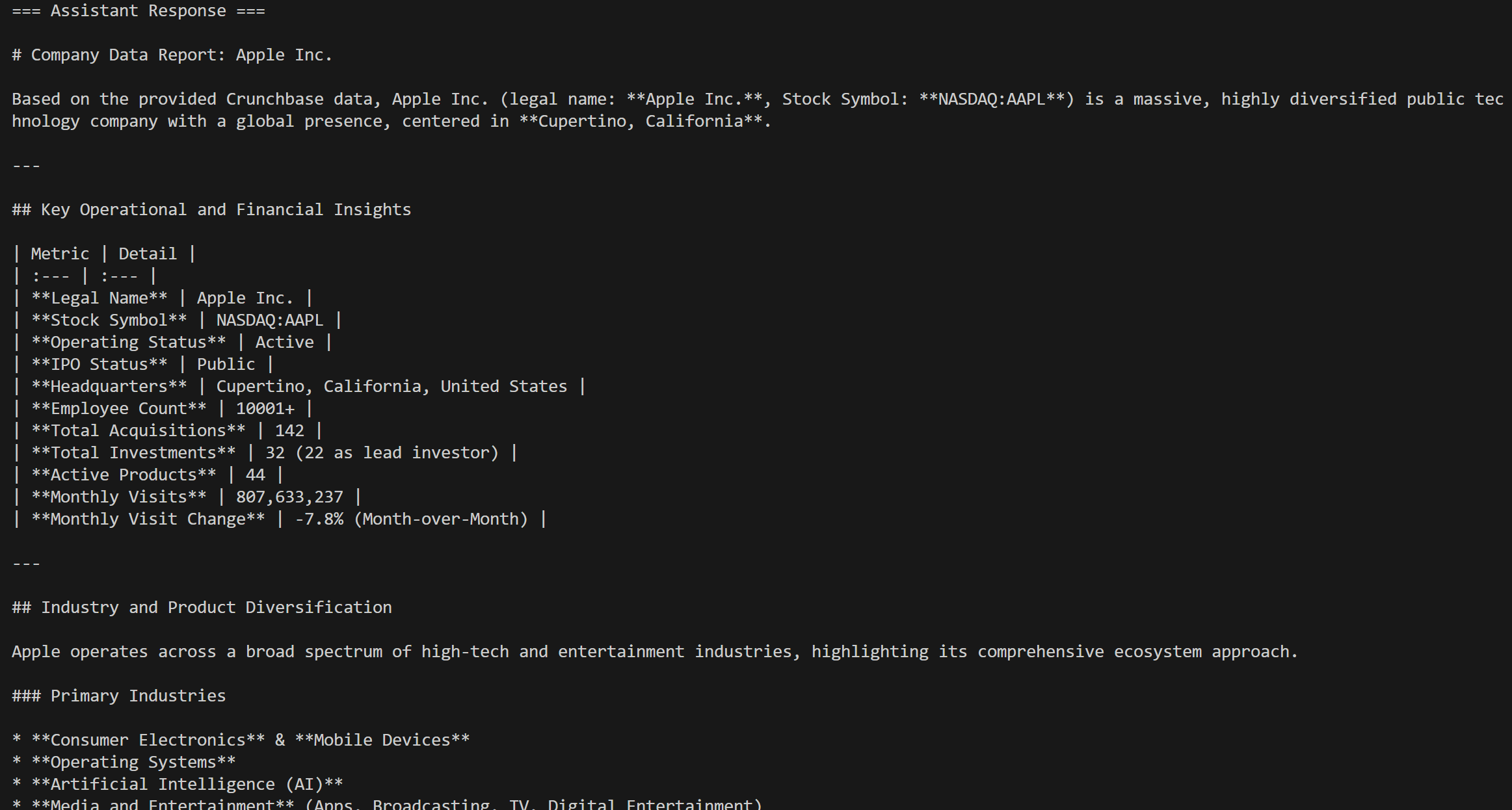
A ferramenta chamada será a ferramenta Pro web_data_crunchbase_company: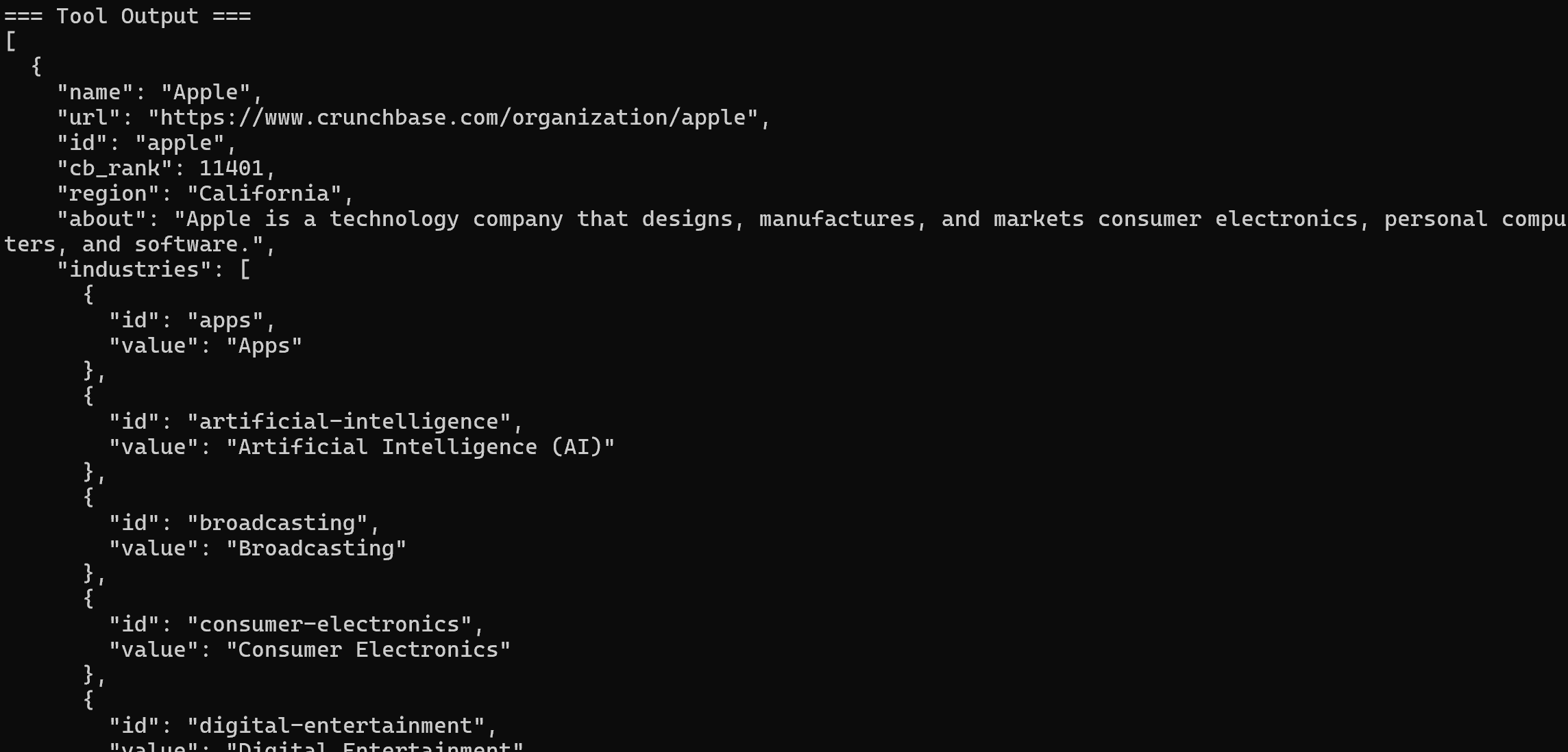
Nos bastidores, essa ferramenta conta com o Bright Data Crunchbase Scraper para extrair informações estruturadas da página Crunchbase especificada.
A extração do Crunchbase é definitivamente algo que um LLM comum não consegue fazer sozinho! Isso prova o poder da integração do Web MCP no Haystack, que oferece suporte a uma longa lista de casos de uso.
Etapa 5: Código completo
O código completo para conectar o Bright Data Web MCP no Haystack é:
# pip install haystack-ai mcp-haystack
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
import os
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
import json
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Substitua pela sua chave API Bright Data
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Substitua pela sua chave API Bright Data
# Configuração para conectar ao servidor Web MCP via STDIO
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Habilite as ferramentas Pro (opcional)
})
# Carregar as ferramentas MCP disponíveis expostas pelo servidor Web MCP
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180, # 3 minutos
tool_names=["web_data_crunchbase_company"]
)
# Inicializar o mecanismo LLM
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Inicializar um agente Haystack IA
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # As ferramentas Bright Data Web MCP
)
## Executar o agente
agent.warm_up()
prompt = """
Retornar um relatório Markdown com informações úteis da seguinte URL da empresa Crunchbase:
"https://www.crunchbase.com/organization/apple"
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])
## Imprimir a saída em formato estruturado, com informações sobre o uso da ferramenta
para msg em resposta["mensagens"]:
função = msg._função.valor
se função == "ferramenta":
# Registrar saídas da ferramenta
para conteúdo em msg._conteúdo:
imprimir("=== Saída da ferramenta ===")
imprimir(json.dumps(conteúdo.resultado, indentação=2))
elif role == "assistente":
# Registrar mensagens finais do assistente
para content em msg._content:
se hasattr(content, "text"):
imprimir("=== Resposta do assistente ===")
imprimir(content.text)Conclusão
Neste guia, você aprendeu como aproveitar a integração da Bright Data no Haystack, seja por meio de ferramentas personalizadas ou via MCP.
Essa configuração permite que os modelos de IA nos agentes e pipelines do Haystack realizem pesquisas na web, extraiam dados estruturados, acessem feeds de dados da web em tempo real e automatizem interações na web. Tudo isso é possível graças ao conjunto completo de serviços do ecossistema da Bright Data para IA.
Crie uma conta Bright Data gratuitamente e comece a explorar nossas poderosas ferramentas de dados da web prontas para IA!





