
Cansado de comparar manualmente produtos na Amazon? Quer fazer perguntas à IA sobre seus resultados de pesquisa? Precisa de insights melhores do que apenas classificar por preço ou classificação? Neste tutorial, você criará um analisador de produtos da Amazon que pesquisa qualquer um dos 23 mercados da Amazon, analisa os resultados com IA e apresenta insights por meio de painéis interativos.
O que você criará
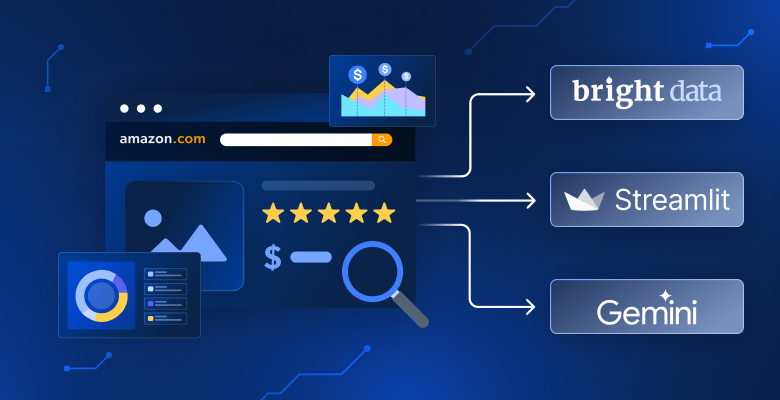
Ao final deste guia, você terá um aplicativo web funcional que busca dados de produtos da Amazon e os organiza em um painel fácil de navegar com insights alimentados por IA.
Recursos principais e fluxo de trabalho do usuário
Veja como funciona:
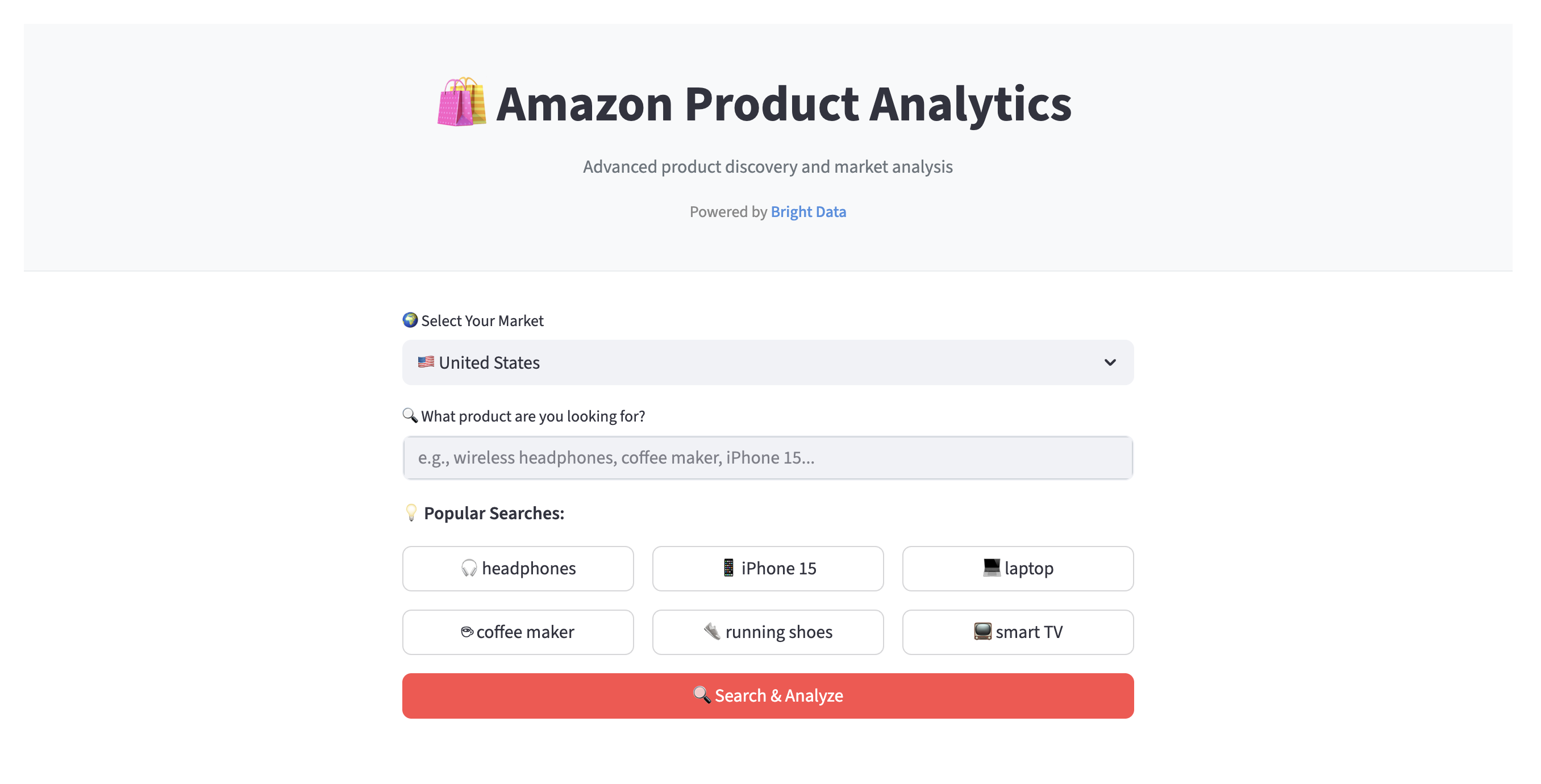
- Pesquisa e coleta de dados. Selecione um dos 23 mercados da Amazon (Estados Unidos, Alemanha, Japão, etc.) e insira uma palavra-chave do produto, como “fones de ouvido sem fio”. O aplicativo usa a API Web Scraper da Bright Data para coletar informações do produto.
- Exibição organizada dos resultados. Os dados são apresentados por meio de uma interface limpa, baseada em guias:
- Recomendações. Veja os produtos classificados por um algoritmo de pontuação personalizado (que combina classificação, número de avaliações e descontos) com três categorias: “Melhor valor geral”, “Mais bem avaliado” e “Melhores ofertas”.
- Análise de mercado. Explore gráficos interativos que mostram distribuições de preços e padrões de classificação para entender o panorama do produto.
- Assistente de IA. Faça perguntas em inglês simples, como “Quais produtos têm as avaliações mais altas abaixo de US$ 100?”. A IA analisa seus resultados de pesquisa atuais e fornece respostas com citações de produtos.
- Resultados do produto. Navegue, classifique e exporte o conjunto de dados completo para CSV para análise posterior.
Agora que vimos o que o aplicativo faz, vamos examinar as tecnologias que o tornam possível.
A pilha de tecnologia e a arquitetura do projeto
Nosso aplicativo usa uma pilha moderna baseada em Python, com cada componente escolhido por seus pontos fortes específicos em tratamento de dados, IA e desenvolvimento web.
| Componente | Tecnologia | Finalidade |
|---|---|---|
| Fonte de dados | Bright Data Amazon Scraper API | Coleta de dados confiável da Amazon em escala empresarial, sem o incômodo de gerenciar proxies ou a resolução de CAPTCHAs. |
| Front-end | Streamlit | Crie rapidamente um painel web interativo e bonito usando apenas Python. |
| Integração com IA | Google Gemini | Insights em linguagem natural, resumo de dados e funcionalidade de assistente de IA. |
| Processamento de dados | Pandas | A base para toda a limpeza, transformação e análise de dados. |
| Operações matemáticas | NumPy | Algoritmos de pontuação de valores e cálculos estatísticos. |
| Visualizações | Plotly | Gráficos e tabelas interativos e ricos que os usuários podem explorar. |
| HTTP(S) e novas tentativas | Solicitações + Tenacidade | Comunicação robusta e resiliente com APIs externas. |
Arquitetura do projeto
O projeto é organizado em uma estrutura modular para garantir uma separação clara das preocupações, tornando o código mais fácil de manter e ampliar.
├── streamlit_app.py # Ponto de entrada principal do aplicativo Streamlit
├── requirements.txt # Dependências do projeto
├── .env # Chaves API e variáveis de ambiente (privadas)
└── amazon_analytics/ # Módulo de lógica central do aplicativo
├── __init__.py # Inicialização do pacote
├── api.py # Integração da API Bright Data
├── data_processor.py # Limpeza, normalização e engenharia de recursos de dados
├── shopping_intelligence.py # Recomendação de produtos e mecanismo de pontuação
├── gemini_ai_engine.py # Análise de IA e engenharia de prompts com Gemini
├── ai_engine_interface.py # Interface abstrata do mecanismo de IA
├── ai_response.py # Objetos de resposta de IA padronizados
└── config.py # Gerenciamento de configuraçãoCom a arquitetura definida, vamos preparar seu ambiente de desenvolvimento.
Pré-requisitos
Antes de começarmos a programar, certifique-se de ter o seguinte pronto:
- Python 3.8+. Se você não tiver instalado, baixe-o do site oficial do Python.
- Uma conta Bright Data. Você precisará de uma chave API para acessar a API Amazon Scraper. Inscreva-se para um teste grátis para começar e gerar sua chave API.
- Uma chave API do Google. Isso é necessário para usar o modelo Gemini IA. Você pode gerar uma no Google AI Studio.
- Conhecimento básico. Familiaridade com Python, Pandas e o conceito de APIs da web será útil.
Depois de ter tudo isso, podemos prosseguir com a configuração do projeto.
Etapa 1 – configurando seu ambiente de desenvolvimento
Primeiro, vamos clonar o repositório do projeto, criar um ambiente virtual para isolar nossas dependências e instalar os pacotes necessários.
Instalação
Abra seu terminal e execute os seguintes comandos:
# Clonar o repositório
git clone https://github.com/triposat/amazon-product-analytics.git
cd amazon-product-analytics
# Criar e ativar um ambiente virtual
python -m venv venv
source venv/bin/activate # No Windows, use: venvScriptsactivate
# Instalar as bibliotecas necessárias
pip install -r requirements.txtConfiguração da chave API
Em seguida, crie um arquivo .env no diretório raiz do projeto para armazenar com segurança suas chaves API.
# Crie o arquivo .env
touch .envAgora, abra o arquivo .env em um editor de texto e adicione suas chaves:
BRIGHT_DATA_TOKEN=sua_chave_bright_data_aqui
GOOGLE_API_KEY=sua_chave_google_api_aquiSeu ambiente agora está totalmente configurado. Vamos mergulhar na lógica central, começando pela coleta de dados.
Etapa 2 – extraindo dados de produtos da Amazon com a Bright Data
A base do nosso aplicativo são dados de alta qualidade. Extrair manualmente um site como o Amazon é complexo – você precisa gerenciar Proxy, lidar com diferentes layouts de página e encontrar maneiras de contornar os CAPTCHAs e mecanismos de bloqueio do Amazon.
A API Amazon Web Scraper da Bright Data elimina toda essa complexidade. Ela oferece:
- Confiabilidade de nível empresarial. Construída em uma rede de mais de 150 milhões de Proxies residenciais de origem ética em 195 países, garantindo acesso consistente e ininterrupto.
- Sem complicações de infraestrutura. A rotação automática de IP, a Resolução de CAPTCHA e o gerenciamento de Proxy são feitos para você nos bastidores.
- Dados estruturados abrangentes. Fornece dados JSON limpos e estruturados com mais de 20 pontos de dados por produto, incluindo ASIN, preços, classificações, avaliações, informações do vendedor, descrições do produto, imagens, disponibilidade e muito mais.
- Preços acessíveis. Modelo de pagamento conforme o uso a partir de US$ 0,001 por registro, tornando-o escalável para projetos de qualquer tamanho.
Integração de API (api.py)
Nossa classe BrightDataAPI em api.py lida com todas as interações com a API. Ela usa um fluxo de trabalho de gatilho-pesquisa-download, ideal para lidar com tarefas de scraping potencialmente longas.
O método trigger_search inicia o trabalho de scraping. Observe o uso do decorador @retry da biblioteca tenacity – isso adiciona resiliência, repetindo automaticamente a solicitação com backoff exponencial se ela falhar.
# amazon_analytics/api.py
class BrightDataAPI:
def __init__(self, token: Optional[str] = None):
self.token = token or BRIGHT_DATA_TOKEN
self.base_url = "https://api.brightdata.com/conjuntos_de_dados/v3"
self.headers = {
"Authorization": f"Bearer {self.token}",
"Content-Type": "application/json"
}
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10),
retry=retry_if_exception_type((requests.RequestException, BrightDataAPIError))
)
def trigger_search(self, keyword: str, amazon_url: str, pages_to_search: str = "") -> str:
"""Aciona uma nova tarefa de scraping e retorna o ID do snapshot."""
payload = [{
"keyword": palavra-chave,
"url": amazon_url,
"pages_to_search": páginas_a_pesquisar
}]
response = requests.post(
f"{self.base_url}/trigger",
headers=self.headers,
json=payload,
params={
"dataset_id": BRIGHT_DATA_DATASET_ID,
"include_errors": "true",
"limit_multiple_results": "150"
},
timeout=30
)
response.raise_for_status()
return response.json()["snapshot_id"]Após acionar uma pesquisa, o método wait_for_results consulta a API até que a tarefa seja concluída e, em seguida, baixa os dados. Isso evita que o aplicativo trave durante a espera e inclui um tempo limite para evitar loops infinitos.
Com uma coleta de dados confiável em vigor, a próxima etapa é limpar e enriquecer esses dados brutos.
Etapa 3 – construção do pipeline de processamento de dados
Os dados brutos de qualquer fonte raramente estão no formato perfeito para análise. Nossa classe DataProcessor em data_processor.py é responsável por limpar, normalizar e criar novos recursos a partir dos dados coletados da Amazon, deixando-os prontos para nossas camadas de IA e visualização. Para uma visão mais ampla do processamento de dados, consulte nosso guia sobre análise de dados com Python.
Parsing inteligente de preços
Um desafio significativo nos dados de comércio eletrônico é lidar com formatos internacionais. Por exemplo, um preço na Alemanha pode ser “1.234,56”, enquanto nos EUA é “1.234,56”. A função parse_float_locale lida de forma inteligente com essas variações.
# amazon_analytics/data_processor.py (simplificado para facilitar a leitura)
def parse_float_locale(self, value: Any) -> Optional[float]:
"""Analisador flutuante robusto que lida com formatos numéricos internacionais."""
if value is None or value == "":
return None
if isinstance(value, (int, float)):
return float(value)
if isinstance(value, str):
s = re.sub(r"[^0-9.,]", "", value)
has_comma = "," in s
has_dot = "." in s
if has_comma and has_dot:
# Determinar o separador decimal pela última posição
if s.rfind(',') > s.rfind('.'):
s = s.replace('.', '').replace(',', '.') # Formato europeu
else:
s = s.replace(',', '') # Formato americano
elif has_comma:
# Verificar se a vírgula é separador de milhares ou decimal
if re.search(r",d{3}$", s):
s = s.replace(',', '') # Separador de milhares
else:
s = s.replace(',', '.') # Separador decimal
return float(s)
return NoneAlgoritmo de pontuação de valor personalizado
Para ajudar os usuários a identificar rapidamente os melhores produtos, criamos um value_score personalizado. Essa métrica composta combina vários fatores em uma única pontuação fácil de entender.
# amazon_analytics/data_processor.py
def compute_value_score(
self,
rating: Optional[float],
num_ratings: Optional[int],
discount_pct: Optional[float],
min_reviews: int = 10)
-> float:
"""Calcula uma pontuação de valor composta com base na qualidade, prova social e valor da oferta."""
score = 0.0
# 40% de peso para a qualidade do produto (classificação)
if rating and rating > 0:
score += (rating / 5.0) * 0.4
# 30% de peso para prova social (número de classificações)
if num_ratings and num_ratings >= min_reviews:
# Escala logarítmica para evitar que itens mega populares dominem
review_score = min(math.log10(num_ratings) / 4, 1.0)
score += review_score * 0.3
# 30% de peso para o valor da oferta (porcentagem de desconto)
if discount_pct and discount_pct > 0:
discount_score = min(discount_pct / 50, 1.0) # Limite máximo de 50% de desconto
score += discount_score * 0.3
return round(score, 2)Este algoritmo equilibra qualidade (classificação), prova social (volume de avaliações) e valor da oferta (desconto) para fornecer uma medida holística do apelo de um produto.
Agora que nossos dados estão limpos e enriquecidos, podemos alimentá-los em nosso mecanismo de IA para obter insights mais profundos.
Etapa 4 – integrando IA para análise inteligente com Gemini
É aqui que nosso aplicativo se torna verdadeiramente inteligente. Usamos a IA Gemini do Google para analisar os dados processados e responder às perguntas dos usuários. Um grande desafio com LLMs é a alucinação – inventar fatos que não estão presentes nos dados de origem. Nosso GeminiAIEngine foi projetado para evitar isso.
# amazon_analytics/gemini_ai_engine.py (simplificado significativamente para clareza do tutorial)
def _create_anti_hallucination_prompt(self, user_query: str, df: pd.DataFrame) -> str:
"""Cria um prompt à prova de alucinações, incluindo todo o contexto dos dados."""
# Observação: a implementação real inclui mapeamento detalhado de campos,
# conversão de tipos e tratamento de NaN para mais de 20 atributos de produtos
products_data = []
for _, row in df.iterrows():
produto = {
'nome': str(row.get('name', 'N/A')),
'asin': str(row.get('asin', 'N/A')),
'preço_final': float(row.get('final_price', 0)) se pd.notna(row.get('final_price')) senão 0,
'rating': float(row.get('rating', 0)) se pd.notna(row.get('rating')) senão 0,
'num_ratings': int(row.get('num_ratings', 0)) se pd.notna(row.get('num_ratings')) senão 0,
# ... campos adicionais com tratamento de tipo adequado
}
products_data.append(product)
return f"""Você é um analista especialista em produtos da Amazon com capacidades avançadas de raciocínio.
REGRAS DE ZERO ALUCINAÇÃO:
1. NUNCA invente ou invente NENHUMA informação sobre o produto.
2. Use APENAS os dados explicitamente fornecidos abaixo.
3. Se faltar alguma informação, indique claramente "Esta informação não está disponível".
4. Cite sempre os ASINs específicos do produto para verificação.
5. Use seu raciocínio para fornecer insights valiosos com base nos dados reais
CAPACIDADES DE RACIOCÍNIO:
- Compare produtos analisando preço, classificações, avaliações e recursos
- Identifique os produtos com melhor custo-benefício considerando a relação entre preço e classificação
- Avalie a confiabilidade do produto avaliando a qualidade da classificação e o volume de avaliações
- Detecte ofertas comparando o preço inicial com o preço final
CONSULTA DO USUÁRIO: {user_query}
DADOS DE PRODUTOS DISPONÍVEIS ({len(df)} produtos):
{json.dumps(products_data, indent=2)}
Use seu raciocínio para analisar esses dados e fornecer insights úteis e precisos. Inclua ASINs e números específicos para verificação."""Principais técnicas anti-alucinação:
- Inclusão completa de dados. Todas as informações do produto são fornecidas à IA, sem deixar margem para especulações.
- Limites explícitos. Regras claras sobre o que a IA pode e não pode fazer.
- Citações ASIN. Obriga a IA a referenciar produtos específicos para verificação.
- Formato de dados estruturado. O formato JSON torna o Parsing de dados confiável para a IA.
Essa abordagem de engenharia rápida transforma a IA em um analista de dados confiável, tornando sua produção confiável e verificável.
Com o mecanismo de IA pronto, podemos construir o sistema de recomendação.
Etapa 5 – criando o mecanismo de inteligência de compras
O ShoppingIntelligenceEngine em shopping_intelligence.py usa os dados processados para gerar três recomendações principais: “Melhor valor geral”, “Mais bem avaliado” e “Melhor oferta”. O mecanismo aplica critérios de filtragem sofisticados para garantir recomendações de qualidade.
O sistema funciona com uma lista de dicionários de produtos e usa métodos auxiliares separados para cada categoria de recomendação, cada um com limites de qualidade específicos.
# amazon_analytics/shopping_intelligence.py
class ShoppingIntelligenceEngine:
def analyze_products(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Gerar inteligência de compras a partir dos dados do produto."""
if not products:
return {'total_items': 0, 'top_picks': []}
top_picks = self._generate_top_picks(products)
return {
'total_items': len(products),
'top_picks': top_picks
}
def _generate_top_picks(self, products: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""Gerar recomendações dos melhores produtos com justificativa."""
tente:
# Primeiro, filtre apenas os produtos válidos
produtos_válidos = []
para produto em produtos:
classificação = produto.obter('classificação')
preço = produto.obter('preço_final')
if rating is not None and price is not None and rating > 0 and price > 0:
produtos_válidos.append(produto)
if not produtos_válidos:
return []
escolhas = []
asins_usados = set()
# Encontre cada categoria usando métodos especializados
melhor_valor = self._find_best_value(produtos_válidos)
se melhor_valor e melhor_valor.get('asin') não estiverem em asins_utilizados:
seleções.append({
'produto': melhor_valor,
'motivo': 'Melhor valor geral',
'explicação': 'Excelente equilíbrio entre qualidade, preço e avaliações dos clientes'
})
asins_utilizados.add(melhor_valor['asin'])
highest_rated = self._find_highest_rated(produtos_válidos)
se highest_rated e highest_rated.get('asin') não estiverem em used_asins:
picks.append({
'produto': highest_rated,
'motivo': 'Mais bem avaliado',
'explicação': 'Maior satisfação do cliente com histórico comprovado'
})
used_asins.add(highest_rated['asin'])
best_deal = self._find_best_deal(valid_products)
if best_deal and best_deal.get('asin') not in used_asins:
picks.append({
'product': best_deal,
'reason': 'Melhor oferta',
'explanation': 'Ótimo custo-benefício com economia significativa e boa qualidade'
})
used_asins.add(best_deal['asin'])
# Preencha os espaços restantes com produtos de qualidade, se necessário
if len(picks) < 3:
remaining_products = [p for p in valid_products if p.get('asin') not in used_asins]
remaining_products.sort(key=lambda x: x.get('value_score', 0), reverse=True)
para produto em produtos_restantes[:3-len(escolhas)]:
picks.append({
'produto': produto,
'motivo': 'Escolha de qualidade',
'explicação': 'Bom equilíbrio entre qualidade e valor'
})
retornar picks[:3]
exceto Exceção:
retornar []Métodos de filtragem de qualidade
Cada categoria de recomendação tem limites de qualidade específicos para garantir recomendações confiáveis:
def _find_best_value(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Encontre o produto com a melhor pontuação de valor - requer mais de 10 avaliações."""
candidates = [p for p in products if
p.get('value_score') is not None and
p.get('num_ratings', 0) >= 10]
if not candidates:
retorne None
retorne max(candidates, key=lambda p: p.get('value_score', 0))
def _find_highest_rated(self, products: List[Dict[str, Any]]) -> Dict[str, Any]:
"""Encontre o produto com a melhor classificação - requer classificação 4.0+ e 50+ avaliações."""
candidatos = [p para p em produtos se
p.get('rating', 0) >= 4.0 e
p.get('num_ratings', 0) >= 50]
se não houver candidatos:
retorne None
retorne max(candidatos, chave=lambda p: (p.get('classificação', 0), p.get('num_classificações', 0)))
def _encontrar_melhor_oferta(self, produtos: Lista[Dict[str, Any]]) -> Dict[str, Any]:
"""Encontre o melhor desconto - requer desconto de 10%+ e classificação de 3,5+."""
candidates = [p for p in products if
p.get('discount_pct') is not None and
p.get('discount_pct', 0) >= 10 and
p.get('rating', 0) >= 3.5]
if not candidates:
return None
return max(candidates, key=lambda p: p.get('discount_pct', 0))Principais decisões de design:
- Limites de qualidade. Cada categoria tem padrões mínimos para evitar a recomendação de produtos de baixa qualidade.
- Sem duplicatas. O conjunto
used_asinsgarante que cada produto apareça apenas uma vez. - Lógica de fallback. Se forem encontradas menos de 3 recomendações, preenche com as pontuações dos melhores valores seguintes.
- Tratamento de erros. Try/catch evita falhas em dados malformados.
Essa abordagem garante que os usuários recebam recomendações confiáveis e de alta qualidade, em vez de apenas os primeiros produtos encontrados.
Agora temos todos os componentes de back-end. Vamos construir a interface do usuário para reunir tudo.
Etapa 6 – projetando o painel interativo com Streamlit
A peça final é a interface do usuário, gerenciada pelo streamlit_app.py. O Streamlit permite que você crie um painel reativo baseado na web com o mínimo de código. O aplicativo usa um layout sofisticado baseado em guias com acompanhamento do progresso em tempo real e vários tipos de gráficos.
Estado da sessão e cache de componentes
O aplicativo usa variáveis específicas do estado da sessão para gerenciar o fluxo de dados e armazena em cache os componentes de back-end para melhorar o desempenho:
# streamlit_app.py - Inicialização do estado da sessão
if 'search_results' not in st.session_state:
st.session_state.search_results = []
if 'shopping_intelligence' not in st.session_state:
st.session_state.shopping_intelligence = {}
if 'current_run_id' not in st.session_state:
st.session_state.current_run_id = None
@st.cache_resource
def get_backend_components():
"""Inicializar e armazenar em cache os componentes de back-end."""
api = BrightDataAPI()
processador = DataProcessor()
inteligência = ShoppingIntelligenceEngine()
ai_engine = get_gemini_ai()
return api, processador, inteligência, ai_engineProcessamento de pesquisa em linha com acompanhamento do progresso
A lógica de pesquisa está incorporada diretamente no fluxo principal do aplicativo, com acompanhamento detalhado do progresso e persistência dos dados:
# streamlit_app.py - Processamento de pesquisa (simplificado)
# Execução da pesquisa com acompanhamento do progresso
if search_clicked and keyword.strip():
progress_bar = st.progress(0)
status_text = st.empty()
start_time = time.time()
try:
# Acionar a pesquisa
status_text.text("Iniciando a pesquisa na Amazon...")
snapshot_id = API.trigger_search(keyword, amazon_url)
progress_bar.progress(25)
# Aguardar resultados com atualizações inteligentes do progresso
status_text.text("A Amazon está processando sua pesquisa...")
results = smart_wait_for_results(API, snapshot_id, progress_bar, status_text)
progress_bar.progress(75)
# Processar resultados
status_text.text("Analisando produtos...")
processed_results = processor.process_raw_data(results)
shopping_intel = intelligence.analyze_products(processed_results)
# Armazenar resultados abrangentes no estado da sessão
st.session_state.search_results = resultados_processados
st.session_state.shopping_intelligence = shopping_intel
st.session_state.current_run_id = str(uuid.uuid4())
st.session_state.raw_data = resultados
st.session_state.search_metadata = {
'keyword': palavra-chave,
'country': países[país_selecionado],
'domain': amazon_url,
'timestamp': datetime.now(timezone.utc).isoformat()
}
elapsed_time = time.time() - start_time
status_text.text(f"Encontrados {len(processed_results)} produtos em {elapsed_time:.1f}s!")
progress_bar.progress(100)
except Exception as e:
st.error(f"Falha na pesquisa: {str(e)}")Várias visualizações interativas
A guia Análise de mercado cria vários tipos de gráficos em linha, cada um com estilo e anotações específicos:
# streamlit_app.py - Distribuição de preços com linha mediana
fig_price = px.histogram(
x=display_prices,
nbins=min(20, max(1, unique_prices)),
title="Faixa de preço",
labels={'x': f'Preço ({currencies.get(current_country_code, "USD")})', 'y': 'Número de produtos'},
color_discrete_sequence=['#667eea']
)
# Adicionar linha mediana para contexto
fig_price.add_vline(x=q50, line_dash="dash", line_color="orange", annotation_text="Mediana")
st.plotly_chart(fig_price, use_container_width=True)
# Dispersão de classificação vs preço com codificação de tamanho e cor
fig_scatter = px.scatter(
df_scatter,
x='final_price',
y='rating',
size='num_ratings',
hover_data=['name', 'num_ratings'],
title="Qualidade vs preço",
labels={'final_price': f'Preço ({currencies.get(current_country_code, "USD")})', 'rating': 'Classificação (Estrelas)'},
color='rating',
color_continuous_scale='Viridis')
st.plotly_chart(fig_scatter, use_container_width=True)
# Distribuição da pontuação de valor com marcadores percentuais
fig_value = px.histogram(
x=value_scores,
nbins=20,
title="Melhores produtos em termos de valor",
labels={'x': 'Pontuação de valor (0,0-1,0)', 'y': 'Número de produtos'},
color_discrete_sequence=['#28a745']
)
p50 = np.percentile(value_scores, 50)
p75 = np.percentile(value_scores, 75)
fig_value.add_vline(x=p50, line_dash="dash", line_color="orange", annotation_text="Mediana")
fig_value.add_vline(x=p75, line_dash="dash", line_color="red", annotation_text="75º percentil")
st.plotly_chart(fig_value, use_container_width=True)Recursos avançados do gráfico
O painel inclui visualizações sofisticadas com inteligência empresarial:
- Histogramas de preços. Com marcadores de mediana e quartil para posicionamento no mercado.
- Gráficos de dispersão de classificação. O tamanho representa o volume de avaliações, a cor mostra a qualidade da classificação.
- Gráficos de pizza de posição. Mostra a distribuição da classificação de pesquisa (1-5, 6-10, 11-20, 21+).
- Gráficos de barras de categorias de preços. Segmentar produtos em níveis de Orçamento/Valor/Premium/Luxo.
- Análise de descontos. Identifica ofertas genuínas versus preços inflacionados.
Essa abordagem abrangente cria um painel de análise profissional que fornece insights de mercado acionáveis.
Conclusão
Você criou com sucesso um analisador de produtos da Amazon que aproveita a coleta de dados de nível empresarial, IA avançada e visualização interativa de dados. O código-fonte completo deste projeto está disponível para você explorar e adaptar no GitHub.
Você viu como:
- Usar a API de Scraping de Dados da Bright Data para coletar dados da Amazon em grande escala de maneira confiável.
- Implementar um pipeline de processamento de dados robusto para lidar com desafios complexos de dados do mundo real.
- Criar um assistente de IA à prova de alucinações com o Google Gemini para análises confiáveis.
- Criar uma interface de usuário intuitiva e interativa com Streamlit e Plotly.
Este projeto serve como um modelo poderoso para qualquer aplicativo que exija transformar grandes quantidades de dados da web em inteligência de negócios acionável. A partir daqui, você pode estendê-lo para criar um rastreador de preços dedicado da Amazon ou integrar outras fontes de dados.
O mundo dos dados de comércio eletrônico é vasto. Se você precisar de Conjuntos de dados pré-coletados e prontos para uso, explore o marketplace da Bright Data para uma ampla gama de opções.





