

Siga este tutorial passo a passo e aprenda a criar um script Python de Scraping de dados do Indeed para recuperar automaticamente dados sobre vagas de emprego.
Este guia abordará:
- Por que coletar dados de vagas na web?
- Bibliotecas e ferramentas para extrair dados do Indeed
- Extraindo dados de vagas de emprego do Indeed com o Selenium
Por que coletar dados de vagas na web?
O scraping de dados de empregos da web é útil por vários motivos, incluindo:
- Pesquisa de mercado: permite que empresas e analistas do mercado de trabalho coletem informações sobre as tendências do setor. Por exemplo, isso envolve quais habilidades estão em alta demanda ou as regiões geográficas que estão experimentando crescimento no mercado de trabalho. Também permite monitorar as atividades de contratação dos concorrentes.
- Otimização da busca e correspondência de vagas: ajuda os candidatos a vagas a pesquisar anúncios de emprego de várias fontes para encontrar vagas que correspondam às suas qualificações e preferências.
- Otimização do recrutamento e dos recursos humanos: apoia o processo de recrutamento, facilitando a contratação e ajudando a compreender as tendências salariais do mercado e os benefícios procurados pelos candidatos.
Assim, os dados de emprego são úteis tanto para empregadores quanto para candidatos a emprego.
Quando se trata de Scrapers de anúncios de emprego, há um aspecto essencial a ser destacado. A plataforma de destino precisa ser pública. Em outros termos, ela deve permitir que mesmo usuários não logados realizem pesquisas de emprego. Isso porque coletar dados sob uma barreira de login pode lhe causar problemas legais.
Isso significa excluir o LinkedIn da equação. Que outras plataformas de emprego restam? Na verdade, uma das principais plataformas de emprego online!
Bibliotecas e ferramentas para scraping do Indeed
Python é considerado uma das melhores linguagens para scraping graças à sua sintaxe, facilidade de uso e rico ecossistema de bibliotecas. Então, vamos em frente. Confira nosso guia sobre Scraping de dados com Python.
Agora você precisa escolher as bibliotecas de extração certas entre as muitas disponíveis. Para tomar uma decisão informada, explore o Indeed em seu navegador. Você notará que a maioria dos dados do site é recuperada após a interação. Isso significa que o site depende muito do AJAX para carregar e atualizar o conteúdo dinamicamente sem usar recargas de página. Para fazer o Scraping de dados da web em um site como esse, você precisa de uma ferramenta capaz de executar JavaScript. Essa ferramenta é o Selenium!
O Selenium torna possível fazer scraping em sites dinâmicos em Python. Ele renderiza sites em um navegador controlável, executando operações conforme você o instrui. Graças ao Selenium, você pode fazer scraping de dados mesmo que o site de destino use JavaScript para renderização ou recuperação de dados.
Aprenda a fazer scraping de anúncios de emprego em sites como o Indeed!
Extraindo dados de vagas de emprego do Indeed com o Selenium
Siga este tutorial passo a passo e veja como criar um script Python para o Scraping de dados do Indeed.
Etapa 1: configuração do projeto
Antes de fazer o Scraping de dados, certifique-se de que você atende a estes pré-requisitos:
- Python 3+ instalado em seu computador: baixe o instalador, clique duas vezes nele e siga o assistente de instalação.
- Um IDE Python de sua escolha: PyCharm Community Edition ou Visual Studio Code com a extensão Python são duas ótimas opções.
Agora você tem tudo o que precisa para configurar um projeto Python!
Abra o terminal e execute os seguintes comandos para:
- Criar uma pasta indeed-scraper
- Entrar nela
- Inicialize-a com um ambiente virtual Python
mkdir indeed-Scraper
cd indeed-Scraper
python -m venv envNo Linux ou macOS, execute o comando abaixo para ativar o ambiente:
./env/bin/activate
No Windows, execute:
envScriptsactivate.ps1
Em seguida, inicialize um arquivo scraper.py contendo a linha abaixo na pasta do projeto:
print("Olá, mundo!")
No momento, ele apenas imprime “Olá, mundo!”, mas em breve conterá a lógica de scraping do Indeed.
Inicie-o para verificar se funciona com:
python Scraper.py
Se tudo correu conforme o planejado, ele deve imprimir esta mensagem no terminal:
Olá, mundo!
Agora que você sabe que o script funciona, abra a pasta do projeto no seu IDE Python.
Muito bem! Prepare-se para escrever algum código Python!
Etapa 2: Instale as bibliotecas de scraping
Como mencionado anteriormente, o Selenium é uma ótima ferramenta quando se trata de Scraping de dados de anúncios de emprego do Indeed. Execute o comando abaixo no ambiente virtual Python ativado para adicioná-lo às dependências do projeto:
pip install selenium
Isso pode demorar um pouco, então seja paciente.
Observe que este tutorial se refere ao Selenium 4.11.2, que vem com recursos de detecção automática de drivers. Se você tiver uma versão mais antiga do Selenium instalada no seu PC, atualize-a com:
pip install selenium -U
Agora, limpe o Scraper.py. Em seguida, importe o pacote e inicialize um Scraper Selenium com:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# configure uma instância controlável do Chrome
# no modo headless
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# lógica de raspagem...
# feche o navegador e libere os recursos
driver.quit()
Este script instancia uma instância do WebDriver para controlar programaticamente uma instância do Chrome. O navegador será aberto em segundo plano no modo headless, o que significa sem GUI. Essa é uma configuração comum para produção. Se você preferir acompanhar as operações executadas pelo script de tarefas de Scraping de dados na página, comente essa opção. Isso é útil no desenvolvimento.
Certifique-se de que seu IDE Python não relate nenhum erro. Ignore os avisos que você possa receber devido às importações não utilizadas. Você está prestes a usar as bibliotecas para extrair dados do repositório do GitHub!
Perfeito! É hora de criar seu Scraper Python para Scraping de dados.
Etapa 3: conecte-se à página da web de destino
Abra o Indded e pesquise as vagas nas quais você está interessado. Neste guia, você verá como extrair vagas remotas para engenheiros de software em Nova York. Lembre-se de que qualquer outra pesquisa de vagas no Indeed servirá. A lógica de extração será a mesma.
Esta é a aparência da página de destino no navegador no momento da redação deste artigo:
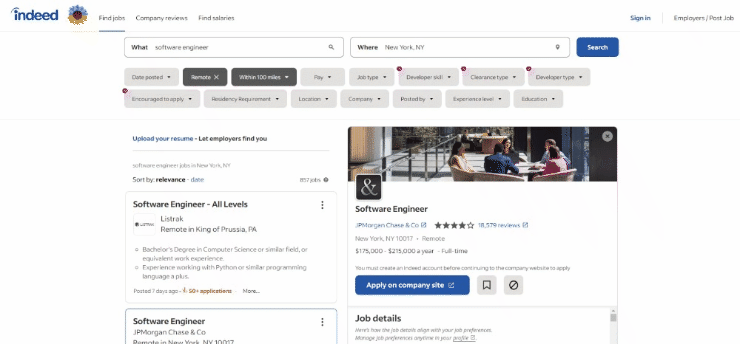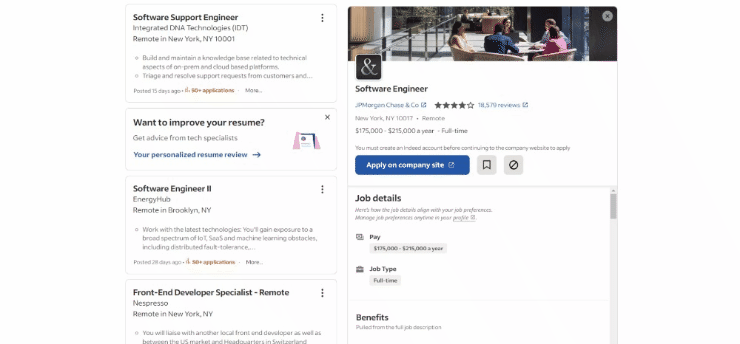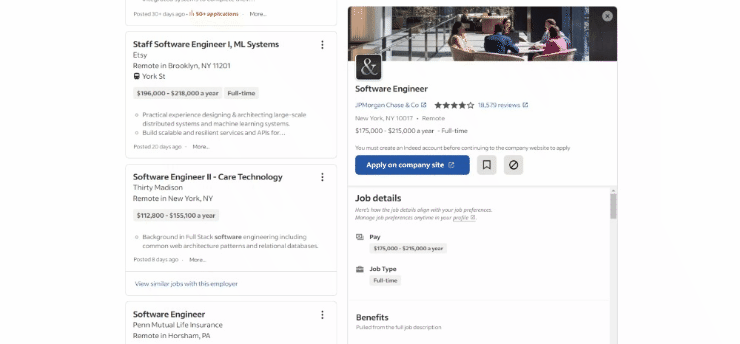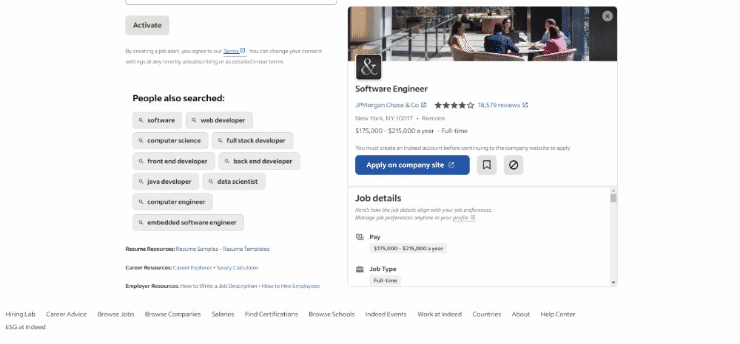
Especificamente, esta é a aparência da URL da página de destino:
https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100
Como você pode ver, é uma URL dinâmica que muda com base em alguns parâmetros de consulta.
Você pode então usar o Selenium para se conectar à página de destino com:
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
A função get() instrui o navegador a visitar a página especificada pela URL passada como parâmetro.
Após abrir a página, você deve definir o tamanho da janela para garantir que todos os elementos fiquem visíveis:
driver.set_window_size(1920, 1080)
Esta é a aparência do seu script de scraping do Indeed até agora:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# configure uma instância controlável do Chrome
# no modo headless
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# definir o tamanho da janela para garantir que as páginas
# não sejam renderizadas no modo responsivo
driver.set_window_size(1920, 1080)
# abrir a página de destino no navegador
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# lógica de scraping...
# fechar o navegador e liberar os recursos
driver.quit()
Comente a opção para ativar o modo headless e execute o script. A janela abaixo será aberta por uma fração de segundo antes de fechar:
Observe o aviso “O Chrome está sendo controlado por um software automatizado”. Isso garante que o Selenium esteja funcionando conforme o esperado.
Etapa 4: familiarize-se com a estrutura da página
Antes de mergulhar na extração, há outra etapa crucial a ser realizada. A extração de dados de um site envolve selecionar elementos HTML e extrair dados deles. Encontrar uma maneira de obter os nós desejados do DOM nem sempre é fácil. É por isso que você deve dedicar algum tempo analisando a estrutura da página para entender como definir uma estratégia de seleção eficaz.
Abra seu navegador e acesse a página de busca de empregos do Indeed. Clique com o botão direito do mouse em qualquer elemento e selecione a opção “Inspect” para abrir o DevTools do seu navegador:
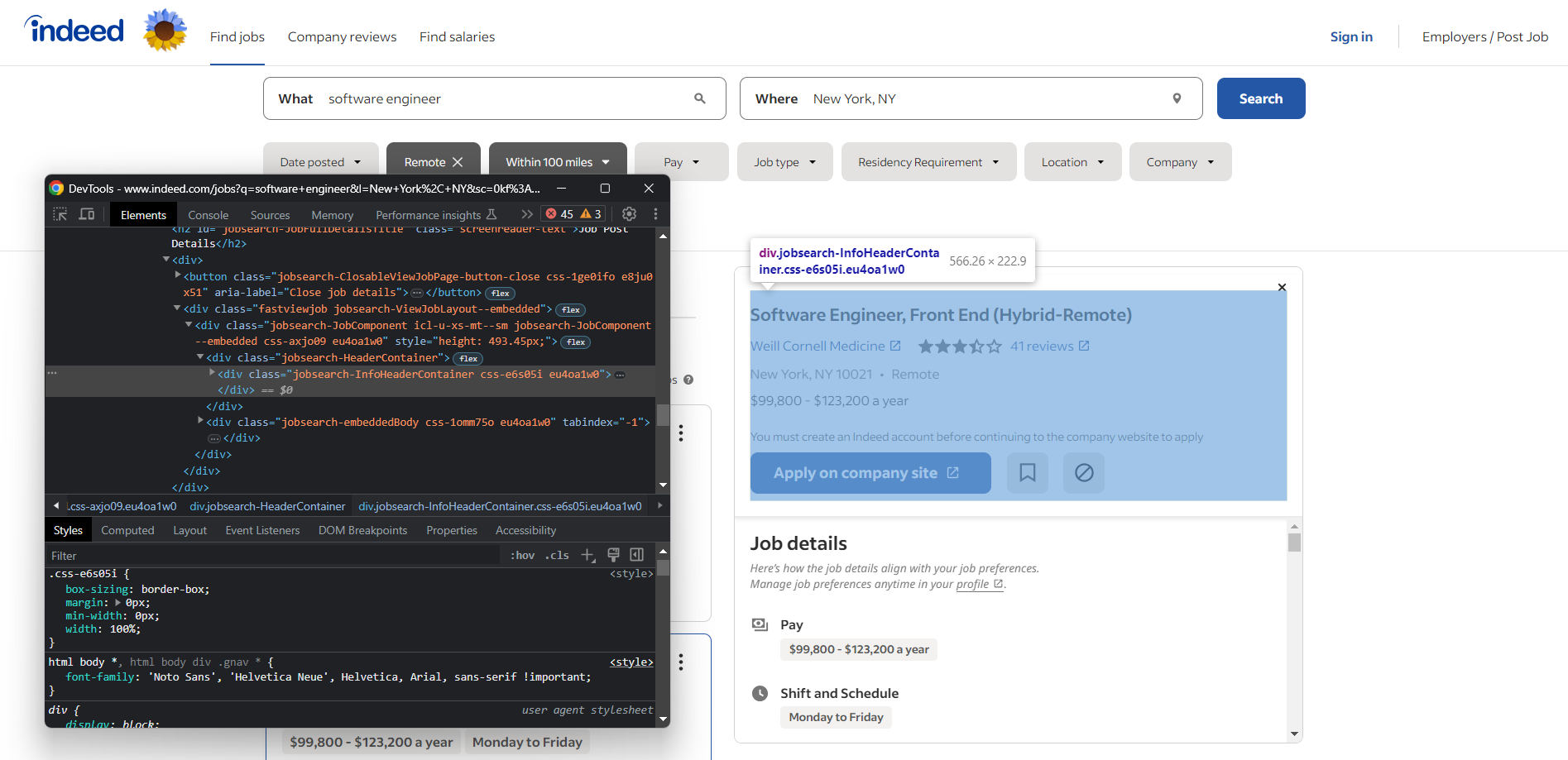
Aqui, você verá que a maioria dos elementos que contêm dados interessantes tem classes CSS como as seguintes:
css-j45z4f,css-1m4cuuf, …e37uo190,eu4oa1w0, …job_f27ade40cc1a3686,job_1a53a17f1faeae92, …
Como eles parecem ser gerados aleatoriamente no momento da compilação, você não deve confiar neles para fazer a extração. Em vez disso, você deve basear a lógica de seleção em classes como:
jobsearch-JobInfoHeader-titledatecardOutline
Ou IDs como:
classificações da empresalink do botão de inscriçãojobDetailsSection
Além disso, observe que alguns nós têm atributos HTML exclusivos:
data-company-namedata-testid
Essas são informações úteis a serem lembradas para trabalhos de Scraping de dados do Indeed. Interaja com a página para estudar como ela reage e quais dados ela mostra. Você perceberá que diferentes vagas de emprego têm diferentes atributos de informação.
Continue inspecionando o site de destino e familiarize-se com sua estrutura DOM até se sentir pronto para prosseguir.
Etapa 5: Comece a extrair os dados de vagas
Uma única página de pesquisa do Indeed envolve várias vagas de emprego. Portanto, você precisa de uma matriz para acompanhar os empregos extraídos da página:
jobs = []Como você deve ter notado na etapa anterior, as vagas de emprego são exibidas em cartões .cardOutline:
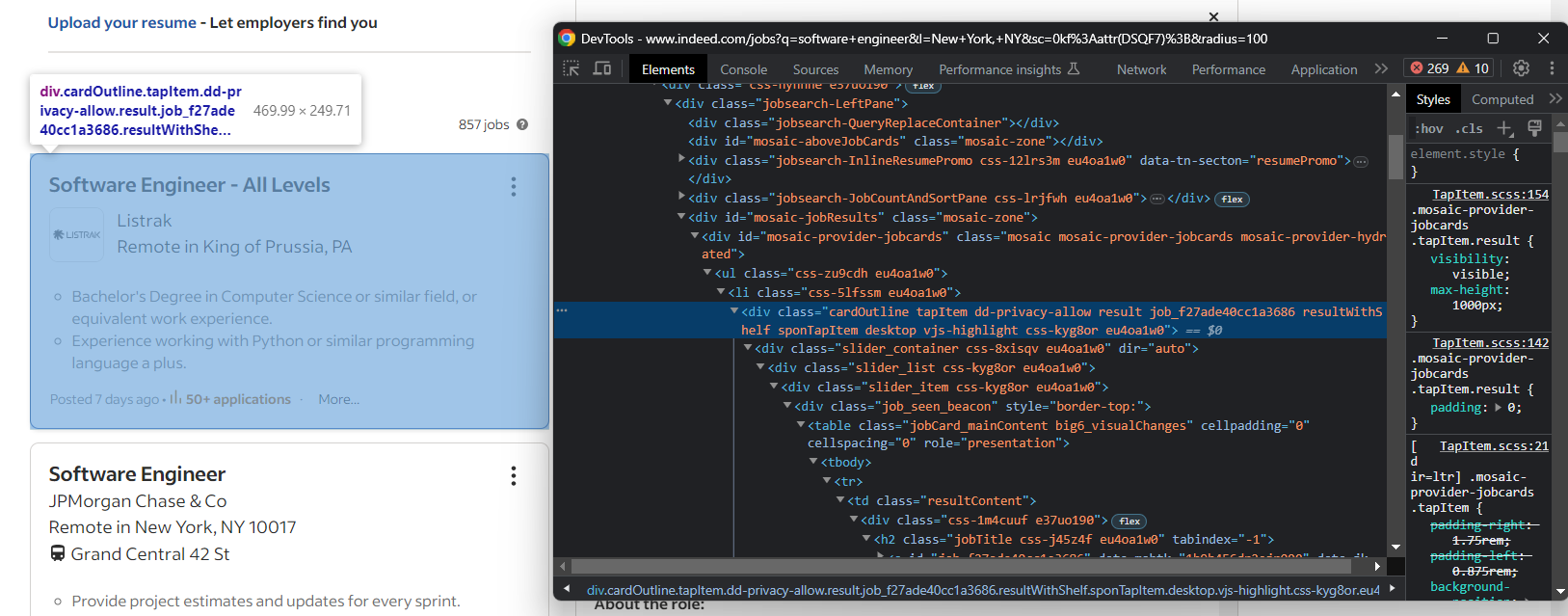
Selecione todos eles com:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
O método find_elements() do Selenium permite localizar elementos da web em uma página da web. Da mesma forma, também existe o método find_element() para obter o primeiro nó que corresponde à consulta de seleção.
By.CSS_SELECTOR instrui o driver a usar uma estratégia de seletor CSS. O Selenium também suporta:
By.ID: para pesquisar um elemento pelo atributo HTMLidBy.TAG_NAME: para pesquisar elementos com base em sua tag HTMLBy.XPATH: para pesquisar elementos por meio de uma expressão XPath
Importar By com:
from selenium.webdriver.common.by import By
Itere sobre a lista de cartões de trabalho e inicialize um dicionário Python onde armazenar os detalhes do trabalho:
para cartão_de_vaga em cartões_de_vaga:
# inicialize um dicionário para armazenar os dados da vaga coletados
vaga = {}
# lógica de extração de dados da vaga...
Uma oferta de emprego pode ter vários atributos. Como apenas uma pequena parte deles é obrigatória, inicialize imediatamente uma lista de variáveis com valores padrão:
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
Agora que você está familiarizado com a página, sabe que alguns detalhes estão no cartão de trabalho do esboço. Outros estão na guia de detalhes que aparece após a interação.
Por exemplo, a data de criação e o número de inscrições estão na guia de resumo:
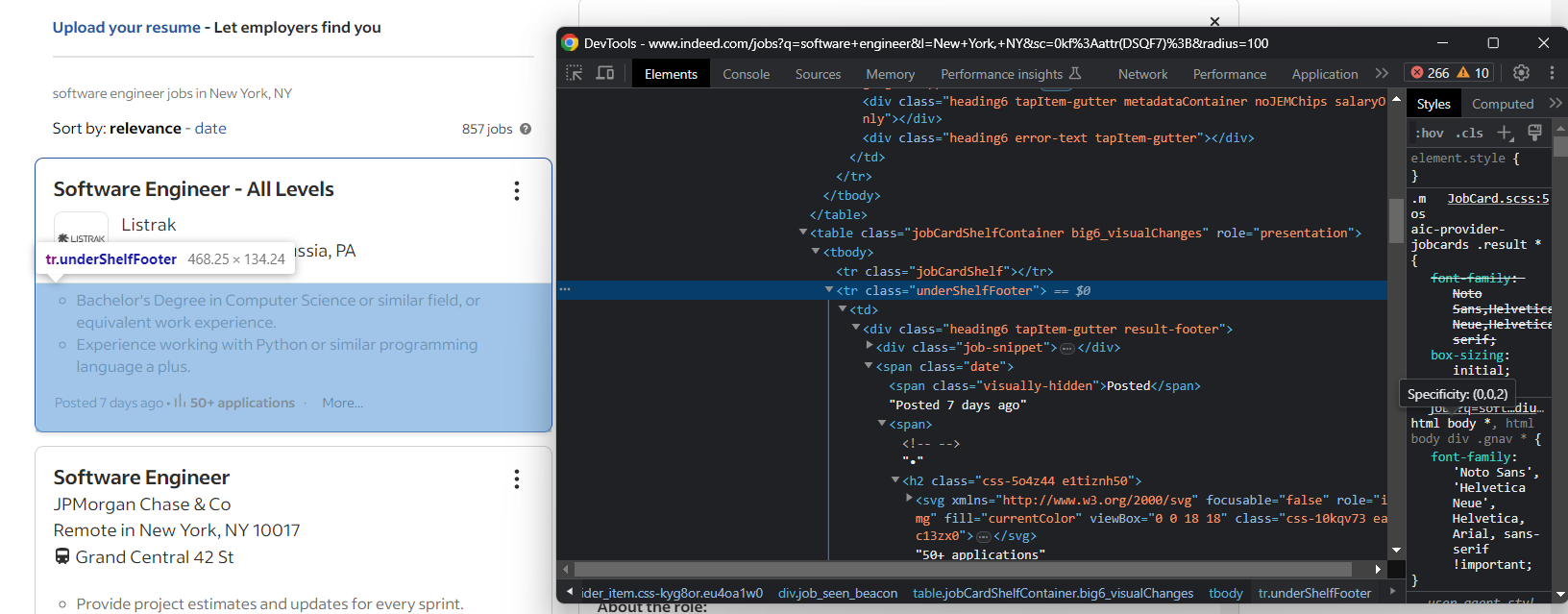
Extraia ambos com:
tente:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
se "•" em date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("in progress", "")
.strip()
posted_at = posted_at_text
.replace("Posted", "")
.replace("Employer", "")
.replace("Active", "")
.strip()
exceto NoSuchElementException:
pass
Este trecho destaca alguns padrões que são fundamentais para o Scraping de dados de anúncios de emprego do Indeed. Como a maioria dos elementos de informação são opcionais, você deve se proteger contra o seguinte erro:
selenium.common.exceptions.NoSuchElementException: Mensagem: elemento inexistente
O Selenium gera esse erro ao tentar selecionar um elemento HTML que não está atualmente na página.
Importe a exceção com:
from selenium.common import NoSuchElementException
A instrução try ... catch garante que, se o elemento de destino não estiver no DOM, o script continuará sem falhas.
Além disso, algumas informações da tarefa estão contidas em strings como:
<info_1> • <info_2>
Se <info_2> estiver faltando, o formato da string será:
<info_1>
Portanto, você precisa alterar a lógica de extração de dados com base na presença do caractere "``•``".
Dado um elemento HTML, você pode acessar seu conteúdo de texto com o atributo text. Use as strings replace() do Python para limpar as strings coletadas.
Etapa 6: Lide com as medidas anti-scraping do Indeed
O Indeed adota algumas técnicas e tecnologias para impedir que bots acessem seus dados. Por exemplo, ao interagir com os cartões de emprego, ele tende a abrir este modal de vez em quando:
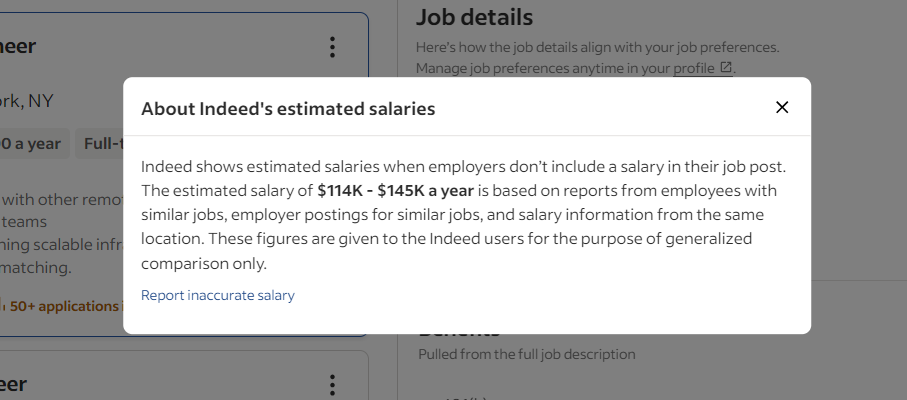
Este pop-up bloqueia a interação. Se não for tratado adequadamente, ele interromperá seu script Selenium Indeed. Inspecione-o no DevTools e preste atenção ao botão Fechar:
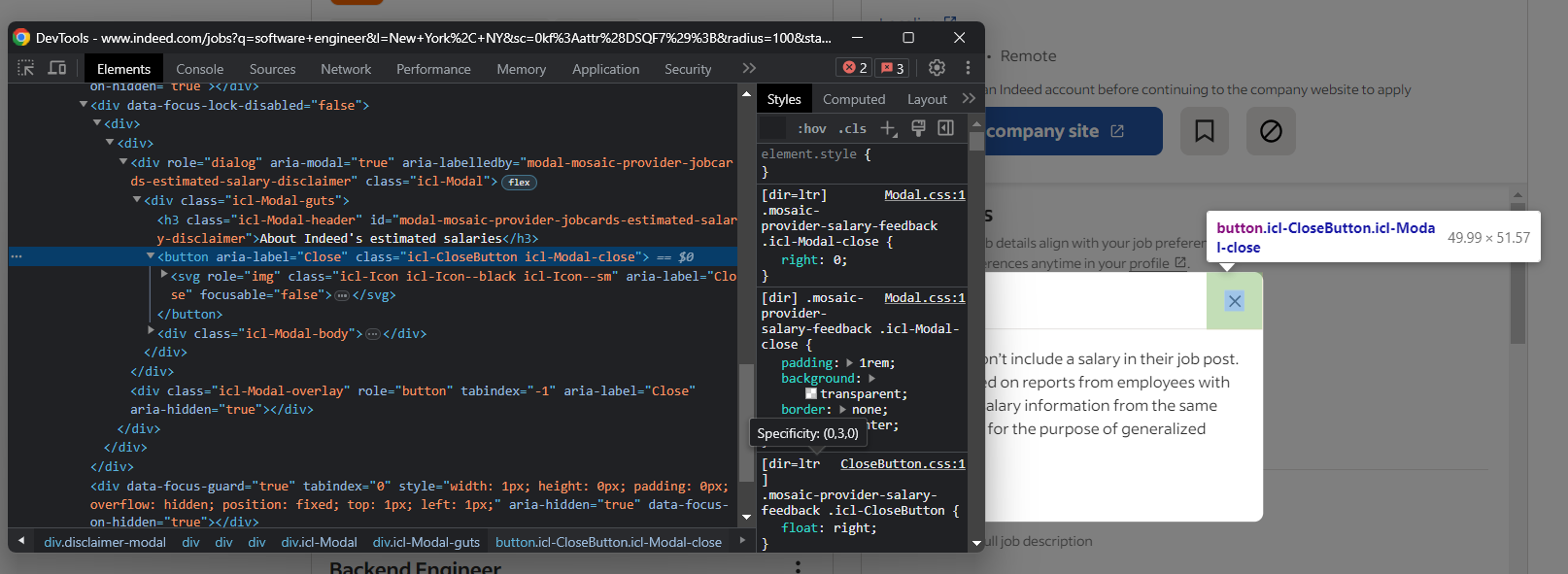
Feche este modal no Selenium com:
tente:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
exceto NoSuchElementException:
pass
O método click() do Selenium permite clicar no elemento selecionado no navegador controlado.
Ótimo! Isso fechará a janela pop-up e permitirá que você continue a interação.
Outra técnica de proteção de dados a ser levada em consideração é o Cloudflare. Ao interagir demais com a página e produzir muitas solicitações, o Indeed exibirá esta tela anti-bot:
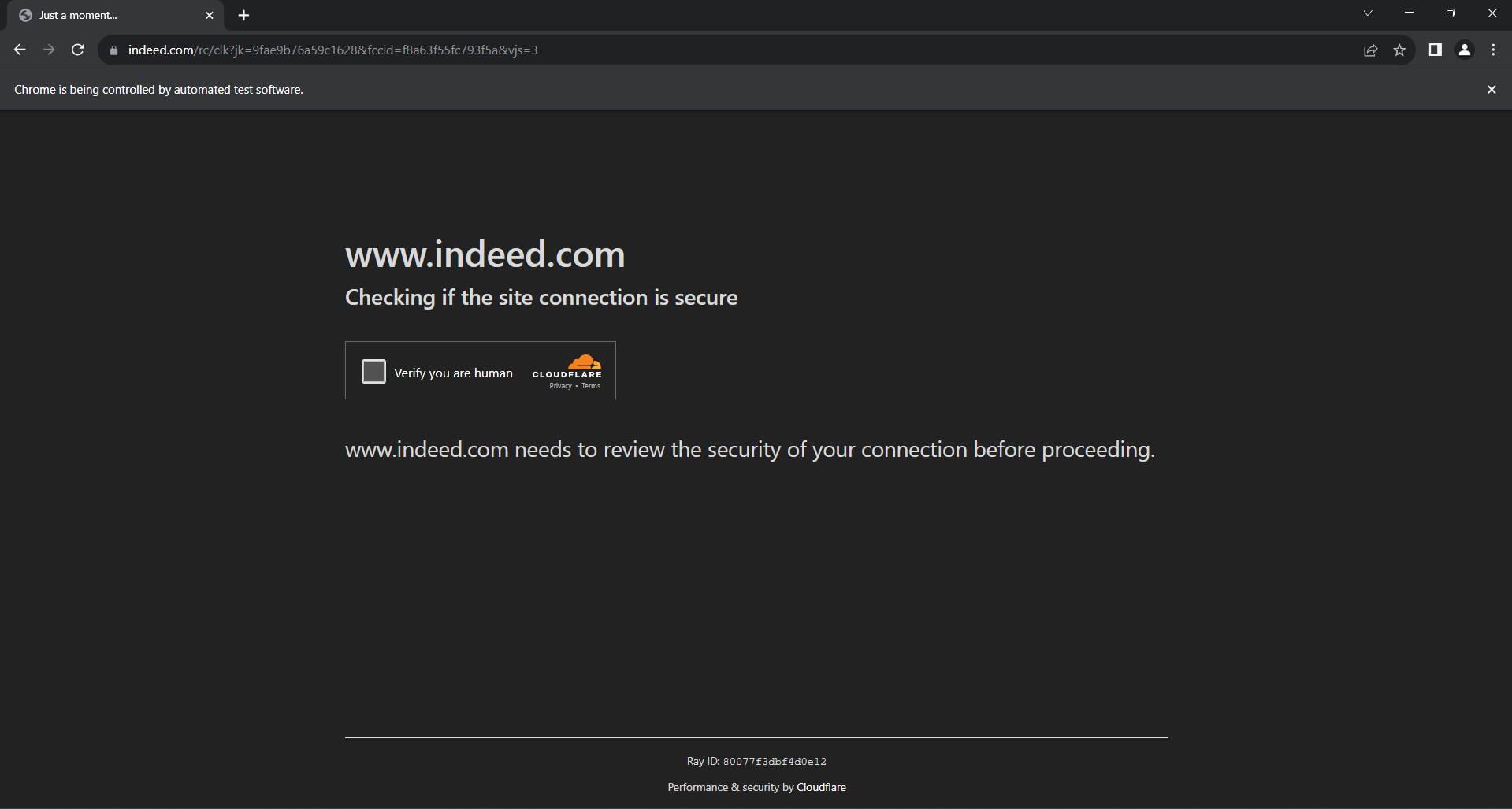
A resolução de CAPTCHAs do Cloudflare a partir do Selenium é uma tarefa muito desafiadora que requer um produto premium. Afinal, não é tão fácil fazer scraping no Indeed. Felizmente, você pode evitá-los introduzindo alguns atrasos aleatórios em seu script.
Certifique-se de que a última operação em seu loop for seja:
time.sleep(random.uniform(1, 5))
Isso interromperá o script por um número aleatório de segundos, de 1 a 5.
Importe os pacotes necessários da Biblioteca Padrão do Python com:
import random
import time
Muito bem! Nada impedirá seu script automatizado de fazer scraping no Indeed.
Etapa 7: Abra o cartão de detalhes da vaga
Quando você clica em um cartão de vaga, o Indeed realiza uma chamada AJAX para recuperar os detalhes instantaneamente. Enquanto aguarda esses dados, a página exibe um espaço reservado animado:
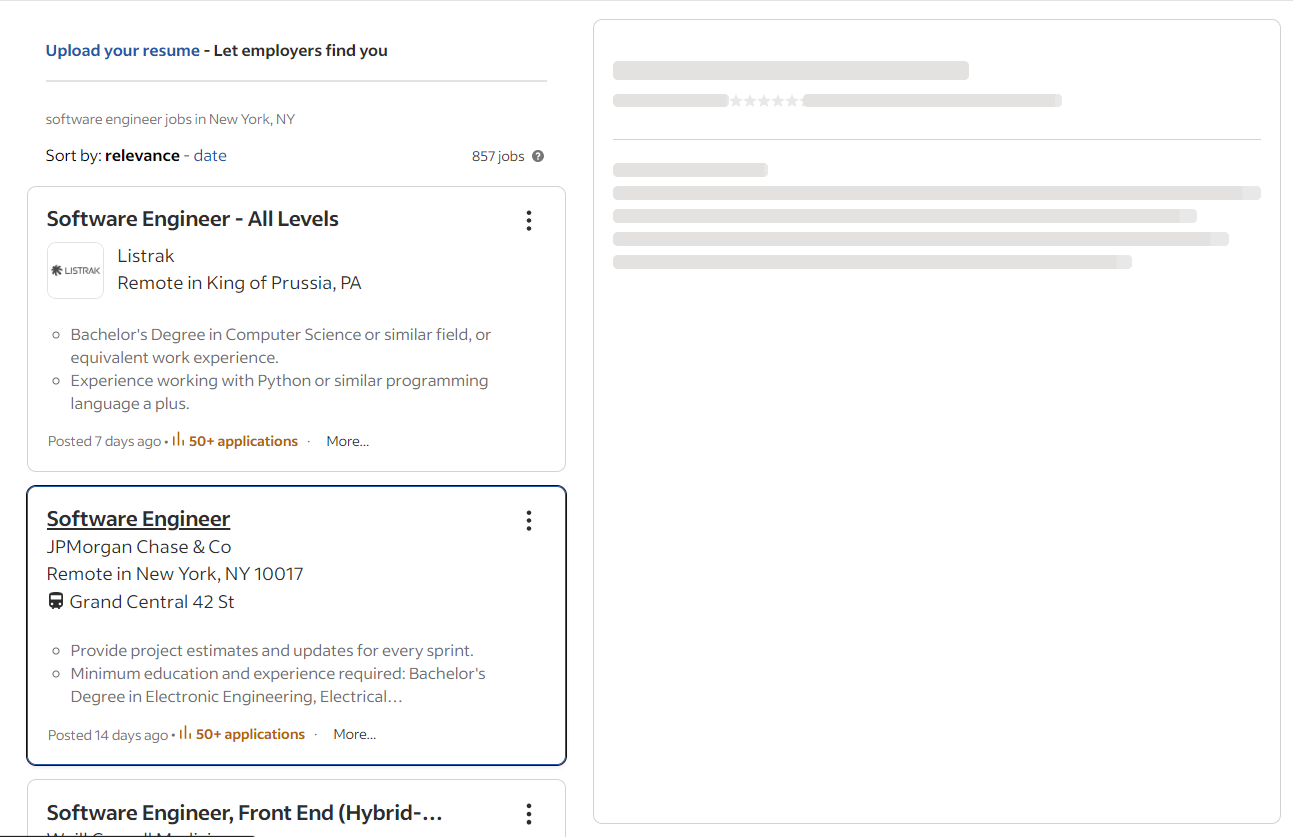
Você pode verificar se as seções de detalhes foram carregadas quando o elemento abaixo estiver na página:
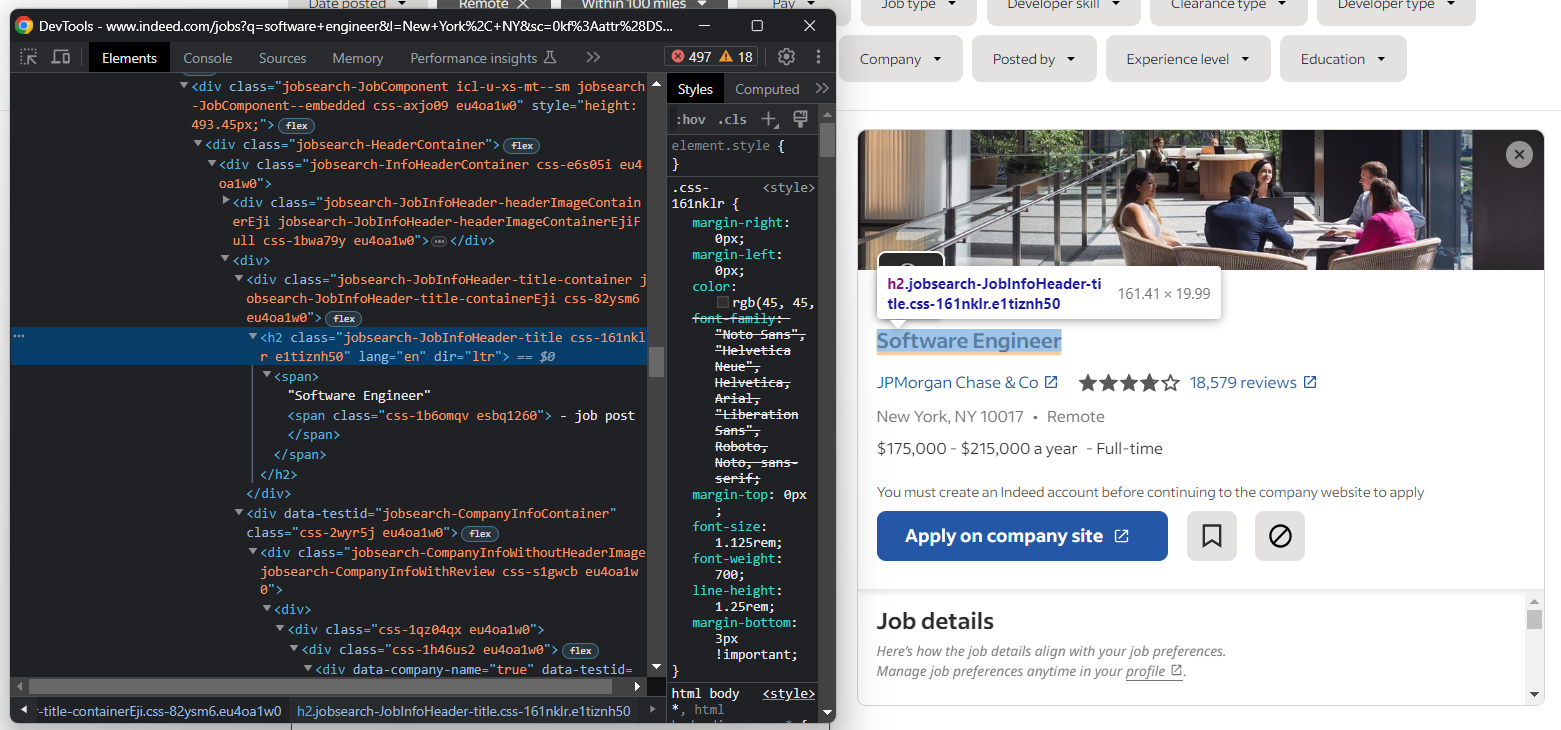
Portanto, para ter acesso aos dados detalhados da vaga no Selenium, você precisa:
- Executar a operação de clique
- Aguardar até que a página contenha os dados de interesse
Consiga isso com:
job_card.click()
tente:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
exceto NoSuchElementException:
continue
O objeto WebDriverWait do Selenium permite que você aguarde até que uma condição específica ocorra. Neste caso, o script aguarda até 5 segundos para que .jobsearch-JobInfoHeader-title apareça na página. Depois disso, ele lançará uma TimeoutException.
Observe que o trecho acima também recupera o título da vaga de emprego.
Importe WebDriverWait e EC:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
A partir de agora, o elemento a ser focado é esta coluna de detalhes:
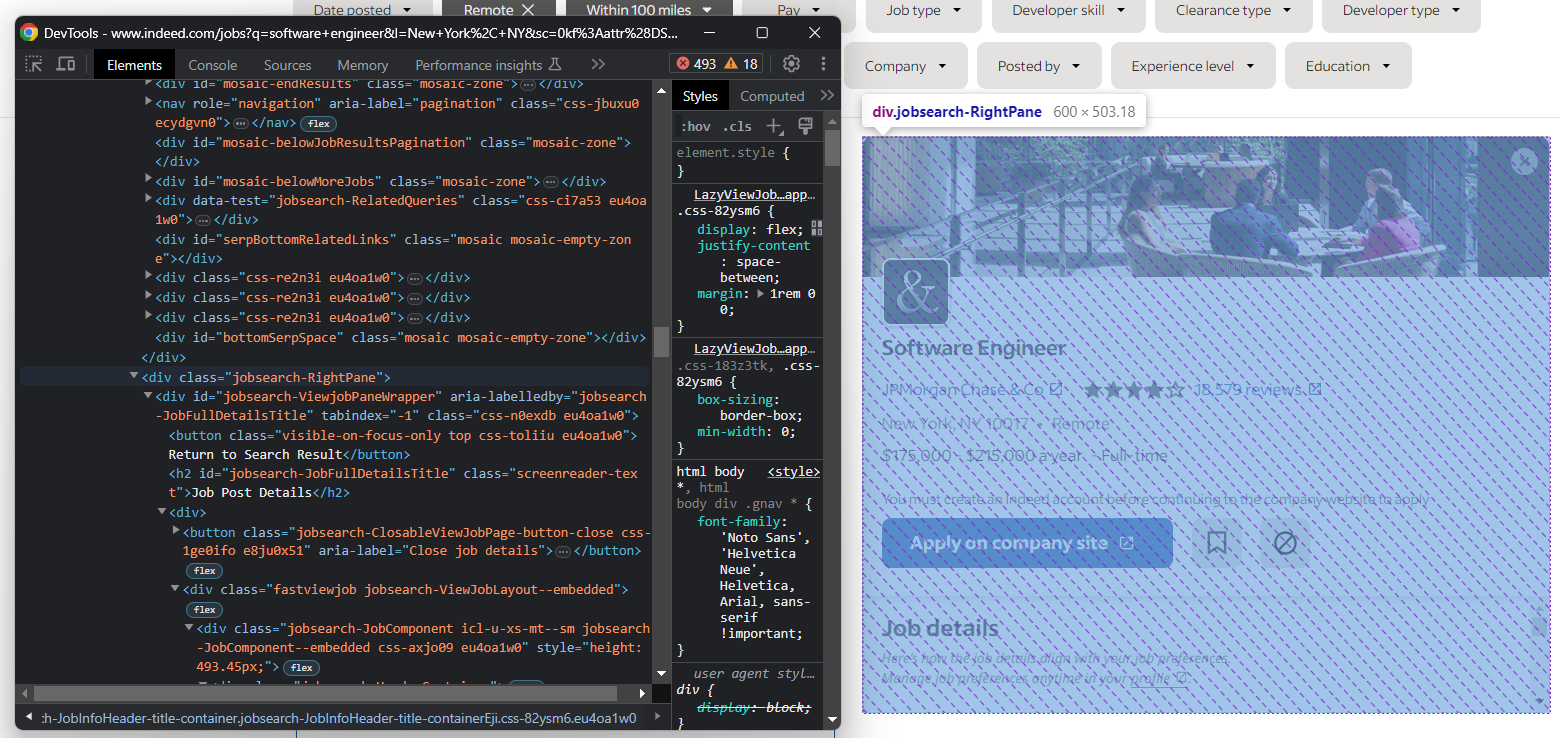
Selecione-a com:
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
Ótimo! Você está pronto para coletar alguns dados de vagas!
Etapa 8: extraia os detalhes da vaga
É hora de preencher as variáveis que definimos na etapa 4 com alguns dados de vagas.
Obtenha o nome da empresa responsável pela vaga:
tente:
elemento_link_da_empresa = elemento_detalhes_da_vaga.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
nome_da_empresa = elemento_link_da_empresa.text
exceto NoSuchElementException:
pass
Em seguida, extraia informações sobre as avaliações dos usuários e o número de avaliações da empresa:
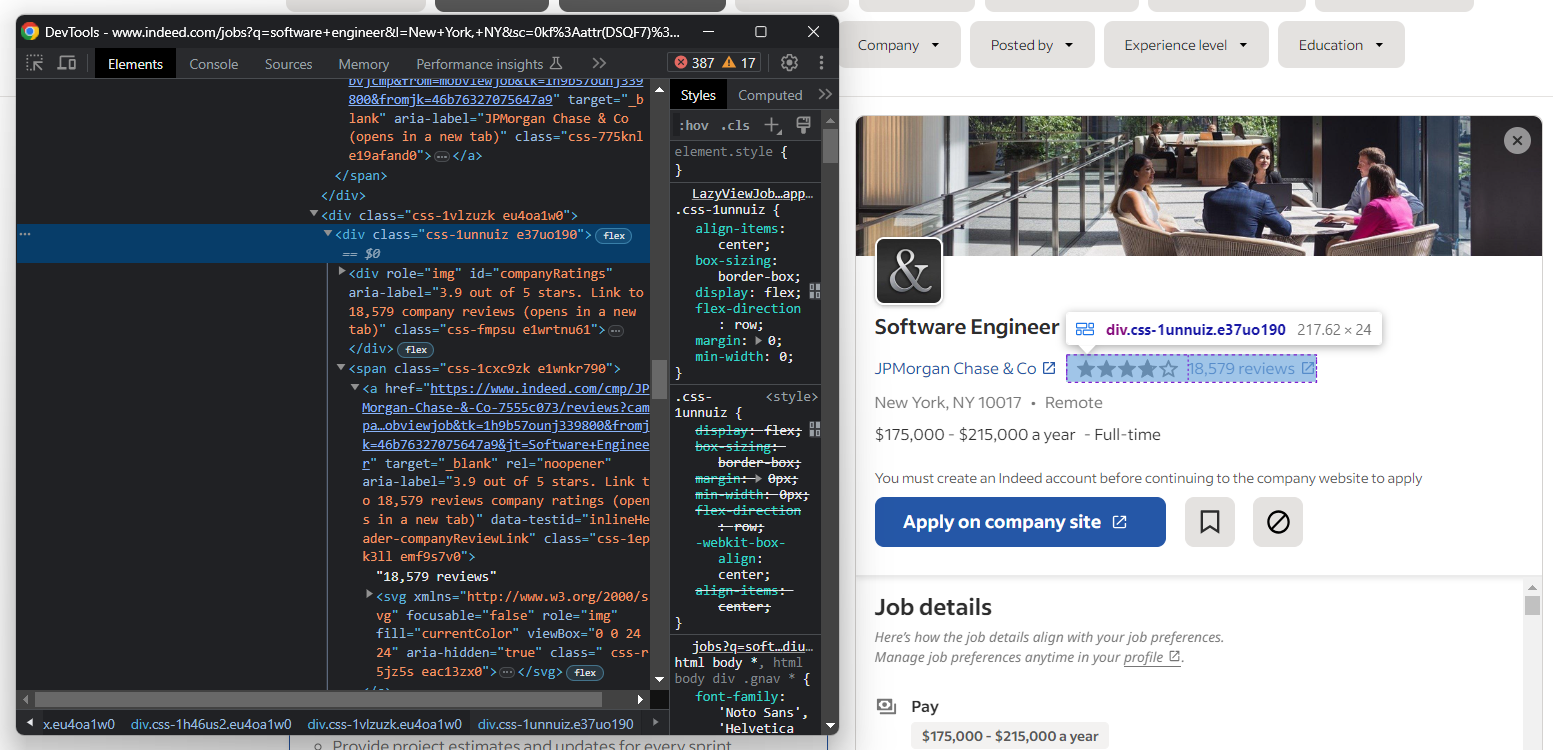
Como você pode ver, não há uma maneira fácil de acessar o elemento que armazena o número de avaliações.
tente:
elemento_avaliação_da_empresa = elemento_detalhes_do_emprego.find_element(By.ID, "companyRatings")
avaliação_da_empresa = elemento_avaliação_da_empresa.get_attribute("aria-label").split("out")[0].strip()
elemento_avaliações_da_empresa = elemento_detalhes_do_emprego.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
avaliações_da_empresa = elemento_avaliações_da_empresa.text.replace(" avaliações", "")
exceto NoSuchElementException:
pass
Em seguida, concentre-se na localização da empresa:
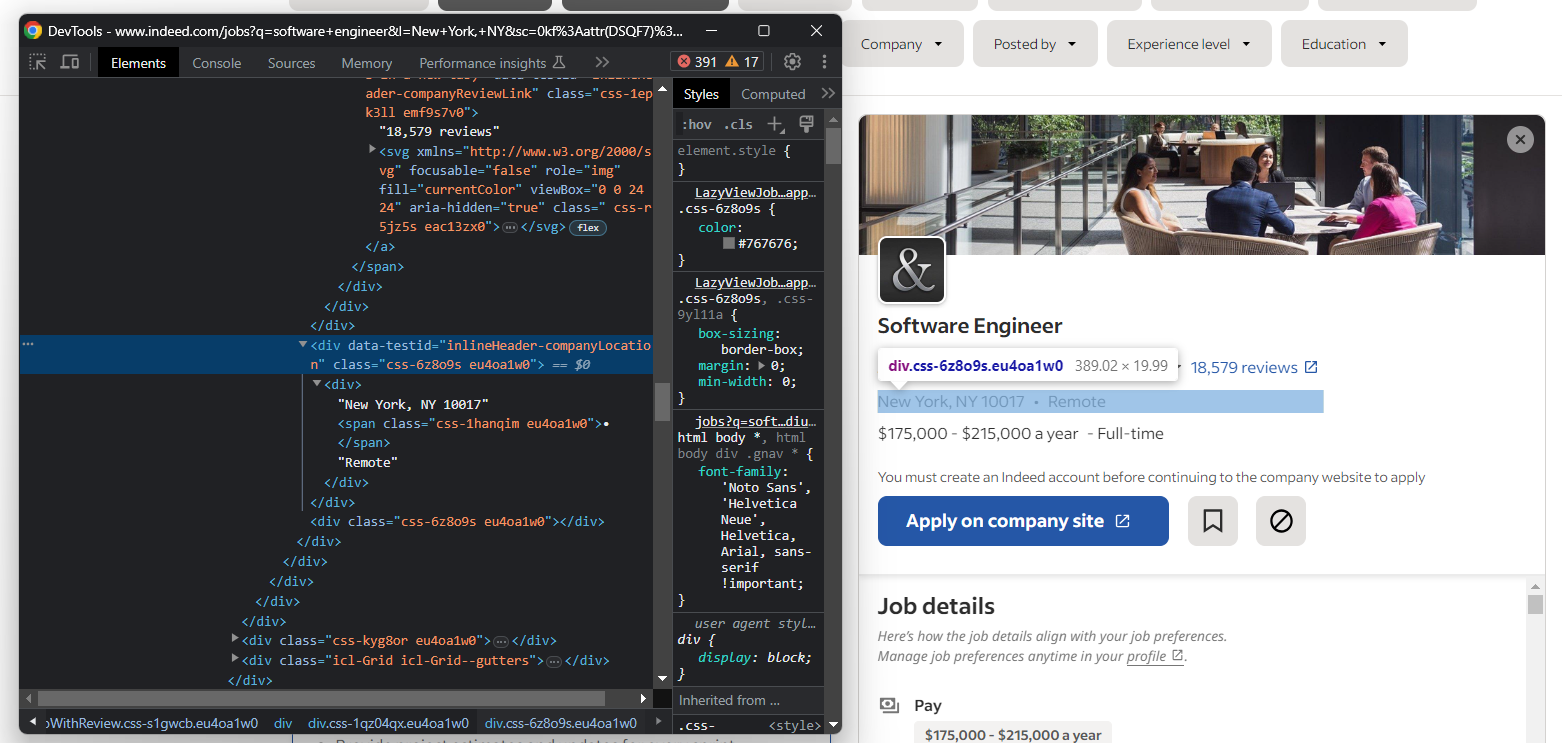
Novamente, você precisa aplicar o padrão "``•``" mencionado na etapa 4:
tente:
elemento_localização_da_empresa = elemento_detalhes_do_emprego.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
texto_elemento_localização_da_empresa = elemento_localização_da_empresa.text
localização = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
localização = company_location_element_text_array[0]
tipo_de_localização = company_location_element_text_array[1]
exceto NoSuchElementException:
pass
Como você pode querer se candidatar rapidamente ao emprego, dê uma olhada também no botão “Candidatar-se no site da empresa” do Indeed:
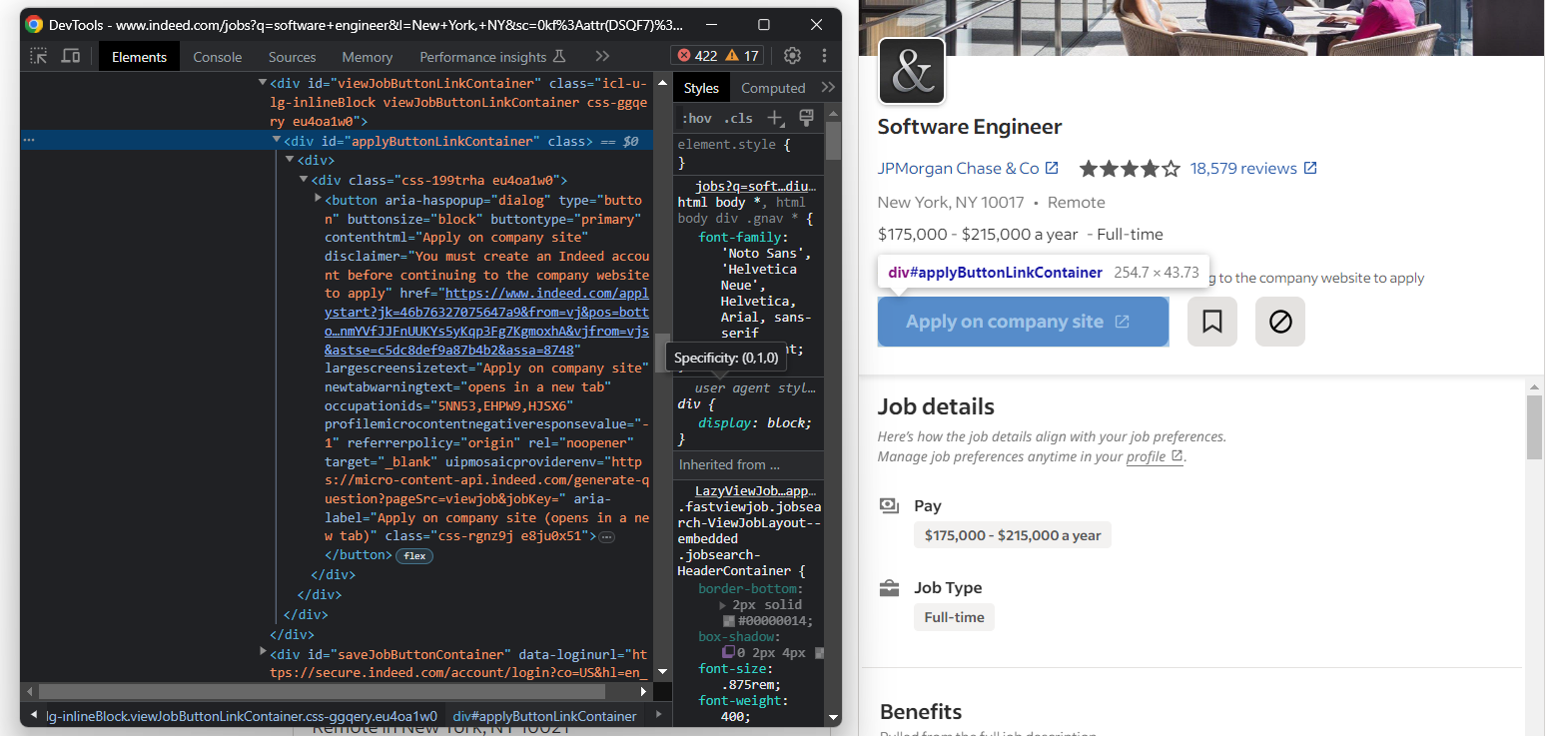
Recupere a URL de destino do botão com:
tente:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
exceto NoSuchElementException:
passe
O get_attribute() do Selenium retorna o valor do atributo HTML especificado.
Agora, começa a parte complicada.
Se você inspecionar a seção “Detalhes do trabalho”, perceberá que não há uma maneira fácil de selecionar os elementos de remuneração e tipo de trabalho:
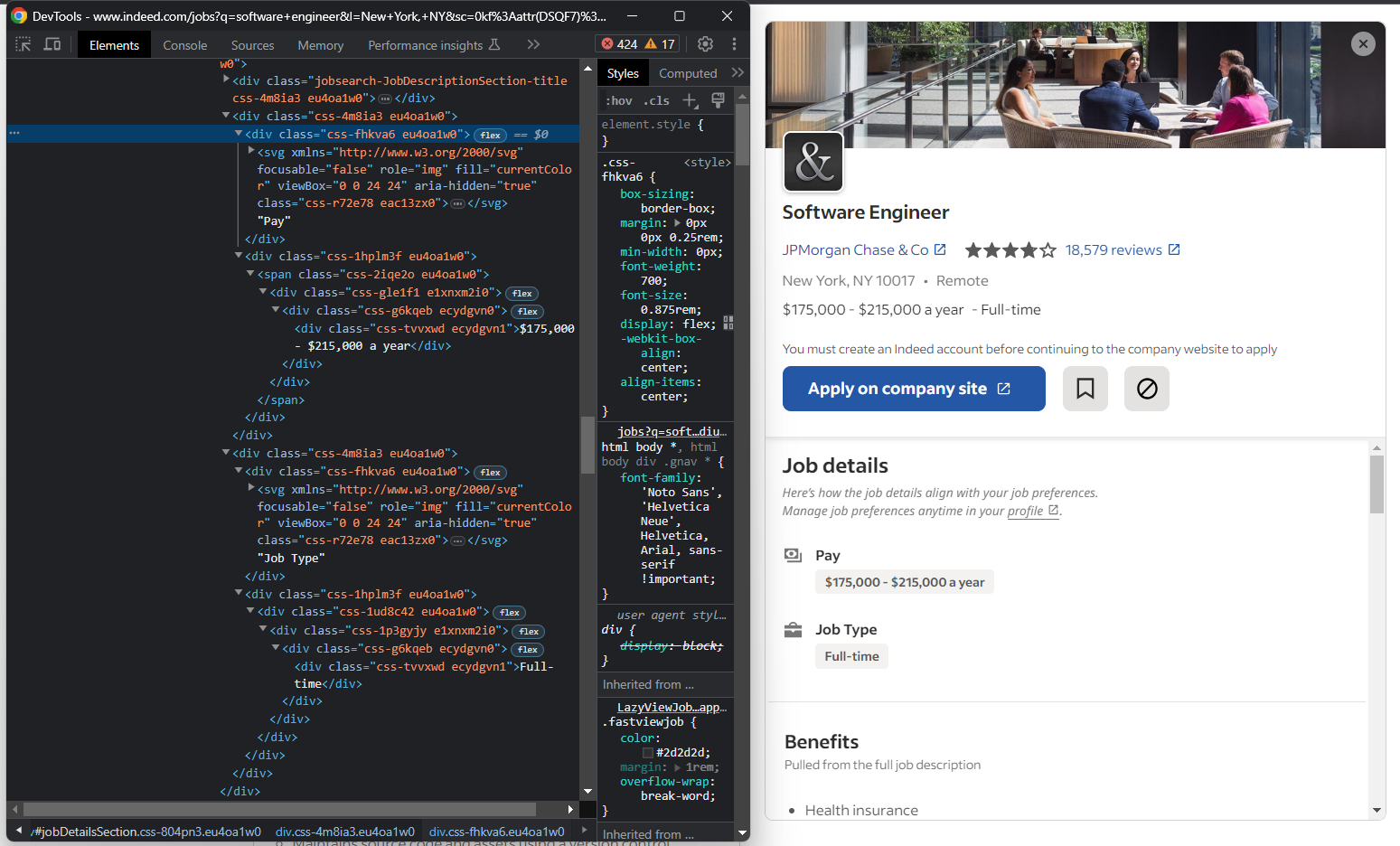
O que você pode fazer é:
- Obter todos os
<div>s dentro do<div>“Detalhes do trabalho” - Iterar sobre eles
- Se o texto do
<div>atual contiver “Remuneração” ou “Tipo de trabalho”, obtenha o próximo irmão - Extrair os dados de interesse
Em outras palavras, você deve implementar a lógica abaixo:
para div em job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
se div.text == "Remuneração":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Tipo de emprego":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
O Selenium não fornece um método utilitário para acessar os irmãos de um nó. O que você pode fazer é usar a expressão Xpath following-sibling::*.
Agora, concentre-se nos benefícios do trabalho. Normalmente, há mais de um:
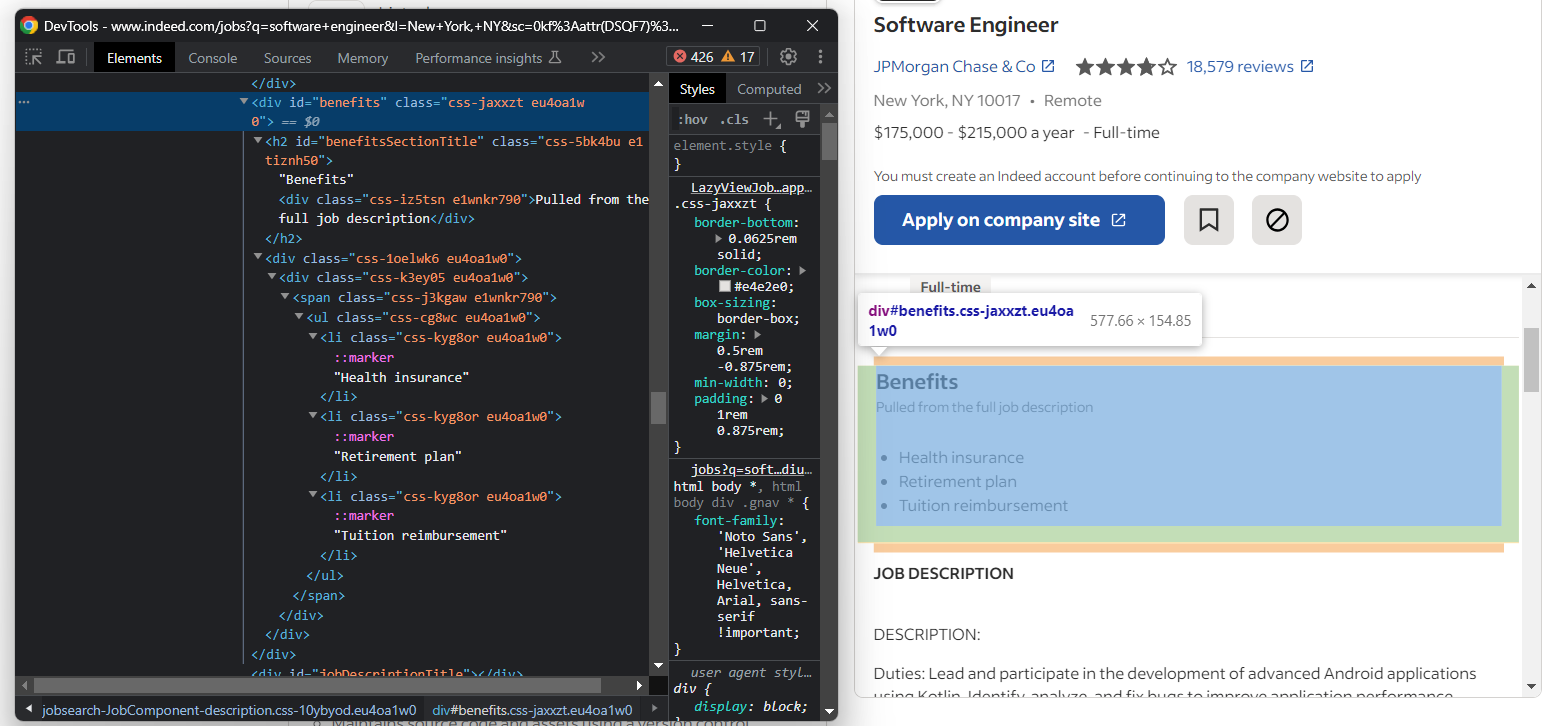
Para recuperá-los todos, você precisa inicializar uma lista e preenchê-la com:
tente:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
para benefit_element em benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
exceto NoSuchElementException:
passe
Por fim, obtenha a descrição bruta do trabalho:
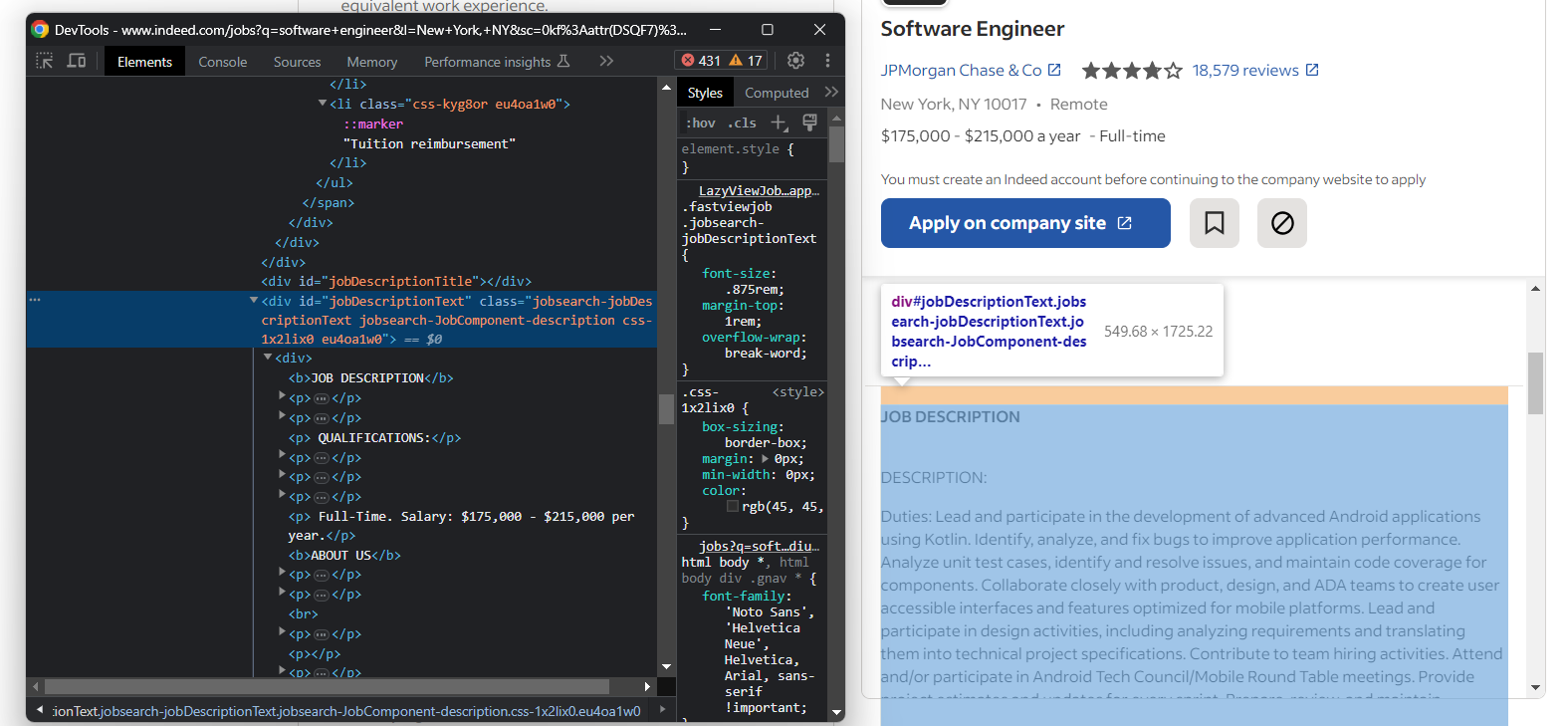
Extraia o texto da descrição com:
tente:
elemento_descrição = elemento_detalhes_do_trabalho.find_element(By.ID, "jobDescriptionText")
descrição = elemento_descrição.text
exceto NoSuchElementException:
passe
Preencha o dicionário de vagas e adicione-o à lista de vagas:
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = localização
job["location_type"] = tipo de localização
job["apply_link"] = link para se candidatar
job["pay"] = remuneração
job["job_type"] = tipo de emprego
job["benefits"] = benefícios
job["description"] = descrição
jobs.append(job)
Você também pode adicionar uma instrução de log para verificar se o script funciona conforme o esperado:
imprimir(trabalho)
Execute o script:
python Scraper.py
Isso produzirá uma saída semelhante a:
{'posted_at': '17 dias atrás', 'applications': '50+', 'title': 'Engenheiro de Suporte de Software', 'company_name': 'Integrated DNA Technologies (IDT)', 'company_rating': '3.5', 'company_reviews': '95', 'location': 'Nova York, NY 10001', 'tipo_de_localização': 'Remoto', 'link_de_candidatura': 'https://www.indeed.com/applystart?jk=c00120130a9c933b&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9fpft0fj3t3800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXiYhWlsa56nLum9aT96NeA9XAwdulcUk0atwlDdDDqlBQ&vjfrom=tp-semfirstjob&astse=bcf3778ad128bc26&assa=2447', 'pay': '$80.000 - $100.000 por ano', 'job_type': 'Tempo integral', 'benefícios': ['401(k)', '401(k) correspondente', 'Seguro odontológico', 'Seguro saúde', 'Licença parental remunerada', 'Férias remuneradas', 'Licença parental', 'Seguro oftalmológico'], 'descrição': “A Integrated DNA Technologies (IDT) é líder na fabricação de oligonucleotídeos personalizados e tecnologias proprietárias para (omitido por brevidade...)”}
Et voilà! Você acabou de aprender como extrair anúncios de emprego de sites.
Etapa 9: extraia várias páginas de vagas de emprego
Uma busca típica de emprego no Indeed produz uma lista paginada com dezenas de resultados. Viu como extrair cada página!
Primeiro, inspecione uma página e observe como o Indeed se comporta. Em detalhes, ele mostra o seguinte elemento quando há uma próxima página disponível.
Caso contrário, o elemento da próxima página está ausente:
Lembre-se de que o Indeed pode retornar uma lista com centenas de vagas de emprego. Como você não quer que seu script seja executado indefinidamente, considere adicionar um limite ao número de páginas coletadas.
Implemente o rastreamento da web no Indeed no Selenium com:
pages_scraped = 0
pages_to_scrape = 5
while pages_scraped < pages_to_scrape:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# lógica de raspagem...
pages_scraped += 1
# se esta não for a última página, vá para a próxima página
# caso contrário, interrompa o loop while
tente:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
exceto NoSuchElementException:
break
O Scraper do Indeed agora continuará em loop até chegar à última página ou passar por 5 páginas.
Etapa 10: Exporte os dados coletados para JSON
No momento, os dados coletados estão armazenados em uma lista de dicionários Python. Exporte-os para JSON para facilitar o compartilhamento e a leitura.
Primeiro, crie um objeto de saída:
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
O atributo de data é necessário porque as datas de publicação das vagas de emprego estão no formato “<X> dias atrás”. Sem algum contexto sobre o dia em que os dados de vagas foram coletados, seria difícil entendê-los.
Lembre-se de importar datetime:
from datetime import datetime
Em seguida, exporte-o com:
import json
# lógica de coleta...
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
O trecho acima inicializa um arquivo de saída jobs.json com open() e o preenche com dados JSON via json.dump(). Confira nosso artigo para saber mais sobre como realizar Parsing e serializar dados para JSON em Python.
O pacote json vem da Biblioteca Padrão do Python, então você nem precisa instalar uma dependência extra para atingir o objetivo.
Uau! Você começou com dados brutos de empregos contidos em uma página da web e agora tem dados JSON semiestruturados. Você está pronto para dar uma olhada em todo o script Python de Scraping de dados do Indeed.
Etapa 11: Junte tudo
Aqui está o arquivo scraper.py completo:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import random
import time
from datetime import datetime
import json
# configurar uma instância controlável do Chrome
# no modo headless
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# abrir a página de destino no navegador
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# definir o tamanho da janela para garantir que as páginas
# não sejam renderizadas no modo responsivo
driver.set_window_size(1920, 1080)
# uma estrutura de dados onde armazenar as vagas de emprego
# extraídas da página
jobs = []
pages_scraped = 0
pages_to_scrape = 3
enquanto pages_scraped < pages_to_scrape:
# selecione os cartões de anúncios de vagas na página
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
para job_card em job_cards:
# inicialize um dicionário para armazenar os dados das vagas coletados
job = {}
# inicializar os atributos da vaga a serem coletados
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
# obter os dados gerais do emprego a partir do cartão de resumo
tente:
elemento_data = cartão_emprego.find_element(By.CSS_SELECTOR, ".date")
texto_elemento_data = elemento_data.text
texto_publicado_em = elemento_data.text
se "•" em date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.substituir("em andamento", "")
.remover()
publicado_em = publicado_em_texto
.substituir("Publicado", "")
.substituir("Empregador", "")
.substituir("Ativo", "")
.remover()
exceto NoSuchElementException:
passar
# fechar o modal anti-scraping
tente:
elemento_dialogo = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
botão_fechar = elemento_dialogo.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
botão_fechar.clicar()
exceto NoSuchElementException:
passar
# carregar o cartão de detalhes do trabalho
job_card.click()
# aguardar o carregamento da seção de detalhes do trabalho após o clique
tente:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
exceto NoSuchElementException:
continue
# extrair os detalhes do trabalho
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
tente:
elemento_link_empresa = elemento_detalhes_da_vaga.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
nome_da_empresa = elemento_link_empresa.text
exceto NoSuchElementException:
pass
tente:
elemento_classificação_da_empresa = elemento_detalhes_da_vaga.find_element(By.ID, "companyRatings")
classificação_da_empresa = elemento_de_classificação_da_empresa.get_attribute("aria-label").split("out")[0].strip()
elemento_de_avaliações_da_empresa = elemento_de_detalhes_do_emprego.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
exceto NoSuchElementException:
pass
tente:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
elemento_localização_da_empresa_texto = elemento_localização_da_empresa.texto
localização = elemento_localização_da_empresa_texto
se "•" em elemento_localização_da_empresa_texto:
elemento_localização_da_empresa_texto_matriz = elemento_localização_da_empresa_texto.split("•")
localização = elemento_localização_da_empresa_texto_matriz[0]
tipo_localização = empresa_localização_elemento_texto_array[1]
exceto NoSuchElementException:
passar
tentar:
aplicar_link_elemento = detalhes_da_vaga_elemento.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
aplicar_link = aplicar_link_elemento.get_attribute("href")
exceto NoSuchElementException:
pass
para div em job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
se div.text == "Remuneração":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
para benefit_element em benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
exceto NoSuchElementException:
pass
tente:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
descrição = elemento_descrição.texto
excepto NoSuchElementException:
passar
# armazenar os dados extraídos
emprego["publicado_em"] = publicado_em
emprego["candidaturas"] = candidaturas
emprego["título"] = título
emprego["nome_da_empresa"] = nome_da_empresa
emprego["classificação_da_empresa"] = classificação_da_empresa
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
# espere por um número aleatório de segundos entre 1 e 5
# para evitar bloqueios de limitação de taxa
time.sleep(random.uniform(1, 5))
# incremente o contador de raspagem
pages_scraped += 1
# se esta não for a última página, vá para a próxima página
# caso contrário, interrompa o loop while
tente:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
exceto NoSuchElementException:
break
# feche o navegador e libere os recursos
driver.quit()
# produza o objeto de saída
saída = {
"data": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"empregos": empregos
}
# exporte para JSON
com open("empregos.json", "w") como arquivo:
json.dump(saída, arquivo, indent=4)
Em menos de 200 linhas de código, você acabou de criar um Scraper completo para extrair dados de vagas do Indeed.
Execute-o com:
python Scraper.py
Aguarde alguns minutos até que o script seja concluído
Ao final do processo de extração, um arquivo jobs.json aparecerá na pasta raiz do seu projeto. Abra-o e você verá:
{
"date": "2023-09-02 19:56:44",
"jobs": [
{
"posted_at": "7 dias atrás",
"applications": "50+",
"title": "Engenheiro de Software - Todos os Níveis",
"company_name": "Listrak",
"company_rating": "3",
"company_reviews": "5",
"location": "King of Prussia, PA",
"location_type": "Remoto",
"link_para_candidatura": "https://www.indeed.com/applystart?jk=f27ade40cc1a3686&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgPYWebWpM-4nO05Ssl8I8z-BhdrQogdzP3xc9-PmOQTQ&vjfrom=vjs&astse=16430083478063d1&assa=2381",
"pay": null,
"job_type": null,
"benefits": [
"Inscrição em academia",
"Férias remuneradas"
],
"description": "Sobre a Listrak: Somos uma empresa de SaaS que oferece uma plataforma integrada de marketing digital na qual mais de 1.000 varejistas e marcas líderes confiam para e-mail, marketing por mensagem de texto, resolução de identidade, gatilhos comportamentais e orquestração multicanal. Nossa sede fica em (omitido por brevidade...)"
},
// omitido por brevidade...
{
“posted_at”: “9 dias atrás”,
“applications”: null,
“title”: “Engenheiro de software, Front End (Híbrido-Remoto)”,
“company_name”: “Weill Cornell Medicine”,
“company_rating”: “3,4”,
"company_reviews": "41",
"location": "Nova Iorque, NY 10021",
"location_type": "Remoto",
"apply_link": "https://www.indeed.com/applystart?jk=1a53a17f1faeae92&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgZADiLYj9Y4htcvtDy_iaWMIfcMu539kP3i1FMxIq2rA&vjfrom=vjs&astse=90a9325429efdf13&assa=4615",
"pagamento": "$99.800 - $123.200 por ano",
"tipo_de_trabalho": nulo,
"benefícios": nulo,
"descrição": "Título: Engenheiro de Software, Front End (Híbrido-Remoto)nTítulo: Engenheiro de Software, Front End (Híbrido-Remoto)nLocalização: Upper East SidenUnidade Organizacional: Olivier Elemento LabnDias de Trabalho: Segunda a Sexta-Feira Status de Isenção: Isento Faixa Salarial: $99.800,00 - $123.200,00nAs (omitido por brevidade...)"
}
}
Parabéns! Você acabou de aprender a fazer scraping no Indeed com Python!
Conclusão
Neste tutorial, você entendeu por que o Indeed é um dos melhores portais de emprego da web e como extrair dados dele. Em particular, você viu como construir um Scraper Python que pode recuperar dados de vagas de emprego dele.
Como mostrado aqui, fazer scraping no Indeed não é uma tarefa fácil. O site vem com uma proteção anti-scraping sorrateira que pode bloquear seu script. Ao lidar com sites como esse, você precisa de um navegador controlável que seja capaz de lidar automaticamente com CAPTCHAs, impressões digitais, tentativas automatizadas e muito mais para você. É exatamente isso que nosso novo Navegador de scraping oferece!
Não quer lidar com Scraping de dados, mas está interessado em dados de vagas de emprego? Explore nossos Conjuntos de dados do Indeed e nosso conjunto de dados de vagas de emprego. Registre-se agora e comece seu Teste grátis.
Observação: este guia foi exaustivamente testado por nossa equipe no momento da redação, mas como os sites atualizam frequentemente seu código e estrutura, algumas etapas podem não funcionar mais como esperado.





