

Este tutorial abordará:
- Porquê raspar Yelp?
- Bibliotecas e ferramentas de raspagem de Yelp
- Raspagem de dados comerciais de Yelp com Beautiful Soup
Porquê raspar Yelp?
Existem várias razões pelas quais as empresas raspam Yelp. Estas incluem:
- Obter acesso a dados comerciais abrangentes: Fornece uma grande quantidade de informações sobre empresas locais, incluindo avaliações, classificações, informações de contato e muito mais.
- Obter informações sobre as opiniões dos clientes: É conhecido pelos seus comentários de usuários, proporcionando um tesouro de informações sobre as opiniões e experiências dos clientes.
- Efetuar análises competitivas e benchmarking: Oferece informações valiosas sobre o desempenho, os pontos fortes, os pontos fracos e o sentimento dos clientes dos seus concorrentes.
Existem plataformas semelhantes, mas Yelp é a escolha preferida para a raspagem de dados devido a:
- Sua vasta base de usuários
- Diversas categorias de empresas
- Reputação bem estabelecida
Os dados extraídos de Yelp podem ser valiosos para estudos de mercado, análise da concorrência, análise de sentimentos e tomada de decisões. Essas informações também o ajudam a identificar áreas a melhorar, a afinar as suas ofertas e a manter-se à frente da concorrência.
Bibliotecas e ferramentas de raspagem de Yelp
Python é amplamente considerado como uma excelente linguagem para a raspagem da web devido à sua natureza fácil de utilizar, à sintaxe simples e à vasta gama de bibliotecas. É por isso que é a linguagem de programação recomendada para a raspagem de Yelp. Para saber mais sobre isso, reveja nosso guia detalhado sobre como fazer raspagem da web com Python.
O passo seguinte consiste em selecionar as bibliotecas de raspagem adequadas a partir da vasta gama de opções disponíveis. Para tomar uma decisão informada, deve começar por explorar a plataforma num navegador web. Ao inspecionar as chamadas AJAX feitas pelas páginas web, descobrirá que a maioria dos dados está incorporada nos documentos HTML recuperados do servidor.
Isto implica que um simples cliente HTTP para efetuar pedidos ao servidor, combinado com um analisador HTML, será suficiente para a tarefa. Eis por que deve optar por:
- Requests: A biblioteca de cliente HTTP mais popular para Python. Simplifica o processo de envio de pedidos HTTP e o tratamento das respostas correspondentes.
- Beautiful Soup: Uma biblioteca abrangente de análise de HTML e XML amplamente utilizada para raspagem da web. Fornece métodos robustos para navegar e extrair dados do DOM.
Graças a Requests e a Beautiful Soup, é possível raspar Yelp usando Python. Vamos entrar nos pormenores de como realizar esta tarefa!
Raspagem de dados comerciais de Yelp com Beautiful Soup
Siga este tutorial passo a passo e saiba como criar um raspador de Yelp.
Passo 1: Configuração do projeto em Python
Antes de começar, é necessário certificar-se de que possui:
- Python 3+ instalado no seu computador: Descarregue o instalador, execute-o e siga as instruções.
- Um IDE de Python à sua escolha: Visual Studio Code com a extensão Python ou PyCharm Community Edition são ambos adequados.
Primeiro, crie uma pasta yelp-scraper e inicialize-a como um projeto em Python com um ambiente virtual com:
mkdir yelp-scrapernncd yelp-scrapernnpython -m venv env
No Windows, execute o comando abaixo para ativar o ambiente:
Your Code Here...
Em seguida, adicione um ficheiro scraper.py contendo a linha abaixo na pasta do projeto:
print('Hello, World!')
Este é o script de Python mais fácil. Neste momento, apenas imprime “Hello, World!” (Olá, mundo!), mas em breve irá conter a lógica para raspar Yelp.
Pode iniciar o raspador com:
python scraper.py
Deve imprimir no terminal:
Hello, World!
Exatamente o que se esperava. Agora que sabe que tudo funciona, abra a pasta do projeto no seu IDE de Python.
Ótimo, prepare-se para escrever algum código de Python!
Passo 2: Instalar as bibliotecas de raspagem
Agora tem de adicionar as bibliotecas necessárias para efetuar a raspagem da web às dependências do projeto. No ambiente virtual ativado, execute o seguinte comando para instalar Beautiful Soup e Requests:
pip install beautifulsoup4 requests
Limpe o ficheiro scraper.py e, em seguida, adicione estas linhas para importar os pacotes:
import requestsnnfrom bs4 import BeautifulSoupnn# scraping logic...
Certifique-se de que o seu IDE de Python não reporta erros. Poderá receber alguns avisos devido a importações não utilizadas, mas pode ignorá-los. Está prestes a utilizar essas bibliotecas de raspagem para extrair dados de Yelp.
Passo 3: Identificar e descarregar a página de destino
Navegue no Yelp e identifique a página que pretende raspar. Neste guia, verá como obter dados da lista dos restaurantes italianos mais bem classificados de Nova Iorque:
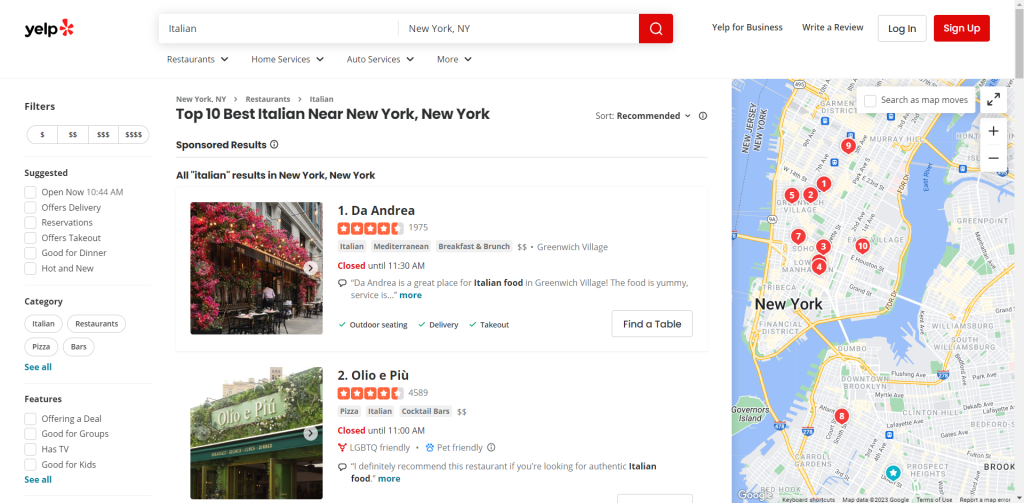
Atribua o URL da página de destino a uma variável:
url = 'https://www.yelp.com/search?find_desc=Italianu0026find_loc=New+York%2C+NY'nnNext, use requests.get() to make an HTTP GET request to that URL:nnpage = requests.get(url)
A página variável conterá agora a resposta produzida pelo servidor.
Especificamente, page.text armazena o documento HTML associado à página web de destino. Pode verificar isso registando-o:
print(page.text)
Isto deve ser impresso:
u003c!DOCTYPE htmlu003eu003chtml lang=u0022en-USu0022 prefix=u0022og: http://ogp.me/ns#u0022 style=u0022margin: 0;padding: 0; border: 0; font-size: 100%; font: inherit; vertical-align: baseline;u0022u003eu003cheadu003eu003cscriptu003edocument.documentElement.className=document.documentElement.className.replace(no-j/,u0022jsu0022);u003c/scriptu003eu003cmeta http-equiv=u0022Content-Typeu0022 content=u0022text/html; charset=UTF-8u0022 /u003eu003cmeta http-equiv=u0022Content-Languageu0022 content=u0022en-USu0022 /u003eu003cmeta name=u0022viewportu0022 content=u0022width=device-width, initial-scale=1, shrink-to-fit=nou0022u003eu003clink rel=u0022mask-iconu0022 sizes=u0022anyu0022 href=u0022https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/b2bb2fb0ec9c/assets/img/logos/yelp_burst.svgu0022 content=u0022#FF1A1Au0022u003eu003clink rel=u0022shortcut iconu0022 href=u0022https://s3-media0.fl.yelpcdn.com/assets/srv0/yelp_large_assets/dcfe403147fc/assets/img/logos/favicon.icou0022u003eu003cscriptu003e window.ga=window.ga||function(){(ga.q=ga.q||[]).push(arguments)};ga.l=+new Date;window.ygaPageStartTime=new Date().getTime();u003c/scriptu003eu003cscriptu003ennu003c!u002du002d Omitted for brevity... u002du002du003e
Perfeito! Vamos aprender a analisá-lo para obter dados a partir dele.
Passo 4: Analisar o conteúdo HTML
Alimentar o conteúdo HTML recuperado pelo servidor para o construtor BeautifulSoup() para o analisar:
soup = BeautifulSoup(page.text, 'html.parser')
A função recebe dois argumentos:
- A cadeia que contém o HTML.
- O analisador que a Beautiful Soup utilizará para analisar o conteúdo.
“html.parser” é o nome do analisador HTML incorporado no Python.
BeautifulSoup() devolverá o conteúdo analisado como uma estrutura de árvore explorável. Em particular, a variável soup expõe métodos úteis para selecionar elementos da árvore DOM. Os mais populares são:
- find(): Retorna o primeiro elemento HTML que corresponde à estratégia do seletor passada como parâmetro.
- find_all(): Devolve a lista de elementos HTML que correspondem à estratégia do seletor de entrada.
- select_one(): Retorna o primeiro elemento HTML que corresponde ao seletor CSS passado como parâmetro.
- select(): Retorna a lista de elementos HTML que correspondem ao seletor CSS de entrada.
Fantástico! Em breve, os utilizará para extrair os dados desejados de Yelp.
Passo 5: Familiarizar-se com a página
Para conceber uma estratégia de seleção eficaz, é necessário, em primeiro lugar, familiarizar-se com a estrutura da página web de destino. Abra-a no seu navegador e comece a explorá-la.
Clique com o botão direito do rato num elemento HTML da página e selecione “Inspecionar” para abrir as ferramentas de desenvolvimento:
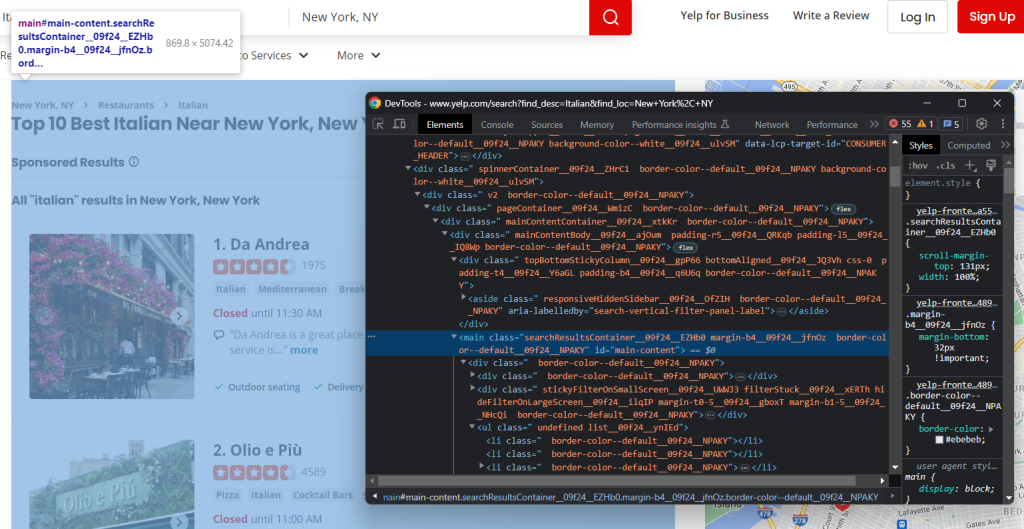
Verificará imediatamente que o sítio se baseia em classes CSS que parecem ser geradas aleatoriamente no momento da criação. Como podem mudar a cada implementação, não deve basear os seus seletores CSS nelas. Esta é uma informação essencial para criar um raspador eficaz.
Se analisa o DOM, verá também que os elementos mais importantes têm atributos HTML distintos. Assim, a sua estratégia de seleção deve basear-se neles.
Continue a inspecionar a página nas ferramentas de desenvolvimento até se sentir preparado para a raspar com Python!
Passo 6: Extrair os dados comerciais
O objetivo aqui é extrair informações comerciais de cada cartão na página. Para manter o registo destes dados, é necessária uma estrutura de dados para os armazenar:
items = []
Primeiro, inspecione um elemento HTML do cartão:
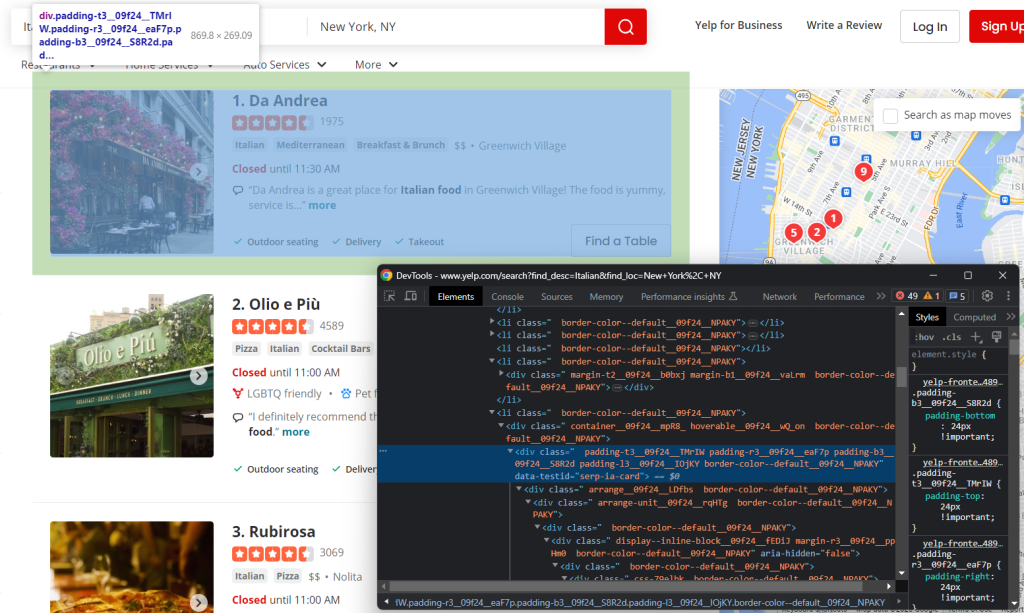
Note que pode selecioná-los a todos com:
html_item_cards = soup.select('[data-testid=u0022serp-ia-cardu0022]')
Itere sobre eles e prepare o seu script para:
- Extrair dados de cada um deles.
- Guardá-lo num item do dicionário de Python.
- Adicioná-lo aos itens.
for html_item_card in html_item_cards:nn item = {}nn # scraping logic...nn items.append(item)
É momento de implementar a lógica de raspagem!
Inspecione o elemento de imagem:
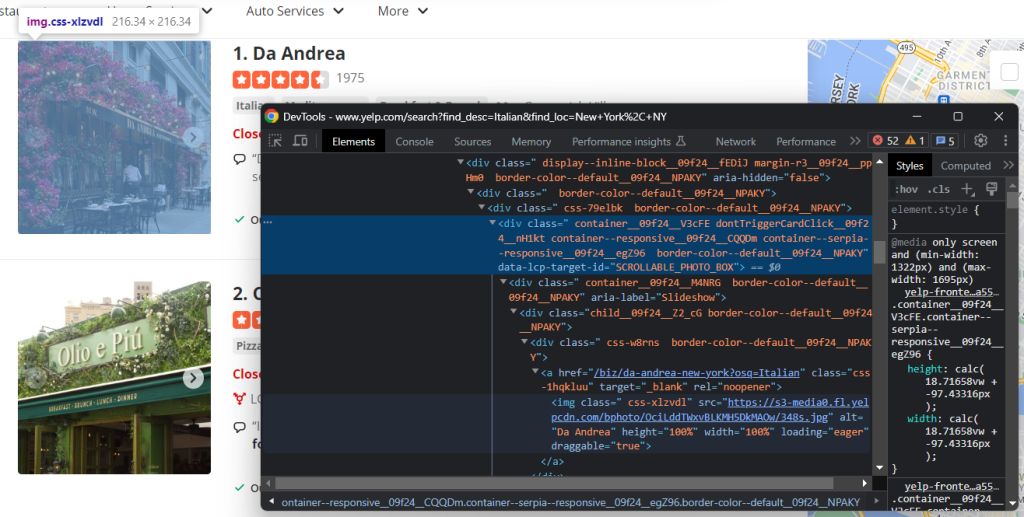
Recupere o URL da imagem da empresa com:
image = html_item_card.select_one('[data-lcp-target-id=u0022SCROLLABLE_PHOTO_BOXu0022] img').attrs['src']
Depois de obter um elemento com select_one(), pode aceder ao seu atributo HTML através do membro attrs.
Outras informações úteis a recuperar são o título e o URL da página de pormenor da empresa:
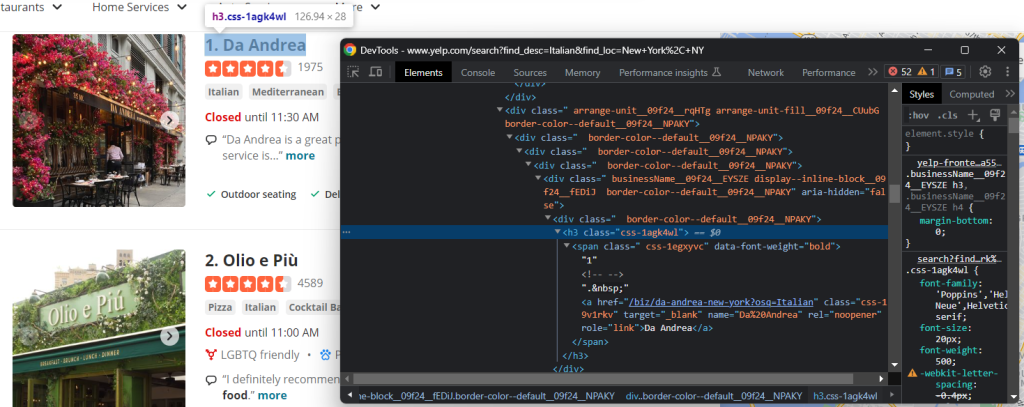
Como pode ver, pode obter ambos os campos de dados a partir do nó h3 a:
name = html_item_card.select_one('h3 a').textnnurl = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']
O atributo text devolve o conteúdo de texto no elemento atual e em todos os seus secundários. Como algumas ligações são relativas, pode ser necessário adicionar o URL de base para as completar.
Um dos dados mais importantes de Yelp é a taxa de avaliação dos usuários:
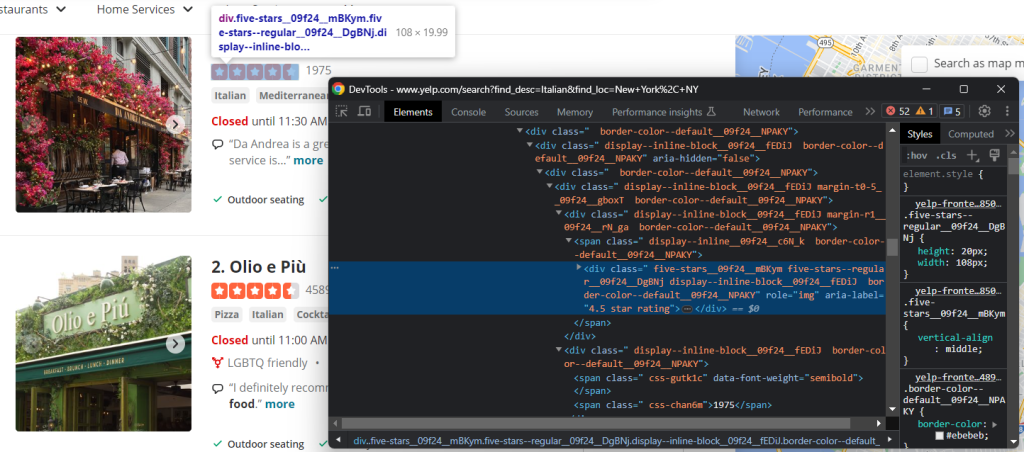
Neste caso, não existe uma forma fácil de o conseguir, mas é possível atingir o objetivo:
html_stars_element = html_item_card.select_one('[class^=u0022five-starsu0022]')nnstars = html_stars_element.attrs['aria-label'].replace(' star rating', '')nnreviews = html_stars_element.parent.parent.next_sibling.text
Repare na utilização da função Python replace() para limpar a cadeia de caracteres e obter apenas os dados relevantes.
Inspecione também as etiquetas e os elementos da gama de preços:
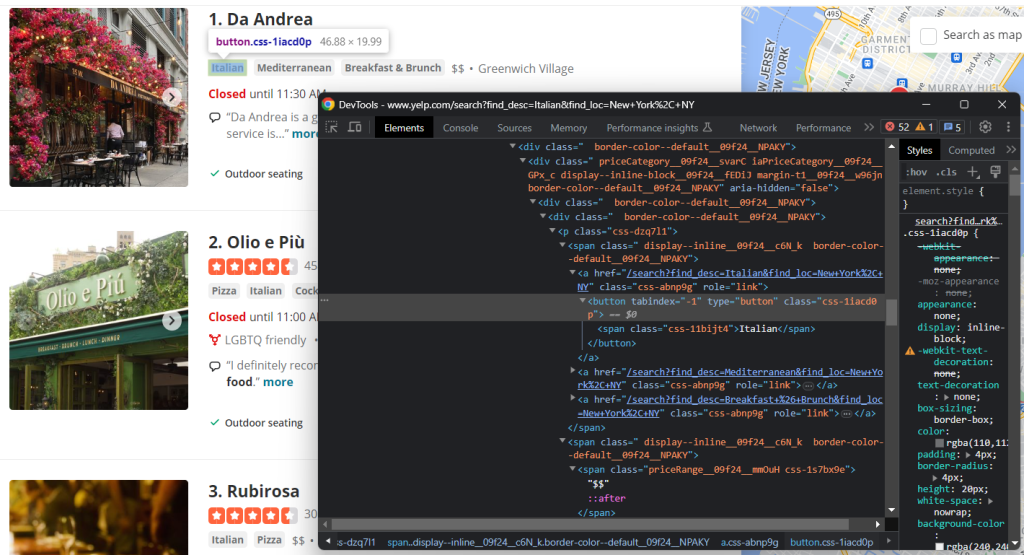
Para coletar todas as cadeias de etiquetas, é necessário selecioná-las todas e iterar sobre elas:
tags = []nnhtml_tag_elements = html_item_card.select('[class^=u0022priceCategoryu0022] button')nnfor html_tag_element in html_tag_elements:nn tag = html_tag_element.textnn tags.append(tag)
Em vez disso, é muito mais fácil obter a indicação opcional do intervalo de preços:
price_range_html = html_item_card.select_one('[class^=u0022priceRangeu0022]')nn# since the price range info is optionalnnif price_range_html is not None:nn price_range = price_range_html.text
Por último, deve também raspar os serviços oferecidos pelo restaurante:
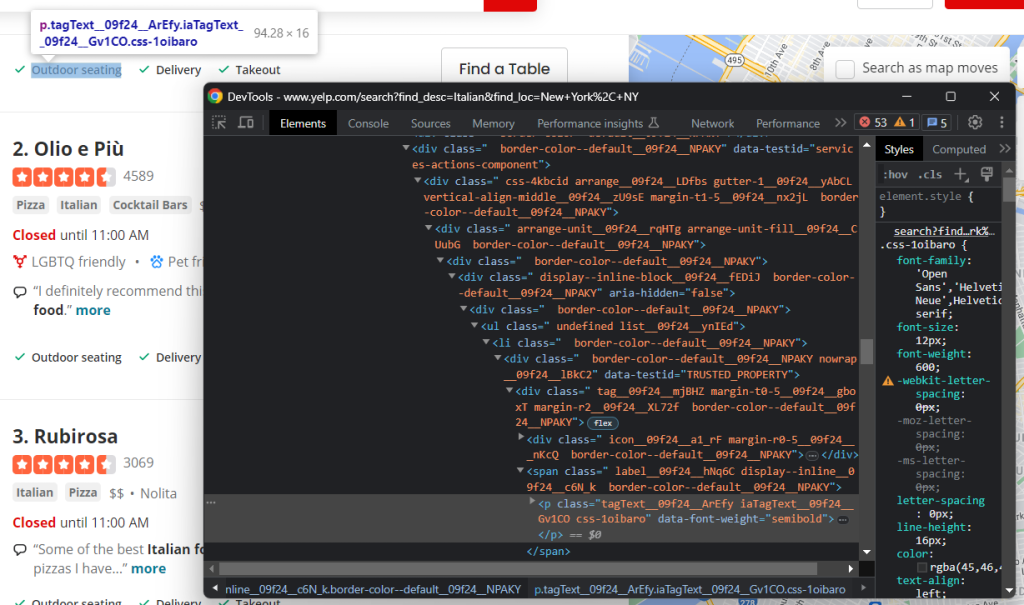
Mais uma vez, é necessário iterar sobre cada um dos nós:
services = []nnhtml_service_elements = html_item_card.select('[data-testid=u0022services-actions-componentu0022] p[class^=u0022tagTextu0022]')nnfor html_service_element in html_service_elements:nn service = html_service_element.textnn services.append(service)
Muito bem! Acabou de implementar a lógica de raspagem.
Adicione as variáveis de dados extraídos ao dicionário:
item['name'] = namennitem['image'] = imagennitem['url'] = urlnnitem['stars'] = starsnnitem['reviews'] = reviewsnnitem['tags'] = tagsnnitem['price_range'] = price_rangennitem['services'] = services
Utilize print(item) para se certificar de que o processo de extração de dados funciona como pretendido. No primeiro cartão, obterá:
{'name': 'Olio e Più', 'image': 'https://s3-media0.fl.yelpcdn.com/bphoto/CUpPgz_Q4QBHxxxxDJJTTA/348s.jpg', 'url': 'https://www.yelp.com/biz/olio-e-pi%C3%B9-new-york-7?osq=Italian', 'stars': '4.5', 'reviews': '4588', 'tags': ['Pizza', 'Italian', 'Cocktail Bars'], 'price_range': '$$', 'services': ['Outdoor seating', 'Delivery', 'Takeout']}
Espetacular! Está mais perto do seu objetivo!
Passo 7: Implementar a lógica de rastejamento
Não se esqueça de que as empresas são apresentadas aos usuários numa lista paginada. Acabou de ver como extrair uma única página, mas e se quisesse obter todos os dados? Para o fazer, terá de integrar o rastejamento da web no raspador de dados de Yelp.
Primeiro, defina algumas estruturas de dados de suporte no topo do seu script:
visited_pages = []nnpages_to_scrape = ['https://www.yelp.com/search?find_desc=Italianu0026find_loc=New+York%2C+NY']n
visited_pages will contain the URLs of the pages scraped, while pages_to_scrape the next ones to visit.nnCreate a while loop that terminates when there are no longer pages to scrape or after a specific number of iterations:nnnlimit = 5 # in production, you can remove itnni = 0nnwhile len(pages_to_scrape) != 0 and i u003c limit:nn # extract the first page from the arraynn url = pages_to_scrape.pop(0)nn # mark it as u0022visitedu0022nn visited_pages.append(url)nn # download and parse the pagenn page = requests.get(url)nn soup = BeautifulSoup(page.text, 'html.parser')nn # scraping logic...nn # crawling logic...nn # increment the page counternn i += 1
Cada iteração irá remover uma página da lista, raspá-la, descobrir novas páginas e adicioná-las à fila. O limite simplesmente impede que o raspador funcione para sempre.
Resta apenas implementar a lógica de rastejamento. Inspecione o elemento de paginação HTML:

É composto por vários links. Recolha-os todos e adicione os recém-descobertos a pages_to_visit com:
pagination_link_elements = soup.select('[class^=u0022pagination-linksu0022] a')nnfor pagination_link_element in pagination_link_elements:nn pagination_url = pagination_link_element.attrs['href']nn # if the discovered URL is newnn if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:nn pages_to_scrape.append(pagination_url)
Maravilhoso! Agora, o seu raspador passará automaticamente por todas as páginas de paginação.
Passo 8: Exportar os dados raspados para CSV
A etapa final consiste em tornar os dados recolhidos mais fáceis de partilhar e ler. A melhor maneira de o fazer é exportá-los para um formato legível por humanos, como o CSV:
import csvnn# ...nn# initialize the .csv output filennwith open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:nn writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)nn writer.writeheader()nn # populate the CSV filenn for item in items:nn # transform array fields from u0022['element1', 'element2', ...]u0022nn # to u0022element1; element2; ...u0022nn csv_item = {}nn for key, value in item.items():nn if isinstance(value, list):nn csv_item[key] = '; '.join(str(e) for e in value)nn else:nn csv_item[key] = valuenn # add a new recordnn writer.writerow(csv_item)
Crie um ficheiro restaurants.csv com open(). Em seguida, utilize DictWriter e alguma lógica personalizada para o preencher. Uma vez que o pacote csv vem da Biblioteca Padrão de Python, não é necessário instalar dependências adicionais.
Ótimo! Começou com dados em bruto contidos numa página web e agora tem dados CSV semiestruturados. É momento de analisar todo o raspador de Yelp com Python.
Passo 9: Juntar tudo
Aqui está o aspeto do script scraper.py completo:
import requestsnnfrom bs4 import BeautifulSoupnnimport csvnn# support data structures to implement thenn# crawling logicnnvisited_pages = []nnpages_to_scrape = ['https://www.yelp.com/search?find_desc=Italianu0026find_loc=New+York%2C+NY']nn# to store the scraped datannitems = []nn# to avoid overwhelming Yelp's servers with requestsnnlimit = 5nni = 0nn# until all pagination pages have been visitednn# or the page limit is hitnnwhile len(pages_to_scrape) != 0 and i u003c limit:nn # extract the first page from the arraynn url = pages_to_scrape.pop(0)nn # mark it as u0022visitedu0022nn visited_pages.append(url)nn # download and parse the pagenn page = requests.get(url)nn soup = BeautifulSoup(page.text, 'html.parser')nn # select all item cardnn html_item_cards = soup.select('[data-testid=u0022serp-ia-cardu0022]')nn for html_item_card in html_item_cards:nn # scraping logicnn item = {}nn image = html_item_card.select_one('[data-lcp-target-id=u0022SCROLLABLE_PHOTO_BOXu0022] img').attrs['src']nn name = html_item_card.select_one('h3 a').textnn url = 'https://www.yelp.com' + html_item_card.select_one('h3 a').attrs['href']nn html_stars_element = html_item_card.select_one('[class^=u0022five-starsu0022]')nn stars = html_stars_element.attrs['aria-label'].replace(' star rating', '')nn reviews = html_stars_element.parent.parent.next_sibling.textnn tags = []nn html_tag_elements = html_item_card.select('[class^=u0022priceCategoryu0022] button')nn for html_tag_element in html_tag_elements:nn tag = html_tag_element.textnn tags.append(tag)nn price_range_html = html_item_card.select_one('[class^=u0022priceRangeu0022]')nn # this HTML element is optionalnn if price_range_html is not None:nn price_range = price_range_html.textnn services = []nn html_service_elements = html_item_card.select('[data-testid=u0022services-actions-componentu0022] p[class^=u0022tagTextu0022]')nn for html_service_element in html_service_elements:nn service = html_service_element.textnn services.append(service)nn # add the scraped data to the objectnn # and then the object to the arraynn item['name'] = namenn item['image'] = imagenn item['url'] = urlnn item['stars'] = starsnn item['reviews'] = reviewsnn item['tags'] = tagsnn item['price_range'] = price_rangenn item['services'] = servicesnn items.append(item)nn # discover new pagination pages and add them to the queuenn pagination_link_elements = soup.select('[class^=u0022pagination-linksu0022] a')nn for pagination_link_element in pagination_link_elements:nn pagination_url = pagination_link_element.attrs['href']nn # if the discovered URL is newnn if pagination_url not in visited_pages and pagination_url not in pages_to_scrape:nn pages_to_scrape.append(pagination_url)nn # increment the page counternn i += 1nn# extract the keys from the first object in the arraynn# to use them as headers of the CSVnnheaders = items[0].keys()nn# initialize the .csv output filennwith open('restaurants.csv', 'w', newline='', encoding='utf-8') as csv_file:nn writer = csv.DictWriter(csv_file, fieldnames=headers, quoting=csv.QUOTE_ALL)nn writer.writeheader()nn # populate the CSV filenn for item in items:
# transform array fields from u0022['element1', 'element2', ...]u0022nn # to u0022element1; element2; ...u0022nn csv_item = {}nn for key, value in item.items():nn if isinstance(value, list):nn csv_item[key] = '; '.join(str(e) for e in value)nn else:nn csv_item[key] = valuenn # add a new recordnn writer.writerow(csv_item)
Em cerca de 100 linhas de código, é possível construir um rastreador da rede para extrair dados de empresas de Yelp.
Utilizar o raspador com:
python scraper.pypython scraper.py
Aguarde que a execução seja concluída e encontrará o ficheiro restaurants.csv abaixo na pasta raiz do seu projeto:
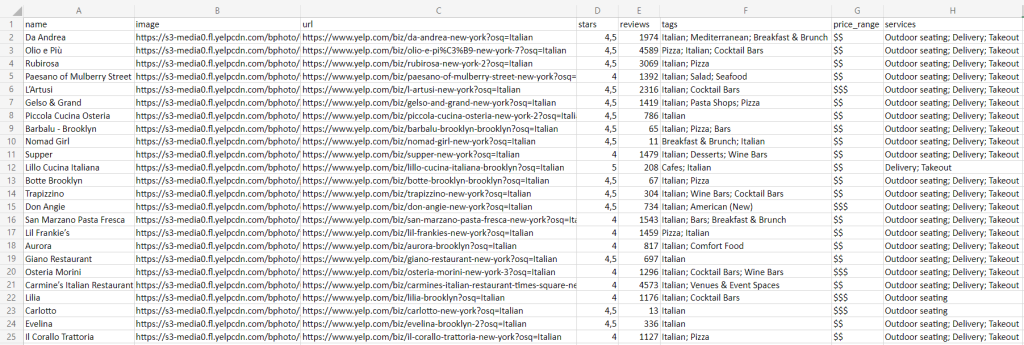
Parabéns! Acabou de aprender a fazer raspagem de Yelp em Python!
Conclusão
Neste guia passo-a-passo, percebeu por que razão Yelp é um dos melhores alvos de raspagem para obter dados de usuários sobre empresas locais. Em pormenor, aprendeu a construir um raspador com Python que pode obter dados de Yelp. Como mostrado aqui, são necessárias apenas algumas linhas de código.
Ao mesmo tempo, os sítios continuam a evoluir e a adaptar a sua IU e estrutura às expectativas em constante mudança dos usuários. O raspador criado aqui funciona hoje, mas pode deixar de ser eficaz amanhã. Evite gastar tempo e dinheiro em manutenção, experimente o nosso raspador de Yelp!
Além disso, não se esqueça de que a maioria dos sítios depende fortemente de JavaScript. Nestes cenários, uma abordagem tradicional baseada num analisador HTML não funcionará. Em vez disso, terá de utilizar uma ferramenta que possa processar JavaScript e lidar com as impressões digitais, CAPTCHAs e tentativas automáticas por você. É exatamente este o objetivo da nossa nova solução, o Navegador de Raspagem!
Não quer lidar com a raspagem de Yelp na web e só quer dados? Compre conjuntos de dados de Yelp






