

Neste guia, você verá o seguinte:
- O que é o Pica e por que ele é uma excelente opção para criar agentes de IA que se integram a ferramentas externas.
- Por que os agentes de IA exigem integração com soluções de terceiros para recuperação de dados.
- Como usar o conector Bright Data integrado em um agente Pica para buscar dados da Web para obter respostas mais precisas.
Vamos mergulhar de cabeça!
O que é Pica?
A Pica é uma plataforma de código aberto projetada para criar rapidamente agentes de IA e integrações de SaaS. Ela fornece acesso simplificado a mais de 125 APIs de terceiros sem exigir o gerenciamento de chaves ou configurações complexas.
O objetivo do Pica é facilitar a conexão dos modelos de IA com ferramentas e serviços externos. Com o Pica, você pode configurar integrações com apenas alguns cliques e usá-las facilmente em seu código. Isso permite que os fluxos de trabalho de IA lidem com a recuperação de dados em tempo real, com automação complexa e muito mais.
O projeto ganhou popularidade rapidamente no GitHub, acumulando mais de 1.300 estrelas em apenas alguns meses. Isso demonstra seu forte crescimento e adoção pela comunidade.
Por que os agentes de IA precisam de integrações de dados da Web
Toda estrutura de agente de IA herda as principais limitações dos LLMs sobre os quais foi construída. Como os LLMs são pré-treinados em conjuntos de dados estáticos, eles não têm consciência em tempo real e não podem acessar de forma confiável o conteúdo da Web ao vivo.
Isso geralmente resulta em respostas desatualizadas ou até mesmo em alucinações. Para superar essas limitações, os agentes (e os LLMs dos quais eles dependem) precisam ter acesso a dados da Web confiáveis e atualizados. Por que dados da Web especificamente? Porque a Web continua sendo a fonte de informações mais abrangente e atualizada disponível.
É por isso que um agente de IA eficaz deve ser capaz de se integrar de forma rápida e fácil com provedores de dados da Web de IA de terceiros. E é exatamente aí que o Pica entra em ação!
Na plataforma da Pica, você encontrará mais de 125 integrações disponíveis, incluindo uma para a Bright Data:
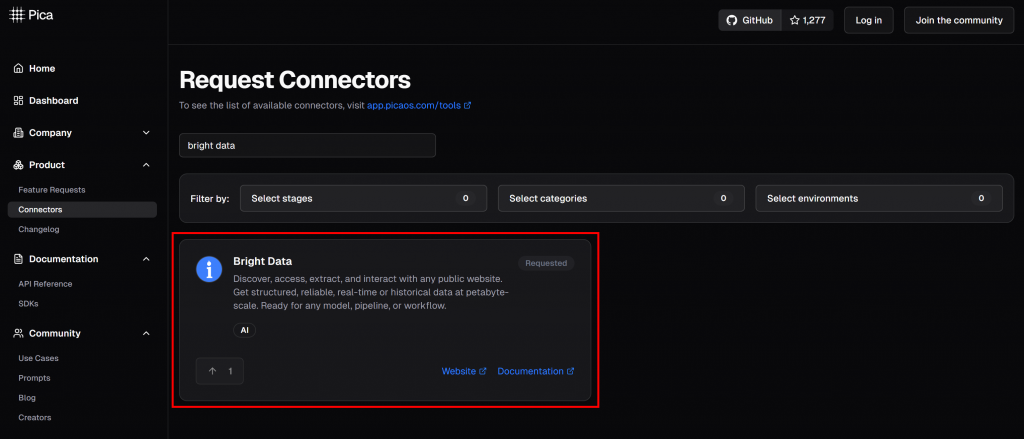
A integração da Bright Data permite que seus agentes e fluxos de trabalho de IA se conectem perfeitamente:
- API do Web Unlocker: Uma API de raspagem avançada que ignora as proteções de bots, fornecendo o conteúdo de qualquer página da Web no formato Markdown.
- APIs do Web Scraper: Soluções especializadas para extrair eticamente dados novos e estruturados de sites populares como Amazon, LinkedIn, Instagram e 40 outros.
Essas ferramentas oferecem aos seus agentes de IA, fluxos de trabalho ou pipelines a capacidade de respaldar suas respostas com dados confiáveis da Web, extraídos em tempo real de páginas relevantes. Veja essa integração em ação no próximo capítulo!
Como criar um agente de IA capaz de recuperar dados da Web com Pica e Bright Data
Nesta seção guiada, você aprenderá a usar o Pica para criar um agente de IA Python que se conecta à integração do Bright Data. Dessa forma, seu agente poderá recuperar dados estruturados da Web de sites como a Amazon.
Siga as etapas abaixo para criar seu agente de IA com base em dados da Bright Data com a Pica!
Pré-requisitos
Para seguir este tutorial, você precisa:
- Python 3.9 ou superior instalado em seu computador (recomendamos a versão mais recente).
- Um relato do Pica.
- Uma chave de API da Bright Data.
- Uma chave de API da OpenAI.
Não se preocupe se você ainda não tiver uma chave de API da Bright Data ou uma conta da Pica. Mostraremos como configurá-las nas próximas etapas.
Etapa 1: inicialize seu projeto Python
Abra um terminal e crie um novo diretório para seu projeto de agente de IA Pica:
mkdir pica-bright-data-agentA pasta pica-bright-data-agent conterá o código Python para seu agente Pica. Ele usará a integração do Bright Data para recuperação de dados da Web.
Em seguida, navegue até o diretório do projeto e crie um ambiente virtual dentro dele:
cd pica-bright-data-agent
python -m venv venvAgora, abra o projeto em seu IDE Python favorito. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Dentro da pasta do projeto, crie um novo arquivo chamado agent.py. Sua estrutura de diretórios deve ser semelhante a esta:
pica-bright-data-agent/
├── venv/
└── agent.pyAtive o ambiente virtual em seu terminal. No Linux ou macOS, execute:
source venv/bin/activateDe forma equivalente, no Windows, acione este comando:
venv/Scripts/activateNas próximas etapas, você instalará os pacotes Python necessários. Se preferir instalar tudo agora mesmo, com seu ambiente virtual ativado, basta executar:
pip install langchain langchain-openai pica-langchain python-dotenvEstá tudo pronto! Agora você tem um ambiente de desenvolvimento Python pronto para criar um agente de IA com integração de Bright Data na Pica.
Etapa 2: Configurar a leitura das variáveis de ambiente
Seu agente se conectará a serviços de terceiros, como Pica, Bright Data e OpenAI. Para manter essas integrações seguras, evite codificar suas chaves de API diretamente em seu código Python. Em vez disso, armazene-as como variáveis de ambiente.
Para facilitar o carregamento de variáveis de ambiente, utilize a biblioteca python-dotenv. Em seu ambiente virtual ativado, instale-a com:
pip install python-dotenvEm seguida, importe a biblioteca e chame load_dotenv() na parte superior do arquivo agent.py para carregar suas variáveis de ambiente:
import os
from dotenv import load_dotenv
load_dotenv()Essa função permite que seu script leia variáveis de um arquivo .env local. Crie esse arquivo .env na raiz do diretório do seu projeto. Sua estrutura de pastas será semelhante a esta:
pica-bright-data-agent/
├── venv/
├── .env # <-----------
└── agent.pyÓtimo! Agora você está preparado para lidar com segurança com suas chaves de API e outros segredos usando variáveis de ambiente.
Etapa 3: Configurar o Pica
Se você ainda não tiver feito isso, crie uma conta gratuita na Pica. Por padrão, o Pica gerará uma chave de API para você. Você pode usar essa chave de API com o LangChain ou qualquer outra integração compatível.
Visite a página “Início rápido” e selecione a guia “LangChain”:
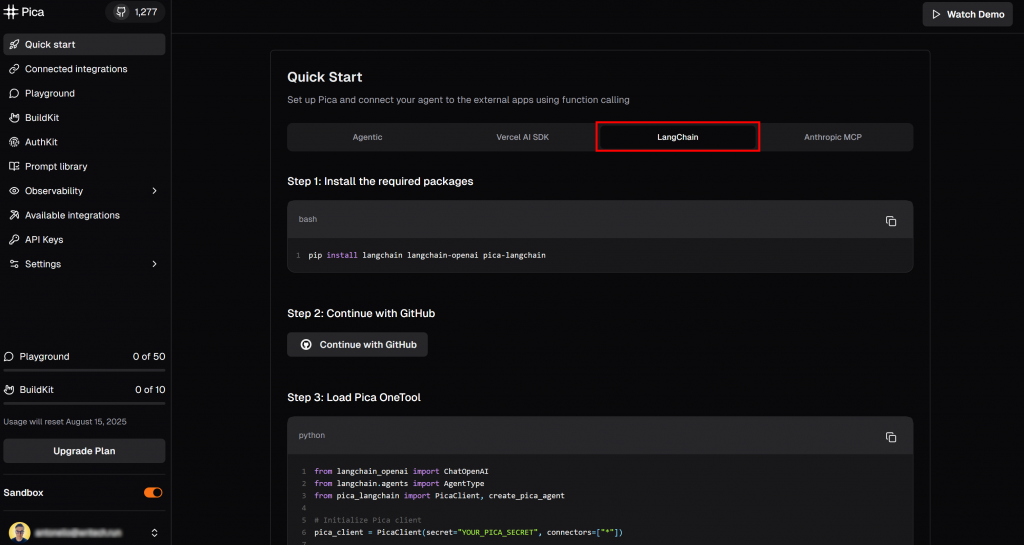
Aqui, você encontrará instruções para começar a usar o Pica no LangChain. Especificamente, siga o comando de instalação mostrado aqui. Em seu ambiente virtual ativado, execute:
pip install langchain langchain-openai pica-langchainAgora, role a tela para baixo até chegar à seção “API Key”:

Clique no botão “copy to clipboard” (copiar para a área de transferência) para copiar sua chave de API da Pica. Em seguida, cole-a em seu arquivo .env definindo uma variável de ambiente como esta:
PICA_API_KEY="<YOUR_PICA_KEY>"Substitua o pelo espaço reservado com a chave de API real que você acabou de copiar.
Fantástico! Sua conta do Pica agora está totalmente configurada e pronta para ser usada em seu código.
Etapa 4: Integrar dados brilhantes no Pica
Antes de começar, certifique-se de seguir o guia oficial para configurar uma chave de API da Bright Data. Você precisará dessa chave para conectar seu agente à Bright Data usando a integração interna disponível na plataforma Pica.
Agora que você tem sua chave de API, pode adicionar a integração do Bright Data no Pica.
Na guia “LangChain” do painel do Pica, role para baixo até a seção “Recent Integrations” (Integrações recentes) e pressione o botão “Browse integrations” (Procurar integrações):
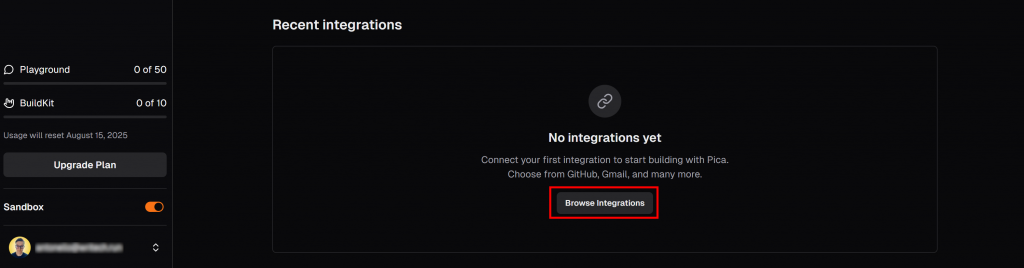
Isso abrirá uma janela modal. Na barra de pesquisa, digite “brightdata” e selecione a integração “BrightData”:
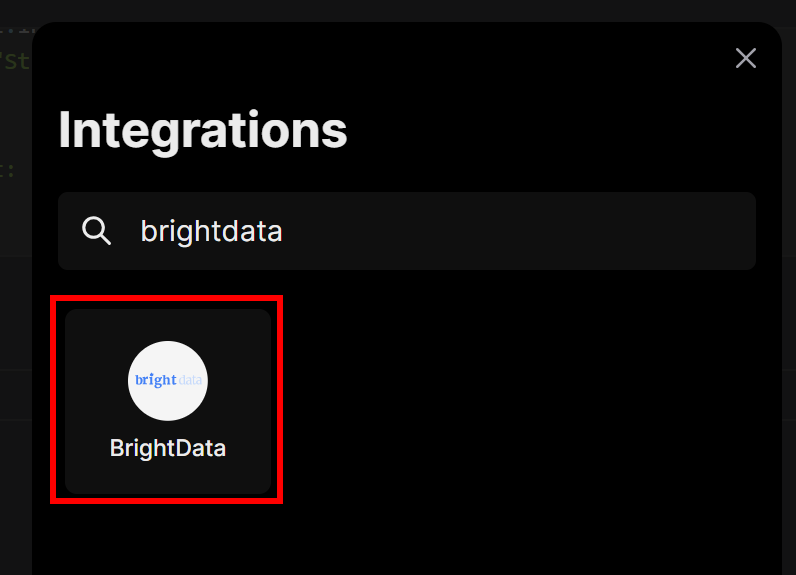
Você será solicitado a inserir a chave da API da Bright Data que criou anteriormente. Cole-a e, em seguida, clique no botão “Connect” (Conectar):
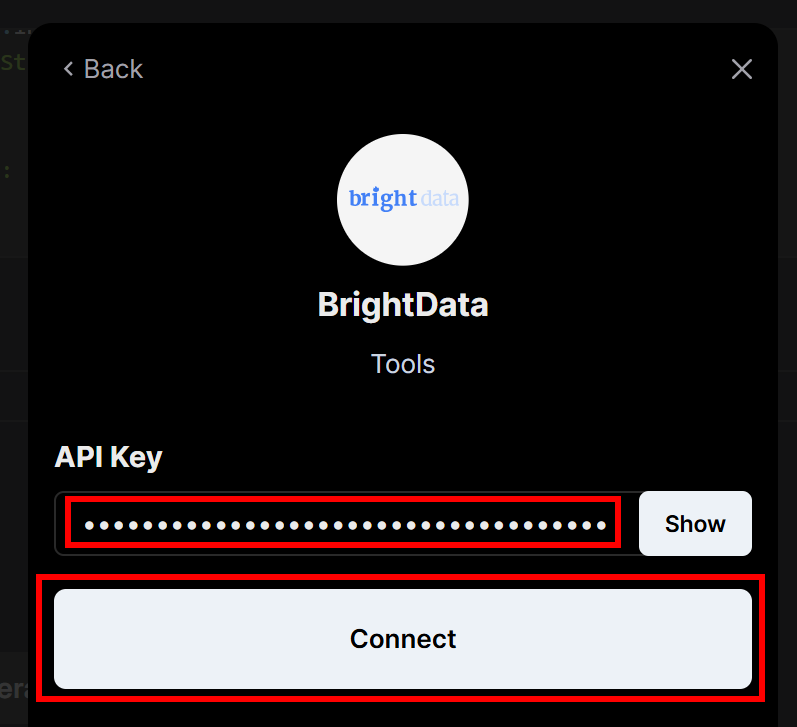
Em seguida, no menu do lado esquerdo, clique no item de menu “Connected Integrations” (Integrações conectadas):
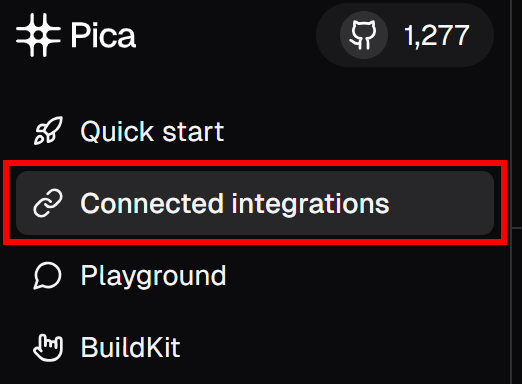
Na página “Connected Integrations” (Integrações conectadas), você deverá ver o Bright Data listado como uma integração conectada. Na tabela, clique no botão “Copy to clipboard” (Copiar para a área de transferência) para copiar sua chave de conexão:
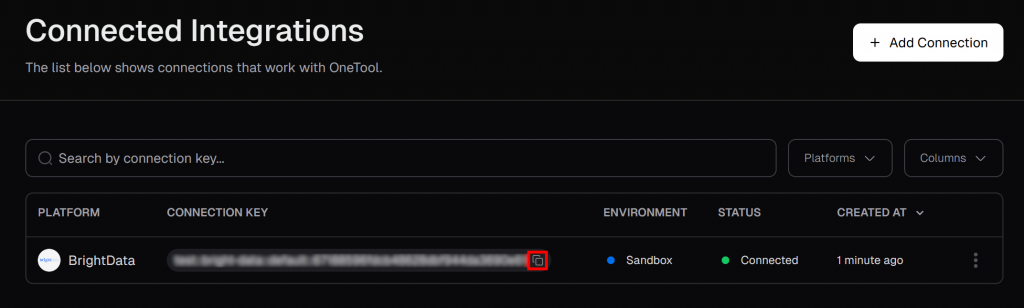
Em seguida, cole-o em seu arquivo .env adicionando:
PICA_BRIGHT_DATA_CONNECTION_KEY="<YOUR_PICA_BRIGHT_DATA_CONNECTION_KEY>"Certifique-se de substituir o com a chave de conexão real que você copiou.
Você precisará desse valor para inicializar seu agente Pica no código, para que ele saiba carregar a conexão Bright Data configurada. Veja como fazer isso na próxima etapa!
Etapa 5: inicializar seu agente Pica
Em agent.py, inicialize seu agente Pica com:
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"]
]
)
)
pica_client.initialize()O snippet acima inicializa um cliente Pica, conectando-se à sua conta Pica usando o segredo PICA_API_KEY carregado do seu ambiente. Além disso, ele seleciona a integração do Bright Data que você configurou anteriormente entre todos os conectores disponíveis.
Isso significa que todos os agentes de IA que você criar com esse cliente poderão aproveitar os recursos de recuperação de dados da Web em tempo real da Bright Data.
Não se esqueça de importar as classes necessárias:
from pica_langchain import PicaClient
from pica_langchain.models import PicaClientOptionsExcelente! Você está pronto para prosseguir com a integração do LLM.
Etapa nº 6: Integrar a OpenAI
Seu agente Pica precisará de um mecanismo LLM para entender os prompts de entrada e executar as tarefas desejadas usando os recursos da Bright Data.
Este tutorial usa a integração do OpenAI, portanto, você definirá o LLM para o seu agente no arquivo agent.py da seguinte forma:
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)Observe que todos os exemplos do Pica LangChain na documentação usam temperatura = 0. Isso garante que o modelo seja determinístico, produzindo sempre o mesmo resultado para a mesma entrada.
Lembre-se de que a classe ChatOpenAI vem dessa importação:
from langchain_openai import ChatOpenAIEm particular, o ChatOpenAI espera que sua chave de API OpenAI seja definida em uma variável de ambiente chamada OPENAI_API_KEY. Portanto, em seu arquivo .env, adicione:
OPENAI_API_KEY=<YOUT_OPENai_API_KEY>Substitua o por sua chave de API OpenAI real.
Incrível! Agora você tem todos os elementos básicos para definir seu agente de IA da Pica.
Etapa nº 7: Defina seu agente de pica
No Pica, um agente de IA consiste em três partes principais:
- Uma instância de cliente Pica
- Um mecanismo LLM
- Um tipo de agente Pica
Nesse caso, você deseja criar um agente de IA que possa chamar as funções do OpenAI (que, por sua vez, se conectam aos recursos de recuperação da Web da Bright Data por meio da integração do Pica). Portanto, crie seu agente Pica da seguinte forma:
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
) Não se esqueça de adicionar as importações necessárias:
from pica_langchain import create_pica_agent
from langchain.agents import AgentTypeMaravilhoso! Agora, tudo o que resta é testar seu agente em uma tarefa de recuperação de dados.
Etapa nº 8: interrogar seu agente de IA
Para verificar se a integração da Bright Data funciona em seu agente da Pica, dê a ele uma tarefa que normalmente não conseguiria realizar por conta própria. Por exemplo, peça que ele recupere dados atualizados de uma página de produto recente da Amazon, como o Nintendo Switch 2 (disponível em https://www.amazon.com/dp/B0F3GWXLTS/).
Para isso, invoque seu agente com essa entrada:
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})Observação: o prompt é intencionalmente explícito. Ele informa ao agente exatamente o que fazer, qual página raspar e qual integração usar. Isso garante que o LLM aproveitará as ferramentas da Bright Data configuradas por meio da Pica, produzindo os resultados esperados.
Por fim, imprima a saída do agente:
print(f"nAgent Result:n{result}")E com essa última linha, seu agente de IA da Pica está completo. É hora de ver tudo isso em ação!
Etapa nº 9: Juntar tudo
Seu arquivo agent.py agora deve conter:
import os
from dotenv import load_dotenv
from pica_langchain import PicaClient, create_pica_agent
from pica_langchain.models import PicaClientOptions
from langchain_openai import ChatOpenAI
from langchain.agents import AgentType
# Load environment variables from .env file
load_dotenv()
# Initialize Pica client with the specific Bright Data connector
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"] # Load the specific Bright Data connection
]
)
)
pica_client.initialize()
# Initialize the LLM
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)
# Create your Pica agent
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
)
# Execute a web data retrieval task in the agent
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})
# Print the produced output
print(f"nAgent Result:n{result}")Como você pode ver, em menos de 50 linhas de código, você criou um agente Pica com recursos avançados de recuperação de dados. Isso é possível graças à integração do Bright Data disponível diretamente na plataforma Pica.
Execute seu agente com:
python agent.pyNo seu terminal, você deverá ver registros semelhantes aos seguintes:
# Omitted for brevity...
2026-07-15 17:06:03,286 - pica_langchain - INFO - Successfully fetched 1 connections
# Omitted for brevity...
2026-07-15 17:06:05,546 - pica_langchain - INFO - Getting available actions for platform: bright-data
2026-07-15 17:06:05,546 - pica_langchain - INFO - Fetching available actions for platform: bright-data
2026-07-15 17:06:05,789 - pica_langchain - INFO - Found 54 available actions for bright-data
2026-07-15 17:06:07,332 - pica_langchain - INFO - Getting knowledge for action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data
# Omitted for brevity...
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: GET
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action for platform: bright-data, method: GET
2026-07-15 17:06:12,975 - pica_langchain - INFO - Successfully executed Get Dataset List via bright-data
2026-07-15 17:06:12,976 - pica_langchain - INFO - Successfully executed action: Get Dataset List on platform: bright-data
2026-07-15 17:06:16,491 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: POST
2026-07-15 17:06:16,492 - pica_langchain - INFO - Executing action for platform: bright-data, method: POST
2026-07-15 17:06:22,265 - pica_langchain - INFO - Successfully executed Trigger Synchronous Web Scraping and Retrieve Results via bright-data
2026-07-15 17:06:22,267 - pica_langchain - INFO - Successfully executed action: Trigger Synchronous Web Scraping and Retrieve Results on platform: bright-dataEm termos mais simples, isso é o que seu agente da Pica fez:
- Conectou-se ao Pica e buscou sua integração configurada do Bright Data.
- Descobriu que havia 54 ferramentas disponíveis na plataforma Bright Data.
- Obteve uma lista de todos os conjuntos de dados da Bright Data.
- Com base em sua solicitação, ele selecionou a ferramenta “Trigger Synchronous Web Scraping and Retrieve Results” (Acionar raspagem síncrona da Web e recuperar resultados) e a usou para raspar dados novos da página especificada do produto Amazon. Nos bastidores, isso aciona uma chamada para o Bright Data Amazon Scraper, passando o URL do produto da Amazon. O raspador recuperará e retornará os dados do produto.
- Executou com sucesso a ação de raspagem e retornou os dados.
Seu resultado deve ser semelhante a este:

Cole essa saída em um editor Markdown e você verá um relatório de produto bem formatado como este:
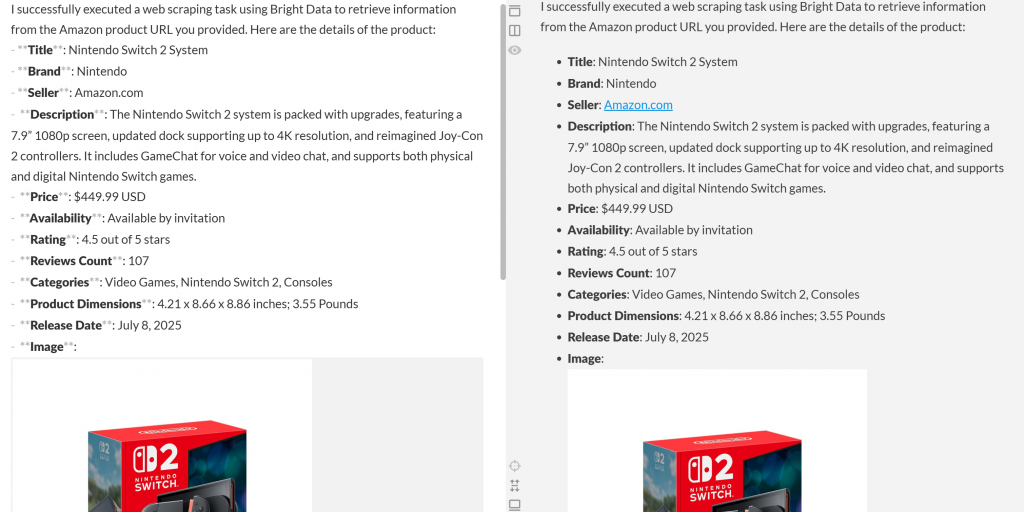
Como você pode ver, o agente conseguiu produzir um relatório Markdown contendo dados significativos e atualizados da página de produto da Amazon. Você pode verificar a precisão visitando a página do produto de destino em seu navegador:
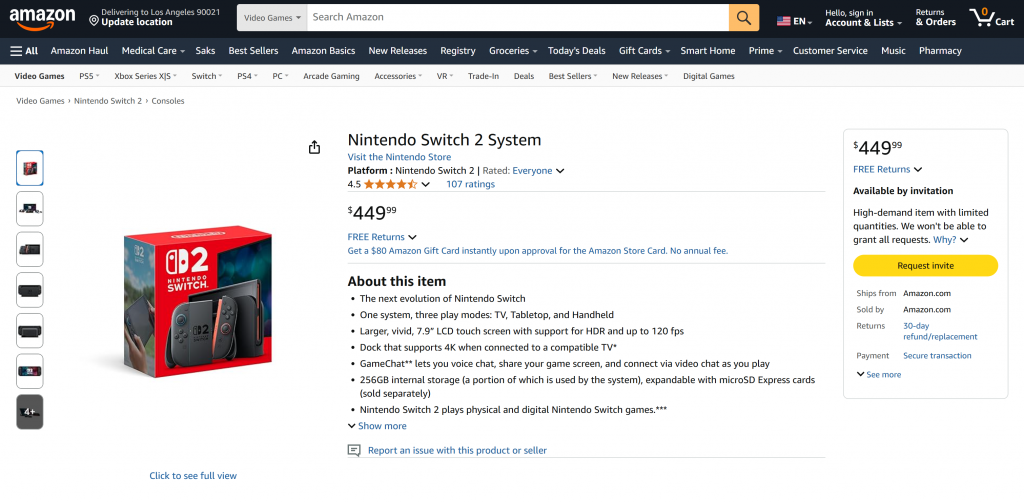
Observe como os dados produzidos são dados reais da página da Amazon, não alucinados pelo LLM. Isso é uma prova da raspagem feita por meio das ferramentas da Bright Data. E isso é apenas o começo!
Com a ampla gama de ações do Bright Data disponíveis no Pica, seu agente agora pode recuperar dados de praticamente qualquer site. Isso inclui alvos complexos, como a Amazon, que são conhecidos por medidas rigorosas contra a coleta de dados (como o famoso CAPTCHA da Amazon).
E pronto! Você acabou de experimentar a raspagem perfeita da Web, com a integração da Bright Data em seu agente de IA da Pica.
Conclusão
Neste artigo, você viu como usar a Pica para criar um agente de IA que pode respaldar suas respostas com dados novos da Web. Isso foi possível graças à integração incorporada da Pica com o Bright Data. O conector Bright Data da Pica oferece à IA a capacidade de buscar dados de qualquer página da Web.
Lembre-se de que este foi apenas um exemplo simples. Se você quiser criar agentes mais avançados, precisará de soluções robustas para buscar, validar e transformar dados da Web em tempo real. É exatamente isso que você pode encontrar na infraestrutura de IA da Bright Data.
Crie uma conta gratuita na Bright Data e comece a explorar nossas ferramentas de extração de dados da Web prontas para IA!





