

Neste guia, você descobrirá:
- Como automatizar a raspagem do LinkedIn usando n8n, Bright Data e OpenAI
- Como criar um fluxo de trabalho sem código que envia perfis de candidatos diretamente para sua caixa de entrada
- Por que a combinação de Web Unlocker, ChatGPT e SMTP cria uma poderosa ferramenta de recrutamento
Vamos começar!
Primeiros passos
Você pode ver esse fluxo de trabalho no n8n aqui. No entanto, para uma configuração mais fácil, há algumas coisas que precisamos fazer primeiro.
Hospedagem autônoma n8n
Esse fluxo de trabalho depende dos nós da comunidade da n8n. Os nós da comunidade são ferramentas de terceiros fornecidas por bons samaritanos da comunidade n8n. A melhor maneira de gerenciar todas essas partes móveis é agrupá-las em um contêiner do Docker.
Instalando o Docker
Usando o Ubuntu nativo ou o Ubuntu via WSL no Windows, execute o seguinte comando para instalar o Docker. Você pode saber mais sobre a instalação do Docker em outras plataformas aqui.
sudo snap install dockerDepois que o Docker estiver instalado, crie um volume de armazenamento e execute o contêiner.
Criando um contêiner n8n
sudo docker volume create n8n_data
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nInstalação de nós comunitários
Abra o site http://localhost:5678/ em seu navegador. Você terá uma versão totalmente auto-hospedada do aplicativo da Web n8n em execução local.
Na barra lateral, clique nos três pontos ao lado de seu perfil e selecione “configurações”.

Quando estiver no menu de configurações, selecione “Community Nodes”. Isso lhe dá acesso às ferramentas de terceiros que mencionei anteriormente.
Clique em “Install” e você verá uma janela pop-up para o nó que deseja instalar. Na seção do pacote npm, cole o seguinte pacote.
n8n-nodes-brightdataQuando estiver pronto, clique em “Install” (Instalar).

Agora, repita esse processo para o Gerador de documentos.
n8n-nodes-document-generator
Reiniciar o contêiner
Quando os nós da comunidade estiverem instalados, elimine o contêiner com ctrl+c. Execute o comando abaixo para reiniciar o n8n.
sudo docker run -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n docker.n8n.io/n8nio/n8nImportando o fluxo de trabalho
Após a configuração, estamos finalmente prontos para importar o fluxo de trabalho que mencionei anteriormente. Vá para a página do n8n e clique no botão “Use for free” (Usar gratuitamente).

Você verá uma janela pop-up com várias opções diferentes. A maneira mais fácil é selecionar “Import template to localhost:5678 self-hosted instance”.

Insira ou importe suas credenciais
Agora, você será automaticamente solicitado a inserir suas credenciais para Bright Data, OpenAI e SMTP.

Obtenção de suas chaves de API
Dados brilhantes
Esse fluxo de trabalho usa o Web Unlocker para realizar nossa pesquisa. Depois de se inscrever no Web Unlocker, navegue até o Painel do Web Unlocker e obtenha sua chave de API. A n8n usará essa chave para extrair resultados com o Bright Data.

OpenAI
Vá até a plataforma de desenvolvedores da OpenAI e crie uma conta, caso ainda não o tenha feito. Em seguida, clique em “API keys” (Chaves de API) para gerar uma chave.

SMTP
Esse processo é compatível com qualquer cliente SMTP. Atualmente, estou usando o Elastic Email. Seu plano gratuito é excelente para projetos locais como este. Salve seu nome de usuário, senha, servidor e porta. Nós os usaremos com o n8n para automatizar seu processo de e-mail.

Etapas do fluxo de trabalho

Quando o usuário preenche um formulário
Quando um usuário preenche um formulário da Web, isso dá início ao nosso fluxo de trabalho. Sinta-se à vontade para abrir esse nó e examinar os parâmetros e as configurações. No entanto, tudo nessa etapa deve estar pré-configurado, não há necessidade de edição.

Como criar o URL do LinkedIn e a pesquisa da empresa
Quando o formulário é preenchido, lançamos dois fluxos de trabalho separados.
Um deles cria um URL do Google para pesquisar o perfil do LinkedIn dessa pessoa.

Nosso outro faz uma url do Google separada para pesquisar a empresa no LinkedIn.
Esses dois URLs são passados para o Web Unlocker para evitar o bloqueio.

Extração de HTML dos resultados
Agora, extraímos o HTML de nossos resultados. Temos dois nós chamados “Extract Body and Title from Website” (Extrair corpo e título do site). Ambos extraem o título e o corpo da resposta JSON da Bright Data.

No fluxo de trabalho, ambas as etapas destacadas estão ocorrendo ao mesmo tempo.

Analisando os resultados com o ChatGPT
Agora que extraímos o título e o corpo de cada pesquisa, passamos nossos resultados HTML para o ChatGPT para processamento. Cada um desses nós contém um processo como o que você vê abaixo. Definimos nosso modelo (GPT-4o mini) e damos a ele um prompt para extrair nossos dados.

Como você pode ver abaixo, isso também acontece em ambos os nossos processos simultaneamente.
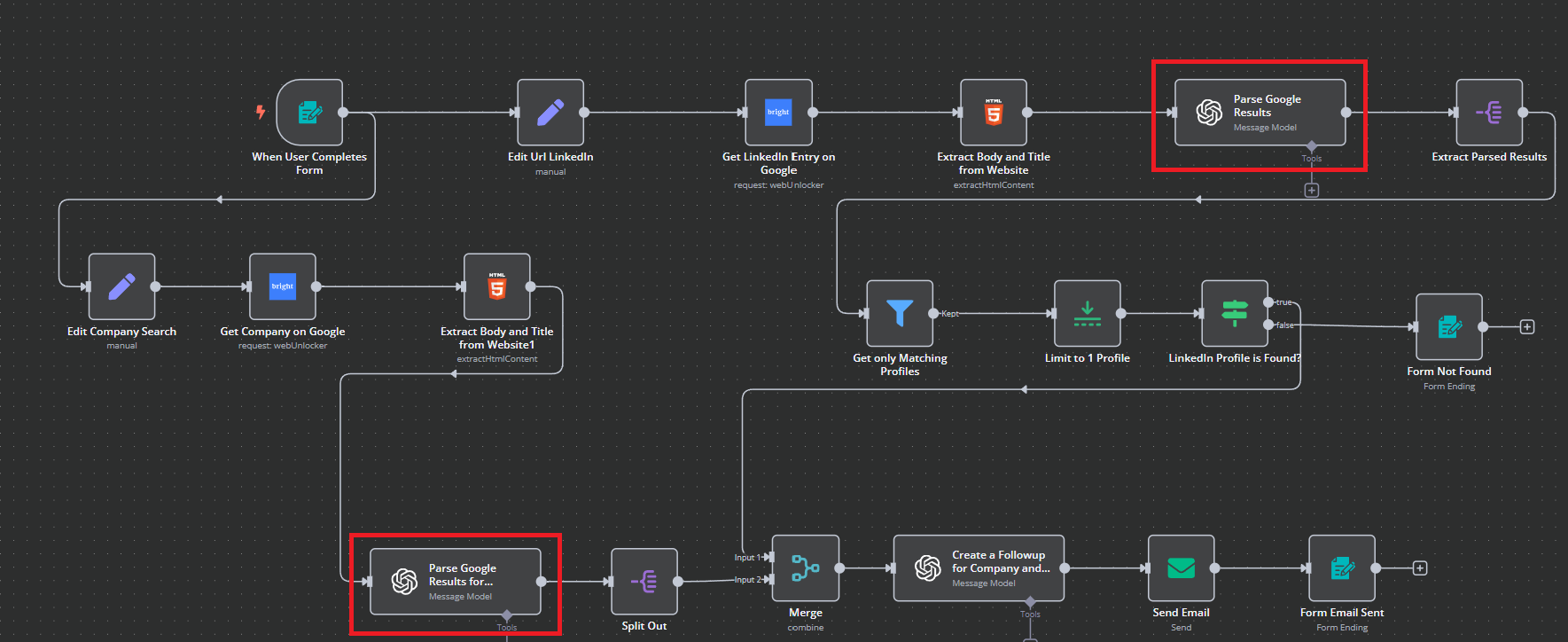
Extraia os resultados analisados e faça a divisão para encerrar a pesquisa da empresa
Durante essa etapa, um de nossos fluxos de trabalho separados termina com um “Split Out”. Quando o fluxo de trabalho “Empresa” termina, extraímos os resultados analisados do nosso fluxo de trabalho “Pessoa”.
Aqui estão as instruções para a extração. Como você pode ver, estamos basicamente extraindo partes menores do corpo JSON maior.

Nosso fluxo de trabalho “Empresa” já terminou e nosso fluxo de trabalho “Pessoa” ainda tem algumas etapas a concluir. O fluxo de trabalho da “Empresa” permanecerá pausado até que esses processos estejam prontos para serem mesclados – é aqui que a beleza do n8n realmente começa a se destacar… programação assíncrona sem codificação envolvida!

Limite a 1 perfil e valide sua existência
Nosso fluxo de trabalho “Pessoa” filtra o resultado para usar apenas perfis correspondentes. Em seguida, limitamos o resultado a um perfil e garantimos que ele exista. Se ele não existir, tratamos o problema atualizando o formulário e informando ao usuário que o perfil não foi encontrado.

Desde que o perfil exista, estamos prontos para mesclar novamente em um fluxo de trabalho único e coerente.

Mesclando os fluxos de trabalho
Como você pode ver abaixo, os dados de ambos os fluxos de trabalho são usados como entrada. Eles são mesclados em uma única saída para que possamos passar para o ChatGPT uma última vez.

Finalmente tudo está se encaixando. Quando tivermos um único fluxo de trabalho, estaremos prontos para executar as etapas finais.

Elaboração de etapas de divulgação e acompanhamento
Agora, passamos essa única saída de volta para o ChatGPT para finalizar nosso e-mail. Ele até mesmo grava HTML personalizado para que não precisemos nos preocupar com o código de marcação.

Quando o HTML retornar, estaremos prontos para enviar os resultados por e-mail.

Envio do e-mail
Abra o nó “Send Email” para garantir que suas credenciais e detalhes de conexão estejam corretos. Como você pode ver, passamos json.message.content.content para criar o e-mail. Isso literalmente pega o HTML do ChatGPT e o cola diretamente no corpo do e-mail.

Altere o “From Email” para o e-mail SMTP que você está usando. O e-mail é então enviado para o “To Email” – altere-o para seu e-mail pessoal para receber os resultados em sua caixa de entrada pessoal.

Atualização do formulário para mostrar a conclusão
Por fim, atualizamos o formulário para informar ao usuário que a operação foi bem-sucedida. Se você abrir “Form Email Sent”, verá os diferentes parâmetros para a atualização do formulário. Como você pode ver, mostramos um “Completion Tile” que diz “Thank you!” e uma mensagem dizendo “We have sent you an email”.

Agora concluímos a etapa final do fluxo de trabalho! Sinta-se à vontade para clicar no botão “Testar fluxo de trabalho” e ver como tudo é executado.

Os resultados
Se você decidir executar o fluxo de trabalho, primeiro verá uma janela pop-up solicitando o preenchimento do formulário de pesquisa. Preencha o formulário e clique em “Get References” (Obter referências).

Depois que o processo for concluído, seu formulário deverá se parecer com o que está abaixo. Como você pode ver, ele diz “Thank you!” e exibe nossa mensagem de conclusão.
Ao abrir sua caixa de entrada, você receberá um novo e-mail com uma visão geral detalhada do seu candidato, com links para o site e o perfil do LinkedIn dele. Abaixo disso, você verá recomendações de contato e acompanhamento do ChatGPT.

Conclusão
Com a n8n, Bright Data, OpenAI e SMTP, você construiu um fluxo de trabalho de coleta e alcance do LinkedIn totalmente automatizado, sem escrever códigos complexos. Essa configuração avançada simplifica seu processo de recrutamento, fornecendo perfis de candidatos enriquecidos e alcance personalizado diretamente em sua caixa de entrada.
Quer esteja ampliando um pipeline de contratação ou melhorando a geração de leads, esse fluxo de trabalho é apenas o começo. A Bright Data oferece um conjunto completo de ferramentas para levar sua automação ao próximo nível:
- Web Unlocker: contorne CAPTCHAs, bloqueios e detecção de bots para coletar dados do LinkedIn e de outros sites de forma confiável.
- Proxies residenciais: Acesse IPs de usuários reais de todo o mundo para garantir altas taxas de sucesso e segmentação geográfica.
- Navegador de raspagem: Um navegador sem cabeça com suporte a proxy integrado, ideal para páginas com muito JavaScript.
- API de raspagem: Use modelos de raspagem pré-criados para extrair dados estruturados sem esforço.
- Conjuntos de dados: Aproveite os conjuntos de dados prontos para listagens de empregos, dados da empresa e muito mais para enriquecer seu alcance.
Inscreva-se para uma avaliação gratuita e comece a automatizar de forma mais inteligente hoje mesmo!





