

Neste guia, você aprenderá:
- O que é o CloudScraper e para que serve
- Por que você deve integrar Proxies no Cloudscraper
- Como fazer isso em um guia passo a passo
- Como implementar a rotação de Proxy no Cloudscraper
- Como lidar com proxies autenticados
- Como usar um provedor de Proxy premium como o Bright Data
Vamos começar!
O que é o CloudScraper?
O CloudScraper é um módulo Python projetado para contornar a página anti-bot do Cloudflare (comumente conhecida como“I’m Under Attack Mode” ou IUAM). Nos bastidores, ele é implementado usando o Requests, um dos clientes HTTP Python mais populares.
Essa biblioteca é particularmente útil para raspar ou rastrear sites protegidos pelo Cloudflare. Atualmente, a página anti-bot verifica se o cliente suporta JavaScript, mas o Cloudflare pode introduzir técnicas adicionais no futuro.
Como a Cloudflare atualiza periodicamente suas soluções anti-bot, a biblioteca é atualizada periodicamente para permanecer funcional.
Por que usar Proxies com o CloudScraper?
O Cloudflare pode bloquear seu IP se você fizer muitas solicitações. Da mesma forma, isso pode acionar defesas mais sofisticadas que são difíceis de contornar, mesmo com ferramentas como o CloudScraper. Para mitigar isso, você precisa de um método confiável para alternar seu endereço IP.
É aí que entra um Proxy. Os Proxies atuam como intermediários entre o seu Scraper e o site de destino, mascarando o seu endereço IP real com o IP do Proxy. Se um IP for bloqueado, você pode mudar rapidamente para um novo Proxy, garantindo acesso ininterrupto.
Os proxies oferecem dois benefícios principais para o Scraping de dados da web com o CloudScraper:
- Maior segurança e anonimato: ao encaminhar as solicitações por meio de um Proxy, sua identidade verdadeira permanece oculta, reduzindo o risco de detecção.
- Evitar bloqueios e interrupções: os Proxy permitem que você alterne endereços IP dinamicamente, o que ajuda a contornar bloqueios e limitadores de taxa.
Ao combinar Proxies com ferramentas como o CloudScraper, você pode criar uma configuração robusta de Scraping de dados que minimiza os riscos e maximiza a eficiência. Essa abordagem em duas camadas garante a extração segura e contínua de dados, mesmo de sites com medidas avançadas anti-scraping.
Configurar um Proxy com o CloudScraper: guia passo a passo
Aprenda a usar Proxy com o CloudScraper nesta seção guiada!
Etapa 1: instale o CloudScraper
Você pode instalar o CloudScraper através do pacote pip cloudscraper usando este comando:
pip install -U cloudscraper
Lembre-se de que o Cloudflare atualiza constantemente seu mecanismo anti-bot. Portanto, inclua a opção -U ao instalar o pacote para garantir que você esteja obtendo a versão mais recente.
Passo 2: Inicialize o Cloudscraper
Para começar, primeiro importe o CloudScraper:
import cloudscraper
Em seguida, crie uma instância do CloudScraper usando o método create_scraper():
Scraper = cloudscraper.create_scraper()
O objeto Scraper funciona de maneira semelhante ao objeto Session da biblioteca requests. Em particular, ele permite que você faça solicitações HTTP contornando as medidas antibot do Cloudflare.
Etapa 3: integrar um Proxy
Como o CloudScraper é construído sobre o Requests, a integração de proxies funciona da mesma forma queno Requests. Se você não estiver familiarizado com esse procedimento, leia nosso tutorial para configurar um Proxy no Requests.
Para usar um Proxy com o CloudScraper, você precisa definir um dicionário de Proxies e passá-lo para o método get() conforme abaixo:
proxies = {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
# Realize uma solicitação através do Proxy especificado
response = scraper.get("<YOUR_TARGET_URL>", proxies=proxies)
O parâmetro Proxy no método get() é passado para Requests. Isso permite que o cliente HTTP encaminhe sua solicitação através do servidor Proxy HTTP ou HTTPS especificado, dependendo do protocolo do seu URL de destino.
Etapa 4: Teste a configuração da integração do Proxy CloudScraper
Para fins de demonstração, vamos direcionar o endpoint /ip do projeto HTTPBin. Esse endpoint retorna o endereço IP do chamador. Se tudo funcionar conforme o esperado, a resposta deverá exibir o endereço IP do Proxy.
Para testar a configuração, você pode obter um IP de Proxy em uma lista de Proxies gratuitos.
Aviso: proxies gratuitos costumam ser pouco confiáveis, coletam dados e são potencialmente inseguros, especialmente se não forem fornecidos por um dos melhores provedores de Proxy do mercado. Tente usá-los apenas para fins educacionais.
Suponha que esta seja a URL do seu servidor Proxy:
http://202.159.35.121:443
Veja como você pode integrá-lo ao CloudScraper:
import cloudscraper
# Crie uma instância do CloudScraper
scraper = cloudscraper.create_scraper()
# Especifique seu Proxy
proxies = {
"http": "http://202.159.35.121:443",
"https": "http://202.159.35.121:443"
}
# Faça uma solicitação através do Proxy
response = Scraper.get("https://httpbin.io/ip", proxies=proxies)
# Imprima a resposta do endpoint "/ip"
print(response.text)
Se configurado corretamente, você deverá ver uma resposta como esta:
{
"origin": "202.159.35.121:1819"
}
Observe como o IP na resposta corresponde ao IP do Proxy, como esperado.
Observação: servidores Proxy gratuitos geralmente têm vida útil curta. Como resultado, o Proxy usado no exemplo abaixo pode não funcionar mais quando você ler este artigo.
Parabéns! Você concluiu uma integração simples do Proxy CloudScraper.
Como implementar a rotação de Proxy
Usar um Proxy com o Cloudscraper ajuda a ocultar seu endereço IP. No entanto, os sites de destino ainda podem bloquear IPs. Isso ocorre se muitas solicitações vierem do mesmo endereço, seja ele o seu próprio IP ou o do Proxy.
Para evitar bloqueios de IP, é essencial alternar seus IPs Proxy regularmente. Ao distribuir suas solicitações por vários endereços IP, você pode fazer com que seu tráfego pareça vir de diferentes usuários. Isso reduz a probabilidade de detecção.
Para implementar a rotação de proxy, comece recuperando uma lista de proxies de um provedor confiável. Armazene-os em uma matriz:
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<YOUR_PROXY_URL_n>", "https": "<YOUR_PROXY_URL_n>"},
]
Em seguida, use o método random.choice() para selecionar aleatoriamente um Proxy da lista:
random_proxy = random.choice(proxy_list)
Não se esqueça de importar random da biblioteca padrão do Python:
import random
Depois disso, basta definir o Proxy selecionado aleatoriamente na solicitação get():
response = Scraper.get("<YOUR_TARGET_URL>", proxies=random_proxy)
Se tudo estiver configurado corretamente, a solicitação usará um Proxy diferente da lista a cada execução. Aqui está o código completo:
import cloudscraper
import random
# Crie uma instância do Cloudscraper
scraper = cloudscraper.create_scraper()
# Lista de URLs de Proxy (substitua pelas URLs de Proxy reais)
proxy_list = [
{"http": "<YOUR_PROXY_URL_1>", "https": "<YOUR_PROXY_URL_1>"},
# ...
{"http": "<SUA_URL_PROXY_n>", "https": "<SUA_URL_PROXY_n>"},
]
# Selecione aleatoriamente um Proxy da lista
random_proxy = random.choice(proxy_list)
# Faça uma solicitação usando o Proxy selecionado aleatoriamente
# (substitua pela URL de destino real)
response = Scraper.get("<SUA_URL_DE_DESTINO>", proxies=random_proxy)
Parabéns! Você integrou a rotação de proxies ao Cloudscraper.
Use Autenticar Proxies no CloudScraper
A maioria dos provedores oferece servidores Proxy autenticados, de modo que apenas usuários pagantes podem acessá-los. Normalmente, você precisa especificar um nome de usuário e uma senha para acessar esses servidores Proxy.
Para autenticar um Proxy no CloudScraper, você deve incluir as credenciais necessárias diretamente na URL do Proxy. O formato para autenticação de nome de usuário e senha é o seguinte:
<PROTOCOLO_PROXY>://<SEU_NOME_DE_USUÁRIO>:<SUA_SENHA>@<ENDEREÇO_IP_PROXY>:<PORTA_PROXY>
Com esse formato, sua configuração de Proxy do CloudScraper ficaria assim:
import cloudscraper
# Crie uma instância do Cloudscraper
scraper = cloudscraper.create_scraper()
# Defina seu Proxy autenticado
proxies = {
"http": "<PROTOCOLO_PROXY>://<SEU_NOME_DE_USUÁRIO>:<SUA_SENHA>@<ENDEREÇO_IP_PROXY>:<PORTA_PROXY>",
"https": "<PROTOCOLO_DO_PROXY>://<SEU_NOME_DE_USUÁRIO>:<SUA_SENHA>@<ENDEREÇO_IP_DO_PROXY>:<PORTA_DO_PROXY>"
}
# Realize uma solicitação através do Proxy autenticado especificado
response = Scraper.get("<SEU_URL_DESTINO>", proxies=proxies)
Excelente! Você está pronto para ver como usar proxies premium no Cloudflare.
Integre proxies premium no Cloudscraper
Para obter resultados confiáveis em ambientes de scraping de produção, você deve usar Proxies de provedores de primeira linha, como a Bright Data. A Bright Data possui uma rede de alta qualidade com mais de 150 milhões de IPs em 195 países, com suporte para os quatro principais tipos de Proxies:
- Proxies de data center
- Proxies residenciais
- Proxy móvel
- Proxy ISP
Com recursos como rotação automática de IP, 100% de tempo de atividade e sessões de IP fixas, a Bright Data se posiciona como o provedor líder de proxies no mercado.
Para integrar os proxies da Bright Data no CloudScraper, crie uma conta ou faça login. Acesse o painel e clique na zona “Residencial” na tabela:
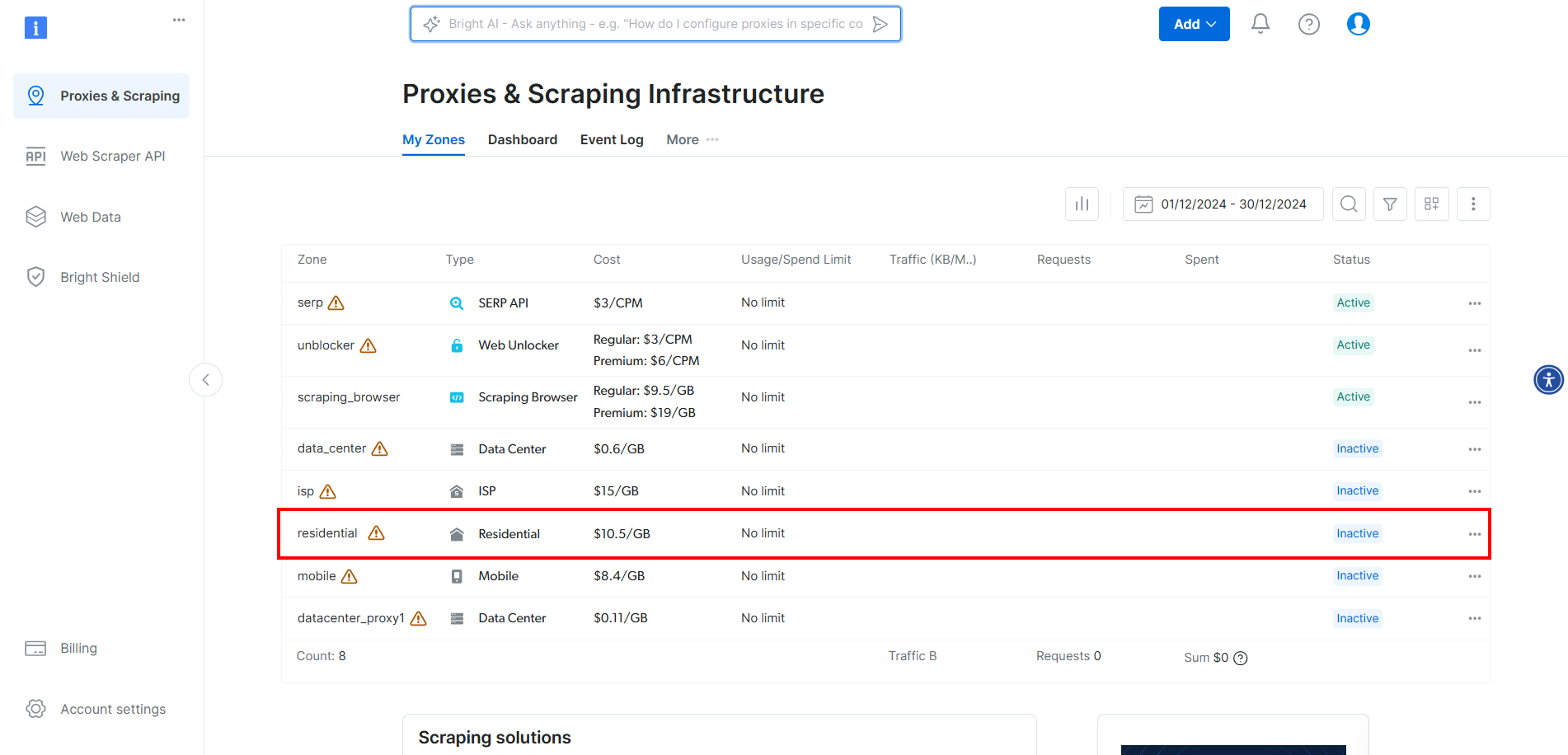
Aqui, ative os Proxies clicando no botão:
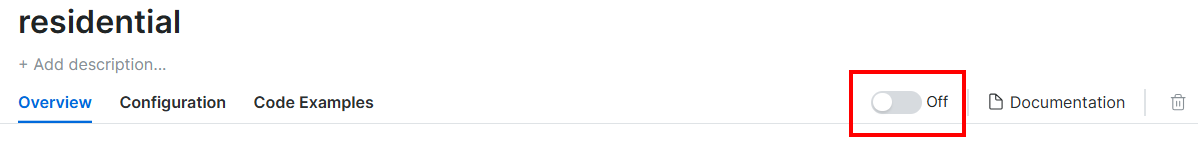
Agora você deverá ver o seguinte:

Na seção “Detalhes de acesso”, copie o host do Proxy, o nome de usuário e a senha:
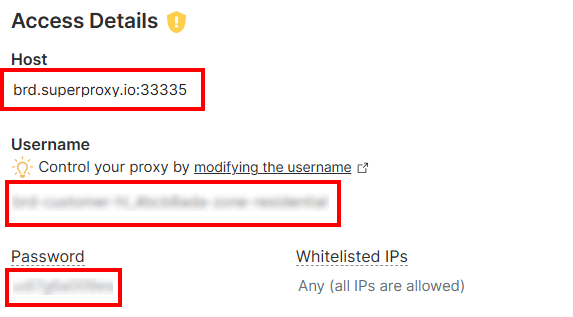
A URL do seu Proxy Bright Data ficará assim:
http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335
Agora, integre o Proxy ao Cloudscraper da seguinte maneira:
import cloudscraper
# Criar instância do CloudScraper
scraper = cloudscraper.create_scraper()
# Definir o Proxy Bright Data
proxies = {
"http": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335",
"https": "http://<PROXY_USERNAME>:<PROXY_PASSOWRD>@brd.superproxy.io:33335"
}
# Realizar uma solicitação usando o Proxy
response = Scraper.get("https://httpbin.io/ip", proxies=proxies)
# Imprimir a resposta
print(response.text)
Lembre-se de que os Proxies residenciais da Bright Data são alternados automaticamente. Portanto, você receberá um IP diferente cada vez que executar o script.
Et voilà! Integração do Proxy CloudScraper concluída.
Conclusão
Neste tutorial, você viu como usar o Cloudscraper com proxies para obter a máxima eficácia. Você aprendeu o básico sobre integração de proxy com a ferramenta Python Cloudflare-bypass e também explorou técnicas mais avançadas, como Proxy rotativo.
É muito mais fácil obter melhores resultados ao usar servidores Proxy IP de alta qualidade de um provedor de primeira linha como a Bright Data.
A Bright Data controla os melhores servidores Proxy do mundo, atendendo empresas da Fortune 500 e mais de 20.000 clientes. Sua rede mundial de Proxy envolve:
- Proxies de datacenter – Mais de 770.000 IPs de datacenter.
- Proxies residenciais– Mais de 150 milhões de IPs residencialis em mais de 195 países.
- Proxies ISP – Mais de 700.000 IPs de ISP.
No geral, esta é uma das maiores e mais confiáveis redes de Proxy disponíveis.
Crie uma conta gratuita na Bright Data hoje mesmo para experimentar nossos servidores Proxy.





