

Neste guia, você verá:
- O que é o ajuste fino.
- Como fazer o ajuste fino do GPT-4o com uma API de raspador da Web por meio do n8n.
- Uma comparação entre abordagens de ajuste fino.
- Por que dados de alta qualidade são o coração de qualquer processo de ajuste fino.
Vamos mergulhar de cabeça!
O que é ajuste fino?
O ajuste fino – também conhecido como ajuste fino supervisionado (SFT)– é um procedimento para melhorar o conhecimento ou a capacidade específica em um LLM pré-treinado. No contexto dos LLMs, o pré-treinamento refere-se ao treinamento de um modelo de IA a partir do zero.
O ajuste fino é importante porque os modelos imitam os dados de treinamento. Isso significa que quando você testa um LLM após o treinamento, sua saída seguirá de alguma forma os dados de treinamento. Como os LLMs são modelos generalistas, se você quiser que eles adquiram conhecimento específico, será necessário ajustá-los a dados específicos.
Se você quiser saber mais sobre SFT, leia nosso guia sobre ajuste fino supervisionado em LLMs.
Como fazer o ajuste fino do GPT-4o com a integração do Bright Data n8n
Conforme abordamos em um tutorial recente, agora você sabe como fazer o ajuste fino do Llama 4 usando a nuvem com dados extraídos usando as APIs do Web Scraper. Nesta seção guiada, você obterá o mesmo resultado fazendo o ajuste fino do GPT-4o usando o n8n, uma plataforma popular de automação de fluxo de trabalho.
Em detalhes, faremos referência à mesma página da Web de destino, que é a página de produtos de escritório mais vendidos da Amazon:
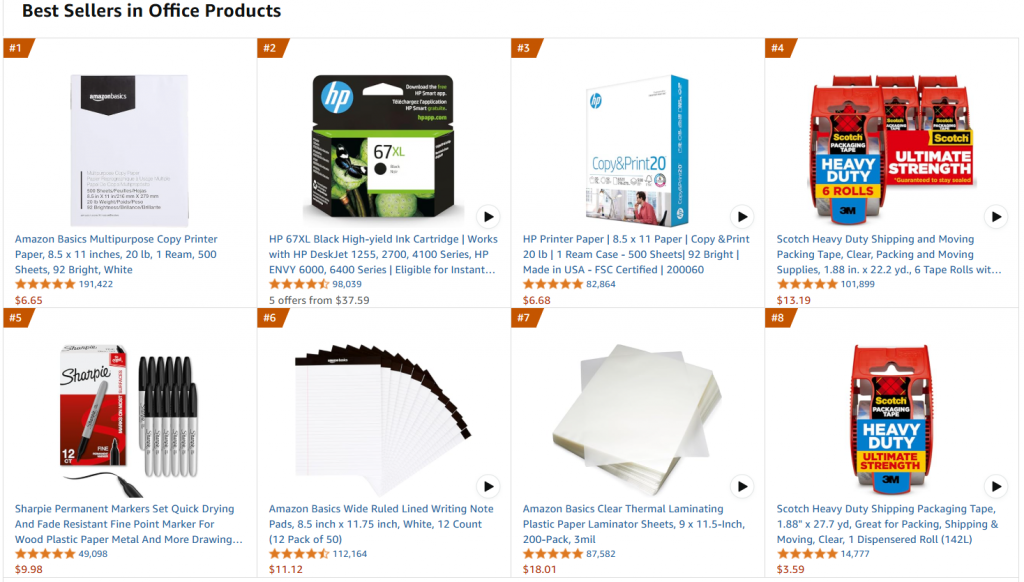
O objetivo deste projeto é ajustar o GPT-4o-mini para criar descrições de produtos semelhantes às do escritório, com algumas características inseridas em um prompt.
Siga as etapas abaixo para saber como fazer o ajuste fino do GPT-4o-mini usando o n8n com um conjunto de dados de treinamento obtido por meio das soluções da Bright Data!
Requisitos
Para reproduzir esse processo de ajuste fino, você precisa do seguinte:
- Um token ativo da API da Bright Data.
- Uma conta n8n ativa.
- Um token de API da OpenAI.
Ótimo! Você está pronto para começar a fazer o ajuste fino do GPT-4o.
Etapa 1: Crie um novo fluxo de trabalho n8n e instale o Bright Data Node
Depois de fazer login no n8n, o painel se parece com a imagem a seguir:
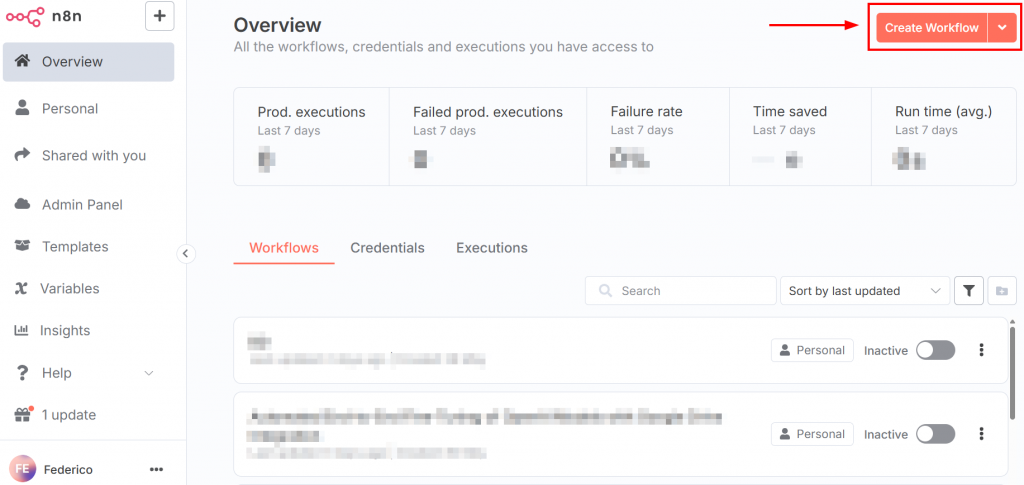
Para criar um novo fluxo de trabalho, clique no botão “Create Workflow” (Criar fluxo de trabalho). Em seguida, clique em “Open nodes panel” (Abrir painel de nós):
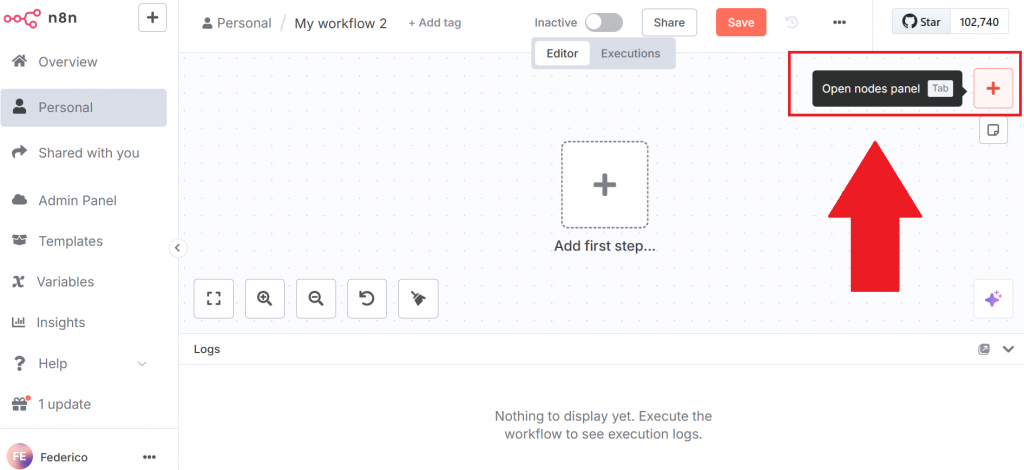
No painel de nós, procure o nó do Bright Data. Na n8n, um “nó” é um bloco de construção de um fluxo de trabalho automatizado, representando uma etapa ou ação distinta no pipeline de processamento de dados.
Clique no nó Bright Data n8n para instalá-lo:

Para obter mais informações, consulte a página da documentação oficial sobre como configurar o Bright Data no n8n.
Muito bem! Você inicializou seu primeiro fluxo de trabalho n8n.
Etapa 2: configurar o nó de dados do Bright Data e extrair os dados
Clique em “Add first step” (Adicionar primeira etapa) na interface do usuário e selecione “Trigger manually” (Acionar manualmente):
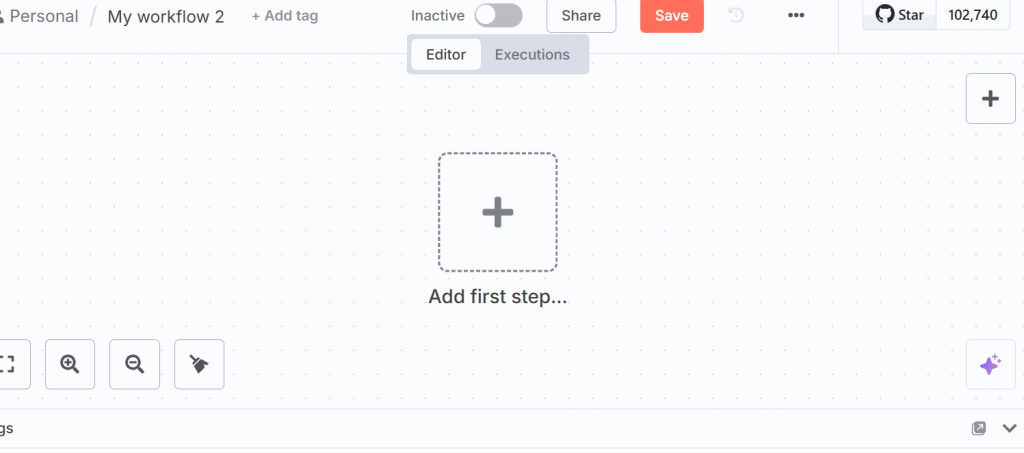
Esse nó permite que você acione manualmente todo o fluxo de trabalho.
Clique no “+” à direita do nó do acionador manual e pesquise Bright Data. Na seção “ações do raspador da Web”, clique em “raspar dados de forma síncrona por URL”:
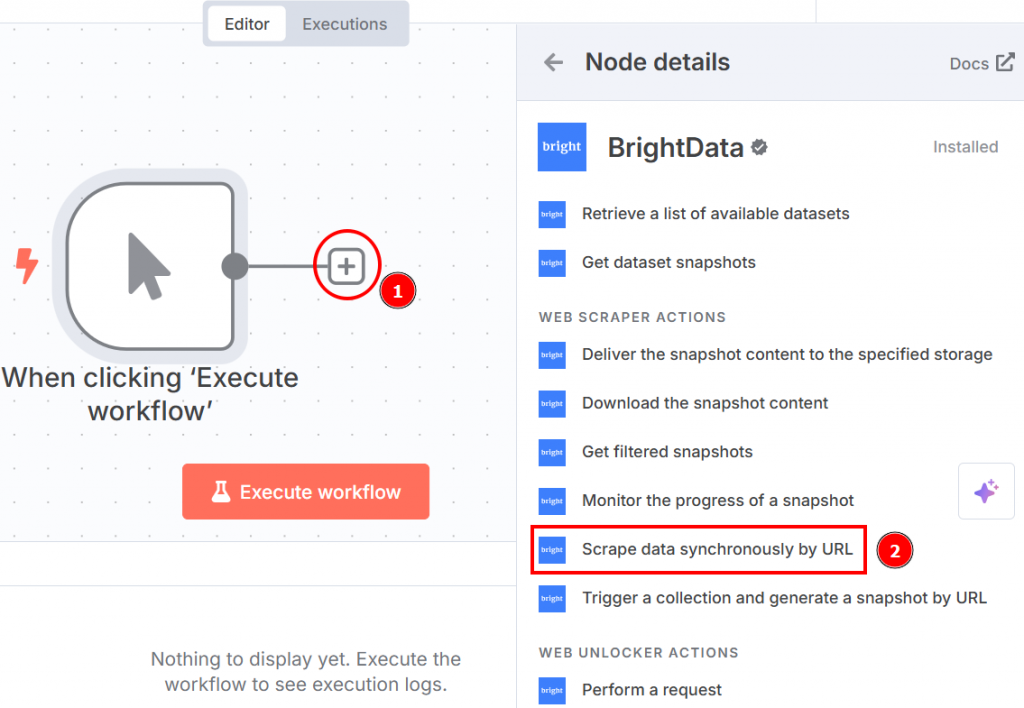
Veja abaixo como as configurações do nó aparecem quando você clica nele:

Configure-os da seguinte forma:
- “Credencial para conectar com”: Clique nela e adicione seu token da API da Bright Data. As credenciais serão salvas.
- “Operation” (Operação): Selecione a opção “Scrape by URL”. Isso permite que você passe uma lista de URLs que a API do Web Scraper usará como páginas de destino para extrair os dados.
- “Dataset” (Conjunto de dados): Escolha a opção “Amazon best seller products” (Produtos mais vendidos da Amazon). Isso é otimizado para extrair os dados dos produtos mais vendidos da Amazon.
- “URLs”: Vá para a página de produtos de escritório mais vendidos da Amazon para copiar e colar uma lista de pelo menos 10 URLs. Você precisa de pelo menos 10 URLs porque o nó do OpenAI Chat precisa de pelo menos 10. Se você passar menos de 10, o nó do OpenAI retornará um erro ao fazer o ajuste fino do LLM de destino.
- “Format” (Formato): Selecione o formato de dados “JSON”, pois a API do Web Scraper oferece suporte a vários formatos de saída.
Abaixo está a aparência de seu fluxo de trabalho até o momento:

Se você pressionar o botão “Execute workflow” (Executar fluxo de trabalho), os dados extraídos estarão disponíveis no nó do Bright Data na seção de saída:
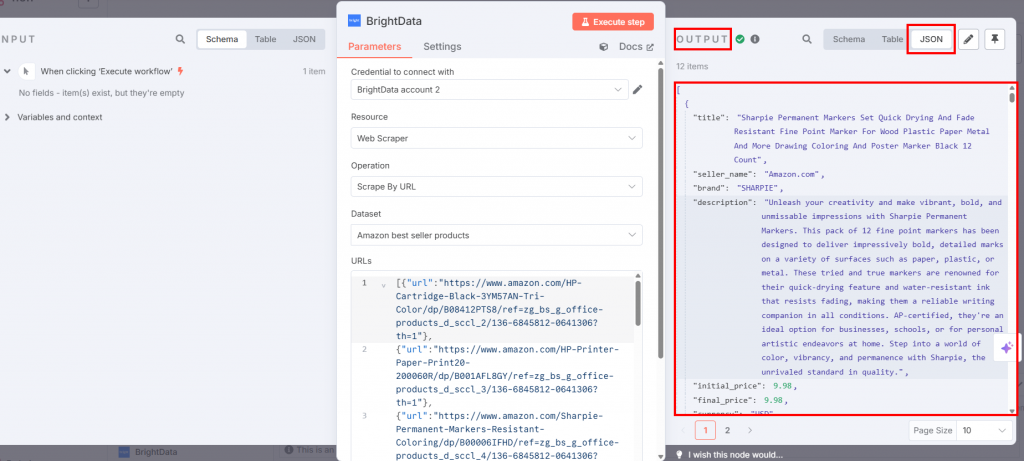
Fantástico! Você coletou os dados direcionados de que precisava com a API do Web Scraper da Bright Data sem escrever uma linha de código sequer.
Etapa 3: Configurar o nó de código
Conecte o nó Code do nó Bright Data e selecione JavaScript na caixa “Language” (Linguagem):

No campo “JavaScript”, cole o seguinte código:
// get all incoming items
const allInputItems = $input.all();
let jsonlString = "";
// define the training prompt
const systemMessage = "You are an expert marketing assistant specializing in writing compelling and informative product descriptions.";
// loop through each item retrieved from the input
for (const item of allInputItems) {
const product = item.json;
// validate if the product data exists and is an object
if (!product || typeof product !== 'object') {
console.warn('Skipping an item because product data is missing or not an object:', item);
continue;
}
// extract product data
const title = product.title || "N/A";
const brand = product.brand || "N/A";
let featuresString = "Not specified";
if (product.features && Array.isArray(product.features) && product.features.length > 0) {
featuresString = product.features.slice(0, 5).join(', ');
}
// create a snippet of the original product description for training
const originalDescSnippet = (product.description || "No original description available.").substring(0, 250) + "...";
// create prompt with specific details about the product
const userPrompt = `Generate a product description for the following item. Title: ${title}. Brand: ${brand}. Key Features: ${featuresString}. Original Description Snippet: ${originalDescSnippet}.`;
// create template for the kind of description the AI should generate
let idealDescription = `Discover the ${title} from ${brand}, a top-choice for discerning customers. `;
idealDescription += `Key highlights include: ${featuresString}. `;
if (product.rating) {
idealDescription += `Boasting an impressive customer rating of ${product.rating} out of 5 stars! `;
}
idealDescription += `This product, originally described as "${originalDescSnippet}", is perfect for anyone seeking quality and reliability. `;
idealDescription += `Don't miss out on the ${product.availability === "In Stock" ? "readily available" : "upcoming"} ${title} – enhance your collection today!`;
// create a training example object in the format expected by OpenAI
const trainingExample = {
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: userPrompt },
{ role: "assistant", content: idealDescription }
]
};
jsonlString += JSON.stringify(trainingExample) + "n";
}
// remove any leading or trailing whitespace
const fileContentString = jsonlString.trim();
// check if any product data was actually processed
if (fileContentString.length === 0) {
console.warn("No product data was processed, outputting empty file content.");
return [{
json: { error: "No products processed", fileNameToUse: "data.jsonl" },
binary: {}
}];
}
// convert the final JSONL string into a Buffer (raw binary data)
const buffer = Buffer.from(fileContentString, 'utf-8');
// define the filename that will be used when this data is sent to OpenAI
const actualFileNameForOpenAI = "data.jsonl";
// define the MIME type for the file
const mimeType = 'application/jsonl';
// prepare the binary data for output
const binaryData = await this.helpers.prepareBinaryData(buffer, actualFileNameForOpenAI, mimeType);
// return the processed data
return [{
json: {
processedFileName: actualFileNameForOpenAI
},
binary: {
// the "Input Data Field Name" in the OpenAI node
"data.jsonl": binaryData
}
}];A entrada desse nó é o arquivo JSON que contém os dados extraídos da Bright Data. No entanto, o nó OpenAI precisa de um arquivo JSONL. Esse código JavaScript transforma o JSON em um JSONL da seguinte forma:
- Ele recupera todos os dados provenientes do nó anterior com o método
$input.all(). - Ele itera e processa produtos. Em particular, para cada item de produto, ele:
- Extrai detalhes do produto, como
título,marca,recursos,descrição,classificaçãoedisponibilidade. Ele inclui valores de fallback se determinados dados estiverem faltando. - Constrói um
userPromptformatando esses detalhes em uma solicitação para que o LLM gere a descrição do produto. - Gera uma
idealDescriptionusando um modelo que incorpora os atributos do produto. Isso serve como a resposta desejada do “assistente” nos dados de treinamento. - Combina uma mensagem do sistema, o
userPrompte oidealDescriptionem um único objetotrainingExample, formatado para treinamento em LLM conversacional. - Serializa esse
trainingExampleem uma string JSON e a anexa a uma string crescente, com cada objeto JSON em uma nova linha (formato JSONL).
- Extrai detalhes do produto, como
- Depois de processar todos os itens, ele converte a string JSONL acumulada em um
bufferde dados binários. - Ele retorna o arquivo chamado
data.jsonl.
Se você clicar em “Execute step” (Executar etapa) no nó Code (Código), o JSONL estará disponível na seção de saída:
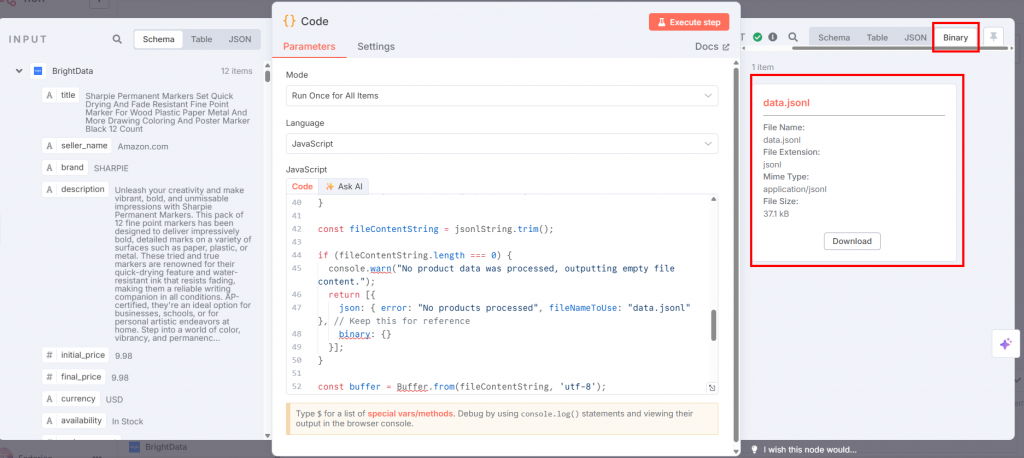
Abaixo está a aparência de seu fluxo de trabalho até o momento:
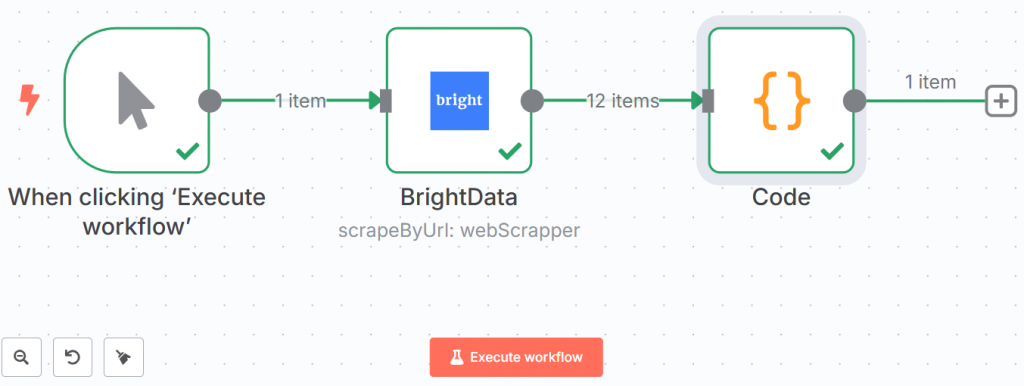
As linhas verdes e os ticks demonstram que cada etapa foi concluída com êxito.
Muito bem! Você recuperou os dados usando o Bright Data e os salvou no formato JSONL. Agora você está pronto para enviá-los para o LLM.
Etapa 4: enviar os dados de ajuste fino para o nó de bate-papo da OpenAI
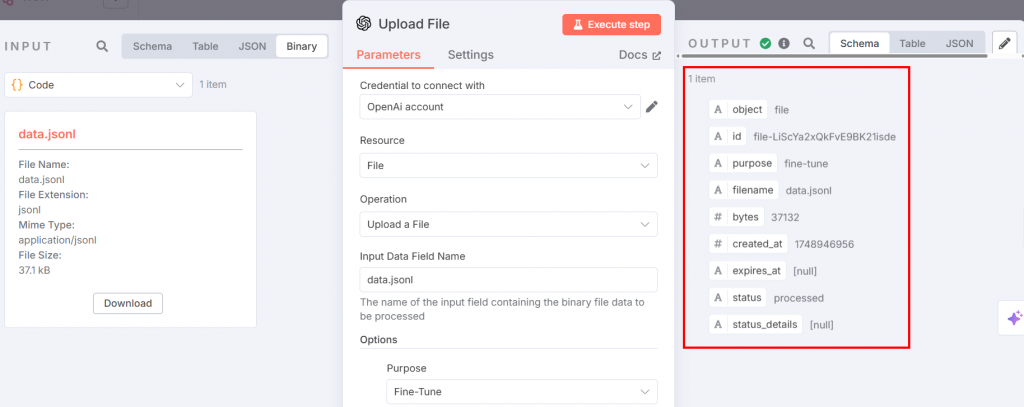
O arquivo JSONL de ajuste fino está pronto para ser carregado na plataforma OpenAI para ajuste fino. Para fazer isso, adicione um nó do OpenAI. Escolha a opção “Upload a file” na seção “File actions”:

Abaixo estão as configurações que você precisa definir:

O nó acima fornece a entrada para o processo de ajuste fino. Defina os parâmetros da seguinte forma:
- “Credencial para se conectar com”: Adicione seu token da API da OpenAI. Depois de defini-lo, as credenciais serão salvas.
- “Resource” (Recurso): Escolha “File” (Arquivo). Isso ocorre porque você fará upload de um arquivo JSONL para a plataforma.
- “Operation” (Operação): Selecione “Upload a File”.
- “Nome do campo de dados de entrada”: O nome do arquivo de ajuste fino é
data.jsonl. - Na seção “Options” (Opções), adicione “Purpose” (Finalidade) e escolha “Fine-tune” (Ajuste fino).
Depois de executar a etapa, a saída terá a seguinte aparência:
Agora, seu fluxo de trabalho terá a seguinte aparência:
Incrível! Você preparou tudo para o processo de ajuste fino. É hora de passar pelo processo real.
Etapa nº 5: Ajuste o LLM
Para realizar o ajuste fino real, conecte um nó de solicitação HTTP ao nó do OpenAI:

As configurações devem ser as seguintes:
- O “Method” deve ser “POST”, pois você está carregando o arquivo de dados de treinamento.
- O campo “URL” deve ser o endpoint
https://api.openai.com/v1/fine_tuning/jobs. Esse é o URL padrão para trabalhos de ajuste fino na plataforma OpenAI. - No campo “Authentication” (Autenticação), escolha “Predefined Credential Type” (Tipo de credencial predefinida) para que ele use seu token da API da OpenAI.
- Em “Credential Type” (Tipo de credencial), selecione “OpenAi” para que o nó se conecte ao OpenAI.
- Na caixa “OpenAI”, escolha o nome da sua conta OpenAI.
- O botão de alternância “Send Body” deve estar ativado. Selecione “JSON” e “Using JSON” respectivamente para os campos “Body Content Type” e “Specify Body”.
O campo JSON deve conter o seguinte:
{
"training_file": "{{ $json.id }}",
"model": "gpt-4o-mini-2024-07-18"
} Este JSON:
- Especifica o nome dos dados de treinamento com
$json.id. - Define o modelo a ser usado para o ajuste fino. Nesse caso, você usará o GPT-4o-mini de acordo com a versão lançada em 2024-07-18.
Abaixo está o resultado que você receberá:
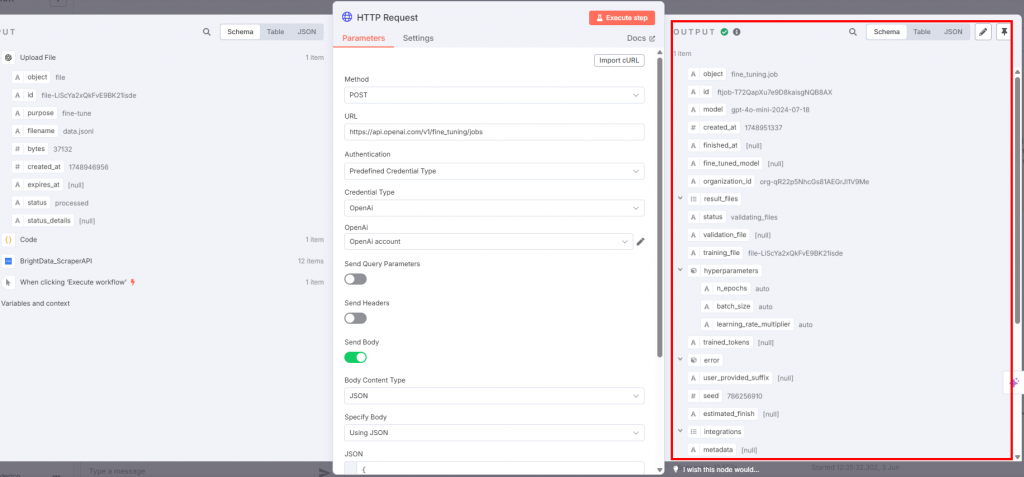
Quando o nó de solicitação HTTP é acionado, o processo de ajuste fino é iniciado. Você pode ver os avanços na seção de ajuste fino da plataforma OpenAI. Quando o processo de ajuste fino for concluído com êxito, a OpenAI fornecerá o modelo ajustado que você usará na Etapa 7:

O fluxo de trabalho do n8n agora deve ter a seguinte aparência:

Parabéns! Você treinou seu primeiro modelo GPT usando dados recuperados com a API Scraper da Bright Data por meio do n8n.
Esse é o nó final da primeira metade de todo o fluxo de trabalho.
Etapa 6: adicionar o nó de bate-papo
A segunda metade de todo o fluxo de trabalho deve começar com um nó do Chat Trigger. Nele, você inserirá o prompt para testar o LLM ajustado:

Abaixo está o prompt que você pode inserir no bate-papo:
You are an expert marketing assistant specializing in writing compelling and informative product descriptions. Generate a product description for the following office item:
Title: ErgoComfort Pro Executive Chair.
Brand: OfficeSolutions.
Key Features: Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters.Como você pode ver, esse prompt:
- Relata a mesma frase sobre ser um assistente de marketing especializado usada na fase de treinamento.
- Solicita a geração de uma descrição do produto com base nas informações sobre o item de escritório necessário definidas por:
- O título.
- A marca.
- Principais recursos do produto de escritório.
É importante que a estrutura do prompt seja assim. Isso ocorre porque o modelo, nessa fase, imita os dados de treinamento. Portanto, você precisa fornecer a ele um prompt e dados semelhantes aos usados na fase de treinamento. Em seguida, o LLM ajustado escreverá a descrição do produto com base nesses fatores.
É possível inserir o prompt na seção de bate-papo na parte inferior da interface do usuário:
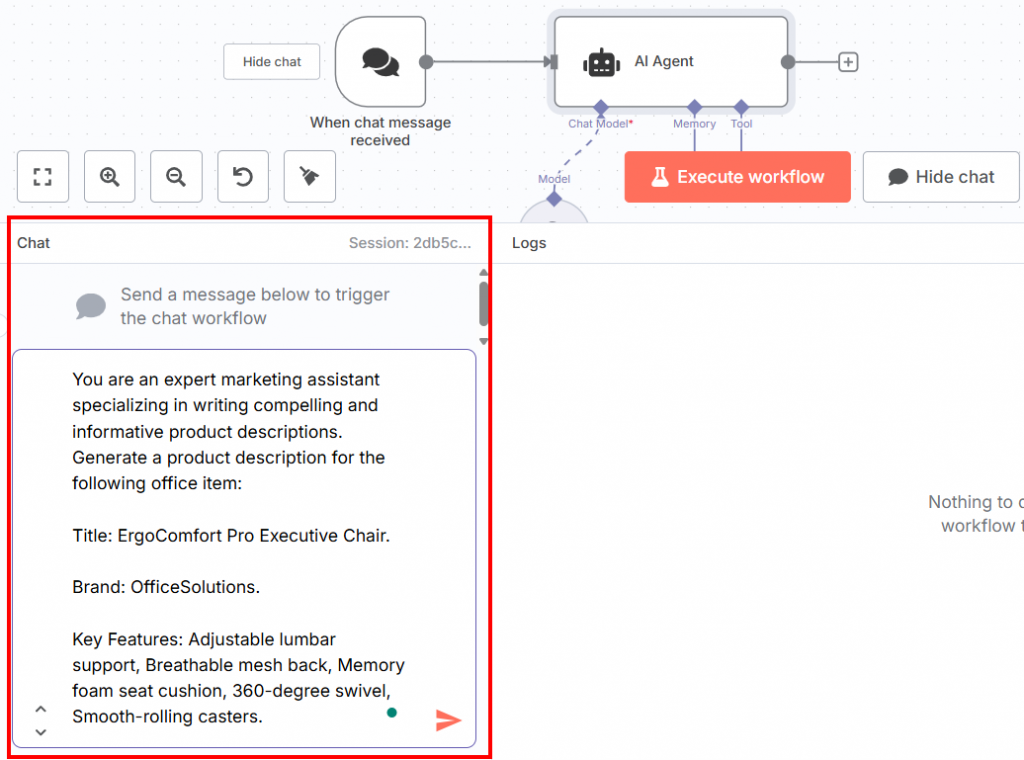
Esse é o fluxo de trabalho atual do n8n:
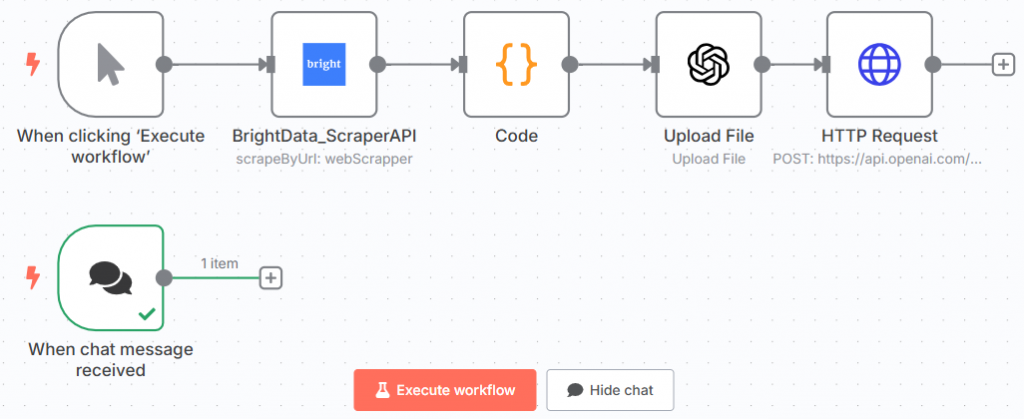
Excelente! Você definiu o prompt para testar o modelo ajustado.
Etapa 7: Adicionar o agente de IA e os nós de bate-papo do OpenAI
Agora você precisa conectar um nó do AI Agent ao Chat Trigger:

As configurações devem ser:
- “Agente”: Escolha “Agente de conversação”. Isso permite que você modifique o que quiser usando o nó Chat Trigger, como faz com qualquer outro agente de conversação.
- Defina a “Source of Prompt (User Message)” como “Connected Chat Trigger Node” para que ele possa ingerir o prompt diretamente do chat.
Conecte um nó do OpenAI Chat Model ao AI Agent por meio de sua opção de conexão “Chat Model”:

A imagem abaixo mostra as configurações do nó OpenAI Chat Model:

Configure o nó da seguinte forma:
- “Credential to connect with” (Credencial para conexão): Selecione suas credenciais OpenAI salvas.
- “Model” (Modelo): Cole o modelo de saída com ajuste fino da seção de ajuste fino da plataforma OpenAI.
Retorne ao nó AI Agent e clique no botão “Execute step” (Executar etapa). Você verá a descrição resultante do produto:
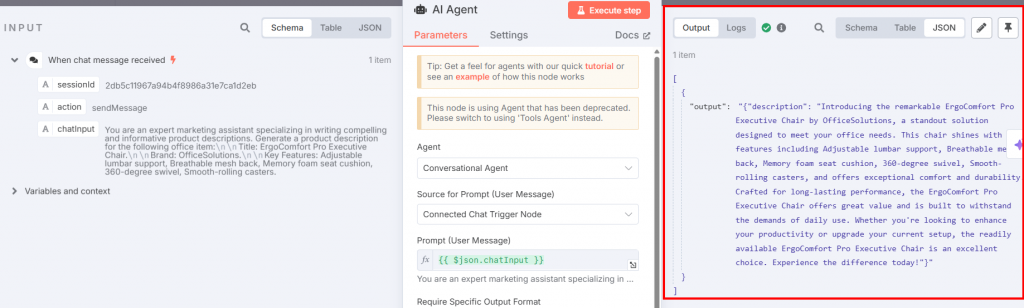
Abaixo está a descrição resultante em texto simples:
Introducing the remarkable ErgoComfort Pro Executive Chair by OfficeSolutions, a standout solution designed to meet your office needs. This chair shines with key features including Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters, and offers exceptional comfort and durability. Crafted for long-lasting performance, the ErgoComfort Pro Executive Chair offers great value and is built to withstand the demands of daily use. Whether you're looking to enhance your productivity or upgrade your current setup, the readily available ErgoComfort Pro Executive Chair is an excellent choice. Experience the difference today!Como você pode ver, a descrição aproveita o nome do título do objeto (“ErgoComfort Pro Executive Chair”), sua marca (“OfficeSolutions”) e todos os seus recursos para gerar a descrição do produto. Em particular, a descrição não lista apenas os dados de entrada; ela os aproveita para criar uma descrição envolvente. As últimas frases são fundamentais:
- “Criada para um desempenho duradouro, a cadeira executiva ErgoComfort Pro oferece um ótimo valor e foi construída para suportar as demandas do uso diário.”
- “Se estiver procurando aumentar a sua produtividade ou atualizar a sua configuração atual, a cadeira executiva ErgoComfort Pro, prontamente disponível, é uma excelente opção. Experimente a diferença hoje mesmo!”
E pronto! Você testou seu modelo GPT-4o-mini ajustado, que gerou uma descrição do produto para responder ao prompt fornecido (definido na Etapa 6).
Etapa #8: Juntar tudo
O fluxo de trabalho final de ajuste fino do GTP-4o n8n agora é o seguinte:

Agora que o fluxo de trabalho está totalmente configurado, se você clicar em “Executar fluxo de trabalho”, ele será executado novamente desde o início. No entanto, observe que os resultados são salvos em cada etapa. Isso significa que, se você quiser experimentar prompts diferentes para testar o modelo ajustado, só precisará gravá-los no nó Chat Trigger e executar esse nó e o nó AI Agent.
Comparação de abordagens de ajuste fino: Infraestrutura de nuvem versus automação do fluxo de trabalho
Este guia foi elaborado por dois motivos:
- Ensinar a você como ajustar um LLM usando uma ferramenta de automação de fluxo de trabalho como a n8n
- Comparando essa maneira de fazer o ajuste fino dos LLMs com a usada em nosso artigo “Fine-Tuning Llama 4 with Fresh Web Data for Better Results“
É hora de comparar as duas abordagens!
Comparação dos métodos de ajuste fino
A abordagem que seguimos em nosso artigo anterior para ajustar o Llama 4 requer:
- O uso de uma infraestrutura de nuvem, que leva tempo para ser configurada e incorre em custos.
- Escrever código para recuperar os dados usando as APIs de raspagem da Bright Data.
- Configuração do Hugging Face.
- A necessidade de desenvolver um notebook com o código Python para ajuste fino, o que requer tempo e habilidades técnicas.
Não é possível estimar as habilidades técnicas necessárias. No entanto, é possível estimar o tempo total necessário para configurar toda a infraestrutura e o dinheiro gasto:
- Tempo: aproximadamente um dia inteiro de trabalho.
- Dinheiro: US$ 25. Depois de gastar US$ 25 pelo serviço de nuvem, o consumo será por hora. Ao mesmo tempo, você precisa pagar US$ 25 antes de começar. Portanto, esse é o preço mínimo para usar a nuvem.
A abordagem que você aprendeu neste guia requer:
- n8n, que é de uso gratuito e não exige muito conhecimento técnico.
- Um token de API OpenAI para acessar o GPT-4o ou outros modelos.
- Habilidades básicas de codificação, especificamente para escrever um trecho de JavaScript para o nó Code.
Nesse caso, as habilidades técnicas são bem menores. O snippet de JavaScript pode ser facilmente criado por qualquer LLM, caso você não consiga escrevê-lo por conta própria. Além disso, você não precisa escrever nenhum outro trecho de código em todo o fluxo de trabalho.
Nesse caso, você pode estimar o tempo necessário para configurar a infraestrutura e o dinheiro necessário da seguinte forma:
- Tempo: cerca de metade de um dia útil.
- Dinheiro: US$ 10 por um token de API da OpenAI. Mesmo nesse caso, você pagará por cada solicitação de API. Ainda assim, você pode começar com apenas US$ 10. Atualmente, uma licença da n8n custa US$ 25/mês para o plano básico ou é totalmente gratuita se você optar por usar a versão auto-hospedada. Portanto, para começar, você precisa de cerca de US$ 10.
Qual abordagem você deve escolher?
| Aspecto | Abordagem de infraestrutura de nuvem | Abordagem de automação do fluxo de trabalho |
|---|---|---|
| Habilidades técnicas | Alta (requer habilidades de codificação em Python, nuvem e recuperação de dados) | Baixo (JavaScript básico) |
| Tempo para configurar | Aproximadamente um dia inteiro de trabalho | Cerca de metade de um dia útil |
| Custo inicial | ~Mínimo de US$ 25 para serviço em nuvem + taxas por hora | ~$10 para token de API da OpenAI + $24/mês para licença n8n ou auto-hospedado gratuito |
| Flexibilidade | Alto (adequado para personalização avançada e vários casos de uso) | Moderado (bom para automatizar fluxos de trabalho e personalização com pouco código) |
| Melhor para | Equipes com altas habilidades técnicas que precisam de uma infraestrutura poderosa e flexível | Equipes que buscam uma configuração rápida ou com conhecimento limitado de codificação |
| Benefícios adicionais | Controle total sobre o ambiente e o processo de ajuste fino | Modelos pré-criados, baixa barreira de entrada, integrações com outros fluxos de trabalho |
As duas abordagens exigem um investimento inicial semelhante, tanto em termos de tempo quanto de dinheiro. Então, como você escolhe entre uma e outra? Aqui estão algumas diretrizes:
- n8n: Escolha o n8n – ou qualquer ferramenta de automação de fluxo de trabalho semelhante – para ajustar os LLMs se precisar automatizar outros fluxos de trabalho e se a sua equipe não for altamente qualificada tecnicamente. Essa abordagem com pouco código o ajudará a automatizar qualquer outro fluxo de trabalho. Ela requer a escrita de código somente se você precisar de personalização. Ela também fornece modelos pré-criados que você pode usar gratuitamente, o que reduz a barreira de entrada para o uso da ferramenta.
- Serviços em nuvem: Escolha um serviço de nuvem para fazer o ajuste fino dos LLMs se precisar dele para várias finalidades e tiver uma equipe altamente qualificada. A configuração do ambiente de nuvem e o desenvolvimento do notebook de ajuste fino exigem conhecimento técnico avançado.
O coração do processo de ajuste fino: Dados de alta qualidade
Independentemente da abordagem que você escolher, a Bright Data continua sendo o principal intermediário em ambas. O motivo é simples: dados de alta qualidade são a base do processo de ajuste fino!
A Bright Data oferece a você uma infraestrutura de IA para dados, oferecendo uma variedade de serviços e soluções para dar suporte aos seus aplicativos de IA:
- Servidor MCP: Um servidor MCP Node.js de código aberto que expõe mais de 20 ferramentas para recuperação de dados em agentes de IA.
- APIs do Web Scraper: APIs pré-configuradas para extrair dados estruturados de mais de 100 domínios principais.
- Web Unlocker: Uma API tudo em um que lida com o desbloqueio de sites com proteções antibot.
- API SERP: Uma API especializada que desbloqueia os resultados dos mecanismos de pesquisa e extrai dados SERP completos.
- Modelos básicos: Acesse conjuntos de dados em conformidade e em escala da Web para potencializar o pré-treinamento, a avaliação e o ajuste fino do LLM.
- Provedores de dados: Conecte-se com provedores confiáveis para obter conjuntos de dados de alta qualidade e prontos para IA em escala.
- Pacotes de dados: Obtenha conjuntos de dados selecionados e prontos para uso – estruturados, enriquecidos e anotados.
Embora este guia tenha lhe ensinado como ajustar o GPT-4o-mini para extrair os dados usando as APIs do Web Scraper, você pode escolher uma abordagem diferente usando um de nossos serviços.
Conclusão
Neste artigo, você aprendeu a fazer o ajuste fino do GPT-4o-mini com dados extraídos da Amazon usando o n8n para automatizar todo o fluxo de trabalho. Você passou por todo o processo, que consiste em duas ramificações:
- Realiza o ajuste fino após a raspagem dos dados.
- Testa o modelo ajustado inserindo o prompt por meio de um acionador de bate-papo.
Você também fez uma comparação entre essa abordagem, que usa uma ferramenta de automação de fluxo de trabalho, e outra que usa um serviço de nuvem.
Independentemente da abordagem que melhor se adapte às suas necessidades e à sua equipe, lembre-se de que dados de alta qualidade permanecem no centro do processo. Nesse sentido, a Bright Data oferece a você vários serviços de dados para IA.
Crie uma conta na Bright Data gratuitamente e teste nossa infraestrutura de dados pronta para IA!





