Neste tutorial sobre truques para extrair sites Next.js, você aprenderá:
- O que é o Next e por que ele é tão popular
- Por que é fácil extrair páginas da web Next.js graças ao funcionamento da hidratação React
- Como aproveitar a hidratação do React para o Scraping de dados
Vamos começar!
O que é o Next.js e como ele funciona?
Next.js é uma estrutura JavaScript construída sobre o React para a criação de sites renderizados no lado do servidor e gerados estaticamente. Ele simplifica o processo de desenvolvimento, fornecendo uma API rica e uma abordagem estruturada para a criação de aplicativos React no lado do servidor.
O Next.js ganhou muita popularidade ao longo dos anos, tornando-se a quinta biblioteca web mais usada, de acordo com o Statista. Isso se deve à sua facilidade de uso, ótimo desempenho, semelhanças com o React, documentação extensa e suporte da comunidade. Não é de se admirar que muitas grandes empresas e startups escolham o Next.js para suas necessidades de desenvolvimento web.
Em um nível elevado, o Next.js funciona recuperando dados no servidor e passando-os para componentes React para criar documentos HTML pré-renderizados. Esse processo melhora o desempenho ao gerar conteúdo HTML no servidor, que pode então ser enviado ao cliente para um carregamento inicial mais rápido da página.
Como tirar proveito da hidratação do React para Scraping de dados
A hidratação preenche a lacuna entre a renderização do lado do servidor e do lado do cliente. Em detalhes, a hidratação do Next.js é o processo pelo qual o documento HTML gerado pelo Next.js é convertido em um aplicativo React do lado do cliente totalmente funcional.
Durante a hidratação — depois que o navegador carrega a página HTML retornada pelo servidor —o React adiciona interatividade à página. Especificamente, ele anexa ouvintes de eventos e lida com o estado nos nós DOM que correspondem aos componentes React renderizados no servidor.
Estas são as etapas necessárias para o React hidratar uma página pré-renderizada:
- Renderização inicial do servidor: o servidor gera o documento HTML com a representação HTML dos componentes React usados na página.
- Execução de JavaScript no lado do cliente: quando o cliente recebe a marcação HTML, ele executa o pacote JavaScript que contém o código React.
- Reconciliação: o React compara o HTML retornado pelo servidor com a representação DOM virtual gerada em tempo real. Saiba mais nos documentos oficiais.
- Hidratação: se os dois forem iguais, o React conclui a renderização adicionando manipuladores de eventos e lidando com o estado, reutilizando o máximo possível do DOM existente.
Para realizar essa operação, o React precisa dos mesmos dados usados pelo servidor para gerar o documento HTML. É por isso que o Next.js adiciona alguns elementos DOM especiais contendo os dados de props à página gerada.
Em alguns sites Next.js, você pode encontrar esses dados no elemento <script> com o ID __NEXT_DATA__. Esse nó DOM especial contém dados no formato JSON que o React usa para hidratação, conforme mostrado a seguir:
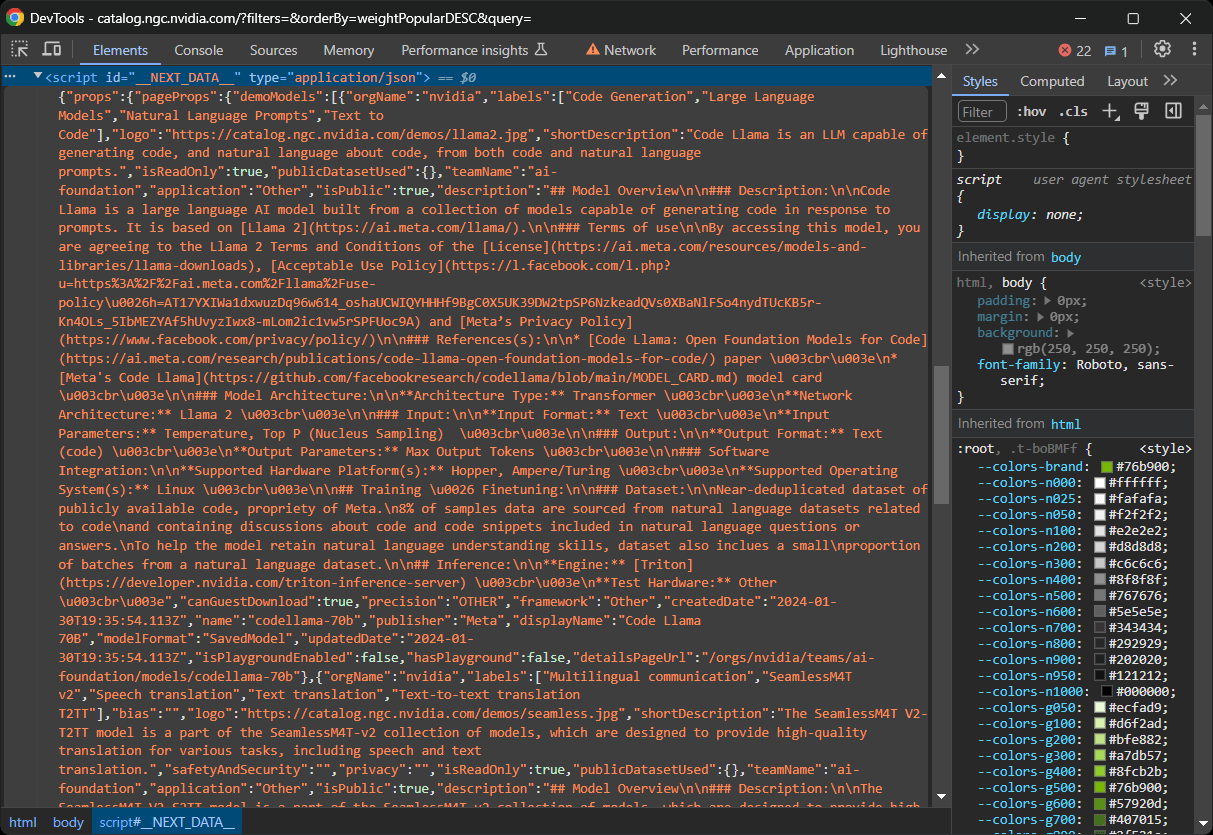
Em sites Next.js recentes que utilizam o novo App Router, os dados de hidratação são armazenados nas chamadas de função self.__next_f.push() em vários nós <script>:
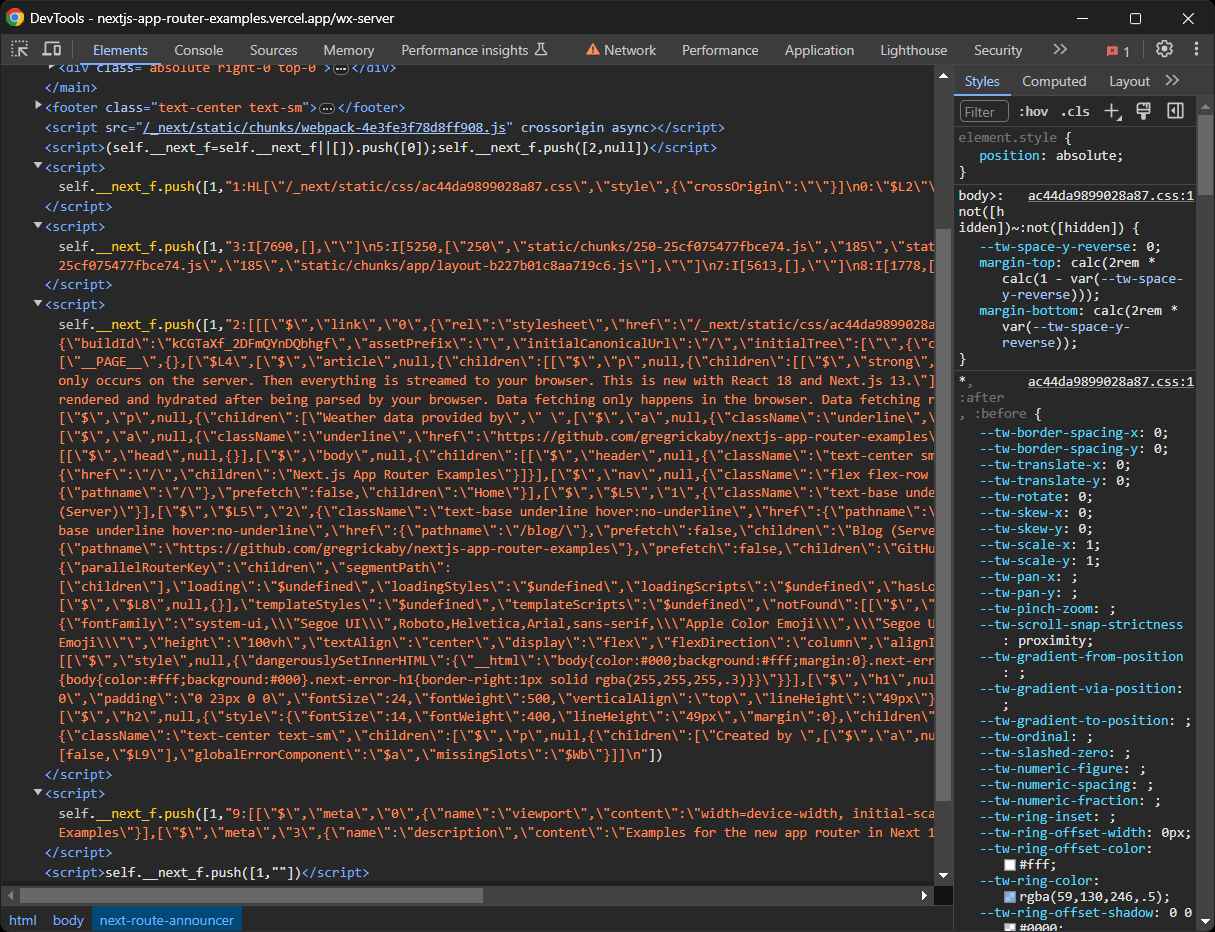
Observe que esses nós podem conter ainda mais dados do que os exibidos no site. Como isso é possível? Porque esses elementos de hidratação armazenam todos os dados da API e do banco de dados recuperados do servidor durante a geração da página e passados para os componentes React. No entanto, nem todos os atributos desses objetos podem realmente ser acessados e usados nos componentes.
Agora, não importa se você realmente entendeu por que esses dados precisam estar lá para o React funcionar. O que importa é que as páginas da web geradas via Next.js contêm os dados a serem renderizados no formato JSON dentro de nós DOM especiais. Como você pode imaginar, isso tem enormes implicações para o Scraping de dados da web com Nex.js!
Raspagem de sites Next.js através dos dados de hidratação
Extrair dados de uma página criada no Next.js é tão fácil que você nem precisa de um script de scraping. O DevTools do seu navegador será suficiente.
Vamos ver agora como aproveitar a hidratação do React para fazer scraping de sites Next.js em segundos!
Extraindo dados de __NEXT_DATA__
Suponha que você verificou que a página de destino a ser raspada foi criada com Next.js (descubra como na pergunta da FAQ).
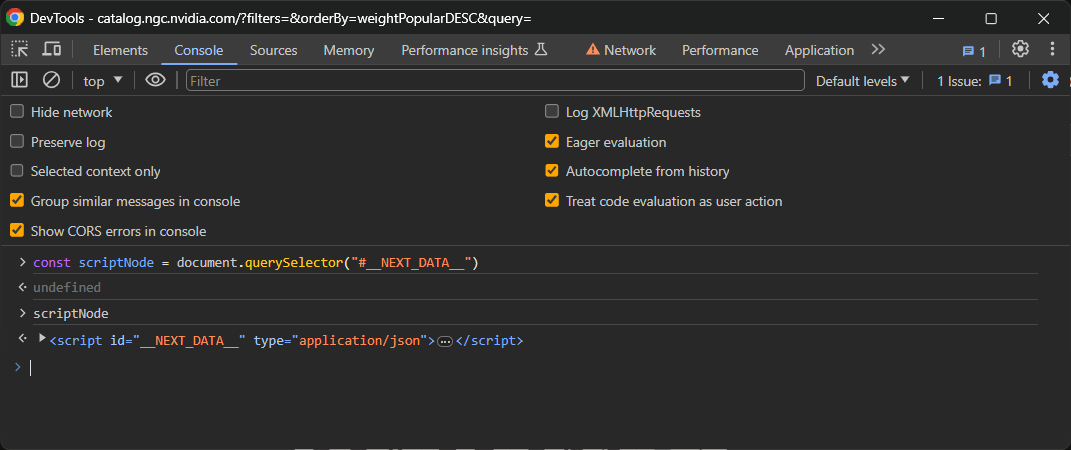
Agora, visite a página no seu navegador, clique com o botão direito do mouse e selecione “Inspect” para acessar o DevTools. Vá para a guia Console e execute a linha JavaScript abaixo para selecionar o elemento <script> desejado:
const scriptNode = document.querySelector("#__NEXT_DATA__")Isso usará a função querySelector() para selecionar o elemento no DOM com ID __NEXT_DATA__ e atribuí-lo à variável scriptNode.
Se você digitar scriptNode no console e pressionar Enter, obterá o nó desejado:
Acesse seu conteúdo HTML interno efaça o Parsing dele como conteúdo JSONcom:
const jsonData = JSON.parse(scriptNode.innerHTML)
Et voilà! O objeto jsonData agora conterá todos os dados que o React usou para renderizar os componentes na página:
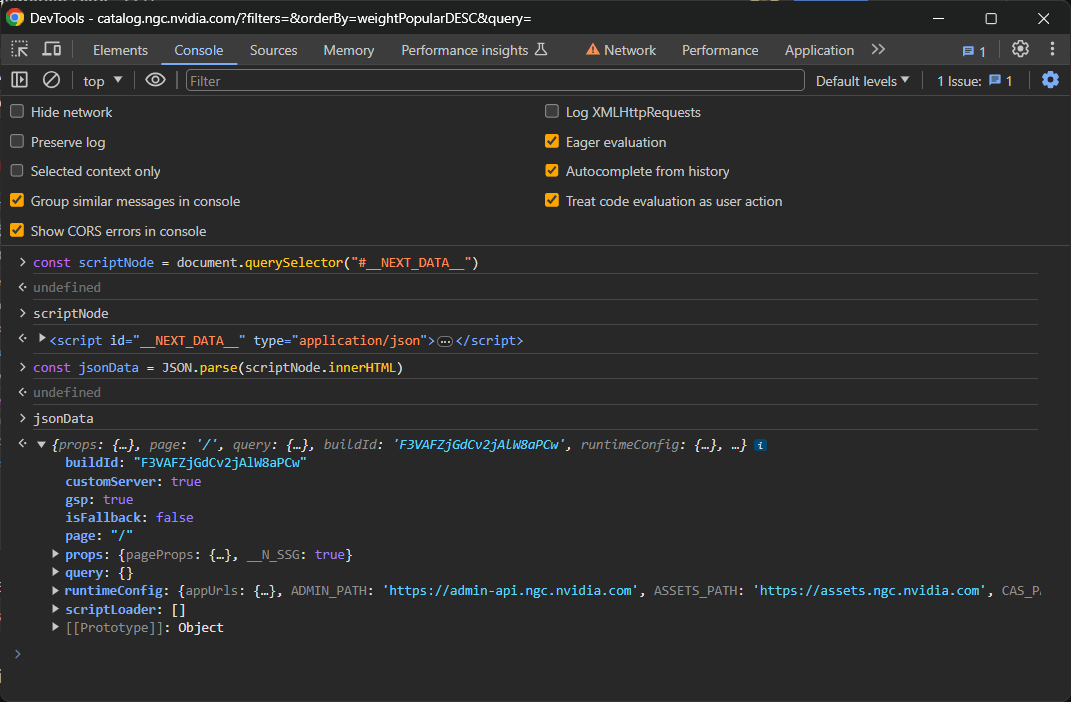
Em detalhes, concentre-se no campo pageProps dentro de props:
jsonData.props.pageProps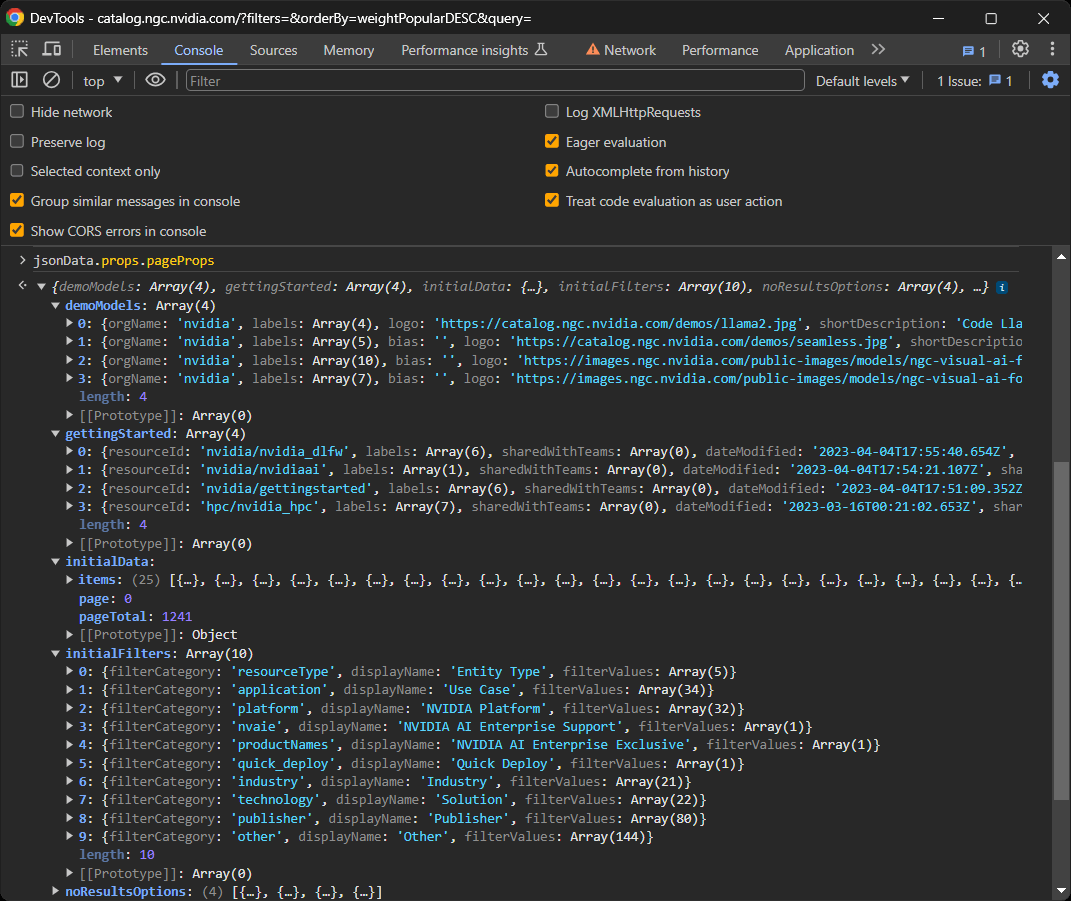
Em seguida, clique com o botão direito do mouse no objeto e selecione a opção “Copiar objeto”:
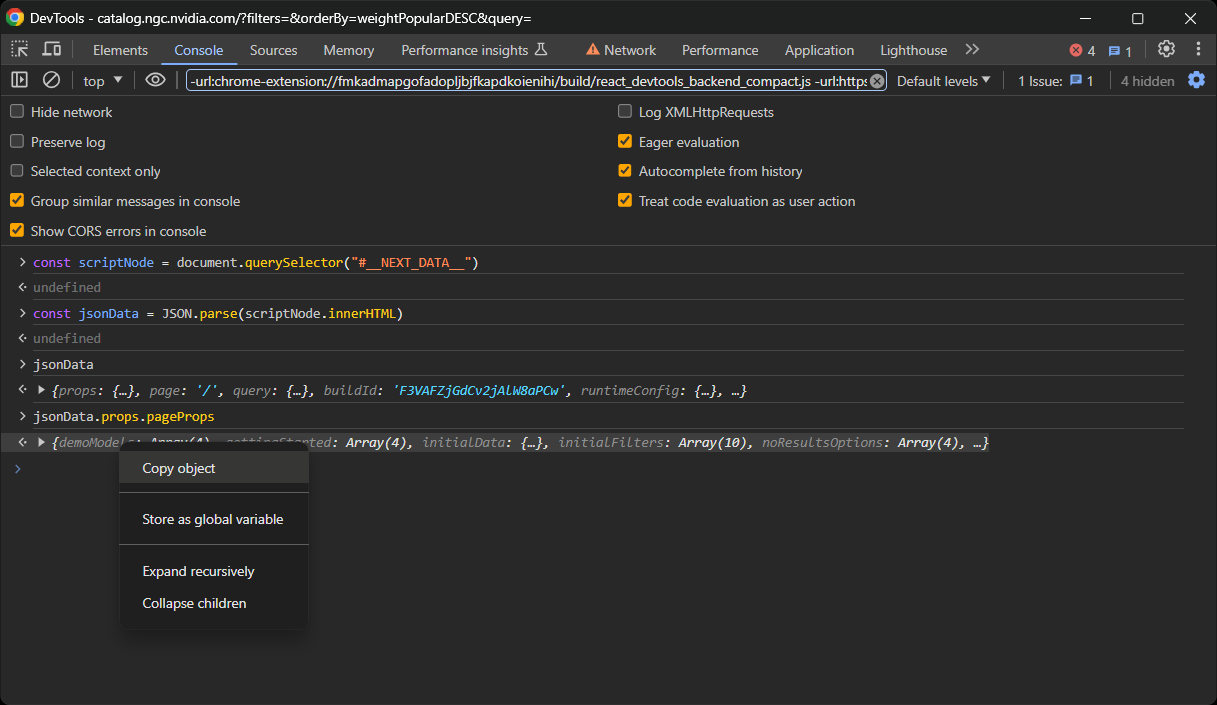
Por último, crie um arquivo data.json e cole o conteúdo desejado nele!
Ótimo! Você acabou de realizar o Scraping de dados da web em um site Next.js em menos de um minuto.
Junte tudo e você obterá este script de scraping do Next.js:
const scriptNode = document.querySelector("#__NEXT_DATA__")
const jsonData = JSON.parse(scriptNode.innerHTML)
jsonData.props.pagePropsRecuperando dados das funções self.__next_f.push
O Next.js 13 introduziu o App Router. Isso muda a maneira como o Next.js entrega os dados ao React para hidratação. Nesse caso, você precisa selecionar todos os nós <script> que contêm a string self.__next_f.push.
Mais uma vez, acesse a página de destino no navegador e abra o console. Execute o comando abaixo para selecionar os nós <script>:
const scriptNodes = document.querySelectorAll("script")querySelectorAll() retorna um objeto NodeList. Converta-o em uma matriz com Array.from() para aplicar o método filter() e obter apenas os nós de interesse:
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))Agora, o hydrationScriptNodes conterá todos os elementos <script> de hidratação na página:
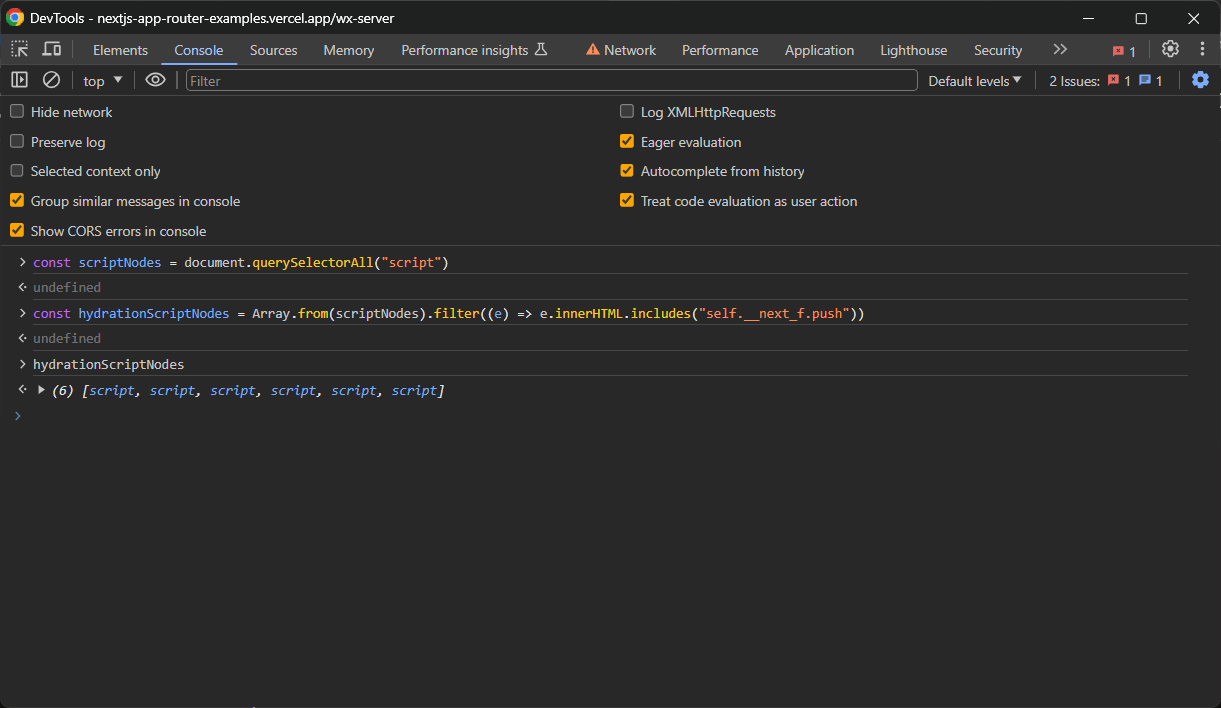
No entanto, geralmente você deseja apenas o nó que possui o atributo initialTree. É aqui que todos os dados de hidratação de interesse são armazenados:
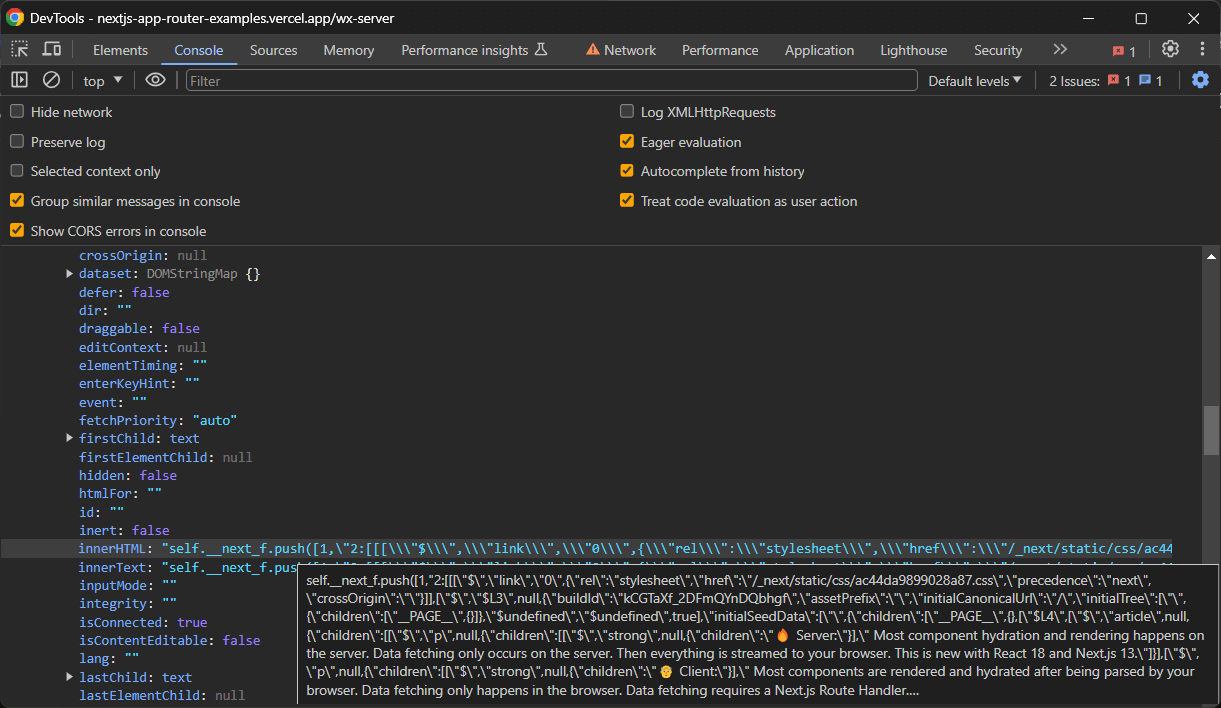
Selecione-o com:
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))Em seguida, extraia os dados de interesse com:
scriptNode.innerHTMLObserve que os dados recuperados contêm as informações de interesse, mas requerem Parsing adicional. Você pode convertê-los para um formato mais legível com algumas linhas extras.
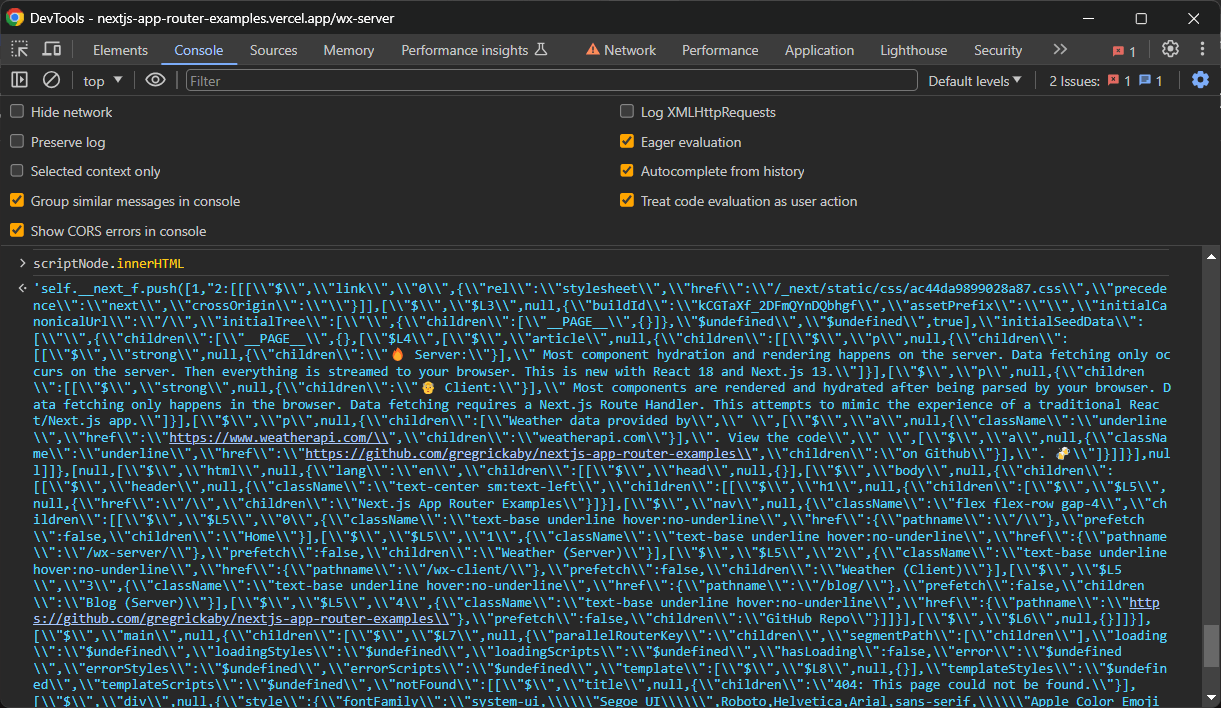
Desta vez, o script de scraping do Next.js é:
const scriptNodes = document.querySelectorAll("script")
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))
scriptNode.innerHTMLParabéns! Raspagem de sites Next.js nunca foi tão fácil!
Limitações desta abordagem de scraping do Next.js
Embora essa abordagem de scraping baseada nos dados de hidratação do React seja rápida e eficaz, ela tem algumas limitações. São elas:
- Dados parciais: os nós especiais
<SCRIPT>adicionados pelo Next.js contêm apenas os dados recuperados pelo servidor e passados para os componentes React durante a hidratação. Isso pode não ser todos os dados contidos na página. Isso ocorre porque os componentes React podem ter valores codificados ou recuperar outros dados dinamicamente via AJAX. Nesse caso, você precisa realizar o Scraping de dados da web com uma ferramenta de automação do navegador. - Parsing extra necessário:
self.__next_f.pushenvolve dados em um formato proprietário, e analisá-los corretamente nem sempre é fácil. - Requer operações manuais: a menos que você traduza os scripts escritos acima em scripts de scraping em JavaScript, Python ou linguagem semelhante e integre a lógica para exportação de dados, você deve exportar os dados manualmente para um arquivo de texto. Saiba mais em nosso guia de Scraping de dados com JavaScript e Node.js.
Conclusão
Neste artigo, você aprendeu o que é Next.js, por que é uma das tecnologias mais utilizadas no mundo para a construção de sites e como extrair dados dele. Em particular, você percebeu que ele depende da hidratação React e o que isso implica. Por causa disso, as páginas HTML retornadas pelo servidor já contêm todos os dados de que você precisa (e até mesmo no formato JSON!). Isso torna o Scraping de dados de sites Next.js muito fácil.
O verdadeiro problema é outro: ser bloqueado por tecnologias anti-bot. Esses sistemas podem detectar e bloquear seu script de extração automatizado. Felizmente, a Bright Data tem várias soluções eficazes para você:
- Web Scraper IDE: um IDE em nuvem para criar web scrapers que podem contornar e evitar automaticamente quaisquer bloqueios.
- Web Scraper API: acesse dados estruturados da web programaticamente com facilidade, com 99,99% de tempo de atividade e escalabilidade ilimitada.
- Navegador de scraping: um navegador controlável baseado em nuvem que oferece recursos de renderização JavaScript enquanto lida com CAPTCHAs, impressão digital do navegador, novas tentativas automatizadas e muito mais para você. Ele se integra às bibliotecas de navegador de automação mais populares, como Playwright e Puppeteer.
- Web Unlocker: uma API de desbloqueio que pode retornar perfeitamente o HTML bruto de qualquer página, contornando quaisquer medidas anti-scraping.
Não quer lidar com Scraping de dados, mas ainda está interessado em dados online? Explore os Conjuntos de dados prontos para uso da Bright Data!
Perguntas frequentes
É possível ocultar ou remover __NEXT_DATA__ do DOM no Next.js?
Não, você não pode remover ou ocultar isso. Se você decidir remover o elemento _NEXT_DATA_ <script> do DOM, o React não poderá hidratar. Como os dados nesse script são necessários para que o React funcione corretamente, você não pode removê-los sem esperar algum mau funcionamento ou degradação da funcionalidade. Leia a discussão no GitHub dedicada a este tópico.
É possível remover as chamadasself.__next_f.push do DOM?
Não, você não pode remover as chamadas self.__next_f.push nos nós <script> adicionados pelo Next.js. Esses elementos DOM são adicionados pelo servidor para permitir que o aplicativo React do lado do cliente hidrate e funcione conforme o esperado. Para obter mais detalhes, confira a discussão no GitHub dedicada a esse tópico.
Como saber se um site foi criado no Next.js?
Existem algumas maneiras de saber se um site foi criado com o Next.js. Primeiro, procure o cabeçalho X-Powered-By definido por padrão por algumas versões do Next.js:
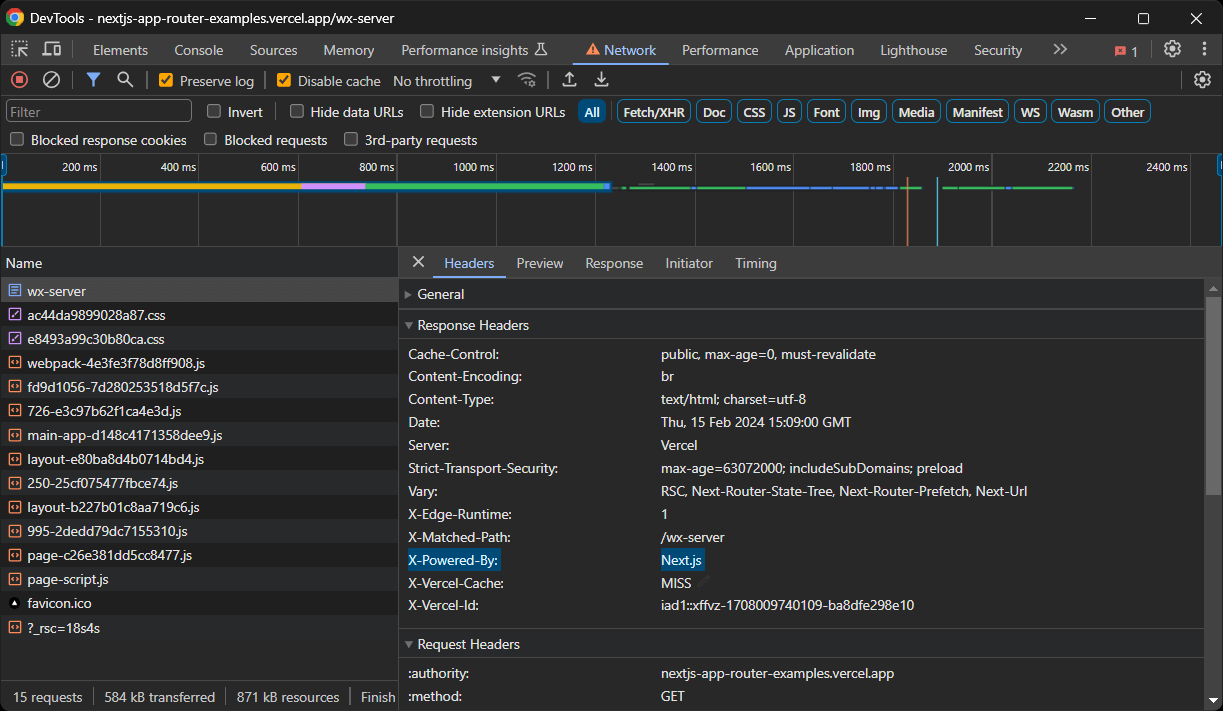
Caso contrário, verifique se o DOM contém um nó <script id="__NEXT_DATA__" ... > ou alguns nós <script>self.__next_f.push(...)</script>.
O Next.js é a única tecnologia que depende da hidratação do React?
Não, o Next.js não é a única tecnologia que depende da hidratação do React. Outros geradores de renderização do lado do servidor (SSR), como o Gatsby, também utilizam a hidratação do React para converter HTML renderizado pelo servidor em aplicativos React interativos no lado do cliente. Esse processo é uma abordagem comum em SSR com React e não se limita ao Next.js.