

Em projetos de dados modernos, o mapeamento de dados alinha campos e registros entre sistemas para que as informações mantenham seu significado à medida que se movem entre bancos de dados e aplicativos. Antes manual e frágil, ele agora se beneficia da IA. Neste guia, exploraremos como a IA transforma o mapeamento de dados, as principais técnicas por trás dele e como transformar dados públicos da Web em conjuntos de dados prontos para análise.
O que é mapeamento de dados e por que ele é desafiador?
O mapeamento de dados simplesmente informa aos sistemas como os campos de dados se correspondem. Por exemplo, o e-mail de um cliente em um banco de dados é mapeado para o endereço de e-mail em outro. Sem o mapeamento adequado, os dados transferidos entre sistemas podem perder o contexto ou gerar duplicatas. O mapeamento é essencial para a integração, a migração e a análise: ele ajuda a garantir que, ao mover os dados para uma nova ferramenta ou depósito, todos os valores acabem no lugar certo.
Entretanto, o mapeamento tradicional é lento e propenso a erros. Em grandes empresas, os dados residem em centenas de fontes e formatos diferentes. As equipes geralmente precisam escrever scripts personalizados ou usar ferramentas de ETL complexas, combinando manualmente cada campo. Esse método não é escalonável: os projetos podem levar meses e os erros humanos são comuns.
O desafio torna-se ainda maior quando se trabalha com dados da Web – páginas HTML não estruturadas, nomes de campos inconsistentes e formatação confusa criam uma complexidade adicional. Dados de origem de baixa qualidade levam a resultados de mapeamento ruins, independentemente do grau de avanço de suas ferramentas de IA.
Como a IA transforma o mapeamento de dados
O mapeamento de dados com IA usa aprendizado de máquina e processamento de linguagem natural para analisar esquemas de origem e destino, interpretar nomes de campos e contexto e aprender com mapeamentos anteriores para propor correspondências precisas em vez de exigir codificação manual de campos.
A IA reconhece que cust_ID, customerID e customer_id representam o mesmo conceito. As plataformas detectam dicas de tipo de dados e sugerem campos de destino de acordo, reduzindo as tarefas de mapeamento de horas para minutos.
Aqui estão os principais benefícios do mapeamento de dados com IA:
- Velocidade e eficiência. A automação lida com o mapeamento repetitivo e a configuração de transformação, reduzindo o esforço manual.
- Precisão e aprendizado. Os sistemas aprendem com suas escolhas de aceitação/rejeição, melhorando as sugestões ao longo do tempo.
- Escalabilidade. O mapeamento com IA lida com conjuntos de dados grandes e complexos. À medida que o volume e a variedade de dados aumentam, as ferramentas modernas podem analisar simultaneamente vários esquemas e fontes.
- Adaptabilidade. Ao contrário dos scripts estáticos, o mapeamento de IA se adapta às mudanças. Quando novos campos ou formatos aparecem, a IA infere as relações a partir do contexto ou do feedback do usuário. O sistema aprende os padrões de dados de sua organização, exigindo menos correções humanas ao longo do tempo.
- Melhor qualidade e governança dos dados. O mapeamento automatizado ajuda a reforçar a consistência e a governança. Ao documentar como os campos se alinham, as ferramentas de IA mantêm a linhagem dos dados e dão suporte à conformidade, rastreando o roteamento de dados confidenciais.
- Custos mais baixos. Esses benefícios reduzem os custos por meio de menos trabalho manual, menos erros que exigem retrabalho e conclusão mais rápida do projeto.
Tecnologias por trás do mapeamento de dados com IA
Várias técnicas de IA potencializam o mapeamento de dados moderno:
- Processamento de linguagem natural (NLP). A PNL interpreta o significado dos nomes e rótulos dos campos (por exemplo, endereço de e-mail vs. e-mail) e pode processar a documentação para extrair o contexto, tornando o mapeamento mais robusto mesmo quando os nomes diferem muito.
- Modelos de aprendizado de máquina. Os modelos de aprendizado de máquina classificam e preveem mapeamentos com base em padrões aprendidos. Cada mapeamento anterior alimenta o modelo: se muitos conjuntos de dados mostrarem o mapeamento de account_manager para sales_rep em um sistema de faturamento, o modelo priorizará essa sugestão na próxima vez, melhorando as recomendações ao longo do tempo com um ser humano no circuito.
- Gráficos de conhecimento. Algumas plataformas mantêm gráficos de conhecimento interno que vinculam entidades e relacionamentos entre sistemas. Um gráfico pode representar que um ID de cliente em um sistema é o mesmo que um número de conta em outro e que ambos estão relacionados a uma referência de faturamento, ajudando a inferir mapeamentos indiretos e a manter os esquemas consistentes.
- Aprendizagem profunda e visão computacional. Para documentos não estruturados ou semiestruturados (por exemplo, PDFs, formulários digitalizados), a aprendizagem profunda pode extrair texto, tabelas e pares de valores-chave para que você possa mapeá-los para destinos estruturados.
- Correspondência semântica e alinhamento de esquemas. As ferramentas modernas integram algoritmos de correspondência de esquemas (incluindo alinhamento de gráficos/ontologias) que combinam evidências léxicas, estruturais e baseadas em instâncias, além de dicionários de domínio, quando disponíveis, para encontrar correspondências.
Como funciona o mapeamento de dados de IA (passo a passo)
As ferramentas de mapeamento de dados de IA seguem este fluxo de trabalho:
- Conectar fontes de dados. A ferramenta se conecta aos seus sistemas de origem e destino (bancos de dados, arquivos, APIs), inspeciona nomes de campos, tipos de dados, valores de amostra e metadados e usa a PNL para ler rótulos/descrições para entender o contexto antes de propor correspondências.
- Analisar e propor correspondências. Ele aplica o mapeamento automático por nome/posição e similaridade semântica para gerar pares candidatos, geralmente com pontuações de confiança. Por exemplo, ele pode mapear country_code com CountryID. Se detectar uma incompatibilidade de tipo (texto como “Qty: 12” versus um destino numérico), ele proporá uma transformação de análise/conversão antes do mapeamento final.
- Revise e refine. As correspondências de alta confiança podem ser aceitas automaticamente, enquanto as ambíguas são sinalizadas para revisão do administrador. As ações de aceitação/rejeição são capturadas para auditoria e usadas para aprimorar sugestões futuras.
- A IA aprende com o feedback. O sistema internaliza suas escolhas (sua memória institucional), de modo que conjuntos de dados semelhantes sejam mapeados mais rapidamente na próxima vez e as recomendações estejam alinhadas com suas convenções e políticas de nomenclatura.
- Implemente transformações. Depois que os mapeamentos são aprovados, a plataforma gera e operacionaliza as transformações necessárias (casts, concatenações, padronizações) e as executa dentro de pipelines ETL/ELT gerenciados com agendamento, monitoramento e captura de linhagem.
Obtenção de dados prontos para mapeamento na Web
Antes que a IA possa mapear seus dados de forma eficaz, você precisa de entradas limpas e estruturadas. Os dados da Web geralmente vêm bagunçados – formatação inconsistente, HTML aninhado, estruturas de página variáveis. É nesse ponto que a coleta adequada de dados da Web se torna crucial para projetos de mapeamento bem-sucedidos.
A Bright Data oferece uma plataforma para extrair e preparar dados da Web para IA, de modo que o mapeamento começa com entradas mais limpas:
- AI Web Scraper. Identifique a estrutura da página e extraia dados estruturados de sites modernos; forneça JSON/CSV via API ou webhooks.
- Conjuntos de dados (pré-criados). Conjuntos de dados prontos e atualizados com esquemas documentados (por exemplo, produtos da Amazon), para que os nomes e os tipos de campo sejam consistentes desde o início.
- Proxy e Web Unlocker. Acesso confiável a sites públicos, manipulando bloqueios e CAPTCHAs, para que você possa coletar os dados antes do mapeamento, mesmo em sites difíceis.
- API do navegador e funções sem servidor. Execute fluxos de trabalho de raspagem programáveis e hospedados para coleta em várias etapas antes do mapeamento.
- Integrações. Conecte as saídas de conjuntos de dados ou de raspagem a estruturas de aplicativos de IA (por exemplo, LangChain, LlamaIndex) ou a seus destinos de armazenamento.
Ao lidar com a coleta e a estruturação inicial, a Bright Data permite que você se concentre no mapeamento e na transformação.
Exemplo simples – mapeamento de um conjunto de dados de produtos da Amazon
Vamos ver um exemplo prático usando dados de produtos da Amazon. Em vez de raspar manualmente páginas de produtos confusas, usaremos o Amazon Product Dataset da Bright Data, que fornece registros limpos e estruturados, perfeitos para o mapeamento de IA.
O conjunto de dados inclui campos como título, marca, initial_price, moeda e disponibilidade. Um registro de amostra é semelhante a:
{
"title": "Cami Tops para meninas da Hanes, Camisolas 100% algodão...",
"brand" (marca): "Roupa íntima Hanes Girls 7-16",
"initial_price": 10.00,
"currency": "USD",
"availability": true
}Suponha que nosso esquema analítico de destino precise de ProductName, Brand, PriceUSD e InStock. A ferramenta de mapeamento de IA proporia essas transformações:
- título → ProductName (correspondência semântica de alta confiança)
- marca → Marca (correspondência exata do nome)
- initial_price + currency → PriceUSD (combinar campos, normalizar para USD)
- availability → InStock (conversão booleana)
Após o mapeamento e a transformação:
{
"ProductName": "Hanes Girls' Cami Tops, ...",
"Brand" (Marca): "Hanes Girls 7-16 Underwear",
"PriceUSD": 10.00,
"InStock": true
}A ferramenta de mapeamento de IA propôs automaticamente a maioria dos alinhamentos porque os dados de origem estavam limpos e formatados de forma consistente.
Para requisitos personalizados, você pode usar o AI Web Scraper para extrair campos específicos da Amazon em seu formato preferido e, em seguida, mapeá-los para o esquema de destino.
Observação – Mantenha os humanos no circuito. O mapeamento de IA funciona melhor como um assistente inteligente, não como um substituto para a experiência em dados. Sempre valide mapeamentos críticos, especialmente para campos confidenciais ou conformidade regulatória.
Mapeamento avançado com consultas em linguagem natural
Às vezes, você precisa pesquisar e mapear dados que não existem em formatos pré-construídos. O Deep Lookup da Bright Data permite que você gere conjuntos de dados personalizados usando consultas de linguagem natural e, em seguida, mapeie os resultados para o esquema de destino. Por exemplo:
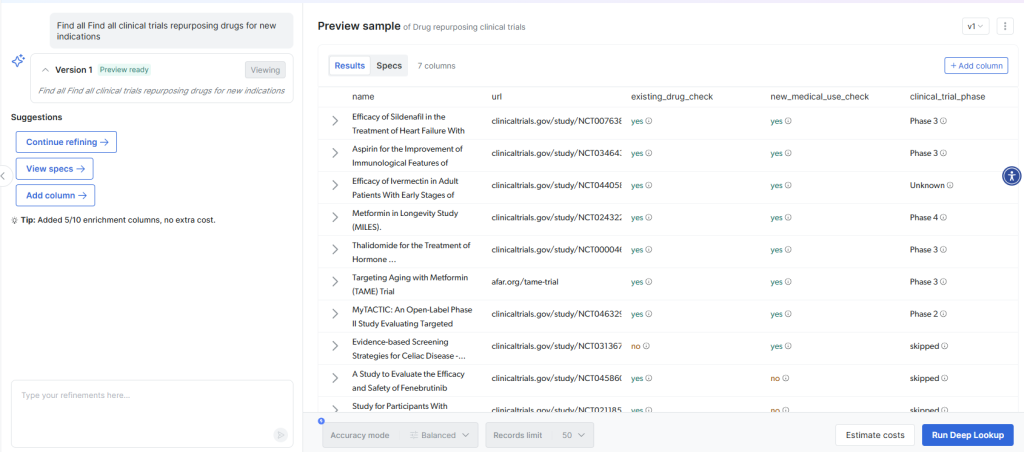
O Deep Lookup pesquisa dados da Web para encontrar empresas correspondentes e retorna resultados estruturados prontos para o mapeamento:

Isso elimina o fluxo de trabalho tradicional de pesquisar, estruturar e mapear, fornecendo dados prontos para mapeamento diretamente de consultas em linguagem natural.
Conclusão
O mapeamento de dados de IA está transformando a forma como as organizações integram dados públicos da Web em fluxos de trabalho de análise e IA. O sucesso começa antes do mapeamento – dados de origem de alta qualidade e bem estruturados melhoram a precisão do mapeamento e reduzem a intervenção manual.
As soluções da Bright Data lidam com a coleta e a estruturação, para que você possa se concentrar no mapeamento de dados da Web para suas necessidades comerciais específicas e estruturas analíticas.
Pronto para ver o impacto dos dados limpos da Web em seus projetos de mapeamento? Entre em contato conosco para obter rapidamente conjuntos de dados estruturados e prontos para mapeamento.





